Capítulo 4. Introducción a las redes Kubernetes
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Ahora que hemos cubierto los componentes críticos de las redes de Linux y de los contenedores, estamos preparados para hablar con más detalle de las redes de Kubernetes. En este capítulo, hablaremos de cómo se conectan los pods interna y externamente al clúster. También veremos cómo se conectan los componentes internos de Kubernetes. Las abstracciones de red de nivel superior en torno al descubrimiento y el equilibrio de carga, como los servicios y las entradas, se tratarán en el próximo capítulo.
La red Kubernetes pretende resolver estos cuatro problemas de red:
-
Comunicaciones de contenedor a contenedor altamente acopladas
-
Comunicaciones pod-a-pod
-
Comunicaciones pod-servicio
-
Comunicaciones externas al servicio
El modelo de red Docker utiliza por defecto una red puente virtual, que se define por host y es una red privada donde se conectan los contenedores. A la dirección IP del contenedor se le asigna una dirección IP privada, lo que implica que los contenedores que se ejecutan en máquinas distintas no pueden comunicarse entre sí. Los desarrolladores tendrán que asignar los puertos del host a los puertos del contenedor y, a continuación, proxyar el tráfico para llegar a través de los nodos con Docker. En este escenario, corresponde a los administradores de Docker evitar los choques de puertos entre contenedores; normalmente, se trata de los administradores del sistema. La red Kubernetes gestiona esto de forma diferente.
El modelo de red de Kubernetes
El modelo de red de Kubernetes admite de forma nativa la red de clústeres multihost . Los pods pueden comunicarse entre sí por defecto, independientemente del host en el que estén implementados. Kubernetes se basa en el proyecto CNI para cumplir los siguientes requisitos:
-
Todos los contenedores deben comunicarse entre sí sin NAT.
-
Los nodos pueden comunicarse con los contenedores sin NAT.
-
La dirección IP de un contenedor es la misma que la de aquellos que están fuera del contenedor y se ven a sí mismos.
La unidad de trabajo de en Kubernetes se llama pod. Un pod contiene uno o más contenedores, que siempre están programados y se ejecutan "juntos" en el mismo nodo. Esta conectividad permite separar las instancias individuales de un servicio en contenedores distintos. Por ejemplo, un desarrollador puede elegir ejecutar un servicio en un contenedor y un reenviador de logs en otro contenedor. Ejecutar procesos en contenedores distintos les permite tener cuotas de recursos separadas (por ejemplo, "el reenviador de logs no puede utilizar más de 512 MB de memoria"). También permite separar la maquinaria de construcción e implementación de contenedores, reduciendo el alcance necesario para construir un contenedor.
La siguiente es una definición mínima de vaina. Hemos omitido muchas opciones. Kubernetes gestiona varios campos, como el estado de los pods, que son de sólo lectura:
apiVersion:v1kind:Podmetadata:name:go-webnamespace:defaultspec:containers:-name:go-webimage:go-web:v0.0.1ports:-containerPort:8080protocol:TCP
Los usuarios de Kubernetes no suelen crear pods directamente. En su lugar, los usuarios de crean una carga de trabajo de alto nivel, como una implementación, que gestiona los pods de acuerdo con algunas especificaciones previstas. En el caso de una implementación, como se muestra en la Figura 4-1, los usuarios especifican una plantilla para los pods, junto con cuántos pods (a menudo llamados réplicas) quieren que existan. Hay otras formas de gestionar cargas de trabajo, como ReplicaSets y StatefulSets, que revisaremos en el próximo capítulo. Algunos proporcionan abstracciones sobre un tipo intermedio, mientras que otros gestionan los pods directamente. También hay tipos de cargas de trabajo de terceros en , en forma de definiciones de recursos personalizadas (CRD). Las cargas de trabajo en Kubernetes son un tema complejo, y sólo intentaremos cubrir lo más básico y las partes aplicables a la pila de redes.
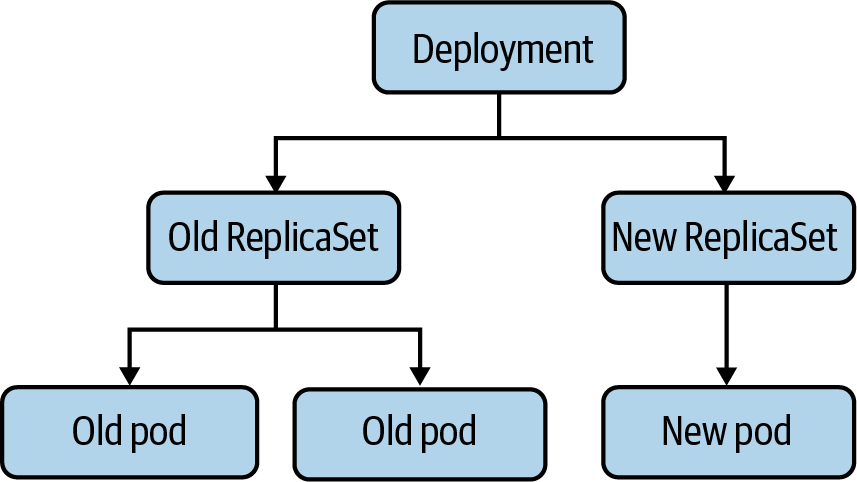
Figura 4-1. Relación entre una Implementación y los Pods
Los pods en sí son efímeros, lo que significa que se borran y se sustituyen por nuevas versiones de sí mismos. La corta vida de los pods es una de las principales sorpresas y retos para los desarrolladores y operadores familiarizados con máquinas físicas o virtuales más semipermanentes y tradicionales. El estado del disco local, la programación de los nodos y las direcciones IP se sustituirán regularmente durante el ciclo de vida de un pod.
Un pod tiene una dirección IP única , que comparten todos los contenedores del pod. La principal motivación para dar a cada pod una dirección IP es eliminar las restricciones en torno a los números de puerto. En Linux, sólo un programa puede escuchar en una dirección, puerto y protocolo determinados. Si los pods de no tuvieran direcciones IP únicas, entonces dos pods en un nodo podrían competir por el mismo puerto (como dos servidores web, ambos intentando escuchar en el puerto 80). Si fueran iguales, sería necesaria una configuración en tiempo de ejecución para solucionarlo, como una bandera --port. Alternativamente, se necesitaría un script feo para actualizar un archivo de configuración en el caso de software de terceros.
En algunos casos, el software de terceros no podría ejecutarse en puertos personalizados en absoluto, lo que requeriría soluciones más complejas, como iptables reglas DNAT en el nodo. Los servidores web tienen el problema adicional de esperar números de puerto convencionales en su software, como 80 para HTTP y 443 para HTTPS. Salirse de estas convenciones requiere un proxy inverso a través de un equilibrador de carga o hacer que los consumidores posteriores conozcan los distintos puertos (lo cual es mucho más fácil para los sistemas internos que para los externos). Algunos sistemas, como Borg de Google, utilizan este modelo. Kubernetes eligió el modelo de IP por pod para que fuera más cómodo de adoptar para los desarrolladores y facilitara la ejecución de cargas de trabajo de terceros. Por desgracia para nosotros, asignar y enrutar una dirección IP para cada pod añade una complejidad sustancial a un clúster Kubernetes.
Advertencia
Por defecto, Kubernetes permitirá cualquier tráfico hacia o desde cualquier pod. Esta conectividad pasiva significa, entre otras cosas, que cualquier pod de un clúster puede conectarse a cualquier otro pod de ese mismo clúster. Esto puede dar lugar fácilmente a abusos, especialmente si los servicios no utilizan autenticación o si un atacante obtiene credenciales.
Para más información, consulta "Plugins CNI populares".
Los pods creados y eliminados con sus propias direcciones IP pueden causar problemas a los principiantes que no entiendan este comportamiento. Supongamos que tenemos un pequeño servicio ejecutándose en Kubernetes, en forma de implementación con tres réplicas de pods. Cuando alguien de actualiza una imagen de contenedor en la implementación, Kubernetes realiza una actualización continua, eliminando los pods antiguos y creando nuevos pods utilizando la nueva imagen de contenedor. Es probable que estos nuevos pods tengan nuevas direcciones IP, haciendo inalcanzables las antiguas direcciones IP. Puede ser un error común de principiante hacer referencia a las IPs de los pods en la configuración o en los registros DNS manualmente, sólo para que no se resuelvan. Este error es lo que intentan resolver los servicios y los puntos finales, y se trata en el capítulo siguiente.
Al crear explícitamente un pod, es posible especificar la dirección IP. Los StatefulSets son un tipo de carga de trabajo incorporado, pensado para cargas de trabajo como las bases de datos, que mantienen un concepto de identidad de pod y dan a un nuevo pod el mismo nombre y dirección IP que al pod al que sustituye. En hay otros ejemplos en forma de CRD de terceros, y es posible escribir un CRD para fines específicos de red.
Nota
Los recursos personalizados son extensiones de la API de Kubernetes definidas por el autor. Permiten a los desarrolladores de software personalizar la instalación de su software en un entorno Kubernetes. Puedes encontrar más información sobre cómo escribir un CRD en la documentación.
Cada nodo Kubernetes ejecuta un componente llamado Kubelet, que gestiona los pods en el nodo. La funcionalidad de red en el Kubelet procede de interacciones de la API con un plugin CNI en el nodo. El plugin CNI es el que gestiona las direcciones IP de los pods y el aprovisionamiento de red de los contenedores individuales. En el capítulo anterior mencionamos en la parte de la interfaz homónima del CNI; el CNI define una interfaz estándar para gestionar la red de un contenedor. La razón de hacer de la CNI una interfaz es disponer de un estándar interoperable, cuando existan múltiples implementaciones del plugin CNI. El plugin CNI es responsable de asignar las direcciones IP de los pods y de mantener una ruta entre todos los pods (aplicables). Kubernetes no incluye un plugin CNI por defecto, lo que significa que en una instalación estándar de Kubernetes, los pods no pueden utilizar la red .
Empecemos a hablar de cómo el CNI habilita la red de vainas y de las diferentes disposiciones de la red.
Disposición de la red de nodos y nodos
El clúster debe tener un grupo de direcciones IP que controle para asignar una dirección IP a un pod, por ejemplo, 10.1.0.0/16. Los nodos y los pods deben tener conectividad L3 en este espacio de direcciones IP. Recuerda del Capítulo 1 que en L3, la capa de Internet, conectividad significa que los paquetes con una dirección IP pueden dirigirse a un host con esa dirección IP. Es importante señalar que la capacidad de entregar paquetes es más fundamental que la creación de conexiones (un concepto de L4). En L4, los cortafuegos pueden optar por permitir las conexiones del host A al B, pero rechazar las conexiones iniciadas desde el host B al A. Las conexiones L4 de A a B, las conexiones en L3, de A a B y de B a A, deben permitirse. Sin conectividad L3, los apretones de manos TCP no serían posibles, ya que no se podría entregar el SYN-ACK.
Generalmente, los pods no tienen direcciones MAC. Por lo tanto, no es posible la conectividad L2 con los pods. El CNI determinará esto para los pods.
En Kubernetes no hay requisitos sobre conectividad L3 con el mundo exterior. Aunque la mayoría de los clusters tienen conectividad a Internet, algunos están más aislados por motivos de seguridad.
A grandes rasgos, hablaremos en tanto de la entrada (tráfico que sale de un host o clúster) como de la salida (tráfico que entra en un host o clúster). Nuestro uso de "entrada" aquí no debe confundirse con el recurso Ingress de Kubernetes, que es un mecanismo HTTP específico para dirigir el tráfico a los servicios de Kubernetes.
En existen a grandes rasgos tres enfoques, con muchas variaciones, para estructurar la red de un clúster: redes aisladas, planas e islas. Hablaremos aquí de los enfoques generales y luego profundizaremos en detalles específicos de implementación cuando tratemos los plugins CNI más adelante en este capítulo.
Redes aisladas
En una red de clúster aislada , los nodos son enrutables en la red más amplia (es decir, los hosts que no forman parte del clúster pueden llegar a los nodos del clúster), pero los pods no. La Figura 4-2 muestra un clúster de este tipo. Observa que los pods no pueden llegar a otros pods (ni a ningún otro anfitrión) fuera del clúster.
Como el clúster no es enrutable desde la red general, varios clústeres pueden incluso utilizar el mismo espacio de direcciones IP. Ten en cuenta que el servidor de la API de Kubernetes tendrá que ser enrutable desde la red general, si los sistemas o usuarios externos deben poder acceder a la API de Kubernetes. Muchos proveedores de Kubernetes gestionados tienen una opción de "clúster seguro" como ésta, en la que no es posible el tráfico directo entre el clúster e Internet.
Ese aislamiento al clúster local puede ser espléndido para la seguridad si las cargas de trabajo del clúster permiten/requieren esa configuración, como los clústeres para el procesamiento por lotes. Sin embargo, no es razonable para todos los clústeres. La mayoría de los clústeres necesitarán alcanzar y/o ser alcanzados por sistemas externos, como los clústeres que deben soportar servicios que tienen dependencias en la Internet más amplia. Los equilibradores de carga y los proxies pueden utilizarse para romper esta barrera y permitir que el tráfico de Internet entre o salga de un clúster aislado .
