Chapter 4. Useful Linux Utilities
The command line and its tooling were one of the main reasons Alfredo felt attached to Linux servers when he started his career. One of his first jobs as a system administrator in a medium-sized company involved taking care of everything that was Linux-related. The small IT department was focused on the Windows servers and desktops, and they thoroughly disliked using the command line. At one point, the IT manager told him that he understood graphical user interfaces (GUIs), installing utilities, and tooling in general to solve problems: âI am not a coder, if it doesnât exist as a GUI, I canât use it,â he said.
Alfredo was hired as a contractor to help out with the few Linux servers the company had. At the time, Subversion (SVN) was all the rage for version control, and the developers depended on this single SVN server to push their work. Instead of using the centralized identity server, provided by two domain controllers, it used a text-based authentication system that mapped a user to a hash representing the password. This meant that usernames didnât necessarily map to those in the domain controller and that passwords could be anything. Often, a developer would ask to reset the password, and someone had to edit this text file with the hash. A project manager asked Alfredo to integrate the SVN authentication with the domain controller (Microsoftâs Active Directory). The first question he asked was why hadnât the IT department done this already? âThey say it is not possible, but Alfredo, this is a lie, SVN can integrate with Active Directory.â
He had never used an authentication service like Active Directory and barely understood SVN, but he was determined to make this work. Alfredo set out to read all about SVN and Active Directory, tinkered his way around a virtual machine with an SVN server running, and tried to get this authentication to work. It took about two weeks to read up on all the pieces involved and to get it to work. He succeeded in the end and was able to get this system into production. This felt incredibly powerful; he had acquired unique knowledge and was now ready to be fully in charge of this system. The IT manager, as well as the rest of the department, were ecstatic. Alfredo tried to share this newly acquired knowledge with others and was always met with an excuse: âno time,â âtoo busy,â âother priorities,â and âperhaps some other timeâmaybe next week.â
An apt description for technologists is: knowledge workers. Your curiosity and a never-ending pursuit of knowledge will continue to make you, and the environments you work on, much better. Donât ever let a coworker (or a whole IT department, as in Alfredoâs case) be a deterrent for improving systems. If there is an opportunity to learn something new, jump on it! The worst that can happen is that you have acquired knowledge that perhaps wonât be used often, but on the other hand, might change your professional career.
Linux does have desktop environments, but its real power comes from understanding and using the command line, and ultimately, by extending it. When there are no pre-made tools to solve a problem, seasoned DevOps people will craft their own. This notion of being able to come up with solutions by putting together the core pieces is incredibly powerful, and is what ultimately happened at that job where it felt productive to complete tasks without having to install off-the-shelf software to fix things.
This chapter will go through some common patterns in the shell and will include some useful Python commands that should enhance the ability to interact with a machine. We find that creating aliases and one-liners is the most fun one can have at work, and sometimes they are so useful that they end up as plug-ins or standalone pieces of software.
Disk Utilities
There are several different utilities that you can use to get information about devices in a system. A lot of them have feature overlap, and some have an interactive session to deal with disk operations, such as fdisk and parted.
It is crucial to have a good grasp on disk utilities, not only to retrieve information and manipulate partitions, but also to accurately measure performance. Performance, in particular, is one of the tough things to accomplish correctly. The best answer to the question How do I measure the performance of a device? is It depends, because it is difficult to do for the specific metric one is looking for.
Measuring Performance
If we had to work in an isolated environment with a server that doesnât have access to the internet or that we donât control and therefore canât install packages, we would have to say that the dd tool (which should be readily available on all major Linux distributions) would help provide some answers. If at all possible, pair it with iostat to isolate the command that hammers the device versus the one that gets the report.
As a seasoned performance engineer once said, it depends on what is measured and how. For example dd is single threaded and has limitations, such as being unable to do multiple random reads and writes; it also measures throughput and not input/output operations per second (IOPS). What are you measuring? Throughput or IOPS?
Caution
A word of warning on these examples. They can destroy your system, donât follow them blindly, and make sure to use devices that can get erased.
This simple one-liner will run dd to get some numbers of a brand-new device (/dev/sdc in this case):
$ dd if=/dev/zero of=/dev/sdc count=10 bs=100M 10+0 records in 10+0 records out 1048576000 bytes (1.0 GB, 1000 MiB) copied, 1.01127 s, 1.0 GB/s
It writes 10 records of 100 megabytes at a rate of 1 GB/s. This is throughput. An easy way to get IOPS with dd is to use iostat. In this example, iostat runs only on the device getting hammered with dd, with the -d flag only to give the device information, and with an interval of one second:
$ iostat -d /dev/sdc 1 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sdc 6813.00 0.00 1498640.00 0 1498640 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sdc 6711.00 0.00 1476420.00 0 1476420
The iostat output will repeat itself for every second until a Ctrl-C is issued to cancel the operation. The second column in the output is tps, which stands for transactions per second and is the same as IOPS. A nicer way to visualize the output, which avoids the clutter that a repeating command produces, is to clear the terminal on each run:
$ while true; do clear && iostat -d /dev/sdc && sleep 1; done
Accurate tests with fio
If dd and iostat arenât sufficient, the most commonly used tool for performance testing is fio. It can help clarify the performance behavior of a device in a read-heavy or write-heavy environment (and even adjust the percentages of reads versus writes).
