Capítulo 1. Fundamentos de la Confianza Cero
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En una época en la que la vigilancia de la red es omnipresente, nos resulta difícil confiar en nadie, y definir qué es la confianza en sí misma es igualmente difícil. ¿Podemos confiar en que nuestro tráfico de Internet estará a salvo de escuchas? Desde luego que no. ¿Qué pasa con ese proveedor al que alquilaste la fibra? ¿O de ese técnico contratado que estuvo ayer en tu centro de datos trabajando en el cableado?
Denunciantes como Edward Snowden y Mark Klein han revelado la tenacidad de las redes de espionaje respaldadas por el gobierno. El mundo quedó conmocionado al revelarse que habían conseguido entrar en los centros de datos de grandes organizaciones. Pero, ¿por qué? ¿No es exactamente lo que tú harías en su lugar? ¿Especialmente si supieras que el tráfico allí no estaría cifrado?
La suposición de que los sistemas y el tráfico dentro de un centro de datos son de confianza es errónea. Las redes modernas y los patrones de uso ya no se hacen eco de los que hacían que la defensa del perímetro tuviera sentido hace muchos años. Como resultado, moverse libremente dentro de una infraestructura "segura" a menudo tiene una barrera de entrada baja una vez que un solo host o enlace se ha visto comprometido.
Puede que pienses que la idea de utilizar un ciberataque como arma para interrumpir infraestructuras críticas como una central nuclear o una red eléctrica es descabellada, pero los ciberataques aloleoducto Colonial Pipeline en Estados Unidos y a la central nuclear Kudankulam en la India sirven como crudo recordatorio de que las infraestructuras críticas seguirán siendo un objetivo de gran valor para los atacantes. ¿Qué tenían en común ambos ataques?
En ambos casos, la seguridad era pésima. Los atacantes se aprovecharon del hecho de que la conexión VPN (red privada virtual) a la red de Colonial Pipeline era posible utilizando una contraseña de texto plano sin que existiera ningún tipo de autenticación multifactor (MFA). En el otro ejemplo, se descubrió malware en el ordenador de un empleado de una central nuclear india que estaba conectado a los servidores de Internet de la red administrativa. Una vez que los atacantes obtuvieron acceso, pudieron deambular por la red debido a la "confianza" que supone estar dentro de la red.
La confianza cero pretende resolver los problemas inherentes a depositar nuestra confianza en la red. En su lugar, es posible asegurar la comunicación y el acceso a la red de forma tan eficaz que la seguridad física de la capa de transporte pueda ignorarse razonablemente. Huelga decir que se trata de un objetivo elevado. La buena noticia es que hoy en día disponemos de algoritmos criptográficos bastante potentes y, con los sistemas de automatización adecuados, esta visión es realmente alcanzable.
¿Qué es una Red de Confianza Cero?
Una red de confianza cero se basa en cinco afirmaciones fundamentales:
-
Siempre se supone que la red es hostil.
-
En la red existen amenazas externas e internas en todo momento.
-
La localidad de la red por sí sola no es suficiente para decidir la confianza en una red.
-
Cada dispositivo, usuario y flujo de red está autenticado y autorizado.
-
Las políticas deben ser dinámicas y calcularse a partir de tantas fuentes de datos como sea posible.
La arquitectura de seguridad de red tradicional divide las distintas redes (o partes de una misma red) en zonas, contenidas por uno o varios cortafuegos. A cada zona se le concede cierto nivel de confianza, que determina los recursos de red a los que puede acceder. Este modelo proporciona una defensa en profundidad muy sólida. Por ejemplo, los recursos considerados más arriesgados, como los servidores web que dan a la Internet pública, se colocan en una zona de exclusión (a menudo denominada "DMZ"), donde el tráfico puede ser estrictamente monitorizado y controlado. Este enfoque da lugar a una arquitectura similar a algunas que hayas visto antes, como la que se muestra en la Figura 1-1.
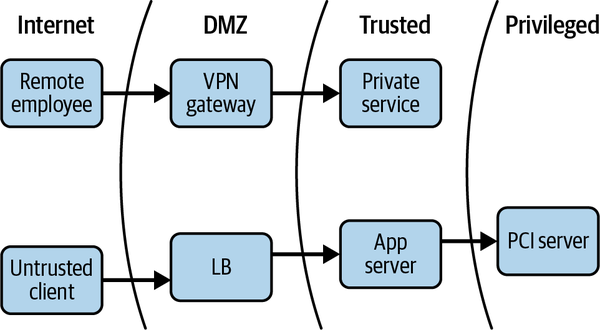
Figura 1-1. Arquitectura tradicional de seguridad de la red
El modelo de confianza cero da la vuelta a este diagrama. Colocar tapones en la red es un sólido paso adelante respecto a los diseños de antaño, pero tiene carencias significativas en el panorama moderno de los ciberataques. Las desventajas son muchas:
-
Falta de inspección del tráfico intrazona
-
Falta de flexibilidad en la colocación del host (tanto física como lógica)
-
Puntos únicos de fallo
Hay que señalar que, si se eliminan los requisitos de localización de la red, también desaparece la necesidad de las VPN. Una red privada virtual (VPN) permite que un usuario se autentique para recibir una dirección IP en una red remota. A continuación, el tráfico se tuneliza desde el dispositivo hasta la red remota, donde se desencapsula y enruta. Es la mayor puerta trasera que nadie sospechaba. Si, por el contrario, declaramos que la ubicación de la red no tiene valor, la VPN queda obsoleta de repente, junto con otras construcciones de red modernas. Por supuesto, este mandato requiere empujar la aplicación de la ley lo más lejos posible hacia el perímetro de la red, pero al mismo tiempo libera al núcleo de tal responsabilidad. Además, los cortafuegos de estado existen en todos los principales sistemas operativos, y los avances en conmutación y encaminamiento han abierto la oportunidad de instalar capacidades avanzadas en el perímetro. Todos estos avances se unen para llegar a una conclusión: es el momento adecuado para un cambio de paradigma. Aprovechando la aplicación de políticas distribuidas y aplicando los principios de confianza cero, podemos producir un diseño similar al que se muestra en la Figura 1-2.