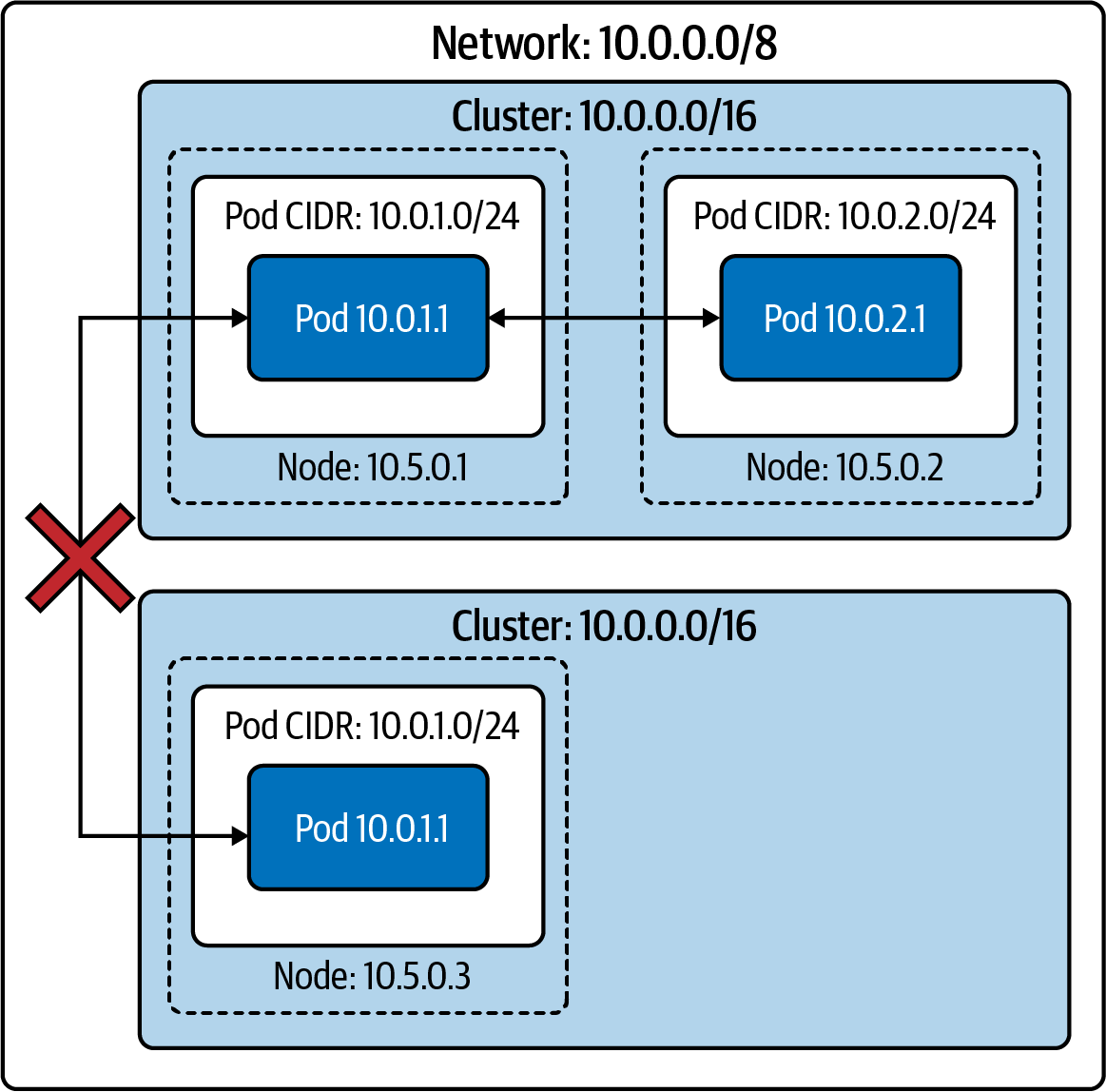
Figura 4-2. Dos clusters aislados en la misma red
Redes planas
En una red plana , todos los pods tienen una dirección IP enrutable desde la red más amplia. Salvo las reglas del cortafuegos, cualquier host de la red puede enrutarse a cualquier pod dentro o fuera del clúster. Esta configuración tiene numerosas ventajas en cuanto a simplicidad y rendimiento de la red. Los pods pueden conectarse directamente a hosts arbitrarios de la red.
Observa en la Figura 4-3 que los CIDRs de los pods de dos nodos no se solapan entre los dos clusters y, por tanto, no se asignará la misma dirección IP a dos pods. Como la red más amplia puede enrutar cada dirección IP de pod al nodo de ese pod, cualquier host de la red es alcanzable desde y hacia cualquier pod.
Esta apertura permite que cualquier host con suficientes datos de descubrimiento de servicios decida qué pod recibirá esos paquetes. Un equilibrador de carga externo al clúster puede equilibrar la carga de los pods, como un cliente gRPC en otro clúster.
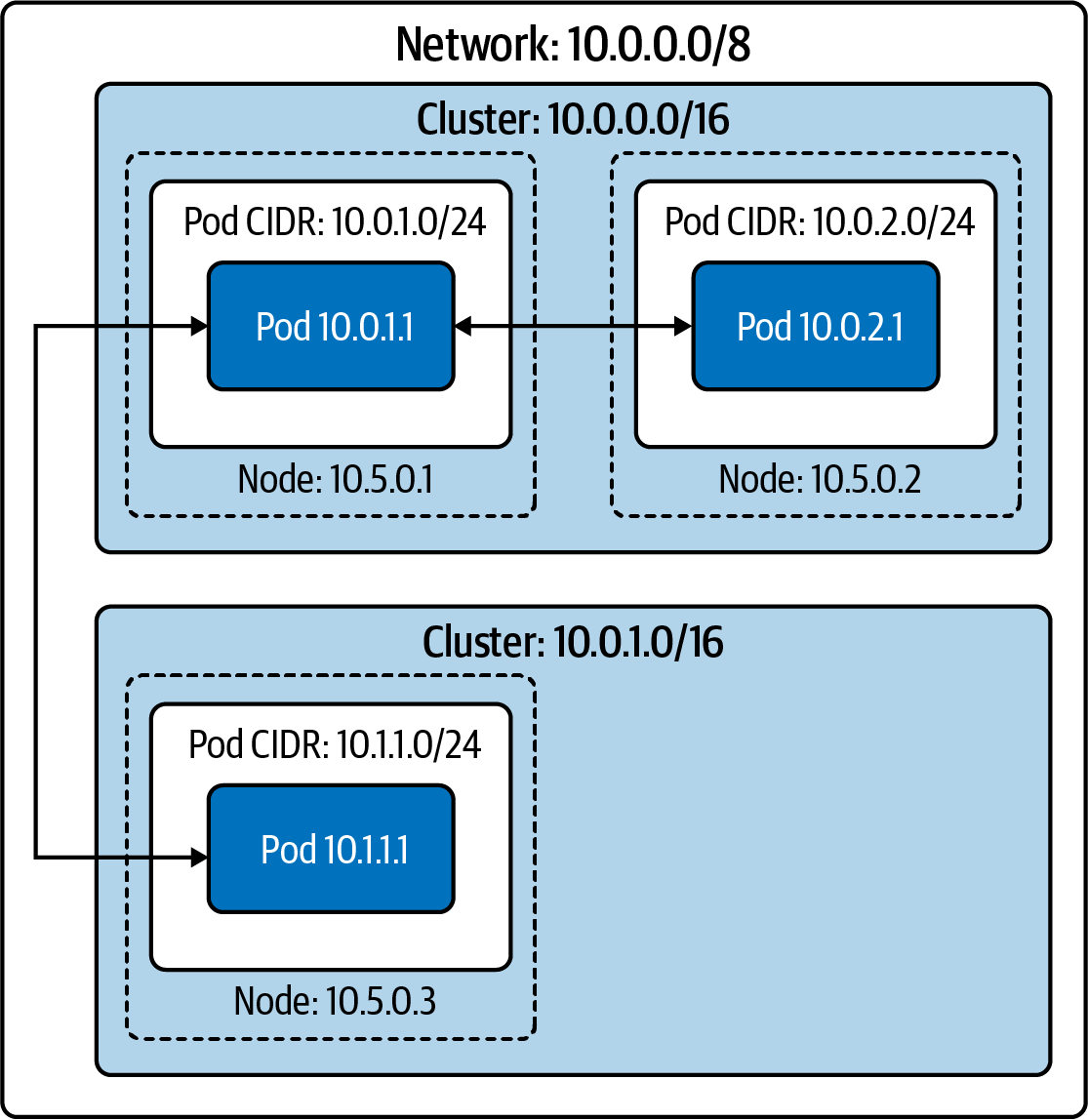
Figura 4-3. Dos agrupaciones en la misma red plana
El tráfico externo del pod (y el tráfico entrante del pod, cuando el destino de la conexión es una dirección IP específica del pod) tiene baja latencia y baja sobrecarga. Cualquier forma de proxy o reescritura de paquetes de incurre en un coste de latencia y procesamiento, que es pequeño pero no trivial (especialmente en una arquitectura de aplicación que implique muchos servicios backend, donde cada retraso se suma).
Por desgracia, este modelo requiere un espacio de direcciones IP grande y contiguo para cada clúster (es decir, un rango de direcciones IP en el que cada dirección IP del rango esté bajo tu control). Kubernetes requiere un único CIDR para las direcciones IP de los pods (para cada familia IP). Este modelo se puede conseguir con una subred privada (como 10.0.0.0/8 o 172.16.0.0/12); sin embargo, es mucho más difícil y costoso hacerlo con direcciones IP públicas, especialmente direcciones IPv4. Los administradores tendrán que utilizar NAT para conectar un clúster que funcione en un espacio de direcciones IP privado a la Internet de .
Aparte de que necesita un gran espacio de direcciones IP, los administradores también necesitan una red fácilmente programable. El plugin CNI debe asignar las direcciones IP de los pods y asegurarse de que existe una ruta a un nodo de un pod determinado.
Las redes planas, en una subred privada, son fáciles de conseguir en un entorno de proveedor de nube. La gran mayoría de las redes de proveedores en nube proporcionarán grandes subredes privadas y dispondrán de una API (o incluso de plugins CNI preexistentes) para la asignación de direcciones IP y la gestión de rutas .
Redes insulares
Racimo insular Las redes son, a alto nivel, una combinación deredes aisladas y planas.
En una configuración de clúster en isla, como se muestra en la Figura 4-4, los nodos tienen conectividad L3 con la red más amplia, pero los pods no. El tráfico hacia y desde los pods debe pasar por algún tipo de proxy, a través de los nodos. La mayoría de las veces, esto se consigue en iptables NAT de origen en los paquetes de un pod que salen del nodo. Esta configuración, denominada enmascaramiento, utiliza SNAT para reescribir las fuentes de los paquetes desde la dirección IP del pod a la dirección IP del nodo (consulta el Capítulo 2 para refrescar conocimientos sobre SNAT). En otras palabras, los paquetes parecen ser "del" nodo, en lugar del pod.
Al compartir una dirección IP y utilizar NAT, se ocultan las direcciones IP individuales de los pods. El cortafuegos y el reconocimiento basados en direcciones IP se hacen difíciles a través de la frontera del clúster. Dentro de un clúster, sigue siendo evidente qué dirección IP es qué pod (y, por tanto, qué aplicación). Los pods de otros clusters, o de otros hosts de la red más amplia, ya no tendrán esa asignación. El cortafuegos basado en direcciones IP y las listas de permitidos no son seguridad suficiente por sí solos, pero son una capa valiosa y a veces necesaria.
Veamos ahora cómo configuramos cualquiera de estos diseños de red con el kube-controller-manager. Plano de control se refiere a todas las funciones y procesos que determinan qué ruta utilizar para enviar el paquete o trama. Plano de datos se refiere a todas las funciones y procesos que reenvían paquetes/tramas de una interfaz a otra basándose en la lógica del plano de control.
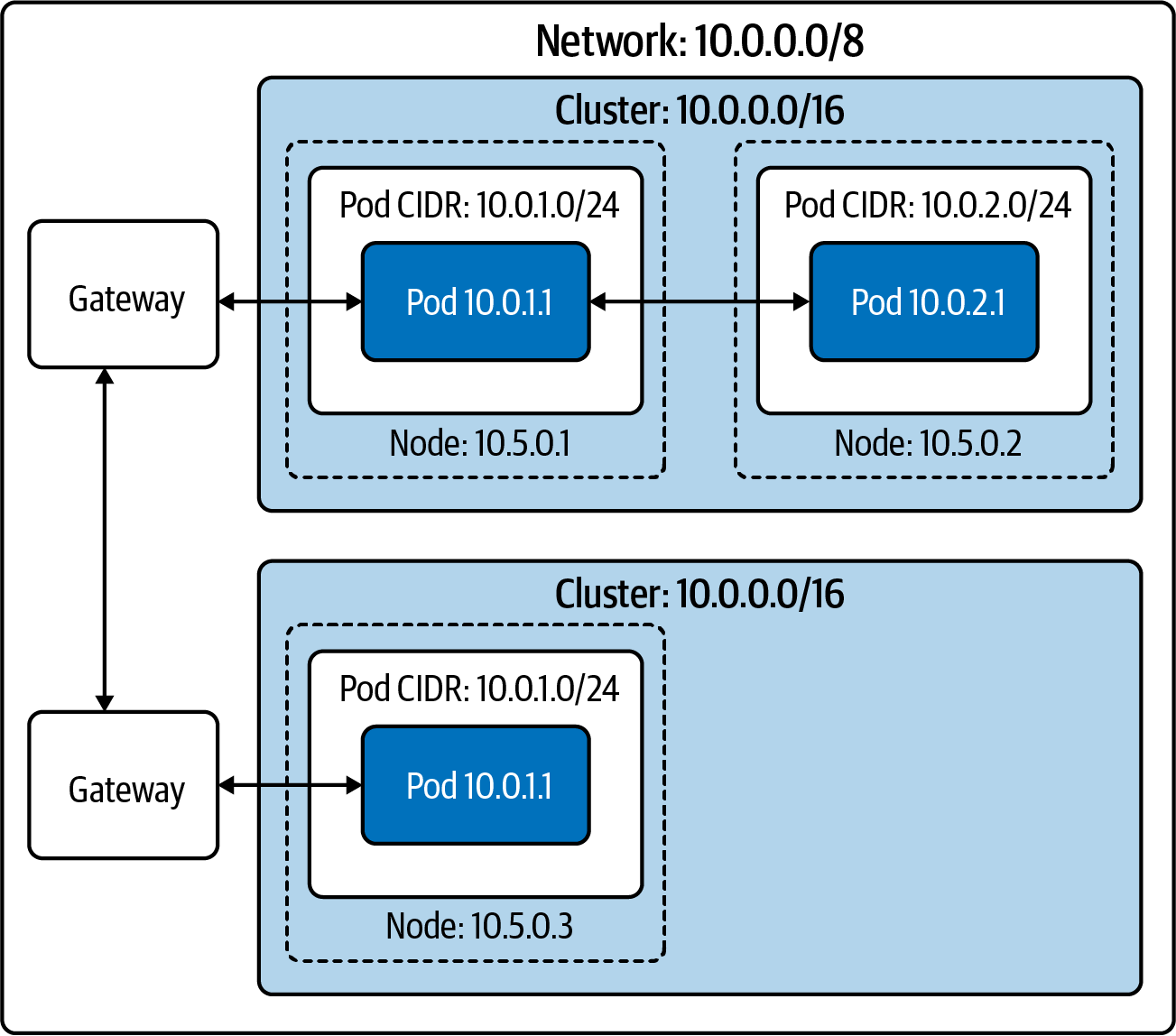
Figura 4-4. Dos en la configuración "red en isla
kube-controller-manager Configuración
El kube-controller-manager ejecuta la mayoría de los controladores individuales de Kubernetes en un binario y un proceso, donde vive la mayor parte de la lógica de Kubernetes. A alto nivel, un controlador en términos de Kubernetes es un software que vigila los recursos y toma medidas para sincronizar o imponer un estado específico (ya sea el estado deseado o reflejar el estado actual como estado). Kubernetes tiene muchos controladores, que generalmente "poseen" un tipo de objeto específico o una operación concreta.
kube-controller-manager incluye varios controladores que gestionan la pila de red de Kubernetes. En particular, los administradores establecen aquí el CIDR del clúster.
kube-controller-managerLaTabla 4-1 muestra algunos de los indicadores de configuración de red más importantes de .
| Bandera | Por defecto | Descripción |
|---|---|---|
|
verdadero |
Establece si los CIDR para pods deben asignarse y establecerse en el proveedor de la nube. |
|
Asignador de rangos |
Tipo de asignador CIDR a utilizar. |
|
Rango CIDR a partir del cual asignar las direcciones IP de los pods. Requiere que |
|
|
verdadero |
Establece si los CIDR deben ser asignados por |
|
24 para clusters IPv4, 64 para clusters IPv6 |
Tamaño de la máscara CIDR del nodo en un clúster. Kubernetes asignará a cada nodo |
|
24 |
Tamaño de la máscara para el CIDR del nodo en un clúster. Utiliza esta bandera en clusters de doble pila para permitir configuraciones tanto IPv4 como IPv6. |
|
64 |
Tamaño de la máscara para el nodo CIDR en un clúster. Utiliza esta bandera en clusters de doble pila para permitir configuraciones tanto IPv4 como IPv6. |
|
Rango CIDR de los servicios del cluster para asignar ClusterIPs de servicio. Requiere que |
Consejo
Todos los binarios de Kubernetes tienen documentación para sus banderas en los documentos en línea . Consulta todas las opciones de kube-controller-manager en ladocumentación.
