Chapter 4. Testing in Action
In the last chapter, we looked at some common objections to testing, and explored the benefits that can hopefully overwhelm those objections. If they can’t for your project, then there’s a strong possibility that either your team doesn’t have the strongest engineering culture (quite possibly for reasons out of their control), or you haven’t quite turned the corner on being able to write tests fast enough to justify their benefits.
In this chapter, we’re getting into the details of how to test in the following scenarios:
- New code from scratch
- New code from scratch with TDD
- New features
- Untested code
- Debugging and regression tests
At the risk of beating a dead horse, you can’t refactor without tests. You can change code, but you need a way to guarantee that your code paths are working.
Refactoring without tests: A historical note
In the original 1992 work on refactoring, “Refactoring Object-Oriented Frameworks” by William Opdyke (and advised by Ralph Johnson of “Design Patterns” fame), the word test appears only 39 times in a 202-page paper. However, Opdyke is insistent on refactoring as a process that preserves behavior. The term invariant appears 125 times, and precondition comes up frequently as well.
In a nonacademic setting, 25 years after the original work, and in JavaScript, with its rich ecosystem of testing tools, the mechanisms of preserving behavior are best facilitated by the processes we discuss in this book, and especially this chapter.
However, if you’re curious about the initial ideas that went into refactoring, in a context likely a bit removed from your day job, checking out the original work is highly recommended.
New Code from Scratch
Say we get the following specification from our boss or client:
Build a program that, given an array of 5 cards (each being a string like
'Q-H'for queen of hearts) from a standard 52-card deck, prints the name of the hand ('straight','flush','pair', etc.).
So how do we start? How about with a checkHand function? First, create a file and save it as check-hand.js. If you run it with node check-hand.js right now, nothing will happen. It’s just a blank file.
Be careful with ordering of function expressions
In this chapter, we use the syntax:
var functionName = function(){
// rather than
function functionName(){
Either style is fine, but in the first one (function expressions) the order in which you define your functions matters. If you get this error:
TypeError: functionName is not a function
then you should rearrange your functions or use the second syntax. We’ll discuss this (along with the idea of “hoisting”) more in Chapter 6.
We can start by writing a function that is basically a large case statement:
varcheckHand=function(hand){if(checkStraightFlush(hand)){return'straight flush';}elseif(checkFourOfKind(hand)){return'four of a kind';}elseif(checkFullHouse(hand)){return'full house';}elseif(checkFlush(hand)){return'flush';}elseif(checkStraight(hand)){return'straight';}elseif(checkThreeOfKind(hand)){return'three of a kind';}elseif(checkTwoPair(hand)){return'two pair';}elseif(checkPair(hand)){return'pair';}else{return'high card';}};console.log(checkHand(['2-H','3-C','4-D','5-H','2-C']));
The last line is typical of something we’d add to ensure things are still behaving. While we’re working, we might adjust this statement, or add more. If we’re honest with ourselves, this console.log is a test case, but it’s very high-level, and the output isn’t structured. So in a way, adding lines like this is like having tests, but just not great ones. Probably the strangest part about doing things this way is that once we have 8 or 10 print statements, it will be hard to keep track of what means what. That means we need some structure to the format of our output. So we add things like:
console.log('value of checkHand is '+checkHand(['2-H','3-C','4-D','5-H','2-C']));
Breaking up long lines of code
Notice that we’re sometimes breaking up lines so that they don’t run off the edge of the page. We’ll talk about the specifics of how to deal with long lines in later chapters, but for now just trust that these breaks are okay.
Once we start doing this, we’re actually doing the job of the test runner part of a test framework: one with very few features, but tons of duplication and inconsistency. Natural as it might be, this is a sure path to guesswork and frustration with temporary fits of confidence.
Instinctively, new coders will manually test like this as they write the code, and then delete all of the console.log statements afterward, effectively destroying any test-like coverage that they had. Because we know that tests are important, we will get our coverage back after we’ve written the tests, but isn’t it odd to write these tiny, weird tests, delete them, and then write better versions after?
So what’s next? Well, you take off for a week, and your coworkers start implementing these check methods, manually testing with console along the way to “see if it’s working.”
And you come back to this:
// not just multiplescheckStraightFlush=function(){returnfalse;};checkFullHouse=function(){returnfalse;};checkFlush=function(){returnfalse;};checkStraight=function(){returnfalse;};checkStraightFlush=function(){returnfalse;};checkTwoPair=function(){returnfalse;};// just multiplescheckFourOfKind=function(){returnfalse;};checkThreeOfKind=function(){returnfalse;};checkPair=function(){returnfalse;};// get just the valuesvargetValues=function(hand){console.log(hand);varvalues=[];for(vari=0;i<hand.length;i++){console.log(hand[i]);values.push(hand[i][0]);}console.log(values);returnvalues;};varcountDuplicates=function(values){console.log('values are: '+values);varnumberOfDuplicates=0;varduplicatesOfThisCard;for(vari=0;i<values.length;i++){duplicatesOfThisCard=0;console.log(numberOfDuplicates);console.log(duplicatesOfThisCard);if(values[i]==values[0]){duplicatesOfThisCard+=1;}if(values[i]==values[1]){duplicatesOfThisCard+=1;}if(values[i]==values[2]){duplicatesOfThisCard+=1;}if(values[i]==values[3]){duplicatesOfThisCard+=1;}if(values[i]==values[4]){duplicatesOfThisCard+=1;}if(duplicatesOfThisCard>numberOfDuplicates){numberOfDuplicates=duplicatesOfThisCard;}}returnnumberOfDuplicates;};varcheckHand=function(hand){varvalues=getValues(hand);varnumber=countDuplicates(values);console.log(number);if(checkStraightFlush(hand)){return'straight flush';}elseif(number==4){return'four of a kind';}elseif(checkFullHouse(hand)){return'full house';}elseif(checkFlush(hand)){return'flush';}elseif(checkStraight(hand)){return'straight';}elseif(number==3){return'three of a kind';}elseif(checkTwoPair(hand)){return'two pair';}elseif(number==2){return'pair';}else{return'high card';}};// debugger;console.log(checkHand(['2-H','3-C','4-D','5-H','2-C']));console.log(checkHand(['3-H','3-C','3-D','5-H','2-H']));
Oh no! What happened? Well, first we decided to make sure pairs worked, so we made every other function return false so that only the pair condition would be triggered. Then we introduced a function to count the number of duplicates, which required getting the values of the cards. We reused this function for four and three of a kind, but it doesn’t seem very elegant. Also, our getValues function is going to break with a value of 10, because it will return a 1, aka an ace. Note that the [0] in the following line takes the first character of the string:
values.push(hand[i][0]);
So we have one very rough implementation, one bug that we may or may not have noticed, half of the functions implemented, half of them replaced with inline variables, and a lot of console.log statements in place as sanity checks. There’s no real consistency in what was logged—these statements were introduced at points of confusion. We also have commented out a place where we might have had a debugger earlier.
Where do we go from here? Fix the bug? Implement the other functions? Hopefully, the last three and a half chapters have convinced you that attempting to improve the countDuplicates function would not be refactoring at this point. It would be changing code, but it would not be a safe process we could be confident in.
If we’re testing after rather than before, how long should we wait? Should we add tests now? Should we finish our attempt at implementation first?