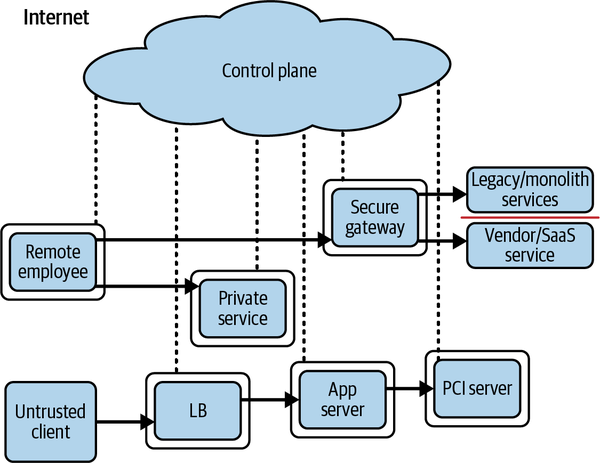
Figura 1-2. Arquitectura de confianza cero
Presentación del Plano de Control de Confianza Cero
El sistema de soporte se conoce como plano de control, mientras que casi todo lo demás se denomina plano de datos, que el plano de control coordina y configura. Las solicitudes de acceso a recursos protegidos se realizan primero a través del plano de control, donde tanto el dispositivo como el usuario deben autenticarse y autorizarse. En esta capa pueden aplicarse políticas detalladas, quizás basadas en el papel que se desempeña en la organización, la hora del día, la ubicación geográfica o el tipo de dispositivo. El acceso a recursos más seguros puede exigir además una autenticación más fuerte.
Una vez que el plano de control ha decidido que se permitirá la solicitud, configura dinámicamente el plano de datos para que acepte el tráfico de ese cliente (y sólo de ese cliente). Además, puede coordinar los detalles de un túnel encriptado entre el solicitante y el recurso. Esto puede incluir credenciales temporales de un solo uso, claves y números de puerto efímeros.
Hay que tener en cuenta que la decisión del plano de control de permitir una solicitud está limitada en el tiempo y no es permanente. Esto significa que si los factores que llevaron al plano de control a tomar la decisión de permitir la solicitud han cambiado, puede coordinarse con el plano de datos para revocar el acceso solicitado al recurso.
Aunque se pueden hacer algunas concesiones sobre la solidez de estas medidas, la idea básica es que una fuente autorizada, o un tercero de confianza, tenga la capacidad de autentificar, autorizar y coordinar el acceso en tiempo real, basándose en una serie de entradas. Hablaremos más sobre los planos de control y de datos en el Capítulo 2.
Evolución del modelo de perímetro
La arquitectura tradicional descrita en este libro suele denominarse modelo perimetral, por el enfoque de muro de castillo utilizado en seguridad física. Este enfoque protege los elementos sensibles construyendo líneas de defensa que un intruso debe penetrar antes de obtener acceso. Por desgracia, este enfoque es fundamentalmente erróneo en el contexto de las redes informáticas y ya no es suficiente. Para comprender plenamente el fallo, es útil recordar cómo se llegó al modelo actual.
Gestión del espacio global de direcciones IP
El viaje que condujo al modelo perimetral comenzó con la asignación de direcciones. Las redes se conectaban a un ritmo cada vez mayor durante los primeros tiempos de Internet. Si una red no se conectaba a Internet (recuerda que Internet no era omnipresente en aquella época), se conectaba a otra unidad de negocio, a otra empresa o quizá a una red de investigación. Por supuesto, las direcciones IP deben ser únicas en cualquier red IP, y si los operadores de la red tuvieran la mala suerte de tener rangos solapados, tendrían mucho trabajo para cambiarlos todos. Si resulta que la red a la que te conectas es Internet, entonces tus direcciones deben ser únicas a nivel mundial. Así que está claro que aquí hace falta algo de coordinación.
La Autoridad de Asignación de Números de Internet (IANA), creada formalmente en 1998, es el organismo que hoy se encarga de esa coordinación. Antes de la creación de la IANA, esta responsabilidad corría a cargo de Jon Postel, que creó el mapa de Internet que se muestra en la Figura 1-3. Él era la fuente autorizada para los registros de propiedad de direcciones IP, y si querías garantizar que tus direcciones IP eran únicas en todo el mundo, debías registrarte con él. En aquella época, se animaba a todo el mundo a registrarse para obtener un espacio de direcciones IP, aunque la red que se registrara no fuera a estar conectada a Internet. Se partía de la base de que, aunque una red no estuviera conectada ahora, probablemente se conectaría a otra red en algún momento.
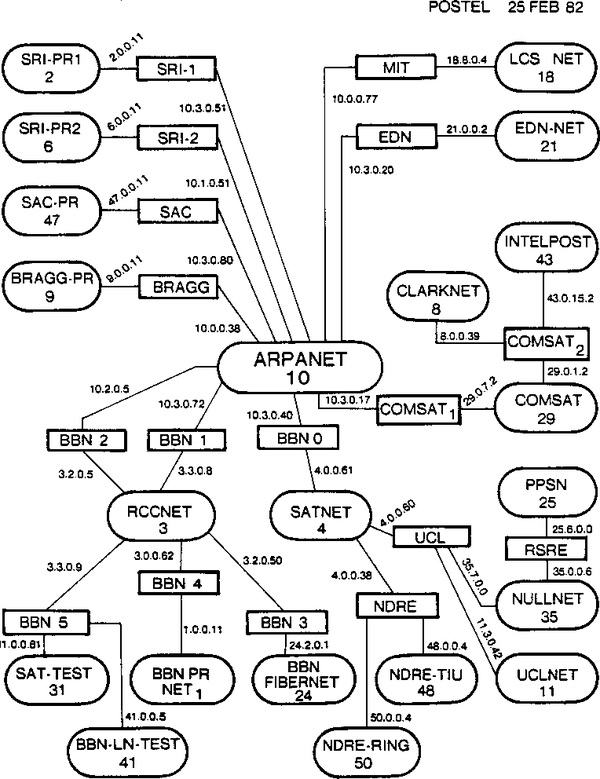
Figura 1-3. Mapa de los inicios de Internet creado por Jon Postel, fechado en febrero de 1982.
Nacimiento del espacio de direcciones IP privadas
A medida que crecía la adopción del IP a finales de los 80 y principios de los 90, el uso frívolo del espacio de direcciones se convirtió en una grave preocupación. Empezaron a surgir numerosos casos de redes realmente aisladas con grandes necesidades de espacio de direcciones IP. Las redes que conectaban los cajeros automáticos y las pantallas de llegadas y salidas de los grandes aeropuertos se citaron como ejemplos principales. Estas redes se consideraban verdaderamente aisladas por varias razones. Algunos dispositivos podían estar aislados para cumplir requisitos de seguridad o privacidad (por ejemplo, las redes destinadas a los cajeros automáticos). Algunos podían estar aislados porque el alcance de su función era tan limitado que tener un acceso más amplio a la red se consideraba excesivamente improbable (por ejemplo, las pantallas de llegadas y salidas de los aeropuertos). El RFC 1597, Asignación de Direcciones para Internets Privadas, se introdujo para resolver este problema de desperdicio de espacio de direcciones públicas.
