第3章 用朴素贝叶斯检测垃圾邮件
本章从垃圾邮件检测着手来开启机器学习分类之旅。我们结合一个实例来学习分类问题,争取开个好头。邮件服务提供商已经向我们提供了垃圾邮件过滤服务,该服务我们自己也能实现。在本章中,我们将学习分类问题的一些基础却很重要的概念,重点学习用朴素贝叶斯这种简单却很强大的算法检测垃圾邮件。
在本章中,我们将深入讲解以下主题。
- 什么是分类?
- 分类的类型。
- 文本分类实例。
- 朴素贝叶斯。
- 朴素贝叶斯的原理。
- 朴素贝叶斯的实现。
- 用朴素贝叶斯检测垃圾邮件。
- 分类性能评估。
- 交叉检验。
- 调试分类器。
3.1 开始分类之旅
从基本概念讲,垃圾邮件检测就是一种机器学习分类问题。我们先从机器学习分类问题的重要概念讲起。分类是机器学习中有监督学习这一类学习任务的主要代表。给定含有观测数据及其所属类别的训练集,分类的目标是学习一种能够扩展的规则,可以正确地将观测数据(亦称特征)映射到目标类别中。换言之,通过从训练数据的特征和目标类别中学习以生成训练好的模型。分类的过程如图3-1所示。新数据或先前未观测到的数据进来之后,模型能够确定它们的类别。利用训练好的分类模型,再根据输入的特征,可预测样本的类别。
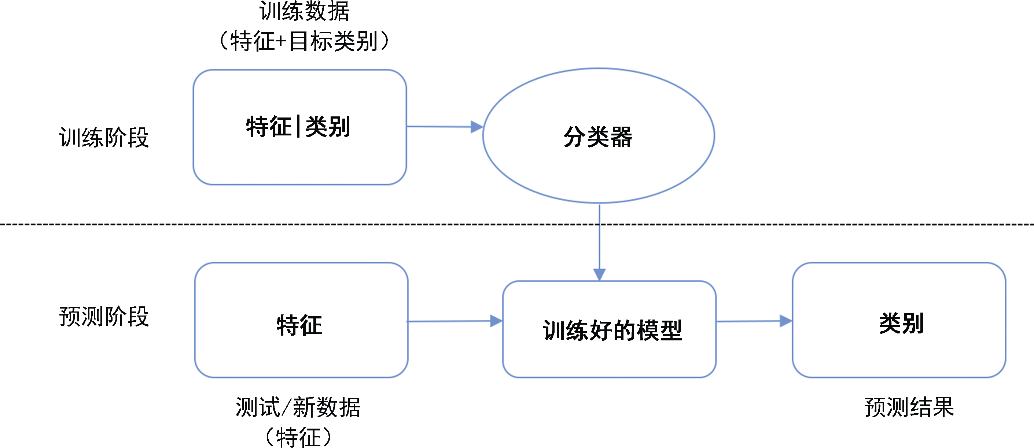
图3-1 分类的主要流程
3.2 分类的类型
根据输出类别的可能性,机器学习分类问题可分为二分类、多分类和多标签分类。
二分类(binary classification)问题是指将观测数据分到两个可能类别之一的问题,如图3-2所示。一个经常提及的例子是,识别邮件信息(输入或观测数据)是否是垃圾邮件(输出或类别),从而过滤垃圾邮件。二分类另一个比较有代表性的应用是客户流失预测,从客户关系管理系统(CRM)得到顾客细分数据和活动数据,识别哪些客户可能会流失。二分类在营销和广告行业的另一个应用是在线广告点击预测——给定用户的cookie信息和浏览器的历史记录,判断他是否会点击某则广告。 ...
Get Python机器学习案例精解 now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

