Kapitel 4. Fortgeschrittene Techniken für die Texterstellung mit LangChain
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Mit einfachen Eingabeaufforderungen (Prompt-Engineering) lassen sich die meisten Aufgaben lösen, aber gelegentlich musst du ein leistungsfähigeres Toolkit einsetzen, um komplexe generative KI-Probleme zu lösen. Zu solchen Problemen und Aufgaben gehören:
- Kontext Länge
-
Ein ganzes Buch in einer verdaulichen Synopsis zusammenfassen.
- Kombination von sequentiellen LLM-Eingängen/Ausgängen
-
Eine Geschichte für ein Buch entwickeln, einschließlich der Charaktere, der Handlung und des Aufbaus der Welt.
- Komplexe logische Aufgaben ausführen
-
LLMs, die als Agent agieren. Du könntest zum Beispiel einen LLM-Agenten erstellen, der dir hilft, deine persönlichen Fitnessziele zu erreichen.
Um solche komplexen generativen KI-Herausforderungen gekonnt anzugehen, ist es von großem Vorteil, sich mit LangChain, einem Open-Source-Framework, vertraut zu machen. Dieses Tool vereinfacht und verbessert die Arbeitsabläufe deines LLMs erheblich.
Einführung in LangChain
LangChain ist ein vielseitiges Framework , das die Erstellung von Anwendungen mit LLMs ermöglicht und sowohl als Python- als auch als TypeScript-Paket erhältlich ist. Sein zentraler Grundsatz ist, dass die wirkungsvollsten und individuellsten Anwendungen nicht nur über eine API mit einem Sprachmodell verbunden sind, sondern auch:
- Datenbewusstsein verbessern
-
Das Framework zielt darauf ab, eine nahtlose Verbindung zwischen einem Sprachmodell und externen Datenquellen herzustellen.
- Agentur verbessern
-
Es strebt danach, Sprachmodelle mit der Fähigkeit auszustatten, sich mit ihrer Umwelt auseinanderzusetzen und sie zu beeinflussen.
Das in Abbildung 4-1 dargestellte LangChain-Framework bietet eine Reihe von modularen Abstraktionen, die für die Arbeit mit LLMs unerlässlich sind, sowie eine breite Auswahl an Implementierungen für diese Abstraktionen.
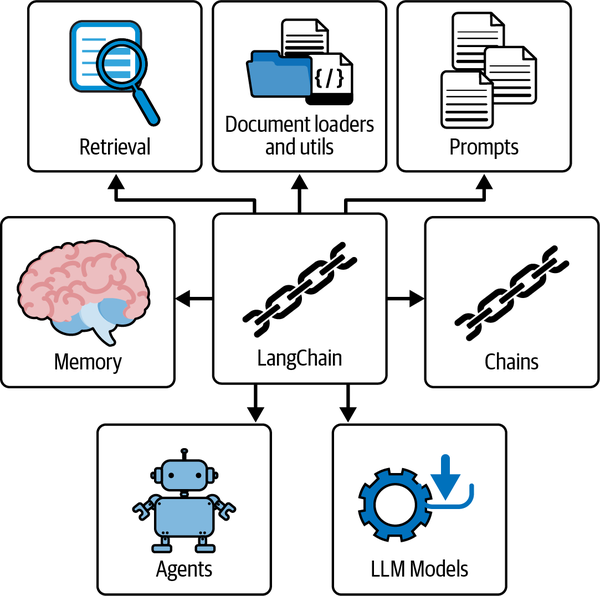
Abbildung 4-1. Die wichtigsten Module des LangChain LLM Frameworks
Jedes Modul ist benutzerfreundlich gestaltet und kann effizient unabhängig oder gemeinsam genutzt werden. Derzeit gibt es sechs gemeinsame Module in LangChain:
- Modell I/O
-
Erledigt Ein-/Ausgabeoperationen im Zusammenhang mit dem Modell
- Abrufen
-
Konzentriert sich auf die Suche nach relevanten Texten für das LLM
- Ketten
-
Auch bekannt als LangChain runnables, ermöglichen Ketten die Konstruktion von Sequenzen von LLM-Operationen oder Funktionsaufrufen
- Agenten
-
Ermöglicht es Ketten, Entscheidungen über die zu verwendenden Werkzeuge auf der Grundlage von übergeordneten Richtlinien oder Anweisungen zu treffen
- Speicher
-
Hält den Zustand einer Anwendung zwischen verschiedenen Läufen einer Kette aufrecht
- Rückrufe
-
Zur Ausführung von zusätzlichem Code bei bestimmten Ereignissen, z. B. wenn ein neues Token erzeugt wird
Umgebung einrichten
Du kannst LangChain mit einem dieser beiden Befehle auf deinem Terminal installieren:
-
pip install langchain langchain-openai -
conda install -c conda-forge langchain langchain-openai
Wenn du lieber die Paketanforderungen für das gesamte Buch installieren möchtest, kannst du die Datei requirements.txt aus dem GitHub-Repository verwenden.
Es wird empfohlen, die Pakete in einer virtuellen Umgebung zu installieren:
- Eine virtuelle Umgebung schaffen
-
python -m venv venv - Aktiviere die virtuelle Umgebung
-
source venv/bin/activate - Installiere die Abhängigkeiten
-
pip install -r requirements.txt
LangChain erfordert Integrationen mit einem oder mehreren Modellanbietern. Um zum Beispiel die Modell-APIs von OpenAI zu nutzen, musst du deren Python-Paket mit pip install openai installieren.
Wie in Kapitel 1 beschrieben, ist es die bewährte Methode, eine Umgebungsvariable namens OPENAI_API_KEY in deinem Terminal zu setzen oder sie aus einer .env-Datei zu laden. python-dotenv. Für das Prototyping kannst du diesen Schritt jedoch auch überspringen, indem du deinen API-Schlüssel direkt beim Laden eines Chatmodells in LangChain angibst:
fromlangchain_openai.chat_modelsimportChatOpenAIchat=ChatOpenAI(api_key="api_key")
Warnung
Das Festcodieren von API-Schlüsseln in Skripten wird aus Sicherheitsgründen nicht empfohlen . Verwende stattdessen Umgebungsvariablen oder Konfigurationsdateien, um deine Schlüssel zu verwalten.
In der sich ständig weiterentwickelnden Landschaft der LLMs kannst du mit der Herausforderung konfrontiert werden, dass die verschiedenen Modell-APIs uneinheitlich sind. Die fehlende Standardisierung der Schnittstellen kann das Prompt-Engineering zusätzlich erschweren und die nahtlose Integration verschiedener Modelle in deine Projekte behindern.
An dieser Stelle kommt LangChain ins Spiel. Als umfassendes Framework ermöglicht es dir LangChain, die unterschiedlichen Schnittstellen der verschiedenen Modelle einfach zu nutzen.
Die Funktionalität von LangChain sorgt dafür, dass du deine Eingabeaufforderungen oder deinen Code nicht jedes Mal neu erfinden musst, wenn du zwischen den Modellen wechselst. Der plattformunabhängige Ansatz von LangChain ermöglicht ein schnelles Experimentieren mit einer breiten Palette von Modellen wie Anthropic, Vertex AI, OpenAI und BedrockChat. Das beschleunigt nicht nur den Prozess der Modellevaluierung, sondern spart auch viel Zeit und Ressourcen, indem es komplexe Modellintegrationen vereinfacht.
In den folgenden Abschnitten wirst du das OpenAI-Paket und seine API in LangChain verwenden.
Chat-Modelle
Chat-Modelle wie GPT-4 sind auf zur wichtigsten Methode geworden, um mit der API von OpenAI zu interagieren. Statt einer einfachen "Eingabe-Text, Ausgabe-Text"-Antwort schlagen sie eine Interaktionsmethode vor, bei der Chat-Nachrichten die Eingabe- und Ausgabeelemente sind.
Um LLM-Antworten mit Hilfe von Chatmodellen zu erzeugen, muss eine oder mehrere Nachrichten in das Chatmodell eingeben. Im Kontext von LangChain sind die derzeit akzeptierten Nachrichtentypen AIMessage, HumanMessage und SystemMessage. Die Ausgabe eines Chat-Modells ist immer ein AIMessage.
- SystemMessage
-
Stellt Informationen dar, die Anweisungen für das KI-System sein sollten. Sie dienen dazu, das Verhalten oder die Aktionen der KI in irgendeiner Weise zu steuern.
- HumanMessage
-
Stellt Informationen dar, die von einem Menschen stammen, der mit dem KI-System interagiert. Dabei kann es sich um eine Frage, einen Befehl oder eine andere Eingabe eines menschlichen Nutzers handeln, die die KI verarbeiten und darauf reagieren muss.
- AIMessage
-
Stellt Informationen dar, die von dem KI-System selbst stammen. Dies ist normalerweise die Antwort der KI auf eine
HumanMessageoder das Ergebnis einerSystemMessageAnweisung.
Hinweis
Achte darauf, dass du die SystemMessage nutzt, um explizite Anweisungen zu übermitteln. OpenAI hat die GPT-4- und die kommenden LLM-Modelle dahingehend verfeinert, dass sie den Richtlinien, die in dieser Art von Nachricht enthalten sind, besondere Aufmerksamkeit schenken.
Lass uns einen Witzegenerator in LangChain erstellen.
Eingabe:
fromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain.schemaimportAIMessage,HumanMessage,SystemMessagechat=ChatOpenAI(temperature=0.5)messages=[SystemMessage(content='''Act as a senior software engineerat a startup company.'''),HumanMessage(content='''Please can you provide a funny jokeabout software engineers?''')]response=chat.invoke(input=messages)(response.content)
Ausgabe:
Sure,here's a lighthearted joke for you:Whydidthesoftwareengineergobroke?Becausehelosthisdomaininabetandcouldn't afford to renew it.
Zuerst importierst du ChatOpenAI, AIMessage, HumanMessage und SystemMessage. Dann erstellst du eine Instanz der Klasse ChatOpenAI mit einem Temperaturparameter von 0,5 (Zufälligkeit).
Nach der Erstellung eines Modells wird eine Liste mit dem Namen messages mit einem SystemMessage Objekt, das die Rolle für den LLM definiert, und einem HumanMessage Objekt, das nach einem Softwareentwicklung-bezogenen Witz fragt, gefüllt.
Wenn du das Chat-Modell mit .invoke(input=messages) aufrufst, wird der LLM mit einer Liste von Nachrichten gefüttert, und du rufst dann die Antwort des LLM mit response.content ab.
Es gibt eine Legacy-Methode, mit der du direkt das chat Objekt mit chat(messages=messages) aufrufen kannst:
response=chat(messages=messages)
Streaming Chat Modelle
Vielleicht hast du auf mit ChatGPT beobachtet, wie die Wörter nacheinander zurückgegeben werden, ein Zeichen nach dem anderen. Dieses ausgeprägte Muster der Antwortgenerierung wird als Streaming bezeichnet und spielt eine entscheidende Rolle bei der Verbesserung der Leistung von chatbasierten Anwendungen:
forchunkinchat.stream(messages):(chunk.content,end="",flush=True)
Wenn du chat.stream(messages) aufrufst, werden Teile der Nachricht nacheinander zurückgegeben. Das bedeutet, dass jedes Segment der Chatnachricht einzeln zurückgegeben wird. Sobald jedes Teilstück ankommt, wird es sofort auf dem Terminal ausgedruckt und geleert. Auf diese Weise sorgt das Streaming für eine minimale Latenzzeit bei deinen LLM-Antworten.
Streaming hat aus Sicht der Endnutzer/innen mehrere Vorteile. Erstens verkürzt es die Wartezeit für die Nutzer drastisch. Sobald der Text Zeichen für Zeichen generiert wird, können die Nutzer/innen mit der Interpretation der Nachricht beginnen. Die Nachricht muss nicht erst vollständig aufgebaut werden, bevor sie zu sehen ist. Das wiederum erhöht die Interaktivität der Nutzer und minimiert die Wartezeit.
Diese Technik bringt jedoch auch eine Reihe von Herausforderungen mit sich. Eine große Herausforderung ist das Analysieren der Ergebnisse, während sie gestreamt werden. Es kann schwierig sein, die Nachricht zu verstehen und angemessen darauf zu reagieren, vor allem, wenn der Inhalt komplex und detailliert ist.
Mehrere LLM-Generationen schaffen
Es kann Szenarien geben, in denen du es nützlich findest , mehrere Antworten von LLMs zu generieren. Das gilt vor allem bei der Erstellung dynamischer Inhalte wie Social Media Posts. Anstatt eine Liste von Nachrichten zu erstellen, stellst du eine Liste von Nachrichtenlisten bereit.
Eingabe:
# 2x lists of messages, which is the same as [messages, messages]synchronous_llm_result=chat.batch([messages]*2)(synchronous_llm_result)
Ausgabe:
[AIMessage(content='''Sure, here's a lighthearted joke for you:\n\nWhy didthe software engineer go broke?\n\nBecause he kept forgetting to Ctrl+ Zhis expenses!'''),AIMessage(content='''Sure, here\'s a lighthearted joke for you:\n\nWhy dosoftware engineers prefer dark mode?\n\nBecause it\'s easier on their"byte" vision!''')]
Der Vorteil der Verwendung von .batch() gegenüber .invoke() ist, dass du die Anzahl der API-Anfragen an OpenAI parallelisieren kannst.
