Capítulo 4. Utilidades útiles de Linux
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
La línea de comandos y sus herramientas fueron una de las principales razones por las que Alfredo se sintió unido a los servidores Linux cuando empezó su carrera. Uno de sus primeros trabajos como administrador de sistemas en una empresa mediana consistió en ocuparse de todo lo relacionado con Linux. El pequeño departamento de informática estaba centrado en los servidores y ordenadores de sobremesa Windows, y les disgustaba profundamente utilizar la línea de comandos. En un momento dado, el director de informática le dijo que entendía de interfaces gráficas de usuario (GUI), instalación de utilidades y herramientas en general para resolver problemas: "No soy un programador, si no existe como GUI, no puedo utilizarlo", dijo.
Alfredo fue contratado para ayudar con los pocos servidores Linux que tenía la empresa. En aquella época, Subversion (SVN) estaba de moda para el control de versiones, y los desarrolladores dependían de este único servidor SVN para impulsar su trabajo. En lugar de utilizar el servidor de identidad centralizado, proporcionado por dos controladores de dominio, utilizaba un sistema de autenticación basado en texto que asignaba un usuario a un hash que representaba la contraseña. Esto significaba que los nombres de usuario no coincidían necesariamente con los del controlador de dominio y que las contraseñas podían ser cualquier cosa. A menudo, un desarrollador pedía restablecer la contraseña, y alguien tenía que editar este archivo de texto con el hash. Un director de proyecto pidió a Alfredo que integrara la autenticación SVN con el controlador de dominio (Active Directory de Microsoft). La primera pregunta que le hizo fue: ¿por qué no lo había hecho ya el departamento informático? "Dicen que no es posible, pero Alfredo, eso es mentira, SVN puede integrarse con Active Directory".
Nunca había utilizado un servicio de autenticación como Active Directory y apenas entendía SVN, pero estaba decidido a hacer que esto funcionara. Alfredo se puso a leer todo sobre SVN y Active Directory, trasteó con una máquina virtual con un servidor SVN en funcionamiento e intentó que esta autenticación funcionara. Tardó unas dos semanas en leer todas las piezas implicadas y conseguir que funcionara. Al final lo consiguió y pudo poner este sistema en producción. Se sintió increíblemente poderoso; había adquirido unos conocimientos únicos y ahora estaba preparado para encargarse por completo de este sistema. El director de informática, así como el resto del departamento, estaban extasiados. Alfredo intentó compartir estos conocimientos recién adquiridos con los demás y siempre se encontró con una excusa: "no hay tiempo " , "demasiado ocupado ", "otras prioridades" y "quizá en otra ocasión, quizá la semana que viene".
Una descripción adecuada para los tecnólogos es: trabajadores del conocimiento. Tu curiosidad y una búsqueda incesante del conocimiento seguirán haciendo de ti, y de los entornos en los que trabajas, algo mucho mejor. No dejes nunca que un compañero de trabajo (o todo un departamento informático, como en el caso de Alfredo) sea un impedimento para mejorar los sistemas. Si hay una oportunidad de aprender algo nuevo, ¡aprovéchala! Lo peor que puede pasar es que hayas adquirido unos conocimientos que quizá no se utilicen a menudo, pero que, por otro lado, podrían cambiar tu carrera profesional.
Linux tiene entornos de escritorio, pero su verdadero poder reside en comprender y utilizar la línea de comandos y, en última instancia, en ampliarla. Cuando no hay herramientas prefabricadas para resolver un problema, los DevOps experimentados crean las suyas propias. Esta noción de ser capaz de idear soluciones juntando las piezas básicas es increíblemente poderosa, y es lo que finalmente ocurrió en ese trabajo en el que se sentía productivo completar tareas sin tener que instalar software estándar para arreglar las cosas.
Este capítulo repasará algunos patrones comunes en el shell e incluirá algunos comandos útiles de Python que deberían mejorar la capacidad de interactuar con una máquina. Nos parece que crear alias y comandos de una sola línea es lo más divertido que se puede hacer en el trabajo, y a veces son tan útiles que acaban siendo plug-ins o piezas de software independientes.
Utilidades de disco
Existen varias utilidades diferentes que puedes utilizar para obtener información sobre los dispositivos de un sistema. Muchas de ellas tienen funciones que se solapan, y algunas tienen una sesión interactiva para tratar las operaciones de disco, como fdisk y parted.
Es crucial dominar las utilidades de disco, no sólo para recuperar información y manipular particiones, sino también para medir con precisión el rendimiento. El rendimiento, en particular, es una de las cosas más difíciles de medir correctamente. La mejor respuesta a la pregunta ¿Cómo mido el rendimiento de un dispositivo? es Depende, porque es difícil hacerlo para la métrica específica que uno busca.
Medir el rendimiento
Si tuviéramos que trabajar en un entorno aislado con un servidor que no tiene acceso a Internet o que no controlamos y, por tanto, no podemos instalar paquetes, tendríamos que decir que la herramienta dd (que debería estar fácilmente disponible en las principales distribuciones de Linux ) ayudaría a dar algunas respuestas. Si es posible, emparéjala con iostat para aislar el comando que martillea el dispositivo frente al que obtiene el informe.
Como dijo una vez un experimentado ingeniero de rendimiento, depende de lo que se mida y cómo. Por ejemplo, dd es monohilo y tiene limitaciones, como no poder hacer múltiples lecturas y escrituras aleatorias; también mide el rendimiento y no las operaciones de entrada/salida por segundo (IOPS). ¿Qué estás midiendo? ¿El rendimiento o las IOPS?
Precaución
Una advertencia sobre estos ejemplos. Pueden destruir tu sistema, no los sigas ciegamente y asegúrate de utilizar dispositivos que puedan borrarse.
Esta sencilla línea de comandos ejecutará dd para obtener algunos números de un dispositivo nuevo(/dev/sdc en este caso):
$ dd if=/dev/zero of=/dev/sdc count=10 bs=100M 10+0 records in 10+0 records out 1048576000 bytes (1.0 GB, 1000 MiB) copied, 1.01127 s, 1.0 GB/s
Escribe 10 registros de 100 megabytes a una velocidad de 1 GB/s. Esto es rendimiento. Una forma fácil de obtener IOPS con dd es utilizar iostat . En este ejemplo, iostat se ejecuta sólo en el dispositivo que está siendo machacado con dd, con la bandera -d sólo para dar información del dispositivo, y con un intervalo de un segundo:
$ iostat -d /dev/sdc 1 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sdc 6813.00 0.00 1498640.00 0 1498640 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sdc 6711.00 0.00 1476420.00 0 1476420
La salida iostat se repetirá cada segundo hasta que se emita un Ctrl-C para cancelar la operación. La segunda columna de la salida es tps, que significa transacciones por segundo y es lo mismo que IOPS. Una forma más agradable de visualizar la salida, que evita el desorden que produce un comando repetitivo, es borrar el terminal en cada ejecución:
$ while true; do clear && iostat -d /dev/sdc && sleep 1; done
Pruebas precisas con fio
Si dd y iostat no son suficientes, la herramienta más utilizada para comprobar el rendimiento es fio . Puede ayudar a aclarar el comportamiento del rendimiento de un dispositivo en un entorno de lectura intensiva o de escritura intensiva (e incluso ajustar los porcentajes de lectura frente a los de escritura).