Later, we’ll deal with a legacy system that we have to basically trust, but at this point, we’ve just started this code. No one is relying on it yet, so we can feel free to throw away all the bad parts. What does that leave us with? Take a look:
console.log(checkHand(['2-H','3-C','4-D','5-H','2-C']));console.log(checkHand(['3-H','3-C','3-D','5-H','2-H']));
Yes. Just the high-level test cases. Let’s use these and start over, with one tiny transformation:
varassert=require('assert');assert(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair');assert(checkHand(['3-H','3-C','3-D','5-H','2-H'])==='three of a kind');
Instead of printing with console.log, let’s use node’s assert library to assert that checkHand returns the values that we want. Now when we run the file, if anything inside of the assert function throws an error or is false, we’ll get an error—no print statements necessary. We just assert that running our function with that input returns the expected strings: 'pair' and 'three of a kind'.
We also added a line to the beginning. This simply makes the assert statement available from node’s core libraries. There are more sophisticated testing framework choices, but this involves minimal setup.
Before we move on, let’s look at a flow chart to introduce all of the possibilities of what code we need to write when (Figure 4-1).
Note
Keep in mind that if you’re not writing tests first, you’re following the “untested code” path rather than the “new code” path.
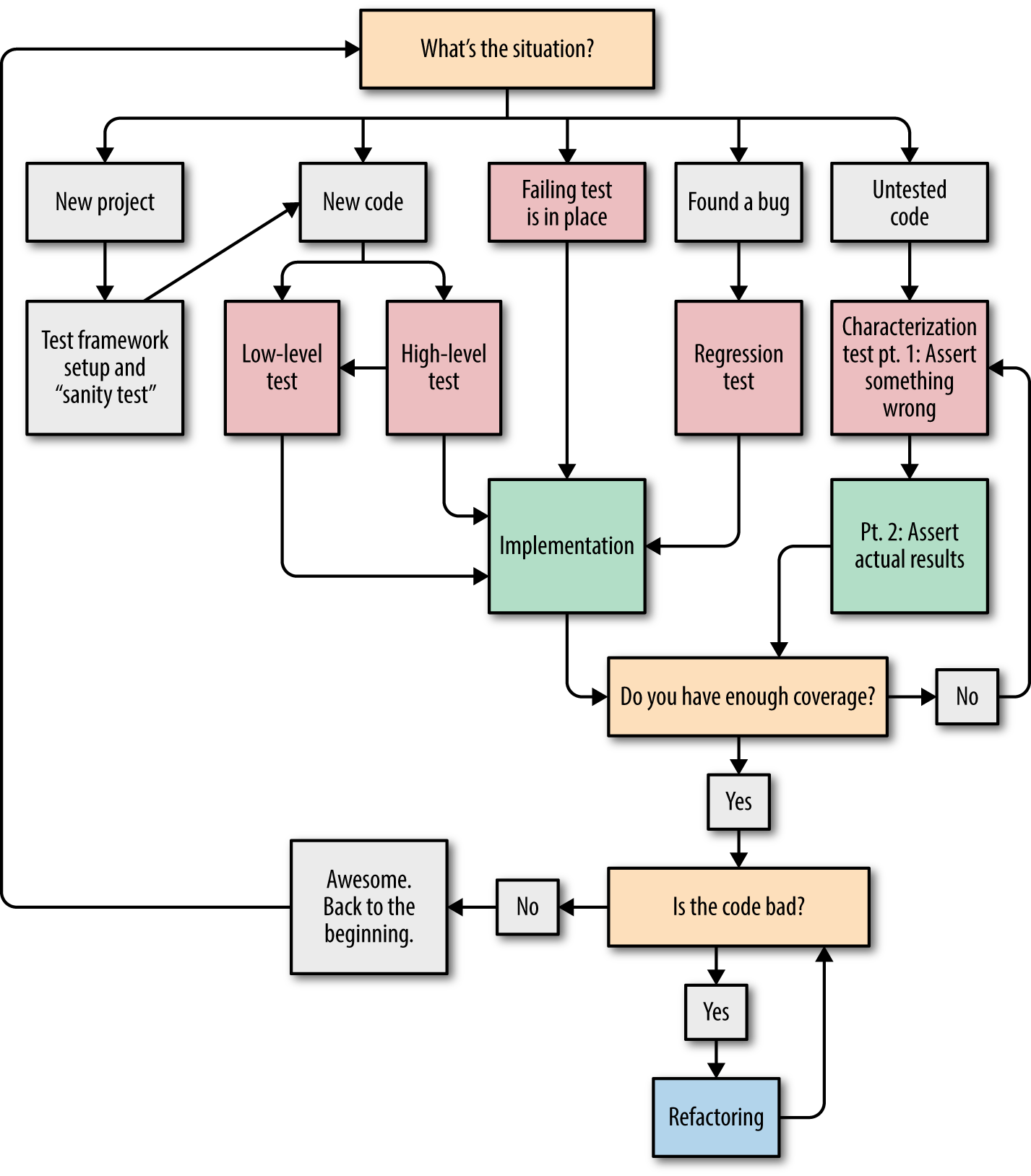
Figure 4-1. Flow chart to help you determine whether to write a test, refactor, or implement the code to make your test pass
New Code from Scratch with TDD
Of course, not all new code written without tests is going to end up in as awkward a state as that in the last section. It is certainly not reflective of an experienced coder’s best efforts. However, it is reflective of a lot of coders’ first effort. The wonderful thing about refactoring is that, given enough test coverage and confidence, your first effort doesn’t have to be your best effort. Get the tests passing, and you have the flexibility to make your code better afterward.
About TDD and red/green/refactor
This section jumps between lots of short code samples. This might seem tedious, but making tiny changes makes it much easier to discover and fix errors more quickly.
If you’ve never done TDD before, actually typing the samples out and running the tests in this section will give you a good idea of how the pacing works. Even if TDD isn’t something that you rely on all the time, knowing how to use tests for immediate feedback is valuable.
Okay, back to our checkHand code. Let’s just start with this:
varassert=require('assert');assert(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair');assert(checkHand(['3-H','3-C','3-D','5-H','2-H'])==='three of a kind');
We’ll keep those lines (the tests) at the bottom and add our implementation to the top of the file as we go. Ordinarily, we would start with just one test case, so let’s ignore the “three of a kind” assertion for now.
varassert=require('assert');assert(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair');/* assert(checkHand(['3-H', '3-C', '3-D','5-H', '2-H'])==='three of a kind'); */
Now save that file as check-hand.js and run it with node check-hand.js.
What happens?
/fs/check-hand.js:2assert(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair');^ReferenceError:checkHandisnotdefinedatObject.<anonymous>(/fs/check-hand.js:2:8)atModule._compile(module.js:397:26)atObject.Module._extensions..js(module.js:404:10)atModule.load(module.js:343:32)atFunction.Module._load(module.js:300:12)atFunction.Module.runMain(module.js:429:10)atstartup(node.js:139:18)atnode.js:999:3shellreturned1
Great! We got to the “red” of the red/green/refactor cycle, and we know exactly what to do next—add a checkHand function:
varcheckHand=function(){};varassert=require('assert');assert(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair');/* assert(checkHand(['3-H', '3-C', '3-D','5-H', '2-H'])==='three of a kind'); */
And we get a new error:
assert.js:89thrownewassert.AssertionError({^AssertionError:false==trueatObject.<anonymous>(/fs/check-hand.js:3:1)...(moreofthestacktrace)
This assertion error is a little harder to understand. All this assertion knows about is whether what is inside evaluates to true, and it doesn’t.
asserts can take two parameters. The first is the assertion, and the second is a message:
varcheckHand=function(){};varassert=require('assert');assert(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair','checkHand did not reveal a "pair"');/* assert(checkHand(['3-H', '3-C', '3-D','5-H', '2-H'])==='three of a kind'); */
Now we get a new error message:
assert.js:89thrownewassert.AssertionError({^AssertionError:checkHanddidnotreveala"pair"atObject.<anonymous>(/fs/check-hand.js:3:1)...(morestacktrace)
That’s a little more clear, but if you find writing that second parameter tedious, there is a better option: use wish. First, install it through npm install wish.