En marzo de 1994, el RFC 1597 anunció que se habían reservado tres rangos de red IP con la IANA para uso general en redes privadas: 10.0.0.0/8, 172.16.0.0/12 y 192.168.0.0/16. Esto tuvo el efecto de ralentizar el agotamiento de las direcciones al garantizar que el espacio de direcciones de las grandes redes privadas nunca creciera más allá de esas asignaciones. También permitió a los operadores de red utilizar direcciones no únicas globalmente donde y cuando lo consideraran oportuno. Tuvo otro efecto interesante, que perdura hoy en día: las redes que utilizaban direcciones privadas eran más seguras, porque eran fundamentalmente incapaces de unirse a otras redes, en particular a Internet.
En aquella época, muy pocas organizaciones (relativamente hablando) tenían conexión o presencia en Internet, por lo que las redes internas solían estar numeradas con los rangos reservados. Además, las medidas de seguridad eran de débiles a inexistentes porque estas redes solían estar confinadas por los muros de una sola organización.
Las redes privadas se conectan a las redes públicas
El número de cosas interesantes en Internet creció con bastante rapidez, y pronto la mayoría de las organizaciones quisieron tener al menos algún tipo de presencia. El correo electrónico fue uno de los primeros ejemplos de ello. La gente quería poder enviar y recibir correo electrónico, pero eso significaba que necesitaban un servidor de correo de acceso público, lo que por supuesto significaba que necesitaban conectarse a Internet de alguna manera. En las redes privadas establecidas, a menudo este servidor de correo era el único con conexión a Internet. Tendría una interfaz de red orientada a Internet y otra a la red interna. De este modo, los sistemas y las personas de la red privada interna podían enviar y recibir correo electrónico por Internet a través de su servidor de correo conectado.
Rápidamente nos dimos cuenta de que estos servidores habían abierto una ruta física de Internet a su red, que de otro modo sería segura y privada. Si uno de ellos quedaba comprometido, un atacante podría abrirse camino hasta la red privada, ya que los hosts de ésta podían comunicarse con él. Esta constatación provocó un escrutinio estricto de estos hosts y sus conexiones de red. Los operadores de red colocaron cortafuegos a ambos lados de ellos para restringir la comunicación y frustrar a los posibles atacantes que intentaran acceder a los sistemas internos desde Internet, como se muestra en la Figura 1-4. Con este paso nació el modelo perimetral. La red interna se convirtió en la red "segura", y la bolsa estrechamente controlada en la que se encontraban los hosts externos se convirtió en la DMZ, o zona desmilitarizada.
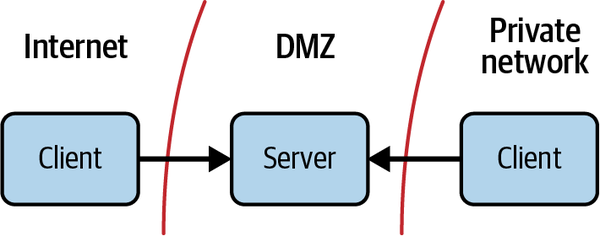
Figura 1-4. Tanto los recursos de Internet como los privados pueden acceder a los hosts de la DMZ; sin embargo, los recursos privados no pueden llegar más allá de la DMZ, por lo que no obtienen acceso directo a Internet
Nacimiento de NAT
El número de recursos de Internet a los que se accedía desde redes internas crecía rápidamente, y enseguida resultó más fácil conceder acceso general a Internet a los recursos internos que mantener hosts intermediarios para cada aplicación deseada. NAT, o traducción de direcciones de red, resolvió este problema de forma muy satisfactoria.
El RFC 1631, El Traductor de Direcciones de Red IP, define una norma para un dispositivo de red capaz de realizar la traducción de direcciones IP en los límites de la organización. Al mantener una tabla que mapea IPs y puertos públicos a privados, permitía a los dispositivos de las redes privadas acceder a recursos arbitrarios de Internet. Este mapeo ligero es agnóstico respecto a las aplicaciones, lo que significa que los operadores de red ya no necesitan dar soporte a la conectividad a Internet para aplicaciones concretas; sólo necesitan dar soporte a la conectividad a Internet en general.
Estos dispositivos NAT tenían una propiedad interesante: como el mapeo de IP era de muchos a uno, no era posible que las conexiones entrantes de Internet accedieran a IP privadas internas sin configurar específicamente el NAT para gestionar este caso especial. De este modo, los dispositivos mostraban las mismas propiedades que un cortafuegos con estado. Los cortafuegos reales empezaron a integrar las funciones NAT casi instantáneamente, y ambas se convirtieron en una única función, en gran medida indistinguible. La compatibilidad con la red y los estrictos controles de seguridad hicieron que, con el tiempo, pudieras encontrar uno de estos dispositivos prácticamente en todos los límites de la organización, como se muestra en la Figura 1-5.
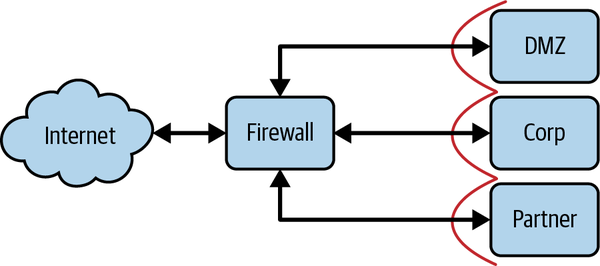
Figura 1-5. Diseño típico (y simplificado) de cortafuegos perimetral
El modelo de perímetro contemporáneo
Con un cortafuegos/dispositivo NAT entre la red interna e Internet, las zonas de seguridad se forman claramente. Está la zona interna "segura", la DMZ (zona desmilitarizada) y la zona no fiable (también conocida como Internet). Si en algún momento del futuro, esta organización necesitara interconectarse con otra, se colocaría un dispositivo en ese límite de forma similar. La organización vecina se convertiría probablemente en una nueva zona de seguridad, con normas particulares sobre qué tipo de tráfico puede pasar de una a otra, igual que la DMZ o la zona segura.
