Chapter 4. Building and Delivering

We delight in the beauty of the butterfly, but rarely admit the changes it has gone through to achieve that beauty.
Maya Angelou
Building and delivering software systems is complicated and expensive—writing code, compiling it, testing it, deploying it to a repository or staging environment, then delivering it to production for end users to consume. Won’t promoting resilience during those activities just increase that complexity and expense? In a word, no. Building and delivering systems that are resilient to attack does not require special security expertise, and most of what makes for “secure” software overlaps with what makes for “high-quality” software too.
As we’ll discover in this chapter, if we can move quickly, replace easily, and support repeatability, then we can go a long way to match attackers’ nimbleness and reduce the impact of stressors and surprises—whether spawned by attackers or other conspiring influences—in our systems. While this chapter can serve as a guide for security teams to modernize their strategy at this phase, our goal in this chapter is for software or platform engineering teams to understand how they can promote resilience by their own efforts. We need consistency and repeatability. We need to avoid cutting corners while still maintaining speed. We need to follow through on innovation to create more slack in the system. We need to change to stay the same.
We will cover a lot of ground in this chapter—it is packed full of practical wisdom! After we’ve discussed mental models and ownership concerns, we’ll inspect the magical contents of our resilience potion to inform how we can build and deliver resilient software systems. We’ll consider what practices help us crystallize the critical functions of the system and invest in their resilience to attack. We’ll explore how we can stay within the boundaries of safe operation and expand those thresholds for more leeway. We’ll talk about tactics for observing system interactions across space-time—and for making them more linear. We’ll discuss development practices that nurture feedback loops and a learning culture so our mental models don’t calcify. Then, to close, we’ll discover practices and patterns to keep us flexible—willing and able to change to support organizational success as the world evolves.
Mental Models When Developing Software
We talked about good design and architecture from a resilience perspective in the last chapter. There are many ways to accidentally subvert resilient design and architecture once we begin building and delivering those designs. This is the stage where design intentions are first reified because programmers must make choices in how they reify the design, and these choices also influence the degree of coupling and interactive complexity in the system. In fact, practitioners at all phases influence this, but we’ll cover each in turn in subsequent chapters. This chapter will explore the numerous trade-offs and opportunities we face as we build and deliver systems.
This phase—building and delivering software—is one of our primary mechanisms for adaptation. This phase is where we can adapt as our organization, business model, or market changes. It’s where we adapt as our organization scales. The way to adapt to such chronic stressors is often by building new software, so we need the ability to accurately translate the intent of our adaptation into the new system. The beauty of chaos experiments is that they expose when our mental models digress from reality. In this phase, it means we have an inaccurate idea of what the system does now, but some idea—represented by our design—of how we want it to behave in the future. We want to voyage safely from the current state to the intended future state.
In an SCE world, we must think in terms of systems. This is part of why this phase is described as “building and delivering” and not just “developing” or “coding.” Interconnections matter. The software only matters when it becomes “alive” in the production environment and broader software ecosystem. Just because it can survive on your local machine doesn’t mean it can survive in the wild. It’s when it’s delivered to users—much like how we describe a human birth as a delivery—that the software becomes useful, because now it’s part of a system. So, while we’ll cover ops in the next chapter, we will emphasize the value of this systems perspective for software engineers who typically focus more on the functionality than the environment. Whether your end users are external customers or other internal teams (who are still very much customers), building and delivering a resilient system requires you to think about its ultimate context.
Security chaos experiments help programmers understand the behavior of the systems they build at multiple layers of abstraction. For example, the kube-monkey chaos experimentation tool randomly deletes Kubernetes (“k8s”) pods in a cluster, exposing how failures can cascade between applications in a k8s-orchestrated system (where k8s serves as an abstraction layer). This is crucial because attackers think across abstraction layers and exploit how the system actually behaves rather than how it is intended or documented to behave. This is also useful for debugging and testing specific hypotheses about the system to refine your mental model of it—and therefore learn enough to build the system better with each iteration.
Who Owns Application Security (and Resilience)?
SCE endorses software engineering teams taking ownership of building and delivering software based on resilient patterns, like those described in this book. This can take a few forms in organizations. Software engineering teams can completely self-serve—a fully decentralized model—with each team coming up with guidelines based on experience and agreeing on which should become standard (a model that is likely best suited for smaller or newer organizations). An advisory model is another option: software engineering teams could leverage defenders as advisors who can help them get “unstuck” or better navigate resilience challenges. The defenders who do so may be the security team, but they could just as easily be the SRE or platform engineering team, which already conducts similar activities—just perhaps not with the attack perspective at present. Or, as we’ll discuss in great depth in Chapter 7, organizations can craft a resilience program led by a Platform Resilience Engineering team that can define guidelines and patterns as well as create tooling that makes the resilient way the expedient way for internal users.
Warning
If your organization has a typical defender model—like a separate cybersecurity team—there are important considerations to keep in mind when transitioning to an advisory model. Defenders cannot leave the rest of the organization to sink or swim, declaring security awareness training sufficient; we’ll discuss why this is anything but sufficient in Chapter 7. Defenders must determine, document, and communicate resilience and security guidelines, remaining accessible as an advisor to assist with implementation as needed. This is a departure from the traditional model of cybersecurity teams enforcing policies and procedures, requiring a mindshift from autocrat to diplomat.
The problem is that traditional security—including in its modern cosmetic makeover as “DevSecOps”—seeks to micromanage software engineering teams. In practice, cybersecurity teams often thrust themselves into software engineering processes however they can to control more of it and ensure it is done “right,” where “right” is seen exclusively through the lens of optimizing security. As we know from the world of organizational management, micromanaging is usually a sign of poor managers, unclear goals, and a culture of distrust. The end result is tighter and tighter coupling, an organization as ouroboros.
The goal of good design and platform tools is to make resilience and security background information rather than foreground. In an ideal world, security is invisible—the developer isn’t even aware of security things happening in the background. Their workflows don’t feel more cumbersome. This relates to maintainability: no matter your eagerness or noble intentions, security measures that impede work at this stage aren’t maintainable. As we described in the last chapter, our higher purpose is to resist the gravity of production pressures that suck you into the Danger Zone. Organizations will want you to build more software things cheaper and more quickly. Our job is to find a sustainable path for this. Unlike traditional infosec, SCE-based security programs seek opportunities to speed up software engineering work while sustaining resilience—because the fast way will be the way that’s used in practice, making the secure way the fast way is often the best path to a win. We will explore this thoroughly in Chapter 7.
It is impossible for all teams to maintain full context about all parts of your organization’s systems. But resilient development depends on this context, because the most optimal way to build a system to sustain resilience—remember, resilience is a verb—depends on its context. If we want resilient systems, we must nurture local ownership. Attempts at centralizing control—like traditional cybersecurity—will only make our systems brittle because they are ignorant of local context.
Determining context starts out with a lucid mission: “The system works with the availability, speed, and functionality we intend despite the presence of attackers.” That’s really open ended, as it should be. For one company, the most efficient way to realize that mission is building their app to be immutable and ephemeral. For another company, it might be writing the system in Rust1 (and avoiding using the unsafe keyword as a loophole…2). And for yet another company, the best way to realize this mission is to avoid collecting any sensitive data at all, letting third parties handle it instead—and therefore handling the security of it too.
Lessons We Can Learn from Database Administration Going DevOps
The idea that security could succeed while being “owned” by engineering teams is often perceived as anathema to infosec. But it’s happened in other tricky problem areas, like database administration (DBA).
DBA has shifted toward the “DevOps” model (and, no, it isn’t called DevDBOps). Without adopting DevOps principles, both speed and quality suffer due to:
Mismatched responsibility and authority
Overburdened database operations personnel
Broken feedback loops from production
Reduced developer productivity
Sound familiar? Like DBA, security programs traditionally sit within a specific, central team kept separate from engineering teams and are often at odds with development work. What else can we learn about applying DevOps to DBA?
Developers own database schema, workload, and performance.
Developers debug, troubleshoot, and repair their own outages.
Schema and data model as code.
A single fully automated deployment pipeline exists.
App deployment includes automated schema migrations.
Automated preproduction refreshes from production.
Automation of database operations exists.
These attributes exemplify a decentralized paradigm for database work. There is no single team “owning” database work or expertise. When things go wrong in a specific part of the system, the engineering team responsible for that part of the system is also responsible for sleuthing out what’s going wrong and fixing it. Teams leverage automation for database work, lowering the barrier to entry and lightening the cognitive load for developers—diminishing the desperate need for deep database expertise. It turns out a lot of required expertise is wrapped up in toil work; eliminate manual, tedious tasks and it gets easier on everyone.
It’s worth noting that, in this transformation, toil and complexity haven’t really disappeared (at least, mostly); they’ve just been highly automated and hidden behind abstraction barriers offered by cloud and SaaS providers. And the biggest objection to this transformation—that it would either ruin performance or hinder operations—has been proven (mostly) false. Most organizations simply never run into problems that expose the limitations of this approach.
As data and software engineer Alex Rasmussen notes, this is the same reason why SQL on top of cloud warehouses has largely replaced custom Spark jobs. Some organizations need the power and flexibility Spark grants and are willing to invest the effort in making it successful. But the vast majority of organizations just want to aggregate some structured data and perform a few joins. At this point, we’ve collectively gained sufficient understanding of this “common” mode, so our solutions that target this common mode are quite robust. There will always be outliers, but your organization probably isn’t one.
There are parallels to this dynamic in security too. How many people roll their own payment processing in a world in which payment processing platforms abound? How many people roll their own authentication when there are identity management platform providers? This also reflects the “choose boring” principle we discussed in the last chapter and will discuss later in this chapter in the context of building and delivering. We should assume our problem is boring unless proven otherwise.
If we adapt the attributes of the DBA to DevOps transformation for security, they might look something like:
Developers own security patterns, workload, and performance.
Developers debug, troubleshoot, and repair their own incidents.
Security policies and rules as code.
A single, fully automated deployment pipeline exists.
App deployment includes automated security configuration changes.
Automated preproduction refreshes from production.
Automation of security operations.
You cannot accomplish these attributes through one security team that rules them all. The only way to achieve this alignment of responsibility and accountability is by decentralizing security work. Security Champions programs represent one way to begin decentralizing security programs; organizations that experimented with this model (such as Twilio, whose case study on their program is in the earlier SCE report) are reporting successful results and a more collaborative vibe between security and software engineering. But Security Champions programs are only a bridge. We need a team dedicated to enabling decentralization, which is why we’ll dedicate all of Chapter 7 to Platform Resilience Engineering.
What practices nurture resilience when building and delivering software? We’ll now turn to which practices promote each ingredient of our resilience potion.
Decisions on Critical Functionality Before Building
How do we harvest the first ingredient of our resilience potion recipe—understanding the system’s critical functionality—when building and delivering systems? Well, we should probably start a bit earlier when we decide how to implement our designs from the prior phase. This section covers decisions you should make collectively before you build a part of the system and when you reevaluate it as context changes. When we are implementing critical functionality by developing code, our aim is simplicity and understandability of critical functions; the complexity demon spirit can lurch forth to devour us at any moment!
One facet of critical functionality during this phase is that software engineers are usually building and delivering part of the system, not the whole thing. Neville Holmes, author of the column “The Profession” in IEEE’s Computer magazine, said, “In real life, engineers should be designing and validating the system, not the software. If you forget the system you’re building, the software will often be useless.” Losing sight of critical functionality—at the component, but especially at the system level—will lead us to misallocate effort investment and spoil our portfolio.
How do we best allocate effort investments during this phase to ensure critical functionality is well-defined before it runs in production? We’ll propose a few fruitful opportunities—presented as four practices—during this section that allow us to move quickly while sowing seeds of resilience (and that support our goal of RAVE, which we discussed in Chapter 2).
Tip
If you’re on a security team or leading it, treat the opportunities throughout this chapter as practices you should evangelize in your organization and invest effort in making them easy to adopt. You’ll likely want to partner with whoever sets standards within the engineering organization to do so. And when you choose vendors to support these practices and patterns, include engineering teams in the evaluation process.
Software engineering teams can adopt these on their own. Or, if there’s a platform engineering team, they can expend effort in making these practices as seamless to adopt in engineering workflows as possible. We’ll discuss the platform engineering approach more in Chapter 7.
First, we can define system goals and guidelines using the “airlock approach.” Second, we can conduct thoughtful code reviews to define and verify the critical functions of the system through the power of competing mental models; if someone is doing something weird in their code—which should be flagged during code review one way or another—it will likely be reflected in the resilience properties of their code. Third, we can encourage the use of patterns already established in the system, choosing “boring” technology (an iteration on the theme we explored in the last chapter). And, finally, we can standardize raw materials to free up effort capital that can be invested elsewhere for resilience.
Let’s cover each of these practices in turn.
Defining System Goals and Guidelines on “What to Throw Out the Airlock”
One practice for supporting critical functionality during this phase is what we call the “airlock approach”: whenever we are building and delivering software, we need to define what we can “throw out the airlock.” What functionality and components can you neglect temporarily and still have the system perform its critical functions? What would you like to be able to neglect during an incident? Whatever your answer, make sure you build the software in a way that you can indeed neglect those things as necessary. This applies equally to security incidents and performance incidents; if one component is compromised, the airlock approach allows you to shut it off if it’s noncritical.
For example, if processing transactions is your system’s critical function and reporting is not, you should build the system so you can throw reporting “out the airlock” to preserve resources for the rest of the system. It’s possible that reporting is extremely lucrative—your most prolific money printer—and yet, because timeliness of reporting matters less, it can still be sacrificed. That is, to keep the system safe and keep reporting accurate, you sacrifice the reporting service during an adverse scenario—even as the most valuable service—because its critical functionality can still be upheld with a delay.
Another benefit of defining critical functions as fine as we can is so we can constrain batch size—an important dimension in our ability to reason about what we are building and delivering. Ensuring teams can follow the flow of data in a program under their purview helps shepherd mental models from wandering too far from reality.
This ruthless focus on critical functionality can apply to more local levels too. As we discussed in the last chapter, trending toward single-purpose components infuses more linearity in the system—and it helps us better understand the function of each component. If the critical function of our code remains elusive, then why are we writing it?
Code Reviews and Mental Models
Code reviews help us verify that the implementation of our critical functionality (and noncritical too) aligns with our mental models. Code reviews, at their best, involve one mental model providing feedback on another mental model. When we reify a design through code, we are instantiating our mental model. When we review someone else’s code, we construct a mental model of the code and compare it to our mental model of the intention, providing feedback on anything that deviates (or opportunities to refine it).
In modern software development workflows, code reviews are usually performed after a pull request (“PR”) is submitted. When a developer changes code locally and wants to merge it into the main codebase (known as the “main branch”), they open a PR that notifies another human that those changes—referred to as “commits”—are ready to be reviewed. In a continuous integration and continuous deployment/delivery (CI/CD) model, all the steps involved in pull requests, including merging the changes into the main branch, are automated—except for the code review.
Related to the iterative change model that we’ll discuss later in the chapter, we want our code reviews to be small and quick too. When code is submitted, the developer should get feedback early and quickly. To ensure the reviewer can be quick in their review, changes should be small. If a reviewer is assigned a PR including lots of changes at once, there can be an incentive to cut corners. They might just skim the code, comment “lgtm” (looks good to me), and move on to work they perceive as more valuable (like writing their own code). After all, they won’t get a bonus or get promoted due to thoughtful code reviews; they’re much more likely to receive rewards for writing code that delivers valuable changes into production.
Sometimes critical functions get overlooked during code review because our mental models, as we discussed in the last chapter, are incomplete. As one study found, “the error-handling logic is often simply wrong,” and simple testing of it would prevent many critical production failures in distributed systems.3 We need code reviews for tests too, where other people validate the tests we write.
Warning
Formal code reviews are often proposed after a notable incident in the hopes that tighter coupling will improve security (it won’t). If the code in a review is already written and is of significant volume, has many changes, or is very complex, it’s already too late. The code author and the reviewer sitting down together to discuss the changes (versus the async, informal model that is far more common) feels like it might help, but is just “review theater.” If we do have larger features, we should use the “feature branch” model or, even better, ensure we perform a design review that informs how the code will be written.
How do we incentivize thoughtful code reviews? There are a few things we can do to discourage cutting corners, starting with ensuring all the nitpicking will be handled by tools. Engineers should never have to point out issues with formatting or trailing spaces; any stylistic concerns should be checked automatically. Ensuring automated tools handle this kind of nitpicky, grunt work allows engineers to focus on higher-value activities that can foster resilience.
Warning
There are many code review antipatterns that are unfortunately common in status quo cybersecurity despite security engineering teams arguably suffering the most from it. One antipattern is a strict requirement for the security team to approve every PR to evaluate its “riskiness.” Aside from the nebulosity of the term riskiness, there is also the issue of the security team lacking relevant context for the code changes.
As any software engineer knows all too well, one engineering team can’t effectively review the PRs of another team. Maybe the storage engineer could spend a week reading the network engineering team’s design docs and then review a PR, but no one does that. A security team certainly can’t do that. The security team might not even understand the critical functions of the system and, in some cases, might not even know enough about the programming language to identify potential problems in a meaningful way.
As a result, the security team can often become a tight bottleneck that slows down the pace of code change, which, in turn, hurts resilience by hindering adaptability. This usually feels miserable for the security team too—and yet leaders often succumb to believing there’s a binary between extremes of manual reviews and “let security issues fall through the cracks.” Only a Sith deals in absolutes.
“Boring” Technology Is Resilient Technology
Another practice that can help us refine our critical functions and prioritize maintaining their resilience to attack is choosing “boring” technology. As expounded upon in engineering executive Dan McKinley’s famous post, “Choose Boring Technology”, boring is not inherently bad. In fact, boring likely indicates well-understood capabilities, which helps us wrangle complexity and reduce the preponderance of “baffling interactions” in our systems (both the system and our mental models become more linear).
In contrast, new, “sexy” technology is less understood and more likely to instigate surprises and bafflements. Bleeding edge is a fitting name given the pain it can inflict when implemented—maybe at first it seems but a flesh wound, but it can eventually drain you and your teams of cognitive energy. In effect, you are adding both tighter coupling and interactive complexity (decreasing linearity). If you recall from the last chapter, choosing “boring” gives us a more extensive understanding, requiring less specialized knowledge—a feature of linear systems—while also promoting looser coupling in a variety of ways.