Ahora que hemos hablado de la arquitectura de red de alto nivel y de la configuración de red en el plano de control de Kubernetes, veamos más de cerca cómo gestionan la red los nodos trabajadores de Kubernetes.
El Kubelet
El Kubelet es un único binario de que se ejecuta en cada nodo trabajador de un clúster. A un alto nivel, el Kubelet es responsable de gestionar cualquier pod programado en el nodo y de proporcionar actualizaciones de estado para el nodo y los pods en él. Sin embargo, el Kubelet actúa principalmente como coordinador para otro software en el nodo. El Kubelet gestiona una implementación de red de contenedores (a través del CNI) y un tiempo de ejecución de contenedores (a través del CRI).
Nota
Definimos los nodos trabajadores de como nodos Kubernetes que pueden ejecutar pods. Algunos clústeres ejecutan técnicamente el servidor API y etcd en nodos trabajadores restringidos. Esta configuración puede permitir que los componentes del plano de control se gestionen con la misma automatización que las cargas de trabajo típicas, pero expone modos de fallo y vulnerabilidades de seguridad adicionales.
Cuando un controlador (o usuario) crea un pod en la API de Kubernetes, inicialmente sólo existe como objeto de la API pod. El programador de Kubernetes busca un pod de este tipo e intenta seleccionar un nodo válido en el que programar el pod. Esta programación tiene varias restricciones. Nuestro pod, con sus solicitudes de CPU/memoria, no debe superar la CPU/memoria no solicitada restante en el nodo. Hay muchas opciones de selección disponibles, como afinidad/antiafinidad a nodos etiquetados u otros pods etiquetados o manchas en los nodos. Suponiendo que el programador encuentre un nodo que satisfaga todas las restricciones del pod, el programador escribe el nombre de ese nodo en el campo nodeName de nuestro pod. Digamos que Kubernetes programa el pod en node-1:
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
nodeName: "node-1"
containers:
- name: example
image: example:1.0
El Kubelet en node-1vigila todos los pods programados para él.El comandokubectl seríakubectl get pods -w --field-selector spec.nodeName=node-1. Cuando el Kubelet observa que nuestro pod existe pero no está presente en el nodo, lo crea. Pasaremos por alto los detalles del CRI y lacreación del propio contenedor. Una vez que el contenedor existe, el Kubelet realiza una llamada ADD al CNI, que indica al plugin CNI que cree la red de pods. En trataremos la interfaz y los plugins en nuestra próxima sección.
Preparación de la cápsula y sondas
Disponibilidad del pod es una indicación adicional de si el pod está preparado para servir tráfico. La disponibilidad del pod determina si la dirección del pod aparece en el objeto Endpoints desde una fuente externa. Otros recursos de Kubernetes que gestionan pods, como las Implementaciones, tienen en cuenta la disponibilidad del pod para la toma de decisiones, como el avance durante una actualización continua. Durante una implementación rodante, un nuevo pod está listo, pero un servicio, política de red o equilibrador de carga aún no está preparado para el nuevo pod por el motivo que sea. Esto puede causar la interrupción del servicio o la pérdida de capacidad del backend. Hay que tener en cuenta que si una especificación de pod contiene sondas de cualquier tipo, Kubernetes, por defecto, tiene éxito para los tres tipos.
Los usuarios pueden especificar comprobaciones de preparación del pod en la especificación del pod. A partir de ahí, el Kubelet ejecuta la comprobación especificada y actualiza el estado del pod en función de los éxitos o fracasos.
Las sondas afectan al campo .Status.Phase de una vaina. A continuación se enumeran las fases del pod y sus descripciones:
- Pendiente
-
El pod ha sido aceptado por el clúster, pero uno o más de los contenedores no se han configurado y preparado para ejecutarse. Esto incluye el tiempo que pasa un pod esperando a ser programado, así como el tiempo que pasa descargando imágenes de contenedores a través de la red.
- Correr
-
El pod se ha programado en un nodo y se han creado todos los contenedores. Al menos un contenedor sigue en ejecución o está en proceso de iniciarse o reiniciarse. Ten en cuenta que algunos contenedores pueden estar en estado de fallo, como en unCrashLoopBackoff.
- Con éxito
-
Todos los contenedores del pod han finalizado con éxito y no se reiniciarán.
- Fallido
-
Todos los contenedores del pod han finalizado, y al menos uno de ellos ha finalizado con un fallo. Es decir, el contenedor ha salido con un estado distinto de cero o ha sido finalizado por el sistema.
- Desconocido
-
Por alguna razón no se ha podido determinar el estado del pod. Esta fase suele producirse debido a un error en la comunicación con el Kubelet donde debería estar ejecutándose el pod.
El Kubelet realiza varios tipos de comprobaciones de salud de los contenedores individuales de un pod: sondas de vitalidad (livenessProbe),sondas de preparación (readinessProbe) y sondas de arranque (startupProbe). El Kubelet (y, por extensión, el propio nodo) debe poder conectarse a todos los contenedores que se ejecuten en ese nodo para poder realizar cualquier comprobación de salud HTTP.
Cada sonda tiene uno de tres resultados:
- Éxito
-
El contenedor superó el diagnóstico.
- Fallo
-
El contenedor no ha superado el diagnóstico.
- Desconocido
-
El diagnóstico ha fallado, por lo que no hay que hacer nada.
Las sondas pueden ser sondas exec, que intentan ejecutar un binario dentro del contenedor, sondas TCP o sondas HTTP. Si la sonda falla más del número de veces failureThreshold, Kubernetes considerará que la comprobación ha fallado. El efecto de esto depende del tipo de sonda.
Cuando falla la sonda de preparación de un contenedor, el Kubelet no lo termina. En su lugar, el Kubelet escribe el fallo en el estado del pod.
Si las sondas de actividad fallan, el Kubelet terminará el contenedor. Las sondas de actividad pueden provocar fácilmente fallos inesperados si se utilizan mal o están mal configuradas. El uso previsto de las sondas de actividad es que el Kubelet sepa cuándo debe reiniciar un contenedor. Sin embargo, como humanos, aprendemos rápidamente que si "algo va mal, reinícialo" es una estrategia peligrosa. Por ejemplo, supongamos que creamos una sonda de vida que carga la página principal de nuestra aplicación web. Además, supongamos que algún cambio en el sistema, ajeno al código de nuestro contenedor, hace que la página principal devuelva un error 404 o 500. Hay causas frecuentes de este tipo de escenarios, como un fallo de la base de datos backend, un fallo de un servicio requerido o un cambio de la bandera de características que expone un error. En cualquiera de estos escenarios, la sonda de actividad reiniciaría el contenedor. En el mejor de los casos, esto no sería útil; reiniciar el contenedor no resolverá un problema en otra parte del sistema y podría empeorar rápidamente el problema. Kubernetes tiene retrocesos de reinicio de contenedores (CrashLoopBackoff), que añaden un retraso cada vez mayor al reinicio de contenedores averiados. Con suficientes pods o fallos suficientemente rápidos, la aplicación puede pasar de tener un error en la página de inicio a estar hard-down. Dependiendo de la aplicación, los pods también pueden perder los datos almacenados en caché al reiniciarse; puede resultar agotador o imposible recuperarlos durante la hipotética degradación. Por ello, utiliza las sondas de liveness con precaución. Cuando los pods las utilizan, sólo dependen del contenedor que están comprobando, sin otras dependencias. Muchos ingenieros tienen puntos finales específicos de comprobación de estado, que proporcionan una validación mínima de criterios, como "PHP se está ejecutando y sirve a mi API".
Una sonda de arranque puede proporcionar un periodo de gracia antes de que surta efecto una sonda de caducidad. Las sondas de caducidad no terminarán un contenedor antes de que la sonda de arranque haya tenido éxito. Un ejemplo de caso de uso es permitir que un contenedor tarde muchos minutos en arrancar, pero terminarlo rápidamente si se vuelve insalubre después de arrancar.
En el Ejemplo 4-1, nuestro servidor web Golang tiene una sonda de disponibilidad que realiza un GET HTTP en el puerto 8080 a la ruta /healthz, mientras que la sonda de disponibilidad utiliza / en el mismo puerto.
Ejemplo 4-1. Podspec de Kubernetes para el servidor web mínimo de Golang
apiVersion:v1kind:Podmetadata:labels:test:livenessname:go-webspec:containers:-name:go-webimage:go-web:v0.0.1ports:-containerPort:8080livenessProbe:httpGet:path:/healthzport:8080initialDelaySeconds:5periodSeconds:5readinessProbe:httpGet:path:/port:8080initialDelaySeconds:5periodSeconds:5
Este estado no afecta al pod en sí, pero otros mecanismos de Kubernetes reaccionan ante él. Un ejemplo clave son los ReplicaSets (y, por extensión, las Implementaciones). Una sonda de preparación fallida hace que el controlador ReplicaSet cuente el pod como no preparado, dando lugar a una implementación detenida cuando hay demasiados pods nuevos no preparados. Los controladores Endpoints/EndpointsSlicetambién reaccionan ante el fallo de las sondas de preparación. Si la sonda de preparación de un pod falla, la dirección IP del pod no estará en el objeto endpoint, y el servicio no dirigirá el tráfico hacia él. Hablaremos más sobre los servicios y los puntos finales en el próximocapítulo.
La startupProbe informará al Kubelet de si la aplicación dentro del contenedor está iniciada. Esta sonda tiene prioridad sobre las demás. Si se define un startupProbe en la especificación del pod, se desactivan todas las demás sondas. Una vez questartupProbe tenga éxito, el Kubelet comenzará a ejecutar las demás sondas. Pero si la sonda de inicio falla, el Kubelet mata al contenedor, y éste ejecuta su política de reinicio. Al igual que los demás, si no existe startupProbe, el estado por defecto es éxito.
- inicialDelaySeconds
-
Cantidad de segundos tras el inicio del contenedor antes de que se inicien las sondas de liveness o readiness. Por defecto 0; Mínimo 0.
- periodoSegundos
-
Frecuencia con la que se realizan los sondeos. Por defecto 10; Mínimo 1.
- timeoutSeconds
-
Número de segundos tras los cuales se agota el tiempo de espera de la sonda. Por defecto 1; Mínimo 1.
- umbral de éxito
-
Mínimo de éxitos consecutivos para que la sonda tenga éxito después de fallar. Por defecto 1; debe ser 1 para las sondas de liveness y startup; Mínimo 1.
- umbral de fallo
-
Cuando falla una sonda, Kubernetes lo intentará muchas veces antes de rendirse. Rendirse en el caso de la sonda de vitalidad significa que el contenedor se reiniciará. En el caso de la sonda de preparación, el pod se marcará como No preparado. Por defecto 3; Mínimo 1.
Los desarrolladores de aplicaciones también pueden utilizar puertas de preparación para ayudar a determinar cuándo está lista la aplicación dentro del pod. Disponible y estable desde Kubernetes 1.14, para utilizar las puertas de preparación, los redactores de manifiestos añadiránreadiness gates en la especificación del pod para especificar una lista de condiciones adicionales que el Kubelet evalúa para la preparación del pod. Esto se hace en en el atributo ConditionType de las puertas de preparación en la especificación del pod. El ConditionTypees una condición de la lista de condiciones del pod con un tipo coincidente. Las puertas de preparación están controladas por el estado actual de los campos status.condition del pod, y si el Kubelet no puede encontrar una condición de este tipo en el campo status.conditionsde un pod, el estado de la condición se establece por defecto en Falso.
Como puedes ver en el siguiente ejemplo, la puerta de preparación feature-Y es verdadera, mientras que feature-X es falsa, por lo que el estado de la vaina es finalmente falso:
kind: Pod
…
spec:
readinessGates:
- conditionType: www.example.com/feature-X
- conditionType: www.example.com/feature-Y
…
status:
conditions:
- lastProbeTime: null
lastTransitionTime: 2021-04-25T00:00:00Z
status: "False"
type: Ready
- lastProbeTime: null
lastTransitionTime: 2021-04-25T00:00:00Z
status: "False"
type: www.example.com/feature-X
- lastProbeTime: null
lastTransitionTime: 2021-04-25T00:00:00Z
status: "True"
type: www.example.com/feature-Y
containerStatuses:
- containerID: docker://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
ready : true
Los equilibradores de carga como el ALB de AWS pueden utilizar la puerta de preparación como parte del ciclo de vida del pod antes de enviarle tráfico.
El Kubelet debe poder conectarse al servidor API de Kubernetes. En la Figura 4-5, podemos ver todas las conexiones realizadas por todos los componentes de un clúster:
- CNI
-
Red plugin en Kubelet que permite la conexión en red para obtener IPs para pods yservicios.
- gRPC
-
API para comunicar desde el servidor API a
etcd. - Kubelet
-
Todos los nodos Kubernetes tienen un Kubelet que garantiza que cualquier pod que se le asigne esté en ejecución y configurado en el estado deseado.
- CRI
-
La API gRPC compilada en Kubelet, permite a Kubelet hablar con tiempos de ejecución de contenedores utilizando la API gRPC. El proveedor del tiempo de ejecución del contenedor debe adaptarlo a la API CRI para permitir que Kubelet hable con los contenedores utilizando el estándar OCI (runC). CRI consta de búferes de protocolo y API y bibliotecas gRPC.
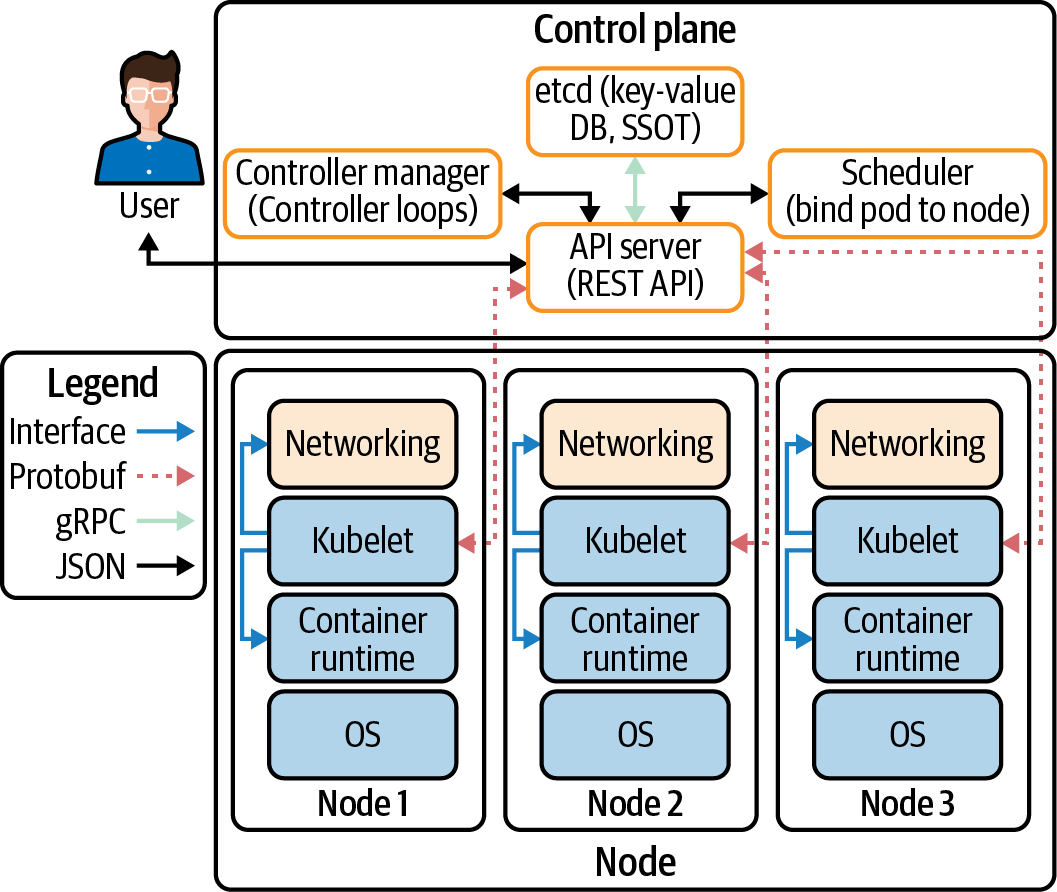
Figura 4-5. Flujo de datos del clúster entre componentes
La comunicación entre los pods y el Kubelet es posible gracias a la CNI. En nuestra próxima sección , hablaremos de la especificación CNI con ejemplos de varios proyectos CNI populares.
