Kapitel 1. Einführung in RESTful Web APIs
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Nutze die globale Reichweite, um Probleme zu lösen, an die du nicht gedacht hast, für Menschen, die du noch nie getroffen hast.
Das Prinzip der RESTful Web APIs
Im Vorwort habe ich auf den vielsagenden Titel dieses Buches hingewiesen. Hier erfahren wir, was hinter RESTful Web APIs steckt und warum ich es für wichtig halte, diese Art der Namensgebung zu verwenden und die Bedeutung dahinter zu verstehen.
Zunächst werde ich ein wenig darüber sprechen, was der Begriff "RESTful Web APIs" bedeutet und warum ich mich für diesen Begriff entschieden habe, der wie ein Modewort klingt. Als Nächstes werden wir uns mit der Technologie beschäftigen, die meiner Meinung nach die Grundlage für stabile und zuverlässige Dienste im offenen Web bildet: Hypermedia. Zum Schluss gibt es einen kurzen Abschnitt, in dem wir eine Reihe gemeinsamer Prinzipien für die Implementierung und Nutzung von REST-basierten Serviceschnittstellen untersuchen - etwas, das die Auswahl und Beschreibung der Muster und Rezepte in diesem Buch leitet.
Hypermedia-basierte Implementierungen stützen sich auf drei Schlüsselelemente: Nachrichten, Aktionen und Vokabularien (siehe Abbildung 1-1). In Hypermedia-basierten Lösungen werden Nachrichten in gängigen Formaten wie HTML, Collection+JSON und SIREN übermittelt. Diese Nachrichten enthalten Inhalte, die auf einem gemeinsamen Domänenvokabular basieren, z. B. PSD2 für Banken, ACORD für Versicherungen oder FIHR für Gesundheitsinformationen. Und dieselben Nachrichten enthalten klar definierte Aktionen wie save, share, approve, und so weiter.
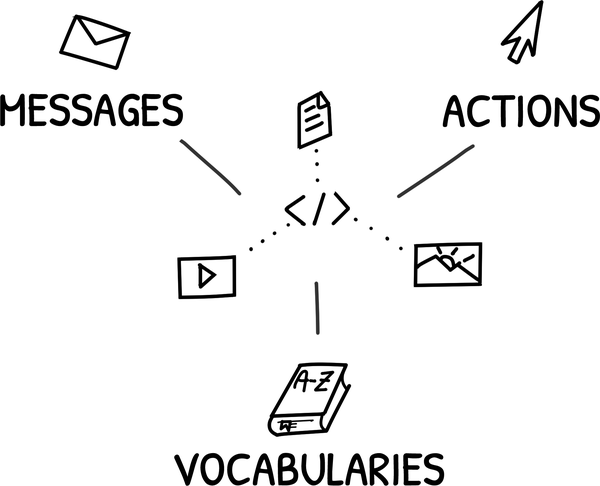
Abbildung 1-1. Elemente von Hypermedia
Mit diesen drei Konzepten hoffe ich, dich zum Nachdenken darüber anzuregen, wie wir heute Dienste über HTTP aufbauen und nutzen und wie wir mit einer leicht veränderten Perspektive und Herangehensweise das Design und die Implementierung dieser Dienste auf eine Weise aktualisieren können, die ihre Nutzbarkeit verbessert, die Kosten für die Erstellung und den Zugang zu ihnen senkt und die Fähigkeit von Dienstanbietern und -nutzern erhöht, lebensfähige API-gestützte Unternehmen aufzubauen und aufrechtzuerhalten - selbst wenn einige der Dienste, auf die wir angewiesen sind, unzuverlässig oder nicht verfügbar sind.
Zunächst erkunden wir die Bedeutung hinter dem Titel des Buches.
Was sind RESTful Web APIs?
Ich verwende den Begriff "RESTful Web APIs" schon seit mehreren Jahren in Artikeln, Präsentationen und Schulungsmaterialien. Mein Kollege Leonard Richardson und ich haben 2013 ein ganzes Buch zu diesem Thema geschrieben. Manchmal stiftet der Begriff Verwirrung oder sogar Skepsis, aber fast immer weckt er Neugierde. Was haben diese drei Wörter miteinander zu tun? Was bedeutet die Kombination dieser drei Begriffe als Ganzes? Um diese Fragen zu beantworten, kann es hilfreich sein, sich einen Moment Zeit zu nehmen, um die Bedeutung der einzelnen Begriffe zu klären.
In diesem Abschnitt werden wir uns also umsehen:
- Fielding's REST
-
Der Architekturstil, der die Skalierbarkeit der Interaktionen zwischen den Komponenten, die Allgemeinheit der Schnittstellen und die unabhängige Bereitstellung der Komponenten betont.
- Das Netz von Tim Berners-Lee
-
Das World Wide Web wurde als universelles, verlinktes Informationssystem konzipiert, bei dem Allgemeinheit und Übertragbarkeit an erster Stelle stehen.
- Alan Kays extrem späte Bindung
-
Die Designästhetik, die es dir ermöglicht, Systeme zu bauen, die du sicher verändern kannst, während sie noch in Betrieb sind.
Fielding's REST
Bereits 1998 hielt Roy T. Fielding einen Vortrag bei Microsoft, in dem er sein Konzept des Representational State Transfer (oder REST, wie es heute genannt wird) erläuterte. In diesem Vortrag und in seiner Dissertation, die zwei Jahre später folgte ("Architectural Styles and the Design of Network-based Software Architectures"), vertrat Fielding die Idee, dass es eine einzigartige Reihe von Softwarearchitekturen für netzwerkbasierte Implementierungen gibt und dass einer der sechs von ihm beschriebenen Stile - REST - besonders für das World Wide Web geeignet ist.
