SARSA with FA tries to learn the optimal weights for the approximation models so that the Q values are best estimated. It optimizes the estimation by taking actions chosen under the same policy, as opposed to learning the experience from another policy in Q-learning.
Similarly, after the SARSA model is trained, we just need to use the regression models to predict the state-action values for all possible actions and pick the action with the largest value given a state.
In Step 6, we plot the rewards with pyplot, which will result in the following plot:
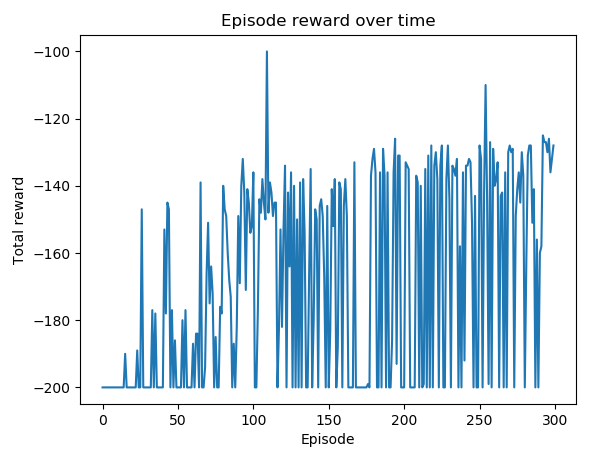
You can see that, in most episodes, after the first 100 episodes, the car ...