La Especificación CNI
La propia especificación de CNI es bastante sencilla. Según la especificación, hay cuatro operaciones que debe soportar un plugin CNI:
- AÑADE
-
Añade un contenedor a la red.
- DEL
-
Eliminar un contenedor de la red.
- COMPROBAR
-
Devuelve un error si hay un problema con la red del contenedor.
- VERSIÓN
-
Informa de la versión del complemento.
Consejo
La especificación CNI completa está disponible en GitHub.
En la Figura 4-6, podemos ver cómo Kubernetes (o el tiempo de ejecución, como el proyecto CNI se refiere a los orquestadores de contenedores) invoca las operaciones del plugin CNI mediante la ejecución de binarios. Kubernetes suministra cualquier configuración para el comando en JSON astdin y recibe la salida del comando en JSON a través de stdout. Los plugins CNI suelen tener binarios muy simples, que actúan como una envoltura para que Kubernetes los llame, mientras que el binario hace una llamada HTTP o RPC API a un backend persistente. Los mantenedores de CNI han discutido cambiar esto a un modelo HTTP o RPC, basándose en problemas de rendimiento cuando se lanzan procesos Windows con frecuencia.
Kubernetes sólo utiliza un plugin CNI a la vez, aunque la especificación CNI permite configuraciones multiplugin (es decir, asignar varias direcciones IP a un contenedor). Multus es un complemento CNI que sortea esta limitación de Kubernetes actuando como distribuidor de varios complementos CNI .
Nota
En el momento de escribir estas líneas, la especificación CNI se encuentra en la versión 0.4. No ha cambiado drásticamente a lo largo de los años y parece poco probable que cambie en el futuro: los responsables de la especificación tienen previsto publicar pronto la versión 1.0.
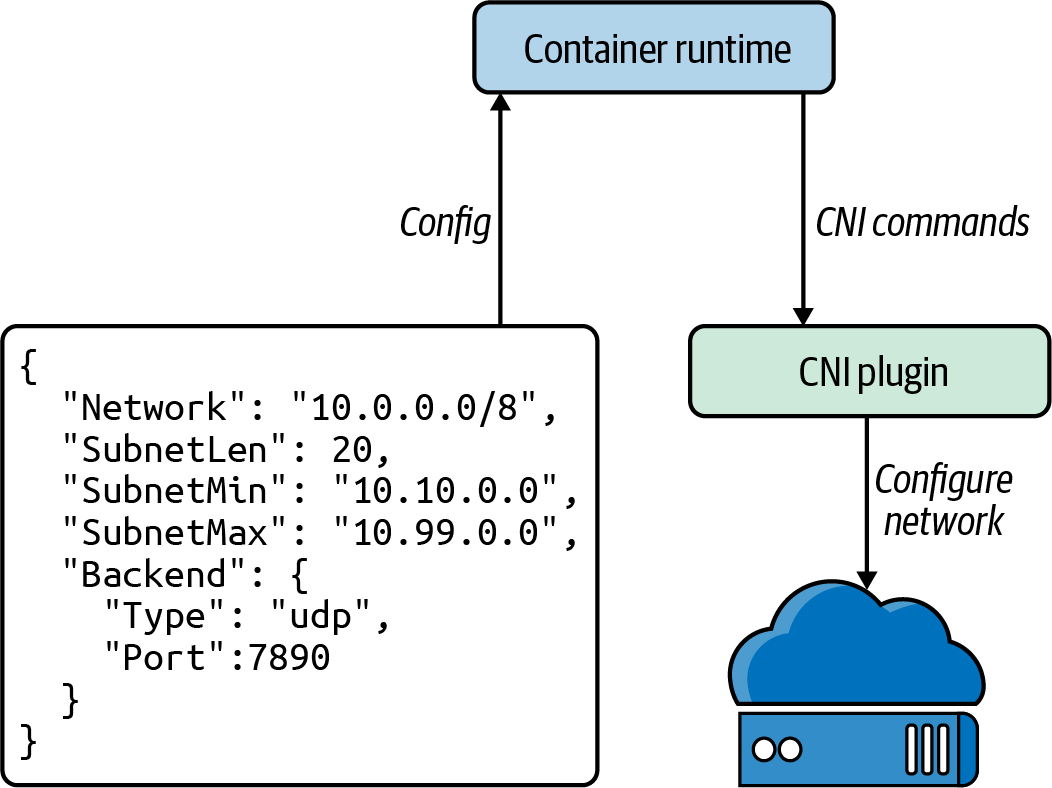
Figura 4-6. Configuración CNI
Plugins CNI
El plugin CNI tiene dos responsabilidades principales: asignar direcciones IP únicas para los pods y asegurarse de que existen rutas dentro de Kubernetes hacia cada dirección IP de pod. Estas responsabilidades significan que la red global en la que reside el clúster dicta el comportamiento del plugin CNI. Por ejemplo, si hay muy pocas direcciones IP o no es posible asignar suficientes direcciones IP a un nodo, los administradores del clúster tendrán que utilizar un plugin CNI que admita una red superpuesta. La pila de hardware, o el proveedor de la nube utilizado, suele dictar qué opciones de CNI son adecuadas. Enel Capítulo 6 se hablará de las principales plataformas en la nube y de cómo afecta el diseño de la red a la elección del CNI.
Para utilizar el CNI , añade --network-plugin=cni a los argumentos de inicio del Kubelet. Por defecto, el Kubelet lee la configuración CNI del directorio /etc/cni/net.d/ y espera encontrar el binario CNI en /opt/cni/bin/. Los administradores pueden anular la ubicación de la configuración con --cni-config-dir=<directory>, y el directorio del binario CNI con--cni-bin-dir=<directory>.
Nota
Las ofertas de Kubernetes gestionado, y muchas "distros" de Kubernetes, vienen con un CNI preconfigurado.
Hay dos grandes categorías de modelos de red CNI: redes planas y redes superpuestas. En una red plana, el controlador CNI utiliza direcciones IP de la red del clúster, lo que suele requerir que el clúster disponga de muchas direcciones IP. En una red superpuesta, el controlador CNI de crea una red secundaria dentro de Kubernetes, que utiliza la red del clúster (llamada red subyacente) para enviar paquetes. Las redes superpuestas crean una red virtual dentro del clúster. En una red superpuesta, el complemento CNI encapsula los paquetes. Hablamos de las redes superpuestas con más detalle enel Capítulo 3. Las redes superpuestas añaden una complejidad sustancial y no permiten que los hosts de la red del clúster se conecten directamente a los pods. Sin embargo, las redes superpuestas permiten que la red del clúster sea mucho más pequeña, ya que sólo hay que asignar direcciones IP a los nodos de esa red.
Los plugins CNI también suelen necesitar una forma de comunicar el estado entre nodos. Los plugins adoptan enfoques muy diferentes, como almacenar los datos en la API de Kubernetes, en una base de datos dedicada.
El plugin CNI también es responsable de llamar a los plugins IPAM para el direccionamiento IP.
La interfaz IPAM
La especificación CNI tiene una segunda interfaz , la interfaz de Gestión de Direcciones IP (IPAM), para reducir la duplicación de código de asignación de IP en los plugins CNI. El plugin IPAM debe determinar y mostrar la dirección IP de la interfaz, la pasarela y las rutas, como se muestra en el Ejemplo 4-2. La interfaz IPAM es similar a la CNI: un binario con entrada JSON a stdin y salida JSON desde stdout.
Ejemplo 4-2. Ejemplo de salida del plugin IPAM, de la documentación de la especificación CNI 0.4
{"cniVersion":"0.4.0","ips":[{"version":"<4-or-6>","address":"<ip-and-prefix-in-CIDR>","gateway":"<ip-address-of-the-gateway>"(optional)},...],"routes":[(optional){"dst":"<ip-and-prefix-in-cidr>","gw":"<ip-of-next-hop>"(optional)},...]"dns":{(optional)"nameservers":<list-of-nameservers>(optional)"domain":<name-of-local-domain>(optional)"search":<list-of-search-domains>(optional)"options":<list-of-options>(optional)}}
Ahora repasará varias de las opciones disponibles para que los administradores de clústeres elijan a la hora de implementar un CNI.
Plugins CNI populares
Cilium es un software de código abierto para asegurar de forma transparente la conectividad de red entre contenedores de aplicaciones. Cilium es un CNI consciente de L7/HTTP y puede aplicar políticas de red en L3-L7 utilizando un modelo de seguridad basado en la identidad y desacoplado del direccionamiento de red. La tecnología eBPF de Linux, de la que hablamos en el Capítulo 2, es la que impulsa a Cilium. Más adelante, en este mismo capítulo, profundizaremos en los objetos NetworkPolicy; por ahora, debes saber que son cortafuegos de nivel pod.
Flannel se centra en la red y es una forma sencilla y fácil de configurar un tejido de red de capa 3 diseñado para Kubernetes. Si un clúster requiere funcionalidades como políticas de red, un administrador debe implementar otras CNI, como Calico. Flannel utiliza el etcd existente en el clúster Kubernetes para almacenar su información de estado y evitar así proporcionar un almacén de datos dedicado.
Según , Calico "combina capacidades de red flexibles con la aplicación de seguridad en cualquier lugar para proporcionar una solución con rendimiento nativo del núcleo Linux y verdadera escalabilidad nativa en la nube". Calico no utiliza una red superpuesta. En su lugar, Calico configura una red de capa 3 que utiliza el protocolo de enrutamiento BGP para encaminar paquetes entre hosts. Calico también puede integrarse con Istio, una malla de servicios, para interpretar y aplicar políticas para las cargas de trabajo dentro del clúster en las capas de malla de servicios e infraestructura de red.
La Tabla 4-2 ofrece un breve resumen de los principales plugins CNI entre los que puedes elegir.
| Nombre | Soporte de NetworkPolicy | Almacenamiento de datos | Configuración de la red |
|---|---|---|---|
Cilio |
Sí |
etcd o cónsul |
Ipvlan(beta), veth, L7 consciente |
Franela |
No |
etcd |
Red superpuesta IPv4 de Capa 3 |
Calico |
Sí |
API etcd o Kubernetes |
Red de capa 3 mediante BGP |
Red tejida |
Sí |
Sin almacén de clústeres externo |
Red de malla superpuesta |
Nota
Las instrucciones completas para ejecutar KIND, Helm y Cilium están en el repositorio GitHub del libro.
Vamos a desplegar Cilium para probarlo con nuestro servidor web Golang en el Ejemplo 4-3. Necesitaremos un clúster Kubernetes para la implementación de Cilium. Una de las formas más sencillas que hemos encontrado de desplegar clusters para pruebas localmente es KIND, que significa Kubernetes en Docker. Es nos permitirá crear un clúster con un archivo de configuración YAML y luego, utilizando Helm, desplegar Cilium en ese clúster.
Ejemplo 4-3. Configuración de KIND para la implementación local de Cilium
kind: ClusterapiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
- role: worker
networking:
disableDefaultCNI: true
Especifica que estamos configurando un clúster KIND
La versión de la configuración de KIND
La lista de nodos del clúster
Un nodo del plano de control
Nodo trabajador 2
Nodo trabajador 3
Opciones de configuración de KIND para la conexión en red

Desactiva la opción de red por defecto para que podamos implementar Cilium
Nota
En la documentación encontrarás instrucciones para configurar un clúster KIND y mucho más.
Con el YAML de configuración del clúster KIND, podemos utilizar KIND para crear ese clúster con el siguiente comando. Si es la primera vez que lo ejecutas, tardará algún tiempo en descargar todas las imágenes Docker del plano de trabajo y de control:
$kind create cluster --config=kind-config.yaml Creating cluster"kind"... ✓ Ensuring node image(kindest/node:v1.18. 2)Preparing nodes ✓ Writing configuration Starting control-plane Installing StorageClass Joining worker nodes Set kubectl context to"kind-kind"You can now use your cluster with: kubectl cluster-info --context kind-kind Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community ߙ⊭--- Always verify that the cluster is up and running with kubectl.
$kubectl cluster-info --context kind-kind Kubernetes master -> control plane is running at https://127.0.0.1:59511 KubeDNS is running at https://127.0.0.1:59511/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy To further debug and diagnose cluster problems, use'kubectl cluster-info dump.'
Nota
Los nodos del clúster permanecerán en estado No preparado hasta que Cilium despliegue la red. Éste es el comportamiento normal del clúster.
Ahora que nuestro clúster está funcionando localmente, podemos empezar a instalar Cilium utilizando Helm, una herramienta de implementación de Kubernetes. Según su documentación, Helm es la forma preferida de instalar Cilium. En primer lugar, tenemos que añadir el repositorio de Helm para Cilium. Opcionalmente, puedes descargar las imágenes Docker para Cilium y, por último, ordenar a KIND que cargue las imágenes de Cilium en el clúster:
$helm repo add cilium https://helm.cilium.io/# Pre-pulling and loading container images is optional.$docker pull cilium/cilium:v1.9.1 kind load docker-image cilium/cilium:v1.9.1
Ahora que se han completado los requisitos previos para Cilium , podemos instalarlo en nuestro clúster con Helm. Hay muchas opciones de configuración para Cilium, y Helm configura las opciones con --set NAME_VAR=VAR:
$helm install cilium cilium/cilium --version 1.10.1\--namespace kube-system NAME: Cilium LAST DEPLOYED: Fri Jan115:39:59 2021 NAMESPACE: kube-system STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: You have successfully installed Cilium with Hubble. Your release version is 1.10.1. For any furtherhelp, visit https://docs.cilium.io/en/v1.10/gettinghelp/
Cilium instala varias piezas en el clúster: el agente, el cliente, el operador y el plugin cilium-cni:
- Agente
-
El agente Cilium,
cilium-agent, se ejecuta en cada nodo del clúster. El agente acepta la configuración a través de las API de Kubernetes que describen la red, el equilibrio de carga de servicios, las políticas de red y los requisitos de visibilidad y monitoreo. - Cliente (CLI)
-
El cliente Cilium CLI (Cilium) es una herramienta de línea de comandos que se instala junto con el agente Cilium. Interactúa con la API REST en el mismo nodo. La CLI permite a los desarrolladores inspeccionar el estado y la situación del agente local. También proporciona herramientas para acceder a los mapas eBPF y validar su estado directamente.