Tipp
Vor Jahren lernte ich den Satz: "Oft zitiert, nie gelesen". Diese bissige Bemerkung scheint ziemlich gut auf Fieldings Dissertation aus dem Jahr 2000 zuzutreffen. Ich empfehle allen, die webbasierte Software erstellen oder pflegen, sich die Zeit zu nehmen, seine Dissertation zu lesen - und zwar nicht nur das berüchtigte Kapitel 5, "Representational State Transfer". Seine Kategorisierung allgemeiner Stile vor über 20 Jahren beschreibt korrekt die Stile, die später als gRPC, GraphQL, ereignisgesteuert, Container und andere bekannt wurden.
Fieldings Methode zur Ermittlung wünschenswerter Eigenschaften auf Systemebene (wie Verfügbarkeit, Leistung, Einfachheit, Änderbarkeit usw.) sowie einer empfohlenen Reihe von Einschränkungen (Client-Server, Zustandslosigkeit, Cache-Fähigkeit usw.), die zur Erreichung dieser Eigenschaften ausgewählt wurden, ist auch heute noch, mehr als zwei Jahrzehnte später, ein wertvoller Weg, um über Software nachzudenken und sie zu entwickeln, die über einen längeren Zeitraum stabil und funktionsfähig sein muss.
Ein guter Weg, Fieldings REST-Stil zusammenzufassen, kommt aus der Dissertation selbst:
REST bietet eine Reihe von architektonischen Einschränkungen, die, wenn sie als Ganzes angewandt werden, die Skalierbarkeit von Komponenteninteraktionen, die Allgemeinheit von Schnittstellen, die unabhängige Bereitstellung von Komponenten und zwischengeschaltete Komponenten betonen, um die Interaktionslatenz zu reduzieren, Sicherheit zu erzwingen und Legacy-Systeme zu kapseln.
Die in diesem Buch enthaltenen Rezepte wurden so ausgewählt, dass sie zum Entwurf und Bau von Dienstleistungen führen, die viele von Fieldings "architektonischen Eigenschaften von zentralem Interesse" aufweisen . Im Folgenden findest du eine Liste der architektonischen Eigenschaften von Fielding sowie eine kurze Zusammenfassung ihrer Verwendung und Bedeutung:
- Leistung
-
Die Leistung einer netzwerkbasierten Lösung wird durch die physischen Grenzen des Netzwerks (Durchsatz, Bandbreite, Overhead usw.) und die von den Nutzern wahrgenommene Leistung begrenzt, z. B. durch die Latenzzeit von Anfragen und die Möglichkeit, die Bearbeitungszeit durch parallele Anfragen zu verkürzen.
- Skalierbarkeit
-
Die Fähigkeit der Architektur, eine große Anzahl von Komponenten oder Interaktionen zwischen den Komponenten innerhalb einer aktiven Konfiguration zu unterstützen.
- Einfachheit
-
Das wichtigste Mittel, um Einfachheit in deine Lösungen zu bringen, ist die Anwendung des Prinzips der Funktionstrennung auf die Zuweisung von Funktionen innerhalb von Komponenten und das Prinzip der Allgemeinheit von Schnittstellen.
- Modifizierbarkeit
-
Die Leichtigkeit, mit der eine Anwendungsarchitektur durch Evolvierbarkeit, Erweiterbarkeit, Anpassbarkeit, Konfigurierbarkeit und Wiederverwendbarkeit verändert werden kann.
- Sichtbarkeit
-
Die Fähigkeit einer Komponente, die Interaktion zwischen zwei anderen Komponenten zu überwachen oder zu vermitteln, indem sie Dinge wie Caches, Proxys und andere Vermittler einsetzt.
- Tragbarkeit
-
Die Fähigkeit, dieselbe Software in verschiedenen Umgebungen auszuführen, einschließlich der Möglichkeit, Code (z. B. JavaScript) und Daten sicher zwischen verschiedenen Laufzeitsystemen (z. B. Linux, Windows, macOS usw.) zu verschieben
- Verlässlichkeit
-
Das Ausmaß, in dem eine Implementierung aufgrund des Ausfalls einer einzelnen Komponente (Maschine oder Dienst) innerhalb des Netzwerks für Ausfälle auf Systemebene anfällig ist.
Der Hauptgrund dafür, dass wir viele von Fieldings Architekturprinzipien in diesen Rezepten verwenden, ist, dass sie zu Implementierungen führen, die skalierbar sind und über weite Strecken von Raum und Zeit sicher verändert werden können.
Das Web von Tim Berners-Lee
Fieldings Arbeit stützt sich auf die Bemühungen eines anderen Pioniers der Online-Welt, Sir Tim Berners-Lee. Mehr als ein Jahrzehnt bevor Fielding seine Dissertation schrieb, verfasste Berners-Lee ein 16-seitiges Dokument mit dem Titel "Information Management: A Proposal" (1989 und 1990). Darin schlug er eine (damals) einzigartige Lösung zur Verbesserung der Speicherung und Abfrage von Informationen für das Physiklabor CERN vor, in dem er arbeitete. Berners-Lee nannte diese Idee das World Wide Web (siehe Abbildung 1-2).
