Capítulo 4. Tomar decisiones de autorización
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Podría decirse que la autorización es el proceso más importante que tiene lugar en una red de confianza cero, y como tal, tomar una decisión de autorización no debe tomarse a la ligera. Cada flujo y/o solicitud requerirá, en última instancia, que se tome una decisión.
Las bases de datos y los sistemas de apoyo de los que hablaremos aquí son los sistemas clave que se unen para tomar y afectar a esas decisiones. Juntos, tienen autoridad para el control de acceso y, por tanto, deben estar rigurosamente aislados unos de otros. Hay que distinguir cuidadosamente entre estas responsabilidades, sobre todo a la hora de decidir si colapsarlas en un único sistema, lo que en general debe evitarse si es posible.
Teniendo en cuenta la realidad, este capítulo se centrará en la disposición arquitectónica de alto nivel de los componentes necesarios para tomar decisiones de autorización de confianza cero, así como en la forma en que encajan entre sí y aplican dichas decisiones.
Arquitectura de autorización
La arquitectura de autorización de confianza cero de consta de cuatro componentes principales, como se muestra en la Figura 4-1:
Ejecución
Motor político
Motor de confianza
Almacenes de datos
Estos cuatro componentes son distintos en sus responsabilidades y, por ello, los tratamos como sistemas separados. Desde el punto de vista de la seguridad, es muy conveniente que estos componentes estén aislados entre sí. Estos sistemas representan en la práctica las joyas de la corona del modelo de seguridad de confianza cero, por lo que debe prestarse especial atención a su mantenimiento y postura de seguridad. Desde el punto de vista de la implementación, es fundamental que exista aislamiento entre estos componentes, de modo que el fallo de uno de ellos no provoque automáticamente el fallo de todo el sistema, tanto desde el punto de vista de la seguridad como de la disponibilidad. De esto se encargan normalmente los sistemas basados en la nube, donde los servicios basados en SaaS permiten el aislamiento en función de diversos factores, mientras que los servicios siguen estando disponibles bajo el paraguas de un único proveedor. Otro patrón común es el uso de microservicios, en los que varios servicios se distribuyen entre proveedores y se exponen a través de API bien definidas. Dado que los sistemas de software suelen estar muy distribuidos hoy en día, la planificación del aislamiento debe priorizarse desde el principio.
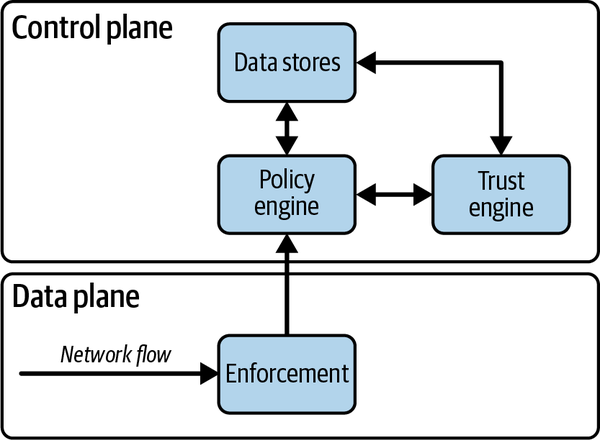
Figura 4-1. Sistema de autorización de confianza cero
La aplicación es el componente que realmente afecta al resultado de la decisión de autorización. Suele manifestarse como un equilibrador de carga, un proxy o incluso un cortafuegos. Este componente interactúa con el motor de políticas, que es la pieza que utilizamos para tomar la decisión real. El componente de aplicación se asegura de que los clientes estén autentificados, y pasa el contexto de cada flujo/solicitud al motor de políticas. El motor de políticas compara la solicitud y su contexto con la política, e informa al ejecutor de si la solicitud se permitirá o no. Los componentes de aplicación deben existir en gran número en todo el sistema y deben estar lo más cerca posible de la carga de trabajo.
Un motor de confianza aprovecha múltiples fuentes de datos para calcular una puntuación de riesgo, similar a una puntuación crediticia. Esta puntuación puede utilizarse para proteger contra desconocidos, y ayuda a mantener una política sólida y robusta sin complicarla con casos de perímetro y firmas. El motor de la política la utiliza como un componente adicional mediante el cual se pueden tomar decisiones de autorización. BeyondCorp de Google es ampliamente reconocida como pionera en esta tecnología. El motor de confianza es aprovechado por el motor de políticas con fines de análisis de riesgos.
Por último, los distintos almacenes de datos representan la fuente de verdad de los datos que se utilizan para informar sobre la autorización. Estos datos se utilizan para dibujar una imagen contextual completa de un flujo/solicitud concreto, utilizando pequeños fragmentos de datos autenticados como claves de búsqueda principales (es decir, un nombre de usuario o el número de serie de un dispositivo). Estos almacenes de datos, ya sean datos de usuario, de dispositivo o de otro tipo, son muy aprovechados tanto por el motor de políticas como por el motor de confianza, y representan el respaldo con el que se miden todas las decisiones.
Ejecución
El componente de aplicación (representado en la Figura 4-2) es un lugar natural para empezar. Se encuentra en la "primera línea" del flujo de autorización y es responsable de ejecutar las decisiones tomadas por el resto del sistema de autorización.