- Operario
-
El operador de es responsable de gestionar las tareas en el clúster, que deben gestionarse por clúster y no por nodo.
- Plugin CNI
-
El plugin CNI (
cilium-cni) interactúa con la API Cilium del nodo para activar la configuración para proporcionar pods de red, equilibrio de carga y políticas de red.
Podemos observar cómo se despliegan todos estos componentes en el clúster con el comando kubectl -n kube-system get pods --watch:
$ kubectl -n kube-system get pods --watch
NAME READY STATUS
cilium-65kvp 0/1 Init:0/2
cilium-node-init-485lj 0/1 ContainerCreating
cilium-node-init-79g68 1/1 Running
cilium-node-init-gfdl8 1/1 Running
cilium-node-init-jz8qc 1/1 Running
cilium-operator-5b64c54cd-cgr2b 0/1 ContainerCreating
cilium-operator-5b64c54cd-tblbz 0/1 ContainerCreating
cilium-pg6v8 0/1 Init:0/2
cilium-rsnqk 0/1 Init:0/2
cilium-vfhrs 0/1 Init:0/2
coredns-66bff467f8-dqzql 0/1 Pending
coredns-66bff467f8-r5nl6 0/1 Pending
etcd-kind-control-plane 1/1 Running
kube-apiserver-kind-control-plane 1/1 Running
kube-controller-manager-kind-control-plane 1/1 Running
kube-proxy-k5zc2 1/1 Running
kube-proxy-qzhvq 1/1 Running
kube-proxy-v54p4 1/1 Running
kube-proxy-xb9tr 1/1 Running
kube-scheduler-kind-control-plane 1/1 Running
cilium-operator-5b64c54cd-tblbz 1/1 RunningAhora que hemos implementado Cilium, podemos ejecutar la comprobación de conectividad de Cilium para asegurarnos de que funciona correctamente:
$kubectl create ns cilium-test namespace/cilium-test created$kubectl apply -n cilium-test\-f\https://raw.githubusercontent.com/strongjz/advanced_networking_code_examples/ master/chapter-4/connectivity-check.yaml deployment.apps/echo-a created deployment.apps/echo-b created deployment.apps/echo-b-host created deployment.apps/pod-to-a created deployment.apps/pod-to-external-1111 created deployment.apps/pod-to-a-denied-cnp created deployment.apps/pod-to-a-allowed-cnp created deployment.apps/pod-to-external-fqdn-allow-google-cnp created deployment.apps/pod-to-b-multi-node-clusterip created deployment.apps/pod-to-b-multi-node-headless created deployment.apps/host-to-b-multi-node-clusterip created deployment.apps/host-to-b-multi-node-headless created deployment.apps/pod-to-b-multi-node-nodeport created deployment.apps/pod-to-b-intra-node-nodeport created service/echo-a created service/echo-b created service/echo-b-headless created service/echo-b-host-headless created ciliumnetworkpolicy.cilium.io/pod-to-a-denied-cnp created ciliumnetworkpolicy.cilium.io/pod-to-a-allowed-cnp created ciliumnetworkpolicy.cilium.io/pod-to-external-fqdn-allow-google-cnp created
La prueba de conectividad desplegará una serie de Implementaciones de Kubernetes que utilizarán varias rutas de conectividad. Las rutas de conectividad vienen con y sin equilibrio de carga de servicio y en varias combinaciones de políticas de red. El nombre del pod indica la variante de conectividad, y la puerta de preparación y liveness indica el éxito o fracaso de la prueba:
$kubectl get pods -n cilium-test -w NAME READY STATUSecho-a-57cbbd9b8b-szn94 1/1 Runningecho-b-6db5fc8ff8-wkcr6 1/1 Runningecho-b-host-76d89978c-dsjm8 1/1 Running host-to-b-multi-node-clusterip-fd6868749-7zkcr 1/1 Running host-to-b-multi-node-headless-54fbc4659f-z4rtd 1/1 Running pod-to-a-648fd74787-x27hc 1/1 Running pod-to-a-allowed-cnp-7776c879f-6rq7z 1/1 Running pod-to-a-denied-cnp-b5ff897c7-qp5kp 1/1 Running pod-to-b-intra-node-nodeport-6546644d59-qkmck 1/1 Running pod-to-b-multi-node-clusterip-7d54c74c5f-4j7pm 1/1 Running pod-to-b-multi-node-headless-76db68d547-fhlz7 1/1 Running pod-to-b-multi-node-nodeport-7496df84d7-5z872 1/1 Running pod-to-external-1111-6d4f9d9645-kfl4x 1/1 Running pod-to-external-fqdn-allow-google-cnp-5bc496897c-bnlqs 1/1 Running
Ahora que Cilium gestiona nuestra red para el clúster, lo utilizaremos más adelante en este capítulo para obtener una visión general de NetworkPolicy. No todos los plugins CNI soportarán NetworkPolicy, por lo que es un detalle importante a la hora de decidir qué plugin utilizar .
kube-proxy
kube-proxy es otro demonio por nodo en Kubernetes, como Kubelet.kube-proxy proporciona una funcionalidad básica de equilibrio de carga dentro del clúster. Implementa servicios y se basa en Endpoints/EndpointSlices, dos objetos API de los que hablaremos en detalle en el próximo capítulo sobre abstracciones de red. Puede que te ayude consultar esa sección, pero la siguiente es la explicación relevante y rápida:
-
Los servicios definen un equilibrador de carga para un conjunto de pods.
-
Los puntos finales (y las rebanadas de puntos finales) enumeran un conjunto de IPs de pods listos. Se crean automáticamente a partir de un servicio, con el mismo selector de pods que el servicio.
La mayoría de los tipos de servicios tienen una dirección IP para el servicio, llamada dirección IP de clúster, que no es enrutable fuera del clúster. kube-proxy es responsable de enrutar las peticiones a la dirección IP de clúster de un servicio a los pods sanos. kube-proxy es, con mucho, la implementación más común para los servicios Kubernetes, pero hay alternativas a kube-proxy, como el modo de sustitución Cilium. Una parte sustancial de nuestro contenido sobre enrutamiento en el Capítulo 2 es aplicable a kube-proxy, sobre todo al depurar la conectividad o el rendimiento del servicio.
Nota
Las direcciones IP de losclusters no suelen ser enrutables desde fuera de uncluster.
kube-proxy tiene cuatro modos , que cambian su modo de ejecución y su conjunto exacto de características: userspace, iptables, ipvs, y kernelspace. Puedes especificar el modo utilizando--proxy-mode <mode>. Cabe señalar que todos los modos dependen de iptables en cierta medida.
Modo espacio de usuario
El primero y más antiguo es el modo userspace. En el modo userspace, kube-proxy ejecuta un servidor web y enruta todas las direcciones IP del servicio al servidor web, utilizando iptables. El servidor web termina las conexiones y desvía la solicitud a un pod de los endpoints del servicio. El modouserspace ya no se utiliza habitualmente, y te sugerimos que lo evites a menos que tengas una razón clara para utilizarlo.
Modo iptables
iptables El modo utiliza iptables por completo. Es el modo por defecto, y el más utilizado (esto puede deberse en parte a que el modo IPVS se graduó a la estabilidad GA más recientemente, y iptables es una tecnología Linux familiar).
iptables realiza un desvío de la conexión, en lugar de un verdadero equilibrio de carga. En otras palabras, el modo iptables dirigirá una conexión a un pod backend, y todas las peticiones realizadas utilizando esa conexión irán al mismo pod, hasta que se termine la conexión. Esto es sencillo y tiene un comportamiento predecible en escenarios ideales (por ejemplo, las solicitudes sucesivas en la misma conexión podrán beneficiarse de cualquier almacenamiento en caché local en los pods backend). También puede ser impredecible cuando se trata de conexiones de larga duración, como las conexiones HTTP/2 (en particular, HTTP/2 es el transporte para gRPC).
Supongamos que tienes dos pods, X y Y, que prestan un servicio, y que sustituyes X por Z durante una actualización continua normal. El pod más antiguo, Y, sigue teniendo todas las conexiones existentes, más la mitad de las conexiones que tuvieron que restablecerse cuando se cerró el pod X, lo que hace que el pod Y sirva mucho más tráfico. Hay muchas situaciones como ésta que conducen a un tráfico desequilibrado.
Recuerda nuestros ejemplos de la sección "iptables prácticos" del Capítulo 2. En ella, demostramos que iptables podía configurarse con una lista de direcciones IP y probabilidades de enrutamiento aleatorias, de forma que las conexiones se realizaran aleatoriamente entre todas las direcciones IP. Dado un servicio que tiene pods de backend sanos 10.0.0.1, 10.0.0.2, 10.0.0.3, y 10.0.0.4, kube-proxy crearía reglas secuenciales que enrutaran las conexiones de esta forma:
-
El 25% de las conexiones van a
10.0.0.1. -
El 33,3% de las conexiones no encaminadas van a
10.0.0.2. -
El 50% de las conexiones no enrutadas van a
10.0.0.3. -
Todas las conexiones no enrutadas van a
10.0.0.4.
Esto puede parecer poco intuitivo y lleva a algunos ingenieros a suponer que kube-proxy está enrutando mal el tráfico (sobre todo porque poca gente mira kube-proxy cuando los servicios funcionan como se espera). El detalle crucial es que cada regla de enrutamiento ocurre para conexiones que no han sido enrutadas en una regla anterior. La regla final enruta todas las conexiones a 10.0.0.4 (porque la conexión tiene que ir a algún sitio), la regla semifinal tiene un 50% de posibilidades de enrutar a 10.0.0.3 como elección de dos direcciones IP, y así sucesivamente. Las puntuaciones de aleatoriedad de enrutamiento se calculan siempre como 1 / ${remaining number of IP addresses}.
Aquí tienes las reglas de reenvío iptables para el servicio kube-dns de un clúster. En nuestro ejemplo, la dirección IP del clúster del servicio kube-dns es 10.96.0.10. Esta salida se ha filtrado y reformateado para mayor claridad:
$sudo iptables -t nat -L KUBE-SERVICES Chain KUBE-SERVICES(2references)target prot optsourcedestination /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain KUBE-MARK-MASQ udp -- !10.217.0.0/16 10.96.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain KUBE-SVC-TCOU7JCQXEZGVUNU udp -- anywhere 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain KUBE-MARK-MASQ tcp -- !10.217.0.0/16 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- anywhere 10.96.0.10 ADDRTYPE match dst-type LOCAL /* kubernetes service nodeports;NOTE: this must be the last rule in this chain */ KUBE-NODEPORTS all -- anywhere anywhere
Hay un par de reglas UDP y TCP para kube-dns. Nos centraremos en las UDP.
La primera regla UDP de marca todas las conexiones al servicio que no procedan de una dirección IP de pod (10.217.0.0/16 es el CIDR predeterminado de la red de pods) para enmascararlas.
La siguiente regla UDP tiene como objetivo la cadena KUBE-SVC-TCOU7JCQXEZGVUNU. Veámoslo más detenidamente:
$sudo iptables -t nat -L KUBE-SVC-TCOU7JCQXEZGVUNU Chain KUBE-SVC-TCOU7JCQXEZGVUNU(1references)target prot optsourcedestination /* kube-system/kube-dns:dns */ KUBE-SEP-OCPCMVGPKTDWRD3C all -- anywhere anywhere statistic mode random probability 0.50000000000 /* kube-system/kube-dns:dns */ KUBE-SEP-VFGOVXCRCJYSGAY3 all -- anywhere anywhere
Aquí vemos una cadena con un 50% de posibilidades de ejecutarse, y la cadena que se ejecutará en caso contrario. Si comprobamos la primera de esas cadenas, vemos que se dirige a 10.0.1.141, una de las IPs de nuestros dos pods CoreDNS:
$sudo iptables -t nat -L KUBE-SEP-OCPCMVGPKTDWRD3C Chain KUBE-SEP-OCPCMVGPKTDWRD3C(1references)target prot optsourcedestination /* kube-system/kube-dns:dns */ KUBE-MARK-MASQ all -- 10.0.1.141 anywhere /* kube-system/kube-dns:dns */ udp to:10.0.1.141:53 DNAT udp -- anywhere anywhere
Modo ipvs
ipvs utiliza IPVS, tratado en el Capítulo 2, en lugar de iptables, para el equilibrio de carga de las conexiones. el modoipvs admite seis modos de equilibrio de carga, especificados con --ipvs-scheduler:
-
rr: Round-robin -
lc: Conexión mínima -
dh: Hashing de destino -
sh: Hashing de origen -
sed: Retraso previsto más corto -
nq: Nunca hagas cola
Round-robin (rr) es el modo de equilibrio de carga por defecto. Es el más parecido al comportamiento del modo iptables (en el sentido de que las conexiones se realizan de forma bastante uniforme, independientemente del estado del pod), aunque el modo iptables no realiza realmente el enrutamiento round-robin.
Modo kernelspace
kernelspace es el modo más reciente, sólo para Windows, de . Proporciona una alternativa al modouserspace para Kubernetes en Windows, ya que iptables y ipvs son específicos de Linux.
Ahora que hemos cubierto los aspectos básicos del tráfico pod-to-pod en Kubernetes, echemos un vistazo a NetworkPolicy y a la seguridad del tráfico pod-to-pod.
Política de red
El comportamiento predeterminado de Kubernetes es permitir el tráfico entre dos pods cualesquiera de la red del clúster. Este comportamiento es una elección de diseño deliberada para facilitar la adopción y la flexibilidad de la configuración, pero es altamente indeseable en la práctica. Permitir que cualquier sistema realice (o reciba) conexiones arbitrarias crea riesgos. Un atacante de puede sondear los sistemas y explotar potencialmente las credenciales capturadas o encontrar una autenticación debilitada o ausente. Permitir conexiones arbitrarias también facilita la exfiltración de datos de un sistema a través de una carga de trabajo comprometida. Todo en todo, desaconsejamos encarecidamente ejecutar clusters reales sin NetworkPolicy. Dado que todos los pods pueden comunicarse con todos los demás pods, recomendamos encarecidamente que los propietarios de las aplicaciones utilicen objetos NetworkPolicy junto con otras medidas de seguridad de la capa de aplicación, como tokens de autenticación o seguridad mutua de la capa de transporte (mTLS), para cualquier comunicación de red.
