Chapter 1. Mind the Semantic Gap
Our agreement or disagreement is at times based on a misunderstanding.
Mokokoma Mokhonoana
In the era of the big data and AI frenzy, data is considered a gold mine that awaits organizations and businesses that will find and extract their gold. Whether you call this data science, data analytics, business intelligence, or something else, you can’t deny that data-related investments have increased significantly, and the demand for data professionals (engineers, analysts, scientists, etc.) has skyrocketed.
Do these professionals manage to find gold? Well, not always. Sometimes, the large ocean of data that an organization claims to have proves to be a small pond. Other times, the data is there but it contains no gold, or at least not the kind of gold that the organization can use. Often it is also the case that both data and gold are there, but the infrastructure or technology needed for the gold’s extraction are not yet available or mature enough. But it can also be that data professionals have all they wish (abundance of the right data, gold to be found, and state-of-the-art technology) and still fail. The reason? The semantic gap between the data supply and the data exploitation side.
Let me explain. As data practitioners, many of us work mainly on the data supply side: we collect and generate data, we represent, integrate, store, and make it accessible through data models, and we get it ready for usage and exploitation. Others of us work mainly on the data exploitation side: we use data to build predictive, descriptive, or other types of analytics solutions, as well as build and power AI applications. And many of us wear both hats. We all have the same mission, though: to derive value from data.
This mission is often compromised by what I like to call the semantic gap—the situation that arises when the data models of the supply side are misunderstood and misused by the exploitation side, and/or when the data requirements of the exploitation side are misunderstood by the supply side. In both cases, the problem is caused by insufficient or problematic modeling of the data’s semantics. This book is about helping practitioners of both sides work better with semantic data models and narrow (if not close) the semantic gap.
What Is Semantic Data Modeling?
Semantics is the study of meaning, concerned with the relationship between signifiers that people use when interacting with the world (words, phrases, signs, and symbols), and the things in that world that these signifiers denote (entities, concepts, ideas). The goal is the creation of a common understanding of the meaning of things, helping people understand each other despite different experiences or points of view. When applied in computer science, semantics helps computer systems interpret more accurately what people and the data they produce mean, as well as interface more efficiently and productively with other disparate computer systems.