Für jede runnable in LangChain kannst du der Funktion batch ein RunnableConfig Argument hinzufügen, das viele konfigurierbare Parameter enthält, darunter max_concurrency:
fromlangchain_core.runnables.configimportRunnableConfig# Create a RunnableConfig with the desired concurrency limit:config=RunnableConfig(max_concurrency=5)# Call the .batch() method with the inputs and config:results=chat.batch([messages,messages],config=config)
Hinweis
In der Informatik sind asynchrone (async) Funktionen diejenigen , die unabhängig von anderen Prozessen arbeiten und so ermöglichen, dass mehrere API-Anfragen gleichzeitig ausgeführt werden können, ohne aufeinander zu warten. In LangChain ermöglichen diese asynchronen Funktionen, dass du viele API-Anfragen auf einmal stellst und nicht eine nach der anderen. Das ist vor allem bei komplexeren Workflows hilfreich und verringert die Gesamtlatenz für deine Nutzer.
Den meisten asynchronen Funktionen innerhalb von LangChain wird einfach der Buchstabe a vorangestellt, z. B. .ainvoke() und .abatch(). Wenn du die asynchrone API für eine effizientere Aufgabenerfüllung nutzen möchtest, kannst du diese Funktionen unter verwenden.
LangChain Eingabeaufforderungen Templates
Bis zu diesem Punkt hast du die Strings in den ChatOpenAI Objekten fest codiert. Wenn deine LLM-Anwendungen größer werden, wird es immer wichtiger, Eingabeaufforderungen zu verwenden.
Prompt-Vorlagen eignen sich gut, um reproduzierbare Eingabeaufforderungen für KI-Sprachmodelle zu erstellen. Sie bestehen aus einer Vorlage, einem Textstring, der Parameter aufnehmen kann, und konstruieren eine Eingabeaufforderung für ein Sprachmodell.
Ohne Eingabeaufforderungen würdest du wahrscheinlich Python f-string Formatierung verwenden:
language="Python"prompt=f"What is the best way to learn coding in{language}?"(prompt)# What is the best way to learn coding in Python?
Aber warum nicht einfach eine f-string für Eingabeaufforderungen Templating verwenden? Wenn du stattdessen die Eingabeaufforderungen von LangChain verwendest, kannst du ganz einfach:
-
Bestätige deine Eingabeaufforderungen
-
Kombiniere mehrere Eingabeaufforderungen mit der Komposition
-
Definiere eigene Selektoren, die k-shot Beispiele in deine Eingabeaufforderung einfügen
-
Eingabeaufforderungen aus .yml- und .json-Dateien speichern und laden
-
Eigene Templates für Eingabeaufforderungen erstellen, die zusätzlichen Code oder Anweisungen ausführen, wenn sie erstellt werden
LangChain Expression Language (LCEL)
Der | Pipe-Operator ist eine Schlüsselkomponente der LangChain Expression Language (LCEL), mit der du verschiedene Komponenten oder Runnables in einer Datenverarbeitungspipeline miteinander verknüpfen kannst.
In LCEL ähnelt der | Operator dem Unix Pipe Operator. Er nimmt die Ausgabe einer Komponente und leitet sie als Eingabe an die nächste Komponente in der Kette weiter. So kannst du ganz einfach verschiedene Komponenten miteinander verbinden und kombinieren, um eine komplexe Kette von Operationen zu erstellen:
chain=prompt|model
Der | Operator wird verwendet, um die Eingabeaufforderung und die Modellkomponente miteinander zu verknüpfen. Die Ausgabe der Eingabeaufforderung wird als Eingabe an die Modellkomponente weitergegeben. Mit diesem Verkettungsmechanismus kannst du komplexe Ketten aus Basiskomponenten aufbauen und einen nahtlosen Datenfluss zwischen den verschiedenen Stufen der Verarbeitungspipeline ermöglichen.
Außerdem spielt die Reihenfolge eine Rolle, du könntest also technisch gesehen diese Kette erstellen:
bad_order_chain=model|prompt
Nach der Verwendung der Funktion invoke würde jedoch ein Fehler auftreten, weil die von model zurückgegebenen Werte nicht mit den erwarteten Eingaben für die Eingabeaufforderung kompatibel sind.
Wir erstellen einen Generator für Unternehmensnamen mit Eingabeaufforderungen, der fünf bis sieben relevante Unternehmensnamen liefert:
fromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain_core.promptsimport(SystemMessagePromptTemplate,ChatPromptTemplate)template="""You are a creative consultant brainstorming names for businesses.You must follow the following principles:{principles}Please generate a numerical list of five catchy names for a start-up in the{industry}industry that deals with{context}?Here is an example of the format:1. Name12. Name23. Name34. Name45. Name5"""model=ChatOpenAI()system_prompt=SystemMessagePromptTemplate.from_template(template)chat_prompt=ChatPromptTemplate.from_messages([system_prompt])chain=chat_prompt|modelresult=chain.invoke({"industry":"medical","context":'''creating AI solutions by automatically summarizing patientrecords''',"principles":'''1. Each name should be short and easy toremember. 2. Each name should be easy to pronounce.3. Each name should be unique and not already taken by another company.'''})(result.content)
Ausgabe:
1. SummarAI 2. MediSummar 3. AutoDocs 4. RecordAI 5. SmartSummarize
Zuerst importierst du ChatOpenAI, SystemMessagePromptTemplate und ChatPromptTemplate. Dann definierst du unter template eine Eingabeaufforderungsvorlage mit bestimmten Richtlinien, die den LLM anweisen, Geschäftsnamen zu generieren. ChatOpenAI() initialisiert den Chat, während SystemMessagePromptTemplate.from_template(template) und ChatPromptTemplate.from_messages([system_prompt]) deine Eingabeaufforderungsvorlage erstellen.
Du erstellst eine LCEL chain, indem du chat_prompt und die Funktion model zusammenfügst, die dann aufgerufen wird. Dadurch werden die Platzhalter {industries}, {context} und {principles} in der Eingabeaufforderung durch die Wörterbuchwerte in der Funktion invoke ersetzt.
Schließlich extrahierst du die Antwort des LLM als String, indem du auf die Eigenschaft .content der Variablen result zugreifst.
Anweisungen geben und Format vorgeben
Sorgfältig ausgearbeitete Anweisungen könnten Dinge beinhalten wie "Du bist ein kreativer Berater, der Namen für Unternehmen ausdenkt" und "Bitte erstelle eine numerische Liste mit fünf bis sieben einprägsamen Namen für ein Start-up." Hinweise wie diese leiten deinen LLM dazu an, genau die Aufgabe zu erfüllen, die du von ihm verlangst.
Verwendung von PromptTemplate mit Chat-Modellen
LangChain bietet eine traditionellere Vorlage namens PromptTemplate, die input_variables und template Argumente benötigt.
Eingabe:
fromlangchain_core.promptsimportPromptTemplatefromlangchain.prompts.chatimportSystemMessagePromptTemplatefromlangchain_openai.chat_modelsimportChatOpenAIprompt=PromptTemplate(template='''You are a helpful assistant that translates{input_language}to{output_language}.''',input_variables=["input_language","output_language"],)system_message_prompt=SystemMessagePromptTemplate(prompt=prompt)chat=ChatOpenAI()chat.invoke(system_message_prompt.format_messages(input_language="English",output_language="French"))
Ausgabe:
AIMessage(content="Vous êtes un assistant utile qui traduit l'anglais enfrançais.", additional_kwargs={}, example=False)
Ausgabe-Parser
In Kapitel 3 hast du reguläre Ausdrücke (regex) verwendet, um strukturierte Daten aus Text zu extrahieren, der numerische Listen enthielt, aber es ist auch möglich, dies in LangChain automatisch mit Ausgabeparsern zu tun.
Output-Parser sind eine übergeordnete Abstraktion, die von LangChain zur Verfügung gestellt wird, um strukturierte Daten aus LLM-String-Antworten zu parsen. Derzeit sind die folgenden Output-Parser verfügbar:
- Listenparser
- Datetime Parser
- Enum-Parser
- Selbstkorrigierender Parser
-
Wickelt einen anderen Ausgabeparser ein. Wenn dieser Ausgabeparser fehlschlägt, ruft er einen anderen LLM auf, um alle Fehler zu beheben.
- Pydantic (JSON) Parser
-
Parst LLM-Antworten in eine JSON-Ausgabe, die mit einem Pydantic-Schema konform ist.
- Parser wiederholen
-
Ermöglicht die Wiederholung eines fehlgeschlagenen Parsers von einem früheren Ausgabeparser.
- Parser für strukturierte Ausgabe
-
Kann verwendet werden, wenn du mehrere Felder zurückgeben möchtest.
- XML-Parser
Wie du entdecken wirst, gibt es zwei wichtige Funktionen für LangChain-Ausgabeparser:
.get_format_instructions()-
Diese Funktion gibt die notwendigen Anweisungen in deine Eingabeaufforderung ein, um ein strukturiertes Format auszugeben, das geparst werden kann.
.parse(llm_output: str)-
Diese Funktion ist für das Parsen deiner LLM-Antworten in ein vordefiniertes Format verantwortlich.
Im Allgemeinen wirst du feststellen, dass der Pydantic (JSON) Parser mit ChatOpenAI() die größte Flexibilität bietet.
Der Pydantic (JSON)-Parser nutzt die Vorteile der Pydantic-Bibliothek in Python. Pydantic ist eine Bibliothek zur Datenvalidierung, mit der eingehende Daten mithilfe von Python-Typ-Annotationen validiert werden können. Das bedeutet, dass du mit Pydantic Schemata für deine Daten erstellen kannst und die Eingabedaten automatisch nach diesen Schemata validiert und geparst werden.
Eingabe:
fromlangchain_core.prompts.chatimport(ChatPromptTemplate,SystemMessagePromptTemplate,)fromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain.output_parsersimportPydanticOutputParserfrompydantic.v1importBaseModel,FieldfromtypingimportListtemperature=0.0classBusinessName(BaseModel):name:str=Field(description="The name of the business")rating_score:float=Field(description='''The rating score of thebusiness. 0 is the worst, 10 is the best.''')classBusinessNames(BaseModel):names:List[BusinessName]=Field(description='''A listof busines names''')# Set up a parser + inject instructions into the prompt template:parser=PydanticOutputParser(pydantic_object=BusinessNames)principles="""- The name must be easy to remember.- Use the{industry}industry and Company context to create an effective name.- The name must be easy to pronounce.- You must only return the name without any other text or characters.- Avoid returning full stops,\n, or any other characters.- The maximum length of the name must be 10 characters."""# Chat Model Output Parser:model=ChatOpenAI()template="""Generate five business names for a new start-up company in the{industry}industry.You must follow the following principles:{principles}{format_instructions}"""system_message_prompt=SystemMessagePromptTemplate.from_template(template)chat_prompt=ChatPromptTemplate.from_messages([system_message_prompt])# Creating the LCEL chain:prompt_and_model=chat_prompt|modelresult=prompt_and_model.invoke({"principles":principles,"industry":"Data Science","format_instructions":parser.get_format_instructions(),})# The output parser, parses the LLM response into a Pydantic object:(parser.parse(result.content))
Ausgabe:
names=[BusinessName(name='DataWiz',rating_score=8.5),BusinessName(name='InsightIQ',rating_score=9.2),BusinessName(name='AnalytiQ',rating_score=7.8),BusinessName(name='SciData',rating_score=8.1),BusinessName(name='InfoMax',rating_score=9.5)]
Nachdem du die notwendigen Bibliotheken geladen hast, richtest du ein ChatOpenAI-Modell ein. Dann erstellst du SystemMessagePromptTemplate aus deiner Vorlage und bildest damit ein ChatPromptTemplate. Du verwendest die Pydantic-Modelle BusinessName und BusinessNames, um die gewünschte Ausgabe zu strukturieren, eine Liste mit eindeutigen Unternehmensnamen. Du erstellst einen Pydantic Parser zum Parsen dieser Modelle und formatierst die Eingabeaufforderung mit Hilfe von Variablen, die vom Benutzer eingegeben wurden, indem du die Funktion invoke aufrufst. Wenn du diese angepasste Eingabeaufforderung an dein Modell weitergibst, kannst du mit Hilfe der Funktion parser kreative, einzigartige Unternehmensnamen erstellen.
Mit dieser Syntax ist es möglich, Output-Parser innerhalb von LCEL zu verwenden:
chain=prompt|model|output_parser
Fügen wir den Ausgabeparser direkt in die Kette ein.
Eingabe:
parser=PydanticOutputParser(pydantic_object=BusinessNames)chain=chat_prompt|model|parserresult=chain.invoke({"principles":principles,"industry":"Data Science","format_instructions":parser.get_format_instructions(),})(result)
Ausgabe:
names=[BusinessName(name='DataTech', rating_score=9.5),...]
Die Kette ist nun für die Eingabeaufforderung, den Aufruf des LLM und das Parsen der Antwort des LLM in ein Pydantic Objekt verantwortlich.
Format angeben
Die vorangegangenen Eingabeaufforderungen verwenden Pydantic-Modelle und Ausgabeparser, mit denen du einem LLM dein gewünschtes Antwortformat explizit mitteilen kannst.
Wenn du einen LLM aufforderst, eine strukturierte JSON-Ausgabe zu liefern, kannst du eine flexible und verallgemeinerbare API aus der Antwort des LLM erstellen. Es gibt zwar einige Einschränkungen, z. B. in Bezug auf die Größe des erzeugten JSON und die Zuverlässigkeit deiner Eingabeaufforderungen, aber es ist dennoch ein vielversprechender Bereich für LLM-Anwendungen.