Mirando hacia atrás, vemos la progresión. Pasamos de redes offline/privadas con sólo uno o dos hosts con acceso a Internet a redes altamente interconectadas con dispositivos de seguridad en todo el perímetro. No es difícil de entender: los operadores de red no podían permitirse sacrificar la perfecta seguridad de su red offline porque tenían que abrir puertas para diversos fines empresariales. Los estrictos controles de seguridad en cada puerta minimizaban el riesgo.
Evolución del panorama de amenazas
Incluso antes de que existiera Internet, era muy conveniente comunicarse con un sistema informático remoto. Esto se hacía habitualmente a través del sistema telefónico público. Los usuarios y los sistemas informáticos podían marcar y, mediante la codificación de datos en tonos audibles, obtener conectividad con la máquina remota. Estas interfaces de acceso telefónico eran el vector de ataque más común de la época, ya que obtener acceso físico era mucho más difícil.
Una vez que las organizaciones dispusieron de hosts conectados a Internet, los ataques pasaron de producirse a través de la red telefónica a lanzarse a través de la conexión telefónica a Internet. Esto provocó un cambio en la dinámica de la mayoría de los ataques. Las llamadas entrantes a interfaces de acceso telefónico ocupaban una línea telefónica, y eran un hecho notable en comparación con una conexión TCP procedente de Internet. Era mucho más fácil tener una presencia encubierta en una red IP que en un sistema al que había que marcar. Los intentos de explotación y fuerza bruta podían llevarse a cabo durante largos periodos de tiempo sin levantar demasiadas sospechas... aunque de este cambio surgió una capacidad adicional y más impactante: el código malicioso podía entonces escuchar el tráfico de Internet.
A finales de los 90, los primeros caballos de Troya (software) del mundo empezaron a hacer sus rondas. Normalmente, se engañaba a un usuario para que instalara el malware, que abría un puerto y esperaba conexiones entrantes. El atacante podía entonces conectarse al puerto abierto y controlar remotamente la máquina objetivo.
No pasó mucho tiempo antes de que la gente se diera cuenta de que sería una buena idea proteger esos hosts orientados a Internet. Los cortafuegos de hardware eran la mejor forma de hacerlo (la mayoría de los sistemas operativos no tenían entonces el concepto de cortafuegos basado en host). Hacían cumplir las políticas, garantizando que sólo se permitiera la entrada de tráfico "seguro" procedente de Internet. Si un administrador instalaba inadvertidamente algo que exponía un puerto abierto (como un troyano), el cortafuegos bloqueaba físicamente las conexiones a ese puerto hasta que se configurara explícitamente para permitirlo. Del mismo modo, se podía controlar el tráfico a los servidores orientados a Internet desde el interior de la red, garantizando que los usuarios internos pudieran hablar con ellos, pero no viceversa. Esto ayudó a evitar la entrada en la red interna de un host DMZ potencialmente comprometido.
Los hosts DMZ eran, por supuesto, un objetivo principal (debido a su conectividad), aunque esos controles tan estrictos sobre el tráfico entrante y saliente dificultaban el acceso a una red interna a través de una DMZ. Un atacante tendría primero que comprometer el servidor con firewall, y luego abusar de la aplicación de forma que pudiera utilizarse para una comunicación encubierta (al fin y al cabo, necesitan sacar datos de esa red). Las interfaces de acceso telefónico seguían siendo la fruta más fácil de conseguir si se quería acceder a una red interna.
Aquí es donde las cosas tomaron un giro interesante. Se introdujo NAT para conceder acceso a Internet a los clientes de las redes internas. Debido en parte a la mecánica de NAT y en parte a verdaderos problemas de seguridad, seguía existiendo un estricto control del tráfico entrante, aunque los recursos internos que deseaban consumir recursos externos podían hacerlo libremente. Hay que hacer una distinción importante al considerar una red con acceso a Internet por NAT frente a una red sin él: la primera tiene una política de red saliente relajada (si es que la tiene).
Esto transformó significativamente el modelo de seguridad de la red. Los servidores de las redes internas "fiables" podían comunicarse directamente con servidores de Internet no fiables, y el servidor no fiable estaba de repente en posición de abusar del cliente que intentara hablar con él. Peor aún, un código malicioso podía enviar mensajes a hosts de Internet desde la red interna. Hoy conocemos esto como "llamar a casa".
Llamar a casa es un componente crítico de la mayoría de los ataques modernos. Permite la exfiltración de datos de redes que, de otro modo, estarían protegidas; pero lo más importante es que, como TCP es bidireccional, también permite inyectar datos. Un ataque típico implica varios pasos, como se muestra en la Figura 1-6. En primer lugar, el atacante compromete un único ordenador de la red interna explotando el navegador del usuario cuando visita una página concreta, enviándole un correo electrónico con un archivo adjunto que explota algún software local, por ejemplo. El exploit lleva una carga útil muy pequeña, sólo el código suficiente para establecer una conexión con un host remoto de Internet y ejecutar el código que recibe en la respuesta. Esta carga útil se denomina a veces dialer.
El dialer descarga e instala el malware real, que la mayoría de las veces intentará establecer una conexión adicional con un host remoto de Internet controlado por el atacante. El atacante utilizará esta conexión para enviar comandos al malware, exfiltrar datos sensibles o incluso obtener una sesión interactiva. Este "paciente cero" puede actuar como trampolín, dando al atacante un host en la red interna desde el que lanzar ataques adicionales.
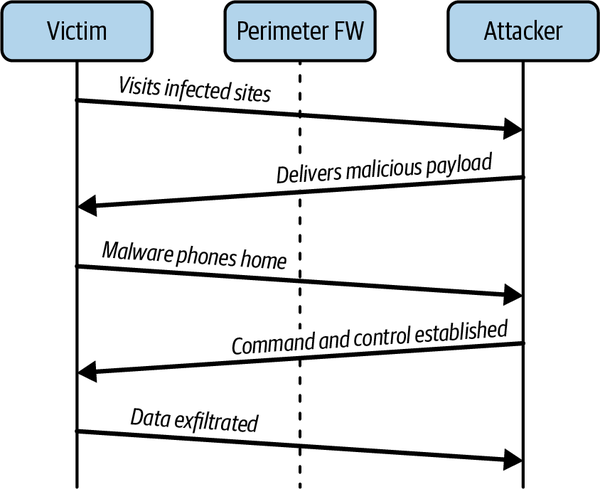
Figura 1-6. El cliente inicia todas las conexiones relacionadas con el ataque, atravesando fácilmente los cortafuegos perimetrales con una seguridad de salida relajada
Seguridad de salida
La seguridad de la red saliente es una medida de mitigación muy eficaz contra los ataques basados en marcadores automáticos, ya que el teléfono de origen puede detectarse y/o bloquearse. A menudo, sin embargo, la llamada a casa se disfraza de tráfico web normal, posiblemente incluso a redes aparentemente benignas o "normales". Una seguridad de salida lo suficientemente estricta como para detener estos ataques a menudo paralizará la usabilidad de la web para los usuarios. Esta es una perspectiva más realista para los sistemas de back-office.
