Chapter 4. Applying the Scale of Resilience to the PL/SQL Code
The containerized Oracle Database instance that was set up in Chapter 2 can now be put to further use. Rather than just discussing PL/SQL code in isolation, I can now apply the scale of resilience and use the results to drive the remediation procedure.
In Chapter 1, you saw the unmodified version of Example 4-1.
Example 4-1. PL/SQL example from Chapter 1
DECLARECURSORc1isSELECTename,empno,salFROMempORDERBYsalDESC;-- start with highest paid employeemy_enameVARCHAR2(10);my_empnoNUMBER(4);my_salNUMBER(7,2);BEGINOPENc1;FORiIN1..5LOOPFETCHc1INTOmy_ename,my_empno,my_sal;EXITWHENc1%NOTFOUND;/* in case the number requested *//* is more than the total *//* number of employees */INSERTINTOtempVALUES(my_sal,my_empno,my_ename);COMMIT;ENDLOOP;CLOSEc1;END;
Applying the scale of resilience, the scores in Table 4-1 were recorded.
| Requirement number | Resilience requirement | Score (0–10) |
|---|---|---|
1 |
Capture all errors and exceptions |
0 |
2 |
Recoverability |
2 |
3 |
Observability |
0 |
4 |
Modifiability |
5 |
5 |
Modularity |
2 |
6 |
Simplicity |
5 |
7 |
Coding conventions |
5 |
8 |
Reusability |
2 |
9 |
Repeatable testing |
2 |
10 |
Avoiding common antipatterns |
0 |
11 |
Schema evolution |
0 |
TOTAL SCORE |
23 |
The following sections take each item in Table 4-1 in turn and explore them in more depth. As part of this, I’ll make some targeted code changes with a view to improving the scores.
For ease of reference, the latest working version of the code is shown in Example 4-2.
Example 4-2. The latest working version of the PL/SQL procedure
CREATEORREPLACEPROCEDUREupdate_employeesISCURSORc1isSELECTename,empno,salFROMempORDERBYsalDESC;-- start with highest paid employeemy_enameVARCHAR2(10);my_empnoNUMBER(4);my_salNUMBER(7,2);BEGINOPENc1;FORiIN1..5LOOPFETCHc1INTOmy_ename,my_empno,my_sal;EXITWHENc1%NOTFOUND;/* in case the number requested *//* is more than the total *//* number of employees */INSERTINTOtempVALUES(my_ename,my_empno,my_sal);COMMIT;ENDLOOP;CLOSEc1;END;
The code in Example 4-2 is now reviewed using the scale of resilience.
Scale of Resilience Requirement 1: Capture All Errors and Exceptions
Referring to Table 4-1, the score for this requirement is 0. The basic problem in relation to error and exception handling in Example 4-2 is that there isn’t any! In other words, if an error or exception occurs, it will result in an immediate termination and exit. This is rarely a desirable outcome because it may prevent an orderly exit and could potentially lead to data inconsistencies.
Let’s apply a few minor additions, as shown in Example 4-3.
Example 4-3. Adding exception handling to the earlier version of the PL/SQL procedure
CREATEORREPLACEPROCEDUREupdate_employeesISCURSORc1isSELECTename,empno,salFROMempORDERBYsalDESC;-- start with highest paid employeemy_enameVARCHAR2(10);my_empnoNUMBER(4);my_salNUMBER(7,2);BEGINOPENc1;FORiIN1..5LOOPFETCHc1INTOmy_ename,my_empno,my_sal;EXITWHENc1%NOTFOUND;/* in case the number requested *//* is more than the total *//* number of employees */DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(my_sal,my_empno,my_ename);DBMS_OUTPUT.PUT_LINE('Successful insert!');COMMIT;ENDLOOP;CLOSEc1;DBMS_OUTPUT.PUT_LINE('Success - we got here!');EXCEPTIONWHENNO_DATA_FOUNDTHEN-- catches all 'no data found' errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENOTHERSTHEN-- handles all other errorsDBMS_OUTPUT.PUT_LINE('We hit a general exception');ROLLBACK;END;
Notice that, for the purpose of illustration, I’ve also reversed the original PL/SQL fix so that we are once again intentionally attempting to:
-
Write the salary value into the
enamecolumn. -
Write the name into the salary column.
This bug just won’t go away! Obviously, I’m just using it for the purposes of illustration and you’ll soon see how to actually catch the exception raised by this bug.
I’ve also added a few extra lines to Example 4-3 using DBMS_OUTPUT to produce some developer output. Can you see the differences? I’ll break down the Example 4-3 changes in the next section.
The Changes for Exception Handling
Notice in Example 4-3 the addition of some screen output in the form of the call:
DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');
Normally only developers will see this screen output, but it can also become visible to other users. As you’ll see, output from DBMS_OUTPUT.PUT_LINE is very useful for providing feedback during coding and testing.
The other main change in Example 4-3 is the addition of the following EXCEPTION block:
EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorsDBMS_OUTPUT.PUT_LINE('We hit a general exception');ROLLBACK;
Notice how the exception block is separate and distinct from the application code. This is a nice feature of the PL/SQL exception model in that the exceptions are handled after the application code section. Thus, there’s no exception-handling code mixed in with (and cluttering up) the application code.
This exception block handles two exceptions, namely NO_DATA_FOUND and OTHERS. A NO_DATA_FOUND exception can occur when a SELECT INTO statement returns no rows. The second exception (OTHERS) catches all other exceptions. The NO_DATA_FOUND exception clause is an example of a specific exception, i.e., it checks for exactly one type of (specific) exception.
The OTHERS exception clause is an example of a general exception. It checks for a large number of potential exceptions. This type of exception case is very powerful. If it is not used correctly, then we may inadvertently run into an egregious antipattern: swallowing all exceptions.
Having said all that, the code in Example 4-3 is intentionally swallowing all exceptions! But this is purely for the purposes of illustration. I will apply further code changes to better handle the exceptions. For the moment, we’ll continue to use the bad approach just to get used to the mechanisms involved. So, let’s run the code and see what happens.
Running the Updated PL/SQL
Before running the new version of the PL/SQL procedure, I need to replace the old one. To do this, I drop the existing version, as shown in Figure 4-1. Just right-click the procedure name and use the dialog you saw back in Figure 3-8. Technically, the
CREATE OR REPLACE will of course obviate the need to manually drop the stored procedure. I’m just focusing here on a simple set of steps to get the procedure update done.
Figure 4-1. Drop the old version of the PL/SQL procedure
Notice in Figure 4-1 the appearance in line 1 of the word NONEDITIONABLE. This text is automatically inserted by the Oracle Database when the procedure is saved. It doesn’t have any effect on this discussion and can be ignored during development. I’ve left the reference to NONEDITIONABLE in the example just in case you come across it in your own work.
Then, replace the code with the new version from Example 4-3, as shown in Figure 4-2. Click the play button and then click the refresh button in Figure 4-2 to verify that the updated procedure has been stored.

Figure 4-2. Updated PL/SQL with exception handling
At this point, I can run the new update_employees procedure and then review the output, as shown in Figure 4-3.
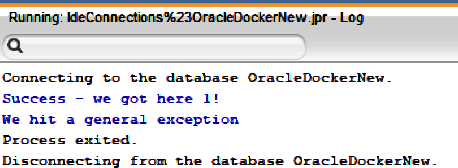
Figure 4-3. Updated PL/SQL output with exception handling
Notice the new screen output at the bottom of Figure 4-3, which consists of the following text:
Success-wegothere1!Wehitageneralexception
Let’s compare this to the PL/SQL code in Figure 4-2. The first message occurs just before the INSERT statement and the second message is produced by the OTHERS clause in the exception block.
This is all you need to know in order to infer the code path taken during execution, which consists of the following actions:
-
An attempt was made to
INSERTsome data. -
An issue occurred during the
INSERTstatement. -
An exception was raised by the runtime system.
-
The exception was caught and handled by the
OTHERSclause.
It’s extremely useful to be able to know in such detail what occurred during the stored procedure run. You can use this information to determine whether the code needs to be changed (it does!) and in what way you should modify it. Having ready access to this level of information goes a long way toward removing the guesswork from such PL/SQL development.
I’ll make just one more code change in order to extract the exact exception that occurs. To do this, I’ll make use of a special PL/SQL function called SQLCODE, which returns the error number associated with the most recently raised exception. I use SQLCODE in the OTHERS clause in Example 4-4.
Example 4-4. Adding enhanced exception handling to the PL/SQL procedure
createorreplacePROCEDUREupdate_employeesISCURSORc1isSELECTename,empno,salFROMempORDERBYsalDESC;--startwithhighestpaidemployeemy_enameVARCHAR2(10);my_empnoNUMBER(4);my_salNUMBER(7,2);err_numNUMBER;err_msgVARCHAR2(100);BEGINOPENc1;FORiIN1..5LOOPFETCHc1INTOmy_ename,my_empno,my_sal;EXITWHENc1%NOTFOUND;/*incasethenumberrequested*//*ismorethanthetotal*//*numberofemployees*/DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(my_sal,my_empno,my_ename);DBMS_OUTPUT.PUT_LINE('Successful insert!');COMMIT;ENDLOOP;CLOSEc1;DBMS_OUTPUT.PUT_LINE('Success - we got here!');EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorserr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);DBMS_OUTPUT.PUT_LINE('We hit a general exception error number '||err_num||' Error message: '||err_msg);ROLLBACK;END;
Remember to drop the old version of the stored procedure and replace it with the one in Example 4-4. It is, of course, not necessary to manually drop the old version, given that the PL/SQL in Example 4-4 contains this line:
createorreplacePROCEDUREupdate_employees
Just make sure that the old code has been replaced with the updated version. Figure 4-4 illustrates the improved code and the associated output. Notice that the exception-handling code has determined the error as being the following:
ORA-01722:invalidnumber
Remember we encountered this at the very beginning of our acquaintance with the PL/SQL bug, way back in Example 3-1? Here in Figure 4-4, you see the code extracting the error detail at the time it occurs. This is a very powerful addition to the PL/SQL toolbox.