The output from fio is quite verbose. The example below trims it to emphasize the IOPS found on both read and write operations:
$ fio --name=sdc-performance --filename=/dev/sdc --ioengine=libaio \ --iodepth=1 --rw=randrw --bs=32k --direct=0 --size=64m sdc-performance: (g=0): rw=randwrite, bs=(R) 32.0KiB-32.0KiB, (W) 32.0KiB-32.0KiB, (T) 32.0KiB-32.0KiB, ioengine=libaio, iodepth=1 fio-3.1 Starting 1 process sdc-performance: (groupid=0, jobs=1): err= 0: pid=2879: read: IOPS=1753, BW=54.8MiB/s (57.4MB/s)(31.1MiB/567msec) ... iops : min= 1718, max= 1718, avg=1718.00, stdev= 0.00, samples=1 write: IOPS=1858, BW=58.1MiB/s (60.9MB/s)(32.9MiB/567msec) ... iops : min= 1824, max= 1824, avg=1824.00, stdev= 0.00, samples=1
The flags used in the example name the job sdc-performance, point to the /dev/sdc device directly (will require superuser permissions), use the native Linux asynchronous I/O library, set the iodepth to 1 (number of sequential I/O requests to be sent at a time), and define random read and write operations of 32 kilobytes for the buffer size using buffered I/O (can be set to 1 to use unbuffered I/O) on a 64-megabyte file. Quite the lengthy command here!
The fio tool has a tremendous number of additional options that can help with most any case where accurate IOPS measurements are needed. For example, it can span the test across many devices at once, do some I/O warm up, and even set I/O thresholds for the test if a defined limit shouldnât be surpassed. Finally, the many options in the command line can be configured with INI-style files so that the execution of jobs can be scripted nicely.
Partitions
We tend to default to fdisk with its interactive session to create partitions, but in some cases, fdisk doesnât work well, such as with large partitions (two terabytes or larger). In those cases, your fallback should be to use parted.
A quick interactive session shows how to create a primary partition with fdisk, with the default start value and four gibibytes of size. At the end the w key is sent to write the changes:
$ sudo fdisk /dev/sds
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-22527999, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-22527999, default 22527999): +4G
Partition 1 of type Linux and of size 4 GiB is set
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
parted accomplishes the same, but with a different interface:
$ sudo parted /dev/sdaa GNU Parted 3.1 Using /dev/sdaa Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) mklabel New disk label type? gpt (parted) mkpart Partition name? []? File system type? [ext2]? Start? 0 End? 40%
In the end, you quit with the q key. For programmatic creation of partitions on the command line without any interactive prompts, you accomplish the same result with a couple of commands:
$ parted --script /dev/sdaa mklabel gpt $ parted --script /dev/sdaa mkpart primary 1 40% $ parted --script /dev/sdaa print Disk /dev/sdaa: 11.5GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 4614MB 4613MB
Retrieving Specific Device Information
Sometimes when specific information for a device is needed, either lsblk or blkid are well suited. fdisk doesnât like to work without superuser permissions. Here fdisk lists the information about the /dev/sda device:
$ fdisk -l /dev/sda fdisk: cannot open /dev/sda: Permission denied $ sudo fdisk -l /dev/sda Disk /dev/sda: 42.9 GB, 42949672960 bytes, 83886080 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x0009d9ce Device Boot Start End Blocks Id System /dev/sda1 * 2048 83886079 41942016 83 Linux
blkid is a bit similar in that it wants superuser permissions as well:
$ blkid /dev/sda $ sudo blkid /dev/sda /dev/sda: PTTYPE="dos"
lsblk allows to get information without higher permissions, and provides the same informational output regardless:
$ lsblk /dev/sda NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 40G 0 disk ââsda1 8:1 0 40G 0 part / $ sudo lsblk /dev/sda NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 40G 0 disk ââsda1 8:1 0 40G 0 part /
This command, which uses the -p flag for low-level device probing, is very thorough and should give you good enough information for a device:
$ blkid -p /dev/sda1 UUID="8e4622c4-1066-4ea8-ab6c-9a19f626755c" TYPE="xfs" USAGE="filesystem" PART_ENTRY_SCHEME="dos" PART_ENTRY_TYPE="0x83" PART_ENTRY_FLAGS="0x80" PART_ENTRY_NUMBER="1" PART_ENTRY_OFFSET="2048" PART_ENTRY_SIZE="83884032"
lsblk has some default properties to look for:
$ lsblk -P /dev/nvme0n1p1 NAME="nvme0n1p1" MAJ:MIN="259:1" RM="0" SIZE="512M" RO="0" TYPE="part"
But it also allows you to set specific flags to request a particular property:
lsblk -P -o SIZE /dev/nvme0n1p1 SIZE="512M"
To access a property in this way makes it easy to script and even consume from the Python side of things.
Network Utilities
Network tooling keeps improving as more and more servers need to be interconnected. A lot of the utilities in this section cover useful one-liners like Secure Shell (SSH) tunneling, but some others go into the details of testing network performance, such as using the Apache Bench tool.
SSH Tunneling
Have you ever tried to reach an HTTP service that runs on a remote server that is not accessible except via SSH? This situation occurs when the HTTP service is enabled but not needed publicly. The last time we saw this happen was when a production instance of RabbitMQ had the management plug-in enabled, which starts an HTTP service on port 15672. The service isnât exposed and with good reason; there is no need to have it publicly available since it is rarely used, and besides, one can use SSHâs tunneling capabilities.
This works by creating an SSH connection with the remote server and then forwarding the remote port (15672, in my case) to a local port on the originating machine. The remote machine has a custom SSH port, which complicates the command slightly. This is is how it looks:
$ ssh -L 9998:localhost:15672 -p 2223 adeza@prod1.rabbitmq.ceph.internal -N
There are three flags, three numbers, and two addresses. Letâs dissect the command to make what is going on here much clearer. The -L flag is the one that signals that we want forwarding enabled and a local port (9998) to bind to a remote port (RabbitMQâs default of 15672). Next, the -p flag indicates that the custom SSH port of the remote server is 2223, and then the username and address are specified. Lastly, the -N means that it shouldnât get us to a remote shell and do the forwarding.