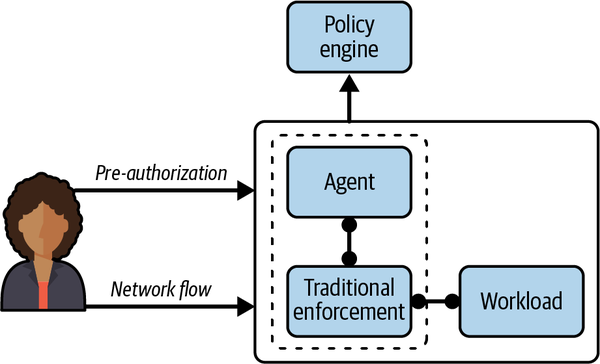
Figura 4-2. Un agente recibe una señal de autorización previa para conceder el acceso a un sistema que utiliza mecanismos de aplicación tradicionales. Estos sistemas juntos forman el componente de aplicación.
La aplicación puede desglosarse en dos responsabilidades principales. En primer lugar, debe producirse una interacción con el motor de políticas. Por lo general, se trata de la propia solicitud de autorización (por ejemplo, un equilibrador de carga ha recibido una solicitud y necesita saber si está autorizada o no). La segunda es la instalación real y la aplicación continua de la decisión. Aunque estas dos responsabilidades representan un único componente en la arquitectura de autorización de confianza cero, puedes elegir si se cumplen juntas o por separado.
La forma que elijas para gestionar esto dependerá probablemente de tu caso de uso. Por ejemplo, un proxy consciente de la identidad puede llamar al motor de políticas para autorizar activamente una solicitud que ha recibido, y en el mismo paso utilizar la respuesta para atender o rechazar la solicitud. Éste es un ejemplo de tratamiento unificado de las preocupaciones. Otra posibilidad es que un demonio de preautorización reciba una solicitud de acceso a un servicio concreto y llame al motor de políticas para que lo autorice. Una vez obtenida la autorización, el demonio puede manipular las reglas del cortafuegos local para permitir la solicitud concreta. Con este enfoque, nos basamos en mecanismos de aplicación "estándar" que son informados/programados por el plano de control de confianza cero. Sin embargo, hay que tener en cuenta que este enfoque requiere un gancho del lado del cliente para notificar al plano de control la solicitud de autorización. Esto puede ser aceptable o no, dependiendo del nivel de control que necesites sobre tus dispositivos y aplicaciones.
La colocación del componente de aplicación es muy importante. Puesto que representa nuestro punto de control dentro del plano de datos, debemos asegurarnos de que los componentes de aplicación se colocan lo más cerca posible de los puntos finales. De lo contrario, la confianza puede acumularse "detrás" del componente de aplicación, socavando la seguridad de confianza cero. Por suerte, el componente de aplicación puede modelarse como una especie de cliente y aplicarse libremente en todo el sistema. Esto contrasta con el resto de componentes de autorización, que se modelan como servicios.
Motor de Política
El motor de la política es el componente que tiene el poder de tomar una decisión. Compara la solicitud procedente del componente de aplicación con la política para determinar si la solicitud está autorizada o no. Una vez determinado, el resultado se devuelve a la pieza de aplicación para su realización efectiva.
La disposición de la capa de aplicación y el motor de políticas permite tomar decisiones dinámicas y puntuales, permitiendo que la revocación se produzca rápidamente. Por ello, es importante que estos componentes se consideren por separado e independientemente. Esto no quiere decir, sin embargo, que no puedan estar ubicados conjuntamente.
Dependiendo de una serie de factores, un motor de políticas puede encontrarse alojado codo con codo con el mecanismo de aplicación. Un ejemplo de ello podría ser un equilibrador de carga que autorice las solicitudes mediante comunicación entre procesos (IPC) en lugar de una llamada remota. La ventaja más atractiva de esta arquitectura es la menor latencia para autorizar la solicitud. Un sistema de autorización de baja latencia permite una autorización detallada y exhaustiva de la actividad de la red; por ejemplo, se podrían autorizar solicitudes HTTP individuales en lugar de la autorización a nivel de sesión que se suele implementar. Hay que tener en cuenta que lo mejor es mantener el aislamiento a nivel de proceso entre el motor de políticas y la capa de aplicación. La capa de aplicación, al estar en la ruta de datos del usuario, está más expuesta; por tanto, integrar el motor de políticas en el mismo proceso podría exponerlo a riesgos no deseados. La implementación del motor de políticas como proceso propio contribuye en gran medida a garantizar que los fallos en la capa de aplicación no comprometan el motor de políticas.
Política de almacenamiento
Es necesario almacenar las reglas a las que hace referencia el motor de políticas. Estas reglas políticas se cargan en última instancia en el motor de políticas, pero se recomienda encarecidamente que las reglas se capturen fuera del propio motor de políticas. Almacenar las reglas políticas en un sistema de control de versiones es lo ideal y proporciona varias ventajas:
Los cambios en la política pueden seguirse a lo largo del tiempo.
Los motivos para cambiar de política se registran en el sistema de control de versiones.
El estado actual previsto de la política puede validarse con los mecanismos de aplicación reales.
Muchas de estas ventajas se han aplicado históricamente mediante rigurosos procedimientos de gestión de cambios. En ese sistema, los cambios en la configuración del sistema se solicitan y aprueban antes de aplicarse en última instancia. El registro de gestión de cambios resultante puede utilizarse para determinar por qué el sistema se encuentra en el estado actual.
Trasladar las definiciones de política al control de versiones es la conclusión lógica de los procedimientos de gestión de cambios cuando el sistema puede configurarse mediante programación. En lugar de confiar en los administradores humanos del sistema para cargar la política deseada en el sistema, podemos capturar la política como datos que un programa puede leer y aplicar. En muchos sentidos, cargar la política es entonces similar a la implementación de software. Como resultado, los administradores del sistema pueden utilizar procedimientos estándar de desarrollo de software (a saber, revisión de código y conductos de promoción) para gestionar los cambios en la política.