Warnung
Du solltest auch auf Kanten achten und Anweisungen zur Fehlerbehandlung hinzufügen, da die LLM-Ausgaben möglicherweise nicht immer das gewünschte Format haben.
Output-Parser ersparen dir die Komplexität und Kompliziertheit von regulären Ausdrücken und bieten benutzerfreundliche Funktionen für eine Vielzahl von Anwendungsfällen. Nachdem du sie nun in Aktion gesehen hast, kannst du Output-Parser nutzen, um die Daten, die du brauchst, mühelos zu strukturieren und aus der Ausgabe eines LLM abzurufen und so das volle Potenzial der KI für deine Aufgaben zu nutzen.
Außerdem kannst du mithilfe von Parsern die aus LLMs extrahierten Daten strukturieren, um die Ausgaben für effizienter zu gestalten. Das kann nützlich sein, wenn du mit umfangreichen Listen zu tun hast und sie nach bestimmten Kriterien sortieren musst, z. B. nach Firmennamen.
LangChain Evals
Die meisten KI-Systeme verwenden nicht nur Output-Parser, um auf Formatierungsfehler zu überprüfen, sondern auch Evals oder Bewertungsmetriken, um die Leistung jeder Eingabeaufforderung zu messen. LangChain bietet eine Reihe von Standardauswertungen an, die direkt in der LangSmith-Plattform für weitere Fehlersuche, Überwachung und Tests gespeichert werden können. Weights and Biases ist eine alternative Plattform für maschinelles Lernen, die ähnliche Funktionen und Nachverfolgungsmöglichkeiten für LLMs bietet.
Bewertungsmetriken sind für nicht nur für Eingabeaufforderungen nützlich, da sie dazu verwendet werden können, positive und negative Beispiele für die Abfrage zu identifizieren und Datensätze für die Feinabstimmung eigener Modelle zu erstellen.
Die meisten Bewertungskennzahlen beruhen auf einer Reihe von Testfällen, d.h. Eingabe- und Ausgabepaaren, bei denen du die richtige Antwort kennst. Oft werden diese Referenzantworten manuell von einem Menschen erstellt oder kuratiert, aber es ist auch üblich, ein intelligenteres Modell wie GPT-4 zu verwenden, um die Ground-Truth-Antworten zu generieren, was wir im folgenden Beispiel getan haben. Ausgehend von einer Liste mit Beschreibungen von Finanztransaktionen haben wir GPT-4 verwendet, um jede Transaktion mit einer transaction_category und transaction_type zu klassifizieren. Der Prozess kann im langchain-evals.ipynb Jupyter Notebook im GitHub Repository für das Buch nachgelesen werden.
Da die GPT-4-Antwort als die richtige Antwort gilt, ist es jetzt möglich, die Genauigkeit kleinerer Modelle wie GPT-3.5-turbo und Mixtral 8x7b (in der API mistral-small genannt) zu bewerten. Wenn du mit einem kleineren Modell eine ausreichend gute Genauigkeit erreichst, kannst du Geld sparen oder die Latenzzeit verringern. Wenn das Modell wie das von Mistral als Open Source verfügbar ist, kannst du diese Aufgabe auf deine eigenen Server migrieren und so vermeiden, dass potenziell sensible Daten außerhalb deines Unternehmens gesendet werden. Wir empfehlen, zunächst mit einer externen API zu testen, bevor du dir die Mühe machst, ein Betriebssystemmodell selbst zu hosten.
Erinnere dich daran, dich anzumelden und zu abonnieren, um einen API-Schlüssel zu erhalten, den du dann als Umgebungsvariable in deinem Terminal eingibst:
export MISTRAL_API_KEY=api-key
Das folgende Skript ist Teil eines Notizbuchs, das zuvor einen Datenrahmen df definiert hat. Aus Gründen der Kürze untersuchen wir nur den Auswertungsabschnitt des Skripts, wobei wir davon ausgehen, dass bereits ein Datenrahmen definiert ist.
Eingabe:
importosfromlangchain_mistralai.chat_modelsimportChatMistralAIfromlangchain.output_parsersimportPydanticOutputParserfromlangchain_core.promptsimportChatPromptTemplatefrompydantic.v1importBaseModelfromtypingimportLiteral,Unionfromlangchain_core.output_parsersimportStrOutputParser# 1. Define the model:mistral_api_key=os.environ["MISTRAL_API_KEY"]model=ChatMistralAI(model="mistral-small",mistral_api_key=mistral_api_key)# 2. Define the prompt:system_prompt="""You are are an expert at analyzingbank transactions, you will be categorizing a singletransaction.Always return a transaction type and category:do not return None.Format Instructions:{format_instructions}"""user_prompt="""Transaction Text:{transaction}"""prompt=ChatPromptTemplate.from_messages([("system",system_prompt,),("user",user_prompt,),])# 3. Define the pydantic model:classEnrichedTransactionInformation(BaseModel):transaction_type:Union[Literal["Purchase","Withdrawal","Deposit","Bill Payment","Refund"],None]transaction_category:Union[Literal["Food","Entertainment","Transport","Utilities","Rent","Other"],None,]# 4. Define the output parser:output_parser=PydanticOutputParser(pydantic_object=EnrichedTransactionInformation)# 5. Define a function to try to fix and remove the backslashes:defremove_back_slashes(string):# double slash to escape the slashcleaned_string=string.replace("\\","")returncleaned_string# 6. Create an LCEL chain that fixes the formatting:chain=prompt|model|StrOutputParser()\|remove_back_slashes|output_parsertransaction=df.iloc[0]["Transaction Description"]result=chain.invoke({"transaction":transaction,"format_instructions":\output_parser.get_format_instructions(),})# 7. Invoke the chain for the whole dataset:results=[]fori,rowintqdm(df.iterrows(),total=len(df)):transaction=row["Transaction Description"]try:result=chain.invoke({"transaction":transaction,"format_instructions":\output_parser.get_format_instructions(),})except:result=EnrichedTransactionInformation(transaction_type=None,transaction_category=None)results.append(result)# 8. Add the results to the dataframe, as columns transaction type and# transaction category:transaction_types=[]transaction_categories=[]forresultinresults:transaction_types.append(result.transaction_type)transaction_categories.append(result.transaction_category)df["mistral_transaction_type"]=transaction_typesdf["mistral_transaction_category"]=transaction_categoriesdf.head()
Ausgabe:
Transaction Description transaction_type transaction_category mistral_transaction_type mistral_transaction_category 0 cash deposit at local branch Deposit Other Deposit Other 1 cash deposit at local branch Deposit Other Deposit Other 2 withdrew money for rent payment Withdrawal Rent Withdrawal Rent 3 withdrew cash for weekend expenses Withdrawal Other Withdrawal Other 4 purchased books from the bookstore Purchase Other Purchase Entertainment
Der Code macht Folgendes:
-
from langchain_mistralai.chat_models import ChatMistralAI: Wir importieren die Mistral-Implementierung von LangChain. -
from langchain.output_parsers import PydanticOutputParser: Importiert die KlassePydanticOutputParser, die zum Parsen von Ausgaben mit Pydantic-Modellen verwendet wird. Wir importieren auch einen String-Output-Parser, um einen Zwischenschritt zu bewältigen, bei dem wir Backslashes aus dem JSON-Schlüssel entfernen (ein häufiges Problem bei Antworten von Mistral). -
mistral_api_key = os.environ["MISTRAL_API_KEY"]: Holt den Mistral-API-Schlüssel aus den Umgebungsvariablen ab. Dieser muss vor dem Ausführen des Notizbuchs gesetzt werden. -
model = ChatMistralAI(model="mistral-small", mistral_api_key=mistral_api_key): Initialisiert eine Instanz vonChatMistralAImit dem angegebenen Modell und API-Schlüssel. Mistral Small ist das, was sie in ihrer API als Mixtral 8x7b Modell bezeichnen (auch als Open Source verfügbar). -
system_promptunduser_prompt: Diese Zeilen definieren Templates für die System- und Eingabeaufforderungen, die im Chat zur Klassifizierung der Transaktionen verwendet werden. -
class EnrichedTransactionInformation(BaseModel): Definiert ein Pydantic-ModellEnrichedTransactionInformationmit zwei Feldern:transaction_typeundtransaction_category, die jeweils bestimmte zulässige Werte haben und die Möglichkeit,Nonezu sein. Daran erkennen wir, ob die Ausgabe im richtigen Format erfolgt. -
def remove_back_slashes(string): Definiert eine Funktion zum Entfernen von Backslashes aus einer Zeichenkette. -
chain = prompt | model | StrOutputParser() | remove_back_slashes | output_parser: Aktualisiert die Kette und fügt einen String-Output-Parser und die Funktionremove_back_slashesvor dem ursprünglichen Output-Parser ein. -
transaction = df.iloc[0]["Transaction Description"]: Extrahiert die erste Transaktionsbeschreibung aus einem Datenrahmendf. Dieser Datenrahmen wird zuvor in das Jupyter Notebook geladen (der Kürze halber weggelassen). -
for i, row in tqdm(df.iterrows(), total=len(df)): Iteriert über jede Zeile im Datenrahmendf, mit einem Fortschrittsbalken. -
result = chain.invoke(...): Innerhalb der Schleife wird die Kette für jede Transaktion aufgerufen. -
except: Im Falle einer Ausnahme wird ein StandardEnrichedTransactionInformationObjekt mitNoneWerten erstellt. Diese werden bei der Auswertung als Fehler behandelt, unterbrechen aber nicht die Verarbeitungsschleife. -
df["mistral_transaction_type"] = transaction_typesdf["mistral_transaction_category"] = transaction_categories: Fügt die Transaktionsarten und Kategorien als neue Spalten in den Datenrahmen ein, die wir dann mit anzeigen.df.head()
Wenn die Antworten von Mistral im Datenrahmen gespeichert sind, können sie mit den zuvor definierten Transaktionskategorien und -typen verglichen werden, um die Genauigkeit von Mistral zu überprüfen. Die grundlegendste LangChain-Evaluierungsmetrik besteht darin, eine exakte String-Übereinstimmung einer Vorhersage mit einer Referenzantwort durchzuführen, die im Falle einer korrekten Antwort eine 1 und im Falle einer falschen Antwort eine 0 ergibt. Das Notizbuch enthält ein Beispiel für die Umsetzung dieser Methode, das zeigt, dass die Genauigkeit von Mistral 77,5 % beträgt. Wenn du jedoch nur Zeichenketten vergleichst, musst du dies wahrscheinlich nicht in LangChain implementieren.
Der Wert von LangChain liegt in den standardisierten und getesteten Ansätzen zur Implementierung von fortgeschrittenen Auswertern mit LLMs. Der Bewerter labeled_pairwise_string vergleicht zwei Ergebnisse und begründet die Wahl zwischen ihnen, indem er GPT-4 verwendet. Ein häufiger Anwendungsfall für diese Art von Auswerter ist der Vergleich der Ergebnisse von zwei verschiedenen Eingabeaufforderungen oder Modellen, vor allem wenn die zu testenden Modelle weniger anspruchsvoll sind als GPT-4. Dieser Auswerter, der GPT-4 verwendet, funktioniert zwar auch für die Auswertung von GPT-4-Antworten, aber du solltest die Argumentation und die Bewertungen manuell überprüfen, um sicherzugehen, dass er gute Arbeit leistet: Wenn GPT-4 bei einer Aufgabe schlecht ist, kann es auch bei der Auswertung dieser Aufgabe schlecht sein. Im Notizbuch wurde dieselbe Klassifizierung der Vorgänge noch einmal durchgeführt, wobei das Modell auf model = ChatOpenAI(model="gpt-3.5-turbo-1106", model_kwargs={"response_format": {"type": "json_object"}},) geändert wurde. Jetzt ist es möglich, die Antworten von Mistral und GPT-3.5 paarweise zu vergleichen, wie im folgenden Beispiel gezeigt. In der Ausgabe kannst du sehen, wie die Bewertung begründet wird.