When executed correctly, the command will appear to hang, but it allows you to go into http://localhost:9998/ and see the login page for the remote RabbitMQ instance. A useful flag to know when tunneling is -f: it will send the process into the background, which is helpful if this connection isnât temporary, leaving the terminal ready and clean to do more work.
Benchmarking HTTP with Apache Benchmark (ab)
We really love to hammer servers we work with to ensure they handle load correctly, especially before they get promoted to production. Sometimes we even try to trigger some odd race condition that may happen under heavy load. The Apache Benchmark tool (ab in the command line) is one of those tiny tools that can get you going quickly with just a few flags.
This command will create 100 requests at a time, for a total of 10,000 requests, to a local instance where Nginx is running:
$ ab -c 100 -n 10000 http://localhost/
That is pretty brutal to handle in a system, but this is a local server, and the requests are just an HTTP GET. The detailed output from ab is very comprehensive and looks like this (trimmed for brevity):
Benchmarking localhost (be patient)
...
Completed 10000 requests
Finished 10000 requests
Server Software: nginx/1.15.9
Server Hostname: localhost
Server Port: 80
Document Path: /
Document Length: 612 bytes
Concurrency Level: 100
Time taken for tests: 0.624 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 8540000 bytes
HTML transferred: 6120000 bytes
Requests per second: 16015.37 [#/sec] (mean)
Time per request: 6.244 [ms] (mean)
Time per request: 0.062 [ms] (mean, across all concurrent requests)
Transfer rate: 13356.57 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 3 0.6 3 5
Processing: 0 4 0.8 3 8
Waiting: 0 3 0.8 3 6
Total: 0 6 1.0 6 9
This type of information and how it is presented is tremendous. At a glance, you can quickly tell if a production server drops connections (in the Failed requests field) and what the averages are. A GET request is used, but ab allows you to use other HTTP verbs, such as POST, and even do a HEAD request. You need to exercise caution with this type of tool because it can easily overload a server. Below are more realistic numbers from an HTTP service in production (trimmed for brevity):
... Benchmarking prod1.ceph.internal (be patient) Server Software: nginx Server Hostname: prod1.ceph.internal Server Port: 443 SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256 Server Temp Key: ECDH P-256 256 bits TLS Server Name: prod1.ceph.internal Complete requests: 200 Failed requests: 0 Total transferred: 212600 bytes HTML transferred: 175000 bytes Requests per second: 83.94 [#/sec] (mean) Time per request: 1191.324 [ms] (mean) Time per request: 11.913 [ms] (mean, across all concurrent requests) Transfer rate: 87.14 [Kbytes/sec] received ....
Now the numbers look different, it hits a service with SSL enabled, and ab lists what the protocols are. At 83 requests per second, we think it could do better, but this is an API server that produces JSON, and it typically doesnât get much load at once, as was just generated.
Load Testing with molotov
The Molotov project is an interesting project geared towards load testing. Some of its features are similar to those of Apache Benchmark, but being a Python project, it provides a way to write scenarios with Python and the asyncio module.
This is how the simplest example for molotov looks:
importmolotov@molotov.scenario(100)asyncdefscenario_one(session):asyncwithsession.get("http://localhost:5000")asresp:assertresp.status==200
Save the file as load_test.py, create a small Flask application that handles both POST and GET requests at its main URL, and save it as small.py:
fromflaskimportFlask,redirect,requestapp=Flask('basic app')@app.route('/',methods=['GET','POST'])defindex():ifrequest.method=='POST':redirect('https://www.google.com/search?q=%s'%request.args['q'])else:return'<h1>GET request from Flask!</h1>'
Start the Flask application with FLASK_APP=small.py flask run, and then run molotov with the load_test.py file created previously:
$ molotov -v -r 100 load_test.py **** Molotov v1.6. Happy breaking! **** Preparing 1 worker... OK SUCCESSES: 100 | FAILURES: 0 WORKERS: 0 *** Bye ***
One hundred requests on a single worker ran against the local Flask instance. The tool really shines when the load testing is extended to do more per request. It has concepts similar to unit testing, such as setup, teardown, and even code, that can react to certain events. Since the small Flask application can handle a POST that redirects to a Google search, add another scenario to the load_test.py_ file. This time change the weight so that 100% of the requests do a POST:
@molotov.scenario(100)asyncdefscenario_post(session):resp=awaitsession.post("http://localhost:5000",params={'q':'devops'})redirect_status=resp.history[0].statuserror="unexpected redirect status:%s"%redirect_statusassertredirect_status==301,error
Run this new scenario for a single request to show the following:
$ molotov -v -r 1 --processes 1 load_test.py
**** Molotov v1.6. Happy breaking! ****
Preparing 1 worker...
OK
AssertionError('unexpected redirect status: 302',)
File ".venv/lib/python3.6/site-packages/molotov/worker.py", line 206, in step
**scenario['kw'])
File "load_test.py", line 12, in scenario_two
assert redirect_status == 301, error
SUCCESSES: 0 | FAILURES: 1
*** Bye ***
A single request (with -r 1) was enough to make this fail. The assertion needs to be updated to check for a 302 instead of a 301. Once that status is updated, change the weight of the POST scenario to 80 so that other requests (with a GET) are sent to the Flask application. This is how the file looks in the end:
importmolotov@molotov.scenario()asyncdefscenario_one(session):asyncwithsession.get("http://localhost:5000/")asresp:assertresp.status==200@molotov.scenario(80)asyncdefscenario_two(session):resp=awaitsession.post("http://localhost:5000",params={'q':'devops'})redirect_status=resp.history[0].statuserror="unexpected redirect status:%s"%redirect_statusassertredirect_status==301,error
Run load_test.py for 10 requests to distribute the requests, two for a GET and the rest with a POST:
127.0.0.1 - - [04/Sep/2019 12:10:54] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:10:56] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:10:57] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:10:58] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [04/Sep/2019 12:10:58] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:10:59] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:11:00] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:11:01] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [04/Sep/2019 12:11:01] "POST /?q=devops HTTP/1.1" 302 - 127.0.0.1 - - [04/Sep/2019 12:11:02] "POST /?q=devops HTTP/1.1" 302 -
As you can see, molotov is easily extensible with pure Python and can be modified to suit other, more complex, needs. These examples scratch the surface of what the tool can do.