Thus, when you receive a thoughtful design (such as one informed by the teachings of Chapter 3!), consider whether the coding, building, and delivering choices you make are adding additional complexity and higher potential for surprises—and if you are tightly coupling yourself or your organization to those choices. Software engineers should be making software choices—whether languages, frameworks, tooling, and so forth—that best solve specific business problems. The end user really doesn’t care that you used the latest and greatest tool hyped up on HackerNews. The end user wants to use your service whenever they want, as quickly as they want, and with the functionality they want. Sometimes solving those business problems will require a new, fancy technology if it grants you an advantage over your competitors (or otherwise fulfills your organization’s mission). Even so, be cautious about how often you pursue “nonboring” technology to differentiate, for the bleeding edge requires many blood sacrifices to maintain.
Warning
One red flag indicating your security architecture has strayed from the principle of “choose boring” is if your threat models are likely to be radically different from your competitors’. While most threat models will be different—because few systems are exactly alike—it is rare for two services performing the same function by organizations with similar goals to look like strangers. An exception might be if your competitors are stuck in the security dark ages but you are pursuing security-by-design.
During the build and deliver phase, we must be careful about how we prioritize our cognitive efforts—in addition to how we spend resources more generally. You can spend your finite resources on a super slick new tool that uses AI to write unit tests for you. Or you can spend them on building complex functionality that better solves a problem for your target end users. The former doesn’t directly serve your business or differentiate you; it adds significant cognitive overhead that doesn’t serve your collective goals for an uncertain benefit (that would only come after a painful tuning process and hair-pulling from minimal troubleshooting docs).
“OK,” you’re saying, “but what if the new, shiny thing is really really really cool?” You know who else likes really cool, new, shiny software? Attackers. They love when developers adopt new tools and technologies that aren’t yet well understood, because that creates lots of opportunities for attackers to take advantage of mistakes or even intended functionality that hasn’t been sufficiently vetted against abuse. Vulnerability researchers have resumes too, and it looks impressive when they can demonstrate exploitation against the new, shiny thing (usually referred to as “owning” the thing). Once they publish the details of how they exploited the new shiny thing, criminal attackers can figure out how to turn it into a repeatable, scalable attack (completing the Fun-to-Profit Pipeline of offensive infosec).
Security and observability tools aren’t exempt from this “choose boring” principle either. Regardless of your “official” title—and whether you’re a leader, manager, or individual contributor—you should choose and encourage simple, well-understood security and observability tools that are adopted across your systems in a consistent manner. Attackers adore finding “special” implementations of security or observability tools and take pride in defeating new, shiny mitigations that brag about defeating attackers one way or another.
Many security and observability tools require special permissions (like running as root, administrator, or domain administrator) and extensive access to other systems to perform their purported function, making them fantastic tools for attackers to gain deep, powerful access across your critical systems (because those are the ones you especially want to protect and monitor). A new, shiny security tool may say that fancy math will solve all your attack woes, but this fanciness is the opposite of boring and can beget a variety of headaches, including time required to tune on an ongoing basis, network bottlenecks due to data hoovering, kernel panics, or, of course, a vulnerability in it (or its fancy collection and AI-driven, rule-pushing channels) that may offer attackers a lovely foothold onto all the systems that matter to you.
For instance, you might be tempted to “roll your own” authentication or cross-site request forgery (XSRF) protection. Outside of edge cases where authentication or XSRF protection is part of the value your service offers to your customers, it makes far more sense to “choose boring” by implementing middleware for authentication or XSRF protection. That way, you’re leveraging the vendor’s expertise in this “exotic” area.
Warning
Don’t DIY middleware.
The point is, if you optimize for the “least-worst” tools for as many of your nondifferentiator problems as you can, then it will be easier to maintain and operate the system and therefore to keep it safe. If you optimize for the best tool for each individual problem, or Rule of Cool, then attackers will gladly exploit your resulting cognitive overload and insufficient allocation of complexity coins into things that help the system be more resilient to attack. Of course, sticking with something boring that is ineffective doesn’t make sense either and will erode resilience over time too. We want to aim for the sweet spot of boring and effective.
Standardization of Raw Materials
The final practice we’ll cover in the realm of critical functionality is standardizing the “raw materials” we use when building and delivering software—or when we recommend practices to software engineering teams. As we discussed in the last chapter, we can think of “raw materials” in software systems as languages, libraries, and tooling (this applies to firmware and other raw materials that go into computer hardware, like CPUs and GPUs too). These raw materials are elements woven into the software that need to be resilient and safe for system operation.
When building software services, we must be purposeful with what languages, libraries, frameworks, services, and data sources we choose since the service will inherit some of the properties of these raw materials. Many of these materials may have hazardous properties that are unsuitable for building a system as per your requirements. Or the hazard might be expected and, since there isn’t a better alternative for your problem domain, you’ll need to learn to live with it or think of other ways to reduce hazards by design (which we’ll discuss more in Chapter 7). Generally, choosing more than one raw material in any category means you get the downsides of both.
The National Security Agency (NSA) officially recommends using memory safe languages wherever possible, like C#, Go, Java, Ruby, Rust, and Swift. The CTO of Microsoft Azure, Mark Russovovich, tweeted more forcefully: “Speaking of languages, it’s time to halt starting any new projects in C/C++ and use Rust for those scenarios where a nonGC language is required. For the sake of security and reliability, the industry should declare those languages as deprecated.” Memory safety issues damage both the user and the maker of a product or service because data that shouldn’t change can magically become a different value. As Matt Miller, partner security software engineer at Microsoft, presented in 2019, ~70% of fixed vulnerabilities with a CVE assigned are memory safety vulnerabilities due to software engineers mistakenly introducing memory safety bugs in their C and C++ code.
When building or refactoring software, you should pick one of dozens of popular languages that are memory safe by default. Memory unsafety is mighty unpopular in language design, which is great for us since we have a cornucopia of memory safe options from which to pluck. We can even think of C code like lead; it was quite convenient for many use cases, but it’s poisoning us over time, especially as more accumulates.
Ideally, we want to adopt less hazardous raw materials as swiftly as we can, but this quest is often nontrivial (like migrating from one language to another). Full rewrites can work for smaller systems that have relatively complete integration, end-to-end (E2E), and functional tests—but those conditions won’t always be true. The strangler fig pattern, which we’ll discuss at the end of the chapter, is the most obvious approach to help us iteratively change our codebase.
Another option is to pick a language that integrates well with C and make your app a polyglot application, carefully choosing which parts to write in each language. This approach is more granular than the strangler fig pattern and is similar to the Oxidation project, Mozilla’s approach to integrating Rust code in and around Firefox (which is worth exploring for guidance on how to migrate from C to Rust, should you need it). Some systems may even stay in this state indefinitely if there are benefits to having both high- and low-level languages in the same program simultaneously. Games are a common example of this dynamic: engine code needs to be speedy to control memory layout, but gameplay code needs to be quick to iterate on and performance matters much less. But in general, polyglot services and programs are rare, which makes standardization of some materials a bit more straightforward.
Security teams wanting to drive adoption of memory safety should partner with the humans in your organization who are trying to drive engineering standards—whether practices, tools, or frameworks—and participate in that process. All things equal, maintaining consistency is significantly better for resilience. The humans you seek are within the engineering organization, making the connections, and advocating for the adoption of these standards.
On the flipside, these humans have their own goals: to productively build more software and the systems the business desires. If your asks are insensitive, they will ignore you. So, don’t ask for things like disconnecting developer laptops from the internet for security’s sake. Emphasizing the security benefits of refactoring C code into a memory safe language, however, will be more constructive, as it likely fits with their goals too—since productivity and operational hazards notoriously sneak within C. Security can have substantial common ground with that group of humans on C since they also want to get rid of it (except for the occasional human insisting we should all write in Assembly and read the Intel instruction manual).
Warning
As Mozilla stresses, “crossing the C++/Rust boundary can be difficult.” This shouldn’t be underestimated as a downside of this pattern. Because C defines the UNIX platform APIs, most languages have robust foreign function interface (FFI) support for C. C++, however, lacks such substantial support as it has way more language oddities for FFI to deal with and to potentially mess up.
Code that passes a language boundary needs extra attention at all stages of development. An emerging approach is to trap all the C code in a WebAssembly sandbox with generated FFI wrappers provided automatically. This might even be useful for applications that are entirely written in C to be able to trap the unreliable, hazardous parts in a sandbox (like format parsing).
Caches are an example of a hazardous raw material that is often considered necessary. When caching data on behalf of a service, our goal is to reduce the traffic volume to the service. It’s considered successful to have a high cache hit ratio (CHR), and it is often more cost-effective to scale caches than to scale the service behind them. Caches might be the only way to deliver on your performance and cost targets, but some of their properties jeopardize the system’s ability to sustain resilience.
There are two hazards with respect to resilience. The first is mundane: whenever data changes, caches must be invalidated or else the data will appear stale. Invalidation can result in quirky or incorrect overall system behavior—those “baffling” interactions in the Danger Zone—if the system relies on consistent data. If careful coordination isn’t correct, stale data can rot in the cache indefinitely.
The second hazard is a systemic effect where if the caches ever fail or degrade, they put pressure on the service. With high CHRs, even a partial cache failure can swamp a backend service. If the backend service is down, you can’t fill cache entries, and this leads to more traffic bombarding the backend service. Services without caches slow to a crawl, but recover gracefully as more capacity is added or traffic subsides. Services with a cache collapse as they approach capacity and recovery often requires substantial additional capacity beyond steady state.
Yet, even with these hazards, caches are nuanced from a resilience perspective. They benefit resilience because they can decouple requests from the origin (i.e., backend server); the service better weathers surprises but not necessarily sustained failures. While clients are now less tightly coupled to our origin’s behavior, they instead become tightly coupled with the cache. This tight coupling grants greater efficiency and reduced costs, which is why caching is widely practiced. But, for the resilience reasons we just mentioned, few organizations are “rolling their own caches.” For instance, they often outsource web traffic caching to a dedicated provider, such as a content delivery network (CDN).
Tip
Every choice you make either resists or capitulates to tight coupling. The tail end of loose coupling is full swapability of components and languages in your systems, but vendors much prefer lock-in (i.e., tight coupling). When you make choices on your raw materials, always consider whether it moves you closer to or away from the Danger Zone, introduced in Chapter 3.
To recap, during this phase, we can pursue four practices to support critical functionality, the first ingredient of our resilience potion: the airlock approach, thoughtful code reviews, choosing “boring” tech, and standardizing raw materials. Now, let’s proceed to the second ingredient: understanding the system’s safety boundaries (thresholds).
Developing and Delivering to Expand Safety Boundaries
The second ingredient of our resilience potion is understanding the system’s safety boundaries—the thresholds beyond which it slips into failure. But we can also help expand those boundaries during this phase, expanding our system’s figurative window of tolerance to adverse conditions. This section describes the range of behavior that should be expected of the sociotechnical system, with humans curating the system as it drifts from the designed ideal (the mental models constructed during the design and architecture phase). There are four key practices we’ll cover that support safety boundaries: anticipating scale, automating security checks, standardizing patterns and tools, and understanding dependencies (including prioritizing vulnerabilities in them).
The good news is that a lot of getting security “right” is actually just solid engineering—things you want to do for reliability and resilience to disruptions other than attacks. In the SCE world, application security is thought of as another facet of software quality: given your constraints, how can you write high-quality software that achieves your goals? The practices we’ll explore in this section beget both higher-quality and more resilient software.
We mentioned in the last chapter that what we want in our systems is sustained adaptability. We can nurture sustainability during this phase as part of stretching our boundaries of safe operation too. Sustainability and resilience are interrelated concepts across many complex domains. In environmental science, both resilience and sustainability involve preservation of societal health and well-being in the presence of environmental change.4 In software engineering, we typically refer to sustainability as “maintainability.” It’s no less true in our slice of life that both maintainability and resilience are concerned with the health and well-being of software services in the presence of destabilizing forces, like attackers. As we’ll explore throughout this section, supporting maintainable software engineering practices—including repeatable workflows—is vital for building and delivering systems that can sustain resilience against attacks.
The processes by which you build and deliver must be clear, repeatable, and maintainable—just as we described in Chapter 2 when we introduced RAVE. The goal is to standardize building and delivering as much as you can to reduce unexpected interactions. It also means rather than relying on everything being perfect ahead of deployment, you can cope well with mistakes because fixing them is a swift, straightforward, repeatable process. Weaving this sustainability into our build and delivery practices helps us expand our safety boundaries and gain more grace in the face of adverse scenarios.
Anticipating Scale and SLOs
The first practice during this phase that can help us expand our safety boundaries is, simply put, anticipating scale. When building resilient software systems, we want to consider how operating conditions might evolve and therefore where its boundaries of safe operation lie. Despite best intentions, software engineers sometimes make architecture or implementation decisions that induce either reliability or scalability bottlenecks.
Anticipating scale is another way of challenging those “this will always be true” assumptions we described in the last chapter—the ones attackers exploit in their operations. Consider an eCommerce service. We may think, “On every incoming request, we first need to correlate that request with the user’s prior shopping cart, which means making a query to this other thing.” There is a “this will always be true” assumption baked into this mental model: that the “other thing” will always be there. If we’re thoughtful, then we must challenge: “What if this other thing isn’t there? What happens then?” This can then refine how we build something (and we should document the why—the assumption that we’ve challenged—as we’ll discuss later in this chapter). What if the user’s cart retrieval is slow to load or unavailable?
Challenging our “this will always be true” assumptions can expose potential scalability issues at lower levels too. If we say, “we’ll always start with a control flow graph, which is the output of a previous analysis,” we can challenge it with a question like “what if that analysis is either super slow or fails?” Investing effort capital in anticipating scale can ensure we do not artificially constrict our system’s safety boundaries—and that potential thresholds are folded into our mental models of the system.
When we’re building components that will run as part of big, distributed systems, part of anticipating scale is anticipating what operators will need during incidents (i.e., what effort investments they need to make). If it takes an on-call engineer hours to discover that the reason for sudden service slowness is a SQLite database no one knew about, it will hurt your performance objectives. We also need to anticipate how the business will grow, like estimating traffic growth based on roadmaps and business plans, to prepare for it. When we estimate which parts of the system we’ll need to expand in the future and which are unlikely to need expansion, we can be thrifty with our effort investments while ensuring the business can grow unimpeded by software limitations.
We should be thoughtful about supporting the patterns we discussed in the last chapter. If we design for immutability and ephemerality, this means engineers can’t SSH into the system to debug or change something, and that the workload can be killed and restarted at will. How does this change how we build our software? Again, we should capture these why points—that we built it this way to support immutability and ephemerality—to capture knowledge (which we’ll discuss in a bit). Doing so helps us expand our window of tolerance and solidifies our understanding of the system’s thresholds beyond which failure erupts.
Automating Security Checks via CI/CD
One of the more valuable practices to support expansion of safety boundaries is automating security checks by leveraging existing technologies for resilience use cases. The practice of continuous integration and continuous delivery5 (CI/CD) accelerates the development and delivery of software features without compromising reliability or quality.6 A CI/CD pipeline consists of sets of (ideally automated) tasks that deliver a new software release. It generally involves compiling the application (known as “building”), testing the code, deploying the application to a repository or staging environment, and delivering the app to production (known as “delivery”). Using automation, CI/CD pipelines ensure these activities occur at regular intervals with minimal interference required by humans. As a result, CI/CD supports the characteristics of speed, reliability, and repeatability that we need in our systems to keep them safe and resilient.
Tip
- Continuous integration (CI)
Humans integrate and merge development work (like code) frequently (like multiple times per day). It involves automated software building and testing to achieve shorter, more frequent release cycles, enhanced software quality, and amplified developer productivity.
- Continuous delivery (CD)
Humans introduce software changes (like new features, patches, configuration edits, and more) into production or to end users. It involves automated software publishing and deploying to achieve faster, safer software updates that are more repeatable and sustainable.7
We should appreciate CI/CD not just as a mechanism to avoid the toil of manual deploys, but also as a tool to make software delivery more repeatable, predictable, and consistent. We can enforce invariants, allowing us to achieve whatever properties we want every time we build, deploy, and deliver software. Companies that can build and deliver software more quickly can also ameliorate vulnerabilities and security issues more quickly. If you can ship when you want, then you can be confident you can ship security fixes when you need to. For some companies, that may look hourly and for others daily. The point is your organization can deliver on demand and therefore respond to security events on demand.
From a resilience perspective, manual deployments (and other parts of the delivery workflow) not only consume precious time and effort better spent elsewhere, but also tightly couple the human to the process with no hope of linearity. Humans are fabulous at adaptation and responding with variety and absolutely hopeless at doing the same thing the same way over and over. The security and sysadmin status quo of “ClickOps” is, through this lens, frankly dangerous. It increases tight coupling and complexity, without the efficiency blessings we’d expect from this Faustian bargain—akin to trading our soul for a life of tedium. The alternative of automated CI/CD pipelines not only loosens coupling and introduces more linearity, but also speeds up software delivery, one of the win-win situations we described in the last chapter. The same goes for many forms of workflow automation when the result is standardized, repeatable patterns.
In an example far more troubling than manual deploys, local indigenous populations on Noepe (Martha’s Vineyard) faced the dangers of tight coupling when the single ferry service delivering food was disrupted by the COVID-19 pandemic.8 If we think of our pipeline as a food pipeline (as part of the broader food supply chain), then we perceive the poignant need for reliability and resilience. It is no different for our build pipelines (which, thankfully, do not imperil lives).
Tip
When you perform chaos experiments on your systems, having repeatable build-and-deploy workflows ensures you have a low-friction way to incorporate insights from those experiments and continuously refine your system. Having versioned and auditable build-and-deploy trails means you can more easily understand why the system is behaving differently after a change. The goal is for software engineers to receive feedback as close to immediate as possible while the context is still fresh. They want to reach the finish line of their code successfully and reliably running in production, so harness that emotional momentum and help them get there.