Then our code becomes:
varcheckHand=function(){};varwish=require('wish');wish(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair');
The error is clear without us specifying a message as a second parameter:
WishError:Expected"checkHand(['2-H', '3-C', '4-D', '5-H', '2-C'])"tobeequal(===)to"'pair'".
There is an idea in TDD that in order to ensure that you’re moving in small steps, you should write only enough code to make your tests pass:
varcheckHand=function(){return'pair';};varwish=require('wish');wish(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair');/* wish(checkHand(['3-H', '3-C', '3-D','5-H', '2-H'])==='three of a kind'); */
When we run this, there are no failures. The file just runs and exits. If we used a test runner, it would give us a message like “All assertions passed!” or similar. We’ll do that later, but in any case, now that we have that test “green,” it’s time to either refactor or write another test. There’s no obvious refactoring here (we’re mostly exploring testing, rather than refactoring, in this chapter), so we’re on to our next test. Conveniently, we already have it written, so we can just uncomment the last line:
varcheckHand=function(){return'pair';};varwish=require('wish');wish(checkHand(['2-H','3-C','4-D','5-H','2-C'])==='pair');wish(checkHand(['3-H','3-C','3-D','5-H','2-H'])==='three of a kind');
Now we get a new failure that is readable (rather than the false == true error from assert):
WishError:Expected"checkHand(['3-H', '3-C', '3-D', '5-H', '2-H'])"tobeequal(===)to"'three of a kind'".
We know it’s talking about the three-of-a-kind line, so how do we fix it? If we are really, truly just writing the simplest code to make the test pass, we could write our function like this:
varcheckHand=function(hand){if(hand[0]==='2-H'&&hand[1]==='3-C'&&hand[2]==='4-D'&&hand[3]==='5-H'&&hand[4]==='2-C'){return'pair';}else{return'three of a kind';}};
This passes (no output when run), but this code reads with the same tone as a child taunting “Not touching! Can’t get mad!” while hovering his hand above your face. While technically it passes, it is ready to break at the slightest change or expansion in test cases. Only this specific array will count as a "pair", while any other hand will return "three-of-a-kind". We would describe this code as brittle, rather than robust, for its inability to handle many test cases. We can also describe tests as brittle when they are so coupled to the implementation that any minor change will break them. While this is true of our pair assertion here as well, it is this implementation, not the test case, that is the problem.
We started with high-level tests, but we’re about to go deeper. For that reason, things are about to get into a more complicated pattern than just red/green/refactor. We will have multiple levels of testing, and multiple failures at once, some of them persisting for a while. If we stick with our simple asserts, things will get confusing. Let’s tool up and start testing with mocha. If you look through the docs for mocha, which you should at some point, you might be intimidated because it has a ton of features. Here, we’re using the simplest setup possible.
As we discussed at the beginning of the chapter, make sure that you have node, npm, and mocha installed, and that they can all be run from the command line. Assuming that’s sorted, let’s create a new file called check-hand-with-mocha.js and fill it out with the following code:
varwish=require('wish');functioncheckHand(hand){if(hand[0]==='2-H'&&hand[1]==='3-C'&&hand[2]==='4-D'&&hand[3]==='5-H'&&hand[4]==='2-C'){return'pair';}else{return'three of a kind';}};describe('checkHand()',function(){it('handles pairs',function(){varresult=checkHand(['2-H','3-C','4-D','5-H','2-C']);wish(result==='pair');});it('handles three of a kind',function(){varresult=checkHand(['3-H','3-C','3-D','5-H','2-H']);wish(result==='three of a kind');});});
What we’re left with is basically the same thing, just in a form that mocha can use. The describe function indicates what function we are testing, and the it functions contain our assertions. The syntax for assertion has changed slightly, but these are the same tests we had before. And you can run them using mocha check-hand-with-mocha.js (make sure you’re in the same directory as your file), which gives the output shown in Figure 4-2.

Figure 4-2. The output looks pretty good—nice and clear
Quick tip about mocha
If you have a file named test.js or put your test file(s) inside of a directory called test, then mocha will find your test file(s) without you specifying a name. If you set up your files like that, you can just run this: mocha.
Let’s work on our checkHand function now. For proof that the checkHand pair checking is broken, add any other array that should count as a pair. Change the test to this:
describe('checkHand()',function(){it('handles pairs',function(){varresult=checkHand(['2-H','3-C','4-D','5-H','2-C']);wish(result==='pair');varanotherResult=checkHand(['3-H','3-C','4-D','5-H','2-C']);wish(anotherResult==='pair');});it('handles three of a kind',function(){varresult=checkHand(['3-H','3-C','3-D','5-H','2-H']);wish(result==='three of a kind');});});
Now run mocha again. There are three things to note here. First, we can have multiple assertions inside of one it block. Second, we get one failing test and one passing test. If any assertion in the it block fails, the whole it block fails. And third, as expected, we have a failure, a “red” state, and thus a code-produced impetus to change our implementation. Because there’s no easy way out of this one, we’re going to have to actually implement a function that checks for pairs. First, let’s code the interface we want on this. Change the checkHand function to this:
functioncheckHand(hand){if(isPair(hand)){return'pair';}else{return'three of a kind';}};
And run mocha again. Two failures! Of course, because we didn’t implement the isPair function yet, as is clearly explained by the errors mocha gives us:
ReferenceError: isPair is not defined
So, again doing just enough to shut the failures up, we write:
functionisPair(){};
And run mocha again...hey, wait a second. We sure are running mocha a lot. What about those watchers we talked about in the previous chapter? Turns out, mocha has one built in! Let’s run this command:
mocha-wcheck-hand-with-mocha.js
Now whenever we save the file, we’ll get a new report (hit Ctrl-C to exit). Okay, now back to the tests. It’s not really clear how to write the isPair function. We know we’ll get a hand and output a boolean, but what should happen in between? Let’s write another test for isPair itself that takes a hand as input, and outputs a boolean. We can put it above our first describe block:
...describe('isPair()',function(){it('finds a pair',function(){varresult=isPair(['2-H','3-C','4-D','5-H','2-C']);wish(result);});});describe('checkHand()',function(){...