¿Qué es una buena política?
La política en una red de confianza cero es en algunos aspectos similar a la seguridad de red tradicional, y en otros sustancialmente diferente.
La Política de Confianza Cero aún no está normalizada
La realidad actual es que la política de confianza cero aún no está estandarizada del mismo modo que una política orientada a la red. Por ello, definir el lenguaje estándar de las políticas utilizadas en una red de confianza cero es una gran oportunidad.
Veamos primero lo que es similar. Una buena política en una red de confianza cero es de grano fino. El nivel de granularidad variará en función de la madurez de la red, pero el objetivo deseado es una política que se ajuste al recurso individual que se está protegiendo. Esto no difiere mucho de un modelo de seguridad de red tradicional que pretende segmentar la red para disminuir la superficie de ataque.
El modelo de confianza cero empieza a divergir de la seguridad de red tradicional en los mecanismos de control que se utilizan para definir la política. En lugar de definir la política en términos de detalles de implementación de la red (como direcciones IP y rangos), la política se define mejor en términos de componentes lógicos de la red. Estos componentes consistirán generalmente en:
Servicios de red
Clases de punto final del dispositivo
Funciones de los usuarios
Definir la política a partir de componentes lógicos que existen en la red permite al motor de la política calcular las decisiones de aplicación basándose en su conocimiento del estado actual de la red. Para ponerlo en términos concretos, un servicio web que se ejecuta hoy en un servidor puede estar mañana en otro distinto, o incluso puede moverse entre servidores automáticamente según lo indique un programador de cargas de trabajo. La política que definamos debe estar separada de estos detalles de implementación para adaptarse a esta realidad. En la Figura 4-3 se muestra un ejemplo de este estilo de política del proyecto Kubernetes.

Figura 4-3. Fragmento de una política de red de Kubernetes. Estas políticas utilizan etiquetas de carga de trabajo, computando las reglas de aplicación subyacentes basadas en IP cuando y donde sea necesario.
Aunque no existe un único método o norma para definir las políticas, suelen configurarse en formato JSON o YAML y son fáciles de entender semánticamente. Considera la política personalizada de Google para la nube a nivel de acceso, que define condiciones para dispositivos conocidos, como los de propiedad corporativa y aprobados por el administrador que ejecutan un sistema operativo conocido:
{
"name": "example_custom_level",
"title": "Example custom level",
"description": "An example custom access level.",
"custom": {
"expr": {
"expression": "device.is_corp_owned == true || (device.os_type != OsType.OS_UNSPECIFIED && device.is_admin_approved_device == true)",
"title": "Check for known devices",
"description": "Permits requests from corp-owned devices and admin-approved devices with a known OS."
}
}
}
La política en una red de confianza cero también se apoya en las puntuaciones de confianza para anticiparse a vectores de ataque desconocidos. Al definir la política con un componente de puntuación de confianza, los administradores pueden mitigar el riesgo que, de otro modo, no podría capturarse con una política específica. Por tanto, la mayoría de las políticas deberían incluir un componente de puntuación de confianza. Mira el siguiente ejemplo de una política de acceso condicional en la nube Azure de Microsoft que exige a cualquier usuario con una puntuación de riesgo "media" o "alta" que realice una autenticación multifactor obligatoria al iniciar sesión en una aplicación de RRHH. La puntuación de confianza se trata en detalle más adelante en este capítulo:
{
"displayName": "Require MFA For High/Medium Sign-in Risk",
"state": "enabled",
"conditions": {
"signInRiskLevels": ["high", "medium"],
"clientAppTypes": [
"all"
],
"users": {
"includeUsers": ["*"]
}
},
"grantControls": {
"operator": "OR",
"builtInControls": [
"mfa"
]
}
}
Falta de normas políticas
En el momento de escribir estas líneas, no existe una norma sectorial para definir las políticas; sin embargo, organizaciones como el Centro Nacional de Excelencia en Ciberseguridad (NCCoE) están realizando esfuerzos en este sentido. Éste ha creado una descripción disponible públicamente de los pasos prácticos necesarios para implantar los diseños de referencia de ciberseguridad para la confianza cero, así como diversos componentes de la confianza cero, incluidas las políticas. Puedes obtener más información visitando el sitio web del NCCoE.
La política no debe basarse únicamente en puntuaciones de confianza. Las características específicas de la solicitud que se autoriza también pueden formar parte de la definición de la política. Un ejemplo podría ser que determinados roles de usuario sólo tuvieran acceso a un servicio concreto.
¿Quién define la política?
La política de red de confianza cero debe ser de grano fino, lo que puede suponer una carga extraordinaria para los administradores del sistema a la hora de mantener la política actualizada. Para ayudar a repartir la carga de esta carga de configuración, la mayoría de las organizaciones deciden distribuir la definición de políticas entre los equipos para que puedan ayudar a mantener la política de los servicios que les pertenecen. Abrir la definición de políticas a toda una organización puede presentar ciertos riesgos, como usuarios bienintencionados que crean políticas demasiado amplias, aumentando así la superficie de ataque del sistema que pretendían restringir. Los sistemas de confianza cero se apoyan en dos flujos de trabajo organizativos para contrarrestar esta exposición.
Revisiones políticas
En primer lugar, dado que la política suele almacenarse bajo control de versiones, tener a otra persona que revise los cambios en la política ayuda a garantizar que los cambios están bien considerados. Además, los equipos de seguridad pueden revisar los cambios y hacer preguntas de sondeo para asegurarse de que la política que se está definiendo tiene el alcance más estricto posible. Como la política se define utilizando la intención lógica en lugar de componentes físicos, la política cambiará menos rápidamente que si se definiera en términos físicos.
La segunda medida organizativa utilizada consiste en superponer una política de infraestructura amplia a una política de grano fino. Por ejemplo, un grupo de infraestructura puede exigir, con razón, que sólo un determinado conjunto de funciones pueda aceptar tráfico de Internet. Por tanto, el equipo de infraestructura definirá una política que haga cumplir esa restricción, y no se permitirá que ninguna política definida por el usuario la eluda. La aplicación de esta restricción puede adoptar varias formas: una prueba automatizada de la política propuesta, o tal vez un motor de políticas que simplemente rechace afirmaciones de políticas demasiado amplias procedentes de fuentes no fiables. Esta aplicación también puede ser útil para el cumplimiento de la normativa.
Aunque no existe un proceso estándar de confianza cero para definir la política, el Método Kipling proporciona una buena pauta para definir políticas de confianza cero. Este método ayuda a explicar sucintamente el Quién, Qué, Cuándo, Dónde, Por qué y Cómo de la política de acceso a los recursos:
¿Aquién se debe permitir acceder a un recurso? Se trata esencialmente de la identidad (que puede ser humana o de máquina) a la que se permite iniciar el flujo.
¿Qué aplicación/API/servicio puede acceder al recurso?
¿Cuándo se permite a la identidad acceder al recurso? Esto se refiere principalmente a los horarios, como las horas de oficina, etc.
¿Dónde se encuentra el recurso? Puede estar en cualquier parte, incluida la nube, centros de datos locales, etc.
¿Por qué se permite el acceso de la identidad al recurso? Ésta es la justificación o razón principal del acceso y es crucial a efectos de cumplimiento y regulación.
¿Cómo debe procesarse el tráfico cuando accede a un recurso?
Motor de confianza
El motor de confianza es el sistema de una red de confianza cero que realiza el análisis de riesgos de una solicitud o acción concreta. La responsabilidad de este sistema es producir una evaluación numérica del riesgo de permitir una solicitud/acción concreta, que el motor de políticas utiliza para tomar una decisión final de autorización.
El motor de confianza recurrirá con frecuencia a datos contenidos en sistemas de inventario autorizados para comprobar los atributos de una entidad al calcular su puntuación. Un inventario de dispositivos, por ejemplo, podría proporcionar al motor de confianza información como la última vez que un dispositivo fue auditado o escaneado para comprobar su cumplimiento, o si tiene una determinada función de seguridad de hardware.
Crear una evaluación numérica del riesgo es una tarea difícil. Un enfoque sencillo sería definir un conjunto de reglas ad hoc que puntúen la peligrosidad de una entidad. Por ejemplo, un dispositivo al que le falten los últimos parches de software podría ver reducida su puntuación. Del mismo modo, se podría reducir la puntuación de confianza de un usuario que no se autentique continuamente. Aunque la puntuación de confianza ad hoc puede ser sencilla para empezar, un conjunto de reglas definidas estáticamente será insuficiente para cumplir el objetivo deseado de defenderse de ataques inesperados. En consecuencia, además de utilizar reglas estáticas, los motores de confianza maduros utilizan técnicas de aprendizaje automático para derivar una función de puntuación.
El aprendizaje automático obtiene una función de puntuación calculando hechos observables a partir de un subconjunto de datos de actividad conocidos como datos de entrenamiento. Los datos de entrenamiento son observaciones en bruto que se han asociado a entidades fiables o no fiables. De estos datos se extraen características que se utilizan para derivar una función de puntuación generada por ordenador. Esta función de puntuación, o modelo en términos de aprendizaje automático, se compara con un conjunto de datos que tienen el mismo formato que los datos de entrenamiento. Las puntuaciones resultantes se comparan con las evaluaciones de riesgo definidas por el ser humano, y la calidad del modelo puede refinarse en función de su capacidad para predecir correctamente el riesgo asociado a los datos analizados. Se puede decir entonces que un modelo que tenga suficiente precisión predice el riesgo de solicitudes aún no vistas en la red.
Los modelos de aprendizaje automático pueden aprender de diversos atributos, como la dirección IP del usuario, la geolocalización, el dispositivo, etc., para evaluar si una solicitud de un usuario es anómala o típica en el contexto actual. Ten en cuenta que los "falsos positivos" pueden producirse en cualquier momento. Esto se debe a que hay situaciones legítimas en las que la actividad del usuario en cuestión es normal, pero la predicción tiende a ser anómala. En la vida real, un ejemplo de falso positivo puede verse cuando un usuario viaja a una nueva ubicación, quizá de vacaciones, y realiza una solicitud de acceso. En este caso, el modelo de aprendizaje automático aún no se ha entrenado con la ubicación de este nuevo usuario, por lo que lo más probable es que lo identifique como un patrón anómalo. Hacer frente a los falsos positivos es un tema candente en el aprendizaje automático, y suele mejorarse ajustando factores como el periodo de aprendizaje, la precisión y el recuerdo, entre otros.
Aunque el aprendizaje automático se utiliza cada vez más para resolver problemas computacionales difíciles, no obvia la necesidad de reglas más explícitas en el motor de confianza. Ya sea por una limitación de los modelos de puntuación derivados o por un deseo de personalización de la función de puntuación, los motores de confianza suelen utilizar una mezcla de métodos de puntuación ad hoc y de aprendizaje automático.