Faster patching and dependency updates
A subset of automating security checks to expand safety boundaries is the practice of faster patching and dependency updates. CI/CD can help us with patching and, more generally, keeping dependencies up to date—which helps avoid bumping into those safety boundaries. Patching is a problem that plagues cybersecurity. The most famous example of this is the 2017 Equifax breach in which an Apache Struts vulnerability was not patched for four months after disclosure. This violated their internal mandate of patching vulnerabilities within 48 hours, highlighting once again why strict policies are insufficient for promoting real-world systems resilience. More recently, the 2021 Log4Shell vulnerability in Log4j, which we discussed in Chapter 3, precipitated a blizzard of activity to both find vulnerable systems across the organization and patch them without breaking anything.
In theory, developers want to be on the latest version of their dependencies. The latest versions have more features, include bug fixes, and often have performance, scalability, and operability improvements.9 But when engineers are attached to an older version, there is usually a reason. In practice, there are many reasons why they might not be; some are very reasonable, some less so.
Production pressures are probably the largest reason because upgrading is a task that delivers no immediate business value. Another reason is that semantic versioning (SemVer) is an ideal to aspire to, but it’s slippery in practice. It’s unclear whether the system will behave correctly when you upgrade to a new version of the dependency unless you have amazing tests that fully cover its behaviors, which no one has.
On the less reasonable end of the spectrum is the forced refactor—like when a dependency is written or experiences substantial API changes. This is a symptom of engineers’ predilection for selecting shiny and new technologies versus stable and “boring”—that is, picking things that aren’t appropriate for real work. A final reason is abandoned dependencies. The dependency’s creator no longer maintains it and no direct replacement was made—or the direct replacement is meaningfully different.
This is precisely why automation—including CI/CD pipelines—can help, by removing human effort from keeping dependencies up to date, freeing that effort for more valuable activities, like adaptability. We don’t want to burn out their focus with tedium. Automated CI/CD pipelines mean updates and patches can be tested and pushed to production in hours (or sooner!) rather than the days, weeks, or even months that it traditionally takes. It can make update-and-patch cycles an automatic and daily affair, eliminating toil work so other priorities can receive attention.
Automated integration testing means that updates and patches will be evaluated for potential performance or correctness problems before being deployed to production, just like other code. Concerns around updates or patches disrupting production services—which can result in procrastination or protracted evaluations that take days or weeks—can be automated away, at least in part, by investing in testing. We must expend effort in writing tests we can automate, but we salvage considerable effort over time by avoiding manual testing.
Automating the release phase of software delivery also offers security benefits. Automatically packaging and deploying a software component results in faster time to delivery, accelerating patching and security changes as we mentioned. Version control is also a security boon because it expedites rollback and recovery in case something goes wrong. We’ll discuss the benefits of automated infrastructure provisioning in the next section.
Resilience benefits of continuous delivery
Continuous delivery is a practice you should only adopt after you’ve already put other practices described in this section—and even in the whole chapter—in place. If you don’t have CI and automated testing catching most of your change-induced failures, CD will be hazardous and will gnaw at your ability to maintain resilience. CD requires more rigor than CI; it feels meaningfully different. CI lets you add automation to your existing processes and achieve workflow benefits, but doesn’t really impose changes to how you deploy and operationalize software. CD, however, requires that you get your house in order. Any possible mistake that can be made by developers as part of development, after enough time, will be made by developers. (Most of the time, of course, anything that can go right will go right.) All aspects of the testing and validation of the software must be automated to catch those mistakes before they become failures, and it requires more planning around backward and forward compatibility, protocols, and data formats.
With these caveats in mind, how can CD help us uphold resilience? It is impossible to make manual deployments repeatable. It is unfair to expect a human engineer to execute manual deployments flawlessly every time—especially under ambiguous conditions. Many things can go wrong even when deployments are automated, let alone when a human performs each step. Resilience—by way of repeatability, security, and flexibility—is baked into the goal of CD: to deliver changes—whether new features, updated configurations, version upgrades, bug fixes, or experiments—to end users with sustained speed and security.10
Releasing more frequently actually enhances stability and reliability. Common objections to CD include the idea that CD doesn’t work in highly regulated environments, that it can’t be applied to legacy systems, and that it involves enormous feats of engineering to achieve. A lot of this is based on the now thoroughly disproven myth that moving quickly inherently increases “risk” (where “risk” remains a murky concept).11
While we are loathe to suggest hyperscale companies should be used as exemplars, it is worth considering Amazon as a case study for CD working in regulated environments. Amazon handles thousands of transactions per minute (up to hundreds of thousands during Prime Day), making it subject to PCI DSS (a compliance standard covering credit card data). And, being a publicly traded company, the Sarbanes-Oxley Act regulating accounting practices applies to them too. But, even as of 2011, Amazon was releasing changes to production on average every 11.6 seconds, adding up to 1,079 deployments an hour at peak.12 SRE and author Jez Humble writes, “This is possible because the practices at the heart of continuous delivery—comprehensive configuration management, continuous testing, and continuous integration—allow the rapid discovery of defects in code, configuration problems in the environment, and issues with the deployment process.”13 When you combine continuous delivery with chaos experimentation, you get rapid feedback cycles that are actionable.
This may sound daunting. Your security culture maybe feels Shakespearean levels of theatrical. Your tech stack feels more like a pile of LEGOs you painfully step on. But, you can start small. The perfect first step to work toward CD is “PasteOps.” Document the manual work involved when deploying security changes or performing security-related tasks as part of building, testing, and deploying. A bulleted list in a shared resource can suffice as an MVP for automation, allowing iterative improvement that can eventually turn into real scripts or tools. SCE is all about iterative improvement like this. Think of evolution in natural systems; fish didn’t suddenly evolve legs and opposable thumbs and hair all at once to become humans. Each generation offers better adaptations for the environment, just as each iteration of a process is an opportunity for refinement. Resist the temptation to perform a grand, sweeping change or reorg or migration. All you need is just enough to get the flywheel going.
Standardization of Patterns and Tools
Similar to the practice of standardizing raw materials to support critical functionality, standardizing tools and patterns is a practice that supports expanding safety boundaries and keeping operating conditions within those boundaries. Standardization can be summarized as ensuring work produced is consistent with preset guidelines. Standardization helps reduce the opportunity for humans to make mistakes by ensuring a task is performed the same way each time (which humans aren’t designed to do). In the context of standardized patterns and tools, we mean consistency in what developers use for effective interaction with the ongoing development of the software.
This is an area where security teams and platform engineering teams can collaborate to achieve the shared goal of standardization. In fact, platform engineering teams could even perform this work on their own if that befits their organizational context. As we keep saying, the mantle of “defender” suits anyone regardless of their usual title if they’re supporting systems resilience (we’ll discuss this in far more depth in Chapter 7).
If you don’t have a platform engineering team and all you have are a few eager defenders and a slim budget, you can still help standardize patterns for teams and reduce the temptation of rolling-their-own-thing in a way that stymies security. The simplest tactic is to prioritize patterns for parts of the system with the biggest security implications, like authentication or encryption. If it’d be difficult for your team to build standardized patterns, tools, or frameworks, you can also scout standard libraries to recommend and ensure that list is available as accessible documentation. That way, teams know there’s a list of well-vetted libraries they should consult and choose from when needing to implement specific functionality. Anything else they might want to use outside of those libraries may merit a discussion, but otherwise they can progress in their work without disrupting the security or platform engineering team’s work.
However you achieve it, constructing a “Paved Road” for other teams is one of the most valuable activities in a security program. Paved roads are well-integrated, supported solutions to common problems that allow humans to focus on their unique value creation (like creating differentiated business logic for an application).14 While we mostly think about paved roads in the context of product engineering activities, paved roads absolutely apply elsewhere in the organization, like security. Imagine a security program that finds ways to accelerate work! Making it easy for a salesperson to adopt a new SaaS app that helps them close more deals is a paved road. Making it easy for users to audit their account security rather than burying it in nested menus is a paved road too. We’ll talk more about enabling paved roads as part of a resilience program in Chapter 7.
Paved roads in action: Examples from the wild
One powerful example of a paved road—standardizing a few patterns for teams in one invaluable framework—comes from Netflix’s Wall-E framework. As anyone who’s had to juggle deciding on authentication, logging, observability, and other patterns while trying to build an app on a shoestring budget will recognize, being bequeathed this kind of framework sounds like heaven. Taking a step back, it’s a perfect example of how we can pioneer ways for resilience (and security) solutions to fulfill production pressures—the “holy grail” in SCE. Like many working in technology, we cringe at the word synergies, but they are real in this case—as with many paved roads—and it may ingratiate you with your CFO to gain buy-in for the SCE transformation.
From the foundation of a curious security program, Netflix started with the observation that software engineering teams had to consider too many security things when building and delivering software: authentication, logging, TLS certificates, and more. They had extensive security checklists for developers that created manual effort and were confusing to perform (as Netflix stated, “There were flowcharts inside checklists. Ouch.”). The status quo also created more work for their security engineering team, which had to shepherd developers through the checklist and validate their choices manually anyway.
Thus, Netflix’s application security (appsec) team asked themselves how to build a paved road for the process by productizing it. Their team thinks of the paved road as a way to sculpt questions into Boolean propositions. In their example, instead of saying, “Tell me how your app does this important security thing,” they verify that the team is using the relevant paved road to handle the security thing.
The paved road Netflix built, called Wall-E, established a pattern of adding security requirements as filters that replaced existing checklists that required web application firewalls (WAFs), DDoS prevention, security header validation, and durable logging. In their own words, “We eventually were able to add so much security leverage into Wall-E that the bulk of the ‘going internet-facing’ checklist for Studio applications boiled down to one item: Will you use Wall-E?”
They also thought hard about reducing adoption friction (in large part because adoption was a key success metric for them—other security teams, take note). By understanding existing workflow patterns, they asked product engineering teams to integrate with Wall-E by creating a version-controlled YAML file—which, aside from making it easier to package configuration data, also “harvested developer intent.” Since they had a “concise, standardized definition of the app they intended to expose,” Wall-E could proactively automate much of the toil work developers didn’t want to do after only a few minutes of setup. The results benefit both efficiency and resilience—exactly what we seek to satisfy our organizations’ thirst for more quickly doing more, and our quest for resilience: “For a typical paved road application with no unusual security complications, a team could go from git init to a production-ready, fully authenticated, internet-accessible application in a little less than 10 minutes.” The product developers didn’t necessarily care about security, but they eagerly adopted it when they realized this standardized patterned helped them ship code to users more quickly and iterate more quickly—and iteration is a key way we can foster flexibility during build and delivery, as we’ll discuss toward the end of the chapter.
Dependency Analysis and Prioritizing Vulnerabilities
The final practice we can adopt to expand and preserve our safety boundaries is dependency analysis—and, in particular, prudent prioritization of vulnerabilities. Dependency analysis, especially in the context of unearthing bugs (including security vulnerabilities), helps us understand faults in our tools so we can fix or mitigate them—or even consider better tools. We can treat this practice as a hedge against potential stressors and surprises, allowing us to invest our effort capital elsewhere. The security industry hasn’t made it easy to understand when a vulnerability is important, however, so we’ll start by revealing heuristics for knowing when we should invest effort into fixing them.
Prioritizing vulnerabilities
When should you care about a vulnerability? Let’s say a new vulnerability is being hyped on social media. Does it mean you should stop everything to deploy a fix or patch for it? Or will alarm fatigue enervate your motivation? Whether you should care about a vulnerability depends on two primary factors:
How easy is the attack to automate and scale?
How many steps away is the attack from the attacker’s goal outcome?
The first factor—the ease of automating and scaling the attack (i.e., vulnerability exploit)—is historically described by the term wormable.15 Can an attacker leverage this vulnerability at scale? An attack that requires zero attacker interaction would be easy to automate and scale. Crypto mining is often in this category. The attacker can create an automated service that scans a tool like Shodan for vulnerable instances of applications requiring ample compute, like Kibana or a CI tool. The attacker then runs an automated attack script against the instance, then automatically downloads and executes the crypto mining payload, if successful. The attacker may be notified if something is going wrong (just like your typical Ops team), but can often let this kind of tool run completely on its own while they focus on other criminal activity. Their strategy is to get as many leads as they can to maximize the potential coins mined during any given period of time.
The second factor is, in essence, related to the vulnerability’s ease of use for attackers. It is arguably an element of whether the attack is automatable and scalable, but is worth mentioning on its own given this is where vulnerabilities described as “devastating” often obviously fall short of such claims. When attackers exploit a vulnerability, it gives them access to something. The question is how close that something is to their goals. Sometimes vulnerability researchers—including bug bounty hunters—will insist that a bug is “trivial” to exploit, despite it requiring a user to perform numerous steps. As one anonymous attacker-type quipped, “I’ve had operations almost fail because a volunteer victim couldn’t manage to follow instructions for how to compromise themselves.”
Let’s elucidate this factor by way of example. In 2021, a proof of concept was released for Log4Shell, a vulnerability in the Apache Log4j library—we’ve discussed this in prior chapters. The vulnerability offered fantastic ease of use for attackers, allowing them to gain code execution on a vulnerable host by passing special “jni:”—referring to the Java Naming and Directory Interface (JNDI)—text into a field logged by the application. If that sounds relatively trivial, it is. There is arguably only one real step in the attack: attackers provide the string (a jndi: insertion in a loggable HTTP header containing a malicious URI), which forces the Log4j instance to make an LDAP query to the attacker-controlled URI, which then leads to a chain of automated events that result in an attacker-provided Java class being loaded into memory and executed by the vulnerable Log4j instance. Only one step (plus some prep work) required for remote code execution? What a value prop! This is precisely why Log4j was so automatable and scalable for attackers, which they did within 24 hours of the proof of concept being released.
As another example, Heartbleed is on the borderline of acceptable ease of use for attackers. Heartbleed enables attackers to get arbitrary memory, which might include secrets, which attackers could maybe use to do something else and then…you can see that the ease of use is quite conditional. This is where the footprint factor comes into play; if few publicly accessible systems used OpenSSL, then performing those steps might not be worth it to attackers. But because the library is popular, some attackers might put in the effort to craft an attack that scales. We say “some,” because in the case of Heartbleed, what the access to arbitrary memory gives attackers is essentially the ability to read whatever junk is in the reused OpenSSL memory, which might be encryption keys or other data that was encrypted or decrypted. And we do mean “junk.” It’s difficult and cumbersome for attackers to obtain the data they might be seeking, and even though the exact same vulnerability was everywhere and remotely accessible, it takes a lot of target-specific attention to turn it into anything useful. The only generic attack you can form with this vulnerability is to steal the private keys of vulnerable servers, and that is only useful as part of an elaborate and complicated meddler-in-the-middle attack.
At the extreme end of requiring many steps, consider a vulnerability like Rowhammer—a fault in many DRAM modules in which repeated memory row activations can launch bit flips in adjacent rows. It, in theory, has a massive attack footprint because it affects a “whole generation of machines.” In practice, there are quite a few requirements to exploit Rowhammer for privilege escalation, and that’s after the initial limitation of needing local code execution: bypassing the cache and allocating a large chunk of memory; searching for bad rows (locations that are prone to flipping bits); checking if those locations will allow for the exploit; returning that chunk of memory to the OS; forcing the OS to reuse the memory; picking two or more “row-conflict address pairs” and hammering the addresses (i.e., activating the chosen addresses) to force the bitflip, which results in read/write access to, for instance, a page table, which the attacker can abuse to then execute whatever they really want to do. And that’s before we get into the complications with causing the bits to flip. You can see why we haven’t seen this attack in the wild and why we’re unlikely to see it at scale like the exploitation of Log4Shell.
So, when you’re prioritizing whether to fix a vulnerability immediately—especially if the fix results in performance degradation or broken functionality—or wait until a more viable fix is available, you can use this heuristic: can the attack scale, and how many steps does it require the attackers to perform? As one author has quipped before, “If there is a vulnerability requiring local access, special configuration settings, and dolphins jumping through ring 0,” then it’s total hyperbole to treat the affected software as “broken.” But, if all it takes is the attacker sending a string to a vulnerable server to gain remote code execution over it, then it’s likely a matter of how quickly your organization will be affected, not if. In essence, this heuristic allows you to categorize vulnerabilities into “technical debt” versus “impending incident.” Only once you’ve eliminated all chances of incidental attacks—which is the majority of them—should you worry about super slick targeted attacks that require attackers to engage in spy movie–level tactics to succeed.
Tip
This is another case where isolation can help us support resilience. If the vulnerable component is in a sandbox, the attacker must surmount another challenge before they can reach their goal.
Remember, vulnerability researchers are not attackers. Just because they are hyping their research doesn’t mean the attack can scale or present sufficient efficiency for attackers. Your local sysadmin or SRE is closer to the typical attacker than a vulnerability researcher.
Configuration bugs and error messages
We must also consider configuration bugs and error messages as part of fostering thoughtful dependency analysis. Configuration bugs—often referred to as “misconfigurations”—arise because the people who designed and built the system have different mental models than the people who use the system. When we build systems, we need to be open to feedback from users; the user’s mental model matters more than our own, since they will feel the impact of any misconfigurations. As we’ll discuss more in Chapter 6, we shouldn’t rely on “user error” or “human error” as a shallow explanation. When we build something, we need to build it based on realistic use, not the Platonic ideal of a user.
We must track configuration errors and mistakes and treat them just like other bugs.17 We shouldn’t assume users or operators read docs or manuals enough to fully absorb them, nor should we rely on users or operators perusing the source code. We certainly shouldn’t assume that the humans configuring the software are infallible or will possess the same rich context we have as builders. What feels basic to us may feel esoteric to users. An iconic reply to exemplify this principle is from 2004, when a user sent an email to the OpenLDAP mailing list in response to the developer’s comment that “the reference manual already states, near the top….” The response read: “You are assuming that those who read that, understood what the context of ‘user’ was. I most assuredly did not until now. Unfortunately, many of us don’t come from UNIX backgrounds and though pick up on many things, some things which seem basic to you guys elude us for some time.”