La salida de fio es bastante verbosa. El ejemplo siguiente la recorta para destacar los IOPS encontrados en las operaciones de lectura y escritura:
$ fio --name=sdc-performance --filename=/dev/sdc --ioengine=libaio \ --iodepth=1 --rw=randrw --bs=32k --direct=0 --size=64m sdc-performance: (g=0): rw=randwrite, bs=(R) 32.0KiB-32.0KiB, (W) 32.0KiB-32.0KiB, (T) 32.0KiB-32.0KiB, ioengine=libaio, iodepth=1 fio-3.1 Starting 1 process sdc-performance: (groupid=0, jobs=1): err= 0: pid=2879: read: IOPS=1753, BW=54.8MiB/s (57.4MB/s)(31.1MiB/567msec) ... iops : min= 1718, max= 1718, avg=1718.00, stdev= 0.00, samples=1 write: IOPS=1858, BW=58.1MiB/s (60.9MB/s)(32.9MiB/567msec) ... iops : min= 1824, max= 1824, avg=1824.00, stdev= 0.00, samples=1
Las banderas utilizadas en el ejemplo nombran el trabajo sdc-performance, apuntan al dispositivo /dev/sdc directamente (requerirá permisos de superusuario), utilizan la biblioteca de E/S asíncrona nativa de Linux, establecen el iodepth en 1 (número de peticiones de E/S secuenciales que se enviarán a la vez), y definen operaciones de lectura y escritura aleatorias de 32 kilobytes para el tamaño del búfer utilizando E/S con búfer (se puede establecer en 1 para utilizar E/S sin búfer) en un archivo de 64 megabytes. ¡Un comando bastante largo!
La herramienta fio tiene un enorme número de opciones adicionales que pueden ayudar en casi cualquier caso en el que se necesiten mediciones precisas de IOPS. Por ejemplo, puede extender la prueba a muchos dispositivos a la vez, realizar un calentamiento de E/S e incluso establecer umbrales de E/S para la prueba si no se debe superar un límite definido. Por último, las numerosas opciones de la línea de comandos se pueden configurar con archivos de tipo INI, de modo que la ejecución de los trabajos se puede guionizar muy bien.
Particiones
Solemos utilizar por defecto fdisk con su sesión interactiva para crear particiones, pero en algunos casos, fdisk no funciona bien, como con particiones grandes (de dos terabytes o más). En esos casos, tu alternativa debería ser utilizar parted.
Una rápida sesión interactiva muestra cómo crear una partición primaria con fdisk, con el valor de inicio por defecto y cuatro gibibytes de tamaño. Al final se envía la clave w para escribir los cambios:
$ sudo fdisk /dev/sds
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-22527999, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-22527999, default 22527999): +4G
Partition 1 of type Linux and of size 4 GiB is set
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
parted consigue lo mismo, pero con una interfaz diferente:
$ sudo parted /dev/sdaa GNU Parted 3.1 Using /dev/sdaa Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) mklabel New disk label type? gpt (parted) mkpart Partition name? []? File system type? [ext2]? Start? 0 End? 40%
Al final, sales con la tecla q. Para la creación programática de particiones en la línea de comandos sin ninguna petición interactiva, obtienes el mismo resultado con un par de comandos:
$ parted --script /dev/sdaa mklabel gpt $ parted --script /dev/sdaa mkpart primary 1 40% $ parted --script /dev/sdaa print Disk /dev/sdaa: 11.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 4614MB 4613MB
Recuperar información específica del dispositivo
A veces, cuando se necesita información específica de un dispositivo, son adecuados lsblk o blkid. A fdisk no le gusta trabajar sin permisos de superusuario. Aquí fdisk lista la información sobre el dispositivo /dev/sda:
$ fdisk -l /dev/sda fdisk: cannot open /dev/sda: Permission denied $ sudo fdisk -l /dev/sda Disk /dev/sda: 42.9 GB, 42949672960 bytes, 83886080 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x0009d9ce Device Boot Start End Blocks Id System /dev/sda1 * 2048 83886079 41942016 83 Linux
blkid es un poco similar en el sentido de que también quiere permisos de superusuario:
$ blkid /dev/sda $ sudo blkid /dev/sda /dev/sda: PTTYPE="dos"
lsblk permite obtener información sin permisos superiores, y proporciona la misma salida informativa a pesar de ello:
$ lsblk /dev/sda NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 40G 0 disk └─sda1 8:1 0 40G 0 part / $ sudo lsblk /dev/sda NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 40G 0 disk └─sda1 8:1 0 40G 0 part /
Este comando, que utiliza la bandera -p para sondear dispositivos a bajo nivel, es muy completo y debería darte información suficiente sobre un dispositivo:
$ blkid -p /dev/sda1 UUID="8e4622c4-1066-4ea8-ab6c-9a19f626755c" TYPE="xfs" USAGE="filesystem" PART_ENTRY_SCHEME="dos" PART_ENTRY_TYPE="0x83" PART_ENTRY_FLAGS="0x80" PART_ENTRY_NUMBER="1" PART_ENTRY_OFFSET="2048" PART_ENTRY_SIZE="83884032"
lsblk tiene algunas propiedades predeterminadas que debes buscar:
$ lsblk -P /dev/nvme0n1p1 NAME="nvme0n1p1" MAJ:MIN="259:1" RM="0" SIZE="512M" RO="0" TYPE="part"
Pero también te permite establecer banderas específicas para solicitar una propiedad concreta:
lsblk -P -o SIZE /dev/nvme0n1p1 SIZE="512M"
Acceder a una propiedad de este modo facilita la escritura e incluso el consumo desde el lado Python.
Utilidades de red
Las herramientas de red siguen mejorando a medida que aumenta la necesidad de interconectar servidores. Muchas de las utilidades de esta sección cubren aspectos útiles de una sola línea, como la creación de túneles Secure Shell (SSH), pero otras entran en los detalles de la comprobación del rendimiento de la red, como el uso de la herramienta Apache Bench.
Túnel SSH
¿Has intentado alguna vez acceder a un servicio HTTP que se ejecuta en un servidor remoto al que no se puede acceder salvo por SSH? Esta situación se produce cuando el servicio HTTP está habilitado pero no se necesita públicamente. La última vez que vimos que esto ocurría fue cuando una instancia de producción de RabbitMQ tenía activado el complemento de gestión, que inicia un servicio HTTP en el puerto 15672. El servicio no está expuesto y con razón; no hay necesidad de tenerlo disponible públicamente ya que raramente se utiliza, y además, se pueden utilizar las capacidades de túnel de SSH.
Esto funciona creando una conexión SSH con el servidor remoto y luego reenviando el puerto remoto (15672, en mi caso) a un puerto local en la máquina de origen. La máquina remota tiene un puerto SSH personalizado, lo que complica ligeramente el comando. Esto es lo que parece:
$ ssh -L 9998:localhost:15672 -p 2223 adeza@prod1.rabbitmq.ceph.internal -N
Hay tres banderas, tres números y dos direcciones. Vamos a diseccionar el comando para que quede mucho más claro lo que está pasando aquí. La bandera -L es la que indica que queremos que se active el reenvío y que se vincule un puerto local (9998) a un puerto remoto (el predeterminado de RabbitMQ es 15672). A continuación, la bandera -p indica que el puerto SSH personalizado del servidor remoto es 2223, y después se especifican el nombre de usuario y la dirección. Por último, el -N significa que no debe llevarnos a un shell remoto y hacer el reenvío.