¿Qué entidades se puntúan?
Decidir qué componentes de una red de confianza cero deben puntuarse es una consideración interesante. ¿Deben calcularse las puntuaciones para cada entidad individual (usuario, dispositivo y aplicación), para el agente de red en su conjunto, o para ambos? Veamos algunos escenarios.
Utilizar agentes de red para puntuar
Imagina que las credenciales de un usuario son forzadas por un tercero malintencionado. Algunos sistemas mitigarán esta amenaza bloqueando la cuenta del usuario, lo que puede suponer un ataque de denegación de servicio contra ese usuario concreto. Si puntuáramos negativamente a un usuario basándonos en esa actividad, una red de confianza cero sufriría el mismo problema. Un enfoque mejor es darse cuenta de que estamos autenticando al agente de red, y así se contrarresta al agente de red del atacante, dejando indemne al agente de red del usuario legítimo. Este escenario defiende que el agente de red es la entidad que debe puntuarse.
Utilizar dispositivos para puntuar
Pero limitarse a anotar el agente de red puede ser insuficiente contra otros vectores de ataque. Considera un dispositivo que ha sido asociado con actividad maliciosa. Puede que el agente de red de un usuario en ese dispositivo no muestre signos de comportamiento malicioso, pero el hecho de que el agente se forme con un dispositivo sospechoso debería tener un claro impacto en la puntuación de confianza de todas las solicitudes originadas en ese dispositivo. Este escenario sugiere claramente que el dispositivo debe ser puntuado.
Por último, considera un usuario humano malicioso (la infame amenaza interna) que utiliza varios dispositivos de quiosco para exfiltrar secretos comerciales. Nos gustaría que el motor de confianza reconociera este comportamiento a medida que el usuario salta de un dispositivo a otro y que reflejara el nivel decreciente de confianza en su puntuación de confianza para todas las futuras decisiones de autorización. Una vez más, vemos que la puntuación del agente de red por sí sola es insuficiente para mitigar las amenazas comunes. En conjunto, parece que la solución correcta es puntuar tanto al propio agente de red como a las entidades subyacentes que lo componen. Estas puntuaciones se pueden exponer al motor de políticas, que puede elegir el componente o componentes correctos a autorizar en función de la política que se esté escribiendo.
Sin embargo, presentar tantas puntuaciones para su consideración al redactar la política puede hacer que la tarea de crearla sea más difícil y propensa a errores. En un mundo ideal, bastaría con una única puntuación, pero ese planteamiento plantea requisitos adicionales de disponibilidad al motor de confianza. Un sistema que intente crear una única puntuación probablemente tendría que pasar a un modelo en línea, en el que se consulte interactivamente al motor de confianza durante la toma de decisiones políticas. Al motor se le daría algún contexto sobre la solicitud que se está autorizando para que pudiera elegir la mejor función de puntuación para esa solicitud concreta. Este diseño es claramente más complejo de construir y manejar. Además, para una política en la que un administrador del sistema desee específicamente dirigirse a un componente concreto (por ejemplo, sólo permitir implementaciones de dispositivos con una puntuación superior a X), parece bastante indirecta.
Exponer las puntuaciones consideradas arriesgadas
Aunque las puntuaciones asignadas a las entidades en una red de confianza cero no se consideran confidenciales, debe evitarse exponer las puntuaciones a los usuarios finales del sistema. Ver la puntuación de uno mismo podría ser una señal para los posibles atacantes de que están aumentando o disminuyendo su confianza en el sistema. Este deseo de ocultar información debe equilibrarse con la frustración provocada por la incapacidad de los usuarios finales para comprender cómo afectan sus acciones a su propia fiabilidad en el sistema. Un buen compromiso del sector del fraude es mostrar a los usuarios sus puntuaciones con poca frecuencia, y destacar los factores que contribuyen a la determinación de su puntuación.
Almacenes de datos
Los almacenes de datos utilizados para tomar decisiones de autorización son, sencillamente, las fuentes de verdad de los estados actuales y pasados del sistema. La información de estos almacenes de datos fluye a través de los sistemas del plano de control, proporcionando una gran parte de la base sobre la que se toman las decisiones de autorización, como se demuestra en la Figura 4-4.
Anteriormente hablamos de que el motor de confianza aprovecha estos almacenes de datos para producir una puntuación de confianza, que a su vez es considerada por el motor de políticas. De este modo, la información de los almacenes de datos del plano de control ha fluido a través del sistema de autorización, llegando finalmente al motor de políticas, donde se ha tomado la decisión. Estos almacenes de datos son utilizados por el motor de políticas, tanto directa como indirectamente, pero pueden ser útiles para otros sistemas que necesiten datos fidedignos sobre el estado de la red.
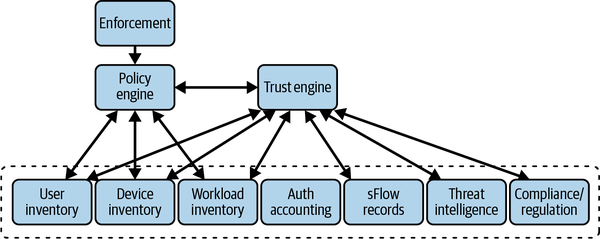
Figura 4-4. Los almacenes de datos autorizados son utilizados por el motor de políticas tanto directamente como indirectamente a través del motor de confianza
Las redes de confianza cero suelen tener muchos almacenes de datos, organizados por funciones. Hay dos tipos principales: de inventario e históricos. Un inventario es una única fuente coherente de verdad, que registra el estado actual del recurso o recursos que representa. Un ejemplo es un inventario de usuarios que almacena toda la información de los usuarios, o un inventario de dispositivos que registra la información sobre los dispositivos conocidos por la empresa.