In that sense, semantic data modeling can be defined as the development of descriptions and representations of data in such a way that the latter’s meaning is explicit, accurate, and commonly understood by both humans and computer systems. This definition encompasses a wide range of data artifacts, including metadata schemas, controlled vocabularies, taxonomies, ontologies, knowledge graphs, entity-relationship (E-R) models, property graphs, and other conceptual models for data representation.
As an example, in Figure 1-1 you can see part of the SNOMED CT Standard Ontology, a semantic model that describes the meaning of core medical terms (such as clinical findings, symptoms, diagnoses, medical procedures, and others) by grouping them into concepts, providing them with synonyms and definitions, and relating them to each other through hierarchical and other types of relations [1].
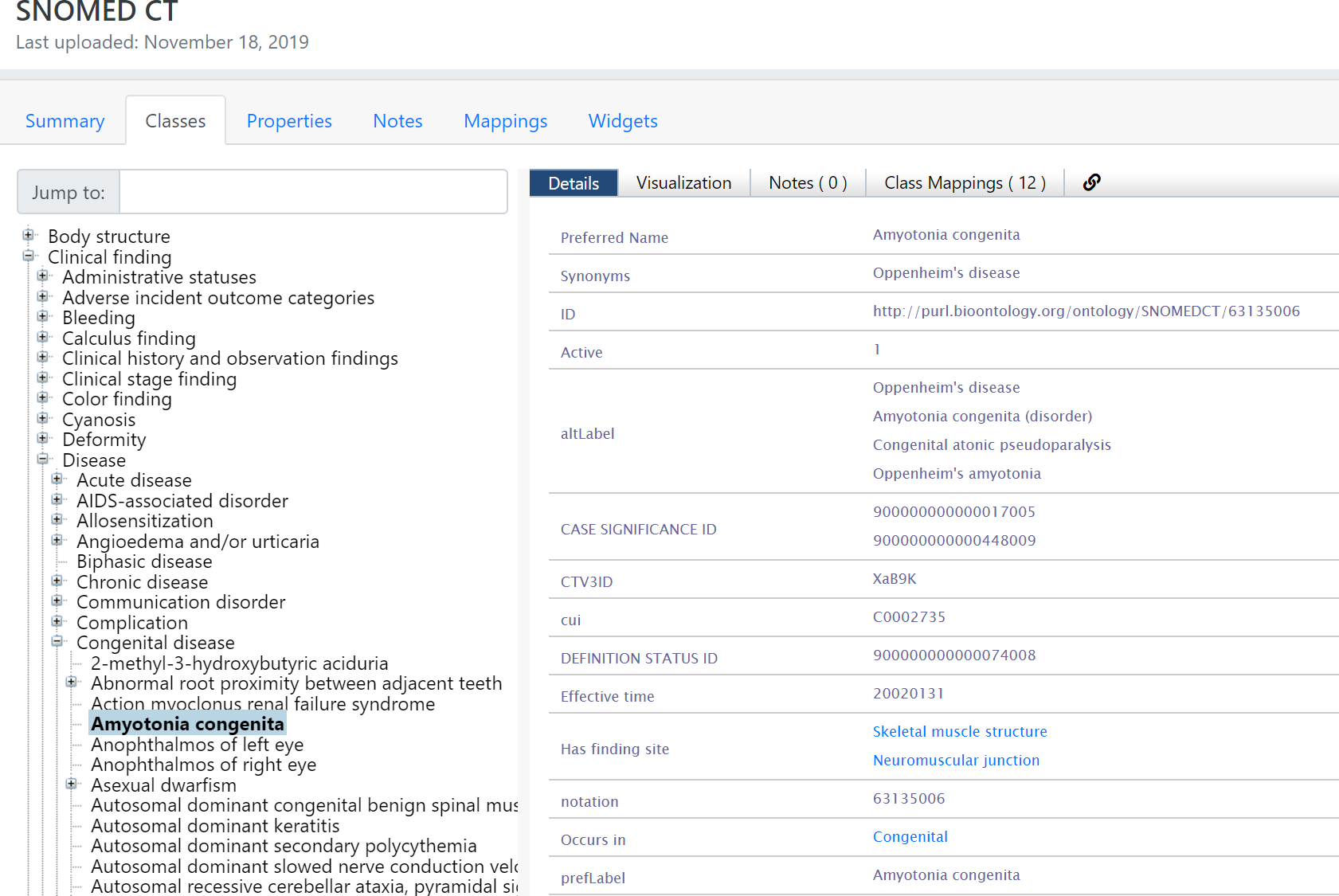
Figure 1-1. View of the SNOMED CT ontology
Similarly, Figure 1-2 shows (part of) the schema of the European Skills, Competences, Qualifications and Occupations (ESCO) classification, a multilingual semantic model that defines and interrelates concepts about occupations, skills, and qualifications, for the European Union labor market domain [2].
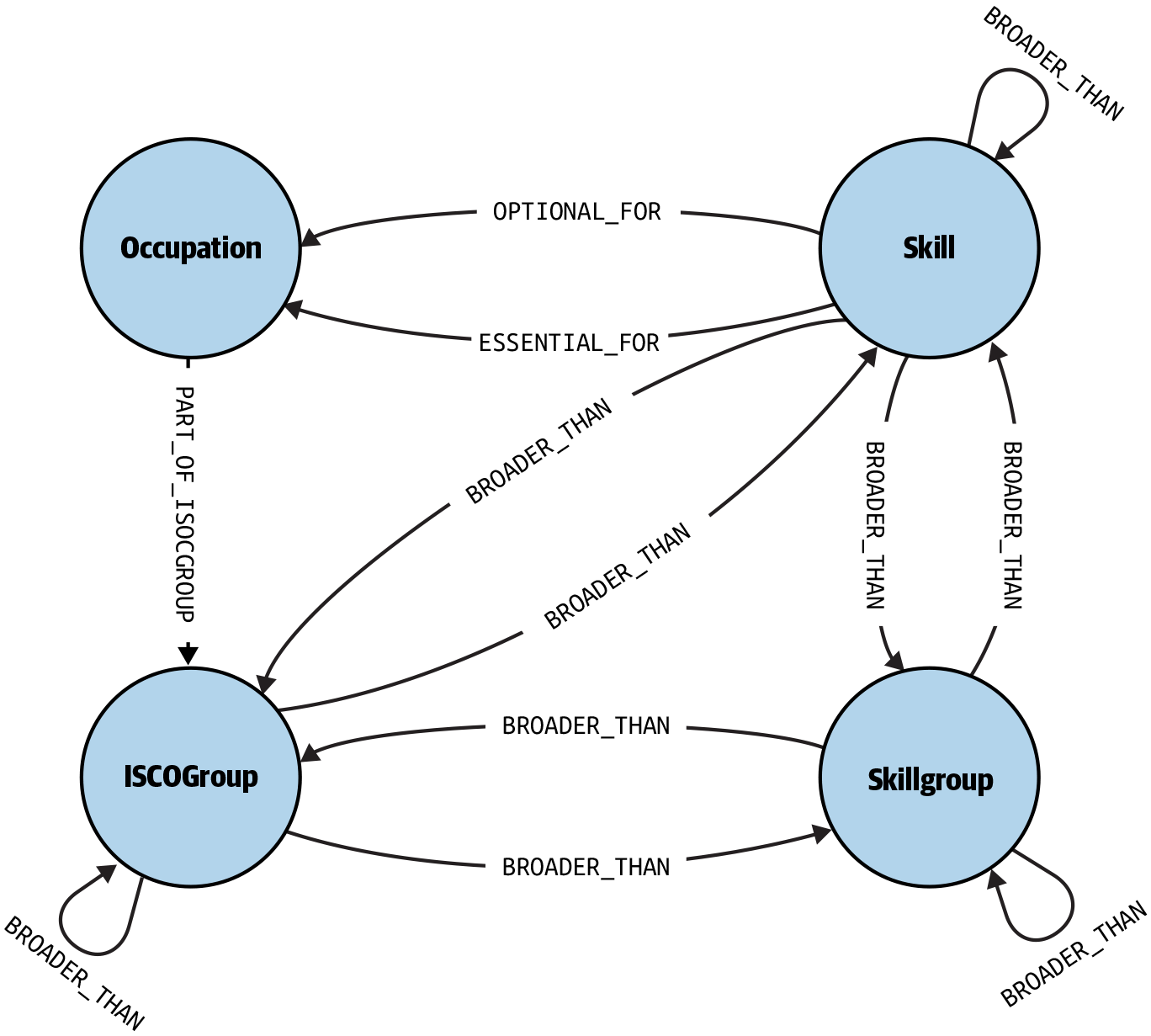
Figure 1-2. ESCO classification schema
In general, defining the necessary and sufficient criteria for a data model to be semantic in a clear way is not a straightforward task, and there are several debates within the data community about this [3] [4]. It can be similarly difficult and controversial to clearly define the exact nature and defining characteristics of particular types of semantic data models (e.g., what exactly is a knowledge graph, what is an ontology, and what are their differences) [5] [6].
In this book I am not going to engage in such debates. Instead, I will use the term semantic model to refer to any representation of data whose goal is to make the meaning of data explicit and commonly understood among humans and machines, and focus on the challenge of achieving this goal.
