Throughout the learning, we monitored many parameters, including p_loss (the loss of the policy), old_p_loss (the policy's loss before the optimization phase), the total rewards, and the length of the episodes, in order to get a better understanding of the algorithm, and to properly tune the hyperparameters. We also summarized some histograms. Look at the code in the book's repository to learn more about the TensorBoard summaries!
In the following figure, we have plotted the mean of the total rewards of the full trajectories that were obtained during training:
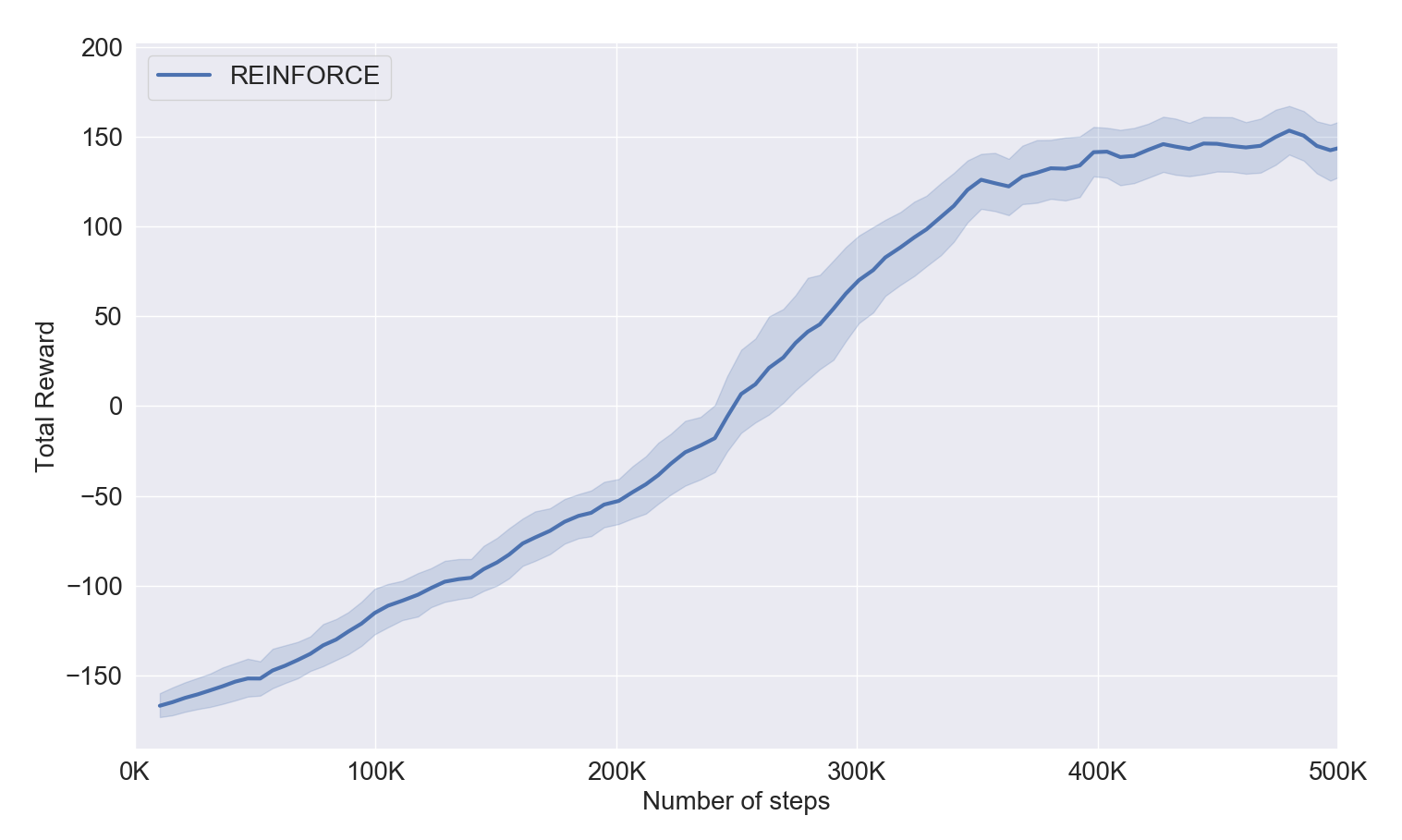
From this plot, we can see that it reaches a mean score of ...