Because we’re using the watcher, we see this failure as soon as we save. We could return true from that function to pass this new test, but we know that will just make the three-of-a-kind tests fail, so let’s actually implement this method. To check for pairs, we want to know how many duplicates are in the hand. What would isPair look like with our ideal interface? Maybe this:
functionisPair(hand){returnmultiplesIn(hand)===2;};
Naturally, we’ll get errors because multiplesIn is not defined. We want to define the method, but we can now imagine a test for it as well:
functionmultiplesIn(hand){};describe('multiplesIn()',function(){it('finds a duplicate',function(){varresult=multiplesIn(['2-H','3-C','4-D','5-H','2-C']);wish(result===2);});});
Another failure. What would our ideal implementation of multiplesIn look like? At this point, let’s assume that we should have a highestCount function that takes the values of the cards:
functionmultiplesIn(hand){returnhighestCount(valuesFromHand(hand));};
We’ll get errors for highestCount and valuesFromHand. So let’s give them empty implementations and tests that describe their ideal interfaces (the parameters we’d like to pass, and the results we’d like to get):
functionhighestCount(values){};functionvaluesFromHand(hand){};describe('valuesFromHand()',function(){it('returns just the values from a hand',function(){varresult=valuesFromHand(['2-H','3-C','4-D','5-H','2-C']);wish(result===['2','3','4','5','2']);});});describe('highestCount()',function(){it('returns count of the most common card from array',function(){varresult=highestCount(['2','4','4','4','2']);wish(result===3);});});
Implementing the valuesFromHand function seems simple, so let’s do that:
functionvaluesFromHand(hand){returnhand.map(function(card){returncard.split('-')[0];})}
Failure?!
Expected"result"tobeequal(===)to" ['2', '3', '4', '5', '2']".
Certainly split is working as expected, right? What about a hardcoded version:
wish(['2','3','4','5','2']===['2','3','4','5','2']);
That gives us:
Expected"['2', '3', '4', '5', '2'] "tobeequal(===)to" ['2', '3', '4', '5', '2']".
Wait a second, aren’t those arrays equal? Unfortunately, not according to JavaScript. Primitives like integers, booleans, and strings work fine with ===, but objects (and arrays are objects under the hood) will only work with === if we are testing variables that reference the same object:
x=[]y=[]x===y;// false
However:
x=[];y=x;x===y;// true
If you want to solve this with a more complicated assertion library, you can. Most have support for something like assert.deepEqual, which checks the contents of the objects. But we want to keep our assertions simple, and just have plain old JavaScript syntax inside of the wish assertions. Additionally, we might reasonably want to check equality of arrays or objects elsewhere in our program.
Rather than build deepEqual ourselves or bring in one that’s tied to an assertion or testing framework, let’s use a standalone library:
npminstalldeep-equal
Now in our test, we can do the following:
vardeepEqual=require('deep-equal');...describe('valuesFromHand()',function(){it('returns just the values from a hand',function(){varresult=valuesFromHand(['2-H','3-C','4-D','5-H','2-C']);wish(deepEqual(result,['2','3','4','5','2']));});});
Now it works. Awesome. Next up, let’s implement highestCount:
functionhighestCount(values){varcounts={};values.forEach(function(value,index){counts[value]=0;if(value==values[0]){counts[value]=counts[value]+1;};if(value==values[1]){counts[value]=counts[value]+1;};if(value==values[2]){counts[value]=counts[value]+1;};if(value==values[3]){counts[value]=counts[value]+1;};if(value==values[4]){counts[value]=counts[value]+1;};});vartotalCounts=Object.keys(counts).map(function(key){returncounts[key];});returntotalCounts.sort(function(a,b){returnb-a})[0];};
It’s not pretty, but it passes the test. In fact, it passes all of them! Which means we’re ready to implement something else.
You probably can see some potential refactoring in this function. That’s great. It’s not a very good implementation, but the first implementation of something often is not. That’s the advantage of having tests. We can happily ignore this working, but ugly, function because it satisfies the right inputs and outputs. We could bring in a more sophisticated functional library like Ramda (Chapter 11) to handle array manipulation, or Array’s built-in reduce function (refactoring using reduce is covered in Chapter 7) to build our object, but for now forEach works fine.
Moving on, let’s actually handle three of a kind:
functioncheckHand(hand){if(isPair(hand)){return'pair';}elseif(isTriple(hand)){return'three of a kind';}};
We get an UndefinedError for isTriple. This time, though, we already have a known test case, so implementation is obvious:
functionisTriple(hand){returnmultiplesIn(hand)===3;};
We don’t have a test specifically for isTriple, but the high-level test should give us enough confidence to move on. For the same confidence on four of a kind, all we need is another high-level test (another it block in the checkHand test):
describe('checkHand()',function(){...it('handles four of a kind',function(){varresult=checkHand(['3-H','3-C','3-D','3-S','2-H']);wish(result==='four of a kind');});...
And the implementation:
functioncheckHand(hand){if(isPair(hand)){return'pair';}elseif(isTriple(hand)){return'three of a kind';}elseif(isQuadruple(hand)){return'four of a kind';}};functionisQuadruple(hand){returnmultiplesIn(hand)===4;};
Next, let’s write a test for the high card, which means another it block in the checkHand test:
it('handles high card',function(){varresult=checkHand(['2-H','5-C','9-D','7-S','3-H']);wish(result==='high card');});
Failure. Red. And here’s the implementation:
functioncheckHand(hand){if(isPair(hand)){return'pair';}elseif(isTriple(hand)){return'three of a kind';}elseif(isQuadruple(hand)){return'four of a kind';}else{return'high card';}}
Green. Passing. Let’s take care of flush with another high-level test in the checkHand section:
it('handles flush',function(){varresult=checkHand(['2-H','5-H','9-H','7-H','3-H']);wish(result==='flush');});
Failure. It doesn’t meet any of the conditions, so our test reports as high card. The ideal interface is:
functioncheckHand(hand){if(isPair(hand)){return'pair';}elseif(isTriple(hand)){return'three of a kind';}elseif(isQuadruple(hand)){return'four of a kind';}elseif(isFlush(hand)){return'flush';}else{return'high card';}};
We get an UndefinedError for isFlush. So we want:
functionisFlush(hand){}
This returns undefined, so we get a failure because we’re still going to hit the high card (else) path. We’re going to need to check that the suits are all the same. Let’s assume we need two functions for that, changing our isFlush implementation to the following:
functionisFlush(hand){returnallTheSameSuit(suitsFor(hand));};
We get UndefinedErrors for those new functions. We could write the boilerplate, but the allTheSameSuit function seems pretty obvious to implement. Let’s do that first. But since we have two functions that are new, we’ll write a test so that we can be sure that allTheSameSuit is working as expected:
functionallTheSameSuit(suits){suits.forEach(function(suit){if(suit!==suits[0]){returnfalse;}})returntrue;}describe('allTheSameSuit()',function(){it('reports true if elements are the same',function(){varresult=allTheSameSuit(['D','D','D','D','D']);wish(result);});});
Passing. But naturally, we still have an undefined error for suitsFor. Here’s the implementation:
functionsuitsFor(hand){returnhand.map(function(card){returncard.split('-')[1];})};
It’s pretty similar to our valuesFromHand function, so we’re going to move on without a test. Feel free to write one if you want to stay in the test-first mode.
Uh-oh! Our flush condition seems to be returning true for our high card as well. Error:
1)checkHand()handleshighcard:WishError:Expected"result"tobeequal(===)to" 'high card'".
That must mean that allTheSameSuit is also returning true. We introduced a bug, so it’s time for a regression test. First, we reproduce the behavior with a test. We didn’t test that the allTheSameSuit function would actually return false when the cards aren’t all the same. Let’s add that test now:
describe('allTheSameSuit()',function(){...it('reports false if elements are not the same',function(){varresult=allTheSameSuit(['D','H','D','D','D']);wish(!result);});});
Two failures, which means we reproduced the bug (and still have the original). Apparently, our return false was only returning from the loop. Let’s change our implementation:
functionallTheSameSuit(suits){vartoReturn=true;suits.forEach(function(suit){if(suit!==suits[0]){toReturn=false;}});returntoReturn;};
And now all of our tests are passing again.
