How It Works
This solution uses a query that performs the following:
• selects all columns
• counts all rows
• groups all of the rows in the Duplicates table by matching rows
• excludes the rows that have no duplicates
Note: You must include all of the columns in your table in the GROUP BY clause to
find exact duplicates.
Expanding Hierarchical Data in a Table
Problem
You want to generate an output column that shows a hierarchical relationship among
rows in a table.
Background Information
There is one input table, called Employees, that contains the following data:
data Employees;
input ID $ LastName $ FirstName $ Supervisor $;
datalines;
1001 Smith John 1002
1002 Johnson Mary None
1003 Reed Sam None
1004 Davis Karen 1003
1005 Thompson Jennifer 1002
1006 Peterson George 1002
1007 Jones Sue 1003
1008 Murphy Janice 1003
1009 Garcia Joe 1002
;
proc print data=Employees;
title 'Sample Data for Expanding a Hierarchy';
run;
Expanding Hierarchical Data in a Table 189
Output 6.11 Sample Input Table for Expanding a Hierarchy
You want to create output that shows the full name and ID number of each employee
who has a supervisor, along with the full name and ID number of that employee's
supervisor.
Solution
Use the following PROC SQL code to expand the data:
proc sql;
title 'Expanded Employee and Supervisor Data';
select A.ID label="Employee ID",
trim(A.FirstName)||' '||A.LastName label="Employee Name",
B.ID label="Supervisor ID",
trim(B.FirstName)||' '||B.LastName label="Supervisor Name"
from Employees A, Employees B
where A.Supervisor=B.ID and A.Supervisor is not missing;
190 Chapter 6 • Practical Problem-Solving with PROC SQL
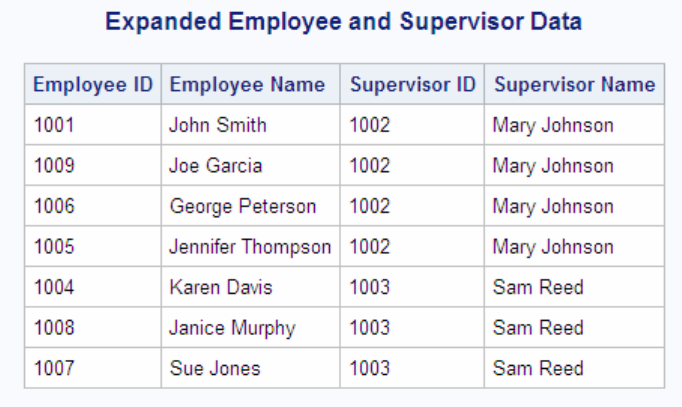
Output 6.12 PROC SQL Output for Expanding a Hierarchy
How It Works
This solution uses a self-join (reflexive join) to match employees and their supervisors.
The SELECT clause assigns aliases of A and B to two instances of the same table and
retrieves data from each instance. From instance A, the SELECT clause performs the
following:
• selects the ID column and assigns it a label of Employee ID
• selects and concatenates the FirstName and LastName columns into one output
column and assigns it a label of Employee Name
From instance B, the SELECT clause performs the following:
• selects the ID column and assigns it a label of Supervisor ID
• selects and concatenates the FirstName and LastName columns into one output
column and assigns it a label of Supervisor Name
In both concatenations, the SELECT clause uses the TRIM function to remove trailing
spaces from the data in the FirstName column, and then concatenates the data with a
single space and the data in the LastName column to produce a single character value for
each full name.
trim(A.FirstName)||' '||A.LastName label="Employee Name"
When PROC SQL applies the WHERE clause, the two table instances are joined. The
WHERE clause conditions restrict the output to only those rows in table A that have a
supervisor ID that matches an employee ID in table B. This operation provides a
supervisor ID and full name for each employee in the original table, except for those
who do not have a supervisor.
where A.Supervisor=B.ID and A.Supervisor is not missing;
Note: Although there are no missing values in the Employees table, you should check
for and exclude missing values from your results to avoid unexpected results. For
example, if there were an employee with a blank supervisor ID number and an
employee with a blank ID, then they would produce an erroneous match in the
results.
Expanding Hierarchical Data in a Table 191
Get SAS 9.4 SQL Procedure User's Guide, Third Edition, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