La capacidad de lanzar ataques desde hosts dentro de una red interna es muy poderosa. Es casi seguro que estos hosts tienen permiso para hablar con otros hosts de la misma zona de seguridad (movimiento lateral) e incluso podrían tener acceso para hablar con hosts de zonas más seguras que la suya. Para ello, comprometiendo primero una zona de baja seguridad de la red interna, un atacante puede desplazarse por la red, consiguiendo finalmente acceder a las zonas de alta seguridad.
Dando un paso atrás por un momento, puede verse que este patrón socava muy eficazmente el modelo de seguridad perimetral. El fallo crítico que permite la progresión de los ataques es sutil, pero claro: las políticas de seguridad se definen por zonas de la red, y sólo se aplican en los límites de las zonas, sin utilizar nada más que los datos de origen y destino.
Otras amenazas han aumentado a medida que el mundo se ha hecho más ubicuo con el paso de los años. Hoy en día, las empresas permiten a sus trabajadores utilizar sus propios dispositivos para trabajar, además de los que les proporciona la empresa, gracias a la popularidad de "trae tu propio dispositivo" (BYOD). Como resultado, los empleados pueden ser más productivos, ya que trabajan desde casa más que nunca. Durante COVID-19, descubrimos las ventajas de BYOD cuando los empleados ya no podían entrar en el lugar de trabajo durante largos periodos de tiempo. Sin embargo, la superficie de ataque ha crecido porque parchear numerosos dispositivos con las correcciones de seguridad más recientes es bastante más difícil que parchear un solo dispositivo. Un tipo de ataque, entre otros, es el ataque de clic cero, que ni siquiera requiere la interacción del usuario (más sobre él en la nota siguiente). Los atacantes buscan deliberadamente dispositivos en los que no se hayan actualizado los parches de seguridad para explotar las vulnerabilidades y obtener acceso no autorizado a ellos. En el Capítulo 5, veremos el papel de los parches de seguridad y cómo automatizarlos para mejorar la confianza en los dispositivos.
Ataque sin clic
Un ataque de clic cero es un ataque muy sofisticado que infecta el dispositivo del usuario sin su participación. Los ataques zero-click suelen aprovecharse de fallos de seguridad no parcheados de ejecución de código arbitrario y desbordamiento de búfer. Como estos ataques se realizan sin interacción del usuario, pueden ser increíblemente eficaces. Se ha informado de que aplicaciones populares como WhatsApp e iMessage de Apple son vulnerables a ataques de clic cero. En 2021, Google proporcionó una investigación exhaustiva de la vulnerabilidad de clic cero de iMessage, que describe las ramificaciones de gran alcance del ataque. Parchear todos los dispositivos que tienen acceso a los recursos y servicios de la empresa es fundamental en todo momento.
Deficiencias del perímetro
Aunque el modelo de seguridad perimetral sigue siendo, con diferencia, el más extendido, cada vez es más evidente que la forma en que confiamos en él es defectuosa. Todos los días se producen ataques complejos (y con éxito) contra redes con una seguridad perimetral perfectamente buena. Un atacante introduce una herramienta de acceso remoto (o RAT) en tu red a través de una miríada de métodos, obtiene acceso remoto y comienza a moverse lateralmente. Los cortafuegos perimetrales se han convertido en el equivalente funcional de construir un muro alrededor de una ciudad para mantener alejados a los espías.
El problema surge cuando se integran zonas de seguridad en la propia red. Imagina el siguiente escenario: diriges una pequeña empresa de comercio electrónico. Tienes algunos empleados, algunos sistemas internos (nóminas, inventario, etc.) y algunos servidores para alimentar tu sitio web. Es natural empezar a clasificar el tipo de acceso que pueden necesitar estos grupos: los empleados necesitan acceso a los sistemas internos, los servidores web necesitan acceso a los servidores de bases de datos, los servidores de bases de datos no necesitan acceso a Internet pero los empleados sí, etc. La seguridad de red tradicional codificaría estos grupos como zonas y luego definiría qué zona puede acceder a qué, como se muestra en la Figura 1-7. Por supuesto, tienes que aplicar realmente estas políticas; y como se definen zona por zona, tiene sentido aplicarlas siempre que una zona pueda dirigir tráfico a otra.
Como puedes imaginar, siempre hay excepciones a estas reglas generalizadas... de hecho, se conocen coloquialmente como excepciones del cortafuegos. Estas excepciones suelen tener un alcance lo más restringido posible. Por ejemplo, tu desarrollador web puede querer acceso SSH a los servidores web de producción, o tu representante de RRHH puede necesitar acceso a la base de datos del software de RRHH para realizar auditorías. En estos casos, un enfoque aceptable es configurar una excepción de cortafuegos que permita el tráfico desde la dirección IP de esa persona al servidor o servidores concretos en cuestión.
Ahora imaginemos que tu archienemigo ha contratado a un equipo de hackers. Quieren echar un vistazo a tus cifras de inventario y ventas. Los hackers envían correos electrónicos a todas las direcciones de correo electrónico de los empleados que encuentran en Internet, haciéndose pasar por un código de descuento para un restaurante cercano a la oficina. Efectivamente, uno de ellos hace clic en el enlace, lo que permite a los atacantes instalar malware. El malware llama a casa y proporciona a los atacantes una sesión en la máquina del empleado ahora comprometido. Por suerte, sólo se trata de un interno, y el nivel de acceso que obtienen es limitado.