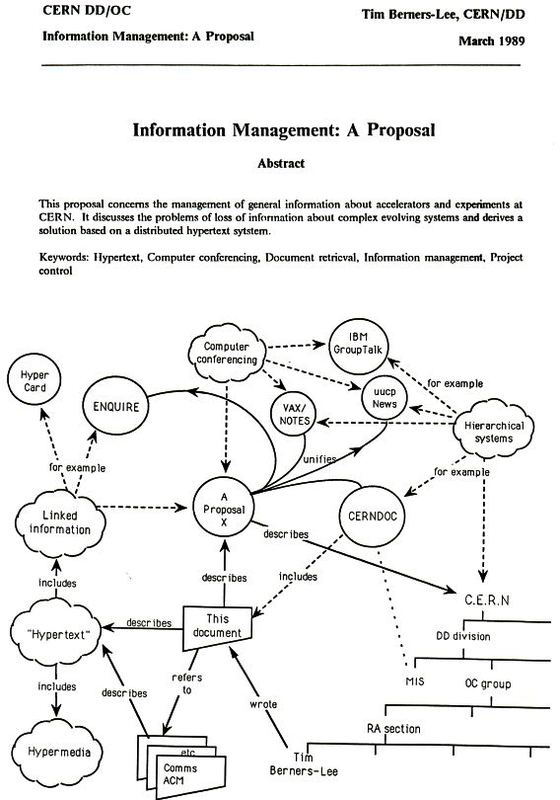
Abbildung 1-2. Berners-Lee's World Wide Web Vorschlag (1989)
Das World Wide Web (WWW) geht auf Ted Nelson zurück, der den Begriff Hypertext geprägt hat. Es verbindet zusammenhängende Dokumente über Links und später über Formulare, mit denen die Benutzer/innen aufgefordert werden können, Daten einzugeben, die dann an Server in der ganzen Welt gesendet werden. Diese Server konnten schnell und einfach mit kostenloser Software eingerichtet werden, die auf gewöhnlichen Desktop-Computern lief. Passenderweise folgte die Entwicklung des WWW der "Rule of Least Power", die besagt, dass wir die am wenigsten leistungsfähige Technologie für die jeweilige Aufgabe verwenden sollten. Mit anderen Worten: Halte die Lösung so einfach wie möglich (und nicht einfacher). Dies wurde später in einem gleichnamigen W3C-Dokument festgeschrieben. Dies schuf eine niedrige Einstiegshürde für alle, die sich der WWW-Gemeinschaft anschließen wollten, und trug dazu bei, dass sie sich in den 1990er und frühen 2000er Jahren explosionsartig verbreitete.
Im WWW kann jedes Dokument so bearbeitet werden, dass es auf jedes andere Dokument im Netz verweist. Dies war möglich, ohne dass an beiden Enden des Links besondere Vorkehrungen getroffen werden mussten. Im Grunde genommen konnten die Menschen ihre eigenen Verbindungen herstellen, ihre eigenen Lieblingsdokumente sammeln und ihre eigenen Inhalte verfassen, ohne dass sie dafür die Erlaubnis von jemand anderem brauchten. All diese Inhalte wurden durch die Verwendung von Links und Formularen innerhalb der Seiten ermöglicht, um einzigartige Pfade und Erfahrungen zu schaffen - von denen die ursprünglichen Autoren der Dokumente (die, die verbunden wurden) nichts wussten.
Diese beiden Aspekte des WWW (die Regel der geringsten Macht und die Freiheit, eigene Verbindungen herzustellen) werden wir in den Rezepten in diesem Buch verwenden.
Alan Kays extreme Spätbindungen
Ein weiterer wichtiger Aspekt bei der Entwicklung zuverlässiger, belastbarer Dienste, die "im Web leben" können, stammt von dem amerikanischen Informatiker Alan Kay. Ihm wird oft zugeschrieben, dass er in den 1990er Jahren den Begriff der objektorientierten Programmierung populär gemacht hat.
2019 schrieb Curtis Poe einen Blogbeitrag, in dem er Kays Erklärung von OOP untersuchte und unter anderem darauf hinwies: "Das extreme Late-Binding ist wichtig, weil Kay argumentiert, dass es dir erlaubt, dich nicht zu früh auf den einzig wahren Weg zur Lösung eines Problems festzulegen (und es somit einfacher macht, diese Entscheidungen zu ändern), aber es kann dir auch erlauben, Systeme zu bauen, die du ändern kannst , während sie noch laufen!" (Hervorhebung von Poe).
Tipp
Eine direktere Untersuchung der Verbindungen zwischen Roy Fieldings REST und Alan Kays OOP findest du in meinem Artikel aus dem Jahr 2015, "Die Vision von Kay und Fielding": Wachsende Systeme, dieJahrzehnte überdauern".
Genau wie Kays Ansicht über die Programmierung mit OOP ist auch das Web - das Internet selbst - immer in Betrieb. Alle Dienste, die wir auf einem mit dem Internet verbundenen Rechner installieren, verändern das System, während es läuft. Das müssen wir im Hinterkopf behalten, wenn wir unsere Dienste für das Internet entwickeln.
Der Gedanke, dass die extreme Spätbindung es ermöglicht, Systeme zu verändern, während sie noch laufen, ist der Leitgedanke, den wir für die Rezepte in diesem Buch verwenden werden.
Also, um diesen Abschnitt zusammenzufassen, werden wir
-
Die Fielding'schen Konzepte der Systemarchitektur nutzen, um Systeme sicher zu skalieren und im Laufe der Zeit zu verändern
-
Nutzung der "Rule of Least Power" von Berners-Lee und des Ethos, die Einstiegshürde zu senken, um es jedem leicht zu machen, sich mit jedem anderen zu verbinden
-
Ausnutzung der extremen Spätbindung von Kay, um es einfacher zu machen, Teile des Systems zu ändern, während es noch läuft
Eine wichtige Technik, mit der wir diese Ziele erreichen können, heißt Hypermedia.
Warum Hypermedia?
Meiner Erfahrung nach steht das Konzept der Hypermedia am Schnittpunkt einer Reihe wichtiger Werkzeuge und Technologien, die unsere Informationsgesellschaft positiv geprägt haben. Und ich denke, es kann uns dabei helfen, die Zugänglichkeit und Nutzbarkeit von Diensten im Web im Allgemeinen zu verbessern.
In diesem Abschnitt werden wir erkunden:
-
Ein Jahrhundert der Hypermedia
-
Der Wert von Nachrichten
-
Die Macht des Vokabulars
-
Richardsons magische Fäden
Die Geschichte von Hypermedia reicht fast 100 Jahre zurück und taucht in Schriften des 20. Jahrhunderts über Psychologie, Mensch-Computer-Interaktion und Informationstheorie auf. Es ist die Grundlage für Berners-Lees World Wide Web (siehe "Das Web von Tim Berners-Lee") und es kann auch unser "Web der APIs" antreiben. Deshalb soll es hier etwas ausführlicher behandelt werden. Definieren wir zunächst Hypermedia und den Begriff der hypermedia-gesteuerten Anwendungen.
Hypermedia: Eine Definition
Ted Nelson wird zugeschrieben, die Begriffe Hypertext und Hypermedia bereits in den 1950er Jahren geprägt zu haben. Er verwendete diese Begriffe 1965 in seinem ACM-Artikel "Complex Information Processing: A File Structure for the Complex, the Changing and the Indeterminate". Laut Tomas Isakowitz (2008) besteht ein Hypertextsystem in seiner ursprünglichen Form "aus Knoten, die Informationen enthalten, und aus Links, die Beziehungen zwischen den Knoten darstellen." Hypermedia-Systeme konzentrieren sich auf die Verbindungen zwischen den Elementen eines Systems.
Im Wesentlichen bietet Hypermedia die Möglichkeit, einzelne Knoten, auch Ressourcen genannt, wie z. B. Dokumente, Bilder, Dienste und sogar Textausschnitte innerhalb eines Dokuments, miteinander zu verbinden. Im Netzwerk wird diese Verbindung über Universal Resource Identifiers (URIs) hergestellt. Wenn die Verbindung die Möglichkeit bietet, Daten weiterzugeben, werden diese Links in Form von Formularen dargestellt, die menschliche Benutzer oder Maschinen mit Skriptsprache zur Eingabe auffordern können. HTML zum Beispiel unterstützt Links und Formulare durch Tags wie <A>, <IMG>, <FORM> und andere. Es gibt mehrere Formate, die Hypermedia-Links und -Formulare unterstützen.
Diese Hypermedia-Elemente können auch als Teil der Anfrageergebnisse zurückgegeben werden. Die Fähigkeit, Links und Formulare in den Antworten bereitzustellen, gibt den Client-Anwendungen die Möglichkeit, diese Hypermedia-Elemente auszuwählen und zu aktivieren, um die Anwendung auf einem Pfad voranzubringen. So ist es möglich, eine netzwerkbasierte Lösung zu erstellen, die aus einer Reihe von Links und Formularen (zusammen mit zurückgegebenen Daten) besteht, die, wenn sie befolgt werden, eine Lösung für das gestellte Problem bieten (z. B. Ergebnisse berechnen, Daten abrufen, aktualisieren und an einem entfernten Ort speichern usw.).
Links und Formulare bieten eine Vielzahl von Schnittstellen (z. B. die Verwendung von Hypermedia-Dokumenten über HTTP), die Hypermedia-basierte Anwendungen ermöglichen. Hypermedia-basierte Client-Anwendungen wie der HTML-Browser können diese Allgemeingültigkeit nutzen, um eine breite Palette neuer Anwendungen zu unterstützen, ohne dass ihr Quellcode geändert oder aktualisiert werden muss. Wir navigieren einfach von einer Lösung zur nächsten, indem wir Links folgen (oder sie manuell eingeben), und verwenden dieselbe installierte Client-Anwendung, um die Nachrichten zu lesen, unsere Aufgabenliste zu aktualisieren, ein Online-Spiel zu spielen, usw.
Die Rezepte in diesem Buch nutzen die Vorteile von Hypermedia-basierten Designs, um nicht nur menschengesteuerte Client-Anwendungen wie HTML-Browser, sondern auch maschinengesteuerte Anwendungen zu betreiben. Das ist besonders hilfreich für Clients, die auf APIs angewiesen sind, um auf Dienste im Netzwerk zuzugreifen. In Kapitel 4 stelle ich eine Kommandozeilenanwendung vor, mit der du schnell hypermediale Client-Anwendungen skripten kannst, ohne die installierte Codebasis der Client-Anwendung zu verändern (siehe Anhang D).
Ein Jahrhundert der Hypermedia
Die Idee, Menschen über Informationen zu verbinden, gibt es schon lange. In den 1930er Jahren stellte sich der Belgier Paul Otlet eine Maschine vor, mit der Menschen eine individuelle Mischung aus Audio-, Video- und Textinhalten suchen und auswählen und die Ergebnisse von überall aus ansehen können. Es dauerte fast hundert Jahre, aber im 21. Jahrhundert war die Streaming-Revolution endlich da.