NetworkPolicy es un tipo de recurso en Kubernetes que contiene reglas de cortafuegos basadas en permisos. Los usuarios pueden añadir objetosNetworkPolicy para restringir las conexiones hacia y desde los pods. El recurso NetworkPolicy actúa como una configuración para los plugins CNI, que a su vez son responsables de garantizar la conectividad entre pods. La API de Kubernetes declara que la compatibilidad con NetworkPolicy es opcional para los controladores CNI, lo que significa que algunos controladores CNI no admiten políticas de red, como se muestra en la Tabla 4-3. Si un desarrollador crea un NetworkPolicy cuando utiliza un controlador CNI que no admite objetos NetworkPolicy, no afecta a la seguridad de red del pod. Algunos controladores CNI, como los productos empresariales o los controladores CNI internos de la empresa, pueden introducir su equivalente de un NetworkPolicy. Algunos controladores CNI también pueden tener "interpretaciones" ligeramente diferentes de la especificación NetworkPolicy.
| Plugin CNI | Política de red admitida |
|---|---|
Calico |
Sí, y admite políticas adicionales específicas de los plugins |
Cilio |
Sí, y admite políticas adicionales específicas de los plugins |
Franela |
No |
Kubenet |
No |
El ejemplo 4-4 detalla un objeto NetworkPolicy, que contiene un selector de pod , reglas de entrada y reglas de salida. La política se aplicará a todos los pods del mismo espacio de nombres que el NetworkPolicy que coincida con la etiqueta del selector. Este uso de etiquetas selectoras es coherente con otras API de Kubernetes: una especificación identifica los pods por sus etiquetas en lugar de por sus nombres u objetos padre.
Ejemplo 4-4. La estructura general de una NetworkPolicy
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:demonamespace:defaultspec:podSelector:matchLabels:app:demopolicyTypes:-Ingress-Egressingress:[]NetworkPolicyIngressRule# Not expandedegress:[]NetworkPolicyEgressRule# Not expanded
Antes de adentrarnos en la API, vamos a recorrer a través de un sencillo ejemplo de creación de un NetworkPolicy para reducir el ámbito de acceso de algunos pods. Supongamos que tenemos dos componentes distintos: demo y demo-DB. Como en la Figura 4-7 no tenemosNetworkPolicy, todos los pods pueden comunicarse con todos los demás pods (incluidos los pods hipotéticamente no relacionados, que no se muestran).
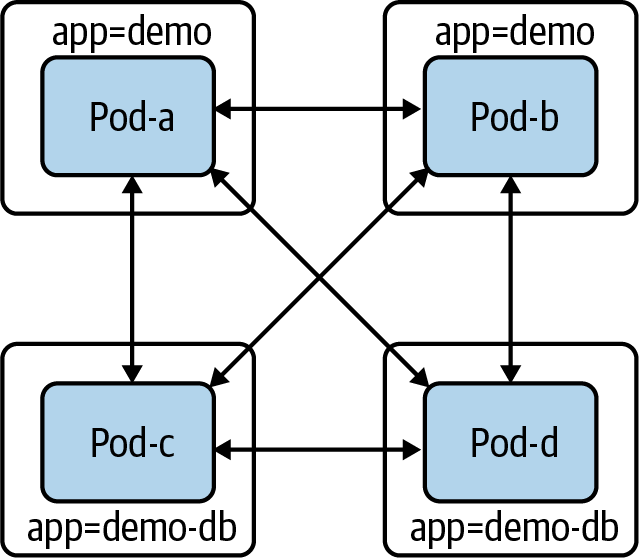
Figura 4-7. Vainas sin objetos NetworkPolicy
Restrinjamos el nivel de acceso de demo-DB. Si creamos el siguiente NetworkPolicy que seleccione los pods demo-DB, los podsdemo-DB no podrán enviar ni recibir ningún tráfico:
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:demo-dbnamespace:defaultspec:podSelector:matchLabels:app:demo-dbpolicyTypes:-Ingress-Egress
En la Figura 4-8, podemos ver ahora que los pods con la etiqueta app=demo ya no pueden crear ni recibir conexiones.
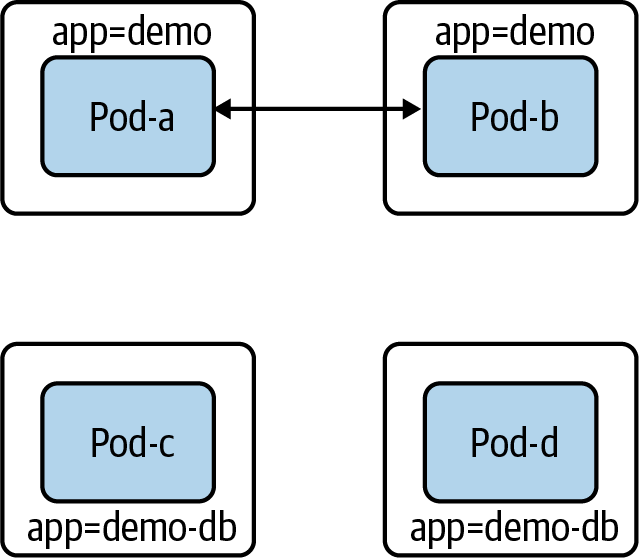
Figura 4-8. Los pods con la etiqueta app:demo-db no pueden recibir ni enviar tráfico
No tener acceso a la red no es deseable para la mayoría de las cargas de trabajo, incluida nuestra base de datos de ejemplo. Nuestro demo-db debe (sólo) poder recibir conexiones de demo pods. Para ello, debemos añadir una regla de entrada a NetworkPolicy:
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:demo-dbnamespace:defaultspec:podSelector:matchLabels:app:demo-dbpolicyTypes:-Ingress-Egressingress:-from:-podSelector:matchLabels:app:demo
Ahora los pods demo-db sólo pueden recibir conexiones de los pods demo. Además, los pods demo-db no pueden establecer conexiones (como se muestra en la Figura 4-9).
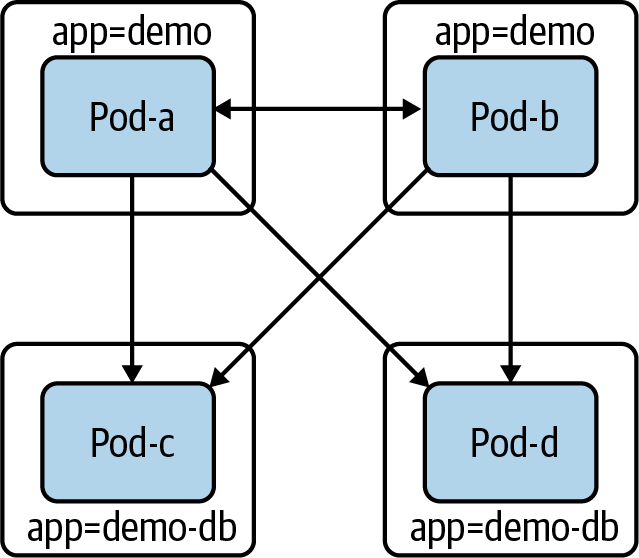
Figura 4-9. Los pods con la etiqueta app:demo-db no pueden crear conexiones, y sólo pueden recibir conexiones de los pods app:demo
Advertencia
Si los usuarios pueden cambiar las etiquetas de forma involuntaria o maliciosa, pueden cambiar la forma en que los objetos NetworkPolicy se aplican a todos los pods. En nuestro ejemplo anterior, si un atacante pudiera editar la etiqueta app: demo-DB en un pod de ese mismo espacio de nombres, laNetworkPolicy que creamos ya no se aplicaría a ese pod. Del mismo modo, un atacante podría obtener acceso desde otro pod de ese espacio de nombres si pudiera añadir la etiqueta app: demo a su pod comprometido.
El ejemplo anterior es sólo un ejemplo de ; con Cilium podemos crear estosNetworkPolicy objetos para nuestro servidor web Golang.
Ejemplo de NetworkPolicy con Cilium
Nuestro servidor web Golang se conecta ahora a una base de datos Postgres sin TLS. Además, sin objetos NetworkPolicy, cualquier pod de la red puede husmear el tráfico entre el servidor web Golang y la base de datos, lo que supone un riesgo potencial para la seguridad. A continuación vamos a desplegar nuestra aplicación web Golang y su base de datos, y después desplegaremos los objetos NetworkPolicy que sólo permitirán la conectividad con la base de datos desde el servidor web. Utilizando el mismo clúster KIND de la instalación de Cilium, vamos a desplegar la base de datos Postgres con los siguientes comandos YAML y kubectl:
$ kubectl apply -f database.yaml
service/postgres created
configmap/postgres-config created
statefulset.apps/postgres createdAquí desplegamos nuestro servidor web como una implementación de Kubernetes en nuestro clúster KIND:
$ kubectl apply -f web.yaml
deployment.apps/app createdPara ejecutar las pruebas de conectividad de dentro de la red del clúster, desplegaremos y utilizaremos un pod dnsutils que dispone de herramientas básicas de red como ping y curl:
$ kubectl apply -f dnsutils.yaml
pod/dnsutils createdComo no estamos desplegando un servicio con entrada, podemos utilizar kubectl port-forward para probar la conectividad con nuestro servidor web:
kubectl port-forward app-5878d69796-j889q 8080:8080
Nota
Puedes encontrar más información sobre kubectl port-forward en la documentación.
Ahora, desde nuestro terminal local , podemos llegar a nuestra API:
$curl localhost:8080/ Hello$curl localhost:8080/healthz Healthy$curl localhost:8080/data Database Connected
Vamos a probar la conectividad con nuestro servidor web dentro del clúster desde otros pods. Para ello, necesitamos obtener la dirección IP de nuestro pod de servidor web:
$kubectl get pods -lapp=app -o wide NAME READY STATUS RESTARTS AGE IP NODE app-5878d69796-j889q 1/1 Running087m 10.244.1.188 kind-worker3
Ahora podemos probar la conectividad L4 y L7 con el servidor web desde el pod dnsutils:
$kubectlexecdnsutils -- nc -z -vv 10.244.1.188 8080 10.244.1.188(10.244.1.188:8080)open sent 0, rcvd 0
Desde nuestro dnsutils, podemos probar el acceso a la API HTTP de capa 7:
$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/ Hello$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/healthz Healthy
También podemos probarlo en el pod de base de datos. En primer lugar, tenemos que recuperar la dirección IP del pod de base de datos, 10.244.2.189. Podemos utilizar kubectl con una combinación de etiquetas y opciones para obtener esta información:
$kubectl get pods -lapp=postgres -o wide NAME READY STATUS RESTARTS AGE IP NODE postgres-0 1/1 Running098m 10.244.2.189 kind-worker
De nuevo, vamos a utilizar dnsutils pod para probar la conectividad con la base de datos Postgres a través de su puerto predeterminado 5432:
$kubectlexecdnsutils -- nc -z -vv 10.244.2.189 5432 10.244.2.189(10.244.2.189:5432)open sent 0, rcvd 0
El puerto está abierto para que todos lo utilicen, ya que no hay ninguna política de red. Ahora vamos a restringirlo con una política de red Cilium. Los siguientes comandos implementan las políticas de red para que podamos probar la conectividad de red segura. Restrinjamos primero el acceso al pod de la base de datos sólo al servidor web. Aplica la política de red que sólo permite el tráfico desde el pod del servidor web a la base de datos:
$ kubectl apply -f layer_3_net_pol.yaml
ciliumnetworkpolicy.cilium.io/l3-rule-app-to-db createdLa Implementación de objetos Cilium crea recursos que se pueden recuperar igual que los pods con kubectl. Conkubectl describe ciliumnetworkpolicies.cilium.io l3-rule-app-to-db, podemos ver toda la información sobre la regla desplegada a través del YAML:
$ kubectl describe ciliumnetworkpolicies.cilium.io l3-rule-app-to-db
Name: l3-rule-app-to-db
Namespace: default
Labels: <none>
Annotations: API Version: cilium.io/v2
Kind: CiliumNetworkPolicy
Metadata:
Creation Timestamp: 2021-01-10T01:06:13Z
Generation: 1
Managed Fields:
API Version: cilium.io/v2
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.:
f:kubectl.kubernetes.io/last-applied-configuration:
f:spec:
.:
f:endpointSelector:
.:
f:matchLabels:
.:
f:app:
f:ingress:
Manager: kubectl
Operation: Update
Time: 2021-01-10T01:06:13Z
Resource Version: 47377
Self Link:
/apis/cilium.io/v2/namespaces/default/ciliumnetworkpolicies/l3-rule-app-to-db
UID: 71ee6571-9551-449d-8f3e-c177becda35a
Spec:
Endpoint Selector:
Match Labels:
App: postgres
Ingress:
From Endpoints:
Match Labels:
App: app
Events: <none>Con la política de red aplicada, el pod dnsutils ya no puede alcanzar el pod de la base de datos; podemos verlo en el tiempo de espera al intentar alcanzar el puerto de la base de datos desde los pods dnsutils:
$kubectlexecdnsutils -- nc -z -vv -w510.244.2.189 5432 nc: 10.244.2.189(10.244.2.189:5432): Operation timed out sent 0, rcvd 0commandterminated withexitcode 1
Mientras el pod del servidor web sigue conectado al pod de la base de datos, la ruta /data conecta el servidor web a la base de datos y el NetworkPolicy lo permite:
$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected$curl localhost:8080/data Database Connected
Ahora vamos a aplicar la política de capa 7. Cilium es consciente de la capa 7, por lo que podemos bloquear o permitir una solicitud específica en las rutas URI HTTP. En nuestra política de ejemplo, permitimos GETs HTTP en / y /data pero no los permitimos en /healthz; vamos a probarlo:
$ kubectl apply -f layer_7_netpol.yml
ciliumnetworkpolicy.cilium.io/l7-rule createdPodemos ver la política aplicada como cualquier otro objeto de Kubernetes en la API:
$kubectl get ciliumnetworkpolicies.cilium.io NAME AGE l7-rule 6m54s$kubectl describe ciliumnetworkpolicies.cilium.io l7-rule Name: l7-rule Namespace: default Labels: <none> Annotations: API Version: cilium.io/v2 Kind: CiliumNetworkPolicy Metadata: Creation Timestamp: 2021-01-10T00:49:34Z Generation: 1 Managed Fields: API Version: cilium.io/v2 Fields Type: FieldsV1 fieldsV1: f:metadata: f:annotations: .: f:kubectl.kubernetes.io/last-applied-configuration: f:spec: .: f:egress: f:endpointSelector: .: f:matchLabels: .: f:app: Manager: kubectl Operation: Update Time: 2021-01-10T00:49:34Z Resource Version: 43869 Self Link:/apis/cilium.io/v2/namespaces/default/ciliumnetworkpolicies/l7-rule UID: 0162c16e-dd55-4020-83b9-464bb625b164 Spec: Egress: To Ports: Ports: Port: 8080 Protocol: TCP Rules: Http: Method: GET Path: / Method: GET Path: /data Endpoint Selector: Match Labels: App: app Events: <none>
Como vemos, / y /data están disponibles, pero no /healthz, precisamente lo que esperamos de NetworkPolicy:
$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/ Hello$kubectlexecdnsutils -- wget -qO- -T510.244.1.188:8080/healthz wget: error getting responsecommandterminated withexitcode 1
Estos pequeños ejemplos muestran lo potentes que pueden ser las políticas de red Cilium para reforzar la seguridad de la red dentro del clúster. Recomendamos encarecidamente que los administradores seleccionen un CNI que admita políticas de red y obliguen a los desarrolladores a utilizarlas. Las políticas de red tienen espacio entre nombres, y si los equipos tienen configuraciones similares, los administradores del clúster pueden y deben obligar a los desarrolladores a definir políticas de red para mayor seguridad .