Eingabe:
# Evaluate answers using LangChain evaluators:fromlangchain.evaluationimportload_evaluatorevaluator=load_evaluator("labeled_pairwise_string")row=df.iloc[0]transaction=row["Transaction Description"]gpt3pt5_category=row["gpt3.5_transaction_category"]gpt3pt5_type=row["gpt3.5_transaction_type"]mistral_category=row["mistral_transaction_category"]mistral_type=row["mistral_transaction_type"]reference_category=row["transaction_category"]reference_type=row["transaction_type"]# Put the data into JSON format for the evaluator:gpt3pt5_data=f"""{{"transaction_category": "{gpt3pt5_category}","transaction_type": "{gpt3pt5_type}"}}"""mistral_data=f"""{{"transaction_category": "{mistral_category}","transaction_type": "{mistral_type}"}}"""reference_data=f"""{{"transaction_category": "{reference_category}","transaction_type": "{reference_type}"}}"""# Set up the prompt input for context for the evaluator:input_prompt="""You are an expert at analyzing banktransactions,you will be categorizing a single transaction.Always return a transaction type and category: do notreturn None.Format Instructions:{format_instructions}Transaction Text:{transaction}"""transaction_types.append(transaction_type_score)transaction_categories.append(transaction_category_score)accuracy_score=0fortransaction_type_score,transaction_category_score\inzip(transaction_types,transaction_categories):accuracy_score+=transaction_type_score['score']+\transaction_category_score['score']accuracy_score=accuracy_score/(len(transaction_types)\*2)(f"Accuracy score:{accuracy_score}")evaluator.evaluate_string_pairs(prediction=gpt3pt5_data,prediction_b=mistral_data,input=input_prompt.format(format_instructions=output_parser.get_format_instructions(),transaction=transaction),reference=reference_data,)
Ausgabe:
{'reasoning': '''Both Assistant A and Assistant B provided the exact same
response to the user\'s question. Their responses are both helpful, relevant,
correct, and demonstrate depth of thought. They both correctly identified the
transaction type as "Deposit" and the transaction category as "Other" based on
the transaction text provided by the user. Both responses are also
well-formatted according to the JSON schema provided by the user. Therefore,
it\'s a tie between the two assistants. \n\nFinal Verdict: [[C]]''',
'value': None,
'score': 0.5}
Dieser Code demonstriert den einfachen exakten String Matching Evaluator von LangChain:
-
evaluator = load_evaluator("labeled_pairwise_string"): Dies ist eine Hilfsfunktion, mit der jeder LangChain-Auswerter nach seinem Namen geladen werden kann. In diesem Fall ist es derlabeled_pairwise_stringEvaluator, der verwendet wird. -
row = df.iloc[0]: Diese Zeile und die sieben folgenden Zeilen holen die erste Zeile und extrahieren die Werte für die verschiedenen benötigten Spalten. Sie enthalten die Transaktionsbeschreibung sowie die Mistral- und GPT-3.5-Transaktionskategorie und -typen. Hier wird nur eine einzige Transaktion gezeigt, aber dieser Code kann leicht in einer Schleife durch jede Transaktion laufen, indem du diese Zeile durch eineiterrowsFunktionfor i, row in tqdm(df.iterrows(), total=len(df)):ersetzst, wie es später im Notizbuch gemacht wird. -
gpt3pt5_data = f"""{{: Um den paarweisen Vergleichsauswerter zu nutzen, müssen wir die Ergebnisse so übergeben, dass sie für die Eingabeaufforderung richtig formatiert sind. Dies geschieht für Mistral und GPT-3.5 sowie für die Referenzdaten. -
input_prompt = """You are an expert...: Die andere Formatierung, die wir richtig hinbekommen müssen, ist die Eingabeaufforderung. Um genaue Bewertungen zu erhalten, muss der Bewerter die Anweisungen sehen, die für die Aufgabe gegeben wurden. -
evaluator.evaluate_string_pairs(...: Alles, was bleibt, ist, den Evaluator auszuführen, indem du diepredictionundprediction_b(GPT-3.5 bzw. Mistral) sowie die Eingabeaufforderunginputund diereferenceDaten, die als Grundwahrheit dienen, eingibst. -
Im Anschluss an diesen Code im Notizbuch gibt es ein Beispiel für das Durchlaufen einer Schleife und das Ausführen des Evaluators für jede Zeile im Datenrahmen und das anschließende Speichern der Ergebnisse und Rückschlüsse auf den Datenrahmen.
Dieses Beispiel zeigt, wie einen LangChain-Auswerter verwendet, aber es gibt viele verschiedene Arten von Auswertern. String-Distanz-(Levenshtein) oder Embedding-Distanz-Auswerter werden häufig in Szenarien verwendet, in denen die Antworten nicht exakt mit der Referenzantwort übereinstimmen, sondern nur semantisch nahe genug sein müssen. Die Levenshtein-Distanz ermöglicht unscharfe Übereinstimmungen, die darauf basieren, wie viele Änderungen an einzelnen Zeichen erforderlich wären, um den vorhergesagten Text in den Referenztext zu verwandeln. Die Einbettungsdistanz verwendet Vektoren (siehe Kapitel 5), um die Ähnlichkeit zwischen Antwort und Referenz zu berechnen.
Die andere Art der Auswertung, die wir auf häufig verwenden, sind paarweise Vergleiche, die nützlich sind, um zwei verschiedene Eingabeaufforderungen oder Modelle zu vergleichen, wobei ein intelligenteres Modell wie GPT-4 verwendet wird. Diese Art von Vergleich ist hilfreich, weil für jeden Vergleich eine Begründung geliefert wird, die bei der Fehlersuche hilfreich sein kann, warum ein Ansatz gegenüber einem anderen bevorzugt wurde. Das Notebook für diesen Abschnitt zeigt ein Beispiel für die Verwendung eines paarweisen Vergleichs, um die Genauigkeit von GPT-3.5-turbo gegenüber Mixtral 8x7b zu überprüfen.
Qualität evaluieren
Ohne die Festlegung geeigneter Bewertungskennzahlen zur Definition des Erfolgs kann es schwierig sein, festzustellen, ob Änderungen an der Eingabeaufforderung oder am weiteren System die Qualität der Antworten verbessern oder beeinträchtigen. Wenn du die Auswertung mit intelligenten Modellen wie GPT-4 automatisieren kannst, kannst du die Ergebnisse schneller verbessern, ohne dass eine kostspielige oder zeitaufwändige manuelle Überprüfung erforderlich ist.
OpenAI Funktionsaufruf
Der Funktionsaufruf bietet eine alternative Methode zur Ausgabe von Parsern, die auf fein abgestimmte OpenAI-Modelle zurückgreift. Diese Modelle erkennen, wann eine Funktion ausgeführt werden sollte und erzeugen eine JSON-Antwort mit dem Namen und den Argumenten für eine vordefinierte Funktion. Es gibt mehrere Anwendungsfälle:
- Hochentwickelte Chatbots entwerfen
-
Kann Zeitpläne organisieren und verwalten. Du kannst zum Beispiel eine Funktion zur Planung eines Meetings definieren:
schedule_meeting(date: str, time: str, attendees: List[str]). - Natürliche Sprache in umsetzbare API-Aufrufe umwandeln
-
Ein Befehl wie "Schalte das Licht im Flur ein" kann in
control_device(device: str, action: 'on' | 'off')umgewandelt werden, um mit deiner Hausautomatisierungs-API zu interagieren. - Strukturierte Daten extrahieren
-
Dies könnte durch die Definition einer Funktion wie
extract_contextual_data(context: str, data_points: List[str])odersearch_database(query: str)geschehen.
Jede Funktion, die du innerhalb der Funktion aufrufst, benötigt ein entsprechendes JSON-Schema. Schauen wir uns ein Beispiel mit dem Paket OpenAI an:
fromopenaiimportOpenAIimportjsonfromosimportgetenvdefschedule_meeting(date,time,attendees):# Connect to calendar service:return{"event_id":"1234","status":"Meeting scheduled successfully!","date":date,"time":time,"attendees":attendees}OPENAI_FUNCTIONS={"schedule_meeting":schedule_meeting}
Nachdem du OpenAI und json importiert hast, erstellst du eine Funktion namens schedule_meeting. Diese Funktion ist eine Attrappe, die den Prozess der Planung eines Meetings simuliert und Details wie event_id, date, time und attendees zurückgibt. Anschließend erstellst du ein OPENAI_FUNCTIONS Wörterbuch, um den Funktionsnamen der tatsächlichen Funktion zuzuordnen, damit du sie leichter finden kannst.
Als nächstes definierst du eine functions Liste, die das JSON-Schema der Funktion enthält. Dieses Schema enthält den Namen der Funktion, eine kurze Beschreibung und die erforderlichen Parameter, um dem LLM zu zeigen, wie er mit der Funktion umgehen soll:
# Our predefined function JSON schema:functions=[{"type":"function","function":{"type":"object","name":"schedule_meeting","description":'''Set a meeting at a specified date and time fordesignated attendees''',"parameters":{"type":"object","properties":{"date":{"type":"string","format":"date"},"time":{"type":"string","format":"time"},"attendees":{"type":"array","items":{"type":"string"}},},"required":["date","time","attendees"],},},}]
Format angeben
Wenn du Funktionsaufrufe mit in deinen OpenAI-Modellen verwendest, solltest du immer ein detailliertes JSON-Schema definieren (einschließlich Name und Beschreibung). Dieses dient als Blaupause für die Funktion und hilft dem Modell zu verstehen, wann und wie es die Funktion richtig aufruft.
Nachdem wir die Funktionen definiert haben, können wir eine OpenAI API-Anfrage stellen. Richte eine messages Liste mit der Benutzeranfrage ein. Dann schickst du diese Nachricht und das Funktionsschema mit einem OpenAI client Objekt an das Modell. Der LLM analysiert die Konversation, stellt fest, dass eine Funktion ausgelöst werden muss, und liefert den Funktionsnamen und die Argumente. Die function und function_args werden aus der LLM-Antwort geparst. Dann wird die Funktion ausgeführt und ihre Ergebnisse werden wieder in die Konversation eingefügt. Anschließend rufst du das Modell erneut auf, um eine benutzerfreundliche Zusammenfassung des gesamten Prozesses zu erhalten.
Eingabe:
client=OpenAI(api_key=getenv("OPENAI_API_KEY"))# Start the conversation:messages=[{"role":"user","content":'''Schedule a meeting on 2023-11-01 at 14:00with Alice and Bob.''',}]# Send the conversation and function schema to the model:response=client.chat.completions.create(model="gpt-3.5-turbo-1106",messages=messages,tools=functions,)response=response.choices[0].message# Check if the model wants to call our function:ifresponse.tool_calls:# Get the first function call:first_tool_call=response.tool_calls[0]# Find the function name and function args to call:function_name=first_tool_call.function.namefunction_args=json.loads(first_tool_call.function.arguments)("This is the function name: ",function_name)("These are the function arguments: ",function_args)function=OPENAI_FUNCTIONS.get(function_name)ifnotfunction:raiseException(f"Function{function_name}not found.")# Call the function:function_response=function(**function_args)# Share the function's response with the model:messages.append({"role":"function","name":"schedule_meeting","content":json.dumps(function_response),})# Let the model generate a user-friendly response:second_response=client.chat.completions.create(model="gpt-3.5-turbo-0613",messages=messages)(second_response.choices[0].message.content)
Ausgabe:
Thesearethefunctionarguments:{'date':'2023-11-01','time':'14:00','attendees':['Alice','Bob']}Thisisthefunctionname:schedule_meetingIhavescheduledameetingon2023-11-01at14:00withAliceandBob.TheeventIDis1234.
Beim Funktionsaufruf sind einige wichtige Punkte zu beachten:
-
Es ist möglich, viele Funktionen zu haben, die der LLM aufrufen kann.
-
OpenAI kann Funktionsparameter verdrehen, also sei in der
systemNachricht expliziter, um dies zu vermeiden. -
Der Parameter
function_callkann auf verschiedene Arten eingestellt werden:-
Um einen bestimmten Funktionsaufruf zu beauftragen:
tool_choice: {"type: "function", "function": {"name": "my_function"}}}. -
Für eine Benutzernachricht ohne Funktionsaufruf:
tool_choice: "none". -
In der Standardeinstellung (
tool_choice: "auto") entscheidet das Modell selbstständig, ob und welche Funktion es aufruft.
-
Paralleler Funktionsaufruf
Du kannst deine Chatnachrichten so einstellen, dass sie intents enthalten, die mehrere Tools gleichzeitig aufrufen. Diese Strategie wird als paralleler Funktionsaufruf bezeichnet.
In Abänderung des zuvor verwendeten Codes wird die Liste messages aktualisiert, um die Planung von zwei Treffen zu ermöglichen:
# Start the conversation:messages=[{"role":"user","content":'''Schedule a meeting on 2023-11-01 at 14:00 with Aliceand Bob. Then I want to schedule another meeting on 2023-11-02 at15:00 with Charlie and Dave.'''}]
Dann passe den vorherigen Codeabschnitt an, indem du eine for Schleife einfügst.
Eingabe:
# Send the conversation and function schema to the model:response=client.chat.completions.create(model="gpt-3.5-turbo-1106",messages=messages,tools=functions,)response=response.choices[0].message# Check if the model wants to call our function:ifresponse.tool_calls:fortool_callinresponse.tool_calls:# Get the function name and arguments to call:function_name=tool_call.function.namefunction_args=json.loads(tool_call.function.arguments)("This is the function name: ",function_name)("These are the function arguments: ",function_args)function=OPENAI_FUNCTIONS.get(function_name)ifnotfunction:raiseException(f"Function{function_name}not found.")# Call the function:function_response=function(**function_args)# Share the function's response with the model:messages.append({"role":"function","name":function_name,"content":json.dumps(function_response),})# Let the model generate a user-friendly response:second_response=client.chat.completions.create(model="gpt-3.5-turbo-0613",messages=messages)(second_response.choices[0].message.content)
Ausgabe:
Thisisthefunctionname:schedule_meetingThesearethefunctionarguments:{'date':'2023-11-01','time':'14:00','attendees':['Alice','Bob']}Thisisthefunctionname:schedule_meetingThesearethefunctionarguments:{'date':'2023-11-02','time':'15:00','attendees':['Charlie','Dave']}Twomeetingshavebeenscheduled:1.MeetingwithAliceandBobon2023-11-01at14:00.2.MeetingwithCharlieandDaveon2023-11-02at15:00.
An diesem Beispiel wird deutlich, wie du mehrere Funktionsaufrufe effektiv verwalten kannst. Du hast gesehen, dass die Funktion schedule_meeting zweimal hintereinander aufgerufen wurde, um verschiedene Treffen zu vereinbaren. Das zeigt, wie flexibel und mühelos du mit KI-gestützten Tools unterschiedliche und komplexe Anfragen bearbeiten kannst.