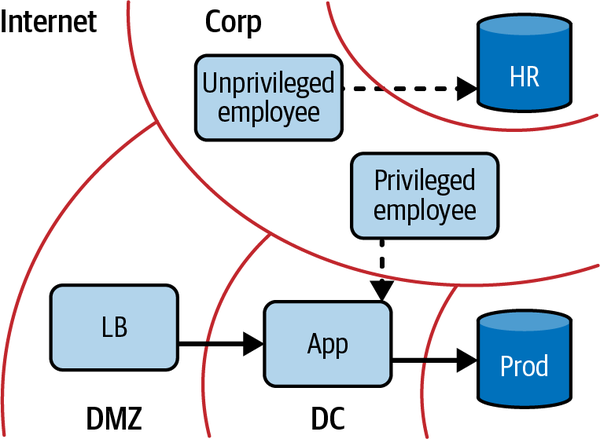
Figura 1-7. Red corporativa interactuando con la red de producción
Empiezan a buscar en la red y descubren que la empresa utiliza software para compartir archivos en su red. De todos los ordenadores de los empleados de la red, ninguno tiene la última versión y son vulnerables a un ataque que se ha hecho público recientemente.
Uno a uno, los hackers empiezan a buscar un ordenador con acceso elevado (este proceso, por supuesto, puede ser más selectivo si el atacante tiene conocimientos avanzados). Finalmente dan con la máquina de tu desarrollador web. Un keylogger que instalan allí recupera las credenciales para iniciar sesión en el servidor web. Se conectan por SSH al servidor utilizando las credenciales obtenidas, y utilizando los derechos sudo del desarrollador web, leen la contraseña de la base de datos del disco y se conectan a la base de datos. Vuelcan el contenido de la base de datos, lo descargan y borran todos los archivos de registro. Si tienes suerte, puede que descubras que se ha producido esta brecha. Han cumplido su misión, como se muestra en la Figura 1-8.
Espera, ¿qué? Como puedes ver, muchos fallos a muchos niveles condujeron a esta brecha, y aunque puedas pensar que se trata de un caso especialmente artificioso, los ataques exitosos como éste son asombrosamente comunes. Sin embargo, la parte más sorprendente pasa desapercibida con demasiada frecuencia: ¿qué ocurrió con toda esa seguridad de la red? Los cortafuegos estaban meticulosamente colocados, las políticas y las excepciones estaban estrechamente delimitadas y muy limitadas, todo se hizo bien desde el punto de vista de la seguridad de la red. Entonces, ¿qué pasó?
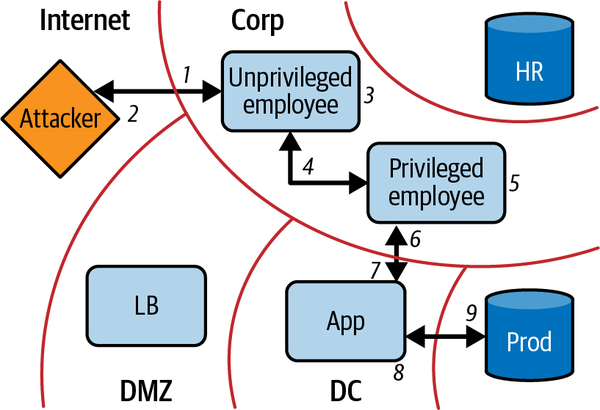
Figura 1-8. Movimiento del atacante hacia la red de la empresa, y posterior producción en la red
Cuando se examina detenidamente, resulta abrumadoramente obvio que este modelo de seguridad de red no es suficiente. Eludir la seguridad del perímetro es trivial con programas maliciosos que llaman a casa, y los cortafuegos entre zonas no tienen en cuenta más que el origen y el destino a la hora de tomar decisiones de aplicación. Aunque los perímetros pueden seguir aportando cierto valor a la seguridad de la red, hay que reconsiderar su papel como mecanismo principal por el que se define la postura de seguridad de una red.
Ejemplo de progresión de ataque
-
Empleados víctimas de phishing por correo electrónico
-
Máquina corporativa comprometida, cáscara paleada
-
Movimiento lateral a través de la red corporativa
-
Puesto de trabajo privilegiado localizado
-
Escalada de privilegios local en estación de trabajo-keylogger instalado
-
Contraseña de desarrollador robada
-
Comprometido el host de la aplicación de producción desde una estación de trabajo privilegiada
-
Contraseña de desarrollador utilizada para elevar privilegios en el host de la aplicación prod
-
Robo de credenciales de base de datos de una aplicación
-
Exfiltración del contenido de la base de datos a través de una aplicación comprometida
El primer paso, por supuesto, es buscar las soluciones existentes. Seguro que el modelo perimetral es el enfoque aceptado para asegurar una red, pero eso no significa que no hayamos aprendido cosas mejores en otros lugares. ¿Cuál es el peor escenario posible para la seguridad de la red? Resulta que en realidad hay un nivel de absoluto en esta pregunta, y el quid de la cuestión reside en la confianza.
Dónde reside la confianza
Al considerar opciones más allá del modelo perimetral, hay que tener una comprensión firme de lo que es de confianza y lo que no lo es. El nivel de confianza define un límite inferior en la robustez de los protocolos de seguridad necesarios. Desgraciadamente, es raro que la robustez supere lo necesario, por lo que conviene confiar lo menos posible. Una vez que la confianza se incorpora a un sistema, puede ser muy difícil eliminarla.
Una red de confianza cero es tal como suena. Es una red en la que no se confía en absoluto. Por suerte para nosotros, interactuamos con una red así con mucha frecuencia: Internet. Internet nos ha enseñado algunas valiosas lecciones de seguridad. Sin duda, un operador protegerá un servidor orientado a Internet de forma muy distinta a como protege su homólogo accesible localmente. ¿Por qué? Y si los dolores asociados a tal rigor se curasen (o incluso sólo disminuyesen), ¿seguiría mereciendo la pena el sacrificio de seguridad?
El modelo de confianza cero dicta que todos los hosts sean tratados como si estuvieran orientados a Internet. Las redes en las que residen deben considerarse comprometidas y hostiles. Sólo con esta consideración puedes empezar a construir una comunicación segura. Dado que la mayoría de los operadores han construido o mantenido sistemas orientados a Internet en el pasado, tenemos al menos alguna idea de cómo asegurar la IP de forma que sea difícil interceptarla o manipularla (y, por supuesto, cómo asegurar esos hosts). La automatización nos permite extender este nivel de seguridad a todos los sistemas de nuestra infraestructura.
La automatización como facilitadora
Las redes de confianza cero no requieren nuevos protocolos o bibliotecas. Sin embargo, utilizan tecnologías existentes de formas novedosas. Los sistemas de automatización son los que permiten construir y hacer funcionar una red de confianza cero.
Las interacciones entre el plano de control y el plano de datos son los puntos más críticos que requieren automatización. Si la aplicación de las políticas no puede actualizarse dinámicamente, la confianza cero será inalcanzable; por tanto, es fundamental que este proceso sea automático y rápido.
Hay muchas formas de realizar esta automatización. Los sistemas creados a propósito son los más ideales, aunque otros más mundanos, como la gestión de la configuración tradicional, también pueden encajar aquí. La adopción generalizada de la gestión de la configuración representa un paso importante para una red de confianza cero, ya que estos sistemas suelen mantener inventarios de dispositivos y son capaces de automatizar la configuración de la aplicación de la red en el plano de datos.
Debido a que los sistemas modernos de gestión de la configuración pueden tanto mantener un inventario de dispositivos como automatizar la configuración del plano de datos, están bien posicionados para ser un primer paso hacia una red madura de confianza cero.
Perímetro frente a confianza cero
Los modelos perimetral y de confianza cero son fundamentalmente diferentes entre sí. El modelo perimetral intenta construir un muro entre los recursos de confianza y los que no lo son (es decir, la red local e Internet). Por otro lado, el modelo de confianza cero básicamente tira la toalla y acepta la realidad de que los "malos" están en todas partes. En lugar de construir muros para proteger a los cuerpos blandos que hay dentro, convierte a toda la población en una milicia.
Los enfoques actuales de las redes perimetrales asignan cierto nivel de confianza a las redes protegidas. Esta noción viola el modelo de confianza cero y conduce a algunos malos comportamientos. Los operadores tienden a bajar un poco la guardia cuando la red es "de confianza" (son humanos). Rara vez los hosts que comparten una zona de confianza están protegidos de sí mismos. Compartir una zona de confianza, después de todo, parece implicar que son igualmente de confianza. Con el tiempo, hemos aprendido que esta suposición es falsa, y que no sólo es necesario proteger a tus servidores del exterior, sino también protegerlos unos de otros.
Como el modelo de confianza cero asume que la red está totalmente comprometida, también debes asumir que un atacante puede comunicarse utilizando cualquier dirección IP arbitraria. Por tanto, proteger los recursos utilizando direcciones IP o la ubicación física como identificador no es suficiente. Todos los hosts, incluso los que comparten "zonas de confianza", deben proporcionar una identificación adecuada. Sin embargo, los atacantes no se limitan a los ataques activos. Todavía pueden realizar ataques pasivos en los que husmean tu tráfico en busca de información sensible. En este caso, ni siquiera la identificación del host es suficiente: también se requiere un cifrado fuerte.
Hay tres componentes clave en una red de confianza cero: autenticación y autorización del usuario/aplicación, autenticación y autorización del dispositivo, y confianza. El primer componente tiene cierta dualidad debido a que no todas las acciones las realizan los usuarios. Así que, en el caso de una acción automatizada (dentro del centro de datos, por ejemplo), nos fijamos en las cualidades de la aplicación del mismo modo que normalmente nos fijaríamos en las cualidades del usuario.
Autenticar y autorizar el dispositivo es tan importante como hacerlo para el usuario/aplicación. Se trata de una función que rara vez se ve en servicios y recursos protegidos por redes perimetrales. A menudo se implementa mediante VPN o tecnología NAC, sobre todo en las redes más maduras, pero encontrarla entre puntos finales (en contraposición a los intermediarios de la red) es poco común.
NAC como tecnología perimetral
NAC, o Control de Acceso a la Red, representa un conjunto de tecnologías diseñadas para autenticar fuertemente los dispositivos con el fin de obtener acceso a una red sensible. Estas tecnologías, que incluyen protocolos como 802.1X y la familia Trusted Network Connect (TNC), se centran en la admisión a una red más que en la admisión a un servicio y, como tales, son independientes del modelo de confianza cero. Un enfoque más coherente con el modelo de confianza cero implicaría comprobaciones similares situadas lo más cerca posible del servicio al que se accede (algo que TNC puede abordar -más sobre esto en el Capítulo 5). Aunque la NAC puede seguir empleándose en una red de confianza cero, no cumple el requisito de autenticación de dispositivos de confianza cero debido a su distancia del punto final remoto.
Por último, se calcula una "puntuación de confianza", y la solicitud, el dispositivo y la puntuación se unen para formar un agente. A continuación, se aplica la política contra el agente para autorizar la solicitud. La riqueza de la información contenida en el agente permite un control de acceso muy flexible, pero de grano fino, que puede adaptarse a condiciones variables mediante la inclusión del componente de puntuación en tus políticas.
Si la solicitud está autorizada, el plano de control indica al plano de datos que acepte la solicitud entrante. Esta acción también puede configurar los detalles del cifrado. La encriptación puede aplicarse a nivel de dispositivo, a nivel de aplicación, o a ambos. Se requiere al menos uno para la confidencialidad.
Con estos componentes de autenticación/autorización, y la ayuda del plano de control en la coordinación de los canales cifrados, podemos afirmar que cada flujo de la red está autenticado y es esperado. Los hosts y los dispositivos de red descartan el tráfico al que no se le han aplicado todos estos componentes, garantizando que nunca puedan filtrarse datos sensibles. Además, al registrar cada uno de los eventos y acciones del plano de control, el tráfico de la red puede auditarse fácilmente flujo a flujo o petición a petición.
Se pueden encontrar redes perimetrales que tienen una capacidad similar, aunque estas capacidades sólo se aplican en el perímetro. Las famosas VPN intentan proporcionar estas cualidades para asegurar el acceso a una red interna, pero la seguridad termina en cuanto tu tráfico llega a un concentrador VPN. Es evidente que los operadores saben cómo se supone que debe ser una seguridad fuerte en Internet; sólo que no aplican esas medidas fuertes en todo el perímetro.
Si se puede imaginar una red que aplique estas medidas de forma homogénea, un breve experimento mental puede arrojar mucha luz sobre este nuevo paradigma. La identidad puede probarse criptográficamente, lo que significa que ya no importa de qué dirección IP procede una conexión determinada (técnicamente, aún puedes asociarle un riesgo; hablaremos de ello más adelante). Con la automatización que elimina las barreras técnicas, la VPN es esencialmente obsoleta. Las redes "privadas" ya no significan nada especial: los hosts que allí se encuentran están tan reforzados como los de Internet. Pensando críticamente sobre NAT y el espacio de direcciones privado, quizás la confianza cero haga más evidente que los argumentos de seguridad a su favor son nulos.