Paul Otlet
Otlets Vorstellung von 1940 (siehe Abbildung 1-3), wie seine Heimcomputer mit verschiedenen Nachrichten-, Unterhaltungs- und Informationsquellen verbunden werden könnten - etwas, das er das "World Wide Network" nannte - sieht sehr danach aus, wie sich auch Ted Nelson (der später in diesem Abschnitt vorgestellt wird) und Tim Berners-Lee (siehe "Das Web von Tim Berners-Lee") die vernetzte Welt vorstellen würden.
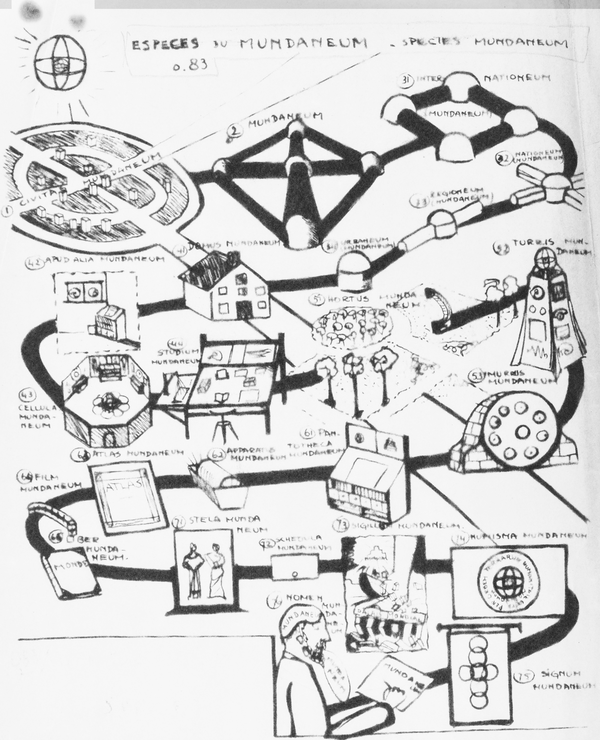
Abbildung 1-3. Otlet's World Wide Network (1940)
Vannevar Bush
Während seiner Arbeit als Manager für das Manhattan-Projekt stellte Vannevar Bush fest, dass Teams von Einzelpersonen, die zusammenkamen, um Probleme in einem kreativen Umfeld zu lösen, sich oft gegenseitig mit Ideen überhäuften, von einer Forschungsidee zur nächsten sprangen und neue Verbindungen zwischen wissenschaftlichen Arbeiten herstellten. Er schrieb seine Beobachtungen in dem Artikel "As We May Think" (Wie wir denken können) im Juli 1945 auf auf und beschrieb einen Informationsarbeitsplatz ähnlich dem von Otlet, der mit Mikrofiches und einem am Kopf des Lesers befestigten "Zeigegerät" arbeitete.
Douglas Engelbart
Die Lektüre dieses Artikels veranlasste einen jungen Offizier, der in Ostasien diente, darüber nachzudenken, wie er Bushs Workstation Wirklichkeit werden lassen könnte. Es dauerte fast 20 Jahre, aber 1968 führte dieser Offizier, Douglas Engelbart, eine Demonstration dessen vor, woran er und sein Team auf gearbeitet hatten, was heute als "Mutter aller Demos" bekannt ist . Bei dieser Veranstaltung wurde der damals noch unbekannte "interaktive Computer" vorgestellt, mit dem der Bediener mit einem Zeigegerät Text markieren und einem "Link" folgen konnte. Engelbart musste den "Mauszeiger" erfinden, damit seine Demo funktionierte.
Ted Nelson
Ein Zeitgenosse von Engelbart, Ted Nelson, schrieb bereits 1965 über die Möglichkeiten des Personal Computings und verwendete dabei von ihm geprägte Begriffe wie Hyperlinks, Hypertext, Hyperdaten und Hypermedia. Im Jahr 1974 entwarf er in seinem Buch Computer Lib/Dream Machines (Tempus Books) eine Welt, die von persönlichen elektronischen Geräten angetrieben wird, die über das Internet miteinander verbunden sind. Zur gleichen Zeit hatte Alan Kay (siehe "Alan Kay's Extreme Late Binding") das Dynabook-Gerät beschrieben, das den heutigen kleinen Laptops und Tablets sehr ähnlich sah.
All diese frühen Versuche, Informationen zu verknüpfen und gemeinsam zu nutzen, hatten eine zentrale Idee: Die Verbindungen zwischen den Dingen würden Menschen befähigen und Kreativität und Innovation fördern. In den späten 1980er Jahren hatte Tim Berners-Lee ein erfolgreiches System entwickelt, das alle Ideen seiner Vorgänger in sich vereinte. Berners-Lee's WWW machte die Verknüpfung von Seiten mit Dokumenten sicher, einfach und skalierbar.
Genau darum geht es bei der Nutzung von Service-APIs - die Verbindungen zwischen Dingen zu definieren, um neue Lösungen zu ermöglichen.
James J. Gibson
Etwa zur gleichen Zeit, als Ted Nelson den Begriff Hypertext in die Welt einführte, schuf auch eine andere Person Begriffe. Der Psychologe James J. Gibson schrieb 1966 in seinem Buch The Senses Considered as Perceptual Systems (Houghton-Mifflin) darüber, wie Menschen und andere Tiere die Welt um sich herum wahrnehmen und mit ihr interagieren, und schuf den Begriff Affordanz. Von Gibson:
[Die Erleichterungen der Umwelt sind das, was sie dem Tier bietet, was sie ihm zur Verfügung stellt oder liefert.