Funktionsaufrufe in LangChain
Wenn du es vorziehst, kein JSON-Schema zu schreiben und einfach nur strukturierte Daten aus einer LLM-Antwort extrahieren willst, dann kannst du mit LangChain Funktionsaufrufe mit Pydantic verwenden.
Eingabe:
fromlangchain.output_parsers.openai_toolsimportPydanticToolsParserfromlangchain_core.utils.function_callingimportconvert_to_openai_toolfromlangchain_core.promptsimportChatPromptTemplatefromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain_core.pydantic_v1importBaseModel,FieldfromtypingimportOptionalclassArticle(BaseModel):"""Identifying key points and contrarian views in an article."""points:str=Field(...,description="Key points from the article")contrarian_points:Optional[str]=Field(None,description="Any contrarian points acknowledged in the article")author:Optional[str]=Field(None,description="Author of the article")_EXTRACTION_TEMPLATE="""Extract and save the relevant entities mentioned\in the following passage together with their properties.If a property is not present and is not required in the function parameters,do not include it in the output."""# Create a prompt telling the LLM to extract information:prompt=ChatPromptTemplate.from_messages({("system",_EXTRACTION_TEMPLATE),("user","{input}")})model=ChatOpenAI()pydantic_schemas=[Article]# Convert Pydantic objects to the appropriate schema:tools=[convert_to_openai_tool(p)forpinpydantic_schemas]# Give the model access to these tools:model=model.bind_tools(tools=tools)# Create an end to end chain:chain=prompt|model|PydanticToolsParser(tools=pydantic_schemas)result=chain.invoke({"input":"""In the recent article titled 'AI adoption in industry,'key points addressed include the growing interest ... However, theauthor, Dr. Jane Smith, ..."""})(result)
Ausgabe:
[Article(points='The growing interest in AI in various sectors, ...',contrarian_points='Without stringent regulations, ...',author='Dr. Jane Smith')]
Zu Beginn importierst du verschiedene Module, darunter PydanticToolsParser und ChatPromptTemplate, die für das Parsen und Templating deiner Eingabeaufforderungen wichtig sind. Dann definierst du ein Pydantic-Modell, Article, um die Struktur der Informationen festzulegen, die du aus einem bestimmten Text extrahieren willst. Mithilfe einer benutzerdefinierten Eingabeaufforderung und dem ChatOpenAI-Modell weist du die KI an, die wichtigsten Punkte und gegenteiligen Ansichten aus einem Artikel zu extrahieren. Zum Schluss werden die extrahierten Daten sauber in dein vordefiniertes Pydantic-Modell umgewandelt und ausgedruckt, damit du die strukturierten Informationen aus dem Text sehen kannst .
Es gibt mehrere wichtige Punkte, darunter:
- Konvertierung des Pydantic-Schemas in OpenAI-Tools
-
tools = [convert_to_openai_tool(p) for p in pydantic_schemas] - Binden der Tools direkt an den LLM
-
model = model.bind_tools(tools=tools) - Erstellen einer LCEL-Kette, die einen Werkzeugparser enthält
-
chain = prompt | model | PydanticToolsParser(tools=pydantic_schemas)
Daten mit LangChain extrahieren
Die Funktion create_extraction_chain_pydantic bietet eine prägnantere Version der vorherigen Implementierung. Durch einfaches Einfügen eines Pydantic-Modells und einer LLM, die Funktionsaufrufe unterstützt, kannst du ganz einfach parallele Funktionsaufrufe erreichen.
Eingabe:
fromlangchain.chains.openai_toolsimportcreate_extraction_chain_pydanticfromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain_core.pydantic_v1importBaseModel,Field# Make sure to use a recent model that supports tools:model=ChatOpenAI(model="gpt-3.5-turbo-1106")classPerson(BaseModel):"""A person's name and age."""name:str=Field(...,description="The person's name")age:int=Field(...,description="The person's age")chain=create_extraction_chain_pydantic(Person,model)chain.invoke({'input':'''Bob is 25 years old. He lives in New York.He likes to play basketball. Sarah is 30 years old. She lives in SanFrancisco. She likes to play tennis.'''})
Ausgabe:
[Person(name='Bob',age=25),Person(name='Sarah',age=30)]
Das Person Pydantic-Modell hat zwei Eigenschaften, name und age; durch den Aufruf der Funktion create_extraction_chain_pydantic mit dem Eingabetext ruft der LLM dieselbe Funktion zweimal auf und erstellt zwei People Objekte.
Abfrageplanung
Es kann zu Problemen kommen, wenn Benutzeranfragen mehrere Intents mit komplizierten Abhängigkeiten haben. Die Abfrageplanung ist eine effektive Methode, um die Abfrage eines Nutzers in eine Reihe von Schritten zu zerlegen, die als Abfragegraph mit relevanten Abhängigkeiten ausgeführt werden können:
fromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain.output_parsers.pydanticimportPydanticOutputParserfromlangchain_core.prompts.chatimport(ChatPromptTemplate,SystemMessagePromptTemplate,)frompydantic.v1importBaseModel,FieldfromtypingimportListclassQuery(BaseModel):id:intquestion:strdependencies:List[int]=Field(default_factory=list,description="""A list of sub-queries that must be completed beforethis task can be completed.Use a sub query when anything is unknown and we might need to askmany queries to get an answer.Dependencies must only be other queries.""")classQueryPlan(BaseModel):query_graph:List[Query]
Wenn du QueryPlan und Query definierst, kannst du einen LLM zunächst bitten, die Abfrage eines Nutzers in mehrere Schritte zu zerlegen. Untersuchen wir, wie man den Abfrageplan erstellt.
Eingabe:
# Set up a chat model:model=ChatOpenAI()# Set up a parser:parser=PydanticOutputParser(pydantic_object=QueryPlan)template="""Generate a query plan. This will be used for task execution.Answer the following query:{query}Return the following query graph format:{format_instructions}"""system_message_prompt=SystemMessagePromptTemplate.from_template(template)chat_prompt=ChatPromptTemplate.from_messages([system_message_prompt])# Create the LCEL chain with the prompt, model, and parser:chain=chat_prompt|model|parserresult=chain.invoke({"query":'''I want to get the results from my database. Then I want to findout what the average age of my top 10 customers is. Once I have the averageage, I want to send an email to John. Also I just generally want to send awelcome introduction email to Sarah, regardless of the other tasks.''',"format_instructions":parser.get_format_instructions()})(result.query_graph)
Ausgabe:
[Query(id=1,question='Get top 10 customers',dependencies=[]),Query(id=2,question='Calculate average age of customers',dependencies=[1]),Query(id=3,question='Send email to John',dependencies=[2]),Query(id=4,question='Send welcome email to Sarah',dependencies=[])]
Initiiere eine ChatOpenAI Instanz und erstelle eine PydanticOutputParser für die QueryPlan Struktur. Dann wird die LLM-Antwort aufgerufen und geparst, wodurch eine strukturierte query_graph für deine Aufgaben mit ihren eindeutigen Abhängigkeiten entsteht.
Erstellen von Few-Shot Eingabeaufforderungen Templates
Wenn du mit den generativen Fähigkeiten von LLMs arbeitest, musst du dich oft zwischen Zero-Shot und Little-Shot Learning (k-shot) entscheiden. Während das Zero-Shot-Lernen keine expliziten Beispiele benötigt und sich allein aufgrund der Eingabeaufforderung an die Aufgaben anpasst, bedeutet seine Abhängigkeit von der Pretrainingsphase, dass es nicht immer präzise Ergebnisse liefert.
Beim "few-shot"-Lernen hingegen, bei dem du in der Eingabeaufforderung einige Beispiele für die gewünschte Aufgabenausführung angibst, hast du die Möglichkeit, das Verhalten des Modells zu optimieren, was zu wünschenswerteren Ergebnissen führt.
Aufgrund der Länge des Token-LLM-Kontextes wirst du oft damit konkurrieren müssen, viele hochwertige K-Shot-Beispiele in deine Eingabeaufforderungen einzubauen und gleichzeitig eine effektive und deterministische LLM-Ausgabe zu erzeugen.
Hinweis
Auch wenn die Grenze für das Token-Kontext-Fenster in LLMs immer weiter ansteigt, hilft dir die Angabe einer bestimmten Anzahl von K-Shot-Beispielen, die API-Kosten zu minimieren.
Es gibt zwei Methoden, mit denen du k-shot Beispiele in deine Eingabeaufforderungen mit few-shot Templates einfügen kannst: mit festen Beispielen und mit einem Beispielselektor.
Beispiele für Few-Shots mit fester Länge
Sehen wir uns zunächst an, wie man eine Eingabeaufforderung mit einer festen Anzahl von Beispielen erstellt. Die Grundlage für diese Methode ist die Erstellung einer robusten Reihe von Beispielen:
fromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain_core.promptsimport(FewShotChatMessagePromptTemplate,ChatPromptTemplate,)examples=[{"question":"What is the capital of France?","answer":"Paris",},{"question":"What is the capital of Spain?","answer":"Madrid",}# ...more examples...]
Jedes Beispiel ist ein Wörterbuch, das einen question und answer Schlüssel enthält, der verwendet wird, um Paare von HumanMessage und AIMessage Nachrichten zu erstellen.
Formatierung der Beispiele
Als nächstes konfigurierst du ein ChatPromptTemplate für die Formatierung der einzelnen Beispiele, die dann in ein FewShotChatMessagePromptTemplate eingefügt werden.
Eingabe:
example_prompt=ChatPromptTemplate.from_messages([("human","{question}"),("ai","{answer}"),])few_shot_prompt=FewShotChatMessagePromptTemplate(example_prompt=example_prompt,examples=examples,)(few_shot_prompt.format())
Ausgabe:
Human:WhatisthecapitalofFrance?AI:ParisHuman:WhatisthecapitalofSpain?AI:Madrid...moreexamples...
Beachte, dass example_prompt die Paare HumanMessage und AIMessage mit den Eingabeaufforderungen {question} und {answer} erstellt.
Nachdem du few_shot_prompt.format() ausgeführt hast, werden die Beispiele als String ausgegeben. Da du diese in einer ChatOpenAI() LLM-Anfrage verwenden möchtest, erstellen wir eine neue ChatPromptTemplate.
Eingabe:
fromlangchain_core.output_parsersimportStrOutputParserfinal_prompt=ChatPromptTemplate.from_messages([("system",'''You are responsible for answeringquestions about countries. Only return the countryname.'''),few_shot_prompt,("human","{question}"),])model=ChatOpenAI()# Creating the LCEL chain with the prompt, model, and a StrOutputParser():chain=final_prompt|model|StrOutputParser()result=chain.invoke({"question":"What is the capital of America?"})(result)
Ausgabe:
Washington,D.C.
Nachdem du die LCEL-Kette auf final_prompt aufgerufen hast, werden deine Kurzbeispiele nach SystemMessage hinzugefügt.
Beachte, dass der LLM nur 'Washington, D.C.' zurückgibt. Das liegt daran, dass die Antwort des LLMs nach der Rückgabe von StrOutputParser(), einem Ausgabeparser , geparst wird. Das Hinzufügen von StrOutputParser() ist eine gängige Methode, um sicherzustellen, dass LLM-Antworten in Ketten String-Werte zurückgeben. Du wirst dies beim Erlernen von sequentiellen Ketten in LCEL genauer untersuchen.
Auswahl von Few-Shot-Beispielen nach Länge
Bevor wir in den Code eintauchen, lass uns deine Aufgabe skizzieren: . Stell dir vor, du baust eine Storytelling-Anwendung auf Basis von GPT-4. Ein Benutzer gibt eine Liste von Zeichennamen ein, zu denen bereits Geschichten erstellt wurden. Die Liste der Charaktere kann jedoch bei jedem Benutzer unterschiedlich lang sein. Wenn du zu viele Zeichen einträgst, kann es passieren, dass die Geschichte die Grenze des LLM-Kontextfensters überschreitet. Auf kannst du LengthBasedExampleSelector verwenden, um die Eingabeaufforderung an die Länge der Benutzereingabe anzupassen:
fromlangchain_core.promptsimportFewShotPromptTemplate,PromptTemplatefromlangchain.prompts.example_selectorimportLengthBasedExampleSelectorfromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain_core.messagesimportSystemMessageimporttiktokenexamples=[{"input":"Gollum","output":"<Story involving Gollum>"},{"input":"Gandalf","output":"<Story involving Gandalf>"},{"input":"Bilbo","output":"<Story involving Bilbo>"},]story_prompt=PromptTemplate(input_variables=["input","output"],template="Character:{input}\nStory:{output}",)defnum_tokens_from_string(string:str)->int:"""Returns the number of tokens in a text string."""encoding=tiktoken.get_encoding("cl100k_base")num_tokens=len(encoding.encode(string))returnnum_tokensexample_selector=LengthBasedExampleSelector(examples=examples,example_prompt=story_prompt,max_length=1000,# 1000 tokens are to be included from examples# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))# You have modified the get_text_length function to work with the# TikToken library based on token usage:get_text_length=num_tokens_from_string,)
Zuerst richtest du eine PromptTemplate ein, die zwei Eingabevariablen für jedes Beispiel benötigt. Dann passt LengthBasedExampleSelector die Anzahl der Beispiele an die Länge der eingegebenen Beispiele an und stellt so sicher, dass dein LLM keine Geschichte erzeugt, die über das Kontextfenster hinausgeht.