What I won’t consider as semantic models, at least for the purposes of this book, are machine learning models, and the reason is that their goal is not the explicitness of meaning. Semantic models consist of symbolic representations of knowledge and reasoning behavior, while machine learning models consist of latent representations at the subsymbolic level that do not have any obvious human interpretation. The latter excel at capturing knowledge that is not crisp (e.g., statistical regularities and similarities) while the former capture discrete facts and record precise identities. For example, a machine learning model might learn the typical features that can separate a cat from a dog, but would not be able to keep track of the fact that Leika was a Soviet dog that went into space.
This does not mean that semantic modeling is an inherently better or worse approach to working with data than machine learning; it merely means that the two approaches are different. And it’s exactly because of these differences that they should be seen as complementary approaches for AI and data science rather than competing ones.
Machine learning can help automate the development of semantic models, and semantic modeling can help accelerate and enhance the development of machine learning models. And while this book is primarily about semantic modeling, it explores and supports this synergy by showing semantic modelers how to make good use of machine learning methods and tools, and machine learning practitioners how to make good use of semantic models.
Why Develop and Use a Semantic Data Model?
Ontologies, knowledge graphs, and other types of semantic models have been around for several decades; their popularity, however, has particularly increased in the last few years, with Google announcing in 2012 that “their knowledge graph allowed searching for things, not strings” [7] and Gartner including knowledge graphs in its 2018 hype cycle for emerging technologies [8]. Currently, apart from Google, many prominent organizations like Amazon [9], LinkedIn [10], Thomson Reuters [11], BBC, and IBM [12] are developing and using semantic data models within their products and services.
One reason why an organization would want to invest in a semantic data model is to enhance the functionality of its AI and data science applications and services. Even though such applications nowadays are (rightly) based on machine learning and statistical techniques, there are several tasks for which having access to explicit symbolic knowledge can be necessary and beneficial.
As an example, consider Watson, IBM’s famous question-answering system that competed in the popular quiz show Jeopardy! in 2011 against human champions, and managed to win the first-place prize of $1 million [13]. As Watson’s creators report, even though the majority of evidence analysis the system performed to find the answer to questions relied on unstructured information, several of its components used knowledge bases and ontologies to tackle specific knowledge and reasoning challenges [14].
