In addition to our initial effort to use an actor-critic method to reduce variance, we can also reduce variance by subtracting a baseline function 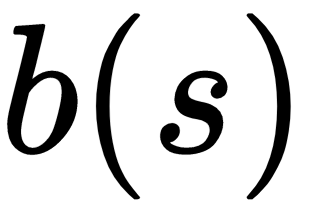 from the policy gradient. This will reduce the variance without affecting the expectation value as shown in the following:
from the policy gradient. This will reduce the variance without affecting the expectation value as shown in the following:

There are many options to choose a baseline function but state value function is regarded to be a good baseline function. Therefore:
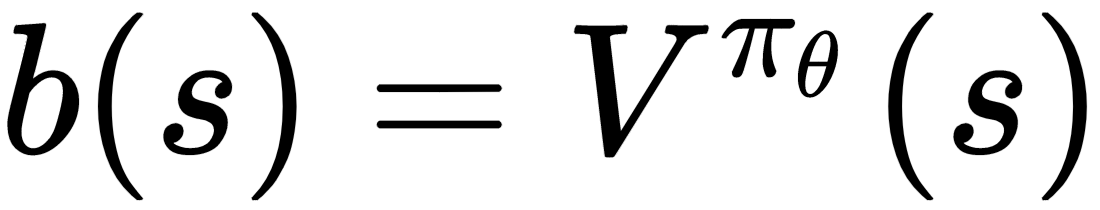
Thus, ...