CPU Utilities
There are two important CPU utilities: top and htop. You can find top preinstalled in most Linux distributions today, but if you are able to install packages, htop is fantastic to work with and we prefer its customizable interface over top. There are a few other tools out there that provide CPU visualization and perhaps even monitoring, but none are as complete and as widely available as both top and htop. For example, it is entirely possible to get CPU utilization from the ps command:
$ ps -eo pcpu,pid,user,args | sort -r | head -10 %CPU PID USER COMMAND 0.3 719 vagrant -bash 0.1 718 vagrant sshd: vagrant@pts/0 0.1 668 vagrant /lib/systemd/systemd --user 0.0 9 root [rcu_bh] 0.0 95 root [ipv6_addrconf] 0.0 91 root [kworker/u4:3] 0.0 8 root [rcu_sched] 0.0 89 root [scsi_tmf_1]
The ps command takes some custom fields. The first one is pcpu, which gives the CPU usage, followed by the process ID, the user, and finally, the command. That pipes into a sorted reverse because by default it goes from less CPU usage to more, and you need to have the most CPU usage at the top. Finally, since the command displays this information for every single process, it filters the top 10 results with the head command.
But the command is quite a mouthful, is a challenge to remember, and is not updated on the fly. Even if aliased, you are better off with top or htop. As you will see, both have extensive features.
Viewing Processes with htop
The htop tool is just like top (an interactive process viewer) but is fully cross-platform (works on OS X, FreeBSD, OpenBSD, and Linux), offers support for better visualizations (see Figure 4-1), and is a pleasure to use. Visit https://hisham.hm/htop for a screenshot of htop running on a server. One of the main caveats of htop is that all the shortcuts you may know about top are not compatible, so you will have to rewire your brain to understand and use them for htop.
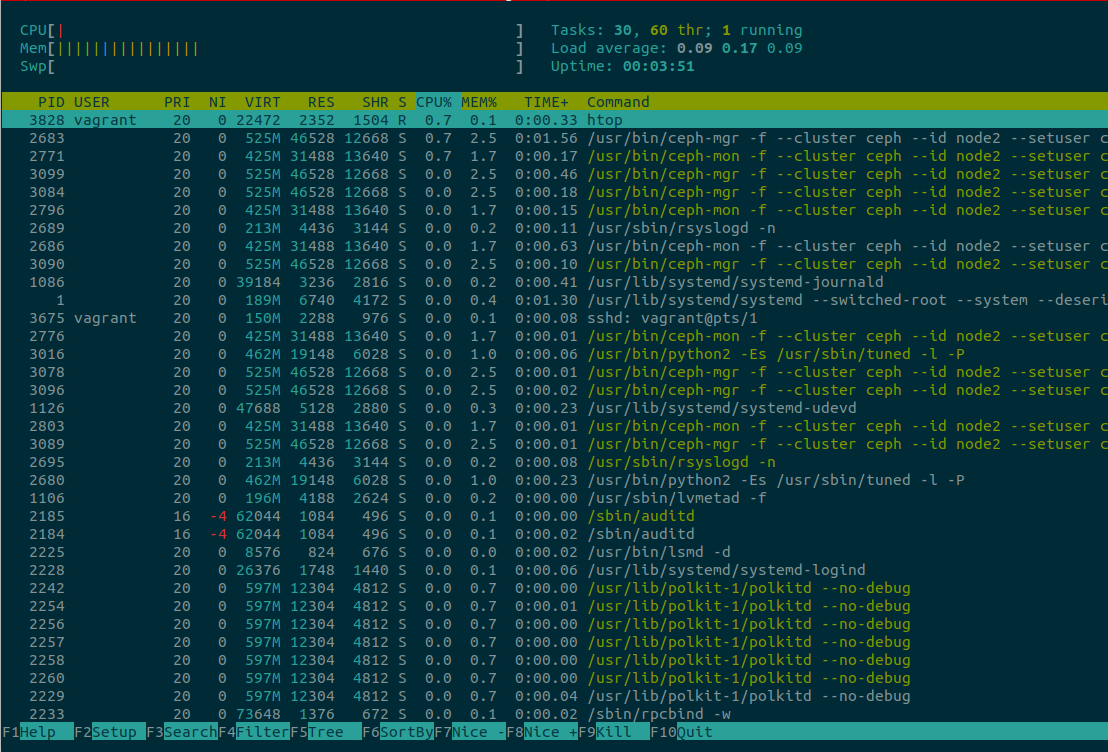
Figure 4-1. htop running on a server
Right away, the look and feel of the information displayed in Figure 4-1 is different. The CPU, Memory, and Swap are nicely shown at the top left, and they move as the system changes. The arrow keys scroll up or down and even left to right, providing a view of the whole command of the process.
Want to kill a process? Move to it with the arrow keys, or hit / to incrementally search (and filter) the process, and then press k. A new menu will show all the signals that can be sent to the processâfor example, SIGTERM instead of SIGKILL. It is possible to âtagâ more than one process to kill. Press the space bar to tag the selected process, highlighting it with a different color. Made a mistake and want to un-tag? Press the space bar again. This all feels very intuitive.
One problem with htop is that it has lots of actions mapped to F keys, and you may not have any. For example, F1 is for help. The alternative is to use the equivalent mappings when possible. To access the help menu, use the h key; to access the setup, use Shift s instead of F2.
The t (again, how intuitive!) enables (toggles) the process list as a tree. Probably the most used functionality is sorting. Press > and a menu appears to select what type of sorting you want: PID, user, memory, priority, and CPU percentage are just a few. There are also shortcuts to sort directly (skips the menu selection) by memory (Shift i), CPU (Shift p), and Time (Shift t).
Finally, two incredible features: you can run strace or lsof directly in the selected process as long as these are installed and available to the user. If the processes require superuser permissions, htop will report that, and it will require sudo to run as a privileged user. To run strace on a selected process, use the s key; for lsof, use the l key.
If either strace or lsof is used, the search and filter options are available with the / character. What an incredibly useful tool! Hopefully, one day other non-F key mappings will be possible, even though most work can be done with the alternative mappings.
Tip
If htop is customized via its interactive session, the changes get persisted in a configuration file that is usually located at ~/.config/htop/htoprc. If you define configurations there and later change them in the session, then the session will overwrite whatever was defined previously in the htoprc file.
Working with Bash and ZSH
It all starts with customization. Both Bash and ZSH will usually come with a âdotfile,â a file prefixed with a dot that holds configuration but by default is hidden when directory contents are listed, and lives in the home directory of the user. For Bash this is .bashrc, and for ZSH it is .zshrc. Both shells support several layers of places that will get loaded in a predefined order, which ends in the configuration file for the user.
When ZSH is installed, a .zshrc is usually not created. This is how a minimal version of it looks in a CentOS distro (all comments removed for brevity):
$ cat /etc/skel/.zshrc
autoload -U compinit
compinit
setopt COMPLETE_IN_WORDBash has a couple of additional items in it but nothing surprising. You will no doubt get to the point of being extremely annoyed at some behavior or thing you saw in some other server that you want to replicate. We canât live without colors in the terminal, so whatever the shell, it has to have color enabled. Before you know it, you are deep into configurations and want to add a bunch of useful aliases and functions.
Soon after, the text editor configurations come in, and it all feels unmanageable on different machines or when new ones are added and all those useful aliases are not set up, and it is unbelievable, but no one has enabled color support anywhere. Everyone has a way to solve this problem in an entirely nontransferable, ad hoc way: Alfredo uses a Makefile at some point, and his coworkers use either nothing at all or a Bash script. A new project called Dotdrop has lots of features to get all those dotfiles in working order, with features such as copying, symlinking, and keeping separate profiles for development and other machinesâpretty useful when you move from one machine to another.
You can use Dotdrop for a Python project, and although you can install it via the regular virtualenv and pip tooling, it is recommended to include it as a submodule to your repository of dotfiles. If you havenât done so already, it is very convenient to keep all your dotfiles in version control to keep track of changes. Alfredoâs dotfiles are publicly available, and he tries to keep them as up-to-date as possible.
Independent of what is used, keeping track of changes via version control, and making sure everything is always updated, is a good strategy.
Customizing the Python Shell
You can customize the Python shell with helpers and import useful modules in a Python file that then has to be exported as an environment variable. I keep my configuration files in a repository called dotfiles, so in my shell configuration file ($HOME/.zshrc for me) I define the following export:
exportPYTHONSTARTUP=$HOME/dotfiles/pythonstartup.py
To try this out, create a new Python file called pythonstartup.py (although it can be named anything) that looks like this:
import typesimport uuidhelpers = types.ModuleType('helpers')helpers.uuid4 = uuid.uuid4()
Now open up a new Python shell and specify the newly created pythonstartup.py:
$ PYTHONSTARTUP=pythonstartup.py python
Python 3.7.3 (default, Apr 3 2019, 06:39:12)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> helpers
<module 'helpers'>
>>> helpers.uuid4()
UUID('966d7dbe-7835-4ac7-bbbf-06bf33db5302')
The helpers object is immediately available. Since we added the uuid4 property, we can access it as helpers.uuid4(). As you may be able to tell, all the imports and definitions are going to be available in the Python shell. This is a convenient way to extend behavior that can be useful with the default shell.
Recursive Globbing
Recursive globbing is enabled in ZSH by default, but Bash (versions 4 and higher) requires shopt to set it. Recursive globbing is a cool setting that allows you to traverse a path with the following syntax:
$ ls **/*.py
That snippet would go through each file and directory recursively and list every single file that ends in .py. This is how to enable it in Bash 4:
$ shopt -s globstar
Searching and Replacing with Confirmation Prompts
Vim has a nice feature in its search and replace engine that prompts for confirmation to perform the replacement or skip it. This is particularly useful when you canât nail the exact regular expression that matches what you need but want to ignore some other close matches. We know regular expressions, but weâve tried to avoid being an expert at them because it would be very tempting to use them for everything. Most of the time, you will want to perform a simple search and replace and not bang your head against the wall to come up with the perfect regex.
The c flag needs to be appended at the end of the command to enable the confirmation prompt in Vim:
:%s/original term/replacement term/gc
The above translates to: search for original term in the whole file and replace it with replacement term, but at each instance, prompt so that one can decide to change it or skip it. If a match is found, Vim will display a message like this one:
replace with replacement term (y/n/a/q/l/^E/^Y)?
The whole confirmation workflow might seem silly but allows you to relax the constraints on the regular expression, or even not use one at all for a simpler match and replace. A quick example of this is a recent API change in a production tool that changed an objectâs attribute for a callable. The code returned True or False to inform if superuser permissions were required or not. The actual replacement in a single file would look like this:
:%s/needs_root/needs_root()/gc
The added difficulty here is that needs_root was also splattered in comments and doc strings, so it wasnât easy to come up with a regular expression that would allow skipping the replacement when inside a comment block or in part of a doc string. With the c flag, you can just hit Y or N and move on. No regular expression needed at all!