Außerdem hast du die Funktion get_text_length so angepasst, dass sie die Funktion num_tokens_from_string verwendet, die mit tiktoken die Gesamtzahl der Token zählt. Das bedeutet, dass max_length=1000 die Anzahl der Token darstellt, anstatt die folgende Standardfunktion zu verwenden:
get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))
Um nun all diese Elemente miteinander zu verbinden:
dynamic_prompt=FewShotPromptTemplate(example_selector=example_selector,example_prompt=story_prompt,prefix='''Generate a story for{character}using thecurrent Character/Story pairs from all of the charactersas context.''',suffix="Character:{character}\nStory:",input_variables=["character"],)# Provide a new character from Lord of the Rings:formatted_prompt=dynamic_prompt.format(character="Frodo")# Creating the chat model:chat=ChatOpenAI()response=chat.invoke([SystemMessage(content=formatted_prompt)])(response.content)
Ausgabe:
Frodo was a young hobbit living a peaceful life in the Shire. However, his life...
Beispiele liefern und Format angeben
Wenn du mit Beispielen arbeitest, die nur wenige Bilder enthalten, ist die Länge des Inhalts entscheidend dafür, wie viele Beispiele das KI-Modell berücksichtigen kann. Passe die Länge deiner Eingabeinhalte an und sorge mit geeigneten Beispielen für effiziente Ergebnisse, um zu verhindern, dass der LLM Inhalte generiert, die seine Kontextfenstergrenze überschreiten könnten.
Nachdem du die Eingabeaufforderung formatiert hast, erstellst du ein Chatmodell mit ChatOpenAI() und lädst die formatierte Eingabeaufforderung in ein SystemMessage, das eine kleine Geschichte über Frodo aus Herr der Ringe erstellt.
Anstatt eine ChatPromptTemplate zu erstellen und zu formatieren, ist es oft viel einfacher, einfach eine SystemMesage mit einer formatierten Eingabeaufforderung aufzurufen:
result=model.invoke([SystemMessage(content=formatted_prompt)])
Beschränkungen mit wenigen Beispielen
Few-Shot-Lernen hat seine Grenzen. Obwohl es sich in bestimmten Szenarien als vorteilhaft erweisen kann, liefert es nicht immer die erwarteten hochwertigen Ergebnisse. Das liegt vor allem an zwei Gründen:
-
Vortrainierte Modelle wie GPT-4 können sich manchmal zu sehr an die wenigen Beispiele anpassen, sodass sie die Beispiele gegenüber der eigentlichen Eingabeaufforderung bevorzugen.
-
LLMs haben ein Token-Limit. Daher wird es immer einen Kompromiss zwischen der Anzahl der Beispiele und der Länge der Antwort geben. Mehr Beispiele können die Länge der Antwort begrenzen und umgekehrt.
Diesen Einschränkungen kann auf verschiedene Weise begegnet werden. Erstens: Wenn die Eingabeaufforderung mit wenigen Worten nicht die gewünschten Ergebnisse bringt, kannst du versuchen, andere Formulierungen zu verwenden oder mit der Sprache der Eingabeaufforderung selbst zu experimentieren. Variationen in der Formulierung der Eingabeaufforderung können zu unterschiedlichen Antworten führen, was den Trial-and-Error-Charakter des Prompt-Engineerings verdeutlicht.
Zweitens solltest du überlegen, ob du dem Modell explizit die Anweisung gibst, die Beispiele zu ignorieren, wenn es die Aufgabe verstanden hat, oder die Beispiele nur als Formatierungshilfe zu verwenden. Das könnte das Modell dazu bringen, sich nicht zu sehr an die Beispiele anzupassen.
Wenn die Aufgaben komplex sind und die Leistung des Modells mit dem Lernen mit wenigen Schüssen nicht zufriedenstellend ist, solltest du eine Feinabstimmung deines Modells in Betracht ziehen. Durch die Feinabstimmung erhält das Modell ein differenzierteres Verständnis für eine bestimmte Aufgabe, wodurch sich die Leistung deutlich verbessert.
Speichern und Laden von LLM-Eingabeaufforderungen
Um generative KI-Modelle wie GPT-4 effektiv zu nutzen, ist es von Vorteil, Eingabeaufforderungen als Dateien statt als Python-Code zu speichern. Auf diese Weise lassen sich die Eingabeaufforderungen besser teilen, speichern und versionieren.
LangChain unterstützt sowohl das Speichern als auch das Laden von Eingabeaufforderungen aus JSON und YAML. Eine weitere wichtige Funktion von LangChain ist die Unterstützung von detaillierten Angaben in einer Datei oder verteilt auf mehrere Dateien. Das bedeutet, dass du die Flexibilität hast, verschiedene Komponenten wie Templates, Beispiele und andere in verschiedenen Dateien zu speichern und bei Bedarf auf sie zu verweisen.
Hier erfährst du, wie du Eingabeaufforderungen speichern und laden kannst:
fromlangchain_core.promptsimportPromptTemplate,load_promptprompt=PromptTemplate(template='''Translate this sentence from English to Spanish.\nSentence:{sentence}\nTranslation:''',input_variables=["sentence"],)prompt.save("translation_prompt.json")# Loading the prompt template:load_prompt("translation_prompt.json")# Returns PromptTemplate()
Nachdem du PromptTemplate und load_prompt aus dem Modul langchain.prompts importiert hast, definierst du eine PromptTemplate für Übersetzungsaufgaben vom Englischen ins Spanische und speicherst sie als translation_prompt.json. Schließlich lädst du die gespeicherte Eingabeaufforderung mit der Funktion load_prompt, die eine Instanz von PromptTemplate zurückgibt.
Warnung
Bitte beachte, dass das Speichern von Eingabeaufforderungen in LangChain möglicherweise nicht mit allen Arten von Templates funktioniert. Um dies zu vermeiden, kannst du die Pickle-Bibliothek oder .txt-Dateien verwenden, um Eingabeaufforderungen zu lesen und zu schreiben, die LangChain nicht unterstützt.
Du hast gelernt, wie du mit LangChain Eingabeaufforderungen mit zwei Techniken erstellen kannst: mit einer festen Anzahl von Beispielen und mit einem Beispielselektor.
Ersteres erstellt eine Reihe von Beispielen mit wenigen Bildern und verwendet ein ChatPromptTemplate Objekt, um diese in Chat-Nachrichten zu formatieren. Dies bildet die Grundlage für die Erstellung eines FewShotChatMessagePromptTemplate Objekts.
Die letztere Methode, bei der ein Beispielselektor verwendet wird, ist praktisch, wenn die Benutzereingaben sehr unterschiedlich lang sind. In solchen Fällen kann eine LengthBasedExampleSelector verwendet werden, um die Anzahl der Beispiele an die Länge der Benutzereingaben anzupassen. Auf diese Weise wird sichergestellt, dass dein LLM die Grenze des Kontextfensters nicht überschreitet.
Außerdem hast du gesehen, wie einfach es ist, Eingabeaufforderungen als Dateien zu speichern/zu laden, wodurch die gemeinsame Nutzung, Speicherung und Versionierung verbessert.
Datenverbindung
Die Nutzung einer LLM-Anwendung in Verbindung mit deckt eine Vielzahl von Möglichkeiten auf, die Effizienz zu steigern und gleichzeitig deine Entscheidungsprozesse zu verbessern.
Die Daten deines Unternehmens können in verschiedenen Formen vorliegen:
- Unstrukturierte Daten
-
Dazu können Google Docs, Threads von Kommunikationsplattformen wie Slack oder Microsoft Teams, Webseiten, interne Dokumentation oder Code-Repositories auf GitHub gehören.
- Strukturierte Daten
-
Daten, die in SQL-, NoSQL- oder Graph-Datenbanken untergebracht sind.
Um deine unstrukturierten Daten abzufragen, müssen sie geladen, umgewandelt, eingebettet und anschließend in einer Vektordatenbank gespeichert werden. Eine Vektordatenbank ist ein spezieller Datenbanktyp, der entwickelt wurde, um Daten in Form von Vektoren effizient zu speichern und abzufragen, die komplexe Daten wie Text oder Bilder in einem für maschinelles Lernen und Ähnlichkeitssuche geeigneten Format darstellen.
Bei strukturierten Daten, die bereits indiziert und gespeichert sind, kannst du einen LangChain-Agenten einsetzen, um eine Zwischenabfrage in deiner Datenbank durchzuführen. Auf diese Weise lassen sich bestimmte Merkmale herausfiltern, die dann in deinen Eingabeaufforderungen verwendet werden können.
Es gibt mehrere Python-Pakete, die dir bei der Dateneingabe helfen können, darunter Unstructured, LlamaIndex und LangChain.
Abbildung 4-2 zeigt einen standardisierten Ansatz für die Dateneingabe. Er beginnt mit den Datenquellen, die dann in Dokumente geladen werden. Diese Dokumente werden dann gechunked und in einer Vektordatenbank zum späteren Abruf gespeichert.
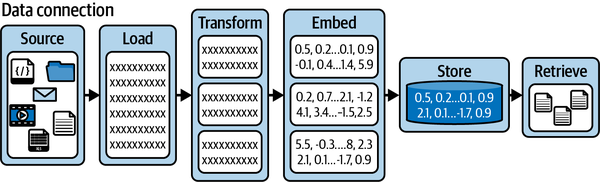
Abbildung 4-2. Eine Datenverbindung zur Retrieval-Pipeline
Insbesondere LangChain stattet dich mit wichtigen Komponenten aus, um deine Daten zu laden, zu ändern, zu speichern und abzurufen:
- Dokumentenlader
-
Diese erleichtern das Hochladen von Informationen Ressourcen oder Dokumenten aus verschiedenen Quellen wie Word-Dokumenten, PDF-Dateien, Textdateien oder sogar Webseiten.
- Dokumententransformatoren
-
Diese Tools ermöglichen die Segmentierung von Dokumenten, die Umwandlung in ein Q&A-Layout, die Eliminierung von überflüssigen Dokumenten und vieles mehr.
- Modelle zur Texteinbettung
-
Diese können unstrukturierten Text in eine Folge von Fließkommazahlen umwandeln, die für die Ähnlichkeitssuche durch Vektorspeicher verwendet werden.
- Vektordatenbanken (Vektorspeicher)
-
Diese Datenbanken können über eingebettete Daten speichern und Suchen ausführen.
- Retriever
-
Diese Tools bieten die Möglichkeit, Daten abzufragen und abzurufen.
Außerdem ist es erwähnenswert, dass andere LLM-Frameworks wie LlamaIndex nahtlos mit LangChain zusammenarbeiten. LlamaHub ist eine weitere Open-Source-Bibliothek, die sich mit dem Laden von Dokumenten beschäftigt und LangChain-spezifische Document Objekte erstellen kann.
Dokumentenlader
Stell dir vor, du wurdest damit beauftragt, eine LLM-Datenerfassungspipeline für NutriFusion Foods zu erstellen. Die Informationen, die du für den LLM sammeln musst, sind darin enthalten:
-
Eine PDF-Datei des Buches " Principles of Marketing
-
Zwei .docx Marketingberichte in einem öffentlichen Google Cloud Storage Bucket
-
Drei .csv-Dateien mit den Marketing-Leistungsdaten für 2021, 2022 und 2023
Erstelle eine neue Jupyter-Notebook- oder Python-Datei in content/chapter_4 des gemeinsamen Repositorys und führe pip install pdf2image docx2txt pypdf aus, um drei Pakete zu installieren.
Alle Daten außer den .docx-Dateien findest du in content/chapter_4/data. Du kannst damit beginnen, alle deine verschiedenen Datenlader zu importieren und eine leere all_documents Liste zu erstellen, um alle Document Objekte aus deinen Datenquellen zu speichern.
Eingabe:
fromlangchain_community.document_loadersimportDocx2txtLoaderfromlangchain_community.document_loadersimportPyPDFLoaderfromlangchain_community.document_loaders.csv_loaderimportCSVLoaderimportglobfromlangchain.text_splitterimportCharacterTextSplitter# To store the documents across all data sources:all_documents=[]# Load the PDF:loader=PyPDFLoader("data/principles_of_marketing_book.pdf")pages=loader.load_and_split()(pages[0])# Add extra metadata to each page:forpageinpages:page.metadata["description"]="Principles of Marketing Book"# Checking that the metadata has been added:forpageinpages[0:2]:(page.metadata)# Saving the marketing book pages:all_documents.extend(pages)csv_files=glob.glob("data/*.csv")# Filter to only include the word Marketing in the file name:csv_files=[fforfincsv_filesif"Marketing"inf]# For each .csv file:forcsv_fileincsv_files:loader=CSVLoader(file_path=csv_file)data=loader.load()# Saving the data to the all_documents list:all_documents.extend(data)text_splitter=CharacterTextSplitter.from_tiktoken_encoder(chunk_size=200,chunk_overlap=0)urls=['''https://storage.googleapis.com/oreilly-content/NutriFusion%20Foods%20Marketing%20Plan%202022.docx''','''https://storage.googleapis.com/oreilly-content/NutriFusion%20Foods%20Marketing%20Plan%202023.docx''',]docs=[]forurlinurls:loader=Docx2txtLoader(url.replace('\n',''))pages=loader.load()chunks=text_splitter.split_documents(pages)# Adding the metadata to each chunk:forchunkinchunks:chunk.metadata["source"]="NutriFusion Foods Marketing Plan - 2022/2023"docs.extend(chunks)# Saving the marketing book pages:all_documents.extend(docs)
Ausgabe:
page_content='Principles of Mark eting'
metadata={'source': 'data/principles_of_marketing_book.pdf', 'page': 0}
{'source': 'data/principles_of_marketing_book.pdf', 'page': 0,
'description': 'Principles of Marketing Book'}
{'source': 'data/principles_of_marketing_book.pdf', 'page': 1,
'description': 'Principles of Marketing Book'}
Dann kannst du mit PyPDFLoader eine .pdf-Datei importieren und sie mit der Funktion .load_and_split() in mehrere Seiten aufteilen.