Using this SQLCODE technique, you can know for certain exactly what type of exception occurs in similar situations. There’s no need for inspired guesswork when the code provides the necessary data.
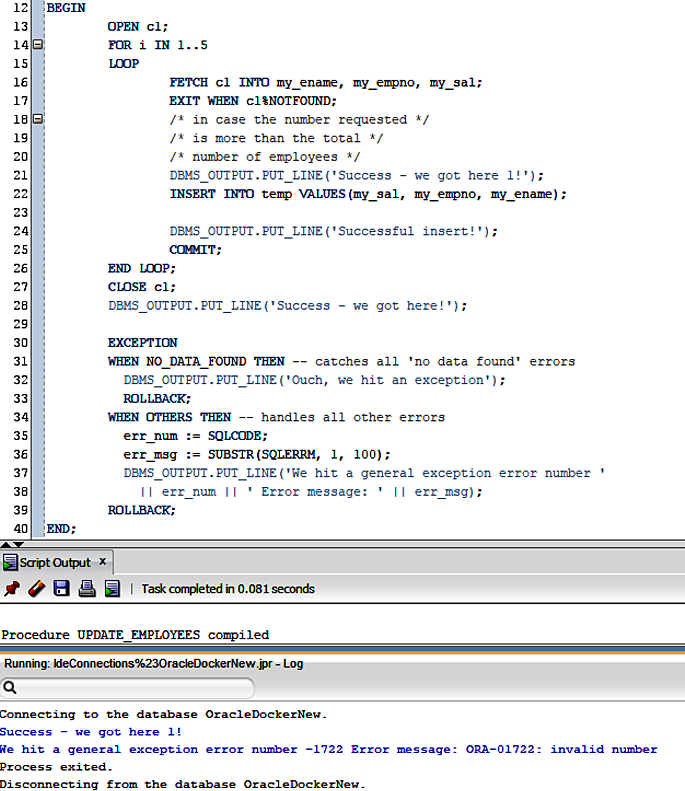
Figure 4-4. Updated PL/SQL with enhanced exception handling
Now that we know the exact exception, I can make a small design change to the PL/SQL code. Rather than using an OTHERS clause, I can opt to catch the specific error we know can occur. The updated code looks like Example 4-5.
Example 4-5. Removing the OTHERS clause from the enhanced exception handling
createorreplacePROCEDUREupdate_employeesISCURSORc1isSELECTename,empno,salFROMempORDERBYsalDESC;--startwithhighestpaidemployeemy_enameVARCHAR2(10);my_empnoNUMBER(4);my_salNUMBER(7,2);err_numNUMBER;err_msgVARCHAR2(100);BEGINOPENc1;FORiIN1..5LOOPFETCHc1INTOmy_ename,my_empno,my_sal;EXITWHENc1%NOTFOUND;/*incasethenumberrequested*//*ismorethanthetotal*//*numberofemployees*/DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(my_sal,my_empno,my_ename);DBMS_OUTPUT.PUT_LINE('Successful insert!');COMMIT;ENDLOOP;CLOSEc1;DBMS_OUTPUT.PUT_LINE('Success - we got here!');EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENINVALID_NUMBERTHEN--handlesINVALID_NUMBERerr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);DBMS_OUTPUT.PUT_LINE('We hit an INVALID_NUMBER exception error number '||err_num||' Error message: '||err_msg);ROLLBACK;END;
Note
The inclusion in Example 4-5 of the two variables err_num and err_msg is not strictly required. Their values could be put straight into the call to PUT_LINE. They are added just to make the code a little easier to read.
So, in Example 4-5 we have no OTHERS clause. This means that the procedure handles just two exceptions: NO_DATA_FOUND and INVALID_NUMBER.
Any other exceptions pass up the chain to the procedure caller. This has the merit of simplifying the update_employees procedure. This simplification is a good pattern to adopt and I’ll build on it in later sections.
Let’s now move on and look at the next important scale of resilience requirement: recoverability.
Scale of Resilience Requirement 2: Recoverability
What do I mean by code that is recoverable? In a nutshell, recoverability means that the code can survive any errors or exceptions as well as letting you know the state at the point of exit. In other words, when attempting to implement recoverability, the aim is to know why the code exited and what (if any) data changes were applied during the run.
If I can achieve the twin aims of knowing the error details and data consistency, then I will have addressed some of the issues raised back in “A Cautionary Tale”. Imagine, in Example 4-5, what happens if either of the two designated exceptions occurs.
In both cases, we have a ROLLBACK call. This means that any database changes made in the current transaction are reversed. Let’s try this out and see if the code is in fact recoverable.
To begin with, let’s check the contents of the TEMP table, as shown in Figure 4-5.
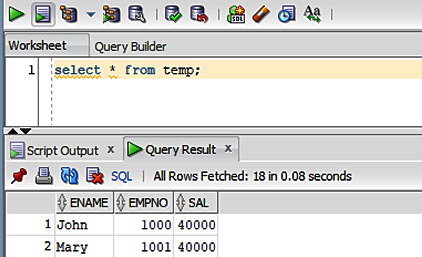
Figure 4-5. Checking the baseline data
Notice in Figure 4-5 that we’ve currently got two rows in the TEMP table. A successful run of the stored procedure would result in an additional two rows in the table. Let’s now run the stored procedure and, after hitting the anticipated (i.e., deliberately inserted) exception, we then rerun the SQL script from Figure 4-5. The result is no change in the TEMP table data. In other words, the rollback worked. No surprises there.
This is a rather roundabout way of checking that the PL/SQL can handle exceptions by rolling back any data changes. The exception condition was of course artificially induced by way of a known bug in the PL/SQL. But the point of the discussion is that if we correct the bug and then subsequently encounter an exception, we can now be certain that no data changes will occur.
This means that it is safe to rerun the PL/SQL once the cause of the exception has been fixed. In other words, the PL/SQL code is recoverable. Running it multiple times in the face of an exception won’t then result in unwarranted data changes.
One issue remains: we still have no idea (after the run) what error occurred. In other words, the code still lacks observability. To resolve this, let’s now have a look at the issue of observability.
Scale of Resilience Requirement 3: Observability
Back in Chapter 1 and in Table 4-1, we got a score of 0 for observability. This is because, outside the safe confines of SQL Developer, we really don’t know much about any given run of the stored procedure. Beyond the TEMP table data changes, it’s very hard to know what has happened during a run.
I’m referring here to the case where the stored procedure is run and we have no access to the messages produced by the calls to DBMS_OUTPUT.PUT_LINE. Also, imagine if there was more going on with the procedure than is currently the case. For example, if the procedure contained a lot more code, it would be very difficult to say with any certainty what occurred during a given run. I need to fix this and therefore address the underlying requirement for improved observability. In other words, I want to provide persistent storage for the output messages.
One way to address this requirement is to introduce a new table purely for logging. With this in mind, let’s extend our existing schema by creating a new table, as shown in Example 4-6.
Example 4-6. Extending the schema with a logging table
CREATETABLELOGGING(--ThenextlineworksonlyonOracleversion12candup--So,pleasemakesureyouareon12corhigherLogging_IDNUMBERGENERATEDALWAYSASIDENTITY,EVENT_DATETIMESTAMPNOTNULL,ACTION_MESSAGEVARCHAR2(255),CODE_LOCATIONVARCHAR2(255));
In Example 4-7, we have a PL/SQL procedure to handle logging by populating the new LOGGING table.
Example 4-7. Implementing logging in PL/SQL
CREATEORREPLACEPROCEDURELOG_ACTION(action_messageINVARCHAR2,code_locationINVARCHAR2)ISPRAGMAAUTONOMOUS_TRANSACTION;BEGININSERTINTOLOGGING(EVENT_DATE,action_message,code_location)VALUES(SYSDATE,action_message,code_location);COMMIT;END;
This is an example of an autonomous transaction specification. It applies to the PL/SQL block that follows and provides for special operation in relation to transaction handling.
As our use of transactions and exception handling becomes more complicated, an important question relates to handling exceptions in logging code. In other words, how should you handle an exception in the code that itself handles reporting on exceptions?
What to Do If Logging Hits an Exception?
Consideration should be given to the case where an exception occurs in the code in Example 4-7. Such an exception is an indication that the logging mechanism is itself failing. This might be due to some very serious runtime issue. Regardless, there should be some way of alerting the DevOps team if such an error occurs.
One simple mechanism might be to add some code that creates or updates an external file. The file could be located in a DevOps-monitored directory so that once an update occurs, it gets brought to the attention of someone who can then address the underlying problem.
A suggested way of handling this is described in Part III and shown in the PL/SQL code in Example 9-8. More information on this can be found in the UTL_FILE package.
Back to our autonomous transaction; let’s now run the SQL from Example 4-7 by compiling and installing the stored procedure.