Gibsons Affordanzen unterstützen die Interaktion zwischen Tieren und der Umwelt auf die gleiche Weise, wie Nelsons Hyperlinks es den Menschen ermöglichen, mit Dokumenten im Netz zu interagieren. Ein Zeitgenosse von Gibson, Donald Norman, machte den Begriff Affordanz in seinem 1988 erschienenen Buch The Design of Everyday Things (Doubleday) bekannt. Norman, der als Großvater der Human-Computer Interaction (HCI)-Bewegung gilt, verwendete den Begriff, um Wege aufzuzeigen, wie Software-Designer die Interaktion zwischen Mensch und Computer verstehen und fördern können. Das meiste, was wir über die Benutzerfreundlichkeit von Software wissen, stammt aus der Arbeit von Norman und anderen auf diesem Gebiet.
Hypermedia hängt von Affordances ab. Hypermedia-Elemente (Links und Formulare) sind die Dinge innerhalb einer Web-Antwort, die zusätzliche Aktionen ermöglichen, wie z. B. die Suche nach vorhandenen Dokumenten, die Übermittlung von Daten an einen Server zur Speicherung usw. Gibson und Norman stehen für die psychologischen und sozialen Aspekte der Computerinteraktion, auf die wir uns in unseren Rezepten stützen werden. Aus diesem Grund wirst du in vielen Rezepten Links und Formulare finden, die es ermöglichen, den Zustand der Anwendung über mehrereDienste hinweg zu ändern.
Der Wert von Botschaften
Wie wir weiter oben in diesem Kapitel gesehen haben, betrachtete Alan Kay die objektorientierte Programmierung als ein Konzept, das in der Weitergabe von Nachrichten wurzelt (siehe "Alan Kays Extreme Late Binding"). Tim Berners-Lee vertrat denselben Standpunkt, als er 1992 das nachrichtenorientierte Hypertext Transfer Protocol (HTTP) vorstellte und im Jahr darauf das Nachrichtenformat der Hypertext Markup Language (HTML) mitdefinierte.
Mit der Entwicklung eines Protokolls und Formats für die Übermittlung allgemeiner Nachrichten (statt für die Übermittlung lokalisierter Objekte oder Funktionen) wurde die Zukunft des Webs festgelegt. Dieser nachrichtenzentrierte Ansatz lässt sich leichter einschränken, im Laufe der Zeit leichter ändern und bietet eine zuverlässigere Plattform für künftige Erweiterungen, z. B. völlig neue Formate (XML, JSON usw.) und eine veränderte Nutzung des Protokolls (Dokumente, Websites, Webanwendungen usw.).
Nachrichtenzentrierte Lösungen im Internet haben auch Parallelen in der physischen Welt. Insektenkolonien wie Termiten und Ameisen, die dafür bekannt sind, dass sie keine Hierarchie oder Führung haben, kommunizieren über ein Pheromon-basiertes Nachrichtensystem. Ungefähr zur gleichen Zeit, als Nelson über Hypermedia und Gibson über Affordances sprach, der amerikanische Biologe und Naturforscher E. O. Wilson (zusammen mit William Bossert) über Ameisenkolonien und ihre Nutzung von Pheromonen als Mittel zur Steuerung großer, komplexer Gemeinschaften geschrieben.
Vor diesem Hintergrund wird es dich wahrscheinlich nicht überraschen, dass die Rezepte in diesem Buch alle auf einem nachrichtenzentrierten Ansatz basieren, um Informationen zwischen Maschinen zu übertragen.
Die Macht der Vokabulare
Ein nachrichtenbasierter Ansatz ist als Plattform gut geeignet. Aber auch generische Nachrichtenformate wie HTML müssen aussagekräftige Informationen auf verständliche Weise transportieren. 1998, etwa zur gleichen Zeit, als Roy Fielding seinen REST-Ansatz für das Netzwerk entwickelte (siehe "Fielding's REST"), veröffentlichten Peter Morville und sein Kollege Louis Rosenfeld das Buch Information Architecture for the World Wide Web (O'Reilly). Dieses Buch gilt als Startschuss für die Informationsarchitekturbewegung. Dan Klyn, Professor an der University of Michigan, erklärt die Informationsarchitektur anhand von drei Schlüsselelementen: Ontologie (bestimmte Bedeutung), Taxonomie (Anordnung der Teile) und Choreografie (Regeln für die Interaktion zwischen den Teilen).
Diese drei Dinge sind alle Teil des Vokabulars von Netzwerkanwendungen. Tim Berners-Lee hat sich nicht lange nach dem Erfolg des World Wide Web mit seinen Initiativen zum Resource Description Framework (RDF) der Herausforderung der Vokabulare im Web zugewandt. RDF und verwandte Technologien wie JSON-LD sind Beispiele dafür, dass man sich auf die Bedeutung innerhalb der Nachrichten konzentrieren kann, und das werden wir auch in unseren Rezepten tun.
Für unsere Arbeit wird die Choreografie von Klyn durch Hypermedia-Links und -Formulare unterstützt. Die Daten, die über diese Hypermedia-Elemente zwischen den Maschinen ausgetauscht werden, sind die Ontologie. Die Taxonomie sind die Verbindungen zwischen den Diensten im Netzwerk, die in ihrer Gesamtheit die verteilten Anwendungen ergeben, die wir entwickeln wollen.
Richardsons magische Saiten
Ein weiteres erwähnenswertes Element ist der Einsatz und die Leistungsfähigkeit von Ontologien, wenn du Dienste im Internet erstellst und mit ihnen interagierst. Es macht zwar Sinn, dass alle Anwendungen ihre eigenen kohärenten, konsistenten Begriffe benötigen (z. B. givenName, familyName, voicePhone, usw.), aber es ist auch wichtig, sich vor Augen zu halten, dass diese Begriffe im Wesentlichen das sind, was Leonard Richardson in seinem Buch RESTful Web APIs aus dem Jahr 2015 als "magic strings" bezeichnet hat.