With recursive globbing enabled (shopt -s globstar in Bash 4), this powerful one-liner will go through all the matching files, perform the search, and replace the item according to the prompts if the pattern is found inside the files:
vim -c "bufdo! set eventignore-=Syntax | %s/needs_root/needs_root()/gce" **/*.py
There is a lot to unpack here, but the above example will traverse recursively to find all the files ending in .py, load them into Vim, and perform the search and replace with confirmation only if there is a match. If there isnât a match, it skips the file. The set eventignore-=Syntax is used because otherwise Vim will not load the syntax files when executing it this way; we like syntax highlighting and expect it to work when this type of replacement is used. The next part after the | character is the replacement with the confirmation flag and the e flag, which helps ignore any errors that would prevent a smooth workflow from being interrupted with errors.
Tip
There are numerous other flags and variations that you can use to enhance the replacement command. To learn more about the special flags with a search and replace in Vim, take a look at :help substitute, specifically at the s_flags section.
Make the complicated one-liner easier to remember with a function that takes two parameters (search and replace terms) and the path:
vsed(){search=$1replace=$2shiftshiftvim -c"bufdo! set eventignore-=Syntax| %s/$search/$replace/gce"$*}
Name it vsed, as a mix of Vim and the sed tool, so that it is easier to remember. In the terminal, it looks straightforward and allows you to make changes to multiple files easily and with confidence, since you can accept or deny each replacement:
$ vsed needs_root needs_root() **/*.py
Removing Temporary Python Files
Pythonâs pyc, and more recently its pycache directories, can sometimes get in the way. This simple one-liner aliased to pyclean uses the find command to remove pyc, then goes on to find pycache directories and recursively deletes them with the toolâs built-in delete flag:
aliaspyclean='find . \\( -type f -name "*.py[co]" -o -type d -name "__pycache__" \) -delete &&echo "Removed pycs and __pycache__"'
Listing and Filtering Processes
Process listing to view what runs in a machine and then filtering to check on a specific application is one of the things that youâll do several times a day at the very least. It is not at all surprising that everyone has a variation on either the flags or the order of the flags for the ps tool (we usually use aux). It is something you end up doing so many times a day that the order and the flags get ingrained in your brain and it is hard to do it any other way.
As a good starting point to list the processes and some information, such as process IDs, try this:
$ ps auxw
This command lists all processes with the BSD-style flags (flags that arenât prefixed with a dash -) regardless or whether they have a terminal (tty) or not, and includes the user that owns the process. Finally, it gives more space to the output (w flag).
Most of the times, you are filtering with grep to get information about a specific process. For example, if you want to check if Nginx is running, you pipe the output into grep and pass nginx as an argument:
$ ps auxw | grep nginx root 29640 1536 ? Ss 10:11 0:00 nginx: master process www-data 29648 5440 ? S 10:11 0:00 nginx: worker process alfredo 30024 924 pts/14 S+ 10:12 0:00 grep nginx
That is great, but it is annoying to have the grep command included. This is particularly maddening when there are no results except for the grep:
$ ps auxw | grep apache alfredo 31351 0.0 0.0 8856 912 pts/13 S+ 10:15 0:00 grep apache
No apache process is found, but the visuals may mislead you to think it is, and double-checking that this is indeed just grep being included because of the argument can get tiring pretty quickly. A way to solve this is to add another pipe to grep to filter itself from the output:
$ ps auxw | grep apache | grep -v grep
To have to always remember to add that extra grep can be equally annoying, so an alias comes to the rescue:
alias pg='ps aux | grep -v grep | grep $1'
The new alias will filter the first grep line out and leave only the interesting output (if any):
$ pg vim alfredo 31585 77836 20624 pts/3 S+ 18:39 0:00 vim /home/alfredo/.zshrc
Unix Timestamp
To get the widely used Unix timestamp in Python is very easy:
In [1]: import timeIn [2]: int(time.time())Out[2]: 1566168361
But in the shell, it can be a bit more involved. This alias works in OS X, which has the BSD-flavored version of the date tool:
alias timestamp='date -j -f "%a %b %d %T %Z %Y" "`date`" "+%s"'
OS X can be awkward with its tooling, and it may be confusing to never remember why a given utility (like date in this case) behaves completely differently. In the Linux version of date, a far simpler approach works the same way:
alias timestamp='date "+%s"'
Mixing Python with Bash and ZSH
It never occurred to us to try and mix Python with a shell, like ZSH or Bash. It feels like going against common sense, but there are a few good cases here that you can use almost daily. In general, our rule of thumb is that 10 lines of shell script is the limit; anything beyond that is a bug waiting to make you waste time because the error reporting isnât there to help you out.
Random Password Generator
The amount of accounts and passwords that you need on a week-to-week basis is only going to keep increasing, even for throwaway accounts that you can use Python for to generate robust passwords. Create a useful, randomized password generator that sends the contents to the clipboard to easily paste it:
In[1]:importosIn[2]:importbase64In[3]:(base64.b64encode(os.urandom(64)).decode('utf-8'))gHHlGXnqnbsALbAZrGaw+LmvipTeFi3tA/9uBltNf9g2S9qTQ8hTpBYrXStp+i/o5TseeVo6wcX2A==
Porting that to a shell function that can take an arbitrary length (useful when a site restricts length to a certain number) looks like this:
mpass(){if[$1];thenlength=$1elselength=12fi_hash=`python3 -c"import os,base64exec('print(base64.b64encode(os.urandom(64))[:${length}].decode(\'utf-8\'))')"`echo$_hash|xclip -selection clipboardecho"new password copied to the system clipboard"}
Now the mpass function defaults to generate 12-character passwords by slicing the output, and then sends the contents of the generated string to xclip so that it gets copied to the clipboard for easy pasting.