Updated Schema
After running the SQL in Example 4-6 and also after installing the stored procedure, the setup should look like that shown in Figure 4-6.
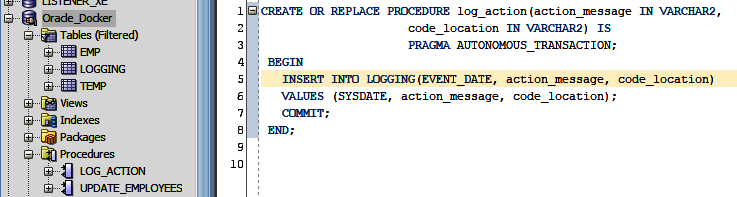
Figure 4-6. Modified schema and new procedure
Notice the successful addition of the new LOGGING table under Tables (Filtered) in Figure 4-6.
I also need to modify the original stored procedure to call the new logging procedure. The updated code for this is shown in Example 4-8.
Example 4-8. Adding a logging call in PL/SQL
createorreplacePROCEDUREupdate_employeesASCURSORc1isSELECTename,empno,salFROMempORDERBYsalDESC;--startwithhighestpaidemployeemy_enameVARCHAR2(10);my_empnoNUMBER(4);my_salNUMBER(7,2);err_numNUMBER;err_msgVARCHAR2(100);BEGINLOG_ACTION('Calling update','update_employees');OPENc1;FORiIN1..5LOOPFETCHc1INTOmy_ename,my_empno,my_sal;EXITWHENc1%NOTFOUND;/*incasethenumberrequested*//*ismorethanthetotal*//*numberofemployees*/DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(my_sal,my_empno,my_ename);DBMS_OUTPUT.PUT_LINE('Successful insert!');COMMIT;ENDLOOP;CLOSEc1;DBMS_OUTPUT.PUT_LINE('Success - we got here!');EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENINVALID_NUMBERTHEN--handlesINVALID_NUMBERerr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);DBMS_OUTPUT.PUT_LINE('We hit an INVALID_NUMBER exception error number'||err_num||'Error message:'||err_msg);ROLLBACK;END;
This is the key line.
After the call to the logging procedure, we have a single row of content in the LOGGING table (see Figure 4-7).
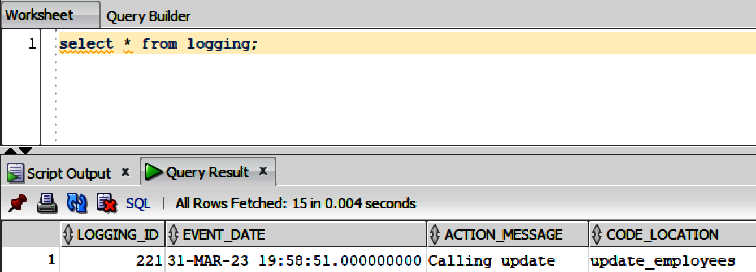
Figure 4-7. Logging data from the procedure call
Notice the logging data at the bottom of Figure 4-7. Note also the LOGGING_ID column in the table. This auto-increments with each new row insertion. Also included is an EVENT_DATE column, which provides the date and time of the row insertion.
The goal is the ability to verify the running of the PL/SQL code in an observable fashion. So, the Figure 4-7 content can be considered a baseline for the required data.
Here’s the key PL/SQL that runs when I execute the logging procedure:
INSERTINTOLOGGING(EVENT_DATE,action_message,code_location)VALUES(SYSDATE,action_message,code_location);
Because the LOGGING_ID column is marked as GENERATED ALWAYS AS IDENTITY, I don’t have to update it in the PL/SQL code. This is handled by the Oracle Database. Note in passing that, if I attempt to insert (or update) a value into the LOGGING_ID column, the database will raise an error.
I use the SYSDATE function in order to supply an event date. So, there’s a lot of power in these few lines of PL/SQL.
If I run a DESCRIBE call to look at the structure of the LOGGING table, like DESCRIBE LOGGING;, for instance, I get this output:
NameNull?Type-----------------------------------LOGGING_IDNOTNULLNUMBEREVENT_DATENOTNULLTIMESTAMP(6)ACTION_MESSAGEVARCHAR2(255)CODE_LOCATIONVARCHAR2(255)
Notice the NOT NULL constraints on the LOGGING_ID and EVENT_DATE columns. This is very useful for ensuring data consistency because the NOT NULL constraint forces a column to not accept NULL values. This is of course another way of saying that these columns must always contain a value. That is, we cannot insert a new row without adding a value to the EVENT_DATE column.
All of this new SQL and PL/SQL helps in achieving improved observability. I can now tell with certainty what happened during a code run. No more need for any inspired guesswork.
Let’s move on to address the next scale of resilience requirement: modifiability.
Scale of Resilience Requirement 4: Modifiability
The latest version of the corrected PL/SQL code is shown in Example 4-9.
Example 4-9. The latest correct version of the PL/SQL code
createorreplacePROCEDUREupdate_employeesASCURSORc1isSELECTename,empno,salFROMempORDERBYsalDESC;--startwithhighestpaidemployeemy_enameVARCHAR2(10);my_empnoNUMBER(4);my_salNUMBER(7,2);err_numNUMBER;err_msgVARCHAR2(100);BEGINLOG_ACTION('Calling update','update_employees');OPENc1;FORiIN1..5LOOPFETCHc1INTOmy_ename,my_empno,my_sal;EXITWHENc1%NOTFOUND;/*incasethenumberrequested*//*ismorethanthetotal*//*numberofemployees*/DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(my_ename,my_empno,my_sal);DBMS_OUTPUT.PUT_LINE('Successful insert!');COMMIT;ENDLOOP;CLOSEc1;DBMS_OUTPUT.PUT_LINE('Success - we got here!');EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENINVALID_NUMBERTHEN--handlesINVALID_NUMBERerr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);DBMS_OUTPUT.PUT_LINE('We hit an INVALID_NUMBER exception error number'||err_num||'Error message:'||err_msg);ROLLBACK;END;
Reverses the artificial bug in the
INSERTstatement.
How modifiable is this code in Example 4-9? The reason why I’m asking is because posing such questions to yourself is a good practice. In other words, it’s best to ask yourself the question rather than rely on colleagues to apply their own thinking to make the code modifiable. Now that I’ve added exception handling to Example 4-9, do you get a feeling there’s something missing from the code? Asking yourself this question is another good habit to develop in general.
The reason for this introspection is because, with the extra exception handler, I’ve now added a new pathway to the code in Example 4-9 and I’ve omitted a call to close the cursor. Now, this is minor enough in this case because the cursor is in fact closed automatically, but it’s generally a good practice to close resources such as cursors when they’re no longer in use. Just for the sake of completeness, I’ll remedy that with the update shown in Example 4-10.
Example 4-10. Closing resources in the PL/SQL code
CREATEORREPLACEPROCEDUREupdate_employeesASCURSORc1ISSELECTename,empno,salFROMempORDERBYsalDESC;--startwithhighestpaidemployeemy_enameVARCHAR2(10);my_empnoNUMBER(4);my_salNUMBER(7,2);err_numNUMBER;err_msgVARCHAR2(100);BEGINLOG_ACTION('Calling update','update_employees');OPENc1;FORiIN1..5LOOPFETCHc1INTOmy_ename,my_empno,my_sal;EXITWHENc1%NOTFOUND;/*incasethenumberrequested*//*ismorethanthetotal*//*numberofemployees*/DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(my_sal,my_empno,my_ename);DBMS_OUTPUT.PUT_LINE('Successful insert!');COMMIT;ENDLOOP;CLOSEc1;DBMS_OUTPUT.PUT_LINE('Success - we got here!');EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsIFc1%ISOPENTHENCLOSEc1;ENDIF;DBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception - CURSOR open: '||sys.diutil.bool_to_int(c1%ISOPEN));ROLLBACK;WHENINVALID_NUMBERTHEN--handlesINVALID_NUMBERIFc1%ISOPENTHENCLOSEc1;ENDIF;err_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);DBMS_OUTPUT.PUT_LINE('We hit an invalid number exception error number - CURSOR open: '||sys.diutil.bool_to_int(c1%ISOPEN)||' '||err_num||' Error message: '||err_msg);ROLLBACK;END;
When we run the code in Example 4-10, the program output is as follows:
ConnectingtothedatabaseOracle_Docker.Success-wegothere1!Wehitaninvalidnumberexceptionerrornumber-cursoropen:0-1722Errormessage:ORA-01722:invalidnumberProcessexited.DisconnectingfromthedatabaseOracle_Docker.
Notice the new output: cursor open: 0. This indicates that the cursor is indeed being explicitly closed as part of the exception handler.
The small changes made in this section suggest that the code is quite modifiable. As you’ll see in the next section on modularity, further improvement will be made possible in modifiability.
Scale of Resilience Requirement 5: Modularity
The code in Example 4-10 is getting a bit clunky at this point. It’s really a bit of a mess! This is actually quite typical with coding in general. As new features are added and with development time pressure, it can get harder to understand the code. This is of course particularly the case for new people who haven’t seen the code before. The original author may well understand the code but, in its current form, it is unnecessarily complicated.
Generally, the best way to resolve this excessive complexity is to resort to the old principle of divide and conquer. This is also referred to as stepwise refinement or, in modern parlance, refactoring.
In this approach, I will break the procedure into two separate procedures, as shown by the pseudocode requirements in Example 4-11.