As we’ll discuss more in Chapter 6, we shouldn’t blame human behavior when things go wrong, but instead strive to help the human succeed even as things go wrong. We want our software to facilitate graceful adaptation to users’ configuration errors. As one study advises: “If a user’s misconfiguration causes the system to crash, hang, or fail silently, the user has no choice but [to] report [it] to technical support. Not only do the users suffer from system downtime, but also the developers, who have to spend time and effort troubleshooting the errors and perhaps compensating the users’ losses.”18
How do we help the sociotechnical system adapt in the face of configuration errors? We can encourage explicit error messages that generate a feedback loop (we’ll talk more about feedback loops later in this chapter). As Yin et al. found in an empirical study on configuration errors in commercial and open source systems, only 7.2% to 15.5% of misconfiguration errors provided explicit messages to help users pinpoint the error.19 When there are explicit error messages, diagnosis time is shortened by 3 to 13 times relative to ambiguous messages and 1.2 to 14.5 times with no messages at all.
Despite this empirical evidence, infosec folk wisdom says that descriptive error messages are pestiferous because attackers can learn things from the message that assist their operation. Sure, and using the internet facilitates attacks—should we avoid it too? Our philosophy is that we should not punish legitimate users just because attackers can, on occasion, gain an advantage. This does not mean we provide verbose error messages in all cases. The proper amount of elaboration depends on the system or component in question and the nature of the error. If our part of the system is close to a security boundary, then we likely want to be more cautious in what we reveal. The ad absurdum of expressive error messages at a security boundary would be, for instance, a login page that returns the error: “That was a really close guess to the correct password!”
As a general heuristic, we should trend toward giving more information in error messages until shown how that information could be misused (like how disclosing that a password guess was close to the real thing could easily aid attackers). If it’s a foreseen error that the user can reasonably do something about, we should present it to them in human-readable text. The system is there so that users and the organization can achieve some goal, and descriptive error messages help users understand what they’ve done wrong and remedy it.
If the user can’t do anything about the error, even with details, then there’s no point in showing them. For that latter category of error, one pattern we can consider is returning some kind of trace identifier that a support operator can use to query the logs and see the details of the error (or even what else happened in the user’s session).20 With this pattern, if an attacker wants to glean some juicy error details from the logs, they must socially engineer the support operator (i.e., find a way to bamboozle them into revealing their credentials). If there’s no ability to talk to a support operator, there’s no point in showing the error trace ID since the user can’t do anything with it.
Tip
Never should a system dump a stack trace into a user’s face unless that user can be expected to build a new version of the software (or take some other tangible action). It’s uncivilized to do so.
To recap, during the build and delivery phase, we can pursue four practices to support safety boundaries, the second ingredient of our resilience potion: anticipating scale, automating security checks via CI/CD, standardizing patterns and tools, and performing thoughtful dependency analysis. Now let’s proceed to the third ingredient: observing system interactions across space-time.
Observe System Interactions Across Space-Time (or Make More Linear)
The third ingredient in our resilience potion is observing system interactions across space-time. When building and delivering systems, we can support this observation and form more accurate mental models as our systems’ behaviors unfold over time and across their topology (because looking at a single component at a single point in time tells us little from a resilience perspective). But we can also help make interactions more linear, augmenting our discussion on designing for linearity in the last chapter. There are practices and patterns we can adopt (or avoid) that can help us introduce more linearity as we build and deliver systems too.
In this section, we’ll explore four practices during this phase that help us either observe system interactions across space-time or nurture linearity: Configuration as Code, fault injection, thoughtful testing practices, and careful navigation of abstractions. Each practice supports our overarching goal during this phase of harnessing speed to vitalize the characteristics and behaviors we need to maintain our systems’ resilience to attack.
Configuration as Code
The first practice granting us the gift of making interactions across space-time more linear (as well as observing them) is Configuration as Code (CaC). Automating deployment activities reduces the amount of human effort required (which can be allocated elsewhere) and supports repeatable, consistent software delivery. Part of software delivery is also delivering the infrastructure underlying your applications and services. How can we ensure that infrastructure is delivered in a repeatable way too? More generally, how can we verify that our configurations align with our mental models?
The answer is through CaC practices: declaring configurations through markup rather than manual processes. While the SCE movement is aspiring toward a future in which all sorts of configurations are declarative, the practice today mostly consists of Infrastructure as Code (IaC). IaC is the ability to create and manage infrastructure via declarative specifications rather than manual configuration processes. The practice uses the same sort of process as source code, but instead of generating the same application binary each time, it generates the same environment every time. It creates more reliable and predictable services. CaC is the idea of extending this approach to all the configurations that matter, like resilience, compliance, and security. CaC resides in the squishy overlap of delivery and operations, but it should be considered part of what engineering teams deliver.
If you’re already familiar with IaC, you might be surprised it’s being touted as a security tool. Organizations are already adopting it for the audit trail it generates, which absolutely supports security by making practices more repeatable. Let’s look at some of the other benefits of IaC for security programs.
- Faster incident response
IaC supports automatic redeployment of infrastructure when incidents happen. Even better, it can automatically respond to leading indicators of incidents too, using signals like thresholding to preempt problems (we’ll discuss this more in the next chapter). With automated reprovisioning of infrastructure, we can kill and redeploy compromised workloads as soon as an attack is detected, without impacting the end user experience.
- Minimized environmental drift
Environmental drift refers to configurations or other environmental attributes “drifting” into an inconsistent state, like production being inconsistent from staging. IaC supports automatic infrastructure versioning to minimize environmental drift and makes it easier to revert deployments as needed if something goes wrong. You can deploy to fleets of machines flawlessly in ways that humans would struggle to perform without mistakes. IaC allows you to make changes nearly atomically. It encodes your deployment processes in notation that can be passed from human to human, especially as teams change membership—loosening our coupling at layer 8 (i.e., the people layer).
- Faster patching and security fixes
IaC supports faster patching and deployment of security changes. As we discussed in the section on CI/CD, the real lesson of the infamous Equifax incident is that patching processes must be usable, else procrastination will be a logical course of action. IaC reduces friction in the way of releasing patches, updates, or fixes and also decentralizes the process, promoting looser organizational coupling. As a more general point, if any organizational process is cumbersome or unusable, it will be circumvented. This is not because humans are bad, it’s the opposite; humans are pretty great at figuring out efficient ways to achieve their goals.
- Minimized misconfigurations
At the time of this writing, misconfigurations are the most common cloud security vulnerability according to the National Security Agency (NSA); they’re both easy for attackers to exploit and highly prevalent. IaC helps correct misconfigurations by users and automated systems alike. Humans and computers are both capable of making mistakes—and those mistakes are inevitable. For instance, IaC can automate the deployment of access control configurations, which are notoriously confusing and easy to mess up.
- Catching vulnerable configurations
To catch vulnerable configurations, the status quo is often authenticated scanning in production environments, which introduces new attack paths and hazards. IaC lets us excise that hazard, instead scanning the code files to find vulnerable configurations. IaC also makes it easier to write and enforce rules on a set of configuration files versus writing and enforcing rules across all your cloud service provider’s (CSP’s) APIs.
- Autonomic policy enforcement
IaC helps automate deployment and enforcement of IAM policies, like Principle of Least Privilege (PoLP). IaC patterns simplify adherence to industry standards, like compliance, with an end goal of “continuous compliance” (Figure 4-1).
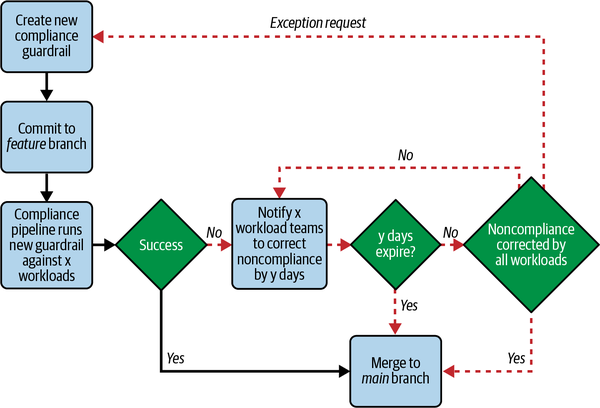
Figure 4-1. An example “continuous compliance workflow for IaC” from AWS
- Stronger change control
IaC introduces change control by way of source code management (SCM), enabling peer reviews on configurations and a strong changelog. This also imparts significant compliance benefits.
Because of all these benefits, and the fact that all engineering teams can leverage them to achieve shared goals, IaC supports a more flexible security program and frees up effort capital for other activities. The audit trail it begets and the experimentation environments it enables support curiosity too, which we want for our resilience potion. It strengthens our resilience potion by making interactions across space-time more linear, but also begets flexibility and willingness to change—like a “buy one reagent get one free deal” at the witch apothecary.
Fault Injection During Development
Another practice we can use in this phase to excavate and observe system interactions across space-time is fault injection.21 In fact, this presents two opportunities for security teams: learning about fault injection to make a case for its value to the organization (and trying to pave the road to its adoption), and collaborating with engineering teams to integrate fault injection into existing workflows. If we only test the “happy path” in our software, our mental model of the system will be a delusion and we’ll be baffled when our software gets wonky in production. To build resilient software systems, we must conceive and explore the “unhappy paths” too.
When you add a new component in the system, consider what disruption events might be possible and write tests to capture them. These tests are called fault injection tests: they stress the system by purposefully introducing a fault, like introducing a voltage spike or oversized input. Given most software systems we build look roughly like a web application connected to a database, an early fault injection test may often take the form of “disconnect and reconnect the database to make sure your database abstraction layer recovers the connection.” Unlike chaos experiments, which simulate adverse scenarios, with fault injection we are introducing a purposefully wonky input to see what happens in a particular component.
Many teams don’t prioritize fault injection (or fault tolerance) until there’s an incident or a near miss. In a reality of finite resources, it’s reasonable to wonder whether fault injection is worth it—but, that assumes you have to perform it everywhere to adopt it. Starting with fault injection for your critical functions (like those you defined in the tier 1 assessment from Chapter 2) helps you invest your effort in the places it really matters. Let’s say your company provides an auction platform for physical equipment, where serving traffic during an auction must happen continuously without downtime, but it’s OK for user analytics to be delayed. Maybe you invest more in fault injection and other testing that informs design improvements in the auction system, but rely on monitoring and observability in the rest of your systems to make recovery from faults more straightforward.
Fault injection tests should be written while the concern is salient—which is during development. Making fault injection a standard practice for critical functions will help developers better understand their dependents before delivering with them, and might discourage introducing components that make the system more difficult to operationalize. This principle holds true for most testing, in fact, which we’ll turn to next.
Integration Tests, Load Tests, and Test Theater
Now on to a vital, and controversial, practice that can support observation of system interactions across space-time: testing. As a discipline, software engineering needs to have an uncomfortable conversation around testing (to say nothing of the abysmal status quo of security testing). Are we testing for resilience or correctness over time, or just to say that we did testing? Some forms of testing can serve more as security devices when automated fully, blocking merges or deploys without need for human intervention. Or, we can write up a bunch of unit tests, use code coverage as a specious proxy for a job well done, and claim “we tested it” if something goes wrong. Alternatively, we can invest our effort capital in more constructive ways to observe the resilience properties of the system through integration and load testing—or even to pursue resilience stress testing (chaos experimentation) as part of the experimentation tier we discussed in Chapter 2.
The traditional triangular hierarchy of tests doesn’t cut it for resilience; the triangle (and its geometric brethren) look nice and feel intuitive, but they are more aesthetic than true. Different types of tests are better at addressing certain issues, and which tests you might find useful will depend on what is most relevant to your local context—your critical functions and your goals and constraints that define your operating boundaries.
We need to think about testing in terms of the Effort Investment Portfolio. The ideal mix of test types and coverage we invest in might be different by project and by part of the system. A software engineer may not care if their configuration parsing code is slow or wonky as long as the application reliably starts with the right configuration, so integration testing is sufficient. If it’s critical to validate incoming user data, however, then fuzz testing might be a candidate for those code paths.
Tests written by engineers are an artifact of their mental models at a certain point in space-time. Because reality evolves—including the systems and workloads within it—tests become outdated. The insights we learn from chaos experiments, real incidents, and even observing healthy systems must be fed back into our testing suites to ensure they are reflective of the production reality. We need to prioritize tests that help us refine our mental models and can adapt as the system context evolves. As the Google SRE handbook says: “Testing is the mechanism you use to demonstrate specific areas of equivalence when changes occur. Each test that passes both before and after a change reduces the uncertainty for which the analysis needs to allow. Thorough testing helps us predict the future reliability of a given site with enough detail to be practically useful.”
History has worked against strong testing in software engineering; organizations used to maintain dedicated testing teams, but they are rare to see today. Culturally, there is often the sense among software engineers that tests are “someone else’s problem.” The issue underlying the excuse is that tests are perceived as too complicated, especially integration tests. This is why paved roads for testing of all kinds, not just security, are one of the most valuable solutions security and platform engineering teams can build. To counter performance objections, we could even allow developers to specify the level of overhead with which they’re comfortable.22
In this section, we’ll explore why, contrary to folk wisdom, the most important test category is arguably the integration test (or “broad integration test”). It checks if the system actually does what it’s supposed to do in the most basic sense. We’ll talk about load tests and how we can leverage traffic replay to observe how the system behaves across space-time. Despite popular folk wisdom, we’ll discuss why unit tests should not be considered the necessary foundation before an organization pursues other forms of testing. Some organizations may choose to forgo unit testing at all, for the reasons we’ll discuss in this section. We’ll close with fuzz testing, a test worth pursuing only once we have our “basics” in place.
Integration tests
Integration testing is typically considered part of “good engineering,” but its benefits for resilience are less discussed. Integration tests observe how different components in the system work together, usually with the goal of verifying that they interact as expected, making it a valuable first pass at uncovering “baffling interactions.” What we observe is the idealized system, like when we propose a new iteration of the system and test to ensure it all integrates as intended. The only changes integration tests inform are roughly, “you made a mistake and you want to prevent that mistake going live.” For more comprehensive feedback on how we can refine system design, we need chaos experiments—the resilience stress tests we covered in Chapter 2.
How does an integration test look in practice? Let’s return to our earlier example of a web application connected to a database. An integration test could and should cover that case—“disconnect and reconnect the database to make sure your database abstraction layer recovers the connection”—in most database client libraries.
The AttachMe vulnerability—a cloud isolation vulnerability in Oracle Cloud Infrastructure (OCI)—is an example of what we hope to uncover with an integration test, and another example of how hazardous it is to focus only on “happy paths” when testing and developing in general. The bug allowed users to attach disk volumes for which they lack permissions—assuming they could name the volume by volume ID—onto virtual machines they control to access another tenant’s data. If an attacker tried this, they could initiate a compute instance, attach the target volume to the compute instance under their control, and gain read/write privileges over the volume (which could allow them to steal secrets, expand access, or potentially even gain control over the target environment). Aside from the attack scenario, however, this is the sort of interaction we don’t want in multitenant environments for reliability reasons too. We could develop multiple integration tests describing a variety of activities in a multitenant environment, whether attaching a disk to a VM in another account, multiple tenants performing the same action simultaneously to a shared database, or spikes in resource consumption in one tenant.
As a general principle, we want to conduct integration tests that allow us to observe system interactions across space-time. This is far more useful to foster resilience than testing individual properties of individual components (like unit tests). One input in one component is insufficient for reproducing catastrophic failures in tests. Multiple inputs are needed, but this need not discombobulate us. A 2014 study found that three or fewer nodes are sufficient to reproduce most failures—but multiple inputs are required and failures only occur on long-running systems, corroborating both the deficiency of unit testing and the necessity of chaos experimentation.25
The study also showed that error-handling code is a highly influential factor in the majority of catastrophic failures, with “almost all” (92%) of catastrophic system failures resulting from “incorrect handling of nonfatal errors explicitly signaled in software.” Needless to say, as part of our allocation of effort investments, we should prioritize testing error-handling code. The authors of the 2014 study wrote, “In another 23% of the catastrophic failures, the error-handling logic of a nonfatal error was so wrong that any statement coverage testing or more careful code reviews by the developers would have caught the bugs.” Caitie McCaffrey, a partner architect at Microsoft, advises when verifying distributed systems, “The bare minimum should be employing unit and integration tests that focus on error-handling, unreachable nodes, configuration changes, and cluster membership changes.” This testing doesn’t need to be costly; it presents an ample ROI for both resilience and reliability.
McCaffrey noted that integration tests are often skipped because of “the commonly held beliefs that failures are difficult to produce offline and that creating a production-like environment for testing is complicated and expensive.”26 The fabulous news is that creating a production-like environment for testing is getting easier and cheaper year after year; we’ll talk about some of the modern infrastructure innovations that enable low-cost experimentation environments—a more rigorous form of test environment, and with a larger scope—in Chapter 5. Now that compute is cheaper, traditional “pre-prod” environments where a menagerie of use cases are forced to share the same infrastructure for cost reasons should be considered an antipattern. We want to run integration (and functional) tests before release, or on every merge to the trunk branch if practicing CD. If we include deployment metadata in a declarative format when writing code, then we can more easily automate integration tests too, wherein our testing infrastructure can leverage a service dependency graph.
Tip
Common objections to integration testing include the presence of many external dependencies, the need for reproducibility, and maintainability. If you blend integration tests with chaos experiments, then there’s less pressure on the integration tests to test the full spectrum of potential interactions. You can concentrate on the select few that you assume matter most and refine that assumption with chaos experiments over time.
Reluctance to use integration tests goes even deeper, however. Integration tests proactively discern unanticipated failures, but engineers sometimes still despise them. Why? Part of it is that when integration tests fail, it’s usually quite an ordeal to figure out why and remedy the failure. A more subjective part is captured in the common engineer refrain, “My integration tests are slow and flaky.” “Flaky” (sometimes called “flappy” or “flickering”) tests are tests where you run the test one time and it succeeds, then when you run it again, it fails. If integration tests are slow and flaky, the system is slow and flaky. It may be your code or your dependencies—but, as systems thinkers, you own your dependencies.
Engineers are often reticent to update their mental model despite evidence that the implementation is unreliable, usually because their unit tests tell them the code does exactly what they want it to (we’ll discuss the downsides of unit testing shortly). If they implemented a more reliable system and wrote better integration tests, there wouldn’t be such a need to chase “flaky” integration tests. The true problem—one of software reliability—deludes engineers into thinking that integration tests are a waste of time because they are unreliable. This is an undesirable state of affairs if we want to support resilience when we build software.