There’s a better way to handle this forEach, by using Ramda (or Sanctuary, underscore, lodash, etc.) or digging into JavaScript’s native Array functions a bit more (keeping in mind that using native functions requires us to check their availability on our target platform), but this was the easiest thing that passed the tests. We want our code to be readable, correct, good, and fast—in that order.
Only a few hands left. Let’s do the straight. First a high-level test:
describe('checkHand()',function(){...it('handles straight',function(){varresult=checkHand(['1-H','2-H','3-H','4-H','5-D']);wish(result==='straight');});});
The code is hitting the else clause for high card. That’s good. We know then that there aren’t any competing conditions and are free to add one to checkHand:
functioncheckHand(hand){if(isPair(hand)){return'pair';}elseif(isTriple(hand)){return'three of a kind';}elseif(isQuadruple(hand)){return'four of a kind';}elseif(isFlush(hand)){return'flush';}elseif(isStraight(hand)){return'straight';}else{return'high card';}}
isStraight is not defined. Let’s define it, and its ideal interface, in one step. We’ll skip the test for isStraight, since it would be redundant with the high-level test:
functionisStraight(hand){returncardsInSequence(valuesFromHand(hand));};
Error. We need to define cardsInSequence. What should it look like?
functioncardsInSequence(values){varsortedValues=values.sort();returnfourAway(sortedValues)&&noMultiples(values);};
Two undefined functions. We’ll add tests for both of these. First, let’s get a passing test for fourAway:
functionfourAway(values){return((+values[values.length-1]-4-+values[0])===0);};describe('fourAway()',function(){it('reports true if first and last are 4 away',function(){varresult=fourAway(['2','6']);wish(result);});});
Note that the + signs in line 2 are turning strings into numbers. If that seems hard to read, unidiomatic, or just likely to be changed without someone realizing the importance, use this line with parseInt instead:
return((parseInt(values[values.length-1])-4-parseInt(values[0]))===0);
Let’s move on to noMultiples. We’ll write a negative test case here, just for added assurance. The implementation turns out to be simple, though, because we already have something to count cards for us:
functionnoMultiples(values){returnhighestCount(values)==1;};describe('noMultiples()',function(){it('reports true when all elements are different',function(){varresult=noMultiples(['2','6']);wish(result);});it('reports false when two elements are the same',function(){varresult=noMultiples(['2','2']);wish(!result);});});
All tests are passing. Now for StraightFlush. Let’s add this to our high-level checkHand describe block:
describe('checkHand()',function(){...it('handles straight flush',function(){varresult=checkHand(['1-H','2-H','3-H','4-H','5-H']);wish(result==='straight flush');});});
It seems to be hitting the flush condition, so we’ll have to add this check above that in the if/else clause:
functioncheckHand(hand){if(isPair(hand)){return'pair';}elseif(isTriple(hand)){return'three of a kind';}elseif(isQuadruple(hand)){return'four of a kind';}elseif(isStraightFlush(hand)){return'straight flush';}elseif(isFlush(hand)){return'flush';}elseif(isStraight(hand)){return'straight';}else{return'high card';}}
isStraightFlush is not defined. Since this code is just the result of two functions, we won’t worry about a low-level test for it (feel free to write one, though):
functionisStraightFlush(hand){returnisStraight(hand)&&isFlush(hand);}
It passes. Only two left: two pair and full house. Let’s do full house first, starting with a high-level test:
describe('checkHand()',function(){...it('handles full house',function(){varresult=checkHand(['2-D','2-H','3-H','3-D','3-C']);wish(result==='full house');});});
The code is following the “three of a kind” branch of the checkHand conditional, so we want the isFullHouse check to go above that:
functioncheckHand(hand){if(isPair(hand)){return'pair';}elseif(isFullHouse(hand)){return'full house';}elseif(isTriple(hand)){return'three of a kind';}elseif(isQuadruple(hand)){return'four of a kind';}elseif(isStraightFlush(hand)){return'straight flush';}elseif(isFlush(hand)){return'flush';}elseif(isStraight(hand)){return'straight';}else{return'high card';}};
Now we need to implement the function isFullHouse. It looks like what we need is buried inside of highestCount. It just returns the top one, but we want them all. Basically, we need everything from that function except for the very last three characters. What kind of subtle, elegant thing should we do to avoid just duplicating the code?
functionallCounts(values){varcounts={};values.forEach(function(value,index){counts[value]=0;if(value==values[0]){counts[value]=counts[value]+1;};if(value==values[1]){counts[value]=counts[value]+1;};if(value==values[2]){counts[value]=counts[value]+1;};if(value==values[3]){counts[value]=counts[value]+1;};if(value==values[4]){counts[value]=counts[value]+1;};});vartotalCounts=Object.keys(counts).map(function(key){returncounts[key];});returntotalCounts.sort(function(a,b){returnb-a});};
Nothing! Don’t try to be elegant. Duplicate the code. Copying and pasting is often the smallest and safest step you can take. Although copying and pasting gets a bad rap, it is absolutely a better first step than trying to extract functions (and other structures) and ending up breaking too many things at once (especially if you’ve strayed too far from your last git commit!). The real problem comes from leaving the duplication, which is a very serious maintenance concern—but the best time to deal with this is in the refactor step of the red/green/refactor cycle, not while you’re trying to get tests to pass in the green phase.
Notice that we’ve left out the [0] because we want all of the results. Now all that’s left is the isFullHouse implementation:
functionisFullHouse(hand){vartheCounts=allCounts(valuesFromHand(hand));return(theCounts[0]===3&&theCounts[1]===2);};
It works. Great. Two pair, and we’re done:
describe('checkHand()',function(){...it('handles two pair',function(){varresult=checkHand(['2-D','2-H','3-H','3-D','8-D']);wish(result==='two pair');});});
This is catching on the pair condition. That means the isTwoPair check will have to go before the isPair check in the conditional:
functioncheckHand(hand){if(isTwoPair(hand)){return'two pair';}elseif(isPair(hand)){...
And then an implementation that looks a great deal like isFullHouse:
functionisTwoPair(hand){vartheCounts=allCounts(valuesFromHand(hand));return(theCounts[0]===2&&theCounts[1]===2);};
And we’re done! That’s how you start new code with tests, and maintain confidence throughout. The rest of the book is about refactoring. This chapter is about how to write lots and lots of tests. There is a ton of duplication in the code and the tests. The number of loops and conditionals is too high. There is barely any information hiding, and there are no attempts at private methods. No classes. No libraries that elegantly do loop-like work. It’s all synchronous. And we definitely have some gaps when it comes to representing face cards.
But for the functionality it has, it is well tested, and in places that it’s not, because we have a functioning test suite in place it’s easy to add more. We even had a chance to try out writing regression tests for bugs.
Untested Code and Characterization Tests
So here’s the scenario: the code for randomly generating a hand of cards was written by a coworker. He’s taken two months off to prepare for Burning Man, and the team is suspicious that he’ll never really come back. You can’t get in touch with him and he didn’t write any tests.
Here, you have three options. First, you could rewrite the code from scratch. Especially for bigger projects, this is risky and could take a long time. Not recommended. Second, you could change the code as needed, without any tests (see Chapter 1 for a description of the difference between “changing code” and “refactoring”). Also not recommended. Your third and best option is to add tests.