Cuando se ejecuta correctamente, el comando parecerá colgarse, pero te permite entrar en http://localhost:9998/ y ver la página de inicio de sesión de la instancia remota de RabbitMQ. Una bandera útil para saber cuando se hace un túnel es -f: enviará el proceso a segundo plano, lo que es útil si esta conexión no es temporal, dejando el terminal listo y limpio para hacer más trabajo.
Benchmarking HTTP con Apache Benchmark (ab)
Nos encanta martillear los servidores con los que trabajamos para asegurarnos de que gestionan la carga correctamente, sobre todo antes de pasarlos a producción. A veces incluso intentamos provocar alguna extraña condición de carrera que pueda producirse bajo una carga pesada. La herramienta Apache Benchmark (ab en la línea de comandos) es una de esas pequeñas herramientas que pueden ponerte en marcha rápidamente con sólo unas pocas banderas.
Este comando creará 100 peticiones cada vez, para un total de 10.000 peticiones, a una instancia local donde se esté ejecutando Nginx:
$ ab -c 100 -n 10000 http://localhost/
Eso es bastante brutal de manejar en un sistema, pero éste es un servidor local, y las solicitudes son sólo un HTTP GET. La salida detallada de ab es muy completa y tiene este aspecto (recortado por brevedad):
Benchmarking localhost (be patient)
...
Completed 10000 requests
Finished 10000 requests
Server Software: nginx/1.15.9
Server Hostname: localhost
Server Port: 80
Document Path: /
Document Length: 612 bytes
Concurrency Level: 100
Time taken for tests: 0.624 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 8540000 bytes
HTML transferred: 6120000 bytes
Requests per second: 16015.37 [#/sec] (mean)
Time per request: 6.244 [ms] (mean)
Time per request: 0.062 [ms] (mean, across all concurrent requests)
Transfer rate: 13356.57 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 3 0.6 3 5
Processing: 0 4 0.8 3 8
Waiting: 0 3 0.8 3 6
Total: 0 6 1.0 6 9
Este tipo de información y cómo se presenta es tremendo. De un vistazo, puedes saber rápidamente si un servidor de producción pierde conexiones (en el campo Failed requests ) y cuáles son los promedios. Se utiliza una petición GET, pero ab te permite utilizar otros verbos HTTP, como POST, e incluso hacer una petición HEAD. Debes tener cuidado con este tipo de herramienta porque puede sobrecargar fácilmente un servidor. A continuación se muestran cifras más realistas de un servicio HTTP en producción (recortadas por brevedad):
... Benchmarking prod1.ceph.internal (be patient) Server Software: nginx Server Hostname: prod1.ceph.internal Server Port: 443 SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256 Server Temp Key: ECDH P-256 256 bits TLS Server Name: prod1.ceph.internal Complete requests: 200 Failed requests: 0 Total transferred: 212600 bytes HTML transferred: 175000 bytes Requests per second: 83.94 [#/sec] (mean) Time per request: 1191.324 [ms] (mean) Time per request: 11.913 [ms] (mean, across all concurrent requests) Transfer rate: 87.14 [Kbytes/sec] received ....
Ahora los números parecen diferentes, accede a un servicio con SSL activado, y ab enumera cuáles son los protocolos. Con 83 peticiones por segundo, creemos que podría hacerlo mejor, pero se trata de un servidor API que produce JSON, y normalmente no recibe mucha carga de golpe, como se acaba de generar.
Pruebas de carga con molotov
El proyecto Molotov es un interesante proyecto orientado a las pruebas de carga. Algunas de sus características son similares a las de Apache Benchmark, pero al ser un proyecto Python, proporciona una forma de escribir escenarios con Python y el módulo asyncio.
Así es como queda el ejemplo más sencillo de molotov:
importmolotov@molotov.scenario(100)asyncdefscenario_one(session):asyncwithsession.get("http://localhost:5000")asresp:assertresp.status==200
Guarda el archivo como load_test.py, crea una pequeña aplicación Flask que gestione las peticiones POST y GET en su URL principal, y guárdala como small.py:
fromflaskimportFlask,redirect,requestapp=Flask('basic app')@app.route('/',methods=['GET','POST'])defindex():ifrequest.method=='POST':redirect('https://www.google.com/search?q=%s'%request.args['q'])else:return'<h1>GET request from Flask!</h1>'
Inicia la aplicación Flask con FLASK_APP=small.py flask run, y luego ejecuta molotov con el archivo load_test.py creado anteriormente:
$ molotov -v -r 100 load_test.py **** Molotov v1.6. Happy breaking! **** Preparing 1 worker... OK SUCCESSES: 100 | FAILURES: 0 WORKERS: 0 *** Bye ***
Cien peticiones en un único trabajador se ejecutaron contra la instancia local de Flask. La herramienta brilla realmente cuando las pruebas de carga se amplían para hacer más cosas por solicitud. Tiene conceptos similares a las pruebas unitarias, como configuración, desmontaje e incluso código, que puede reaccionar ante determinados eventos. Puesto que la pequeña aplicación Flask puede manejar un POST que redirige a una búsqueda de Google, añade otro escenario al archivo load_test.py_. Esta vez cambia el peso para que el 100% de las peticiones hagan un POST:
@molotov.scenario(100)asyncdefscenario_post(session):resp=awaitsession.post("http://localhost:5000",params={'q':'devops'})redirect_status=resp.history[0].statuserror="unexpected redirect status:%s"%redirect_statusassertredirect_status==301,error
Ejecuta este nuevo escenario para una única solicitud para mostrar lo siguiente:
$ molotov -v -r 1 --processes 1 load_test.py
**** Molotov v1.6. Happy breaking! ****
Preparing 1 worker...
OK
AssertionError('unexpected redirect status: 302',)
File ".venv/lib/python3.6/site-packages/molotov/worker.py", line 206, in step
**scenario['kw'])
File "load_test.py", line 12, in scenario_two
assert redirect_status == 301, error
SUCCESSES: 0 | FAILURES: 1
*** Bye ***
Una sola petición (con -r 1) era suficiente para que esto fallara. Hay que actualizar la aserción para que compruebe si hay un 302 en lugar de un 301. Una vez actualizado ese estado, cambia el peso del escenario POST a 80 para que se envíen otras peticiones (con un GET) a la aplicación Flask. Este es el aspecto final del archivo:
importmolotov@molotov.scenario()asyncdefscenario_one(session):asyncwithsession.get("http://localhost:5000/")asresp:assertresp.status==200@molotov.scenario(80)asyncdefscenario_two(session):resp=awaitsession.post("http://localhost:5000",params={'q':'devops'})redirect_status=resp.history[0].statuserror="unexpected redirect status:%s"%redirect_statusassertredirect_status==301,error
Ejecuta load_test.py para 10 peticiones para distribuir las peticiones, dos para un GET y el resto con un POST:
127.0.0.1 - - [04/Sep/2019 12:10:54] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:10:56] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:10:57] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:10:58] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [04/Sep/2019 12:10:58] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:10:59] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:11:00] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:11:01] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [04/Sep/2019 12:11:01] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:11:02] "POST /?q=devops HTTP/1.1" 302 -
Como puedes ver, molotov es fácilmente extensible con Python puro y puede modificarse para adaptarse a otras necesidades más complejas. Estos ejemplos arañan la superficie de lo que la herramienta puede hacer .