Warning
The 2021 Codecov compromise, in which attackers gained unauthorized access to Codecov’s Bash Uploader script and modified it, is a good example of the “you own your dependencies” principle.
Codecov’s design did not seem to reflect a resilience approach. To use Codecov, users had to add bash <(curl -s https://codecov.io/bash) into their build pipelines (the command is now deprecated). Codecov could have designed this script to check code signatures or have a chain of trust, but they didn’t. On the server side, they could have implemented measures to limit deployments to that server/path, but they didn’t. They could have inserted alerts and logs for deployments to it, but they didn’t. There were numerous places where the design did not reflect the confidence users placed in them.
With that said, the developers writing software and implementing Codecov’s agent into it chose to use Codecov without fully vetting the design or thinking through its n-order effects. Remember, attackers will happily “vet” these designs for you and surprise you with their findings, but it’s better to adopt the “you own your dependencies” mindset and scrutinize what you insert into your systems first.
Countering these biases requires cultivation of a curious culture and a relentless emphasis on the necessity of refining mental models rather than clinging to delusory but convenient narratives. Peer review on tests, as discussed earlier in this chapter, can also help expose when an engineer takes umbrage with the integration test rather than their code.
Load testing
If we want to observe interactions across space-time as part of our resilience potion, we need to observe how the system behaves under load when testing a new version of software. Testing with toy loads is like testing a new recipe in an Easy-Bake Oven rather than a real oven. It is only when we design realistic workloads that simulate how users interact with the system that we can uncover the potential “baffling” functional and nonfunctional problems that would emerge when delivered in production. Needless to say, it isn’t ideal from a resilience perspective if we are shocked by a deadlock after the new version runs in production for a while.
An automated approach ensures software engineers aren’t forced to constantly rewrite tests, which is counter to the spirit of maintaining flexibility and willingness to change. If we can conduct load tests on demand (or daily), we can keep up as the system evolves. We also must ensure that resulting findings are actionable. When a test takes too much effort to design, run, or analyze, it will be unused. Can we highlight whether a result was part of previous test findings, reflecting a recurring problem? Can we visualize interactions to make it easier to understand what design refinements could improve resilience? We’ll discuss user experience and respecting attention more in Chapter 7.
Yet, designing realistic workloads is nontrivial. How users—whether human or machine—interact with software (the load) is constantly changing, and collecting all the data about those interactions requires significant effort.27 From a resilience perspective, we care much less about capturing aggregate behavior than capturing the variety of behavior. If we only tested with the median behavior, we would likely confirm our mental models, but not challenge them.
One tactic is to perform persona-based load testing, which models how a specific type of user interacts with the system. The researchers behind the tactic give the example of “the personas for an e-commerce system could include ‘shopaholics’ (users who make many purchases) and ‘window shoppers’ (users who view many items without making any purchases).” We could create personas for machine users (APIs) and human users too. From the perspective of refining our mental models about interactions across space-time, discovering unknown personas that influence system behavior (and resilience) is instrumental.
Warning
One hazard is writing what you believe are load tests that are actually benchmarks. The goal of a load test is to simulate realistic load that the system might encounter when running in the real world. Benchmarks generally are taken at a fixed point in time and used for all future proposed versions of the software—and those are the better benchmarks based on a real-world corpus. In practice, most of what we witness are synthetic benchmarks that measure a particular workload designed for the test.
The persona-based load-testing researchers even found that, using their approach, “load tests using workloads that were only designed to meet throughput targets are insufficient to confidently claim that the systems will perform well in production.” Microbenchmarks veer even further from the reality of the system, exercising only one small part of it to help engineers determine if some change makes that part of the system execute more quickly or more slowly.
Writing an ad hoc benchmark to inform a decision and then throwing it away can be sensible in some circumstances, but as a long-term assessment, they are abysmal. Even so, benchmarking tests are super tricky. It’s difficult to know if you’re measuring the right thing, it’s difficult to know if your test is representative, it’s difficult to interpret the results, and it’s difficult to know what to do because of the results.28 Even when the results of some change are super significant, they always need to be weighed against the diversity of factors at play. Many commercial databases prohibit publishing benchmark results for this and other reasons (known as “the DeWitt Clause”).
Traffic replay helps us gain a better sense of how the system behaves with realistic input. If we want to observe system interactions across space-time and incorporate them in our mental models, we need to simulate how our software might behave in the future once running in production. A paucity of realistic flows when testing new environments results in superfluous bafflement when we deploy and run our software in production. Writing scripted requests limits our testing to our mental models, whereas ingesting real production traffic offers healthy surprises to our mental models.
Traffic mirroring (or traffic “shadowing”) involves capturing real production traffic that we can replay to test a new version of a workload. The existing version of the service is unaffected; it keeps handling requests as usual. The only difference is traffic is copied to the new version, where we can observe how it behaves when handling realistic requests.
Using cloud infrastructure can make traffic replay—and high-fidelity testing in general—more cost-effective. We can provision a complete environment in the cloud for testing, then tear it down once we’re done (using the same processes we should have in place for disaster recovery anyway). Traffic replay also works with monolithic, legacy services. Either way, we’re getting a more empirical, panoramic view of future behavior when testing than if we attempt to define and divine realistic flows ourselves. The tools can be open source tools like GoReplay, service meshes, or native tools in cloud service providers. In fact, many incumbent security solutions—think intrusion detection systems (IDS), data loss prevention (DLP), and extended detection and response (XDR)—use traffic mirroring to analyze network traffic.
Warning
Depending on your compliance regime, replaying legitimate user traffic in a test or experimentation environment may add liability. This problem can be mitigated by anonymizing or scrambling traffic before it is replayed into the environment.
Organizations in highly regulated industries already use the approach of generating synthetic datasets—those that mimic production data but do not include any real user data—to populate preproduction, staging, and other test environments while still complying with privacy regulations (such as HIPAA). Organizations in less privacy-conscious industries may need to adopt a similar approach to avoid unwanted liability.
Unit testing and testing theater
You can think of unit tests as verifying local business logic (within a particular component) and integration tests as checking interactions between the component and a selected group of other components. The benefit of unit tests is that they are granular enough to verify precise outcomes that happen as a result of very specific scenarios. So far so good. The trouble is that they also verify how that outcome is achieved by communicating with the internal structure of a program. If someone were to ever change that internal structure, the tests wouldn’t work anymore—either by the tests failing or the tests no longer compiling or type-checking.
Unit testing is often a poor investment of our effort capital; we should likely allocate our efforts elsewhere. Some might call deployment without unit testing reckless, but it can be sensible depending on your objectives and requirements. Unit tests preserve the status quo by adding a level of friction to software development—an example of introducing tight coupling into testing. In fact, a unit test is the most tightly coupled type of test you could write and dwells in the realm of component-level thinking. We can look to a similar critique of formal methods to understand why we need a system-level rather than component-level assessment: “Formal methods can be used to verify that a single component is provably correct, but composition of correct components does not necessarily yield a correct system; additional verification is needed to prove that the composition is correct.”29
This isn’t to say unit tests are useless. There is value to adding tests when you don’t expect the state of the system to change. When you expect the implementation to be stable, it’s probably a good idea to assert what the behavior is. Asserting the intended behavior in a component can expose tight coupling for you—if changes in the rest of the system break this part of it. The unexpected, baffling interaction gets exposed in your development cycle rather than in your deployment and rollback cycle.
Some unit tests even reach into the internal structure of a module to puppeteer it—almost literal test theater. Imagine you have a multistep process that a module implements. Other modules call into it via its exposed interface, triggering each step at the appropriate time and with the appropriate data. Unit tests should be calling that exposed interface and affirming that the results are as expected. It does mean that to test any of the steps that have prerequisites, you have to run those previous steps, which can be slow and repetitive. One way around this tedium is to redesign the module in a “functional style” where each step receives its prerequisites explicitly rather than implicitly through the internal state of the module. Callers must then pass prerequisites from the output of one step to the input of subsequent steps. Tests can instead create the prerequisites explicitly with known values and can appropriately validate each step. But instead of refactoring, many engineers will try to “extract” the internal state and then “inject” it via startup code that runs as part of the setup of the test. The interface to the module doesn’t have to change, it’s only the tests that must contort—which elucidates little knowledge for us.
What happens when you want to add some new behaviors to your system? If you can add them without changing the structure of the code, your unit tests can run as is and may report unintended changes in behavior of the updated program. If you can’t add the new behaviors without changing the structure of the code, now you have to change the unit tests alongside the structure of the code. Can you trust the tests that you are changing in tandem with the code they test? Maybe, if the engineer updating them is diligent. Hopefully during code review, the reviewer will examine the test changes to make sure the new assertions match the old assertions...but ask an engineer (or yourself) when you’ve last seen someone do that. We need a test that verifies the behavior, but doesn’t depend on the structure of the code. This is why the common Test Pyramid offers aesthetic appeal more than real guidance or value.
Thus, to obtain the benefit of unit testing, you must never change the structure of your code. This stasis is anathema to resilience. Building tools to uphold the status quo and lock the system into its present-day design does not effectuate high-quality software. It takes some brave soul rewriting both the code and the tests that live alongside it in order to push the design forward. Maybe that’s perfect for systems that are in maintenance mode, where substantial changes are unlikely to be made, or for teams that experience such churn that no one understands the design of the system—rendering it impossible to redesign anyway. Those systems stifle engineers’ creativity and sense of wonder for software—aside from their desiccated brittleness—so we should avoid those anyway lest our curiosity perish.
Warning
The correlation between code coverage and finding more bugs may be weak.30 Software engineering researchers Laura Inozemtseva and Reid Holmes concluded that “coverage, while useful for identifying under-tested parts of a program, should not be used as a quality target because it is not a good indicator of test suite effectiveness.”
We should not conflate high code coverage with good testing. As these researchers advise: “Code coverage merely measures that a statement, block, or branch has been exercised. It gives no measure of whether the exercised code behaved correctly.”
Fuzz testing (fuzzing)
A fuzz tester “iteratively and randomly generates inputs with which it tests a target program,” usually looking for exceptions to program behavior (like crashes or memory leaks).31 A fuzz tester (also known as a “fuzzer”) runs on a target program, like the one we’re developing (attackers also use fuzzers to find vulnerabilities in programs that are potentially exploitable). Every time we run the fuzz tester—a “fuzzing run”—it may “produce different results than the last due to the use of randomness.”32 The same goes for chaos experiments (which we’ll explore more in Chapter 8), which are subject to the vagaries of reality.
To set expectations, fuzzers can involve substantial effort to write and integrate with every part of the system that might accept data (and what parts of the system don’t accept data?). You really want to ensure your other tests are reliable before you attempt it. If engineers are still bypassing integration tests, figure out why and refine the process before you try something fancier, like fuzzing. Once those “basics” are in place, however, fuzz testing can be a very useful category of test for resilience.
Beware Premature and Improper Abstractions
The final practice we can consider in the context of system interactions across space-time is the art of abstractions. Abstractions are a ferocious example of the Effort Investment Portfolio because abstractions are only convenient when you don’t have to maintain them. Consider a noncomputer abstraction: the grocery store. The grocery store ensures plantains are available all year round, despite fluctuations in supply based on seasonality, rain levels, and so forth. The complex interactions between the store and suppliers, between suppliers and farmers, between farmers and the plantain tree, between the plantain tree and its environment—all of that is abstracted away for the consumer. For the consumer, it’s as easy as going to the store, picking out plantains with the desired level of ripeness, and purchasing them at checkout. For the store, it is an effortful process of maintaining interaction with multiple plantain suppliers—because tightly coupling to just one supplier would result in brittleness (what if the supplier has an off year and there are no plantains for your consumers now?)—as well as buffering and queueing plantains to smooth out vagaries in supply (while maintaining enough efficiency to turn a profit).
Tip
We can even think of teams as abstractions over a certain problem or domain that the rest of the organization can use. Most organizations making money have some sort of billing service. In those organizations, not only do software systems use the billing service to bill customers for products, the humans in the system also use the billing team for their billing needs and expect the billing team to know the domain much better than anyone else.
When we create abstractions, we must remember that someone must maintain them. Handwaving away all that effort for the consumer comes with a high cost, and someone must design and maintain those illusions. For anything that isn’t providing differentiated organizational value, it’s worth outsourcing all that illusion-making to humans whose value is based on abstracting that complexity. A grocery store doesn’t mold their own plastic to make shopping baskets. Likewise, a transportation company with an eCommerce site isn’t in the business of creating and maintaining infrastructure abstractions, like, say, handling mutual exclusion and deadlocks.
Each time we create an abstraction, we must remember we are creating an illusion. This is the danger of creating abstractions for our own work; it can result in a self-bamboozle. An abstraction is ultimately tight coupling toward minimized overhead. It hides underlying complexity by design—but it doesn’t get rid of it unless we are only consuming, not maintaining. So, if we are the creators and maintainers of the abstraction, we can bristle at the idea of loose coupling because it requires you to account for the truth. It doesn’t hide those complex interactions across space-time, which can feel scary. We thought we understood the system and now look at all of this “baffling” interactivity! The abstraction gave us the illusion of understanding, but not the truth.
Necessarily, an abstraction hides some detail, and that detail may be important to the resilience of your system. When your software systems are a tangled nest of abstractions and something goes wrong, how do you debug it? You sacrifice a RAM stick at the altar of the eldritch gods, find a different vocation, or silently weep in front of your computer screen for a while before guzzling caffeine and performing the virtual equivalent of slamming your head into a brick wall as you tease the abstractions apart. The abstractions try to conceal baffling interactions and n-order effects of events, but tight coupling cannot eradicate interactive complexity. Smaller faults in components balloon into system-level failures and the immediacy of incident response required by tight coupling is impossible because the information needed is opaque beneath the thick, shiny gloss of abstraction.
Opportunity cost frames the abstraction trade-off well. What benefits do we give up by choosing an abstraction? How does that compare to the streamlining and legibility we receive from the time it is implemented to when it contributes to failure? What we seek is for the socio part of the system to get as close to understanding as possible. We will soon talk about the vital importance of sharing knowledge when we explore how we can support the fourth potion ingredient: feedback loops and learning culture. Much like we don’t want a single service on which our entire system depends, we don’t want a single human on which our entire system depends. Our strength comes from collaboration and communication, that different perspectives not only help, but are explicitly necessary to understand the system as it behaves in reality, not just in the static models of our minds or in an architecture diagram or in lines of code.
Fostering Feedback Loops and Learning During Build and Deliver
Our fourth ingredient of the resilience potion is feedback loops and learning culture, the capacity to remember failure and learn from it. When we remember system behavior in response to stressors and surprises, we can learn from it and use it to inform changes that improve system resilience to those events in the future. What can we do to summon, preserve, and learn from these memories to create a feedback loop when building and delivering?
This section covers how to be curious and collaborative about the sociotechnical system to build more effectively, exploring four opportunities to foster feedback loops and learning during this phase: test automation, documenting why and when, distributed tracing and logging, and refining how humans interact with our development practices.
Test Automation
Our first opportunity to nurture feedback loops and learning during this phase is the practice of test automation. We need to articulate the why for tests just as much as we must for other things. When we write a test, can we articulate why we are verifying each thing we are verifying? Without knowing why each thing is being verified, we’ll be flummoxed when our tests fail after changing or adding new code. Did we break something? Or are the tests simply stale, unable to reason about the updated state of the world?
When the why behind tests—or anything else—isn’t documented and digestible, humans are more likely to assume that they are unnecessary, something that can be ripped out and replaced with ease. This biased reasoning is known as the Chesterton’s fence fallacy, first described in G.K. Chesterton’s book The Thing:
In the matter of reforming things, as distinct from deforming them, there is one plain and simple principle; a principle which will probably be called a paradox. There exists in such a case a certain institution or law; let us say, for the sake of simplicity, a fence or gate erected across a road. The more modern type of reformer goes gaily up to it and says, “I don’t see the use of this; let us clear it away.” To which the more intelligent type of reformer will do well to answer: “If you don’t see the use of it, I certainly won’t let you clear it away. Go away and think. Then, when you can come back and tell me that you do see the use of it, I may allow you to destroy it.”
How can we promote faster feedback loops from our tests? Through test automation. Automation helps us achieve repeatability and standardizes a sequence of tasks (giving us both looser coupling and more linearity). We want to automate the tasks that don’t benefit from human creativity and adaptation, like testing, which can also keep code easy to change. If you don’t automate your tests, any learning cycle iteration will straggle and will be far more expensive. Test automation speeds up our feedback loops and smooths friction around learning from our tests.
Alas, test automation sometimes spooks cybersecurity people, who lionize heavy change processes for the sake of “risk” coverage (whatever that really means). The traditional cybersecurity team shouldn’t be testing software since they should already be involved in the design process (as discussed in the last chapter), and should trust software engineers to implement those designs (we don’t want a panopticon). When we interfere with test automation and tightly couple testing to an external entity, like a separate, siloed cybersecurity team, we jeopardize resilience by reducing the socio part of the system’s capacity to learn.
But, enough about all the ways the cybersecurity industry currently gets it wrong. How do we do test automation correctly? Security test suites can trigger automatically once a PR is submitted, working in tandem with code reviews by other developers to improve efficiency (and satisfy the eldritch production pressure gods). Of course, some traditional security testing tools are not fit for automated workflows; if a static analysis tool takes 10 minutes—or, as is lamentably still common, a few hours—to perform its scan, then it will inevitably clog the pipeline. As of the 2019 Accelerate State of DevOps report, only 31% of elite DevOps performers use automated security tests compared with an even more meager 15% of low performers. Security test suites historically are controlled by the security team, but as we will continue stressing throughout the book, this centralization only hurts our ability to maintain resilience—as Figure 4-2 illustrates.
