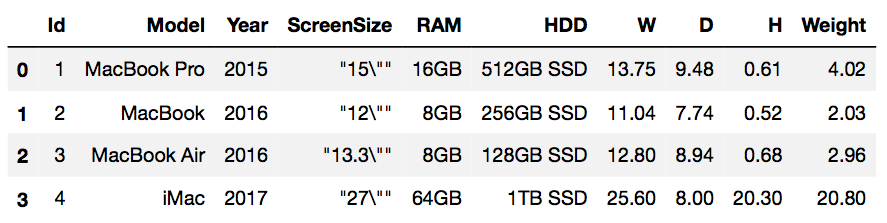
The .toPandas() action, as the name suggests, converts the Spark DataFrame into a pandas DataFrame. The same warning needs to be issued here as with the .collect() action – the .toPandas() action collects all the records from all the workers, returns them to the driver, and then converts the results into a pandas DataFrame.
Since our sample data is tiny, we can do this without any problems:
sample_data_schema.toPandas()
This is what the results look like: