LDA is a topic model that infers topics from a collection of text documents. LDA can be thought of as a clustering algorithm where topics correspond to cluster centers, and documents correspond to examples (rows) in a dataset. Topics and documents both exist in a feature space, where feature vectors are vectors of word counts (bags of words). Instead of estimating a clustering using a traditional distance, LDA uses a function based on a statistical model of how text documents are generated (see in Figure 3):
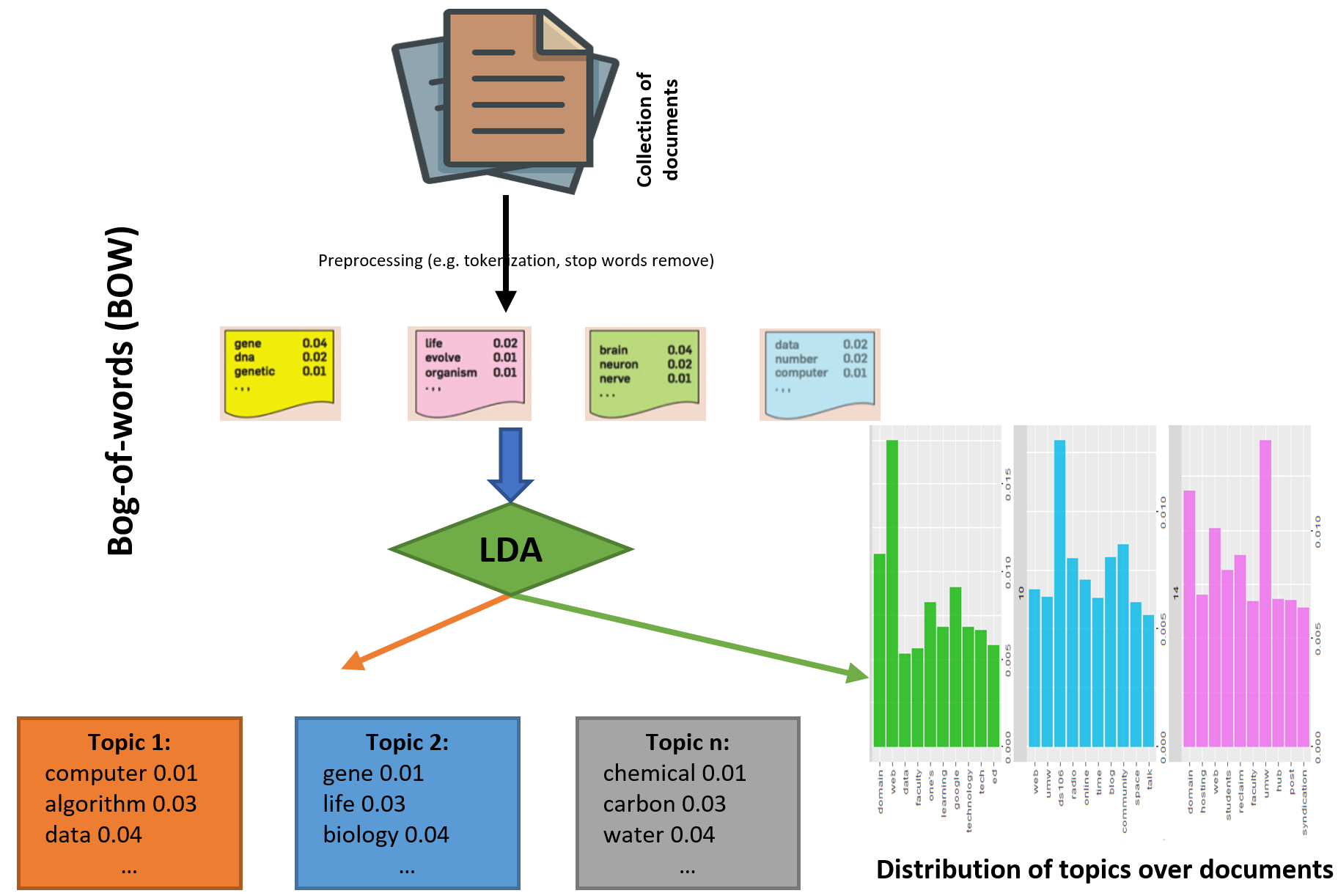
Figure 3: Working principle of LDA algorithms on a collection of documents
Particularly, we would like to ...