Here is your colleague’s code (save it as random-hand.js):
vars=['H','D','S','C'];varv=['1','2','3','4','5','6','7','8','9','10','J','Q','K'];varc=[];varrS=function(){returns[Math.floor(Math.random()*(s.length))];};varrV=function(){returnv[Math.floor(Math.random()*(v.length))];};varrC=function(){returnrV()+'-'+rS();};vardoIt=function(){c.push(rC());c.push(rC());c.push(rC());c.push(rC());c.push(rC());};doIt();console.log(c);
Pretty cryptic. Sometimes when you see code that you don’t understand, it’s right next to data that’s very important, and it seems the confusing code won’t work without it. Those situations are tougher, but here, we can get this in a test harness (exercising the code through tests) fairly easily. We’ll talk about variable names later, but for now, recognize that getting this under test does not depend on good variable names, or even understanding the code very well.
If we were using assert, we’d write a characterization test like this (you can put this test code at the bottom of the preceding code, and run it with mocha random-hand.js):
constassert=require('assert');describe('doIt()',function(){it('returns nothing',function(){varresult=doIt();assert.equal(result,null);});});
That is, we’d just assume that the function returns nothing. And when we assume nothing from the code, normally it protests through the tests, “I beg your pardon, I’m actually returning something when I’m called with no arguments, thank you very much.” This is called a characterization test. Sometimes (like in this case) the tests will pass, though, because they actually do return null, or whatever other value we provide as the second parameter to assert.equal. When we use assert.equal like this, the test passes, because null == undefined. If we instead use assert(result === null);, we’re left with this gem of an error:
AssertionError:false==true
Neither one of those is helpful. Yes, we could get a better error with a different arbitrary value that JavaScript won’t coerce to a value that happens to be equal in some way to the output of a function. For instance, we’d get a decent error like this:
assert.equal(result,3);AssertionError:undefined==3
But personally, I like to avoid thinking about different types of equality and coercion as much as possible when writing characterization tests. So instead of using assert for characterization tests, we’ll use wish’s characterization test mode. We activate it by adding a second parameter of true to the call to wish, like this:
wish(whateverValueIAmChecking,true);
We can add the following code (replacing the assert-based test) to the bottom of the file and run it with mocha random-hand.js:
constwish=require('wish');describe('doIt()',function(){it('returns something',function(){wish(doIt(),true);});});describe('rC()',function(){it('returns something',function(){wish(rC(),true);});});describe('rV()',function(){it('returns something',function(){wish(rV(),true);});});describe('rS()',function(){it('returns something',function(){wish(rS(),true);});});
And the test errors tell us what we need to know:
WishCharacterization:doIt()evaluatedtoundefinedWishCharacterization:rC()evaluatedto"3-C"WishCharacterization:rV()evaluatedto"7"WishCharacterization:rS()evaluatedto"H"
Our failures tell us what the code did, at least in terms of what type of return values we’re dealing with. However, the doIt function returns undefined, which usually means there’s a side effect in that code (unless the function actually does nothing at all, in which case it’s dead code and we’d remove it).
Side effects
A side effect means something like printing, altering a variable, or changing a database value. In some circles, immutability is very cool and side effects are very uncool. In JavaScript, how side effect–friendly you are depends on what JavaScript you’re writing (Chapter 2) as well as your personal style. Aiming to minimize side effects is generally in line with the goals of this book. Eliminating them is an altogether different thing. We’ll talk about them throughout the book, but the deepest dive is in Chapter 11.
For the non-null returning functions, you can just plug in input values and assert whatever is returned by the test. That is the second part of a characterization test. If there aren’t side effects, you never even have to look at the implementation! It’s just inputs and outputs.
But there’s a catch in this code. It’s not deterministic! If we just plugged values into wish assertions, our tests would only work on rare occasions.
The reason is that randomness is involved in these functions. It’s a little trickier, but we can just use a regex (regular expression) to cover the variations in outputs. We can delete our characterization tests, and replace them with the following:
describe('rC()',function(){it('returns match for card',function(){wish(rC().match(/\w{1,2}-[HDSC]/));});});describe('rV()',function(){it('returns match for card value',function(){wish(rV().match(/\w{1,2}/));});});describe('rS()',function(){it('returns match for suit',function(){wish(rS().match(/[HDSC]/));});});
Because these three functions simply take input and output, we’re done with these ones. What to do about our undefined-returning doIt function, though?
We have options here. If this is part of a multifile program, first, we need to make sure that the variable c isn’t accessed anywhere else. It’s hard to do with a one-letter variable name, but if we’re sure it’s confined to this file, we can just move the first line where c is defined and return it inside the doIt function like this:
vardoIt=function(){varc=[];c.push(rC());c.push(rC());c.push(rC());c.push(rC());c.push(rC());returnc;};console.log(c);
Now we’ve broken the console output. The console.log(c) statement no longer knows what c is. This is a simple fix. We just replace it with the function call:
console.log(doIt());
We still need a doIt test. Let’s use a characterization test again:
describe('doIt()',function(){it('does something',function(){wish(doIt(),true);});});
This gives us back something like:
WishCharacterization:doIt()evaluatedto["7-S","8-S","9-H","4-D","J-H"]
Specifically, it returns what looks like the results of five calls to rC. For the test, we could use a regex to check every element of this array, but we already test rC like that. We probably don’t want the brittleness of that kind of high-level test. If we decide to change the format of rC, we don’t want two tests to become invalid. So what’s a good high-level test here? Well, what’s unique about the doIt function is that it returns five of something. Let’s test that:
describe('doIt()',function(){it('returns something with a length of 5',function(){wish(doIt().length===5);});});
For smaller codebases that you want to get in a test harness or “under test,” this process works well. For larger codebases, even with approval and enthusiasm from management and other developers, it is impractical to go from 0 (or even 50) percent coverage all the way to 100 percent in a short time via a process like this.
In those cases, you may identify some high-priority sections to get under test through this process. You’ll want to target areas that are especially lacking in test coverage, core to the application, very low quality, or that have a high “churn rate” (files and sections that frequently change), or some combination of all of these.
Another adaptation you can make is to adopt a process that insists on certain quality standards or code coverage rates for all new code. See the previous chapter for some types of tools and processes that will help you with this. Over time, your high-quality and well-tested new (and changed) lines will begin to dwarf the older, more “legacy” sections of the codebase. This is what paying off technical debt looks like. It begins with getting code coverage, and then continues through refactoring. Keep in mind that for larger codebases, it takes months, not a weekend, of heroic effort from the team, and certainly not from one particularly enthusiastic developer.
Alongside process improvements and emphasizing quality in new changes to the code, one additional policy is worth considering. If the code is live and has people using it, even if it is poorly tested and low quality, it should be looked at with some skepticism, but not too critically. The implications are that changing code that is not under test should be avoided, the programmers who wrote the legacy code should not be marginalized or insulted (they often understand the business logic better than newer programmers), and bugs should be handled on an ad hoc basis through regression tests (detailed in the next section). Also, since code in use is exercised (although unfortunately by the people using it rather than a test suite), it’s possible that you can be slightly more confident in it than in new code.
To recap, if you find yourself with a large legacy codebase with poor coverage, identify small chunks to get under test (using the process from this section), adopt a policy of complete or majority coverage for new work (using the processes described in the sections on new features and new code from scratch—with or without TDD), and write regression tests for bugs that come up. Along the way, try not to insult the programmers who wrote the legacy code, whether they’re still with the team or not.