Utilidades de la CPU
Hay dos utilidades importantes para la CPU: top y htop. Hoy en día puedes encontrar top preinstalada en la mayoría de las distribuciones de Linux, pero si puedes instalar paquetes, es fantástico trabajar con htop y preferimos su interfaz personalizable a top. Existen algunas otras herramientas que proporcionan visualización de la CPU y quizás incluso monitoreo, pero ninguna es tan completa y está tan ampliamente disponible como top y htop. Por ejemplo, es totalmente posible obtener la utilización de la CPU a partir del comando ps:
$ ps -eo pcpu,pid,user,args | sort -r | head -10 %CPU PID USER COMMAND 0.3 719 vagrant -bash 0.1 718 vagrant sshd: vagrant@pts/0 0.1 668 vagrant /lib/systemd/systemd --user 0.0 9 root [rcu_bh] 0.0 95 root [ipv6_addrconf] 0.0 91 root [kworker/u4:3] 0.0 8 root [rcu_sched] 0.0 89 root [scsi_tmf_1]
El comando ps toma algunos campos personalizados. El primero es pcpu, que da el uso de CPU, seguido del ID del proceso, el usuario y, por último, el comando. Eso se canaliza en orden inverso, porque por defecto va de menor a mayor uso de CPU, y necesitas tener el mayor uso de CPU en la parte superior. Por último, como el comando muestra esta información para cada proceso, filtra los 10 primeros resultados con el comando head .
Pero el comando es bastante farragoso, es difícil de recordar y no se actualiza sobre la marcha. Aunque sea un alias, es mejor que utilices top o htop. Como verás, ambos tienen amplias funciones.
Ver procesos con htop
La herramienta htop es igual que top (un visor de procesos interactivo), pero es totalmente multiplataforma (funciona en OS X, FreeBSD, OpenBSD y Linux), ofrece soporte para mejores visualizaciones (ver Figura 4-1) y es un placer utilizarla. Visita https://hisham.hm/htop para ver una captura de pantalla de htop ejecutándose en un servidor. Una de las principales advertencias de htop es que todos los atajos que puedas conocer de top no son compatibles, por lo que tendrás que volver a cablear tu cerebro para entenderlos y utilizarlos en htop.
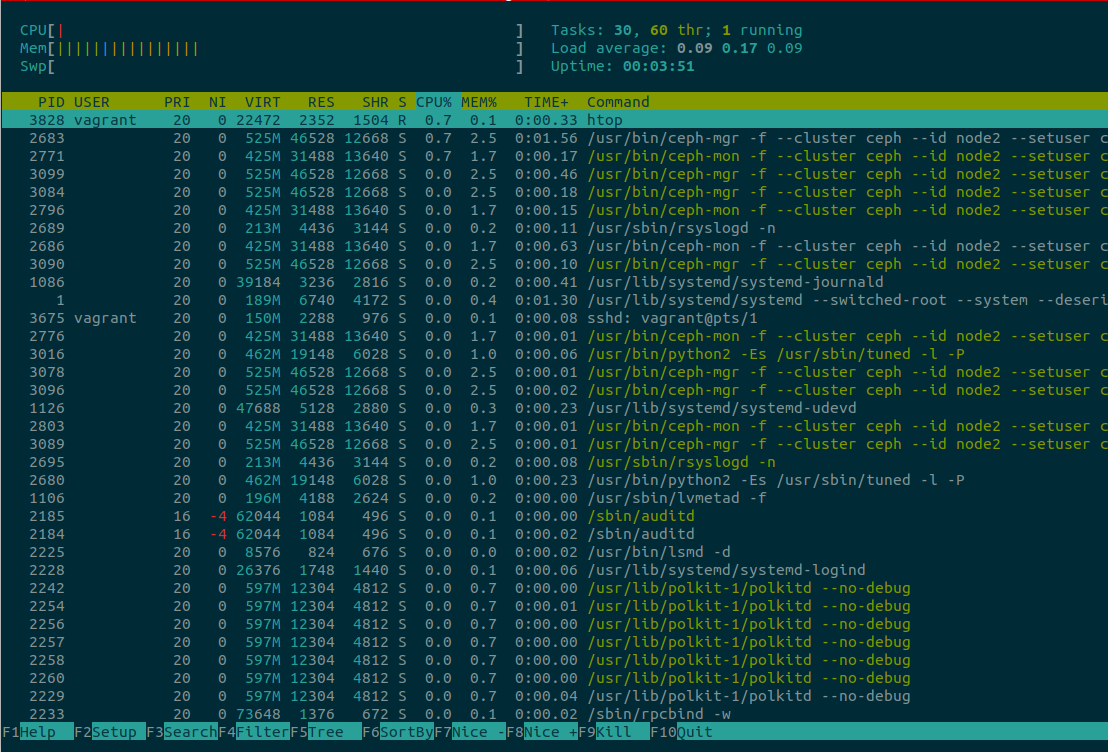
Figura 4-1. htop ejecutándose en un servidor
De inmediato, el aspecto de la información mostrada en la Figura 4-1 es diferente. La CPU, la Memoria y el Swap se muestran muy bien en la parte superior izquierda, y se mueven a medida que cambia el sistema. Las teclas de flecha se desplazan hacia arriba o hacia abajo e incluso de izquierda a derecha, proporcionando una visión de todo el comando del proceso.
¿Quieres matar un proceso? Muévete hasta él con las teclas de flecha, o pulsa / para buscar (y filtrar) el proceso de forma incremental, y luego pulsa k. Un nuevo menú mostrará todas las señales que se pueden enviar al proceso -por ejemplo, SIGTERM en lugar de SIGKILL. Es posible "etiquetar" más de un proceso para matarlo. Pulsa la barra espaciadora para etiquetar el proceso seleccionado , resaltándolo con un color diferente. ¿Te has equivocado y quieres quitar la etiqueta? Vuelve a pulsar la barra espaciadora. Todo esto resulta muy intuitivo.
Un problema de htop es que tiene muchas acciones asignadas a las teclas F, y puede que tú no tengas ninguna. Por ejemplo, F1 es para ayuda. La alternativa es utilizar las asignaciones equivalentes siempre que sea posible. Para acceder al menú de ayuda, utiliza la tecla h; para acceder a la configuración, utiliza Shift s en lugar de F2.
El t (de nuevo, ¡qué intuitivo!) habilita (activa) la lista de procesos como un árbol. Probablemente la funcionalidad más utilizada es la ordenación. Pulsa > y aparecerá un menú para seleccionar qué tipo de ordenación quieres: PID, usuario, memoria, prioridad y porcentaje de CPU son sólo algunos. También hay atajos para ordenar directamente (se salta la selección del menú) por memoria (Shift i), CPU (Shift p) y Tiempo (Shift t).