En última instancia, el defecto del modelo perimetral es su falta de protección y aplicación universales. Celdas seguras con cuerpos blandos dentro. Lo que realmente buscamos son cuerpos duros, cuerpos que sepan comprobar identificaciones y hablar de forma que no puedan ser escuchados. Tener cuerpos duros no te impide necesariamente mantener también las células de seguridad. En instalaciones muy sensibles, esto seguiría siendo recomendable. Sin embargo, eleva el listón de seguridad lo suficiente como para que no sea descabellado disminuir o eliminar esas células. Combinado con el hecho de que la mayor parte de la función de confianza cero puede hacerse con transparencia para el usuario final, el modelo casi parece violar el compromiso seguridad/conveniencia: mayor seguridad, mayor conveniencia. Tal vez el problema de la comodidad (o la falta de ella) se haya trasladado a los operadores.
Aplicado en la nube
Hay muchos retos en la implementación de infraestructuras en la nube, y uno de los mayores es la seguridad. La confianza cero encaja perfectamente en las Implementaciones en la nube por una razón obvia: ¡no puedes confiar en la red de una nube pública! La capacidad de autenticar y asegurar la comunicación sin depender de las direcciones IP o de la seguridad de la red que las conecta significa que los recursos informáticos pueden ser casi comoditizados. Como la confianza cero defiende que cada paquete esté cifrado, incluso dentro del mismo centro de datos, los operadores no tienen que preocuparse de qué paquetes atraviesan Internet y cuáles no. A menudo se subestima esta ventaja. La carga cognitiva asociada a cuándo, dónde y cómo encriptar el tráfico puede ser bastante grande, sobre todo para los desarrolladores, que pueden no entender del todo el sistema subyacente. Al eliminar los casos especiales, también podemos eliminar el error humano asociado a ellos.
Algunos podrían argumentar que el cifrado intracentro de datos es una exageración, incluso con la reducción de la carga cognitiva. La historia ha demostrado lo contrario. En los grandes proveedores de la nube, como AWS, una única "región" consta de muchos centros de datos, con enlaces de fibra entre ellos. Para el usuario final, esta sutileza suele estar ofuscada. La NSA apuntaba precisamente a enlaces como éstos en salas como la que se muestra en la Figura 1-9.

Figura 1-9. Sala 641A-Instalación de interceptación de la NSA dentro de un centro de datos de AT&T en San Francisco
Existen riesgos adicionales en la implementación de red del propio proveedor. No es imposible pensar que pueda existir una vulnerabilidad en la que los vecinos puedan ver tu tráfico. Un caso más probable es que los operadores de red inspeccionen el tráfico mientras solucionan problemas. Tal vez el operador sea honesto, pero ¿qué hay de la persona que le robó su portátil unas horas más tarde con tus capturas en el disco? La desafortunada realidad es que ya no podemos dar por sentado que nuestro tráfico está protegido del fisgoneo o la modificación mientras se encuentra en el centro de datos.
Papel de la Confianza Cero en la Ciberseguridad Nacional
En 2021, la Casa Blanca de Estados Unidos publicó la Orden Ejecutiva (OE) 14028, en la que se reclamaba la necesidad de mejorar urgentemente la ciberseguridad nacional. El telón de fondo de esta OE eran los ciberataques cada vez más sofisticados a lo largo de muchos años, predominantemente de adversarios extranjeros, que ponían en peligro la seguridad nacional. La OE 14028 señala específicamente el avance hacia una arquitectura de confianza cero como paso fundamental para mejorar la ciberseguridad nacional:
El Gobierno Federal debe adoptar buenas prácticas de seguridad; avanzar hacia la Arquitectura de Confianza Cero; .....
Extracto de la OE 14028
La adopción de la confianza cero no es exclusiva del gobierno de Estados Unidos, ni mucho menos. Gobiernos de todo el mundo la han adoptado para mejorar la postura de seguridad. Otro ejemplo son los principios de diseño de la arquitectura de confianza cero del Centro Nacional de Ciberseguridad del Reino Unido.
En capítulos posteriores, cubriremos los esfuerzos de varias organizaciones gubernamentales y no gubernamentales como el Instituto Nacional de Estándares y Tecnología (NIST), la Agencia de Ciberseguridad y Seguridad de Infraestructuras (CISA), The Open Group, etc., en la publicación de una arquitectura, principios y directrices de confianza cero.
Resumen
En este capítulo se han explorado los conceptos de alto nivel que nos han llevado hacia el modelo de confianza cero. El modelo de confianza cero prescinde del modelo perimetral, que intenta garantizar que los malos actores permanezcan fuera de la red interna de confianza. En su lugar, el sistema de confianza cero reconoce que este enfoque está condenado al fracaso y, en consecuencia, parte del supuesto de que los actores maliciosos están dentro de la red interna y construye mecanismos de seguridad para protegerse de esta amenaza.
Para entender mejor por qué el modelo perimetral nos está fallando, repasamos cómo surgió el modelo perimetral. En los inicios de Internet, la red era totalmente enrutable. A medida que el sistema evolucionaba, algunos usuarios identificaron zonas de la red que no tenían una razón creíble para ser enrutables en Internet, y así nació el concepto de red privada. Con el tiempo, esta idea arraigó, y las organizaciones modelaron su seguridad en torno a la protección de la red privada de confianza. Por desgracia, estas redes privadas no están ni de lejos tan aisladas como lo estaban las redes privadas originales. El resultado final es un perímetro muy poroso, que se vulnera con frecuencia en incidentes de seguridad habituales.
Con la comprensión compartida de las redes perimetrales, podemos contrastar ese diseño con el de confianza cero. El modelo de confianza cero gestiona cuidadosamente la confianza en el sistema. Este tipo de redes se apoyan en la automatización para gestionar de forma realista los sistemas de control de seguridad que nos permiten crear un sistema más dinámico y reforzado. Hemos introducido algunos conceptos clave, como la autenticación de usuarios, dispositivos y aplicaciones, y la autorización de la combinación de esos componentes. Trataremos estos conceptos con más detalle a lo largo del resto del libro.
Por último, hablamos de cómo el paso a entornos de nube pública y la omnipresencia de la conectividad a Internet han cambiado fundamentalmente el panorama de las amenazas. Las redes "internas" son ahora cada vez más compartidas y están lo suficientemente abstraídas como para que los usuarios finales no tengan una comprensión tan clara de cuándo sus datos están transitando por enlaces de red de larga distancia más vulnerables. El resultado final de este cambio es que la seguridad de los datos es más importante que nunca a la hora de construir nuevos sistemas. En el próximo capítulo se tratarán los conceptos de alto nivel que hay que comprender para construir sistemas que puedan gestionar la confianza de forma segura.
Get Redes de Confianza Cero, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