Außerdem ist es möglich, jeder Seite zusätzliche Metadaten hinzuzufügen, denn die Metadaten sind ein Python-Wörterbuch auf jedem Document Objekt. Beachte auch, dass in der vorangegangenen Ausgabe für Document Objekte die Metadaten source angehängt sind.
Mit dem Paket glob kannst du ganz einfach alle .csv-Dateien finden und diese einzeln in LangChain Document Objekte mit einem CSVLoader laden.
Schließlich werden die beiden Marketingberichte aus einem öffentlichen Google Cloud Storage-Bucket geladen und dann mit Hilfe eines text_splitter in 200 Token-Chunk-Größen aufgeteilt.
In diesem Abschnitt hast du dir das nötige Wissen angeeignet, um eine umfassende Pipeline zum Laden von Dokumenten für das LLM von NutriFusion Foods zu erstellen. Beginnend mit der Datenextraktion aus einem PDF, mehreren CSV-Dateien und zwei.docx-Dateien wurde jedes Dokument mit relevanten Metadaten angereichert, um den Kontext zu verbessern.
Du hast jetzt die Möglichkeit, nahtlos Daten aus einer Vielzahl von Dokumentenquellen in eine zusammenhängende Datenpipeline zu integrieren.
Text Splitter
Die Ausgewogenheit der Länge jedes Dokuments ist ebenfalls ein entscheidender Faktor. Wenn ein Dokument zu lang ist, kann es die Kontextlänge des LLM überschreiten (die maximale Anzahl von Token, die ein LLM in einer einzigen Anfrage verarbeiten kann). Wenn die Dokumente jedoch zu sehr in kleinere Teile zerlegt werden, besteht die Gefahr, dass wichtige Kontextinformationen verloren gehen, was ebenfalls unerwünscht ist.
Bei der Textaufteilung können besondere Herausforderungen auftreten, z. B:
-
Sonderzeichen wie Hashtags, @-Symbole oder Links werden möglicherweise nicht wie vorgesehen aufgeteilt, was die Gesamtstruktur der aufgeteilten Dokumente beeinträchtigt.
-
Wenn dein Dokument komplizierte Formatierungen wie Tabellen, Listen oder mehrstufige Überschriften enthält, kann es für den Textsplitter schwierig sein, die ursprüngliche Formatierung beizubehalten.
Es gibt Wege, diese Herausforderungen zu überwinden, die wir später erkunden werden.
In diesem Abschnitt lernst du die Textsplitter in LangChain kennen, Werkzeuge, mit denen du große Textabschnitte aufteilen kannst, um sie besser an das Kontextfenster deines Modells anzupassen.
Hinweis
Es gibt keine perfekte Dokumentengröße. Beginne damit, gute Heuristiken zu verwenden und baue dann eine Trainings-/Testmenge auf, die du für die LLM-Evaluierung verwenden kannst.
LangChain bietet eine Reihe von Textsplittern, so dass du ganz einfach nach einem der folgenden Kriterien splitten kannst:
-
Anzahl der Token
-
Rekursiv durch mehrere Zeichen
-
Anzahl der Zeichen
-
Code
-
Markdown Kopfzeilen
Schauen wir uns drei beliebte Splitter an: CharacterTextSplitter,TokenTextSplitter, und RecursiveCharacterTextSplitter.
Textaufteilung nach Länge und Tokengröße
In Kapitel 3 hast du gelernt, wie die Anzahl der Token innerhalb eines GPT-4-Aufrufs mit tiktoken zählt. Du kannst tiktoken auch verwenden, um Strings in entsprechend große Chunks und Dokumente aufzuteilen.
Erinnere dich daran, tiktoken und langchain-text-splitters mit pip install tiktoken langchain-text-splitters zu installieren.
Um in LangChain nach der Anzahl der Token zu trennen, kannst du eine CharacterTextSplitter mit einer .from_tiktoken_encoder() Funktion verwenden.
Du erstellst zunächst eine CharacterTextSplitter mit einer Stückgröße von 50 Zeichen und ohne Überlappung. Mit der Methode split_text zerschneidest du den Text in Stücke und gibst dann die Gesamtzahl der erstellten Chunks aus.
Dann machst du dasselbe, aber dieses Mal mit einer Überlappung von 48 Zeichen. Hier siehst du, wie sich die Anzahl der Chunks ändert, je nachdem, ob du eine Überlappung zulässt, und wie sich diese Einstellungen darauf auswirken, wie dein Text aufgeteilt wird:
fromlangchain_text_splittersimportCharacterTextSplittertext="""Biology is a fascinating and diverse field of science that explores theliving world and its intricacies\n\n. It encompasses the study of life, itsorigins, diversity, structure, function, and interactions at various levelsfrom molecules and cells to organisms and ecosystems\n\n. In this 1000-wordessay, we will delve into the core concepts of biology, its history, keyareas of study, and its significance in shaping our understanding of thenatural world.\n\n...(truncated to save space)..."""# No chunk overlap:text_splitter=CharacterTextSplitter.from_tiktoken_encoder(chunk_size=50,chunk_overlap=0,separator="\n",)texts=text_splitter.split_text(text)(f"Number of texts with no chunk overlap:{len(texts)}")# Including a chunk overlap:text_splitter=CharacterTextSplitter.from_tiktoken_encoder(chunk_size=50,chunk_overlap=48,separator="\n",)texts=text_splitter.split_text(text)(f"Number of texts with chunk overlap:{len(texts)}")
Ausgabe:
Number of texts with no chunk overlap: 3 Number of texts with chunk overlap: 6
Im vorigen Abschnitt hast du das folgende Verfahren verwendet, um das .pdf-Dokument zu laden und in LangChain-Dokumente aufzuteilen:
pages = loader.load_and_split()
Du kannst die Größe der einzelnen Dokumente genauer steuern, indem du ein TextSplitter erstellst und es an deine Document Ladepipelines anhängst:
def load_and_split(text_splitter: TextSplitter | None = None) -> List[Document]
Erstelle einfach eine TokenTextSplitter mit einer chunk_size=500 und einer chunk_overlap von 50:
fromlangchain.text_splitterimportTokenTextSplitterfromlangchain_community.document_loadersimportPyPDFLoadertext_splitter=TokenTextSplitter(chunk_size=500,chunk_overlap=50)loader=PyPDFLoader("data/principles_of_marketing_book.pdf")pages=loader.load_and_split(text_splitter=text_splitter)(len(pages))#737
Das Buch Principles of Marketing umfasst 497 Seiten, aber nachdem du ein TokenTextSplitter mit einem chunk_size von 500 Token benutzt hast, hast du 776 kleinere LangChain Document Objekte erstellt.
Textaufteilung mit rekursiver Zeichenteilung
Der Umgang mit großen Textblöcken kann einzigartige Herausforderungen bei der Textanalyse darstellen. Eine hilfreiche Strategie für solche Situationen ist die rekursive Aufteilung von Zeichen. Diese Methode erleichtert die Aufteilung eines großen Textes in überschaubare Segmente und macht die weitere Analyse leichter zugänglich.
Dieser Ansatz ist besonders effektiv, wenn es um generischen Text geht. Sie nutzt eine Liste von Zeichen als Parameter und teilt den Text anhand dieser Zeichen nacheinander auf. Die resultierenden Abschnitte werden so lange geteilt, bis sie eine akzeptable Größe erreicht haben. Standardmäßig besteht die Zeichenliste aus "\n\n", "\n", " " und "". Diese Anordnung zielt darauf ab, die Integrität von Absätzen, Sätzen und Wörtern zu erhalten und den semantischen Kontext zu bewahren.
Der Prozess hängt von der angegebenen Zeichenliste ab und verkleinert die resultierenden Abschnitte auf der Grundlage der Zeichenanzahl.
Bevor du in den Code eintauchst, musst du verstehen, was RecursiveCharacterTextSplitter macht. Er nimmt einen Text und eine Liste von Begrenzungszeichen (Zeichen, die die Grenzen für die Aufteilung des Textes festlegen). Beginnend mit dem ersten Begrenzungszeichen in der Liste versucht der Splitter, den Text aufzuteilen. Wenn die resultierenden Stücke immer noch zu groß sind, geht er zum nächsten Begrenzungszeichen über, und so weiter. Dieser Prozess wird rekursiv fortgesetzt, bis die Stücke klein genug sind oder alle Begrenzungszeichen ausgeschöpft sind.
Beginnen Sie mit der vorangegangenen Variable text mit dem Import von RecursiveCharacterTextSplitter. Diese Instanz wird für die Aufteilung des Textes verantwortlich sein. Bei der Initialisierung des Splitters werden die Parameter chunk_size, chunk_overlap und length_function gesetzt. Hier wird chunk_size auf 100 und chunk_overlap auf 20 gesetzt.
length_function ist wie len definiert, um die Größe der Chunks zu bestimmen. Es ist auch möglich, das Argument length_function zu ändern, um eine Tokenizer-Zählung zu verwenden, anstatt die Standardfunktion len zu verwenden, die die Zeichen zählt:
fromlangchain_text_splittersimportRecursiveCharacterTextSplittertext_splitter=RecursiveCharacterTextSplitter(chunk_size=100,chunk_overlap=20,length_function=len,)
Sobald die Instanz text_splitter fertig ist, kannst du .split_text verwenden, um die Variable text in kleinere Chunks zu unterteilen. Diese Chunks werden in der texts Python-Liste gespeichert:
# Split the text into chunks:texts=text_splitter.split_text(text)
Du kannst den Text nicht nur einfach mit Überlappung in eine Liste von Zeichenketten aufteilen, sondern mit der Funktion .create_documents auch ganz einfach LangChain Document Objekte erstellen. Das Erstellen von Document Objekten ist nützlich, weil es dir erlaubt:
-
Dokumente in einer Vektordatenbank für die semantische Suche speichern
-
Hinzufügen von Metadaten zu bestimmten Textabschnitten
-
Iteriere über mehrere Dokumente, um eine übergeordnete Zusammenfassung zu erstellen
Um Metadaten hinzuzufügen, gibst du eine Liste von Wörterbüchern im Argument metadatas an:
# Create documents from the chunks:metadatas={"title":"Biology","author":"John Doe"}docs=text_splitter.create_documents(texts,metadatas=[metadatas]*len(texts))
Aber was ist, wenn deine bestehenden Document Objekte zu lang sind?
Das kannst du ganz einfach erledigen, indem du die Funktion .split_documents mit einer TextSplitter. Diese nimmt eine Liste von Document Objekten auf und gibt eine neue Liste von Document Objekten zurück, die auf den Einstellungen deiner TextSplitter Klassenargumente basiert:
text_splitter=RecursiveCharacterTextSplitter(chunk_size=300)splitted_docs=text_splitter.split_documents(docs)
Du bist jetzt in der Lage, eine effiziente Datenladepipeline zu erstellen und Quellen wie PDFs, CSVs und Google Cloud Storage Links zu nutzen. Außerdem hast du gelernt, wie du die gesammelten Dokumente mit relevanten Metadaten anreichern kannst, um einen aussagekräftigen Kontext für die Analyse und Eingabeaufforderung zu erhalten.
Mit der Einführung von Textsplittern kannst du jetzt die Größe von Dokumenten strategisch steuern und dabei sowohl das Kontextfenster des LLM als auch den Erhalt kontextreicher Informationen optimieren. Du hast den Umgang mit größeren Texten mit Hilfe von Rekursion und Zeichenteilung gemeistert. Mit diesem neuen Wissen kannst du nahtlos mit verschiedenen Dokumentenquellen arbeiten und sie in eine robuste Datenpipeline integrieren.
Aufgabenzerlegung
Die Aufgabenzerlegung ist ein strategischer Prozess , bei dem komplexe Probleme in eine Reihe von überschaubaren Teilproblemen zerlegt werden. Dieser Ansatz fügt sich nahtlos in die natürliche Tendenz von Softwareentwicklern ein, die Aufgaben oft als zusammenhängende Teilkomponenten konzipieren.
In der Softwareentwicklung kannst du durch die Aufgabenzerlegung den kognitiven Aufwand reduzieren und die Vorteile der Problemisolierung und der Einhaltung des Prinzips der einzigen Verantwortung ausnutzen.
Interessanterweise können LLMs von der Anwendung der Aufgabenzerlegung in einer Reihe von Anwendungsfällen erheblich profitieren . Dieser Ansatz trägt dazu bei, den Nutzen und die Effektivität von LLMs in Problemlösungsszenarien zu maximieren, indem er sie in die Lage versetzt, komplizierte Aufgaben zu bewältigen, die als einzelne Einheit nur schwer zu lösen wären, wie in Abbildung 4-3 dargestellt.