Por último, dos características increíbles: puedes ejecutar strace o lsof directamente en el proceso seleccionado, siempre que estén instalados y disponibles para el usuario. Si los procesos requieren permisos de superusuario, htop informará de ello, y requerirá que sudo se ejecute como usuario privilegiado. Para ejecutar strace en un proceso seleccionado, utiliza la tecla s; para lsof, utiliza la tecla l.
Si se utiliza strace o lsof, las opciones de búsqueda y filtro están disponibles con el carácter /. ¡Qué herramienta tan increíblemente útil! Esperemos que algún día sean posibles otras correspondencias de teclas que no seanF, aunque la mayor parte del trabajo puede hacerse con las correspondencias alternativas .
Consejo
Si se personaliza htop a través de su sesión interactiva, los cambios se guardan en un archivo de configuración que normalmente se encuentra en ~/.config/htop/htoprc. Si defines configuraciones allí y más tarde las cambias en la sesión, ésta sobrescribirá lo que se haya definido previamente en el archivo htoprc.
Trabajar con Bash y ZSH
Todo empieza con la personalización. Tanto Bash como ZSH suelen venir con un "dotfile", un archivo prefijado con un punto que contiene la configuración, pero que por defecto está oculto cuando se lista el contenido de los directorios, y vive en el directorio personal del usuario. Para Bash es .bashrc, y para ZSH es .zshrc. Ambos shells admiten varias capas de lugares que se cargarán en un orden predefinido, que termina en el archivo de configuración para el usuario.
Cuando se instala ZSH, normalmente no se crea un .zshrc. Así es como se ve una versión mínima en una distro CentOS (se han eliminado todos los comentarios por brevedad):
$ cat /etc/skel/.zshrc
autoload -U compinit
compinit
setopt COMPLETE_IN_WORDBash contiene un par de elementos adicionales, pero nada sorprendente. Sin duda llegarás al punto de sentirte extremadamente molesto por algún comportamiento o cosa que hayas visto en algún otro servidor y que quieras replicar. No podemos vivir sin colores en el terminal, así que sea cual sea el shell, tiene que tener activado el color. Antes de que te des cuenta, estás metido de lleno en configuraciones y quieres añadir un montón de alias y funciones útiles.
Poco después, llegan las configuraciones de los editores de texto, y todo resulta inmanejable en máquinas diferentes o cuando se añaden otras nuevas y no se configuran todos esos útiles alias, y es increíble, pero nadie ha habilitado el soporte de color en ningún sitio. Todo el mundo tiene una forma de resolver este problema de forma totalmente intransferible y ad hoc: Alfredo utiliza un Makefile en algún momento, y sus compañeros de trabajo no utilizan nada en absoluto o utilizan un script Bash. Un nuevo proyecto llamado Dotdrop tiene un montón de funciones para poner en orden todos esos dotfiles, con funciones como copiar, enlazar simbólicamente y mantener perfiles separados para las máquinas de desarrollo y las demás, algo muy útil cuando te mudas de una máquina a otra.
Puedes utilizar Dotdrop para un proyecto Python, y aunque puedes instalarlo mediante las herramientas habituales virtualenv y pip, se recomienda incluirlo como submódulo en tu repositorio de dotfiles. Si aún no lo has hecho, es muy conveniente mantener todos tus dotfiles en control de versiones para hacer un seguimiento de los cambios. Los dotfiles de Alfredo están a disposición del público, y él intenta mantenerlos lo más actualizados posible.
Independientemente de lo que se utilice, hacer un seguimiento de los cambios mediante el control de versiones, y asegurarse de que todo está siempre actualizado, es una buena estrategia.
Personalizar el shell de Python
Puedes personalizar el shell de Python con ayudantes e importar módulos útiles en un archivo Python que luego hay que exportar como variable de entorno. Yo guardo mis archivos de configuración en un repositorio llamado dotfiles, así que en mi archivo de configuración del shell($HOME/.zshrc para mí) defino la siguiente exportación:
exportPYTHONSTARTUP=$HOME/dotfiles/pythonstartup.py
Para probarlo, crea un nuevo archivo Python llamado pythonstartup.py (aunque puede llamarse como quieras) que tenga este aspecto:
import typesimport uuidhelpers = types.ModuleType('helpers')helpers.uuid4 = uuid.uuid4()
Ahora abre un nuevo intérprete de comandos Python y especifica el recién creado pythonstartup.py:
$ PYTHONSTARTUP=pythonstartup.py python
Python 3.7.3 (default, Apr 3 2019, 06:39:12)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> helpers
<module 'helpers'>
>>> helpers.uuid4()
UUID('966d7dbe-7835-4ac7-bbbf-06bf33db5302')
El objeto helpers está disponible inmediatamente. Como hemos añadido la propiedad uuid4, podemos acceder a él como helpers.uuid4() . Como puedes deducir, todas las importaciones y definiciones van a estar disponibles en el shell de Python. Esta es una forma cómoda de ampliar el comportamiento que puede ser útil con el shell por defecto.
Globbing recursivo
El globbing recursivo está activado en ZSH por defecto, pero Bash (versiones 4 y superiores) requiere shopt para configurarlo. El globbing recursivo es una configuración genial que te permite recorrer una ruta con la siguiente sintaxis:
$ ls **/*.py
Ese fragmento recorrería cada archivo y directorio recursivamente y listaría cada archivo que terminara en .py. Así es como se activa en Bash 4:
$ shopt -s globstar
Buscar y sustituir con preguntas de confirmación
Vim tiene una buena función en su motor de búsqueda y reemplazo que pide confirmación para realizar el reemplazo u omitirlo. Esto es especialmente útil cuando no das con la expresión regular exacta que coincide con lo que necesitas, pero quieres ignorar otras coincidencias cercanas. Conocemos las expresiones regulares, pero hemos intentado evitar ser expertos en ellas porque sería muy tentador utilizarlas para todo. La mayoría de las veces, querrás realizar una simple búsqueda y sustitución y no darte cabezazos contra la pared para dar con la expresión regular perfecta.
Es necesario añadir la bandera c al final de la orden para activar el mensaje de confirmación en Vim:
:%s/original term/replacement term/gc
Lo anterior se traduce en: busca el término original en todo el archivo y sustitúyelo por el término de sustitución, pero en cada instancia, avisa para que uno pueda decidir cambiarlo u omitirlo. Si se encuentra una coincidencia, Vim mostrará un mensaje como éste:
replace with replacement term (y/n/a/q/l/^E/^Y)?
Todo el flujo de trabajo de confirmación puede parecer una tontería, pero te permite relajar las restricciones de la expresión regular, o incluso no utilizar ninguna para una coincidencia y sustitución más sencillas. Un ejemplo rápido de esto es un cambio reciente de la API en una herramienta de producción que cambió el atributo de un objeto para una llamada. El código devolvía True o False para informar de si se requerían permisos de superusuario o no. El reemplazo real en un único archivo tendría este aspecto:
:%s/needs_root/needs_root()/gc
La dificultad añadida aquí es que needs_root también estaba salpicado en comentarios y cadenas doc, por lo que no era fácil idear una expresión regular que permitiera saltarse el reemplazo cuando estuviera dentro de un bloque de comentarios o en parte de una cadena doc. Con la bandera c, basta con pulsar Y o N y seguir adelante. ¡No necesitas ninguna expresión regular!