Die Macht der Bezeichner, die für Eigenschaftsnamen verwendet werden, ist schon seit geraumer Zeit bekannt. Die gesamte RDF-Bewegung (siehe "The Power of Vocabularies") basierte auf der Schaffung eines netzwerkweiten Verständnisses von gut definierten Begriffen. Auf der Anwendungsebene werden in Eric EvansBuch Domain-Driven Design (Addison-Wesley) aus dem Jahr 2014 die Konzepte der "allgegenwärtigen Sprache" (die von allen Teammitgliedern verwendet wird, um alle Aktivitäten innerhalb der Anwendung miteinander zu verbinden) und "Bounded Context" (eine Möglichkeit, große Anwendungsmodelle in kohärente Unterabschnitte aufzuteilen, in denen die Begriffe gut verstanden werden) ausführlich erläutert.
Evans schrieb sein Buch etwa zur gleichen Zeit, als Fielding seine Dissertation fertigstellte. Beide beschäftigten sich mit der Frage, wie man ein stabiles Verständnis über große Anwendungen hinweg erreichen und erhalten kann. Während Evans sich auf die Kohärenz innerhalb einer einzigen Codebasis konzentrierte, arbeitete Fielding daran, die gleichen Ziele in unabhängigen Codebasen zu erreichen.
Dieser gemeinsame Kontext für separat erstellte und gewartete Dienste ist ein Schlüsselfaktor für die Rezepte in diesem Buch. Wir versuchen, Richardsons "semantische Lücke" durch das Design und die Implementierung von Diensten im Web zu schließen.
In diesem Abschnitt haben wir die mehr als hundert Jahre an Überlegungen und Bemühungen (siehe "Ein Jahrhundert Hypermedia") untersucht, die der Nutzung von Maschinen zur besseren Kommunikation von Ideen über ein Netzwerk von Diensten gewidmet sind. Wir haben gesehen, wie die Sozialtechnik und die Psychologie die Macht der Affordanzen (siehe "James J. Gibson") erkannt haben, um eine Handlungsoption in Hypermedia-Botschaften zu unterstützen (siehe "Der Wert von Botschaften"). Schließlich haben wir uns mit der Bedeutung und der Macht gut definierter und gepflegter Vokabulare befasst (siehe "Die Macht der Vokabulare"), die das semantische Verständnis im Netzwerk ermöglichen und unterstützen.
Diese Konzepte bilden eine Art Werkzeugkasten oder eine Reihe von Richtlinien, mit denen du im ganzen Buch hilfreiche Rezepte findest. Bevor wir in die Details der einzelnen Muster eintauchen, lohnt sich ein weiterer Abstecher. Einen, der einen übergreifenden Leitfaden für den gesamten Inhalt des Buches liefert.
Gemeinsame Grundsätze für skalierbare Dienste im Web
Zum Abschluss dieses Einführungskapitels möchte ich einige gemeinsame Grundprinzipien nennen, die mir bei der Auswahl und Definition der Rezepte in diesem Buch als Leitfaden dienten. Für diese Sammlung werde ich ein einziges, übergreifendes Prinzip nennen:
Nutze die globale Reichweite, um Probleme zu lösen, an die du nicht gedacht hast, für Menschen, die du noch nie getroffen hast.
Wir können dieses Prinzip noch ein bisschen weiter in seine drei Bestandteile zerlegen.
Nutzen Sie die globale Reichweite...
Es gibt viele kreative Menschen auf der Welt, und Millionen von ihnen haben Zugang zum Internet. Wenn wir daran arbeiten, einen Dienst zu entwickeln, ein Problemfeld zu definieren oder eine Lösung zu implementieren, können wir über das Internet auf eine Fülle von Informationen und Kreativität zugreifen. Allerdings schränken unsere Servicemodelle und Umsetzungswerkzeuge unsere Reichweite allzu oft ein. Es kann sehr schwierig sein, das zu finden, wonach wir suchen, und selbst wenn wir eine kreative Lösung für unser Problem bei jemand anderem finden, kann es viel zu kostspielig und kompliziert sein, diese Erfindung in unsere eigene Arbeit zu integrieren.
Bei den Rezepten in diesem Buch habe ich versucht, sie so auszuwählen und zu beschreiben, dass die Wahrscheinlichkeit, dass andere deine Lösung finden, steigt und die Einstiegshürde für die Verwendung deiner Lösung in anderen Projekten sinkt. Das bedeutet, dass die Details des Designs und der Implementierung den Schwerpunkt auf kontextspezifische Vokabeln legen, die auf standardisierte Nachrichten und Protokolle angewendet werden, die relativ leicht zugänglich und implementierbar sind.
Gute Rezepte vergrößern unsere globale Reichweite: die Fähigkeit, unsere Lösungen zu teilen und die Lösungen anderer zu finden und zu nutzen.
...um Probleme zu lösen, an die du noch nicht gedacht hast...
Ein weiterer wichtiger Teil unseres Leitfadens ist der Gedanke, dass wir versuchen, Dienste zu entwickeln, die für die Lösung von Problemen genutzt werden können, über die wir noch nicht nachgedacht haben. Das bedeutet nicht, dass wir versuchen, eine Art "allgemeinen Dienst" zu schaffen, den andere nutzen können (z. B. Datenspeicherung als Dienst oder Zugriffskontroll-Engines). Ja, auch diese werden gebraucht, aber darum geht es mir hier nicht.