En un inventario, existe una clave primaria que representa unívocamente a la entidad rastreada. En el caso de un usuario, lo más probable es que sea el nombre de usuario; para un dispositivo, quizá sea un número de serie. Cuando un agente de confianza cero se somete a la autenticación, está autenticando su identidad frente a esta clave primaria del inventario. Piénsalo así: un usuario se autentica con un nombre de usuario determinado. El motor de políticas conoce el nombre de usuario y sabe que el usuario se ha autenticado correctamente. El nombre de usuario se utiliza entonces como clave primaria para la búsqueda en el inventario de usuarios. Tener en cuenta este flujo y propósito te ayudará a elegir las claves primarias correctas, dependiendo de tu implementación particular y de tus opciones de autenticación.
Un almacén de datos históricos es un poco diferente. Los almacenes de datos históricos se guardan principalmente con fines de análisis de riesgos. Son útiles para examinar comportamientos y patrones recientes/pasados con el fin de evaluar el riesgo en relación con una solicitud o acción concreta. Lo más probable es que los componentes del motor de confianza consuman estos datos, ya que las determinaciones de confianza/riesgo son la principal responsabilidad del motor.
Se pueden imaginar muchos tipos de almacenes de datos históricos, y cuando se trata de análisis de riesgos, el cielo es el límite. Algunos ejemplos comunes son los registros contables de usuarios y los datos sFlow1 y los datos sFlow. Independientemente de los datos que se almacenen, deben poder consultarse utilizando la clave primaria de uno de los sistemas de inventario. Hablaremos de varios almacenes de datos históricos y de inventario a medida que introduzcamos conceptos relacionados a lo largo de este libro.
La inteligencia sobre amenazas recopilada de fuentes internas y externas de terceros, como la Inteligencia de Fuente Abierta (OSINT), proporciona información valiosa que los motores de confianza pueden utilizar para determinar una puntuación de confianza. Considera un escenario en el que las credenciales de un usuario se filtraron en la web oscura como resultado de una reciente filtración de datos. En este caso, el motor de confianza puede utilizar la inteligencia sobre amenazas para calcular la puntuación de confianza contra el usuario, lo que puede llevar al motor de políticas a denegar la solicitud o a concederle un acceso limitado.
Las normas de cumplimiento y reglamentarias, como el Reglamento General de Protección de Datos (RGPD), el Programa Federal de Gestión de Riesgos y Autorizaciones (FedRAMP), etc., influyen en el proceso de toma de decisiones del motor de políticas al analizar una solicitud. Las organizaciones suelen mantener un sistema versionado para mantener el cumplimiento y los requisitos normativos que puede utilizarse para crear políticas, idealmente totalmente automatizadas, pero que muy probablemente requieran una revisión humana final antes de su publicación. El resultado final es un sistema sólido en el que el motor de políticas puede consultar el almacén de cumplimiento y normativa para determinar si una solicitud debe concederse o rechazarse.
Recorrido del escenario
Antes de terminar este capítulo, consideremos un escenario sencillo pero real que te ayudará a comprender los distintos componentes tratados en este capítulo y en los anteriores, además de cómo interactúan entre sí. En capítulos posteriores ampliaremos el escenario a medida que profundicemos en diversos aspectos de la confianza cero, como los usuarios, los dispositivos, las aplicaciones y el tráfico.
Veamos un flujo de trabajo típico para un usuario llamado Bob, que trabaja como director comercial para Wayne Corporation e intenta acceder a un recurso, como una impresora. La Figura 4-5 muestra un desglose de alto nivel de los componentes de confianza cero en este escenario.
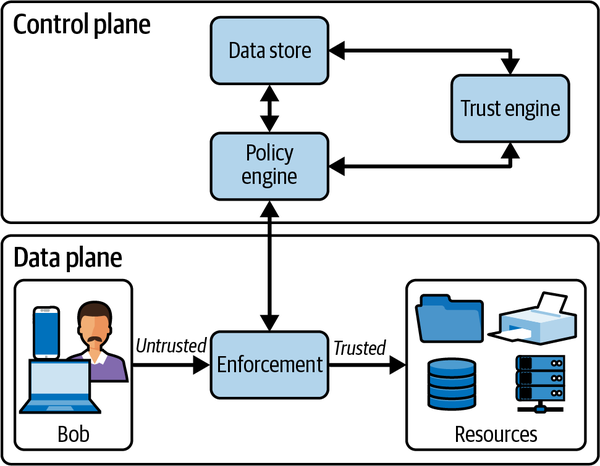
Figura 4-5. Vista lógica de un modelo de seguridad de confianza cero con plano de control, plano de datos, usuario y recursos
En primer lugar, examina los componentes del plano de control, como se muestra en la Figura 4-6. La información personal de Bob, como su nombre, dirección IP y ubicación, se almacena en el almacén de usuarios. Los datos del dispositivo incluyen detalles como el sistema operativo y si los dispositivos de Bob han recibido o no el parche de seguridad más reciente. Por último, los registros de actividad registran cada interacción que tiene, incluyendo la marca de tiempo (en formato Unix), la dirección IP y la ubicación.