Note
xclip is not installed by default in many distros, so you need to ensure that it is installed for the function to work properly. If xclip is not available, any other utility that can help manage the system clipboard will work fine.
Changing Directories to a Moduleâs Path
âWhere does this module live?â is often asked when debugging libraries and dependencies, or even when poking around at the source of modules. Pythonâs way to install and distribute modules isnât straightforward, and in different Linux distributions the paths are entirely different and have separate conventions. You can find out the path of a module if you import it and then use print:
In[1]:importosIn[2]:(os)<module'os'from'.virtualenvs/python-devops/lib/python3.6/os.py'>
It isnât convenient if all you want is the path so that you can change directories to it and look at the module. This function will try to import the module as an argument, print it out (this is shell, so return doesnât do anything for us), and then change directory to it:
cdp(){MODULE_DIRECTORY=`python -c"exec('''try:import os.path as _,${module}print(_.dirname(_.realpath(${module}.__file__)))except Exception as e:print(e)''')"`if[[-d$MODULE_DIRECTORY]];thencd$MODULE_DIRECTORYelseecho"Module${1}not found or is not importable:$MODULE_DIRECTORY"fi}
Letâs make it more robust, in case the package name has a dash and the module uses an underscore, by adding:
module=$(sed's/-/_/g'<<<$1)
If the input has a dash, the little function can solve this on the fly and get us to where we need to be:
$ cdp pkg-resources $ pwd /usr/lib/python2.7/dist-packages/pkg_resources
Converting a CSV File to JSON
Python comes with a few built-ins that are surprising if youâve never dealt with them. It can handle JSON natively, as well as CSV files. It only takes a couple of lines to load a CSV file and then âdumpâ its contents as JSON. Use the following CSV file (addresses.csv) to see the contents when JSON is dumped in the Python shell:
John,Doe,120 Main St.,Riverside, NJ, 08075 Jack,Jhonson,220 St. Vernardeen Av.,Phila, PA,09119 John,Howards,120 Monroe St.,Riverside, NJ,08075 Alfred, Reynolds, 271 Terrell Trace Dr., Marietta, GA, 30068 Jim, Harrison, 100 Sandy Plains Plc., Houston, TX, 77005
>>>importcsv>>>importjson>>>contents=open("addresses.csv").readlines()>>>json.dumps(list(csv.reader(contents)))'[["John", "Doe", "120 Main St.", "Riverside", " NJ", " 08075"],["Jack","Jhonson","220 St. Vernardeen Av.","Phila"," PA","09119"],["John","Howards","120 Monroe St.","Riverside"," NJ","08075"],["Alfred"," Reynolds"," 271 Terrell Trace Dr."," Marietta"," GA"," 30068"],["Jim"," Harrison"," 100 Sandy Plains Plc."," Houston"," TX"," 77005"]]'
Port the interactive session to a function that can do this on the command line:
csv2json(){python3 -c"exec('''import csv,jsonprint(json.dumps(list(csv.reader(open(\'${1}\')))))''')"}
Use it in the shell, which is much simpler than remembering all the calls and modules:
$ csv2json addresses.csv [["John", "Doe", "120 Main St.", "Riverside", " NJ", " 08075"], ["Jack", "Jhonson", "220 St. Vernardeen Av.", "Phila", " PA", "09119"], ["John", "Howards", "120 Monroe St.", "Riverside", " NJ", "08075"], ["Alfred", " Reynolds", " 271 Terrell Trace Dr.", " Marietta", " GA", " 30068"], ["Jim", " Harrison", " 100 Sandy Plains Plc.", " Houston", " TX", " 77005"]]
Python One-Liners
In general, writing a long, single line of Python is not considered good practice. The PEP 8 guide even frowns on compounding statements with a semicolon (it is possible to use semicolons in Python!). But quick debug statements and calls to a debugger are fine. They are, after all, temporary.
Debuggers
A few programmers out there swear by the print() statement as the best strategy to debug running code. In some cases, that might work fine, but most of the time we use the Python debugger (with the pdb module) or ipdb, which uses IPython as a backend. By creating a break point, you can poke around at variables and go up and down the stack. These single-line statements are important enough that you should memorize them:
Set a break point and drop to the Python debugger (pdb):
importpdb;pdb.set_trace()
Set a break point and drop to a Python debugger based on IPython (ipdb):
importipdb;ipdb.set_trace()
Although not technically a debugger (you canât move forward or backward in the stack), this one-liner allows you to start an IPython session when the execution gets to it:
importIPython;IPython.embed()
Note
Everyone seems to have a favorite debugger tool. We find pdb to be too rough (no auto-completion, no syntax highlighting), so we tend to like ipdb better. Donât be surprised if someone comes along with a different debugger! In the end, itâs useful to know how pdb works, as itâs the base needed to be proficient regardless of the debugger. In systems you canât control, use pdb directly because you canât install dependencies; you may not like it, but you can still manage your way around.
How Fast Is this Snippet?
Python has a module to run a piece of code several times over and get some performance metrics from it. Lots of users like to ask if there are efficient ways to handle a loop or update a dictionary, and there are lots of knowledgeable people that love the timeit module to prove performance.