Example 4-11. Requirements for producing a more modular example
Procedure1istaskedwith:*Dataacquisition*Flowcontrol*ExceptionhandlingProcedure2istaskedwith:*Datamodification*Businesslogic
To enhance the modularity, I therefore want to break up and simplify the code in some way. This is where it becomes useful to have knowledge of some additional PL/SQL language constructs. In Example 4-12, you can see an example of the cursor FOR LOOP.
Example 4-12. Using a language construct for simpler PL/SQL code
createorreplacePROCEDUREupdate_employeesASCURSORc_employeeISSELECTename,empno,salFROMempORDERBYsalDESC;BEGINFORr_employeeINc_employeeLOOPdbms_output.put_line(r_employee.ename||': $'||r_employee.sal);DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(r_employee.empno,r_employee.ename,r_employee.sal);DBMS_OUTPUT.PUT_LINE('Successful insert!');ENDLOOP;END;
One benefit of the FOR LOOP in Example 4-12 is implicit (or automatic) opening and closing of the cursor. So, in Example 4-12, we therefore no longer need to worry about cursor handling.
What about exceptions? Do I need to concern myself with exceptions now that I’m using the cursor FOR LOOP? To find out, let’s run the code and put in our familiar (exception-producing) bug by changing this code:
INSERTINTOtempVALUES(r_employee.empno,r_employee.ename,r_employee.sal);
to this:
INSERTINTOtempVALUES(r_employee.sal,r_employee.empno,r_employee.ename);
In other words, I’m swapping the salary and name columns so as to produce a data type violation. Running the (now buggy) code, we see this output:
ORA-01722:invalidnumberORA-06512:at"STEPHEN.UPDATE_EMPLOYEES",line15ORA-06512:atline2Mary:$40000Success-wegothere1!Processexited.
So, I’m still getting the expected exceptions in the substantially reduced code. I’ll address this by making a quick addition of some exception handling, which produces Example 4-13.
Example 4-13. Using a language construct for simpler PL/SQL code
createorreplacePROCEDUREupdate_employeesASerr_numNUMBER;err_msgVARCHAR2(100);CURSORc_employeeISSELECTename,empno,salFROMempORDERBYsalDESC;BEGINFORr_employeeINc_employeeLOOPdbms_output.put_line(r_employee.ename||': $'||r_employee.sal);DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(r_employee.sal,r_employee.empno,r_employee.ename);DBMS_OUTPUT.PUT_LINE('Successful insert!');ENDLOOP;EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorserr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);DBMS_OUTPUT.PUT_LINE('We hit a general exception error number - '||' '||err_num||' Error message: '||err_msg);ROLLBACK;END;
Let’s now run the code in Example 4-13. We should see the following output:
ConnectingtothedatabaseOracle_Docker.Mary:$40000Success-wegothere1!Wehitageneralexceptionerrornumber-1722Errormessage:ORA-01722:invalidnumber
I’ve caught the same exception as before, but look at how much smaller the code is in Example 4-13. That’s a whole lot less code to maintain—no cursor management is required of us. Producing compact and easily understood code is always worth the effort. One important merit is that you are freer to focus on implementing important business capabilities.
But what about the modularity requirements? Example 4-11 specifies that we are to break the existing procedure into two procedures:
-
Data acquisition, flow control, and exception handling
-
Data modification and business logic
Example 4-14 shows how to divide the procedure in order to make it more modular. First, we have a data modification procedure and business logic.
Example 4-14. Data modification procedure and business logic
createorreplacePROCEDUREupdateEmployeeData(ENAMEINVARCHAR2,EMPNOINNUMBER,SALINNUMBER)ASBEGINdbms_output.put_line('Employee: '||ENAME||' Number: '||EMPNO||' Salary: '||SAL);DBMS_OUTPUT.PUT_LINE('Success - we got here 1!');INSERTINTOtempVALUES(SAL,EMPNO,ENAME);dbms_output.put_line('Successful insert');END;
The procedure in Example 4-14 is called during the loop by the now further-reduced procedure in Example 4-15.
Example 4-15. The main (driving) procedure
createorreplacePROCEDUREupdate_employeesASerr_numNUMBER;err_msgVARCHAR2(100);CURSORc_employeeISSELECTename,empno,salFROMempORDERBYsalDESC;BEGINFORr_employeeINc_employeeLOOPupdateEmployeeData(r_employee.ename,r_employee.empno,r_employee.sal);ENDLOOP;EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorserr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);DBMS_OUTPUT.PUT_LINE('We hit a general exception error number - '||' '||err_num||' Error message: '||err_msg);ROLLBACK;END;
Note
In Chapter 6, I’ll introduce the idea of helpers, which are very short procedures and functions that provide specialized, clearly defined actions on behalf of the main code. When the main code requires some assistance (e.g., calculating the tax due on a sale) it calls an appropriate helper. In this context, updateEmployeeData is an example of a helper.
I have at last arrived at a more modular version of the PL/SQL code. In Example 4-15, you see a main procedure called update_employees that invokes a service (or helper) procedure with the name updateEmployeeData.
The main procedure (update_employees) handles any exceptions as well. So, if the service procedure (updateEmployeeData) happens to raise an exception (which it does), then it will be handled in the main procedure (update_employees). This approach gives us the benefits of good exception handling without adding burdens to the service code.
Tip
A slight change to this approach of handling exceptions in the calling procedure is commonly adopted by very experienced PL/SQL developers, where exceptions are handled as close to their origin as possible. When using this approach, every procedure/function has its own exception handler with a WHEN OTHERS clause ending in raise. The purpose of the raise is to push the exception back up the chain for any further processing.
This is also a good pattern in that it allows for localized processing of exceptions. Regardless of whether you opt for this approach or the helper-based technique, this discussion underlines the importance of having a defined strategy for modularity and exception management.
I think the structure in Example 4-15 is a nice division of labor, and it has the additional merit of being quite easy to understand for anyone who has to maintain it down the line.
Oracle PL/SQL also provides a packaging facility that allows for enhanced modularity. Let’s have a look at this in relation to the logging code.
A Logging Package
The use of PL/SQL packages allows for code to be easily shared across the environment. As you’ll soon see, packages can be compiled and stored in the Oracle Database. This facilitates sharing the package contents across many applications.
Tip
When you call a packaged subprogram for the first time, the whole package is loaded into memory. Subsequent calls to related subprograms in the package then require no additional disk I/O. It is for this reason that packages can be used to enhance developer productivity and improve performance. The use of packages also helps protect the runtime system.
One typical use case for PL/SQL packages is utility code, i.e., code that is of use to a range of callers. Logging fits nicely into this category. Getting up to speed with PL/SQL packages isn’t difficult. I’ve created a packaged version of the logging procedure in Example 4-16. See if you can figure it out.
Example 4-16. The logging package
createorreplacePACKAGEloggingPackageASPROCEDURELOG_ACTION(action_messageINVARCHAR2,code_locationINVARCHAR2);ENDloggingPackage;createorreplacePACKAGEBODYloggingPackageASPROCEDURELOG_ACTION(action_messageINVARCHAR2,code_locationINVARCHAR2)ISPRAGMAAUTONOMOUS_TRANSACTION;BEGININSERTINTOLOGGING(EVENT_DATE,action_message,code_location)VALUES(SYSDATE,action_message,code_location);COMMIT;END;ENDloggingPackage;
This is the API.
This is the implementation of the API.
As with APIs in general, the package specification is the contract and the implementation remains hidden from the callers. Packages provide for enhanced modularity and they are strongly encouraged by Oracle.
Let’s look now at the nuts and bolts of how to create a PL/SQL package and how to store it in the Oracle Database.
Creating a Logging Package
To create a new package, right-click Packages, as shown in Figure 4-8, and select New Package.
Figure 4-8. Create a new package
Type a new name for the package, such as LOGGINGPACKAGE. Then, paste or type the code from Example 4-17, overwriting the previous contents.
Example 4-17. The logging package API
createorreplacePACKAGEloggingPackageASPROCEDURELOG_ACTION(action_messageINVARCHAR2,code_locationINVARCHAR2);ENDloggingPackage;
Supplies only the name and the required parameters of the procedure. This is crucial because the specification is the API that users of the package will see. In other words, package users won’t know (or generally care) about the implementation of the package procedure(s).
Select the contents of Example 4-17, then right-click it and select Compile. This should then store the package specification in the database and you can verify this by clicking the refresh button on the upper-left menu.
Next up, we have to create the LOG_ACTION procedure implementation. Right-click the package name and select the Create Body option, as shown in Figure 4-9.

Figure 4-9. Create a new package body
Overwrite the LOG_ACTION procedure contents with the following (don’t delete the package details surrounding the procedure code):
PROCEDURELOG_ACTION(action_messageINVARCHAR2,code_locationINVARCHAR2)ISPRAGMAAUTONOMOUS_TRANSACTION;BEGININSERTINTOLOGGING(EVENT_DATE,action_message,code_location)VALUES(SYSDATE,action_message,code_location);COMMIT;END;
Then select all (only required if there is other code in your worksheet), right-click, and select Compile. At this point, the package should be stored in the database, ready for use. To verify it, clear the LOGGING table:
deletefromLOGGING;
Finally, call the package procedure with some PL/SQL:
BEGINloggingPackage.LOG_ACTION('A log message','Trouble at mill');END;
If all is well, there should now be a single row in the LOGGING table, as shown by the data at the bottom of Figure 4-10.