El motor de confianza emplea un modelo de aprendizaje automático para calcular dinámicamente la puntuación de confianza buscando comportamientos anómalos en los registros de actividad de Bob. Su principal responsabilidad es calcular y comunicar la puntuación de confianza al motor de políticas.
El motor de políticas, que está en el corazón del plano de control, utiliza la puntuación de confianza y las políticas de cumplimiento para determinar si la solicitud de Bob debe concederse o denegarse.
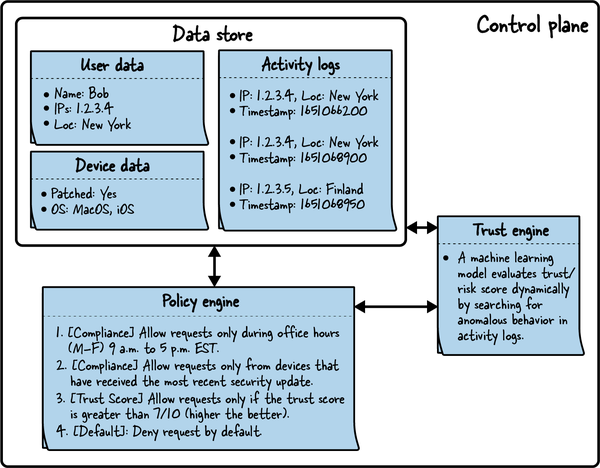
Figura 4-6. Para tomar una decisión de autorización frente a una solicitud de acceso, el motor de políticas utiliza una puntuación de confianza, así como reglas de conformidad
Ahora examinaremos más detenidamente las reglas de política que rigen el comportamiento del motor de políticas. Las dos primeras están relacionadas con el cumplimiento, y garantizan que el sistema cumpla siempre los requisitos empresariales normativos y operativos. La tercera añade una puntuación de confianza como entrada dinámica a la política, garantizando que las solicitudes sólo se concedan si la puntuación supera un determinado umbral. Por último, si no se aplica ninguna otra regla de política, el comportamiento por defecto es denegar la solicitud de autorización, garantizando que el acceso se deniegue a menos que una regla de política lo conceda explícitamente:
- 1. Conformidad
Sólo se admiten solicitudes en horario de oficina, de lunes a viernes, entre las 9.00 y las 17.00 horas, zona horaria del este (EST).
- 2. Conformidad
Permite solicitudes sólo de dispositivos que hayan recibido la actualización de seguridad más reciente. El objetivo es garantizar que los dispositivos estén parcheados y sean menos vulnerables a los exploits.
- 3. Puntuación de confianza
Permitir solicitudes sólo si la puntuación de confianza es superior a 7/10. Una puntuación de confianza más alta inspira más confianza en este caso, por lo que se utiliza un valor de 7. Normalmente, los valores de la puntuación de confianza en las políticas son configurables y se ajustan con el tiempo para garantizar un equilibrio; un umbral de puntuación bajo permite que las solicitudes maliciosas se cuelen por las rendijas, mientras que una puntuación alta puede afectar negativamente a las solicitudes de acceso auténticas.
- 4. Por defecto
Si no se aplica ninguna otra regla de política, ésta es la regla general (por tanto, predeterminada) que entra en vigor. Esta regla es importante porque se recomienda denegar por defecto en lugar de permitir por defecto. Esto es útil porque no hay confianza inherente en un sistema de confianza cero, por lo que cada petición se evalúa por sus propios méritos y se trata como igualmente maliciosa.
A continuación, considera el plano de datos, que incluye la aplicación, los recursos (impresoras, archivos compartidos, etc.) y el usuario Bob, que solicita acceso a un recurso (archivo compartido en este caso). La Figura 4-7 muestra el plano de control y el plano de datos.
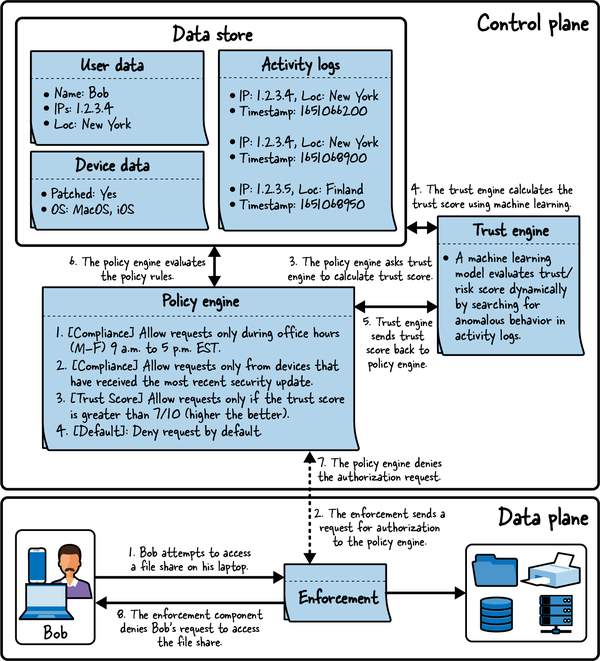
Figura 4-7. La solicitud de Bob para acceder al archivo compartido se deniega después de que el motor de políticas evalúe la solicitud utilizando la puntuación de confianza y otras reglas de política
Aquí tienes un análisis paso a paso de la petición de Bob:
El lunes, a las 9.30 h de la Zona Horaria del Este (EST), Bob solicita acceso al archivo compartido desde su portátil. El portátil está totalmente parcheado y ejecuta MacOS.
El componente de aplicación intercepta la solicitud y la envía al motor de políticas para su autorización.