Hemos utilizado dos aspectos de la API de Kubernetes, las etiquetas y los selectores; en la próxima sección daremos más ejemplos de cómo se utilizan dentro de un clúster.
Selección de vainas
Los pods están sin restricciones hasta que son seleccionados por un NetworkPolicy. Si se seleccionan, el plugin CNI permite la entrada o salida del pod sólo cuando una regla coincidente lo permite. Un NetworkPolicy tiene un campo spec.policyTypes que contiene una lista de tipos de políticas (entrada o salida). Por ejemplo, si seleccionamos un pod con un NetworkPolicy en el que aparece la entrada pero no la salida, se restringirá la entrada y no la salida.
El campo spec.podSelector dictará a qué pods se aplicará el NetworkPolicy. Un label selector.vacío (podSelector: {}) seleccionará todos los pods del espacio de nombres . En breve trataremos con más detalle los selectores de etiquetas .
NetworkPolicy son objetos con espacio de nombres, lo que significa que existen en un espacio de nombres específico y se aplican a él. El campo spec
.podSelector sólo puede seleccionar pods cuando están en el mismo espacio de nombres que el NetworkPolicy. Esto significa que si seleccionas app:
demo, sólo se aplicará en el espacio de nombres actual, y cualquier pod de otro espacio de nombres con la etiqueta app: demo no se verá afectado.
Existen múltiples soluciones para que consiga el comportamiento firewalled-by-default, entre las que se incluyen las siguientes:
-
Crear un objeto general de denegación de todo
NetworkPolicypara cada espacio de nombres, lo que obligará a los desarrolladores a añadir objetosNetworkPolicyadicionales para permitir el tráfico deseado. -
Añadir un plugin CNI personalizado que viole deliberadamente el comportamiento de la API abierta por defecto. Múltiples plugins CNI tienen una configuración adicional que expone este tipo de comportamiento.
-
Crear políticas de admisión para exigir que las cargas de trabajo tengan un
NetworkPolicy.
NetworkPolicy dependen en gran medida de etiquetas y selectores; por eso, vamos a sumergirnos en ejemplos más complejos.
El tipo LabelSelector
Esta es la primera vez en este libro que vemos un LabelSelector en un recurso. Es un elemento de configuración omnipresente en Kubernetes y aparecerá muchas veces en el próximo capítulo, así que cuando llegues allí, puede ser útil volver a mirar esta sección como referencia.
Cada objeto en Kubernetes tiene un campo metadata, con el tipo ObjectMeta. Eso da a cada tipo los mismos campos de metadatos, como etiquetas. Las etiquetas son un mapa de pares de cadenas clave-valor:
metadata:labels:colour:purpleshape:square
Un LabelSelector identifica un grupo de recursos por las etiquetas presentes (o ausentes). Muy pocos recursos en Kubernetes harán referencia a otros recursos por su nombre. En su lugar, la mayoría de los recursos (NetworkPolicy objetos, servicios, implementaciones y otros objetos de Kubernetes). utilizan la coincidencia de etiquetas con un LabelSelector. LabelSelectors también pueden utilizarse en llamadas a la API y kubectly evitar devolver objetos irrelevantes. Un LabelSelector tiene dos campos: matchExpressions y matchLabels. El comportamiento normal para un LabelSelector vacío es seleccionar todos los objetos del ámbito, por ejemplo todos los pods del mismo espacio de nombres que un NetworkPolicy. matchLabels es el más sencillo de los dos. matchLabels contiene un mapa de pares clave-valor. Para que un objeto coincida, cada clave debe estar presente en el objeto, y esa clave debe tener el valor correspondiente.matchLabels, a menudo con una sola clave (por ejemplo, app=example-thing), suele ser suficiente para un selector.
En el Ejemplo 4-5, podemos ver un objeto coincidente que tiene tanto la etiqueta colour=purple como la etiqueta shape=square.
Ejemplo4-5. matchLabels ejemplo
matchLabels:colour:purpleshape:square
matchExpressions es más potente pero más complicado. Contiene una lista de LabelSelectorRequirements. Todos los requisitos deben ser verdaderos para que un objeto coincida. La Tabla 4-4 muestra todos los campos requeridos para unmatchExpressions.
| Campo | Descripción |
|---|---|
clave |
La clave de la etiqueta con la que se compara este requisito. |
operador |
Una de
|
valores |
Una lista de valores de cadena para la clave en cuestión. Debe estar vacía cuando el operador sea |
Veamos en dos breves ejemplos de matchExpressions.
El equivalente matchExpressions de nuestro ejemplo anterior matchLabels se muestra en el Ejemplo 4-6.
Ejemplo 4-6. matchExpressions ejemplo 1
matchExpressions:-key:colouroperator:Invalues:-purple-key:shapeoperator:Invalues:-square
matchExpressions del Ejemplo 4-7, coincidirá con objetos cuyo color no sea rojo, naranja o amarillo, y con una etiqueta de forma.
Ejemplo 4-7. matchExpressions ejemplo 2
matchExpressions:-key:colouroperator:NotInvalues:-red-orange-yellow-key:shapeoperator:Exists
Ahora que ya tenemos cubiertas las etiquetas, podemos hablar de las reglas de . Las reglas aplicarán nuestras políticas de red una vez identificada una coincidencia.
Reglas
NetworkPolicy Los objetos contienen secciones de configuración de entrada y salida distintas, que contienen una lista de reglas de entrada y reglas de salida, respectivamente. NetworkPolicy Las reglas actúan como excepciones, o una "lista de permitidos", al bloqueo por defecto causado por la selección de pods en una política. Las reglas no pueden bloquear el acceso; sólo pueden añadirlo. Si varios objetos NetworkPolicy seleccionan un pod, se aplican todas las reglas de cada uno de esos objetos NetworkPolicy. Puede tener sentido utilizar varios objetos NetworkPolicy para el mismo conjunto de pods (por ejemplo, declarando permisos de aplicación en una política y permisos de infraestructura como la exportación de telemetría en otra). Sin embargo, ten en cuenta que no tienen por qué ser objetos NetworkPolicy separados, y con demasiados objetos NetworkPolicy puede resultar difícil razonar.
Advertencia
Para soportar las comprobaciones de salud y las comprobaciones de vitalidad desde el Kubelet, el plugin CNI debe permitir siempre el tráfico desde el nodo de un pod.
Es posible abusar de las etiquetas si un atacante tiene acceso al nodo (incluso sin privilegios de administrador). Los atacantes pueden falsificar la IP de un nodo y entregar paquetes con la dirección IP del nodo como origen.
Las reglas de entrada y las reglas de salida son tipos distintos en la API NetworkPolicy (NetworkPolicyIngressRule yNetworkPolicyEgressRule). Sin embargo, funcionalmente están estructuradas de la misma manera. CadaNetworkPolicyIngressRule/NetworkPolicyEgressRule contiene una lista de puertos y una lista de NetworkPolicyPeers.
Un NetworkPolicyPeer tiene cuatro formas para que las reglas se refieran a entidades en red: ipBlock, namespaceSelector,podSelector, y una combinación.
ipBlock es útil para permitir el tráfico hacia y desde sistemas externos. Sólo puede utilizarse por sí solo en una regla, sin un namespaceSelector o podSelector. ipBlock contiene un CIDR y un except CIDR opcional. El exceptCIDR excluirá un sub-CIDR (debe estar dentro del rango CIDR). En el Ejemplo 4-8, permitimos el tráfico desde todas las direcciones IP del rango 10.0.0.0 a 10.0.0.255, excluyendo 10.0.0.10. El Ejemplo 4-9 permite el tráfico desde todos los pods de cualquier espacio de nombres etiquetado group:x.
Ejemplo 4-8. Permitir tráfico ejemplo 1
from:-ipBlock:-cidr:"10.0.0.0/24"-except:"10.0.0.10"
Ejemplo 4-9. Permitir tráfico ejemplo 2
#from:-namespaceSelector:-matchLabels:group:x
En el Ejemplo 4-10, permitimos el tráfico de todos los pods de cualquier espacio de nombre etiquetado service: x.. podSelector se comporta como el campospec.podSelector que hemos comentado antes.Si no hay namespaceSelector, selecciona los pods del mismo espacio de nombre que elNetworkPolicy.
Ejemplo 4-10. Permitir tráfico ejemplo 3
from:-podSelector:-matchLabels:service:y
Si especificamos en un namespaceSelector y un podSelector, la regla selecciona todos los pods con la etiqueta pod especificada en todos los espacios de nombres con la etiqueta namespace especificada. Es habitual y muy recomendado por los expertos en seguridad mantener pequeño el ámbito de un espacio de nombres; los ámbitos típicos de los espacios de nombres son por un grupo o equipo de aplicaciones o servicios. Hay una cuarta opción que se muestra en el Ejemplo 4-11 con un selector de espacio de nombres y pod. Este selector se comporta como una condición AND para el selector de espacio de nombres y pod: los pods deben tener la etiqueta coincidente y estar en un espacio de nombres con la etiqueta coincidente.
Ejemplo 4-11. Permitir tráfico ejemplo 4
from:-namespaceSelector:-matchLabels:group:monitoringpodSelector:-matchLabels:service:logscraper
Ten en cuenta que se trata de un tipo distinto de en la API, aunque la sintaxis YAML es muy similar. Como las secciones to y frompueden tener múltiples selectores, un solo carácter puede marcar la diferencia entre un AND y un OR, así que ten cuidado al escribir políticas.
Nuestra anterior advertencia de seguridad sobre el acceso a la API también se aplica aquí. Si un usuario puede personalizar las etiquetas de su espacio de nombres, puede hacer que un NetworkPolicy de otro espacio de nombres se aplique a su espacio de nombres de un modo no previsto. En nuestro ejemplo anterior del selector, si un usuario puede establecer la etiqueta group: monitoring en un espacio de nombres arbitrario, puede potencialmente enviar o recibir tráfico que no se supone que deba recibir. Si el NetworkPolicy en cuestión sólo tiene un selector de espacio de nombres, entonces esa etiqueta de espacio de nombres es suficiente para ajustarse a la política. Si también hay una etiqueta de pod en el selector NetworkPolicy, el usuario tendrá que configurar las etiquetas de pod para que coincidan con la selección de la política. Sin embargo, en una configuración típica, los propietarios del servicio concederán permisos para crear/actualizar pods en el espacio de nombres de ese servicio (directamente en el recurso pod o indirectamente a través de un recurso como una implementación, que puede definir pods).
Un típico NetworkPolicy podría tener este aspecto:
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:store-apinamespace:storespec:podSelector:matchLabels:{}policyTypes:-Ingress-Egressingress:-from:-namespaceSelector:matchLabels:app:frontendpodSelector:matchLabels:app:frontendports:-protocol:TCPport:8080egress:-to:-namespaceSelector:matchLabels:app:downstream-1podSelector:matchLabels:app:downstream-1-namespaceSelector:matchLabels:app:downstream-2podSelector:matchLabels:app:downstream-2ports:-protocol:TCPport:8080
En este ejemplo, todos los pods de nuestro espacio de nombres store sólo pueden recibir conexiones de pods etiquetados como app: frontenden un espacio de nombres etiquetado como app: frontend. Esos pods sólo pueden crear conexiones con pods de espacios de nombres en los que tanto el pod como el espacio de nombres tengan app: downstream-1 o app: downstream-2. En cada uno de estos casos, sólo se permite el tráfico al puerto 8080. Por último, recuerda que esta política no garantiza una política coincidente para downstream-1 odownstream-2 (ver el siguiente ejemplo). Aceptar estas conexiones no excluye otras políticas contra pods en nuestro espacio de nombres, añadiendo excepciones adicionales:
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:store-to-downstream-1namespace:downstream-1spec:podSelector:app:downstream-1policyTypes:-Ingressingress:-from:-namespaceSelector:matchLabels:app:storeports:-protocol:TCPport:8080
Aunque son un recurso "estable" (es decir, forman parte de la API de redes/v1), creemos que los objetos NetworkPolicy son todavía una versión temprana de la seguridad de redes en Kubernetes. La experiencia del usuario al configurar los objetos NetworkPolicy es algo tosca, y el comportamiento abierto por defecto es muy poco deseable. Actualmente existe un grupo de trabajo para debatir el futuro de NetworkPolicy y lo que contendría una API v2.
Las CNI y quienes las implementan utilizan etiquetas y selectores para determinar qué pods están sujetos a restricciones de red. Como hemos visto en muchos de los ejemplos anteriores, son una parte esencial de la API de Kubernetes, y tanto los desarrolladores como los administradores deben conocer a fondo cómo utilizarlos.
NetworkPolicy son una herramienta importante de en la caja de herramientas del administrador del clúster. Son la única herramienta disponible para controlar el tráfico interno del clúster, nativa de la API de Kubernetes. Hablamos de las mallas de servicios, que añadirán más herramientas para que los administradores aseguren y controlen las cargas de trabajo, en "Mallas de servicios".
A continuación, hablaremos de otra herramienta importante para que los administradores entiendan cómo funciona dentro del clúster: el Sistema de Nombres de Dominio (DNS).
DNS
DNS es una pieza crítica de la infraestructura de cualquier red. En Kubernetes, esto no es diferente, por lo que se justifica una breve visión general. En las siguientes secciones de "Servicios", veremos hasta qué punto dependen del DNS y por qué una distribución Kubernetes no puede declarar que es una distribución Kubernetes conforme sin proporcionar un servicio DNS que siga la especificación. Pero antes, repasemos cómo funciona el DNS dentro deKubernetes.
Nota
No esbozaremos toda la especificación en este libro. Si los lectores están interesados en leer más sobre ella, está disponible en GitHub.
KubeDNS se utilizaba en en versiones anteriores de Kubernetes. KubeDNS tenía varios contenedores dentro de un mismo pod:kube-dns, dnsmasq, y sidecar. El contenedor kube-dns vigila la API de Kubernetes y sirve registros DNS basados en la especificación DNS de Kubernetes, dnsmasq proporciona caché y soporte de dominios stub, y sidecar proporciona métricas y comprobaciones de estado. Las versiones de Kubernetes posteriores a la 1.13 utilizan ahora el componente independiente CoreDNS.
Hay varias diferencias entre CoreDNS y KubeDNS:
-
Para simplificar, CoreDNS se ejecuta como un único contenedor.
-
CoreDNS es un proceso Go que replica y mejora la funcionalidad deKube-DNS.
-
CoreDNS está diseñado para ser un servidor DNS de uso general compatible con Kubernetes, y sus complementos ampliables pueden hacer más de lo que se proporciona en la especificación DNS de Kubernetes.
La Figura 4-10 muestra los componentes de CoreDNS. Ejecuta una implementación con una réplica por defecto de 2, y para que se ejecute, CoreDNS necesita acceso al servidor API, un ConfigMap para contener su Corefile, un servicio para poner DNS a disposición del clúster, y una implementación para lanzar y gestionar sus pods. Todo esto también se ejecuta en el espacio de nombres kube-system junto con otros componentes críticos del clúster.