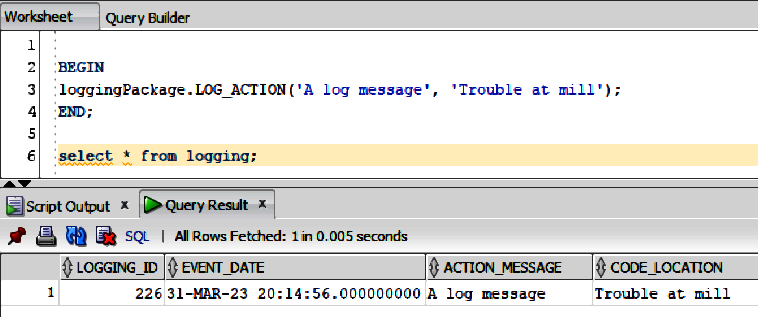
Figure 4-10. Successfully running the newly packaged procedure
The single row at the bottom of Figure 4-10 is, of course, the same data supplied by the call to loggingPackage.LOG_ACTION.
Integrating the Logging Facility
Now that we have a nice logging utility, let’s get it integrated into the existing code. This is a simple task. In Example 4-18, you see the current revision of the main procedure, i.e., update_employees.
Example 4-18. The main (driving) procedure with no logging calls
createorreplacePROCEDUREupdate_employeesASerr_numNUMBER;err_msgVARCHAR2(100);CURSORc_employeeISSELECTename,empno,salFROMempORDERBYsalDESC;BEGINFORr_employeeINc_employeeLOOPupdateEmployeeData(r_employee.ename,r_employee.empno,r_employee.sal);ENDLOOP;EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsDBMS_OUTPUT.PUT_LINE('Ouch, we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorserr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);DBMS_OUTPUT.PUT_LINE('We hit a general exception error number - '||' '||err_num||' Error message: '||err_msg);ROLLBACK;END;
By adding logging to Example 4-18, I produce Example 4-19. Notice that the calls to the logging procedure required a small change to the logging message (i.e., I had to split the string into two parameters).
Example 4-19. The main (driving) procedure with integrated logging calls
createorreplacePROCEDUREupdate_employeesASerr_numNUMBER;err_msgVARCHAR2(100);CURSORc_employeeISSELECTename,empno,salFROMempORDERBYsalDESC;BEGINFORr_employeeINc_employeeLOOPupdateEmployeeData(r_employee.ename,r_employee.empno,r_employee.sal);ENDLOOP;EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsloggingPackage.LOG_ACTION('Ouch','we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorserr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);loggingPackage.LOG_ACTION('We hit a general exception error number - '||' '||err_num||' Error message: '||err_msg,'update_employees');ROLLBACK;END;
Adding logging to the other (helper) procedure is very similar, as shown in Example 4-20.
Tip
It is of course better to improve the INSERT statement by explicitly specifying the target columns as follows:
INSERTINTOtemp(column1,column2,column3)VALUES(value1,value2,value3);
A less obvious point is that this more verbose approach can also help avoid problems with virtual columns, the values of which are derived rather than being stored on disk.
Example 4-20. Data modification procedure with logging integrated
createorreplacePROCEDUREupdateEmployeeData(ENAMEINVARCHAR2,EMPNOINNUMBER,SALINNUMBER)ASBEGINloggingPackage.LOG_ACTION('Employee: '||ENAME||' Number: '||EMPNO||' Salary: '||SAL,'updateEmployeeData');loggingPackage.LOG_ACTION('Success - we got here 1!','updateEmployeeData');INSERTINTOtempVALUES(SAL,EMPNO,ENAME);loggingPackage.LOG_ACTION('Successful insert','updateEmployeeData');END;
The code is now modularized with integrated logging packaged as per the scale of resilience requirement 5.
Let’s now turn our attention to the requirement for simplicity.
Scale of Resilience Requirement 6: Simplicity
Prior to refactoring the code for modularity and the addition of a utility logging package, it was getting a little bit hard to understand. This was on account of cursor resource management and exception handling being mixed in with business logic.
The business logic is of course the database updates that are provided in relation to employee details. The latest code version in Example 4-21 is simple enough and yet it also provides a good deal of capability. How does it stack up in terms of simplicity? This is always a good question to ask when adopting the mindset and work practices of resilience and shift-left.
Example 4-21. The latest version of the main procedure with integrated logging calls
createorreplacePROCEDUREupdate_employeesASerr_numNUMBER;err_msgVARCHAR2(100);CURSORc_employeeISSELECTename,empno,salFROMempORDERBYsalDESC;BEGINFORr_employeeINc_employeeLOOPupdateEmployeeData(r_employee.ename,r_employee.empno,r_employee.sal);ENDLOOP;EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsloggingPackage.LOG_ACTION(('Ouch','we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorserr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);loggingPackage.LOG_ACTION('We hit a general exception error number - '||' '||err_num||' Error message: '||err_msg,'update_employees');ROLLBACK;END;
The exception-handling code and the later modularization effort have been beneficial in that it is probably difficult to make the code in Example 4-21 very much simpler than is currently the case.
Tip
This is one of the merits of using an iterative design approach such as following a scale of resilience. You get what might be called pull-through benefits. That is, by applying careful design patterns and integration techniques, you get modularity, logging, simplicity, and a good foundation for exception and error handling.
Let’s move on from simplicity and take a look at coding conventions.
Scale of Resilience Requirement 7: Coding Conventions
It’s not uncommon to find multiple coding conventions even inside the same organization. This can arise when new entrants join and they have wide experience in similar or different organizations and industries.
Mixing and matching coding conventions can make for complexity across the software development lifecycle. Some developers may favor strong exception handling, while others prefer to put more effort into automation or testing.
Having a standard coding convention is an advantage when the goal is resilient software. Let’s look a little at how to use a basic coding convention. As usual in this book, we can define a few fairly loose requirements as follows:
-
Good comments
-
Consistent variable names
-
Clear formatting
-
Exception handling
-
Testing and automatic test cases
-
Avoiding excessive complexity
The main thrust of these requirements is of course to make the code easier to understand. By following the scale of resilience, we get additional benefits including those that arise from using a coding convention.
The code examples so far have used a few coding styles. This has been done purely to illustrate the flexibility of PL/SQL. Also, it reflects the fact that you are at liberty to choose your own style.
In my own work, I tend to use a single style of coding and then stick to that. Then, later on, if I can’t understand some code I’ve written, I only have myself to blame.
The examples from this point on will aim to adhere to a more rigorous style.
Scale of Resilience Requirement 8: Reusability
Is the code in Example 4-22 reusable? That is, would there be merit in placing this code, or part of it, in a shared package for use by other developers (as we did with the logging feature)?
Note
Experienced PL/SQL developers may insist on all code being placed in a package even if it is just one procedure or function.
Example 4-22. Is this code reusable?
createorreplacePROCEDUREupdateEmployeeData(ENAMEINVARCHAR2,EMPNOINNUMBER,SALINNUMBER)ASBEGINloggingPackage.LOG_ACTION('Employee: '||ENAME||' Number: '||EMPNO||' Salary: '||SAL,'updateEmployeeData');loggingPackage.LOG_ACTION('Success - we got here 1!','updateEmployeeData');INSERTINTOtempVALUES(SAL,EMPNO,ENAME);loggingPackage.LOG_ACTION('Successful insert','updateEmployeeData');END;createorreplacePROCEDUREupdate_employeesASerr_numNUMBER;err_msgVARCHAR2(100);CURSORc_employeeISSELECTename,empno,salFROMempORDERBYsalDESC;BEGINFORr_employeeINc_employeeLOOPupdateEmployeeData(r_employee.ename,r_employee.empno,r_employee.sal);ENDLOOP;EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsloggingPackage.LOG_ACTION(('Ouch','we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorserr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);loggingPackage.LOG_ACTION('We hit a general exception error number - '||' '||err_num||' Error message: '||err_msg,'update_employees');ROLLBACK;END;
In truth, the code in Example 4-22 is not very reusable. Not because it’s bad but more because it is such simple code and it’s very specific to the task at hand. The overall pattern in use in Example 4-22 is certainly reusable. But the specific code itself, not so much.
In general, the case for reusable code tends to arise when dealing with less specific (i.e., more generic) coding tasks, system-level assets, and resources, such as the management of the following:
-
Cursors
-
Files
-
Locking
-
Logging
Having said all that, it is a best practice (and one strongly encouraged by Oracle) to deliver PL/SQL as packaged code. So (as noted at the beginning of this section), on balance I think the effort of producing a package for the type of code in Example 4-22 is outweighed by the benefits.
Note
In Example 4-22, it is also possible to use a SAVEPOINT. Once a SAVEPOINT has been created, you can then either continue processing, commit your work, and roll back the entire transaction, or roll back just to the SAVEPOINT. In other words, SAVEPOINT provides more granular control over the rollback.
As you’ll see in the next section, packaged PL/SQL is compatible with one of the de facto standard PL/SQL test frameworks, utPLSQL.
Let’s now have a look at whether there is scope for repeatable testing in Example 4-22.
Scale of Resilience Requirement 9: Repeatable Testing
In modern development, it is common to use the model of a continuous integration delivery pipeline. In this approach, code is designed, written, tested, and deployed much as in traditional methods.
However, the pipeline approach tends to make heavy use of automated tools to build, deploy, and test the code, as shown (in simple terms) in Figure 4-11.

