Now, the first thing we need to clarify is how to sample from the environment, and how to interact with it to get usable information about its dynamics:

Figure 4.1. A trajectory that starts from state 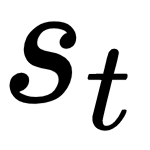
The simple way to do this is to execute the current policy until the end of the episode. You would end up with a trajectory as shown in figure 4.1. Once the episode terminates, the return values can be computed for each state by backpropagating upward the sum of the rewards, . Repeating this process multiple times (that is, running ...