Um Donald Norman zu zitieren (aus seinem Video von 1994):
Der Wert eines gut gestalteten Objekts liegt darin, dass es so viele Möglichkeiten bietet, dass die Menschen, die es benutzen, Dinge damit tun können, die sich der Designer nie vorgestellt hat.
Ich sehe diese Rezepte als Werkzeuge in der Werkstatt eines Handwerkers. Was auch immer du tust, es geht oft besser, wenn du genau das richtige Werkzeug für die Arbeit hast. Für dieses Buch habe ich versucht, Rezepte auszuwählen, die deinem Werkzeugkasten Tiefe und ein bisschen Befriedigung verleihen können.
Gute Rezepte machen gut durchdachte Dienste verfügbar, die andere auf eine Weise nutzen können, an die wir noch nicht gedacht haben.
...für Menschen, die du noch nie getroffen hast
Und schließlich müssen wir, da wir auf Dienste abzielen, die im Web funktionieren - einem Ort mit globaler Reichweite -, anerkennen, dass wir die Menschen, die unsere Dienste nutzen werden, möglicherweise nie treffen werden. Deshalb ist es wichtig, die Schnittstellen unserer Dienste sorgfältig und explizit mit kohärenten und konsistenten Vokabularen zu definieren. Wir müssen die allgegenwärtige Sprache von Eric Evans auf alle Dienste anwenden. Wir müssen es den Menschen leicht machen, die Absicht des Dienstes zu verstehen, ohne dass wir sie ihnen erklären müssen. Unsere Implementierungen müssen - um es mit Fieldings Worten zu sagen - "zustandslos" sein; sie müssen den gesamten Kontext enthalten, der für das Verständnis und die erfolgreiche Nutzung des Dienstes erforderlich ist.
Gute Rezepte ermöglichen es, dass "Fremde" (Dienste und/oder Menschen) sicher und erfolgreich miteinander interagieren können, um ein Problem zu lösen.
Umgang mit Zeitplänen
Eine weitere Überlegung, die wir im Hinterkopf behalten müssen, ist, dass Systeme ein Eigenleben haben und in ihrem eigenen Zeitrahmen funktionieren. Das Internet gibt es seit den frühen 1970er Jahren. Während sich die grundlegenden Funktionen nicht verändert haben, hat sich das Internet selbst im Laufe der Zeit in einer Weise entwickelt, die kaum jemand vorhersehen konnte. Dies ist ein gutes Beispiel für Normans Begriff des "gut gestalteten Objekts".
Große Systeme entwickeln sich nicht nur langsam weiter - auch Funktionen, die nur selten genutzt werden, bleiben lange Zeit erhalten. Es gibt Funktionen der HTML-Sprache (z. B. <marquee>, <center>, <xmp>, usw.), die veraltet sind, und doch kann man diese Sprachelemente heute noch online finden. Es zeigt sich, dass es schwer ist, etwas loszuwerden, wenn es erst einmal im Internet ist. Dinge, die wir heute tun, können noch Jahre später langfristige Auswirkungen haben.
Natürlich müssen nicht alle Lösungen für eine lange Zeit ausgelegt sein. Es kann sein, dass du es eilig hast, ein kurzfristiges Problem zu lösen, von dem du annimmst, dass es nicht lange dauern wird (z. B. ein kurzer Service, um eine Massenaktualisierung deines Produktkatalogs durchzuführen). Und das ist auch in Ordnung so. Meiner Erfahrung nach solltest du nicht davon ausgehen, dass deine Kreationen immer kurzlebig sein werden.
Gute Rezepte fördern Langlebigkeit und eine unabhängige Entwicklung über Jahrzehnte hinweg.
Das wird sich alles ändern
Abschließend ist zu sagen, dass sich das alles ändern wird, egal was wir tun, egal wie viel wir planen und planen. Das Internet hat sich im Laufe der Jahrzehnte auf unerwartete Weise weiterentwickelt. So auch die Rolle des HTTP-Protokolls und des ursprünglichen HTML-Nachrichtenformats. Software, von der wir dachten, dass es sie für immer geben würde, ist nicht mehr verfügbar, und Anwendungen, die einst als entbehrlich galten, werden heute noch genutzt.
Was auch immer wir bauen - wenn wir es gut bauen - wird wahrscheinlich auf unerwartete Weise von unbekannten Menschen genutzt werden, um noch unbekannte Probleme zu lösen. Für diejenigen, die sich der Entwicklung von Software auf Netzwerkebene verschrieben haben, ist das unser Schicksal: vom Schicksal unserer Bemühungen (angenehm oder nicht) überrascht zu werden.
Ich habe an Projekten gearbeitet, die mehr als 10 Jahre gebraucht haben, um wahrgenommen zu werden und nützlich zu sein. Und ich habe kurzfristige Lösungen entwickelt, die nun schon seit mehr als zwei Jahrzehnten laufen. Für mich ist das eine der Freuden meiner Arbeit. Ich bin immer wieder überrascht, immer wieder erstaunt und selten enttäuscht. Selbst wenn die Dinge nicht so laufen wie geplant, kann ich mich damit trösten, dass sich das alles irgendwann ändern wird.
Gute Rezepte erkennen an, dass nichts von Dauer ist und sich die Dinge im Laufe der Zeit immer wieder ändern werden.
Vor diesem Hintergrund sollten wir uns etwas Zeit nehmen, um die Technik und das Designdenken hinter den ausgewählten Rezepten in diesem Buch genauer zu erkunden. Lass uns die Kunst des "Denkens in Hypermedia" erkunden.
Get RESTful Web API Patterns and Practices Cookbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