Figure 4-11. The software development pipeline
The global adoption of Agile methods has resulted in the activities in Figure 4-11 becoming very compressed in time. Very often, the activities overlap such that design and API creation may be considered coding. Likewise, a code check-in to a repository such as Git or Subversion is commonly used to signal the start of an automated build and deployment cycle. At this point, it is also quite common to receive an (often unwelcome) email attributing a build break to you.
Development is therefore no longer a strictly linear set of tasks. For this reason, we as developers need as much help as we can get in the form of:
-
Compiler warnings
-
Automatic test facilities
-
Vulnerability checking
-
Information concerning build issues
In Figure 4-11, much of the behind-the-scenes work, including testing, is automated. Nowadays, automated tests can be run as part of the build procedure and failing tests can result in the build terminating. In other words, tests must pass in order to proceed to the end of the pipeline.
Pretty much all the mainstream programming languages have tools and frameworks for this type of automated testing and PL/SQL is no exception. In any case, the database repository–based approach is a useful and instructive test method, which I’ve used myself. We will instead focus on a different technique for PL/SQL unit testing, one that uses the utPLSQL product. Let’s have a look at how to get started with this interesting technology by getting it installed into the Docker-containerized Oracle Database setup.
Note
There is a facility for unit testing built into the Oracle Database. To use the Oracle-centric testing, it is necessary to create a special-purpose unit test repository.
On shared databases (i.e., installations not using a Docker-based Oracle setup), it is often necessary to request this repository setup from a database administrator. This does add an extra step to getting set up with PL/SQL unit testing and it may act as a disincentive to team environments where there is a preference to keep such work internal to the team. It’s worth remembering that, as we are using a Docker-based Oracle Database installation, there is a little more latitude than is normally the case when you are using a shared database.
Installing utPLSQL
The following commands require that your Docker container is running. So, make sure to run the usual startup command:
dockerstart<CONTAINER_ID>
As usual, you need to supply your own container ID, which you get by running the command:
dockercontainerls-a
Now open a command prompt in the Docker container
dockerexec-itw/home/oracle/<CONTAINER_ID>bash
This command opens a prompt in the directory /home/oracle. Type pwd to verify the path is /home/oracle. Next, download the most recently released utPLSQL ZIP file from GitHub. The utPLSQL version may well be different from v3.1.12 by the time you’re reading this:
curl\https://github.com/utPLSQL/utPLSQL/releases/download/v3.1.12/utPLSQL.zip\-L-outPLSQL.zip
Tip
Run the Linux commands in this section on one line only. If you need to separate a command so that it occupies two lines, then add “\” at the end of each line as shown.
For multiline Windows commands in a basic command prompt window, you can use the character “^” to continue a command across a line boundary, for example:
dockerexec-itw/home/oracle/utPLSQL/source^380195f59d0dbash-c^"source /home/oracle/.bashrc; sqlplus /nolog"
Optionally, run ls -l to verify that the ZIP file is not a 0-byte file, i.e., indicating that the download failed for some reason (such as supplying an incorrect URL). Then, extract the downloaded ZIP file:
unzip-qutPLSQL.zip
Next, you need to create a schema in the Oracle Database, and this is done by connecting using sqlplus with the SYS account. For simplicity, you can exit the current command prompt—just type exit and press Enter.
Now, open a new command prompt in the Docker container (again supplying your own local container ID):
dockerexec-itw/home/oracle/utPLSQL/source<CONTAINER_ID>\bash-c"source /home/oracle/.bashrc; sqlplus /nolog"
This opens a command prompt in the directory /home/oracle/utPLSQL/source. Next, type connect sys as sysdba;. At this point, you are prompted for a password. Use the password you provided in the setup back in Example 2-1. I used mySyspwd1.
Next, run the following command:
altersessionset"_ORACLE_SCRIPT"=true;
Then, run this command to create the ut3 user:
@create_utplsql_owner.sqlut3ut3users;
Note
Use !pwd to see the current directory. This command did disconnect my session from the database. Just make sure you’re in the correct directory. The installation seems to be a little fussy about running from this directory: /home/oracle/utPLSQL/source.
Next, run this command (which takes a few minutes):
@install.sqlut3;
List schemas using this command:
selectusernameasschema_namefromsys.dba_usersorderbyusername;
In SQL Developer, under Other Users, you should now see the user UT3. Click Packages to see the required framework packages. Also, click Tables to verify the framework tables are installed.
Run the following command to allow access to public for user ut3. This gives access to all users. Normally, just one user is provided access, but for the Docker setup, the public option is fine:
@create_synonyms_and_grants_for_public.sqlut3;
The next two steps are optional. They grant access to a specific user by running this command (a username is required):
@create_user_grants.sqlut3<Specific_user>;@create_user_synonyms.sqlut3<Specific_user>;
If the utPLSQL installation was successful, then you can exit both sqlplus and the bash session. You’re now ready to create a utPLSQL unit test.
Creating a utPLSQL Unit Test in SQL Developer
An implicit assumption with utPLSQL is that the code you want to test must reside in a package. This is a reasonable and useful requirement, given that packaged PL/SQL provides the foundation for the following:
-
Shareability
-
Generality
-
Simplicity
-
Modularity
So, forcing us to write packaged PL/SQL helps in producing better-quality code. Let’s now create a simple utPLSQL unit test suite:
CREATEORREPLACEPACKAGEtest_LOGGINGPACKAGEIS--%suite--%suitepath(alltests)--%testPROCEDURELOG_ACTION;ENDtest_LOGGINGPACKAGE;
As you learned earlier in the chapter, a package specification needs a body where the LOG_ACTION procedure is implemented. This is done in Example 4-23.
As you’ve done in earlier chapters, it’s a good idea to try to figure out what the code in Example 4-23 is trying to achieve.
Example 4-23. The test procedure
CREATEORREPLACEPACKAGEBODYtest_LOGGINGPACKAGEASPROCEDURELOG_ACTIONISl_actualINTEGER:=0;l_expectedINTEGER:=1;BEGINdeletefromLOGGING;loggingpackage.log_action('An action','A log message');selectcount(*)intol_actualfromlogging;ut.expect(l_actual).to_equal(l_expected);--to_equalisthematcherENDLOG_ACTION;ENDtest_LOGGINGPACKAGE;
In general, in unit testing, the aim is to set up an expected result and then call the code under test and verify whether the actual result matches the expected result. Here, we’re expecting a value of 1.
Clears down the
LOGGINGtable and calls thelog_actionprocedure from the packageloggingpackage. After clearing theLOGGINGtable and callinglog_action, it’s safe to assume I will have a single row in the table (at least in the context of this session), which explains our assumption in.
Verifies the expected condition. This line simply counts the number of rows in the
LOGGINGtable and stores the result in thel_actualvariable. By deduction, this value is1.
Compares the two values.
And that’s the test. If the two values match, the test passes. If they don’t match, the test fails.
Running a utPLSQL Unit Test
Let’s have a look at how running the test happens in a normal unit test workflow. Before I get into test creation, look at Figure 4-12, which illustrates a failing test.
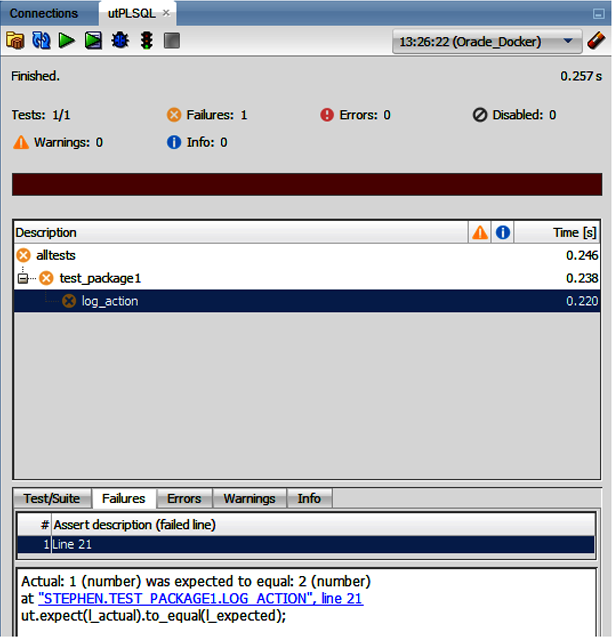
Figure 4-12. A test failure
I forced the test in Figure 4-12 to fail by making a small change to the expected result, as shown in Example 4-24.
Example 4-24. A failing test
procedurelog_actionisl_actualinteger:=0;l_expectedinteger:=2;begin--arrange--act--package1.log_action;deletefromLOGGING;PACKAGE1.log_action('An action','A log message');selectcount(*)intol_actualfromlogging;--assertut.expect(l_actual).to_equal(l_expected);endlog_action;
We know the
LOGGINGtable is cleared at the beginning of the test and then one row is added. So, if the test is to pass, the expected number of rows should be1and not2, as shown here.
Having done all this, we now know what a failing test looks like in SQL Developer, as shown in Figure 4-12. Let’s get back to creating a utPLSQL unit test from scratch.
In SQL Developer, you can employ a nice, easy method for creating the test. This does require installation of the utPLSQL plug-in as described in “Installing utPLSQL”. Starting with the package you want to test, right-click the package containing the logging code. This opens the context menu, as shown in Figure 4-13.
Figure 4-13. Generating a test suite
Select the highlighted option:
GenerateutPLSQLTest
This produces the boilerplate code in Example 4-25.