El motor de políticas recibe la solicitud y consulta con el motor de confianza para determinar la puntuación de confianza de la solicitud.
El motor de confianza utiliza un modelo de aprendizaje automático para calcular la puntuación de confianza basándose en los registros de actividad. Se detectan anomalías porque la dirección IP de Bob 1.2.3.5 y su ubicación en Finlandia son inusuales. Además, dado que las solicitudes se hicieron desde Nueva York y Finlandia y sólo tienen unos segundos de diferencia, las marcas de tiempo entre las dos últimas actividades parecen imposibles de hacer coincidir para un humano. El modelo de aprendizaje automático decide que a la solicitud se le debe asignar una puntuación de confianza de 3, lo que indica un bajo nivel de confianza, y envía la puntuación al motor de políticas.
El motor de políticas recibe la puntuación de confianza de 3 del motor de confianza.
Para la autorización, el motor de la política compara la solicitud con todas las reglas de la política:
Esta primera regla da lugar a una acción de conceder (o permitir) porque la solicitud se realiza durante las horas permitidas del lunes.
La segunda regla da como resultado una acción de conceder (o permitir) porque la solicitud se realiza utilizando un dispositivo que ha sido totalmente parcheado con la actualización de seguridad más reciente.
La tercera regla resulta en una acción de denegación porque la solicitud recibió una puntuación de confianza de 3, mientras que la política requiere una puntuación de confianza de 7 o superior para conceder el acceso. Como la acción denegar es una acción final, el motor de la política no procesa ninguna regla adicional.
El motor de la política envía una acción de denegación al componente de aplicación. También envía información adicional sobre el resultado, que puede ayudar a comprender el motivo de la denegación de la acción solicitada.
El componente de aplicación recibe el resultado del motor de políticas y deniega la solicitud de Bob, impidiéndole acceder al archivo compartido. También envía a Bob un mensaje de ayuda sobre cómo mejorar sus posibilidades de acceder al recurso si decide hacerlo en una futura solicitud.
Aunque de naturaleza básica, el recorrido del escenario de esta sección proporciona una comprensión funcional de varios componentes del plano de control y del plano de datos que trabajan juntos para denegar la solicitud de Bob de acceder al archivo compartido. Lo más importante es que el sistema establecido no toma decisiones de autorización basándose en criterios ad hoc, sino que tiene en cuenta el contexto general de la solicitud de acceso a la hora de tomar decisiones.
Resumen
Este capítulo se ha centrado en los sistemas responsables de tomar la decisión última de si una solicitud concreta debe autorizarse en una red de confianza cero. Esta decisión es un componente crítico de una red de este tipo y, por tanto, debe diseñarse y aislarse cuidadosamente para garantizar que sea digna de confianza.
Desglosamos esta responsabilidad en cuatro sistemas clave: aplicación, motor de políticas, motor de confianza y almacenes de datos. Estos componentes son áreas lógicas de responsabilidad. Aunque podrían colapsarse en menos sistemas físicos, los autores prefieren un diseño aislado.
El sistema de aplicación es responsable de garantizar que la decisión de autorización del motor de la política surta efecto. Este sistema, al estar en la ruta de datos del tráfico de usuarios, se implementa mejor de forma que se haga referencia a la decisión política y luego se aplique. Dependiendo de la arquitectura elegida, el motor de la política podría ser notificado antes de que se produzca una solicitud, o durante el procesamiento de esa misma solicitud.
El motor de políticas es el sistema clave que calcula la decisión de autorización basándose en los datos de que dispone y en las definiciones de políticas que han elaborado los administradores del sistema. Este sistema debe estar fuertemente aislado. Lo ideal es que la política definida se almacene separada del motor y que se utilicen buenas prácticas de desarrollo de software para garantizar que los cambios se comprenden, se revisan y no se pierden a medida que la política pasa de ser propuesta a ser aplicada. Además, dado que las redes de confianza cero esperan tener una política mucho más detallada, las organizaciones maduras optan por distribuir la responsabilidad de definir esa política en la organización, con equipos de seguridad que revisen los cambios propuestos.
El motor de confianza es un concepto nuevo en los sistemas de seguridad. Este motor se encarga de calcular una puntuación de confianza de los componentes del sistema utilizando algoritmos estáticos e inferidos derivados de comportamientos anteriores. La puntuación de confianza es una determinación numérica de la fiabilidad de un componente y permite a los redactores de políticas centrarse en el nivel de confianza necesario para acceder a algún recurso, en lugar de en los detalles concretos de las acciones que podrían reducir esa confianza.
El componente final de esta parte del sistema son las fuentes de datos autorizadas que capturan los datos actuales e históricos que pueden utilizarse para tomar la decisión de autorización. Estos almacenes de datos deben centrarse en ser fuentes de verdad. El motor de políticas, el motor de confianza y quizás los sistemas de terceros pueden aprovechar estos datos, por lo que la recopilación de estos datos tendrá un retorno decente de la inversión de capturarlos.
El recorrido del escenario demostró cómo interactúan varios componentes del plano de control y del plano de datos para que funcione el sistema. En nuestro escenario, la solicitud del usuario Bob para acceder a un archivo compartido se evaluó basándose en el contexto general de la solicitud, que incluía tanto un cálculo dinámico de la puntuación de confianza como diversas políticas establecidas por la empresa para tomar una decisión final de autorización. Este recorrido por el escenario se ampliará en capítulos posteriores.
El próximo capítulo profundizará en cómo los dispositivos ganan y mantienen la confianza.
Get Redes de Confianza Cero, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