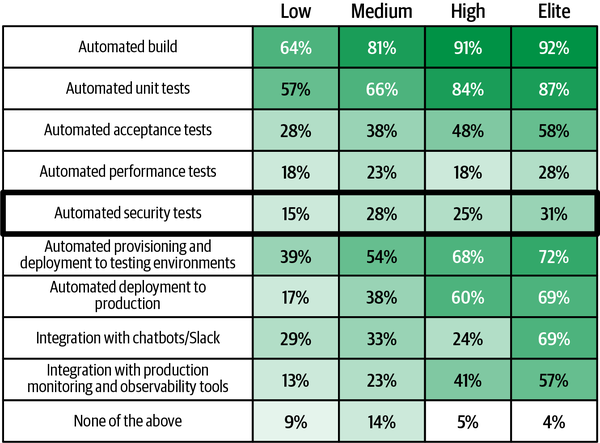
Figure 4-2. Adoption of different forms of automation across DevOps performers (source: Accelerate State of DevOps 2019 report)
We can use static analysis as an example of how test automation can improve quality. Static analysis, aside from the setup cost of writing the test, can be seen as inexpensive when amortized over time as it uncovers bugs in your code automatically. With that said, there is often a substantial meta divide among software engineering teams. When you’re on top of your backlog and regularly refining design, you can afford the luxury of caring and doing something about potential security failings. When you’re suffocating under a scrapheap of C code and discouraged from refining code, being presented with more security bugs adds insult to injury. The safety net, so to speak, to help the software engineering teams battling with difficult-to-maintain legacy code is woven with tools that can help them iteratively modernize and automate processes. Whether self-serve, delivered by a platform engineering team, or delivered by a security team following a platform engineering model, test automation—among other automation that we’ve discussed in this chapter—can help struggling teams climb out of the mire bit by bit.
This is why security programs must include software engineering perspectives when selecting tools; there may already be static analysis tools—or more general “code-quality” tools—that are CI/CD-friendly, implemented, or under consideration that could suffice to find bugs with security impacts too. For instance, integrating static analysis tools into IDEs can reduce time spent by developers fixing vulnerabilities and increase the frequency that developers run the security analysis on their code. Developers are already familiar with tools like these and even rely on them to improve their workflows. You may hear a developer, for instance, raving about TypeScript, a language that exists purely to add type checking to an existing less-safe language, because it makes them more productive. If we can help software engineering teams be more productive while learning more from faster feedback loops, we are well worthy of self–high fives.
Documenting Why and When
Another opportunity for fostering feedback loops and learning when building and delivering systems is the practice of documentation—specifically, documenting why and when. As we discussed in Chapter 1, resilience relies on memory. We will flail when learning if we cannot recall relevant knowledge. We need this knowledge to remain accessible so that as many humans as possible in the socio part of the system can employ it in their feedback loops. Hence, we must elevate documentation as a core practice and higher priority than other “sexier” activities. This section will describe how to develop docs to best facilitate learning.
When we share knowledge, we can’t think in terms of static components. Remember, resilience is a verb. We need to share our understanding of the system—not just how the components interact but why and when they interact—and even why they exist at all. We need to treat it like describing an ecosystem. If you were documenting a beach, you could describe what each thing is and how it works. There is sand. There are waves that move in and out. There are shells. But that doesn’t tell us much. More meaningful is how and when these components interact. Low tide is at 13:37 and, when it happens, shrimp and sea stars take refuge in tide pools; tide pools become exposed, as do oysters; crabs scurry along the beach foraging for food—like those tasty oysters and critters in the tide pools; shorebirds also peck for morsels along the shoreline. When the tide comes in six hours later (high tide), oysters and scallops open their shells to feed; shrimp and sea stars wash out into the sea; crabs burrow; shorebirds roost; female sea turtles crawl onto shore to lay their eggs—and high tides will eventually pull the baby turtles into the ocean.
Our software systems are complex, made of interacting components. It is those interactions that make systems “baffling” and therefore it’s imperative to capture them as builders. We need to think about our systems as a habitat, not a disparate collection of concepts. When encountering a system for the first time, we usually wonder, “Why was it built this way?” or perhaps even more fundamentally, “Why does this exist?” Yet this is what we tend to document the least when building and delivering software.
We mentioned Mozilla’s Oxidation project earlier in this chapter in the context of migrating to a memory safe language, but it’s also a laudable example of documenting the why. For most components they’ve shipped in Rust, they answer the question “Why Rust?” For instance, with their integration of the fluent-rs localization system they explicitly documented that they compiled it in Rust because: “Performance and memory wins are substantial over previous JS implementation. It brings zero-copy parsing, and memory savvy resolving of localization strings. It also paves the way for migrating the rest of the Fluent APIs away from JS which is required for Fission.”
Such a detailed answer indicating the purpose and even the mental model behind the decision deftly avoids Chesterton’s fence problem in the future. But even less detailed answers can still support a learning culture, feedback loops, and, crucially, prioritization. For example, one of the proposed components to be “oxidated” into Rust—replacing DOM serializers (XML, HTML for Save As.., plain text)—simply states: “Why Rust? Need a rewrite anyway. Minor history of security vulnerabilities.” Migrating to a memory safe language can be an opportunity to tackle long-standing issues that hinder reliability, resilience, or even just maintainability. We should always seek opportunities to maximize our return on effort investments where we can.
Documenting security requirements
Documenting why and when is a critical part of optimizing effort allocation in our Effort Investment Portfolio. Requirements define expectations around qualities and behaviors, allowing teams to choose how to invest their effort capital to meet those requirements. Documented security requirements support repeatability and maintainability—essential qualities for feedback loops—while reducing effort expended by all stakeholders on crafting specific requirements for each separate project.
For instance, security teams often invest substantial effort into answering software engineering teams’ ad hoc questions around how to build a product, feature, or system in a way that won’t be vetoed by the security program. In practice, this manual effort causes backlogs and bottlenecks, leaving engineering teams “stuck” and security teams with more limited effort capital to invest elsewhere (like in activities that might fulfill the security program’s goals more fruitfully).
Tip
The 2021 Accelerate State of DevOps report found that teams with high quality documentation are 3.8 times more likely to implement security practices (and 2.4 times more likely to meet or exceed their reliability targets).
Defining explicit requirements and granting engineering teams the flexibility to build their projects while adhering to those requirements frees up time and effort for both sides: engineering teams can self-serve and self-start without having to interrupt their work to discuss and negotiate with the security team, and the security team is no longer as inundated with requests and questions, freeing up time and effort for work with more enduring value. If we write documentation around, for instance, “Here is how to implement a password policy in a service,” we invest some of our effort capital so other teams have more freedom allocating their own effort capital. They can access the documentation, understand the requirements, and avoid having to ask ad hoc questions about one-off requirements.
As a recent example, Principal Software Architect Greg Poirier applied this approach to CI/CD pipelines, eliminating the need for a centralized CI/CD system while maintaining the ability to attest software changes and determine software provenance. Rather than instituting strict guardrails that apply equally to all engineering teams, we can instead define the desired requirements in CI/CD pipelines (and make them available in a single accessible place). This allows engineering teams to build and evolve their CI/CD pipelines as fits their local needs as long as they meet the requirements.
We can improve how we handle vulnerabilities through knowledge sharing too. When vulnerabilities are discovered in standardized, shared frameworks and patterns, they’re easier to fix. If teams drift off the beaten path and build things in a weird way, then we should expect more vulnerabilities. To use SQL injection (SQLi) as an example, it shouldn’t take one team suffering an attacker exploiting a SQLi vulnerability in their service for the organization to discover parameterized queries and ORMs (object relational mappers), which make writing SQLi vulnerabilities more difficult. The organization should instead standardize on their database access patterns and make choices that make the secure way the default way. We’ll discuss defaults more in Chapter 7. If one engineering team spots a vulnerability in their code, publicizing this to other teams, rather than fixing the single instance and moving on, can lead to brainstorming about how to check for the presence of the vulnerability elsewhere and strategies for mitigating it across systems.
Writing learning-driven docs
No one gets a bonus for writing great docs. Therefore, we need to make it easy for humans to create and maintain docs despite writing them not being their core skill set or their most scintillating challenge. The best resource we can create is a template with a vetted format that everyone agrees to and that requires low effort to fill in. The template should reflect the minimum required for sharing knowledge to other humans; this will make it clear what the minimum is when creating the doc while allowing for flexibility if the human wants to add more to the doc.
Sometimes engineers think that good docs for their feature or service are only relevant if the users are developers. That is not the right mindset if we wish to support repeatability or preserve possibilities. What if our service is consumed by other teams? What if it is useful to our organization if, at some point, our service is sold as an API? In a world that is increasingly API-driven, documentation gives us this flexibility and ensures our software (including firmware or even hardware) is consumable. And through this lens, documentation directly improves our metrics.
When you’re building a system, you’re interacting with components doing different things with different relationships to each other. Document your assumptions about these interactions. When you conduct a security chaos experiment, you learn even more about those components and relationships. Document those observations. As a thought experiment, imagine a kind stranger gifts you a lottery ticket when you go get your caffeine of choice during a work break; you win the lottery, decide to take a year off work to travel around all the gorgeous islands in the world, and then come back to your desk at day 366 to dive back into your work (assuming relaxing on pristine beaches and frolicking with exotic flora and fauna ever gets boring). Your mind is totally refreshed and thus you’ve forgotten mostly everything about whatever it was you’re doing. Would the documentation you left for yourself be sufficient for you to understand the system again? Would you be cursing Past You for not writing out assumptions about how this component doing one thing relates to another component doing another thing?
Explain to Future You how you built the system, how you think it works, and why you think it works that way. Future You may conduct a security chaos experiment that disproves some of those assumptions, but it’s at least a basis upon which Future You can hatch hypotheses for experiments. Of course, as you’ve likely already surmised, we aren’t just writing these things for Future You as you develop software; it’s also for new team members and existing ones who maybe aren’t as familiar with the part of the system you wrote specifically. Documentation can be invaluable for incident response too, which we’ll cover more in Chapter 6.
With that said, documents benefit Future You in another way too, by capturing your knowledge in a digestible format that removes the need to contact you directly and interrupt your work. We want to incentivize other humans to use documentation as their go-to source rather than performing the high-cost action of contacting us, which means we need to not only answer the basics in the docs, but also make them accessible and digestible (and if we keep getting asked the same question, it’s a call to action to add the answer to the doc). Who among us hasn’t looked at a novella-like doc with confusing structure and poor writing and wanted to give up? Or the doc will explain the minutiae about how the component is constructed as a static entity, but completely miss explaining why it is constructed that way or how it works across space-time.
If we don’t describe how it behaves at runtime, including its common interactions with machines and humans alike, we’ll only get a written version of a “still life” portrait of the component. A visual explanation of its interactions across space-time—a movie, rather than a portrait—can make the doc even more digestible to human eyes. Why and when do components interact? When and where does data flow? Why is there a particular temporal order? Ensuring that this visual explanation, whether a diagram or gif or decision tree or other format, is easy to change (and versioned) will keep knowledge fresh as conditions evolve and feedback is collected. For instance, a README file can be versioned and decoupled from one individual engineer, allowing you to capture a CI/CD process with both a visual and written explanation of why each step unfolds and why interactions exist at each step.
As we will keep stressing, it is far more important to explain why the system behaves in a particular way and why we chose to build it this way than how it behaves. If our goal is for a brand-new team to be able to get started with a system quickly and understand how to maintain and add to it, then explaining why things are the way they are will fill in knowledge gaps much more quickly than the how. The why is what drives our learning, and continual prodding of those assumptions enlivens our feedback loops.
We want software components that are well-understood and well-documented because when we share our own knowledge about the system, it makes it easier for us to explain why we built something using these components and why it works the way it does. Building our own software component might be easier for us to mentally model, but harder for us to share that mental model with others and maintain by incorporating feedback. It also makes components harder to swap out; the endowment effect33 (a subset of loss aversion)34 means we never want to discard our “darlings.” We don’t want to glue things together into a tangled, tightly coupled mess where both the why and how are difficult to discern. If we declare bankruptcy on having a mental model at all, doing by blind faith, then we will defile our resilience potion; we won’t understand the critical functions of the systems, and we will be unaware of safety boundaries (and push closer to them), be baffled by interactions across space-time, and neither learn nor adapt.
Distributed Tracing and Logging
The third practice we’ll discuss that can fuel feedback loops and promote learning during this phase is distributed tracing and logging. It’s difficult to just look at little breadcrumbs spread by the system that aren’t brought together into the story (and humans very much think in stories). Whether triaging an incident or refining your mental model to inform improvements, observing interactions over time is essential. You can’t form a feedback loop without being able to see what’s going on; the feedback is a core part of the loop.
We should plan for and build this feedback into our services through tracing and logging. Neither one is something you can bolt on post-delivery or apply automatically to all the services you operate. You invest effort during the build and delivery phase, then receive a return on that investment in the observe and operate phase. Alternatively, you can decide not to invest effort capital during this phase and tear your hair out in frustration when you try to debug your complicated microservice system when it fails by guessing which log messages match up to which (which is incredibly cumbersome on services with reasonable volume). We can think of tracing and logging as a hedge against a severe downturn when our software runs in production—the feedback that helps us maintain a productive loop rather than a downward spiral. This section will explore how we can think about each during this phase.
Distributed tracing to track data flows
Distributed tracing is a mechanism to observe the flow of data as it moves through a distributed system.35 Distributed tracing gives us a timeline of logs and the flow of data between systems, a way to make sense of interactions across space-time. It lets you stitch individual operations back to the original event. By way of analogy, consider a partnership with another organization; every time they make a product or feature request, there is a ticket ID. Any activity internally related to the request gets that ticket ID too, so you know how to bill for it (and can track work dedicated to it). Distributed tracing is the same idea; an incoming request gets tagged with a trace ID, which shows up in the logs of each service as it flows through.
Let’s consider a case where an attacker is exfiltrating data from a hospital’s patient portal. We can see data is being exfiltrated—but how is it happening? There is a frontend service that’s responsible for displaying the dashboard the patient sees when they log in (the Patient Portal service). The Patient Portal service needs to request data from other services maintained by other teams, like recent lab reports from the Labs service, verifying the login token from the Token service, and querying the list of upcoming appointments from the Schedule service. The frontend will make a single request from the Patient Portal service, which makes requests to all those other services. Maybe the lab reports are mixed between in-house and outsourced lab work. The in-house service can read directly from the internal database and properly check user IDs. To ingest the partner lab reports, however, the Labs service must query a partner’s lab report integration service. Even in this simple scenario, you’re three services deep.
Let’s say the team associated with the partner lab results service discovers they made a mistake (like accidentally introducing a vulnerability) and an attacker is exfiltrating data. They might be able to say what data is being sent out, but they wouldn’t be able to trace the data flows without understanding all of the requests coming from the Labs service—and they’d need to follow it through to all the requests coming from the Patient Portal service. This is a nightmare, because it’s unclear which operations (or events) might even make a request to the partner lab results service, let alone which requests are by the attacker versus a legitimate user. All of the traffic surging into this service is from inside the company, from peer teams, but that traffic is associated with some sort of user operation that is from outside the company (like a patient clicking on their dashboard to view recent lab results).
Distributed tracing dissipates this nightmare by assigning a trace ID at the point of traffic ingress, and that trace ID follows the event as it flows through the system. That way, the partner lab results service can look at where the trace ID appears in logs across other services to determine the event’s route through the system.
Distributed tracing not only helps us observe system interactions across space-time, but it also helps us refine system design and design new versions—giving us an elegant feedback loop. At the enterprise scale, you don’t have complete visibility into what the teams consuming your data and accessing your service are doing with it. Their incidents can easily become your incidents. When you’re refining the design of your system, you want to understand the impact it has on your tree of consumers. The more partners and consumers are braided into the chain, the more difficult it is to understand the chain. You have a mental model of how events flow through the system and how your specific part of the system interacts with other parts—but, how accurate is your mental model?
Distributed tracing helps you refine that mental model by learning about real interactions in your system and between its services. We can use distributed tracing to plan for capacity, to fix bugs, to inform consumers of downtime and API changes, and more. It bears repeating that the value we derive from distributed tracing is when software runs in production; however, we must make our effort investment during the development phase to realize this value. Distributed tracing is, in essence, making the statement that we want to be able to correlate data across systems—that we want that trace ID. It is during development that you must make the decision that you want to have the capability in the system, even if much of the value is derived during the next phase, operating and observing.
If you follow the advice of loosely coupling your systems and splitting them out over logical boundaries, you may end up with visibility problems and it may become more difficult to see the flow—even if that flow is more resilient now. That’s exactly what distributed tracing is designed to divulge. It isn’t fancy, but it’s indisputably useful for powering a feedback loop.
Deciding how and what to log
Logging helps us learn about system behavior; when we insert logging statements into code as it’s written, we sow seedlings to stimulate our feedback loops. Logging statements generate a record of system execution behaviors, what we refer to as logs. When we discover that we need some information about the system (or part of the system) to add a new feature, fix a problem (like a bug), or expand capacity, we need logging to furnish that information for the feedback loop. Software engineers sometimes even build a new version of the system with new logging statements in place just to get that information. For instance, during an incident, a software engineering team may expedite deployment of a version that adds a new logger.log so they can peer into the system and deduce what is happening with the baffling surprise. Most software engineers know the mechanics of adding logging statements, so we won’t cover those details in this section. However, it’s worth reminding all stakeholders of what we should log and how we should think about logging.
Tip
Blocks are the constructs developers use when adding logging statements. Blocks are the organizational structure of the code. For example, in Python, the indentation levels—like the contents of the function—reflect a block. If you have indentations inside the function, there will be a sub-block for the true condition and a sub-block for the else part (if there is one). Basically, each of the control flow mechanisms opens a separate block. If you have a for loop or a while loop, you get a block.
A block is kind of like a paragraph. In compiler and reverse engineering land, a basic block is the substructure that always executes from top to bottom. A statement is the equivalent of a sentence—one line within a block. Expression refers to part of the statement that is evaluated separately. And a clause refers to the predicate in an if or a while statement.