Example 4-25. Boilerplate test code
createorreplacepackagetest_package1is--generatedbyutPLSQLforSQLDeveloperon2022-06-0213:47:44--%suite(test_package1)--%suitepath(alltests)--%testprocedurelog_action;endtest_package1;createorreplacepackagebodytest_package1is--generatedbyutPLSQLforSQLDeveloperon2022-06-0213:47:44----testlog_action--procedurelog_actionisl_actualinteger:=0;l_expectedinteger:=1;begin--arrange--act--package1.log_action;--assertut.expect(l_actual).to_equal(l_expected);endlog_action;endtest_package1;
This is really useful! I now have a basic test ready for use. Let’s just add a few lines into the procedure log_action in Example 4-25 as follows:
procedurelog_actionisl_actualinteger:=0;l_expectedinteger:=1;begin--arrange--act--package1.log_action;deletefromLOGGING;PACKAGE1.log_action('An action','A log message');selectcount(*)intol_actualfromlogging;--assertut.expect(l_actual).to_equal(l_expected);endlog_action;
Now, select all, right-click, and then select the Run Statement menu option, as shown in Figure 4-14.
Figure 4-14. Compiling the test code
If all is well, you should see the following message in the result window:
PackageBodyTEST_PACKAGE1compiled
At this point, the test package (called TEST_PACKAGE1) is stored in the database. Click the refresh button and then open the Packages control, and it should look somewhat like Figure 4-15.
Figure 4-15. The new test package
All that remains is to run the test in Figure 4-15. Do this by right-clicking the package called TEST_PACKAGE1, as shown in Figure 4-16, and clicking the highlighted option “Run utPLSQL test.”
Figure 4-16. Launching the new test
After running the test, the result should look somewhat like Figure 4-17.
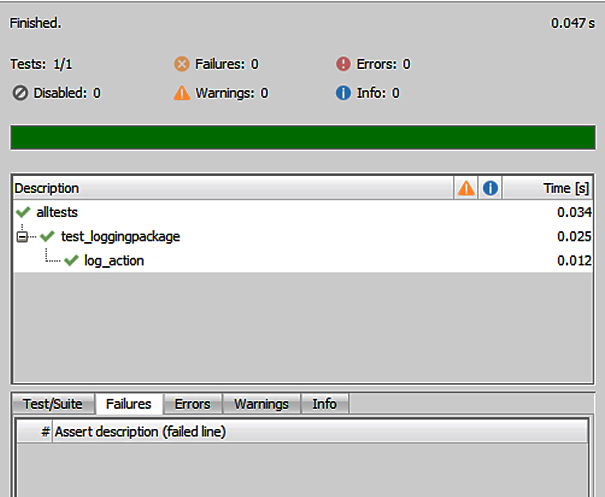
Figure 4-17. The result of the new test
A green bar indicates that the test was successful. I’ll now make a minor change (as was done earlier in this section) to the test code. This is to ensure that a failure occurs in the test. Remember I noted earlier that errors are good teachers? This also applies in the case of test code.
As before, I change the value of l_expected to 2 instead of 1:
PROCEDURElog_actionISl_actualINTEGER:=0;l_expectedINTEGER:=2;BEGIN--arrange--act--package1.log_action;DELETEFROMLOGGING;PACKAGE1.log_action('An action','A log message');SELECTCOUNT(*)INTOl_actualFROMlogging;--assertut.expect(l_actual).to_equal(l_expected);ENDlog_action;
Then, select all, right-click, and select Compile. At this point the updated package should be stored in the database, ready for use. Right-click the test package and run the test. The result of this should appear somewhat similar to Figure 4-18. Test failures are clearly indicated with a red bar along with the following explanatory text describing the issue:
Actual:1(number)wasexpectedtoequal:2(number)at"STEPHEN.TEST_PACKAGE1.LOG_ACTION",line20ut.expect(l_actual).to_equal(l_expected);
The error report indicates that the number 1 was expected to equal the number 2. As this is not a valid comparison, the test is correctly marked as a failure.
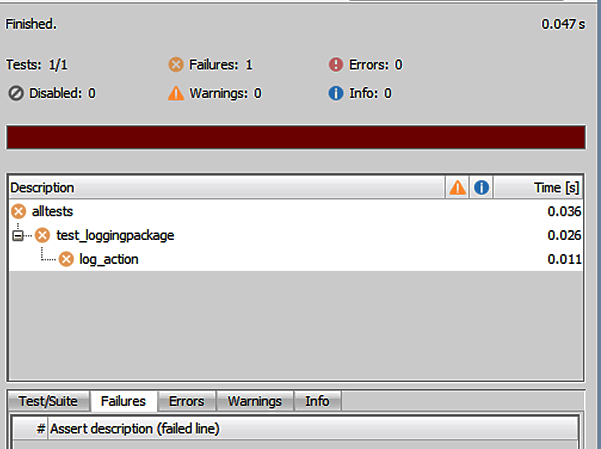
Figure 4-18. The test is now failing
So, that’s a rapid tour of the full workflow for utPLSQL unit tests, namely:
-
Generating
-
Running
-
Modifying
-
Rerunning
It’s clear that unit testing tends to be something of an iterative process. The examples were chosen to be simple but illustrative of the procedures required for a test-centric development process.
I’ll return to testing later in the book (in Part III). But for now the message to retain is that testing should afford the developer a high degree of confidence that the code is in good shape and that the system functions correctly.
There is of course no substitute for feedback from expert user-driven testing. But automatic tests should provide a close second. Good unit tests can flush out many minor issues, leaving the more complex test cases either to other automated tests or to your human testers.
So, we now have some utPLSQL tests that can help verify that the logging code is working correctly. Clearly, this could be extended to include the other code.
In general, tests should be written to exercise any important application code. What do I mean by important? Well, important code is that which underpins your application—that which your application couldn’t survive without.
Let’s now move on to look at how to avoid common antipatterns.
Scale of Resilience Requirement 10: Avoiding Common Antipatterns
Let’s have a look at the code now that it has been passed through nine stages of the scale of resilience:
CREATEORREPLACEPROCEDUREupdateEmployeeData(ENAMEINVARCHAR2,EMPNOINNUMBER,SALINNUMBER)ASBEGINloggingPackage.LOG_ACTION('Employee: '||ENAME||' Number: '||EMPNO||' Salary: '||SAL,'updateEmployeeData');loggingPackage.LOG_ACTION('Success - we got here 1!','updateEmployeeData');INSERTINTOtempVALUES(SAL,EMPNO,ENAME);loggingPackage.LOG_ACTION('Successful insert','updateEmployeeData');END;CREATEORREPLACEPROCEDUREupdate_employeesASerr_numNUMBER;err_msgVARCHAR2(100);CURSORc_employeeISSELECTename,empno,salFROMempORDERBYsalDESC;BEGINFORr_employeeINc_employeeLOOPupdateEmployeeData(r_employee.ename,r_employee.empno,r_employee.sal);ENDLOOP;EXCEPTIONWHENNO_DATA_FOUNDTHEN--catchesall'no data found'errorsloggingPackage.LOG_ACTION(('Ouch','we hit an exception');ROLLBACK;WHENOTHERSTHEN--handlesallothererrorserr_num:=SQLCODE;err_msg:=SUBSTR(SQLERRM,1,100);loggingPackage.LOG_ACTION('We hit a general exception error number - '||' '||err_num||' Error message: '||err_msg,'update_employees');ROLLBACK;END;
We also have a logging procedure, which resides in a shared package:
PROCEDURELOG_ACTION(action_messageINVARCHAR2,code_locationINVARCHAR2)ISPRAGMAAUTONOMOUS_TRANSACTION;BEGININSERTINTOLOGGING(EVENT_DATE,action_message,code_location)VALUES(SYSDATE,action_message,code_location);COMMIT;END;
What types of antipatterns should we look out for? We have already addressed some common antipatterns. Some of the more common antipatterns include:
-
Code that is too long
-
Overly complex code
-
Lack of exception/error handling
-
Exceptions that we decide to live with
-
Lack of modularity
-
Crashes with no known root cause
Let’s take a look at each of these in turn.
Code That Is Too Long
There is often a temptation to just write big blocks of code. In fact, we saw this very issue back in Figure 1-1. Such large blocks of code are hard to understand. Perhaps a less obvious issue is that they are also hard to test.
It is best to break down large chunks of code into smaller units using additional procedures and functions. This is a passing reference to the old Linux principle of doing one thing well.
If each of your procedures and functions does just one thing well, then your code has the additional merit of being simpler. When the time then comes to create unit tests for the code, you can right-click on the procedure and generate a utPLSQL test template.
If your procedures are kept short and sweet, then the creation of the working unit test boils down to just pasting some key PL/SQL code into the test procedure. Remember, each unit test is a bit like having a dedicated inspector for the associated code. The inspector then keeps an eye on the code each time the test is run. Any issues, such as passing bad data into the procedure, should then result in a failed test result. This alerts you to a possible problem.
This is a further example of one of the pull-through benefits of adhering to the scale of resilience model.
Overly Complex Code
It’s quite common nowadays to look at code and come away puzzled. Java lambda code is a good example. It’s a similar story with JavaScript and Python. There seems to often be a desire to make code written in these languages hard to understand, which in turn can make it harder to test and verify. Worse still is the difficulty that arises when complex code has to be changed.