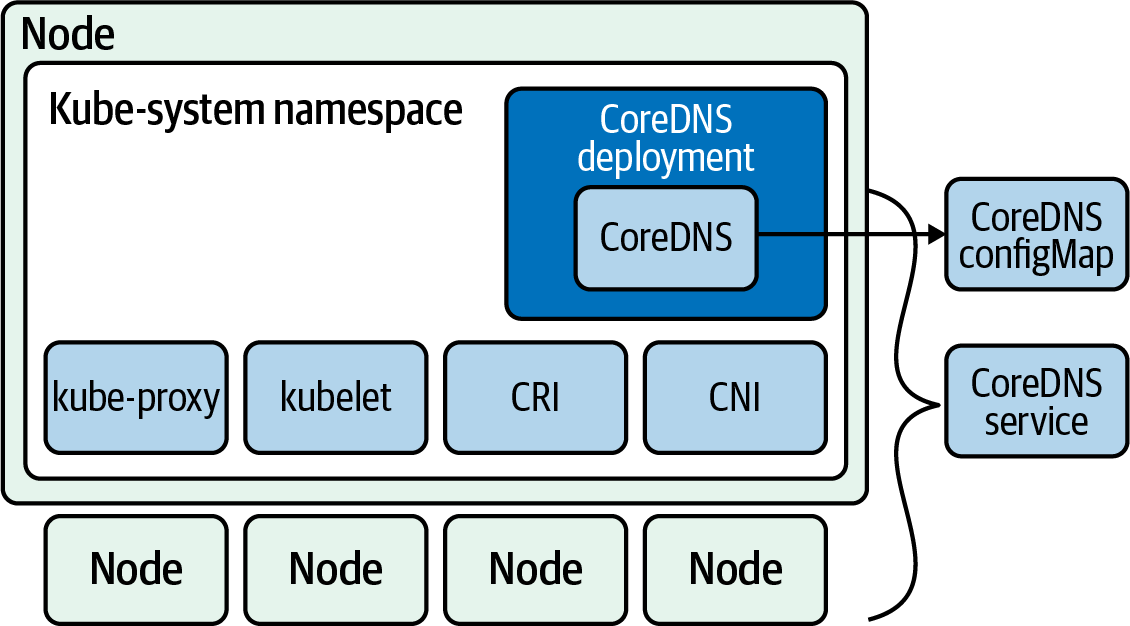
Figura 4-10. Componentes de CoreDNS
Como la mayoría de las opciones de configuración, la forma en que el pod realiza las consultas DNS se encuentra en la especificación del pod, en el atributo dnsPolicy.
Esbozado en el Ejemplo 4-12, la vaina spec tiene ClusterFirstWithHostNet comodnsPolicy.
Ejemplo 4-12. Especificación Pod con configuración DNS
apiVersion:v1kind:Podmetadata:name:busyboxnamespace:defaultspec:containers:-image:busybox:1.28command:-sleep-"3600"imagePullPolicy:IfNotPresentname:busyboxrestartPolicy:AlwayshostNetwork:truednsPolicy:ClusterFirstWithHostNet
Hay cuatro opciones para dnsPolicy que afectan significativamente a cómo funcionan las resoluciones DNS dentro de un pod:
Default-
El pod hereda la configuración de resolución de nombres del nodo en el que se ejecutan los pods.
ClusterFirst-
Cualquier consulta DNS que no coincida con el sufijo del dominio del clúster, como www.kubernetes.io, se envía al servidor de nombres ascendente heredado del nodo.
ClusterFirstWithHostNet-
Para los pods que se ejecutan con
hostNetwork, los administradores deben establecer la política DNS enClusterFirstWithHostNet. None-
Todos los ajustes DNS utilizan el campo
dnsConfigde la especificación del pod.
Si none, los desarrolladores tendrán que especificar los servidores de nombres en la especificación del pod. nameservers: es una lista de direcciones IP que el pod utilizará como servidores DNS. Puede haber un máximo de tres direcciones IP especificadas. searches: es una lista de dominios de búsqueda DNS para la búsqueda de nombres de host en el pod. Kubernetes permite un máximo de seis dominios de búsqueda. A continuación se muestra un ejemplo de especificación:
apiVersion:v1kind:Podmetadata:namespace:defaultname:busyboxspec:containers:-image:busybox:1.28command:-sleep-"3600"imagePullPolicy:IfNotPresentname:busyboxdnsPolicy:"None"dnsConfig:nameservers:-1.1.1.1searches:-ns1.svc.cluster-domain.example-my.dns.search.suffix
Otros están en el campo options, que es una lista de objetos en la que cada objeto puede tener una propiedad name y una propiedad value (opcional).
Todas estas propiedades generadas se fusionan con resolv.conf de la política DNS. Las opciones de consulta habituales hacen que CoreDNS recorra la siguiente ruta de búsqueda:
<service>.default.svc.cluster.local
↓
svc.cluster.local
↓
cluster.local
↓
The host search path
La ruta de búsqueda de host proviene de la política DNS del pod o de la política CoreDNS .
Consultar un registro DNS en Kubernetes puede dar lugar a muchas solicitudes y aumentar la latencia de las aplicaciones que esperan a que se respondan las solicitudes DNS. CoreDNS tiene una solución para esto llamada Autopath. Autopath permite completar la ruta de búsqueda en el lado del servidor. Acorta la resolución de la ruta de búsqueda del cliente eliminando el dominio de búsqueda del clúster y realizando las búsquedas en el servidor CoreDNS; cuando encuentra una respuesta, almacena el resultado como un CNAME y vuelve con una consulta en lugar de cinco.
Sin embargo, utilizar Autopath aumenta el uso de memoria en CoreDNS. Asegúrate de escalar la memoria de la réplica CoreDNS con el tamaño del cluster. Asegúrate de establecer adecuadamente las peticiones de memoria y CPU para los pods CoreDNS. Para monitorizar CoreDNS, exporta varias métricas que expone, enumeradas aquí:
- coredns build info
-
Información sobre el propio CoreDNS
- recuento total de peticiones dns
-
Recuento total de consultas
- duración de la solicitud dns segundos
-
Duración del procesamiento de cada consulta
- tamaño solicitud dns bytes
-
El tamaño de la petición en bytes
- plugin coredns activado
-
Indica si un plugin está activado por servidor y zona
Combinando las métricas del pod junto con las métricas de CoreDNS, los administradores del plugin se asegurarán de que CoreDNS se mantiene sano y funcionando dentro de tu clúster.
Consejo
Esto es sólo un breve resumen de las métricas disponibles. La lista completa está disponible.
Autopath y otras métricas se activan mediante plugins. Esto permite a CoreDNS centrarse en su única tarea, el DNS, pero seguir siendo extensible a través del marco de plugins, de forma muy similar al patrón CNI . En la Tabla 4-5, vemos una lista de los plugins disponibles actualmente. Al ser un proyecto de código abierto , cualquiera puede contribuir con un plugin. Hay varios específicos de la nube, como router53, que permite servir datos de zona desde el servicio route53 de AWS.
| Nombre | Descripción |
|---|---|
auto |
Permite servir datos de zona desde un archivo maestro estilo RFC 1035, que se recoge automáticamente del disco. |
autópata |
Permite completar la ruta de búsqueda en el servidor. autopath [ZONA...] RESOLV-CONF. |
enlaza |
Anula el host al que debe vincularse el servidor. |
caché |
Activa una caché de frontend. caché [TTL] [ZONAS...]. |
caos |
Permite responder a consultas TXT en la clase CH. |
depurar |
Desactiva la recuperación automática en caso de fallo para que obtengas un buen seguimiento de la pila. text2pcap. |
dnssec |
Permite la firma DNSSEC sobre la marcha de los datos servidos. |
dnstap |
Activa el registro en dnstap. http://dnstap.info golang: go get -u -v github.com/dnstap/golang-dnstap/dnstap. |
errático |
Un complemento útil para comprobar el comportamiento de los clientes. |
errores |
Activa el registro de errores. |
etcd |
Permite leer datos de zona de una instancia etcd versión 3. |
federación |
Permite que las consultas federadas se resuelvan a través del plugin de Kubernetes. |
archivo |
Permite servir datos de zona desde un archivo maestro estilo RFC 1035. |
adelante |
Facilita el envío de mensajes DNS a los resolutores ascendentes. |
salud |
Activa un punto final de comprobación de salud. |
alberga |
Permite servir datos de zona desde un archivo del estilo de /etc/hosts. |
Kubernetes |
Activa la lectura de datos de zona de un clúster Kubernetes. |
equilibrador de carga |
Aleatoriza el orden de los registros A, AAAA y MX. |
activa el registro |
Consulta el registro en la salida estándar. |
detectar bucle |
Los bucles de reenvío simples y detienen el servidor. |
metadatos |
Activa un recopilador de metadatos. |
métricas |
Activa las métricas de Prometheus. |
nsid |
Añade un identificador de este servidor a cada respuesta. RFC 5001. |
pprof |
Publica datos de perfilado en tiempo de ejecución en puntos finales bajo /debug/pprof. |
proxy |
Facilita tanto un proxy inverso básico como un equilibrador de carga robusto. |
recarga |
Permite la recarga automática de un Corefile modificado. Recarga automática. |
reescribe |
Realiza la reescritura interna de mensajes. rewrite name foo.example.com foo.default.svc.cluster.local. |
raíz |
Simplemente especifica la raíz de dónde encontrar los archivos de zona. |
router53 |
Permite servir datos de zona desde AWS route53. |
secundario |
Permite servir una zona recuperada de un servidor primario. |
plantilla |
Respuestas dinámicas basadas en la consulta entrante. |
tls |
Configura los certificados de servidor para los servidores TLS y gRPC. |
rastrea |
Activa el rastreo de peticiones DNS basado en OpenTracing. |
whoami |
Devuelve la dirección IP local del resolver, el puerto y el transporte. |
Nota
Hay disponible una lista completa de plugins CoreDNS.
CoreDNS es excepcionalmente configurable y compatible con el modelo Kubernetes. Sólo hemos arañado la superficie de lo que CoreDNS es capaz; si quieres saber más sobre CoreDNS, te recomendamos encarecidamente leer Learning CoreDNS de John Belamaric Cricket Liu (O'Reilly).
CoreDNS permite a los pods averiguar las direcciones IP que deben utilizar para llegar a aplicaciones y servidores internos y externos al clúster. En nuestra próxima sección, trataremos más a fondo cómo se gestionan IPv4 y 6 en un clúster.
Doble pila IPv4/IPv6
Kubernetes tiene soporte aún en desarrollo para ejecutarse en modo "dual-stack" IPv4/IPv6, que permite a un clúster utilizar tanto direcciones IPv4 como IPv6. Kubernetes dispone de soporte estable para ejecutar clústeres en modo sólo IPv6; sin embargo, la ejecución en modo sólo IPv6 supone una barrera para la comunicación con clientes y hosts que sólo admiten IPv4. El modo dual-stack es un puente crítico para permitir la adopción de IPv6. Intentaremos describir el estado actual de la red dual-stack en Kubernetes a partir de Kubernetes 1.20, pero ten en cuenta que puede cambiar sustancialmente en versiones posteriores. La propuesta de mejora completa de Kubernetes (KEP) para la compatibilidad con doble pila está en GitHub.
Advertencia
En Kubernetes, una función de es "alfa" si el diseño no está finalizado, si la escalabilidad/cobertura de pruebas/fiabilidad es insuficiente, o si simplemente aún no se ha probado lo suficiente en el mundo real. Las Propuestas de Mejora de Kubernetes (KEP) establecen el listón para que una función individual pase a beta y luego sea estable. Como todas las funciones alfa, Kubernetes desactiva por defecto el soporte de doble pila, y la función debe activarse explícitamente.
Las funciones IPv4/IPv6 habilitan las siguientes funciones para la conexión en red de los pods:
-
Una única dirección IPv4 e IPv6 por pod
-
Servicios IPv4 e IPv6
-
Enrutamiento de salida del clúster pod a través de interfaces IPv4 e IPv6
Al ser una función alfa, los administradores deben habilitar IPv4/IPv6 dual-stack; para ello, la puerta de función IPv6DualStack para los componentes de red debe estar configurada para tu clúster. Aquí tienes una lista de esas opciones de red de clúster dual-stack:
kube-apiserver-
-
feature-gates="IPv6DualStack=true" -
service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>
-
kube-controller-manager-
-
feature-gates="IPv6DualStack=true" -
cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR> -
service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR> -
node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6por defecto /24 para IPv4 y /64 para IPv6
-
kubelet-
-
feature-gates="IPv6DualStack=true"
-
kube-proxy-
-
cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR> -
feature-gates="IPv6DualStack=true"
-
Cuando IPv4/IPv6 está activado en un clúster, los servicios de tienen ahora un campo adicional en el que los desarrolladores pueden elegir laipFamilyPolicy a implementar para su aplicación:
SingleStack-
Servicio de pila única. El plano de control asigna una IP de clúster para el servicio, utilizando el primer rango de IP de clúster de servicio configurado.
PreferDualStack-
Sólo se utiliza si el cluster tiene activada la pila dual. Esta configuración utilizará el mismo comportamiento que
SingleStack. RequireDualStack-
Asigna las direcciones IP del cluster de servicios a partir de rangos de direcciones IPv4 e IPv6.
ipFamilies-
Una matriz que define qué familia IP utilizar para una pila única o define el orden de las familias IP para la pila dual; puedes elegir las familias de direcciones configurando este campo en el servicio. Los valores permitidos son
["IPv4"],["IPv6"], y["IPv4","IPv6"](pila dual).
Nota
A partir de la 1.21, la doble pila IPv4/IPv6 está activada por defecto.
Aquí tienes un manifiesto de servicio de ejemplo que tiene PreferDualStack establecido en PreferDualStack:
apiVersion:v1kind:Servicemetadata:name:my-servicelabels:app:MyAppspec:ipFamilyPolicy:PreferDualStackselector:app:MyAppports:-protocol:TCPport:80
Conclusión
El modelo de red de Kubernetes es la base de cómo se diseña el funcionamiento de la red dentro de un clúster. El CNI que se ejecuta en los nodos implementa los principios establecidos en el modelo de red de Kubernetes. El modelo no define la seguridad de la red; la extensibilidad de Kubernetes permite al CNI implementar la seguridad de la red mediante políticas de red.
CNI, DNS y la seguridad de la red son partes esenciales de la red del clúster; tienden un puente entre las redes Linux, tratadas en el Capítulo 2, y las redes de contenedores y Kubernetes, tratadas en los Capítulos 3 y 5, respectivamente.
Elegir el CNI adecuado requiere una evaluación tanto desde el punto de vista de los desarrolladores como de los administradores. Hay que establecer los requisitos y probar los CNI. En nuestra opinión, un cluster no está completo sin un debate sobre la seguridad de la red y la CNI que la soporta.
DNS es esencial; una configuración completa y una red que funcione sin problemas requieren que los administradores de red y de clústeres sean expertos en escalar CoreDNS en sus clústeres. Un número excepcional de problemas de Kubernetes se derivan del DNS y de la mala configuración de CoreDNS.
La información de este capítulo será importante cuando hablemos de las redes en la nube en el capítulo 6 y de las opciones que tienen los administradores al diseñar e implementar sus redes de clústeres de producción.
En nuestro próximo capítulo, nos sumergiremos en cómo Kubernetes utiliza todo esto para potenciar sus abstracciones.
Get Redes y Kubernetes now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