We might not know what we need to log until we start interpreting data generated when our code actually runs. We must be somewhat speculative about what might be useful to recover from a future incident, to inform traffic growth, to know how effective our caches are, or any of the thousand other things that are relevant. When adding logging statements in our code as we write it, we want to preserve possibilities once our code is running in production and fuel a feedback loop. Computing scholars Li et al. describe the trade-off between sparsity and verbosity: “On one hand, logging too little may increase the maintenance difficulty due to missing important system execution information. On the other hand, logging too much may introduce excessive logs that mask the real problems and cause significant performance overhead.”36
Warning
It should go without saying, but we don’t want to include passwords, tokens, keys, secrets, or other sensitive information in our logs. For example, if you are a financial services or fintech company handling multitudes of sensitive PII, that sensitive information—whether names, email addresses, national identifiers (like Social Security numbers), or phone numbers—ending up in your logs constitutes a data leakage that could lead to problematic outcomes.
In general, there is rarely a reason PII must be logged rather than using a database identifier instead. A log describing “There is an issue with Charles Kinbote, charles@zembia.gov, database id 999” can be replaced, without loss of utility, with “There is an issue with user database id 999.” The investigating engineer can use authenticated systems to scour more information about the impacted user or database record—but without the hazard of revealing sensitive data.
The point of logs is to inform feedback loops—not blast so much noise that it doesn’t help anyone, nor be so sparing that it also doesn’t help anyone. We log to learn. If the success or failure of something matters to your business, consider logging it. We must think about operations—system functionality—and ensure they’re reflected usefully in our logging and observability tools. What you might need to log depends on local context. The closest to generalized logging wisdom is that you need to log faults that occur in your system if you want to preserve the possibility of uncovering them. If your database transaction times out, that may indicate that the data wasn’t saved. This kind of event isn’t something you want to ignore in an empty catch block, and it should probably be categorized at least at the ERROR level.
Crucially, we want to ensure errors—and their context—are assessed by a human. Often, there is a torrent of logging statements that gush into a bucket (or black hole, depending on whom you ask) for querying later in case you need them. Our mental model might be that errors make it into someone’s inbox or notification stream at some point, but that may not be the case—so chaos experiments can verify this expected behavior. In fact, one of the best places to start with chaos experiments is verifying that your logging pipelines (or alerting pipelines) behave the way you expect. We’ll talk more about this precise use case for experimentation in “Experience Report: Security Monitoring (OpenDoor)”.
Tip
Log levels indicate the importance of the message; FATAL (“Critical” on Windows) is viscerally dire while INFO (“Informational” on Windows) is less doom-inspiring. When software engineers set log levels, they are based on their mental models of how important this behavior is for understanding the system (whether to troubleshoot or refine). This makes the decision of what level to apply subjective and, therefore, tricky.
We must consider where we should weave local context into log messages too: like the associated user ID requests, trace IDs, whether the user is logged in or not, and more depending on local context. If you’re building a transaction processing system, maybe you associate each transaction with an ID so if a specific transaction fails, you can use the ID for troubleshooting and investigation.
As a final note of caution, engineering teams already maintain logging infrastructure, so there’s really no need for the security team to create parallel infrastructure. Instead, security teams should insist that their vendors interoperate with that existing infrastructure. There’s no reason to invent the wheel—remember, we want to “choose boring”—and, when security teams create this shadow realm of duplicative infrastructure, it disrupts your ability to learn—a crucial ingredient in our resilience potion.
Refining How Humans Interact with Build and Delivery Practices
Finally, we can refine how humans interact with our development practices as another opportunity to strengthen feedback loops and nurture a learning culture. To build and deliver software systems that maintain resilience, our practices in this phase need to be sustainable. We need to be in a constant learning mode of how the humans in our sociotechnical systems interact with the practices, patterns, and tools that allow them to build and deliver systems. We need to be open to trying new IDEs, software design patterns, CLI tools, automation, pairing, issue management practices, and all the other things that are woven throughout this phase.
Part of this learning mode is also being open to the idea that the status quo isn’t working—listening to feedback that things could be better. We need to be willing to discard our old practices, patterns, and tools when they no longer serve us or if they make it difficult to build a resilient or reliable system. Remembering local context also helps us refine how work is done in this phase; some projects may demand different practices and we must decide to refine them accordingly.
To recap, we have four opportunities for fostering feedback loops and nourishing learning—the fourth ingredient of our resilience potion recipe—during build and delivery: testing automation, documenting why and when, distributed tracing and logging, and refining how humans interact with development processes. How we change these interactions—and how we change anything during this phase—brings us to the final ingredient of our resilience potion: flexibility and willingness to change.
Flexibility and Willingness to Change
With those four ingredients now stirred into our hot and chocolatey concoction, we can discuss how to plop our final ingredient, the marshmallow—symbolizing flexibility and willingness to change—into our resilience potion that we can brew while building and delivering. This section describes how to build and deliver systems so we can remain flexible in the face of failures and evolving conditions that would otherwise quash success. Distributed systems researcher Martin Kleppmann said, “Agility in product and process means you also need the freedom to change your mind about the structure of your code and your data,” and this fits perfectly with the last ingredient of our resilience potion.
For some organizations with lots of “classic” applications, a willingness to change means a willingness to stick with iteration and migration over many quarters, if not years, to transform their applications and services into more adaptable, changeable versions. A seed-stage tech startup is building from scratch and change can happen overnight. A century-old business with mainframes and older languages arguably needs flexibility and willingness to change even more, since they’re already starting with a brittle foundation, but that change cannot happen overnight. Nature is a patient architect, allowing evolution to unfold over generational cycles. Migrating from a classic, tightly coupled paradigm to a modern, loosely coupled one requires patience and carefully architected evolution too. There are quick wins along the way, with resilience benefits accumulating with each iteration. None of what we describe in this book is out of reach for even the most mainframey and COBOLy of organizations; what it takes is careful assessment of your Effort Investment Portfolio and prioritization of which resilience ingredients you’ll pursue first.
In this section, we will present five practices and opportunities to help flexibility and willingness to change flourish during this phase: iteration, modularity, feature flags, preserving possibilities for refactoring, and the strangler fig pattern. Many of these strategies encourage evolution and interweave willingness to change by design—promoting the speed on which our graceful adaptability depends.
Iteration to Mimic Evolution
The first practice we can adopt to foster flexibility and maintain willingness to change is iteration. As a first approximation of what makes for “good code,” it is code that is easy to replace. It helps us foster the flexibility and willingness to change that is essential for systems resilience by allowing us to modify and refactor code as we receive feedback and as conditions change. Code that is easy to replace is easy to patch. Security teams often tell software engineers to mend security issues in code at a more “fundamental” level rather than slapping a bandage on it; code that is easy to replace is also easy to refactor to remedy such problems.
An iterative approach to building and delivering systems enables the evolvability we need to support systems resilience. Minimum viable products (MVPs) and feature experimentation are our best friends during this phase. Not only does it hasten time to market for code—reaching end users more quickly—but also allows us to more quickly determine what works, or doesn’t, to escape the trap of rigidity (which erodes resilience). It is a means to achieve not only looser coupling, but the easy substitutions that characterize more linear systems. We need to encourage experimentation, making it easy to quickly innovate, but discard what doesn’t work without shame or blame.
We also need to follow through on our MVPs and experiments. For instance, if you develop a new authentication pattern that is better than the status quo, make sure to finish the job—move from MVP to a real product. It’s easy to lose steam after getting a prototype to work in part of the system, but follow-through is required for resilience. If we don’t follow through or invest in maintaining it, we shrink the slack in the system and let brittleness take hold. This follow-through is necessary even if our experiments don’t turn out as we hoped. If evidence suggests the experiment isn’t viable, we need follow-through in the form of cleaning up after ourselves and expunging the experiment from the codebase. Remnants of failed experiments will clutter the codebase, causing confusion to anyone who stumbles upon them. (Knight Capital’s stunning failure in 2014 arguably is an example of this.)
Alas, the incremental approach to building and delivering often fails for social reasons. Humans relish novelty. We often love achieving a big win at one time rather than a bunch of smaller wins over time. Of course, this penchant for novelty and flashy feature releases means we will sacrifice incremental progress and therefore our ability to maintain resilience. It’s far more difficult to evolve software that only gets “big bang” releases once a quarter than software deploying on demand, like every day or every week. When a new high-impact vulnerability strikes like thunder, the incremental approach means a patch can be released quickly, while the big, splashy release model will likely be slower to patch for both technical and social reasons.
How can we keep things feeling fresh in the iterative model? Chaos experiments, whether the security kind or performance kind, can spark adrenaline and offer a novel perspective that can lead engineers to see their code and software through a different lens. For example, we could analyze the architecture and code of a system to try to understand its performance, but a more effective approach is attaching a profiler while simulating load; the tooling will tell us exactly where the system is spending its time. We can also incentivize people to follow through, be curious, and take ownership of code, as in “you own this module personally.”
An iterative approach also aligns with modularity in design, which we’ll cover next.
Modularity: Humanity’s Ancient Tool for Resilience
The second opportunity at our fingertips to cultivate flexibility and maintain adaptability is modularity. According to the U.S. National Park Service (NPS), modularity in complex systems “allows structurally or functionally distinct parts to retain autonomy during a period of stress, and allows for easier recovery from loss.” It is a system property reflecting the degree to which system components—usually densely connected in a network37—can be decoupled into separate clusters (sometimes referred to as “communities”).38
We may think of modules in terms of software, but humans have intuitively grasped how modularity supports resilience in sociotechnical systems for thousands of years. In ancient Palestine, modular stone terraces grew olive trees, grapevines, and other produce.39 The Anglo-Saxons implemented three-field systems, rotating crops from one field to another, a strategy pioneered in China during the first millennium BCE.40 For this reason, the NPS describes modularity as reflecting “a human response to a scarcity of resources or stressors that threaten economic activities.” Modularity is enlaced in humanity’s history, and with it we can weave a resilient future too.
In the context of cultural landscapes—a natural landscape shaped by a cultural group—possessing modular units (like land use areas) or features (like orchards or fields) improves resilience to stress. During a disturbance, a modular unit or feature can persist or function independently of the rest of the landscape or other modular features. It proffers looser coupling, quelling the contagion effect. The single-purpose nature of the modules also introduces linearity—a way of making the landscape more “legible” without the homogeneity of the tightly coupled Normalbaum we discussed in Chapter 3.
At the John Muir National Historic Site, for instance, there are multiple blocks of multispecies, multivariety trees that foster resilience to frost, as shown in Figure 4-3. This clever design ensures that if late frosts damage some of the blooming trees, there can still be some fruit yield. This resilience did not blossom at the expense of efficiency, either—it actually enhanced efficiency. The NPS writes, “The historic system of orchards at the John Muir National Historic Site was planted as modular units of species blocks containing mixed varieties, gaining efficiencies in operations but also building resilience into the system.”
Figure 4-3. An example of modular architecture in a cultural landscape, from the John Muir National Historic Site managed by the NPS (source: National Park Service)
Whether cultural landscapes or software landscapes, when there is low modularity, failure cascades pervade. Low modularity unfetters contagion effects, where a stressor or surprise in one component can lead to failure in most or all of the system. A system with high modularity, however, can contain or “buffer” those stressors and surprises so they don’t spread from one component to the others. It is through this benefit that modularity can be characterized as a “measurement of the strength of dividing a system into groups of communities and is related to the degree of connectivity within a system.”41
For instance, increased modularity can slow the spread of infectious diseases—precisely the theory behind social distancing and, particularly, “COVID bubbles,” where a group of less than 10 humans stay together, but otherwise minimize interaction with other groups. Other examples of modularity in our everyday lives include airport quarantine to prevent invasive wildlife or epidemics and firebreaks—gaps in combustible material—that break the spread of wildfire.42
While our software “species”—separate services or applications with a unique purpose—rarely perform the same function43 (like fruit-producing trees), we can still benefit from modularity. To extend the orchard analogy, the common irrigation and maintenance labor applied to all of the trees within the orchard is akin to the common infrastructure in our software “orchards” like logging, monitoring, and orchestration. Modularity can even refine our critical functions. An adtech company could create duplicated services that share 95% of behavior, but with small, critical parts to play user segmentation strategies against each other.
Note
In the sociotechnical dimension of our software systems, a frenzy of new features are added to a system, then the system stabilizes as we behold the ramifications of our changes. The fact that features are labeled alpha, beta, limited availability, or GA is a reflection of this. We can think of this as a “breathe in, breathe out” cycle for software projects (or a “tick-tock” cycle in the now-defunct Intel architecture metaphor).
Modules often introduce more linearity, allowing for basic encapsulation and separation of concerns. They also create a local boundary upon which we can later introduce isolation. At a more localized level we have modularity for organizational purposes, to make navigating and updating the system easier, and to provide a level of logical linearization (where data flows in one direction, but backpressure and faults disrupt full linearity)—even if the modules aren’t isolated.
Modularity, when done right, directly supports looser coupling: keeping things separate and limiting coordination across the codebase. It also supports linearity by allowing us to break things down into smaller components that get us closer to a single purpose. If we try to keep functionality together, we can add complexity. In tef’s post on counterintuitive software wisdom, they advise, “In trying to avoid duplication and keep code together, we end up entangling things…over time their responsibilities will change and interact in new and unexpected ways.” To achieve modularity, the author says we must understand:
Which components need to communicate with each other
Which components need to share resources
Which components share responsibilities
What external constraints exist—and which way are they moving
Warning
The most notable downside for loose coupling is transactional consistency. In most natural complex systems, relative time and space suffices, but we want our computers to be in lockstep (or at least appear to be).44 As any engineer who has built eventually consistent systems knows, eventual consistency is so complicated that it can break your brain trying to mentally model it.45 So, maybe you allow tighter coupling in a case like this, but only this.
Sometimes tools can’t operate in a degraded state; it’s a Boolean of working or not working. Phasing is necessary for some activities, but a tool embodying multiple sequences can be brittle and lead to failure cascades. Modularity can keep our options open as we scale, allowing us to maintain more generous boundaries of safe operation and evade such failure cascades. We can piece together phases like LEGO blocks so users can take them apart when they are using the tool, allowing them to adapt, modify, or debug it themselves. It aligns with the reality that, despite our best efforts, our mental models will never 100% anticipate how users will interact with what we build. It’s important for some systems to fail quickly rather than attempt to proceed.
Feature Flags and Dark Launches
Another practice to support flexibility and remain poised for rapid change is the art of dark launches—like launching a ship from a quiet harbor at midnight under a new moon. The practice of dark launches allows you to deploy code in production without exposing it to production traffic or, if preferred, exposing a new feature or version to a subset of users.
Feature flags allow us to perform dark launches. Feature flags (or feature “toggles”) are a pattern for choosing between alternate code paths at runtime, like enabling or disabling a feature, without having to make or deploy code changes. They’re sometimes considered a neat trick useful to product managers and UX engineers, but this belies their resilience potential. It makes us nimbler, speeding up our ability to deploy new code while offering the flexibility to tweak how accessible it is to users. If something goes wrong, we can “uncheck” the feature flag, giving us time to investigate and refine while keeping all other functionality healthy and operational.
Feature flags also help us decouple code deployments from the big, shiny feature releases we announce to the world. We can observe system interactions on a subpopulation of users, informing any refinements (which are now easier and faster for us to deploy) ahead of making new code available to all users. Of course, there is a cost to feature flagging (like any practice), but product engineering teams should expect the capability as a paved road from their platform teams and use it liberally to improve reliability.
We’ll continue emphasizing the importance of inventing clever ways to improve resilience while enticing with “carrots” in other dimensions to incentivize adoption. Dark launching is precisely in that category of delectable medicine. Product Engineering teams can accelerate their feature development and get more experimental—improving coveted product metrics, like conversion rates—while we gain more flexibility, allowing us to quickly change as conditions change (not to mention granting us an opportunity to observe user interactions with the system and cultivate a feedback loop too).
Preserving Possibilities for Refactoring: Typing
Our fourth opportunity for flexibility and willingness to change is preservation of possibilities, specifically with an eye toward the inevitable refactor. When writing code, engineers are swept up in the electrifying anticipation of the release and aren’t gazing upon the hazy horizon pondering what matters when the code inevitably needs refactoring (much like movie crews aren’t ruminating on the remake when filming the original). Nevertheless, like the destinies allotted by the Moirai of ancient Greece, refactoring is ineluctable and, in the spirit of allocating effort with a wise investment strategy, we should try to preserve possibilities when building software. We must anticipate that the code will need to change and make decisions that support flexibility to do so.
How does this look in practice? At a high level, we need an easy path to safely restructure abstractions, data models, and approaches to the problem domain. Type declarations are a tool we can wield to preserve possibilities—although we acknowledge the subject is contentious. For those uninitiated in the nerd fight, you might be wondering what type declarations and type systems are at all.
Type systems are meant to “prevent the occurrence of execution errors during the running of a program.”46 We won’t go into the deep rabbit hole of type systems except to explore how it might help us build more resilient software. A type is a set of requirements declaring what operations can be performed on values that are considered to conform to the type. Types can be concrete, describing a particular representation of values that are permitted, or abstract, describing a set of behaviors that can be performed on them with no restriction on representation.
A type declaration specifies the properties of functions or objects. It is a mechanism to assign a name (like a “numeric” type47) to a set of type requirements (like the ability to add, multiply, or divide it), which can then be used later when declaring variables or arguments. For all values stored into the variable, the language compiler or runtime will verify that these values match the expanded set of requirements.
Statically typed languages require a type to be associated with each variable or function argument, with all allowing a named type and some allowing an anonymous, unnamed list of type requirements. For types with a long set of requirements, it is less error-prone and more reusable to define the type requirements once with a name attached to them and then reference the type via the name wherever it is used.
Static typing can make it easier to refactor software since type errors help guide the migration. Your Effort Investment Portfolio may prefer less allocation of effort up front, however, in which case fixing type errors when trying out new structures may be perceived as overly onerous. Table 4-1 explores the differences between static typing and dynamic typing to help you navigate this trade-off.
| Static typing | Dynamic typing |
|---|---|
| Requirements are specified and checked ahead of time so that the checks don’t have to occur as the program is running | Requirements are declared implicitly, with appropriate requirements checked every time an operation is performed on a value |
| Checking is performed up front before the program starts | Lots of checking as the program runs |
| Effort required to ensure all parts of the program (even parts that won’t run) are correctly typed with the range of possible values that could be used | No need to expend up-front effort convincing the language that values are compatible with the places they’re used |
| Valid programs that can’t be expressed in the type system cannot be written or will need to use the type system’s escape hatches, such as type assertions | Invalid programs are allowed, but may fail at runtime when an operation is performed on data of the wrong type |
The more we can encode into the type system to help the tools assist us in building safe and correct systems, the easier we can refactor. For instance, if we pass around int64s everywhere to represent a timestamp, then an alternative might be to call them “timestamps” for clarity; that way, we avoid accidentally comparing them to or mistaking them for a loop index or for a day of the month. In general, the more clarity we can provide around the system’s functions, down to individual components, the better our ability to adapt the system as necessary. Refactoring code to add useful type declarations can ensure developers’ mental models of their code are more aligned to reality.