One of these challenges was that, because many questions expressed temporal or geospatial relations, Watson needed to determine whether candidate answers for a given question were temporally compatible with it, or contained the same geospatial relation as the one expressed in the question. Also, in order to rule out candidate answers whose types were incompatible with what the question asked (e.g., ruling out persons when the question asked for countries), the system required to know which types were mutually exclusive (e.g., that a person cannot also be a country). This kind of knowledge was provided to Watson via semantic data models.
Another important reason organizations would want a semantic model is to standardize and align the meaning of typically heterogeneous and managed-in-silos data, provide it with context, and make it more discoverable, interoperable, and usable for analytics and other purposes [15].
For example, Thomson Reuters, a news and information services company, launched a knowledge graph in 2017 that integrated data about organizations, people, financial instruments, quotes, deals, and other entities, coming from more than 20,000 different sources (content analysts, content partners, and news sources) [16]. The graph’s purpose was to enable data discovery and analytics services that could help the company’s clients assemble the data and information they needed faster and more reliably.
In all cases, if you are building a semantic data model for a given application scenario, it’s very important that the model effectively conveys to its users those aspects of the data’s meaning that are important for its effective interpretation and usage within that scenario. If that’s not the case, there is a substantial risk that your model will not be used or, even worse, be used in wrong ways and with undesired consequences. Conversely, if for a given application scenario you are using a semantic model that you haven’t yourself developed, it’s very important to ensure that the semantics of its data are the ones your scenario actually needs. If that doesn’t happen, you might also have undesired consequences. Let’s see why.
Bad Semantic Modeling
To see how a semantic model can be problematic, let’s take a closer look at the ESCO classification in Figure 1-2. This model was released in 2017 by the European Commission, after six years of development, with the ambition to provide standardized conceptual knowledge about occupations, skills, and qualifications, that could be used by data scientists and software developers for the following purposes:
-
Semantically analyze labor market data (CVs, job vacancies, educational programs, etc.) in a consistent, standardized, and commonly understood way, across languages.
-
Develop intelligent software that could automatically match job seekers to job providers.
-
Derive labor market analytics that could provide actionable insights to job seekers, employers, governments, and policy makers (e.g., a country predicting future skill needs in a particular industry and adapting its educational policy accordingly).
Now, ESCO provides several semantic “goodies” to achieve this ambition. For example, it identifies and groups together all terms that may refer to the same occupation, skill, or qualification concept. This is a very useful piece of knowledge because it can be used to identify job vacancies for the same occupation, even if the latter may be expressed in many different ways. Equally useful is the knowledge the model provides about the skills that are most relevant to a given occupation (see essential_for and optional_for relations in Figure 1-2). Such knowledge can be used, for example, by education providers to identify gaps in the demand and supply of particular skills in the market, and update their curricula accordingly. Table 1-1 shows some examples of essential skills for three occupations.
| Occupation | Essential skills |
|---|---|
Data scientist |
Data mining, data models, information categorization, information extraction, online analytical processing, query languages, resource description framework query language, statistics, visual presentation techniques |
Knowledge engineer |
Business intelligence, business process modeling, database development tools, information extraction, natural language processing, principles of artificial intelligence, resource description framework query language, systems development life cycle, systems theory, task algorithmization, web programming |
Data entry supervisor |
LDAP, LINQ, MDX, N1QL, SPARQL, XQuery, company policies, database, documentation types, information confidentiality, query languages, resource description framework query language |
Now, the modelers of this latter piece of knowledge in ESCO have fallen into one of the many semantic modeling pitfalls I describe in this book, namely presenting subjective knowledge as objective, and not adequately informing the model’s users about vagueness.
Here is the problem: If you ask one hundred different professionals which skills are most important for their profession, you will most likely get one hundred different answers. If, even worse, you attempt to distinguish between essential and optional skills, as ESCO does, then you should prepare for a lot of debate and disagreement. Just take a look at Table 1-1 and see how many essential skills you agree with.
The issue is that the notion of essentiality of a skill for a profession is (in the majority of the cases) vague; i.e., it lacks crisp applicability criteria that clearly separate the essential from the nonessential skills. And without such criteria, it’s wrong (and potentially harmful) to present the essential_for relation as objective and valid in all contexts.
Imagine, for example, that you are building some career advice software that takes as input someone’s desired profession (e.g., data scientist) and tells them what skills they need to obtain and/or enhance in order to find a job in that profession. For that purpose, you could directly use ESCO’s data and tell your users, for instance, that in order to become knowledge engineers they must learn web programming. This might indeed be the case in some contexts, but do you think presenting it as an indisputable fact applicable in all contexts is a sound practice?