Con el globbing recursivo activado (shopt -s globstar en Bash 4), este potente one-liner recorrerá todos los archivos coincidentes, realizará la búsqueda y sustituirá el elemento según las indicaciones si el patrón se encuentra dentro de los archivos:
vim -c "bufdo! set eventignore-=Syntax | %s/needs_root/needs_root()/gce" **/*.py
Hay mucho que desentrañar aquí, pero el ejemplo anterior recorrerá recursivamente para encontrar todos los archivos que terminen en .py, los cargará en Vim, y realizará la búsqueda y sustitución con confirmación sólo si hay una coincidencia. Si no hay ninguna coincidencia, omite el archivo. Se utiliza set eventignore-=Syntax porque, de lo contrario, Vim no cargará los archivos de sintaxis al ejecutarlo de esta forma; nos gusta el resaltado de sintaxis y esperamos que funcione cuando se utiliza este tipo de sustitución. La siguiente parte después del carácter | es la sustitución con la bandera de confirmación y la bandera e, que ayuda a ignorar cualquier error que impida que un flujo de trabajo fluido se vea interrumpido por errores.
Consejo
Hay muchas otras banderas y variaciones que puedes utilizar para mejorar el comando de reemplazo. Para saber más sobre las banderas especiales de búsqueda y sustitución en Vim, echa un vistazo a :help substitute, concretamente a la sección s_flags.
Haz que la complicada línea única sea más fácil de recordar con una función que tome dos parámetros (términos de búsqueda y sustitución) y la ruta:
vsed(){search=$1replace=$2shiftshiftvim -c"bufdo! set eventignore-=Syntax| %s/$search/$replace/gce"$*}
Nómbralo vsed, como una mezcla de Vim y la herramienta sed, para que sea más fácil de recordar. En el terminal, tiene un aspecto sencillo y te permite realizar cambios en varios archivos fácilmente y con confianza, ya que puedes aceptar o rechazar cada sustitución:
$ vsed needs_root needs_root() **/*.py
Eliminar archivos temporales de Python
El sitio web de Python pyc, y más recientemente sus pycache a veces se interponen en tu camino. Este sencillo comando de una sola línea con el alias pyclean utiliza el comando find para eliminar pyc, y luego sigue buscando pycache y los elimina recursivamente con la bandera de borrado integrada en la herramienta:
aliaspyclean='find . \\( -type f -name "*.py[co]" -o -type d -name "__pycache__" \) -delete &&echo "Removed pycs and __pycache__"'
Procesos de listado y filtrado
Listar procesos para ver lo que se ejecuta en una máquina y luego filtrar para comprobar una aplicación concreta es una de las cosas que harás varias veces al día, como mínimo. No es en absoluto sorprendente que todo el mundo tenga una variación en las banderas o en el orden de las banderas para la herramienta ps (nosotros solemos utilizar aux). Es algo que acabas haciendo tantas veces al día que el orden y las banderas se arraigan en tu cerebro y es difícil hacerlo de otra manera.
Como buen punto de partida para listar los procesos y alguna información, como los ID de los procesos, prueba esto:
$ ps auxw
Este comando enumera todos los procesos con las banderas estilo BSD (banderas que no van prefijadas con un guión -) independientemente de si tienen o no un terminal (tty), e incluye el usuario propietario del proceso. Por último, da más espacio a la salida (banderaw ).
La mayoría de las veces, filtras con grep para obtener información sobre un proceso concreto. Por ejemplo, si quieres comprobar si Nginx se está ejecutando, canalizas la salida en grep y pasas nginx como argumento:
$ ps auxw | grep nginx root 29640 1536 ? Ss 10:11 0:00 nginx: master process www-data 29648 5440 ? S 10:11 0:00 nginx: worker process alfredo 30024 924 pts/14 S+ 10:12 0:00 grep nginx
Eso está muy bien, pero es molesto que se incluya el comando grep. Esto es especialmente molesto cuando no hay más resultados que el grep:
$ ps auxw | grep apache alfredo 31351 0.0 0.0 8856 912 pts/13 S+ 10:15 0:00 grep apache
No se encuentra ningún proceso apache, pero el aspecto visual puede inducirte a pensar que sí, y comprobar dos veces que, efectivamente, sólo se incluye grep debido al argumento puede cansar bastante rápido. Una forma de solucionarlo es añadir otra tubería a grep para que se filtre a sí mismo de la salida:
$ ps auxw | grep apache | grep -v grep
Tener que acordarse siempre de añadir ese grep extra puede ser igual de molesto, así que un alias viene al rescate:
alias pg='ps aux | grep -v grep | grep $1'
El nuevo alias filtrará la primera línea grep y dejará sólo la salida interesante (si la hay):
$ pg vim alfredo 31585 77836 20624 pts/3 S+ 18:39 0:00 vim /home/alfredo/.zshrc
Marca de tiempo Unix
Obtener en Python la tan utilizada marca de tiempo de Unix es muy fácil:
In [1]: import timeIn [2]: int(time.time())Out[2]: 1566168361
Pero en el shell, puede ser un poco más complicado. Este alias funciona en OS X, que tiene la versión con sabor BSD de la herramienta date:
alias timestamp='date -j -f "%a %b %d %T %Z %Y" "`date`" "+%s"'
OS X puede ser torpe con sus herramientas, y puede resultar confuso no recordar nunca por qué una determinada utilidad (como date en este caso) se comporta de forma completamente diferente. En la versión Linux de date, funciona de la misma manera un enfoque mucho más sencillo:
alias timestamp='date "+%s"'
Mezclar Python con Bash y ZSH
Nunca se nos ocurrió intentar mezclar Python con una shell, como ZSH o Bash. Parece ir en contra del sentido común, pero hay algunos buenos casos que puedes utilizar casi a diario. En general, nuestra regla general es que 10 líneas de script de shell es el límite; todo lo que vaya más allá es un error a la espera de hacerte perder el tiempo porque el informe de errores no está ahí para ayudarte.
Generador de contraseñas aleatorias
La cantidad de cuentas y contraseñas que necesitas cada semana no va a hacer más que aumentar, incluso para cuentas desechables para las que puedes utilizar Python para generar contraseñas robustas. Crea un generador de contraseñas útil y aleatorio que envíe el contenido al portapapeles para pegarlo fácilmente:
In[1]:importosIn[2]:importbase64In[3]:(base64.b64encode(os.urandom(64)).decode('utf-8'))gHHlGXnqnbsALbAZrGaw+LmvipTeFi3tA/9uBltNf9g2S9qTQ8hTpBYrXStp+i/o5TseeVo6wcX2A==
Portar eso a una función shell que pueda tomar una longitud arbitraria (útil cuando un sitio restringe la longitud a un número determinado) se parece a esto:
mpass(){if[$1];thenlength=$1elselength=12fi_hash=`python3 -c"import os,base64exec('print(base64.b64encode(os.urandom(64))[:${length}].decode(\'utf-8\'))')"`echo$_hash|xclip -selection clipboardecho"new password copied to the system clipboard"}
Ahora la función mpass genera por defecto contraseñas de 12 caracteres troceando la salida, y luego envía el contenido de la cadena generada a xclip para que se copie en el portapapeles y puedas pegarla fácilmente.