It’s best to aim to keep PL/SQL code as simple as possible. Splitting code into smaller blocks is a good habit to develop. As you saw in the previous section, this stepwise refinement also pays dividends in the form of making the unit tests easier to write.
Tip
If you really must use a complex mechanism, then try to document it in order to help a downstream maintainer.
Lack of Exception/Error Handling
We’ve looked in some detail at the issue of exception handling. Not catering rigorously to exceptions is an example of a risky shortcut. It saves you some time now, but later on it can be problematic when exceptions start to arise in your code.
Without handling or at the very least logging exceptions, you may be forced into trying to guess why certain problems arise. Guess-based diagnosis is invariably wrong, and you may then apply code changes based on an inaccurate understanding of the problem that occurred.
Exception management code is a good friend. Treat it well and it will return the compliment.
Exceptions That You Decide to Live With
When looking through log data from running code, it’s quite common to see exceptions that occur all the time. Very often, the established developers will say that a given exception always occurs and has never been fixed. Living with exceptions is a really bad idea.
Exceptions are an indication that something may be seriously wrong with the code and its interaction with the runtime system. At the very least, all exceptions should be investigated and a determination made about their severity.
Even if an exception turns out to be a harmless logic error, the generated output will clutter up your logs. This can make it more difficult to diagnose a real problem. Which is easier in general: a 1 MB logfile, or one that is 500 MB, where the latter has loads of legacy exception data?
Tip
When an exception occurs, it’s best to try to fix the underlying issue.
Lack of Modularity
Earlier in this chapter, you saw the benefits of modularity. Modular code is perhaps a little harder to write than is the case with larger blocks. But modular code gives us a number of advantages:
-
Modular code is simpler and easier to understand.
-
Modular code can be shared in packages.
-
It is easier to test, even allowing for automatic test generation.
As with exception handling, not producing modular code might initially save you a little time, but in the longer term those savings are lost if the code proves to be brittle or insufficiently tested.
Crashes with No Known Root Cause
The unknown crash or runtime failure is a more common occurrence than might be supposed. Surprisingly, such crashes can occur when unexpected data is pushed through a system. A typical case of this is in date string handling, where the code expects a US date format such as 12/15/2022, i.e., MM/DD/YYYY. However, instead of US format, a European date format is used: 15/12/2022, i.e., DD/MM/YYYY.
In some cases, a simple oversight such as this can result in a fatal runtime error when an attempt is made to parse the unexpected date format—by trying to find the 12th day of the 15th month in the year. For this reason, it is prudent to check how a given library call handles such unexpected cases. It may be far more preferable to simply log this and return a default or placeholder value rather than allowing a runtime failure to occur.
A major difficulty with allowing runtime failures is that the normal exception pathway may be bypassed. In other words, the date format parsing code simply doesn’t expect the wrong format to be presented and exits in an unexpected fashion. The lack of any log data can make this type of bug into one of the ones that never gets fixed.
Scale of Resilience Requirement 11: Schema Evolution
Let’s now turn our attention to the important topic of schema evolution. In Example 4-26, you see the original schema that was introduced in “A Simple Schema”.
Example 4-26. Schema creation SQL
CREATETABLEemp(enameVARCHAR2(10),empnoNUMBER(4),salNUMBER(7,2));CREATETABLEtemp(enameVARCHAR2(10),empnoNUMBER(4),salNUMBER(7,2));INSERTINTOemp(ename,empno,sal)VALUES('John',1000,40000.00);INSERTINTOemp(ename,empno,sal)VALUES('Mary',1001,40000.00);commit;
Schema evolution refers to the way in which a given schema changes over time. Such changes are generally in response to updated business requirements or simple fixes and refactoring. The types of changes that occur in schema evolution can include:
-
Column addition
-
Column removal
-
Column renaming
-
Table addition
-
Table name changes
In fact, the schema shown in Example 4-26 is not of particularly high quality for the following reasons:
-
Unclear table names
-
No primary keys
-
No data constraints
I’ll discuss how to fix these issues shortly. In the meantime, let’s have a look at the LOG_ACTION procedure in Example 4-27 in the context of schema evolution.
Example 4-27. LOG_ACTION without accommodating possible schema evolution
PROCEDURELOG_ACTION(action_messageINVARCHAR2,code_locationINVARCHAR2)ISPRAGMAAUTONOMOUS_TRANSACTION;BEGININSERTINTOLOGGING(EVENT_DATE,action_message,code_location)VALUES(SYSDATE,action_message,code_location);COMMIT;END;
Notice in Example 4-27 the parameters to LOG_ACTION:
PROCEDURELOG_ACTION(action_messageINVARCHAR2,code_locationINVARCHAR2)
This parameter definition is not tied to the underlying database table columns. So, if we change the latter so that they no longer match the procedure parameters, then the procedure won’t work correctly. This issue is resolved with the use of anchored declarations, as shown in Example 4-28. By using anchored declarations, the procedure will only become invalid if one (or more) of the anchors are modified.
Example 4-28. LOG_ACTION accommodating possible schema evolution
PROCEDURELOG_ACTION(action_messageINlogging.action_message%TYPE,code_locationINlogging.code_location%TYPE)ISPRAGMAAUTONOMOUS_TRANSACTION;BEGININSERTINTOLOGGING(EVENT_DATE,action_message,code_location)VALUES(SYSDATE,action_message,code_location);COMMIT;END;
If a subsequent change is made to the LOGGING table (such as extending the length of the ACTION_MESSAGE column), then we need only recompile the stored procedure and the code will once again be tied to the new columns. This eliminates a common source of error in the PL/SQL code, i.e., data type mismatch.
The changes in Example 4-29 illustrate an effort to improve the schema quality.
Example 4-29. Better-quality schema creation SQL
CREATETABLEEMPLOYEE(IDNUMBERGENERATEDALWAYSASIDENTITY,employee_nameVARCHAR2(10)NOTNULL,employee_numberNUMBER(4)NOTNULL,salaryNUMBER(7,2));CREATETABLEPROCESSED_EMPLOYEE(IDNUMBERGENERATEDALWAYSASIDENTITY,employee_nameVARCHAR2(10)NOTNULL,employee_numberNUMBER(4)NOTNULL,salaryNUMBER(7,2));INSERTINTOEMPLOYEE(employee_name,employee_number,salary)VALUES('John',1000,40000.00);INSERTINTOEMPLOYEE(employee_name,employee_number,salary)VALUES('Mary',1001,40000.00);commit;
In Example 4-29, the table names have been updated to improve readability. Also, autogenerated primary keys have been added. The other column names have also been updated to improve readability and data constraints have been added.
To implement these data changes, it would be necessary to use RENAME and ALTER. Obviously, the associated PL/SQL would also have to be modified to suit.
Scale of Resilience Change Summary
The original PL/SQL code has now been filtered through the scale of resilience. Having applied the changes, how does the new code score? In Table 4-2, I record the new scores with the old values in parentheses.
| Requirement number | Resilience requirement | Score (0–10) |
|---|---|---|
1 |
Capture all errors and exceptions |
10 (0) |
2 |
Recoverability |
10 (2) |
3 |
Observability |
10 (0) |
4 |
Modifiability |
8 (5) |
5 |
Modularity |
10 (2) |
6 |
Simplicity |
10 (5) |
7 |
Coding conventions |
8 (5) |
8 |
Reusability |
8 (2) |
9 |
Repeatable testing |
6 (2) |
10 |
Avoiding common antipatterns |
8 (0) |
11 |
Schema evolution |
8 (0) |
TOTAL SCORE |
96 (23) |
That’s a significant improvement over the original score. Areas that could use more work are adherence to coding conventions and unit testing. While the code in question is very simple, the approach used is a good template for future PL/SQL work.
In Part III, I’ll use the scale of resilience up front, i.e., for new code rather than for refactoring legacy code.
Summary
PL/SQL code errors are good teachers. The resolution of such errors forces you to adopt a rigorous approach. The shift-left method is an example of such an approach, where a key goal is to push errors in the direction of developers rather than users. It is the former who can do something about the errors whereas for the latter, errors can result in a loss of confidence about the solution.
The scale of resilience can be applied to PL/SQL code multiple times. It was revisited in this chapter following the refactoring modifications. The new code scored much better than was the case for the original version.
Exception handling requires particularly delicate handling, taking care to never swallow all exceptions, which is an egregious antipattern that may subsequently thwart future error resolution.
You also saw the way exception handling can be narrowed down in a given PL/SQL procedure. This allows for the propagation of exceptions not handled by that procedure to move up the chain to a more appropriate handler location. Exception handling is a key design issue that can greatly facilitate future remediation efforts.
Autonomous transactions allow for an originating transaction to be suspended until the autonomous transaction is committed or rolled back. This mechanism is crucial for supporting design patterns, such as effective PL/SQL logging. The simple logging mechanism described in this chapter is purely for illustration. An open source alternative logger is available here.
The application of a scale of resilience can be viewed as a type of filter. The model can be thought of as: “You push your PL/SQL code through the filter and it comes out the other side in better shape.”
PL/SQL packages are strongly encouraged by Oracle and they represent an important part of achieving modularity. Unit testing is also extremely important and for this you can use products, such as utPLSQL. Good tests should function somewhat like a really good human tester.
Root cause analysis can be facilitated by adhering to the scale of resilience approach.
In the next chapter, you’ll see feature development in the context of PL/SQL, starting with how to invoke PL/SQL code from Java.
Get Resilient Oracle PL/SQL now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