As you have probably seen, we are fans of IPython, and its interactive shell comes with a âmagicâ special function for the timeit module. âMagicâ functions are prefixed with the % character and perform a distinct operation within the shell. An all-time favorite regarding performance is whether list comprehension is faster than just appending to a list. The two examples below use the timeit module to find out:
In[1]:deff(x):...:returnx*x...:In[2]:%timeitforxinrange(100):f(x)100000loops,bestof3:20.3usperloop
In the standard Python shell (or interpreter), you import the module and access it directly. The invocation looks a bit different in this case:
>>>array=[]>>>defappending():...foriinrange(100):...array.append(i)...>>>timeit.repeat("appending()","from __main__ import appending")[5.298534262983594,5.32031941099558,5.359099322988186]>>>timeit.repeat("[i for i in range(100)]")[2.2052824340062216,2.1648171059787273,2.1733458579983562]
The output is a bit odd, but thatâs because itâs meant to be processed by another module or library, and is not meant for human readability. The averages favor the list comprehension. This is how it looks in IPython:
In[1]:defappending():...:array=[]...:foriinrange(100):...:array.append(i)...:In[2]:%timeitappending()5.39µs±95.1nsperloop(mean±std.dev.of7runs,100000loopseach)In[3]:%timeit[iforiinrange(100)]2.1µs±15.2nsperloop(mean±std.dev.of7runs,100000loopseach)
Because IPython exposes timeit as a special command (notice the prefix with %), the output is human readable and more helpful to view, and it doesnât require the weird import, as in the standard Python shell.
strace
The ability to tell how a program is interacting with the operating system becomes crucial when applications arenât logging the interesting parts or not logging at all. Output from strace can be rough, but with some understanding of the basics, it becomes easier to understand what is going on with a problematic application. One time, Alfredo was trying to understand why permission to access a file was being denied. This file was inside of a symlink that seemed to have all the right permissions. What was going on? It was difficult to tell by just looking at logs, since those werenât particularly useful in displaying permissions as they tried to access files.
strace included these two lines in the output:
stat("/var/lib/ceph/osd/block.db", 0x7fd) = -1 EACCES (Permission denied)
lstat("/var/lib/ceph/osd/block.db", {st_mode=S_IFLNK|0777, st_size=22}) = 0
The program was setting ownership on the parent directory, which happened to be a link, and block.db, which in this case was also a link to a block device. The block device itself had the right permissions, so what was the problem? It turns out that the link in the directory had a sticky bit that prevented other links from changing the pathâincluding the block device. The chown tool has a special flag (-h or --no-dereference) to indicate that the change in ownership should also affect the links.
This type of debugging would be difficult (if not impossible) without something like strace. To try it out, create a file called follow.py with the following contents:
importsubprocesssubprocess.call(['ls','-alh'])
It imports the subprocess module to do a system call. It will output the contents of the system call to ls. Instead of a direct call with Python, prefix the command with strace to see what happens:
$ strace python follow.py
A lot of output shouldâve filled the terminal, and probably most of it will look very foreign. Force yourself to go through each line, regardless of whether you understand what is going on. Some lines will be easier to tell apart than others. There are a lot of read and fstat calls; youâll see actual system calls and what the process is doing at each step. There are also open and close operations on some files, and there is a particular section that should show up with a few stat calls:
stat("/home/alfredo/go/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/local/go/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/local/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/home/alfredo/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/local/sbin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/local/bin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/sbin/python", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/bin/python", {st_mode=S_IFREG|0755, st_size=3691008, ...}) = 0
readlink("/usr/bin/python", "python2", 4096) = 7
readlink("/usr/bin/python2", "python2.7", 4096) = 9
readlink("/usr/bin/python2.7", 0x7ff, 4096) = -1 EINVAL (Invalid argument)
stat("/usr/bin/Modules/Setup", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/bin/lib/python2.7/os.py", 0x7ffd) = -1 ENOENT (No such file)
stat("/usr/bin/lib/python2.7/os.pyc", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/lib/python2.7/os.py", {st_mode=S_IFREG|0644, ...}) = 0
stat("/usr/bin/pybuilddir.txt", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/bin/lib/python2.7/lib-dynload", 0x7ff) = -1 ENOENT (No such file)
stat("/usr/lib/python2.7/lib-dynload", {st_mode=S_IFDIR|0755, ...}) = 0
This system is pretty old, and python in the output means python2.7, so it pokes around the filesystem to try and find the right executable. It goes through a few until it reaches /usr/bin/python, which is a link that points to /usr/bin/python2, which in turn is another link that sends the process to /usr/bin/python2.7. It then calls stat on /usr/bin/Modules/Setup, which weâve never heard of as Python developers, only to continue to the os module.
It continues to pybuilddir.txt and lib-dynload. What a trip. Without strace we wouldâve probably tried to read the code that executes this to try and figure out where it goes next. But strace makes this tremendously easier, including all the interesting steps along the way, with useful information for each call.
The tool has many flags that are worth looking into; for example, it can attach itself to a PID. If you know the PID of a process, you can tell strace to produce output on what exactly is going on with it.
One of those useful flags is -f; it will follow child processes as they are created by the initial program. In the example Python file, a call to subprocess is made, and it calls out to ls; if the command to strace is modified to use -f, the output becomes richer, with details about that call.
When follow.py runs in the home directory, there are a quite a few differences with the -f flag. You can see calls to lstat and readlink for the dotfiles (some of which are symlinked):
[pid 30127] lstat(".vimrc", {st_mode=S_IFLNK|0777, st_size=29, ...}) = 0
[pid 30127] lgetxattr(".vimrc", "security.selinux", 0x55c5a36f4720, 255)
[pid 30127] readlink(".vimrc", "/home/alfredo/dotfiles/.vimrc", 30) = 29
[pid 30127] lstat(".config", {st_mode=S_IFDIR|0700, st_size=4096, ...}) = 0
Not only do the calls to these files show, but the PID is prefixed in the output, which helps identify which (child) process is doing what. A call to strace without the -f flag would not show a PID, for example.
Finally, to analyze the output in detail, it can be helpful to save it to a file. This is possible with the -o flag:
$ strace -o output.txt python follow.py
Exercises
-
Define what IOPS is.
-
Explain what the difference is between throughput and IOPS.
-
Name a limitation with
fdiskfor creating partitions thatparteddoesnât have. -
Name three tools that can provide disk information.
-
What can an SSH tunnel do? When is it useful?
Get Python for DevOps now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