Nota
xclip no está instalado por defecto en muchas distribuciones, por lo que debes asegurarte de que está instalado para que la función funcione correctamente. Si xclip no está disponible, cualquier otra utilidad que pueda ayudar a gestionar el portapapeles del sistema funcionará bien.
¿Existe mi módulo?
Averigua si existe un módulo y, en caso afirmativo, obtén la ruta a ese módulo. Esto es útil cuando se reutiliza para otras funciones que pueden tomar esa salida para procesarla:
try(){python -c"exec('''try:import${1}as _print(_.__file__)except Exception as e:print(e)''')"}
Cambiar directorios a la ruta de un módulo
"¿Dónde vive este módulo?" es una pregunta frecuente cuando se depuran bibliotecas y dependencias, o incluso cuando se husmea en el código fuente de los módulos. La forma que tiene Python de instalar y distribuir módulos no es sencilla, y en las distintas distribuciones de Linux las rutas son totalmente diferentes y tienen convenciones distintas. Puedes averiguar la ruta de un módulo si lo importas y luego utilizas print:
In[1]:importosIn[2]:(os)<module'os'from'.virtualenvs/python-devops/lib/python3.6/os.py'>
No es conveniente si lo único que quieres es la ruta para poder cambiar de directorio a ella y mirar el módulo. Esta función intentará importar el módulo como argumento, imprimirlo (esto es shell, así que return no hace nada por nosotros), y luego cambiar de directorio hasta él:
cdp(){MODULE_DIRECTORY=`python -c"exec('''try:import os.path as _,${module}print(_.dirname(_.realpath(${module}.__file__)))except Exception as e:print(e)''')"`if[[-d$MODULE_DIRECTORY]];thencd$MODULE_DIRECTORYelseecho"Module${1}not found or is not importable:$MODULE_DIRECTORY"fi}
Hagámoslo más robusto, en caso de que el nombre del paquete tenga un guión y el módulo utilice un guión bajo, añadiendo:
module=$(sed's/-/_/g'<<<$1)
Si la entrada tiene un guión, la pequeña función puede resolverlo sobre la marcha y llevarnos a donde necesitamos:
$ cdp pkg-resources $ pwd /usr/lib/python2.7/dist-packages/pkg_resources
Convertir un archivo CSV a JSON
Python viene con algunas funciones integradas que son sorprendentes si nunca has tratado con ellas. Puede manejar JSON de forma nativa, así como archivos CSV. Bastan un par de líneas para cargar un archivo CSV y "volcar" su contenido como JSON. Utiliza el siguiente archivo CSV(direcciones.csv) para ver el contenido cuando se vuelca JSON en el shell de Python:
John,Doe,120 Main St.,Riverside, NJ, 08075 Jack,Jhonson,220 St. Vernardeen Av.,Phila, PA,09119 John,Howards,120 Monroe St.,Riverside, NJ,08075 Alfred, Reynolds, 271 Terrell Trace Dr., Marietta, GA, 30068 Jim, Harrison, 100 Sandy Plains Plc., Houston, TX, 77005
>>>importcsv>>>importjson>>>contents=open("addresses.csv").readlines()>>>json.dumps(list(csv.reader(contents)))'[["John", "Doe", "120 Main St.", "Riverside", " NJ", " 08075"],["Jack","Jhonson","220 St. Vernardeen Av.","Phila"," PA","09119"],["John","Howards","120 Monroe St.","Riverside"," NJ","08075"],["Alfred"," Reynolds"," 271 Terrell Trace Dr."," Marietta"," GA"," 30068"],["Jim"," Harrison"," 100 Sandy Plains Plc."," Houston"," TX"," 77005"]]'
Transporta la sesión interactiva a una función que pueda hacer esto en la línea de comandos:
csv2json(){python3 -c"exec('''import csv,jsonprint(json.dumps(list(csv.reader(open(\'${1}\')))))''')"}
Utilízalo en el shell, que es mucho más sencillo que recordar todas las llamadas y módulos:
$ csv2json addresses.csv [["John", "Doe", "120 Main St.", "Riverside", " NJ", " 08075"], ["Jack", "Jhonson", "220 St. Vernardeen Av.", "Phila", " PA", "09119"], ["John", "Howards", "120 Monroe St.", "Riverside", " NJ", "08075"], ["Alfred", " Reynolds", " 271 Terrell Trace Dr.", " Marietta", " GA", " 30068"], ["Jim", " Harrison", " 100 Sandy Plains Plc.", " Houston", " TX", " 77005"]]
Monólogos de Python
En general, escribir una sola línea larga de Python no se considera una buena práctica. La guía PEP 8 incluso desaprueba las sentencias compuestas con punto y coma (¡es posible utilizar punto y coma en Python!). Pero las sentencias de depuración rápida y las llamadas a un depurador están bien. Al fin y al cabo, son temporales.
Depuradores
Algunos programadores juran que la sentencia print() es la mejor estrategia para depurar código en ejecución. En algunos casos, puede funcionar bien, pero la mayoría de las veces utilizamos el depurador de Python (con el módulo pdb ) o ipdb, que utiliza IPython como backend. Al crear un punto de interrupción, puedes hurgar en las variables y subir y bajar por la pila. Estas declaraciones de una sola línea son lo suficientemente importantes como para que debas memorizarlas:
Establece un punto de interrupción y pasa al depurador de Python (pdb):
importpdb;pdb.set_trace()
Establece un punto de interrupción y pasa a un depurador de Python basado en IPython (ipdb):
importipdb;ipdb.set_trace()
Aunque técnicamente no es un depurador (no puedes avanzar ni retroceder en la pila), este one-liner te permite iniciar una sesión de IPython cuando la ejecución llegue a ella:
importIPython;IPython.embed()
Nota
Todo el mundo parece tener una herramienta depuradora favorita. A nosotros nos parece que pdb es demasiado tosco (sin autocompletado, sin resaltado de sintaxis), así que nos suele gustar más ipdb. No te sorprendas si alguien propone un depurador diferente. Al final, es útil saber cómo funciona pdb, ya que es la base necesaria para ser competente independientemente del depurador. En los sistemas que no puedas controlar, utiliza directamente pdb porque no puedes instalar dependencias; puede que no te guste, pero aún así puedes arreglártelas.
¿Cómo de rápido es este fragmento?
Python tiene un módulo para ejecutar un trozo de código varias veces y obtener de él algunas métricas de rendimiento. A muchos usuarios les gusta preguntar si hay formas eficientes de manejar un bucle o actualizar un diccionario, y hay mucha gente entendida a la que le encanta el módulo timeit para probar el rendimiento.