The Strangler Fig Pattern
Sometimes we may be willing and eager to change our system, but unclear how to do so without contaminating critical functionality. The strangler fig pattern supports our capacity to change—even for the most conservative of organizations—helping us maintain flexibility. Rewriting a feature, a service, or an entire system by discarding the existing code and writing everything anew will suffocate flexibility in an organization, as will a “big bang” release where everything is changed concurrently. Some organizations in more mature industries that are tethered to decades-old systems often worry that modern software engineering practices, patterns, and technologies are inaccessible because how could they possibly rewrite everything without breaking things? They likely would crack like Humpty Dumpty and it would take exorbitant effort to put it back together again if we attempt rewriting or changing everything all at once. Thankfully, we can leverage iteration and modularity to change a subset of a system at a time, keeping the overall system running while we change some of what lies beneath.
The strangler fig pattern allows us to gradually replace parts of our system with new software components rather than attempting a “big bang” rewrite (Figure 4-4). Usually, organizations use this pattern to migrate from a monolithic architecture to a more modular one. Adopting the strangler fig pattern allows us to keep our options open, to understand evolving contexts and feel prepared to evolve our systems accordingly.
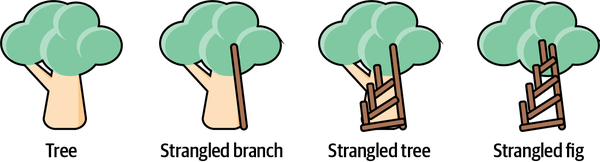
Figure 4-4. The strangler fig pattern for transforming software systems (adapted from https://oreil.ly/KyMO1)
In a browser-delivered service, you could replace one page at a time, starting with your least critical pages, evaluating the evidence once the redesigned component is deployed, then moving to the next page. The evidence collected after each migration informs improvements to the next migration; by the end of the strangler fig pattern, your team will likely be a pro. The same goes for rewriting an on-prem, monolithic mainframe application written in a hazardous raw material like C—a common status quo in older organizations or those in highly regulated industries. The strangler fig pattern allows us to pull out one function and rewrite it in a memory safe language like Go, which has a relatively low learning curve (Figure 4-5). It is, in effect, the conservative approach—but often also the faster one. The “big bang” model is often all “break things” without the “move quickly,” since tightly coupled systems are difficult to change.
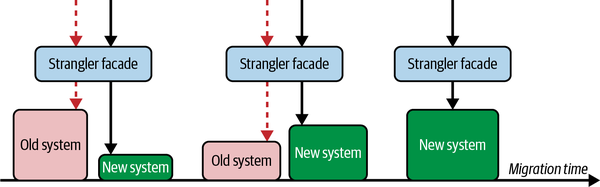
Figure 4-5. The strangler fig pattern involves extracting one part of the system and iteratively migrating more functionality over time
The strangler fig pattern is especially useful for highly regulated organizations or those with legacy, on-prem applications. By drawing on their thoughts presented in the 2021 AWS re:Invent talk “Discover Financial Services: Payments mainframe to cloud platform”, we can learn from how they migrated part of their monolithic, legacy payments mainframe application to a public cloud—maintaining PCI compliance—through the strangler fig pattern. This service is a key hub in the payments network, making changes a precarious proposition since disruption in it would disrupt the entire network. Hence, many conservative organizations often stick with their legacy, mainframe applications out of fear of disruption, even if there are tantalizing benefits awaiting them if they modernize those services—like gaining a market advantage, or at least keeping up in an increasingly competitive market.
The global financial services company Discover brainstormed the modernized platform they sought, featuring a few key characteristics: standard interfaces (like REST APIs); edge services tokenizing sensitive data (so core services can only process tokenized, canonical data); loosely coupled microservices (with a service registry for APIs and event bus for messaging); and centralized customer and event data accessed through APIs.
They didn’t try to migrate from the mainframe to this modernized platform all at once (a “big bang” approach); they chose to “slowly, slowly shift to the cloud” through the strangler fig pattern, allowing them to incrementally migrate the classic mainframe payments application by gradually replacing functionality. The classic application was tightly coupled, making it difficult to change. It was in fact their conservatism on change that dissuaded them from a “big bang” release to adopt the strangler fig pattern instead, since changing that much code in one fell swoop could spell disaster.
The team identified pieces within modules that they could “reasonably recreate elsewhere” to act in concert with the mainframe until they could be confident in the modern version and switch off the classic version. Discover chose the pricing component as the first one to migrate from the classic settlement system, since it can be “sliced and diced” in a variety of ways (Figure 4-6). Migrating the pricing component allowed them to adopt pricing changes within three weeks versus the status quo six months in the mainframe application—a huge win for the organization, fulfilling the production pressures we’ll discuss more in Chapter 7. It allowed them to “open up the possibility of greater flexibility, a lot more consistency, and definitely a lot more speed to market” than they could achieve with the classic mainframe application. It also created the possibility of providing dashboards and analytics about pricing data to their business partners, creating new value propositions.
Figure 4-6. Discover’s “Strangulation” phase 1
How did they reduce hazards in the migration? They ran the new version of the pricing engine side by side with the mainframe to gain confidence. There were zero incidents in production, and they even reduced the execution time in the settlement process by 50%. To their surprise, they actually uncovered issues in the old system that the business didn’t even know were there. As Senior Director of Application Development Ewen McPherson notes, just because a system is “classic” or legacy does not mean it perfectly matches your intentions.
Discover was starting this journey at “ground-zero,” with no experience in the cloud. They took a phased approach—aligning with the iterative approach we recommended earlier in this section—starting with a “toe-dipping phase” where the key change was calling Amazon Relational Database Service (RDS) from their internal cloud. The next phase was driven by their data analytics team, which pushed to move their on-prem data warehouse to the cloud because they conceived big data as a potential business differentiator. This push, in particular, forced Discover to “get over” their security and risk fears. A bit over a year later, they entered the next phase where they began migrating core functionality to the cloud.
This first attempt at migrating functionality to the cloud didn’t work out as planned; they lacked sufficient effort capital in their Effort Investment Portfolio to allocate to operating microservices. There are two important lessons from this false start. First, only one core change should be made at a time; in Discover’s case, they were trying to change both the architecture (transforming to microservices) and migrate functionality (to the cloud). Second, their flexibility and willingness to change—both technically and culturally—allowed them to amend this misstep without severe penalty. Discover implemented this initial attempt in a way that could be extended and changed based on evolving business goals and constraints, so they could pivot based on feedback from the sociotechnical system.
Their refined attempt to migrate pricing functionality was to implement a batch-based model in the cloud, with the resulting calculations sent back to the mainframe (since they only migrated part of the classic application to start). Everything will eventually be migrated from the mainframe, but starting with one part of system functionality is exactly what we want for an iterative, modular, strangler fig approach. We don’t have to migrate everything all at once, nor should we. Iteration with small modules sets us up for success and the ability to adapt to evolving conditions in a way that “big bang” releases or attempting multiple sweeping changes at once cannot.
Technology is only one part of this transformation with the strangler fig pattern. We can adopt new tooling and move functionality to a new environment, but the old ways of humans interacting with the technical part of the system likely won’t work anymore. Mental models are often sticky. As Discover noted, whoever owns the new process sees it through the lens of their old process—one ritual is being traded for another. The new principles we adopt when changing the system need incremental iteration too. At the core of our principles, however, must be a willingness to change—providing the socio part of the system with the psychological safety to make mistakes and try again.
To recap, we have five opportunities for maintaining flexibility and stimulating willingness to change—the final ingredient of our resilience potion when building and delivering systems: iteration, modularity, feature flags, preserving possibilities for refactoring, and the strangler fig pattern. Next in our journey through the SCE transformation is what we must perform once our systems are deployed in production: operating and observing.
Chapter Takeaways
When we build and deliver software, we are implementing intentions described during design, and our mental models almost certainly differ between the two phases. This is also the phase where we possess many opportunities to adapt as our organization, business model, market, or any other pertinent context changes.
Who owns application security (and resilience)? The transformation of database administration serves as a template for the shift in security needs; it migrated from a centralized, siloed gatekeeper to a decentralized paradigm where engineering teams adopt more ownership. We can similarly transform security.
There are four key opportunities to support critical functionality when building and delivering software: defining system goals and guidelines (prioritizing with the “airlock” approach); performing thoughtful code reviews; choosing “boring” technology to implement a design; and standardizing “raw materials” in software.
We can expand safety boundaries during this phase with a few opportunities: anticipating scale during development; automating security checks via CI/CD; standardizing patterns and tools; and performing dependency analysis and vulnerability prioritization (the latter in a quite contrary approach to status quo cybersecurity).
There are four opportunities for us to observe system interactions across space-time and make them more linear when building and delivering software and systems: adopting Configuration as Code; performing fault injection during development; crafting a thoughtful test strategy (prioritizing integration tests over unit tests to avoid “test theater”); and being especially cautious about the abstractions we create.
To foster feedback loops and learning during this phase, we can implement test automation; treat documentation as an imperative (not a nice-to-have), capturing both why and when; implement distributed tracing and logging; and refine how humans interact with our processes during this phase (keeping realistic behavioral constraints in mind).
To sustain resilience, we must adapt. During this phase, we can support this flexibility and willingness to change through five key opportunities: iteration to mimic evolution; modularity, a tool wielded by humanity over millennia for resilience; feature flags and dark launches for flexible change; preserving possibilities for refactoring through (programming language) typing; and pursuing the strangler fig pattern for incremental, elegant transformation.
1 Rust, like many languages, is memory safe. Unlike many languages, it is also thread safe. But the key difference between Rust and, say, Go—and why people associate Rust with “more secure”—is that Rust is more of a systems language, making it a more coherent replacement for C programs (which are not memory safe and therefore what people are often looking to replace).
2 Hui Xu et al., “Memory-Safety Challenge Considered Solved? An In-Depth Study with All Rust CVEs,” ACM Transactions on Software Engineering and Methodology (TOSEM) 31, no. 1 (2021): 1-25; Yechan Bae et al., “Rudra: Finding Memory Safety Bugs in Rust at the Ecosystem Scale,” Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (October 2021): 84-99.
3 Ding Yuan et al., “Simple Testing Can Prevent Most Critical Failures: An Analysis of Production Failures in Distributed {Data-Intensive} Systems,” 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14) (2014): 249-265.
4 Xun Zeng et al., “Urban Resilience for Urban Sustainability: Concepts, Dimensions, and Perspectives,” Sustainabilitys 14, no. 5 (2022): 2481.
5 The “D” sometimes stands for Deployment too.
6 Mojtaba Shahin et al., “Continuous Integration, Delivery and Deployment: A Systematic Review on Approaches, Tools, Challenges and Practices,” IEEE Access 5 (2017): 3909-3943.
7 Jez Humble, “Continuous Delivery Sounds Great, But Will It Work Here?” Communications of the ACM 61, no. 4 (2018): 34-39.
8 Emerson Mahoney et al., “Resilience-by-Design and Resilience-by-Intervention in Supply Chains for Remote and Indigenous Communities,” Nature Communications 13, no. 1 (2022): 1-5.
9 New versions can also give you new bugs, but the idea is that now we can fix them more quickly with automated CI/CD.
10 Humble, “Continuous Delivery Sounds Great, But Will It Work Here?” 34-39.
11 Michael Power, “The Risk Management of Nothing,” Accounting, Organizations and Society 34, no. 6-7 (2009): 849-855.
12 Jon Jenkins, “Velocity Culture (The Unmet Challenge in Ops)”, O’Reilly Velocity Conference (2011).
13 Humble, “Continuous Delivery Sounds Great, But Will It Work Here?” 34-39.
14 Thanks to Senior Principal Engineer Mark Teodoro for this fabulous definition.
15 It’s a bit anachronistic today (although Microsoft still uses it for tagging vulnerabilities), but roughly refers to an attack that does not require human interaction to replicate itself across a network. In modern times, that network can be the internet itself. Since we’re trying to avoid infosec jargon as part of the SCE transformation, this factor can be referred to as “scalable” rather than “wormable.”
16 Nir Fresco and Giuseppe Primiero, “Miscomputation,” Philosophy & Technology 26 (2013): 253-272.
17 Tianyin Xu and Yuanyuan Zhou, “Systems Approaches to Tackling Configuration Errors: A Survey,” ACM Computing Surveys (CSUR) 47, no. 4 (2015): 1-41.
18 Xu, “Systems Approaches to Tackling Configuration Errors,” 1-41.
19 Zuoning Yin et al., “An Empirical Study on Configuration Errors in Commercial and Open Source Systems,” Proceedings of the 23rd ACM Symposium on Operating Systems Principles (Cascais, Portugal: October 23-26, 2011): 159-172.
20 Austin Parker et al., “Chapter 4: Best Practices for Instrumentation”, in Distributed Tracing in Practice: Instrumenting, Analyzing, and Debugging Microservices (Sebastopol, CA: O’Reilly, 2020).
21 Peter Alvaro et al., “Lineage-Driven Fault Injection,” Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (2015): 331-346.
22 Jonas Wagner et al., “High System-Code Security with Low Overhead,” 2015 IEEE Symposium on Security and Privacy (May 2015): 866-879.
23 Leslie Lamport, “Time, Clocks, and the Ordering of Events in a Distributed System,” Concurrency: The Works of Leslie Lamport (2019): 179-196.
24 Justin Sheehy, “There Is No Now,” Communications of the ACM 58, no. 5 (2015): 36-41.
25 Ding Yuan, “Simple Testing Can Prevent Most Critical Failures: An Analysis of Production Failures in Distributed Data-Intensive Systems,” Proceedings of the 11th USENIX Conference on Operating Systems Design and Implementation, 249-265.
26 Caitie McCaffrey, “The Verification of a Distributed System,” Communications of the ACM 59, no. 2 (2016): 52-55.
27 Tse-Hsun Peter Chen et al., “Analytics-Driven Load Testing: An Industrial Experience Report on Load Testing of Large-Scale Systems,” 2017 IEEE/ACM 39th International Conference on Software Engineering: Software Engineering in Practice Track (ICSE-SEIP) (May 2017): 243-252.
28 Bart Smaalders, “Performance Anti-Patterns: Want Your Apps to Run Faster? Here’s What Not to Do,” Queue 4, no. 1 (2006): 44-50.
29 McCaffrey, “The Verification of a Distributed System,” 52-55 (emphasis ours).
30 Laura Inozemtseva and Reid Holmes, “Coverage Is Not Strongly Correlated with Test Suite Effectiveness,” Proceedings of the 36th International Conference on Software Engineering (May 2014): 435-445.
31 Andrew Ruef, “Tools and Experiments for Software Security” (doctoral diss., University of Maryland, 2018).
32 George Klees et al., “Evaluating Fuzz Testing,” Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (October 2018): 2123-2138.
33 Keith M. Marzilli Ericson and Andreas Fuster, “The Endowment Effect,” Annual Review of Economics 6 (August 2014): 555-579.
34 Nicholas C. Barberis, “Thirty Years of Prospect Theory in Economics: A Review and Assessment,” Journal of Economic Perspectives 27, no. 1 (2013): 173-196.
35 Benjamin H. Sigelman et al., “Dapper, a Large-Scale Distributed Systems Tracing Infrastructure” (Google, Inc., 2010).
36 Zhenhao Li et al., “Where Shall We Log? Studying and Suggesting Logging Locations in Code Blocks,” Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering (December 2020): 361-372.
37 Matheus Palhares Viana et al., “Modularity and Robustness of Bone Networks,” Molecular Biosystems 5, no. 3 (2009): 255-261.
38 Simon A. Levin, Fragile Dominion: Complexity and the Commons (United Kingdom: Basic Books, 2000).
39 Chris Beagan and Susan Dolan, “Integrating Components of Resilient Systems into Cultural Landscape Management Practices,” Change Over Time 5, no. 2 (2015): 180-199.
40 Shuanglei Wu et al., “The Development of Ancient Chinese Agricultural and Water Technology from 8000 BC to 1911 AD,” Palgrave Communications 5, no. 77 (2019): 1-16.
41 Ali Kharrazi et al., “Redundancy, Diversity, and Modularity in Network Resilience: Applications for International Trade and Implications for Public Policy,” Current Research in Environmental Sustainability 2, no. 100006 (2020).
42 Erik Andersson et al., “Urban Climate Resilience Through Hybrid Infrastructure,” Current Opinion in Environmental Sustainability 55, no. 101158 (2022).
43 Usually, it’s only on the core business services where there is more than one right answer and there are multiple strategies for coming to that answer if there is duplication.
44 As one of our technical reviewers noted, “The CALM theorem and related work that seeks to avoid coordination whenever possible is another great way of making eventual consistency easier to understand.” Alas, it is not a mainstream idea at the time of this writing.
45 Michael J. Fischer et al., “Impossibility of Distributed Consensus with One Faulty Process,” Journal of the ACM (JACM) 32, no. 2 (1985): 374-382; M. Pease et al., “Reaching Agreement in the Presence of Faults,” Journal of the ACM (JACM) 27, no. 2 (1980): 228-234; Cynthia Dwork et al., “Consensus in the Presence of Partial Synchrony,” Journal of the ACM (JACM) 35, no. 2 (1988): 288-323.
46 Luca Cardelli, “Type Systems,” ACM Computing Surveys (CSUR) 28, no. 1 (1996): 263-264.
47 Computers have multiple types of numbers and it takes complicated type theory to correctly apply mathematical operations to numbers of varying types. What does it mean to multiply an 8-bit integer with an imaginary number? That is complicated. This example glosses over this complication.
Get Security Chaos Engineering now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