To be fair to ESCO, similar problems appear in many semantic data models. And to be fair to data modelers, semantic modeling is hard, because human language and perception is full of ambiguity, vagueness, imprecision, and other phenomena, that make the formal and universally accepted representation of data semantics quite a difficult task.
In practice, the key challenge in building a good semantic model is to find the right level of semantic expressiveness and clarity that will be beneficial to its users and applications, without excessive development and maintenance costs. From my experience, software developers and data engineers tend to under-specify meaning when building data models, while ontologists, linguists, and domain experts tend to over-specify it and debate about semantic distinctions for which the model’s users may not care at all. The job of a semantic modeler is to strike the right balance of meaning explicitness and shareability that their data, domains, applications, and users need. This job is threatened by pitfalls and dilemmas.
Avoiding Pitfalls
A pitfall in semantic modeling is a situation in which the model’s creators take a decision or action that is clearly wrong with respect to the data’s semantics, the model’s requirements, or other aspects of the model’s development process, and leads to undesired consequences when the model is put to use. A pitfall can also be the omission of an action that is necessary to avoid such consequences. The latter’s probability or severity may vary, but that doesn’t mean that a pitfall is not a mistake that we should strive to avoid when possible. ESCO’s nontreatment of vagueness that I described earlier may not seem like a big problem at first, but it’s undeniably a risk whose consequences remain to be seen.
Falling into a pitfall is not always a result of the modeler’s incompetence or inexperience. More often than we would like to admit, the academic and industry communities that develop semantic modeling languages, methodologies, and tools, contribute to the problem in at least three ways:
-
We use contradictory or even completely wrong terminology when describing and teaching semantic modeling
-
We ignore or dismiss some of the pitfalls as nonexistent or unimportant
-
We fall into these pitfalls ourselves and produce technology, literature, and actual models that contain them
To see how this actually happens, consider the following two excerpts from two different semantic modeling resources:
“…OWL classes are interpreted as sets that contain individuals… The word concept is sometimes used in place of class. Classes are a concrete representation of concepts…”
“A [SKOS] concept can be viewed as an idea or notion; a unit of thought…the concepts of a thesaurus or classification scheme are modeled as individuals in the SKOS data model…”
The first excerpt is found in a popular tutorial about Protégé [17], a tool that enables you to build semantic models according to the Ontology Web Language (OWL) [18]. The second one is derived from the specification of the Simple Knowledge Organization System (SKOS) [19], a World Wide Web Consortium (W3C) recommendation designed for representation of thesauri, classification schemes, taxonomies, and other types of structured controlled vocabularies.
Based on these definitions, what do you understand to be a concept in a semantic model? Is it a set of things as the Protégé tutorial suggests, or some unit of thought as SKOS claims? And what should you do if you need to model a concept in OWL that is not really a set of things? Should you still have to make it a class? The answer, as we will see in the rest of the book, is that the SKOS definition is more accurate and useful, and that the “concept = class” claim of the OWL tutorial is at best misleading, causing several semantic modeling errors that we will see later in the book.
In any case, my goal in this book is not to assign blame to people and communities for bad semantic modeling advice, but to help you navigate this not-so-smooth landscape and show you how to recognize and avoid pitfalls, both as a model creator and user.
Breaking Dilemmas
Contrary to a pitfall, a semantic modeling dilemma is a situation in which the model’s creators have to choose between different courses of action, each of which comes with its own pros and cons, and for which there’s no clear decision process and criteria to be applied.
As an example, consider the options that the developers of ESCO have to treat the vague essential_for relation between occupations and skills. One option is to flag the relation as “vague” so that the users know what to expect, but that won’t reduce the potential disagreements that may occur. Another option is to try to create different versions of the relation that are applicable to different contexts (e.g., different countries, industries, user groups, etc.) so that the level of potential disagreement is lower. Doing this, however, is costlier and more difficult. So, what would you advise ESCO to do?
In this book, I will describe several dilemmas related to a semantic model’s development and usage, but I won’t give you a definite and “expert” solution for them simply because there’s no such thing. To tackle a semantic modeling dilemma you need to treat it as a decision-making problem; i.e., you need to formulate the alternative options and find a way to evaluate them from a feasibility, cost-benefit, strategic, or other perspective that makes sense for your goals and context. For that, I will show you how to frame each dilemma as a decision-making problem, and show you what information you should look for in order to reach a decision.
Get Semantic Modeling for Data now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