Como ya habrás visto, somos fans de IPython, y su shell interactivo viene con una función especial "mágica " para el módulo timeit. Las funciones "mágicas" llevan como prefijo el carácter % y realizan una operación distinta dentro del shell. Una de las cuestiones favoritas en cuanto a rendimiento es si la comprensión de una lista es más rápida que simplemente anexar a una lista. Los dos ejemplos siguientes utilizan el módulo timeit para averiguarlo:
In[1]:deff(x):...:returnx*x...:In[2]:%timeitforxinrange(100):f(x)100000loops,bestof3:20.3usperloop
En el shell (o intérprete) estándar de Python, importas el módulo y accedes a él directamente. En este caso, la invocación es un poco diferente:
>>>array=[]>>>defappending():...foriinrange(100):...array.append(i)...>>>timeit.repeat("appending()","from __main__ import appending")[5.298534262983594,5.32031941099558,5.359099322988186]>>>timeit.repeat("[i for i in range(100)]")[2.2052824340062216,2.1648171059787273,2.1733458579983562]
La salida es un poco extraña, pero eso se debe a que está pensada para ser procesada por otro módulo o biblioteca, y no está pensada para la legibilidad humana. Los promedios favorecen la comprensión de la lista. Así es como se ve en IPython:
In[1]:defappending():...:array=[]...:foriinrange(100):...:array.append(i)...:In[2]:%timeitappending()5.39µs±95.1nsperloop(mean±std.dev.of7runs,100000loopseach)In[3]:%timeit[iforiinrange(100)]2.1µs±15.2nsperloop(mean±std.dev.of7runs,100000loopseach)
Como IPython expone timeit como un comando especial (fíjate en el prefijo con %), la salida es legible para los humanos y más útil de ver, y no requiere la extraña importación, como en el shell estándar de Python.
strace
La capacidad de saber cómo interactúa un programa con el sistema operativo resulta crucial cuando las aplicaciones no registran las partes interesantes o no lo hacen en absoluto. La salida de strace puede ser tosca, pero si se comprenden los conceptos básicos, resulta más fácil entender qué está pasando con una aplicación problemática. En una ocasión, Alfredo intentaba comprender por qué se denegaba el permiso de acceso a un archivo. Este archivo estaba dentro de un enlace simbólico que parecía tener todos los permisos correctos. ¿Qué ocurría? Era difícil saberlo con sólo mirar los registros, ya que éstos no eran especialmente útiles para mostrar los permisos mientras se intentaba acceder a los archivos.
strace incluye estas dos líneas en la salida:
stat("/var/lib/ceph/osd/block.db", 0x7fd) = -1 EACCES (Permission denied)
lstat("/var/lib/ceph/osd/block.db", {st_mode=S_IFLNK|0777, st_size=22}) = 0
El programa estaba estableciendo la propiedad sobre el directorio padre, que resultó ser un enlace, y block.db, que en este caso también era un enlace a un dispositivo de bloque. El propio dispositivo de bloque tenía los permisos correctos, así que ¿cuál era el problema? Resulta que el enlace del directorio tenía un bit adhesivo que impedía que otros enlaces cambiaran la ruta, incluido el dispositivo de bloque. La herramienta chown tiene una bandera especial (-h o --no-dereference) para indicar que el cambio de propiedad debe afectar también a los enlaces.
Este tipo de depuración sería difícil (si no imposible) sin algo como strace. Para probarlo, crea un archivo llamado follow.py con el siguiente contenido:
importsubprocesssubprocess.call(['ls','-alh'])
Importa el módulo subprocess para hacer una llamada al sistema. Enviará el contenido de la llamada al sistema a ls. En lugar de una llamada directa con Python, antepone al comando strace para ver qué ocurre:
$ strace python follow.py
Un montón de salida habrá llenado el terminal, y probablemente la mayor parte de ella te parecerá muy extraña. Oblígate a repasar cada línea, independientemente de que entiendas o no lo que está pasando. Algunas líneas serán más fáciles de distinguir que otras. Hay muchas llamadas a read y fstat; verás llamadas reales al sistema y lo que hace el proceso en cada paso. También hay operaciones open y close en algunos archivos, y hay una sección concreta en la que deberían aparecer unas cuantas llamadas a stat:
stat("/home/alfredo/go/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/local/go/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/local/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/home/alfredo/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/local/sbin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/local/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/sbin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/bin/python", {st_mode=S_IFREG|0755, st_size=3691008, ...}) = 0
readlink("/usr/bin/python", "python2", 4096) = 7
readlink("/usr/bin/python2", "python2.7", 4096) = 9
readlink("/usr/bin/python2.7", 0x7ff, 4096) = -1 EINVAL (Invalid argument)
stat("/usr/bin/Modules/Setup", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/bin/lib/python2.7/os.py", 0x7ffd) = -1 ENOENT (No such file)
stat("/usr/bin/lib/python2.7/os.pyc", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/lib/python2.7/os.py", {st_mode=S_IFREG|0644, ...}) = 0
stat("/usr/bin/pybuilddir.txt", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/bin/lib/python2.7/lib-dynload", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/lib/python2.7/lib-dynload", {st_mode=S_IFDIR|0755, ...}) = 0
Este sistema es bastante antiguo, y python en la salida significa python2.7, así que husmea por el sistema de archivos para intentar encontrar el ejecutable correcto. Pasa por unos cuantos hasta que llega a /usr/bin/python, que es un enlace que apunta a /usr/bin/python2, que a su vez es otro enlace que envía el proceso a /usr/bin/python2.7. A continuación, llama a stat en /usr/bin/Modules/Setup, del que nunca hemos oído hablar como desarrolladores de Python, para continuar con el módulo os.
Continúa con pybuilddir.txt y lib-dynload. Menudo viaje. Sin strace probablemente habríamos intentado leer el código que ejecuta esto para intentar averiguar a dónde va después. Pero strace lo hace tremendamente más fácil, incluyendo todos los pasos interesantes del camino, con información útil para cada llamada.
La herramienta tiene muchas banderas que merece la pena examinar; por ejemplo, puede adjuntarse a un PID. Si conoces el PID de un proceso, puedes decirle a strace que produzca una salida sobre lo que ocurre exactamente con él.
Una de esas banderas útiles es -f; seguirá a los procesos hijos a medida que sean creados por el programa inicial. En el archivo Python de ejemplo, se hace una llamada a subprocess, y éste llama a ls; si se modifica la orden a strace para utilizar -f, la salida se enriquece, con detalles sobre esa llamada.
Cuando follow.py se ejecuta en el directorio raíz, hay bastantes diferencias con la bandera -f. Puedes ver llamadas a lstat y readlink para los dotfiles (algunos de los cuales están enlazados simbólicamente):
[pid 30127] lstat(".vimrc", {st_mode=S_IFLNK|0777, st_size=29, ...}) = 0
[pid 30127] lgetxattr(".vimrc", "security.selinux", 0x55c5a36f4720, 255)
[pid 30127] readlink(".vimrc", "/home/alfredo/dotfiles/.vimrc", 30) = 29
[pid 30127] lstat(".config", {st_mode=S_IFDIR|0700, st_size=4096, ...}) = 0
No sólo se muestran las llamadas a estos archivos, sino que el PID aparece prefijado en la salida, lo que ayuda a identificar qué proceso (hijo) está haciendo qué. Una llamada a strace sin la bandera -f no mostraría un PID, por ejemplo.
Por último, para analizar la salida en detalle, puede ser útil guardarla en un archivo. Esto es posible con la bandera -o:
$ strace -o output.txt python follow.py
Ejercicios
-
Define qué es IOPS.
-
Explica cuál es la diferencia entre rendimiento e IOPS.
-
Nombra una limitación de
fdiskpara crear particiones que no tengaparted. -
Nombra tres herramientas que pueden proporcionar información sobre discos.
-
¿Qué puede hacer un túnel SSH? ¿Cuándo es útil?
Get Python para DevOps now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