Debugging and Regression Tests
After writing the tests from the last section, we’ve successfully created an automated way to confirm that the code works. We should be happy with getting the random hand generator under test, because now we can confidently refactor, add features, or fix bugs.
Beware of the urge to “just fix the code”!
Sometimes, a bug looks easy to fix. It’s tempting to “just fix the code,” but what stops the bug from coming back? If you write a regression test like we do here, you can squash it for good.
A related but distinct impulse is to fix code that “looks ugly or would probably cause bugs.” The code could even be something that you identify as causing a bug. Unless you have a test suite in place, don’t “just fix” this code either. This is changing code, not refactoring.
And that’s a good thing. Here’s the scenario: we’ve just encountered a bug in the code that made it into production. The bug report says that sometimes players get multiple versions of the same card.
The implications are dire. Certain hands, like four of a kind, are far more likely than expected (and five of a kind is even possible!). The competing online casinos have a perfectly working card dealing system, and people playing our game are losing trust in our faulty one.
So what’s wrong with the code? Let’s take a look:
varsuits=['H','D','S','C'];varvalues=['1','2','3','4','5','6','7','8','9','10','J','Q','K'];varrandomSuit=function(){returnsuits[Math.floor(Math.random()*(suits.length))];};varrandomValue=function(){returnvalues[Math.floor(Math.random()*(values.length))];};varrandomCard=function(){returnrandomValue()+'-'+randomSuit();};varrandomHand=function(){varcards=[];cards.push(randomCard());cards.push(randomCard());cards.push(randomCard());cards.push(randomCard());cards.push(randomCard());returncards;};console.log(randomHand());
The first thing to notice is that the variable and function names have been expanded to make the code more clear. That also breaks all of the tests. Can you reproduce the test coverage from scratch without just renaming the variables? If you want to try it on your own first, go for it, but in either case, here are the tests:
varwish=require('wish');vardeepEqual=require('deep-equal');describe('randomHand()',function(){it('returns 5 randomCards',function(){wish(randomHand().length===5);});});describe('randomCard()',function(){it('returns nothing',function(){wish(randomCard().match(/\w{1,2}-[HDSC]/));});});describe('randomValue()',function(){it('returns nothing',function(){wish(randomValue().match(/\w{1,2}/));});});describe('randomSuit()',function(){it('returns nothing',function(){wish(randomSuit().match(/[HDSC]/));});});
First, we want to reproduce the problem somehow. Let’s try running this code using just node (without the tests or mocha, so comment out the tests lines for now, but leave the console.log(randomHand());). Did you see the same card twice? Try running it again, and again if need be. How many times did it take to reproduce the bug?
With the manual testing (see Chapter 3) approach it can take a while, and be hard to see the error even when it does show up. Our next step is writing a test to exercise the code and attempt to produce the error. Note that we want a failing test before we write any code. Our first instinct might be to write a test like this:
describe('randomHand()',function(){...for(vari=0;i<100;i++){it('should not have the first two cards be the same',function(){varresult=randomHand();wish(result[0]!==result[1]);});};});
This will produce failures fairly often, but isn’t a great test for two reasons, both having to do with the randomness. First, by requiring many iterations of the code to be exercised, we’ve created a test that is sure to be fairly slow. Second, our test won’t always reproduce the error and fail. We could increase the number of test runs to make not getting a failure virtually impossible, but that will necessarily slow our system down further.
In spite of this not being a great test, we can use it as scaffolding to change our randomHand function. We don’t want to change the format of the output, but our implementation is off. We can use as many iterations of the functions as we need to (almost) guarantee observing the failure in action.
Now that we have a harness (the currently failing test) in place, we can change the implementation of the function safely. Note that this is not refactoring. We are changing code (safely, because it is under test), but we are also changing behavior. We are moving the test from red to green, not refactoring.
Instead of pulling a random value and suit, let’s return both at once from one array of values. We could manually build this array as having 52 elements, but since we already have our two arrays ready to go, let’s use those. First, we’ll test to make sure we get a full deck:
describe('buildCardArray()',function(){it('returns a full deck',function(){wish(buildCardArray().length===52);});});
This produces an error because we haven’t defined buildCardArray:
varbuildCardArray=function(){};
This produces an error because buildCardArray doesn’t return anything:
varbuildCardArray=function(){return[];};
This isn’t really the simplest thing to get us past our error, but anything with a length would have worked to get us to a new failure (instead of an error), which in our case is that the length is 0 rather than 52. Here, maybe you think the simplest solution is to build the array of possible cards manually and return that. That’s fine, but typos and editor macro mishaps might cause some issues. Let’s just build the array with some simple loops:
varbuildCardArray=function(){vartempArray=[];for(vari=0;i<values.length;i++){for(varj=0;j<suits.length;j++){tempArray.push(values[i]+'-'+suits[j])}};returntempArray;};
The test is passing. But we’re not really testing the behavior, are we? Where are we? Are we lost? How do we test if we’re outside the red/green/refactor cycle? Well, what do we have? Basically, if we move in a big step like this, we create untested code. And just like before, we can use a new characterization test to tell us what happens when we run the function:
describe('buildCardArray()',function(){it('does something?',function(){wish(buildCardArray(),true);});...});
Depending on your mocha setup, you could get the full deck of cards back as an array, or it might be truncated. There are dozens of flags and reporters for mocha, so while it might be possible to change the output to what we want, in this case, it’s just as fast to manually add a console.log to the test case:
it('does something?',function(){console.log(buildCardArray());wish(buildCardArray(),true);});
So now we have the full array printed in the test runner. Depending on what output you got, you might have a bit of reformatting to do (now is a good time to learn your editor’s “join lines” function if you don’t already know it). In the end, we get:
['1-H','1-D','1-S','1-C','2-H','2-D','2-S','2-C','3-H','3-D','3-S','3-C','4-H','4-D','4-S','4-C','5-H','5-D','5-S','5-C','6-H','6-D','6-S','6-C','7-H','7-D','7-S','7-C','8-H','8-D','8-S','8-C','9-H','9-D','9-S','9-C','10-H','10-D','10-S','10-C','J-H','J-D','J-S','J-C','Q-H','Q-D','Q-S','Q-C','K-H','K-D','K-S','K-C']
Great. If this array contained thousands of elements we’d need another way to derive confidence, but since it only has 52, by visual inspection we can affirm that the array looks good. We are playing with a full deck. Let’s change our characterization test so that it asserts against the output. Here, we actually got our confidence in the result from visual inspection. This characterization test is so that we have coverage, and to make sure we don’t break anything later:
it('gives a card array',function(){wish(deepEqual(buildCardArray(),['1-H','1-D','1-S','1-C','2-H','2-D','2-S','2-C','3-H','3-D','3-S','3-C','4-H','4-D','4-S','4-C','5-H','5-D','5-S','5-C','6-H','6-D','6-S','6-C','7-H','7-D','7-S','7-C','8-H','8-D','8-S','8-C','9-H','9-D','9-S','9-C','10-H','10-D','10-S','10-C','J-H','J-D','J-S','J-C','Q-H','Q-D','Q-S','Q-C','K-H','K-D','K-S','K-C']));});
Passing. Good. Okay, so now we have a function that returns a full deck of cards so that our randomHand function can stop returning duplicates. If we uncomment our slow and occasionally failing “should not have the first two cards be the same” test, we’ll see that it’s still failing. That makes sense, as we haven’t actually changed anything about the randomHand function yet. Let’s have it return a random element from our array:
varrandomHand=function(){varcards=[];vardeckSize=52;cards.push(buildCardArray()[Math.floor(Math.random()*deckSize)]);cards.push(buildCardArray()[Math.floor(Math.random()*deckSize)]);cards.push(buildCardArray()[Math.floor(Math.random()*deckSize)]);cards.push(buildCardArray()[Math.floor(Math.random()*deckSize)]);cards.push(buildCardArray()[Math.floor(Math.random()*deckSize)]);returncards;};
We should still see our failure for the random/slow test (given enough iterations), and this is a great moment. What if we didn’t have that test in place? Perhaps even without the test, it’s obvious in this instance that we didn’t fix the problem, but this isn’t always the case. Without a test like this one, we could very well think that we had fixed the problem, only to see the same bug come up again later. By the way, are we changing the behavior? Not really, since we’re still returning five cards as strings, so we would say that we changed the implementation. As evidence to that, we have the same passing and failing tests.
So how do we fix it?
varrandomHand=function(){varcards=[];varcardArray=buildCardArray();cards.push(cardArray.splice(Math.floor(Math.random()*cardArray.length),1)[0]);cards.push(cardArray.splice(Math.floor(Math.random()*cardArray.length),1)[0]);cards.push(cardArray.splice(Math.floor(Math.random()*cardArray.length),1)[0]);cards.push(cardArray.splice(Math.floor(Math.random()*cardArray.length),1)[0]);cards.push(cardArray.splice(Math.floor(Math.random()*cardArray.length),1)[0]);returncards;};
Instead of just returning a card at a random index, we’re only using the function once to build the array. Then, we use the splice function to, starting at a random index, return one element (the 1 is the second parameter of the slice function) and push it onto the array. For better or worse, splice returns an element, but also has the side effect of removing it from the array. That’s perfect for our situation here, but the terms destructive and impure both apply to this function (see Chapter 11 for more details). Note that we need the [0] because splice returns an array. Although it only has one element in it, it’s still an array, so we just need to grab the first element.
Back to a recurring question: are we refactoring yet? Nope. We’ve changed the behavior (moving from the “red” to the “green” part of the cycle). As testament to that, our test appears to be passing now, even with many iterations.
So are we confident that our change worked? The trouble is, we’re still testing something random, which means we’re stuck with an inconsistent and possibly slow test.
If you search for “testing randomness” online, many of the solutions will suggest things that make the random function more predictable. In our case, though, it’s the implementation itself that we should still be skeptical about. How can we get rid of the slow scaffolding test and still have confidence that our code works? We need to test the implementation of a function that doesn’t depend on randomness. Here’s one way:
describe('spliceCard()',function(){it('returns two things',function(){wish(spliceCard(buildCardArray()).length===2);});it('returns the selected card',function(){wish(spliceCard(buildCardArray())[0].match(/\w{1,2}-[HDSC]/));});it('returns an array with one card gone',function(){wish(spliceCard(buildCardArray())[1].length===buildCardArray().length-1);});});
In this approach, we decide that to isolate the spliceCard function, we have to return its return value as well as its side effect:
varspliceCard=function(cardArray){vartakeAway=cardArray.splice(Math.floor(Math.random()*cardArray.length),1)[0];return[takeAway,cardArray];};
Not bad. Our tests, including the slow test, still pass. But we still need to hook in the randomHand function. Here’s what a first attempt could look like:
varrandomHand=function(){varcards=[];varcardArray=buildCardArray();varresult=spliceCard(cardArray);cards[0]=result[0];cardarray=result[1];result=spliceCard(cardArray);cards[1]=result[0];cardarray=result[1];result=spliceCard(cardArray);cards[2]=result[0];cardarray=result[1];result=spliceCard(cardArray);cards[3]=result[0];cardarray=result[1];result=spliceCard(cardArray);cards[4]=result[0];cardarray=result[1];returncards;};
Are we refactoring yet? Yes. We extracted a function without changing the behavior (our tests behave the same). Our scaffolding test will not fail no matter how many times we run it.
We have three considerations left. First, is this inner function that we’ve tested useful by itself, or only in this context? If it’s useful outside of the context of dealing a hand of five (say, for blackjack?), leaving it in the same scope as dealHand makes sense. If it’s only useful for the poker game, we might want to attempt to make it “private” (to the extent this is possible in JavaScript; see “Context Part 2: Privacy” in Chapter 5), which leads to a potentially unexpected conundrum: should you test private functions?
Many say no because behavior should be tested by the outer function, and testing an implementation rather than an interface is a path that leads to brittle and unnecessary tests. However, if you take this advice too far, what happens? Do you still need unit tests at all? Maybe you just need extremely high-level tests aligned with corporate objectives? (How much money do people spend playing poker in our application? How many new people signed up today?) Maybe a survey that asks people if they had fun using the application?
For this code, adhering strictly to the idea of “testing an interface, not an implementation” does not give us the confidence we need. Can we be confident in this code as a whole if we do not test the inner function? Not really, unless we leave our scaffold in place. Our second concern, getting rid of this slow test while retaining confidence, should be solved by our new test.
Third, are we done? As we covered in the TDD discussion, the red/green/refactor cycle is an appropriate process for improving code quality. We got to green, and we even refactored by extracting a method. Although this refactoring had a dual purpose in increasing confidence to delete a slow test, we used all three of those steps.
One last bit of cleanup we can do is removing the dead code. Specifically, in addition to getting rid of the slow test, or isolating it in another file, we can remove the functions that are no longer called—randomSuit, randomValue, and randomCard—as well as their tests. See more about identifying dead code in “Dead Code”.
But if we do that, are we done? It depends. Another iteration of the red/green/refactor cycle is appropriate if we can think of more features to implement (tests that would fail). We’re happy with how our code works, so another iteration of the cycle doesn’t make sense. We’re also happy with our test coverage, so we needn’t go through the process for untested code covered earlier.
So we’re done? In many contexts, yes. But because this book is about refactoring, it’s worth proposing an augmentation to the red/green/refactor cycle (see Figure 4-1 earlier in this chapter for a flow chart of the interaction between testing and refactoring. You can also find this flow chart at the beginning of Chapter 5).
We’ve already refactored once by removing the dead code, but let’s refactor our randomHand function one more time, taking advantage of destructuring. It sounds intimidating, but we’re just setting multiple values at once:
varrandomHand=function(){varcards=[];varcardArray=buildCardArray();[cards[0],cardArray]=spliceCard(cardArray);[cards[1],cardArray]=spliceCard(cardArray);[cards[2],cardArray]=spliceCard(cardArray);[cards[3],cardArray]=spliceCard(cardArray);[cards[4],cardArray]=spliceCard(cardArray);returncards;};
And the tests still pass.
Wrapping Up
As you’re refactoring, you might be tempted to change the interface of a function (not just the implementation). If you find yourself at that point, you are writing new code that requires new tests. Refactoring shouldn’t require new tests for code that is already covered and passing, although there are cases where more tests can increase confidence.
To recap, use the red/green/refactor cycle for regressions. Write tests for confidence. Write characterization tests for untested code. Write regression tests for bugs. You can refactor as much as is practical, but only if you have enough coverage to be reasonably confident in the changes. In any case, keep the steps between your git commit commands small, so that you’re ready to roll back to a clean version easily.
Get Refactoring JavaScript now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