Hier sind einige Beispiele für LLMs, die die Dekomposition nutzen:
- Komplexe Problemlösung
-
In Fällen, in denen ein Problem vielschichtig ist und nicht mit einer einzigen Eingabeaufforderung gelöst werden kann, ist eine Aufgabenzerlegung äußerst nützlich. Die Lösung eines komplexen Rechtsfalls könnte zum Beispiel in das Verstehen des Kontextes, die Ermittlung der relevanten Gesetze, die Bestimmung von Präzedenzfällen und die Ausarbeitung von Argumenten aufgeteilt werden. Jede Teilaufgabe kann von einem LLM unabhängig voneinander gelöst werden und ergibt in Kombination eine umfassende Lösung.
- Generierung von Inhalten
-
Bei der Erstellung von langen Inhalten wie Artikeln oder Blogs kann die Aufgabe in das Erstellen einer Gliederung, das Schreiben einzelner Abschnitte und das Zusammenstellen und Verfeinern des endgültigen Entwurfs aufgeteilt werden. Jeder Schritt kann von GPT-4 einzeln verwaltet werden, um bessere Ergebnisse zu erzielen.
- Zusammenfassung des großen Dokuments
-
Das Zusammenfassen langer Dokumente wie Forschungsarbeiten oder Berichte kann effektiver erfolgen, wenn du die Aufgabe in mehrere kleinere Aufgaben zerlegst, z. B. einzelne Abschnitte verstehen, sie unabhängig voneinander zusammenfassen und dann eine endgültige Zusammenfassung erstellen.
- Interaktive Gesprächsagenten
-
Bei der Entwicklung fortschrittlicher Chatbots kann die Aufgabenzerlegung dabei helfen, verschiedene Aspekte der Konversation zu verwalten, z. B. das Verstehen von Benutzereingaben, die Aufrechterhaltung des Kontexts, die Generierung relevanter Antworten und die Steuerung des Dialogflusses.
- Lern- und Nachhilfesysteme
-
In digitalen Nachhilfesystemen kann das System effektiver werden, wenn es die Aufgabe, ein Konzept zu lehren, in das Verstehen des aktuellen Wissensstandes des Lernenden, das Erkennen von Lücken, das Vorschlagen von Lernmaterialien und die Bewertung des Lernfortschritts zerlegt. Jede Teilaufgabe kann die generativen Fähigkeiten von GPT-4 nutzen.
Abbildung 4-3. Aufgabenzerlegung mit LLMs
Arbeitsteilung
Die Aufgabenzerlegung ist eine wichtige Strategie , mit der du das volle Potenzial der LLMs ausschöpfen kannst. Indem du komplexe Probleme in einfachere, überschaubare Aufgaben zerlegst, kannst du die Problemlösungsfähigkeiten dieser Modelle effektiver und effizienter nutzen.
In den folgenden Abschnitten erfährst du, wie du mehrere LLM-Ketten erstellen und integrieren kannst, um kompliziertere Arbeitsabläufe zu organisieren.
Eingabeaufforderung Verkettung
Oft wirst du feststellen, dass es unmöglich ist, eine einzige Aufgabe mit einer Eingabeaufforderung zu erledigen. Du kannst eine Mischung aus Eingabeaufforderungen und speziell zugeschnittenen LLM-Aufforderungen verwenden, um eine Idee zu entwickeln.
Stellen wir uns ein Beispiel mit einer Filmfirma vor, die ihre Filmerstellung teilweise automatisieren möchte. Dies könnte in mehrere Schlüsselkomponenten aufgeteilt werden, wie zum Beispiel:
-
Charaktererstellung
-
Plot-Erstellung
-
Schauplätze/Weltaufbau
Abbildung 4-4 zeigt, wie der Eingabeaufforderung-Workflow aussehen könnte.
Abbildung 4-4. Ein sequentieller Prozess zur Erstellung einer Geschichte
Sequentielle Kette
Zerlegen wir die Aufgabe in mehrere Ketten und fügen sie wieder zu einer einzigen Kette zusammen:
character_generation_chain-
Eine Kette, die dafür verantwortlich ist, mehrere Zeichen zu erstellen, die eine
'genre'. plot_generation_chain-
Eine Kette, die den Plot mit den Schlüsseln
'characters'und'genre'erstellt. scene_generation_chain-
Diese Kette generiert alle fehlenden Szenen, die nicht ursprünglich aus der
plot_generation_chaingeneriert wurden.
Beginnen wir damit, drei separate ChatPromptTemplate Variablen zu erstellen, eine für jede Kette:
fromlangchain_core.prompts.chatimportChatPromptTemplatecharacter_generation_prompt=ChatPromptTemplate.from_template("""I want you to brainstorm three to five characters for my short story. Thegenre is {genre}. Each character must have a Name and a Biography.You must provide a name and biography for each character, this is veryimportant!---Example response:Name: CharWiz, Biography: A wizard who is a master of magic.Name: CharWar, Biography: A warrior who is a master of the sword.---Characters: """)plot_generation_prompt=ChatPromptTemplate.from_template("""Given the following characters and the genre, create an effectiveplot for a short story:Characters:{characters}---Genre: {genre}---Plot: """)scene_generation_plot_prompt=ChatPromptTemplate.from_template("""Act as an effective content creator.Given multiple characters and a plot, you are responsible forgenerating the various scenes for each act.You must decompose the plot into multiple effective scenes:---Characters:{characters}---Genre: {genre}---Plot: {plot}---Example response:Scenes:Scene 1: Some text here.Scene 2: Some text here.Scene 3: Some text here.----Scenes:""")
Beachte, dass du beim Übergang der Eingabeaufforderungen von der Charakter- zur Plot- und Szenengenerierung weitere Platzhaltervariablen aus den vorherigen Schritten hinzufügst.
Es bleibt die Frage, wie du sicherstellen kannst, dass diese zusätzlichen Strings für deine nachgelagerten ChatPromptTemplate Variablen verfügbar sind.
itemgetter und Wörterbuchschlüssel-Extraktion
In LCEL kannst du die Funktion itemgetter aus dem Paket operator verwenden, um Schlüssel aus dem vorherigen Schritt zu extrahieren, sofern im vorherigen Schritt ein Wörterbuch vorhanden war:
fromoperatorimportitemgetterfromlangchain_core.runnablesimportRunnablePassthroughchain=RunnablePassthrough()|{"genre":itemgetter("genre"),}chain.invoke({"genre":"fantasy"})# {'genre': 'fantasy'}
Die Funktion RunnablePassThrough übergibt alle Eingaben direkt an den nächsten Schritt . Dann wird ein neues Wörterbuch erstellt, indem der gleiche Schlüssel in der Funktion invoke verwendet wird; dieser Schlüssel wird mit itemgetter("genre") extrahiert.
Es ist wichtig, dass du die Funktion itemgetter in allen Teilen deiner LCEL-Ketten verwendest, damit alle nachfolgenden ChatPromptTemplate Platzhaltervariablen immer gültige Werte haben.
Außerdem kannst du die Funktionen lambda oder RunnableLambda innerhalb einer LCEL-Kette verwenden, um vorherige Wörterbuchwerte zu manipulieren. Ein lambda ist eine anonyme Funktion in Python:
fromlangchain_core.runnablesimportRunnableLambdachain=RunnablePassthrough()|{"genre":itemgetter("genre"),"upper_case_genre":lambdax:x["genre"].upper(),"lower_case_genre":RunnableLambda(lambdax:x["genre"].lower()),}chain.invoke({"genre":"fantasy"})# {'genre': 'fantasy', 'upper_case_genre': 'FANTASY',# 'lower_case_genre': 'fantasy'}
Da du nun weißt, wie du die Funktionen RunnablePassThrough, itemgetter und lambda verwenden kannst, wollen wir noch einen letzten Teil der Syntax einführen: RunnableParallel:
fromlangchain_core.runnablesimportRunnableParallelmaster_chain=RunnablePassthrough()|{"genre":itemgetter("genre"),"upper_case_genre":lambdax:x["genre"].upper(),"lower_case_genre":RunnableLambda(lambdax:x["genre"].lower()),}master_chain_two=RunnablePassthrough()|RunnableParallel(genre=itemgetter("genre"),upper_case_genre=lambdax:x["genre"].upper(),lower_case_genre=RunnableLambda(lambdax:x["genre"].lower()),)story_result=master_chain.invoke({"genre":"Fantasy"})(story_result)story_result=master_chain_two.invoke({"genre":"Fantasy"})(story_result)# master chain: {'genre': 'Fantasy', 'upper_case_genre': 'FANTASY',# 'lower_case_genre': 'fantasy'}# master chain two: {'genre': 'Fantasy', 'upper_case_genre': 'FANTASY',# 'lower_case_genre': 'fantasy'}
Zunächst importierst du RunnableParallel und erstellst zwei LCEL-Ketten namens master_chain und master_chain_two. Diese werden dann mit genau denselben Argumenten aufgerufen; das RunnablePassthrough übergibt dann das Wörterbuch an den zweiten Teil der Kette.
Der zweite Teil von master_chain und master_chain_two wird genau das gleiche Ergebnis liefern .
Anstatt direkt ein Wörterbuch zu verwenden, kannst du stattdessen auch eine RunnableParallel Funktion nutzen. Diese beiden Kettenausgänge sind austauschbar, also wähle die Syntax, die dir besser gefällt.
Lass uns drei LCEL-Ketten mit Hilfe der Eingabeaufforderungen erstellen:
fromlangchain_openai.chat_modelsimportChatOpenAIfromlangchain_core.output_parsersimportStrOutputParser# Create the chat model:model=ChatOpenAI()# Create the subchains:character_generation_chain=(character_generation_prompt|model|StrOutputParser())plot_generation_chain=(plot_generation_prompt|model|StrOutputParser())scene_generation_plot_chain=(scene_generation_plot_prompt|model|StrOutputParser())
Nachdem du alle Ketten erstellt hast, kannst du sie an eine Master-LCEL-Kette anhängen.
Eingabe:
fromlangchain_core.runnablesimportRunnableParallelfromoperatorimportitemgetterfromlangchain_core.runnablesimportRunnablePassthroughmaster_chain=({"characters":character_generation_chain,"genre":RunnablePassthrough()}|RunnableParallel(characters=itemgetter("characters"),genre=itemgetter("genre"),plot=plot_generation_chain,)|RunnableParallel(characters=itemgetter("characters"),genre=itemgetter("genre"),plot=itemgetter("plot"),scenes=scene_generation_plot_chain,))story_result=master_chain.invoke({"genre":"Fantasy"})
Die Ausgabe wird abgeschnitten, wenn du ... siehst, um Platz zu sparen. Insgesamt wurden jedoch fünf Zeichen und neun Szenen erzeugt.
Ausgabe:
{'characters':'''Name: Lyra, Biography: Lyra is a young elf who possesses..\n\nName: Orion, Biography: Orion is a ..''','genre':{'genre':'Fantasy'}'plot':'''In the enchanted forests of a mystical realm, a greatdarkness looms, threatening to engulf the land and its inhabitants. Lyra,the young elf with a deep connection to nature, ...''','scenes':'''Scene1: Lyra senses the impending danger in the forest ...\n\nScene 2: Orion, onhis mission to investigate the disturbances in the forest...\n\nScene 9:After the battle, Lyra, Orion, Seraphina, Finnegan...'''}
Die Szenen werden in einzelne Elemente einer Python-Liste aufgeteilt. Dann werden zwei neue Eingabeaufforderungen erstellt, um sowohl ein Zeichenskript als auch eine zusammenfassende Eingabeaufforderung zu erzeugen:
# Extracting the scenes using .split('\n') and removing empty strings:scenes=[sceneforsceneinstory_result["scenes"].split("\n")ifscene]generated_scenes=[]previous_scene_summary=""character_script_prompt=ChatPromptTemplate.from_template(template="""Given the following characters:{characters}and the genre:{genre}, create an effective character script for a scene.You must follow the following principles:- Use the Previous Scene Summary:{previous_scene_summary}to avoidrepeating yourself.- Use the Plot:{plot}to create an effective scene character script.- Currently you are generating the character dialogue script for thefollowing scene:{scene}---Here is an example response:SCENE 1: ANNA'S APARTMENT(ANNA is sorting through old books when there is a knock at the door.She opens it to reveal JOHN.)ANNA: Can I help you, sir?JOHN: Perhaps, I think it's me who can help you. I heard you'reresearching time travel.(Anna looks intrigued but also cautious.)ANNA: That's right, but how do you know?JOHN: You could say... I'm a primary source.---SCENE NUMBER:{index}""",)summarize_prompt=ChatPromptTemplate.from_template(template="""Given a character script, create a summary of the scene.Character script:{character_script}""",)
Technisch gesehen könntest du alle Szenen asynchron erstellen. Es ist jedoch von Vorteil, wenn du weißt, was jede Figur in der vorherigen Szene getan hat , um Wiederholungen zu vermeiden.
Deshalb kannst du zwei LCEL-Ketten erstellen, eine für die Erstellung der Zeichenskripte pro Szene und die andere für Zusammenfassungen der vorherigen Szenen:
# Loading a chat model:model=ChatOpenAI(model='gpt-3.5-turbo-16k')# Create the LCEL chains:character_script_generation_chain=({"characters":RunnablePassthrough(),"genre":RunnablePassthrough(),"previous_scene_summary":RunnablePassthrough(),"plot":RunnablePassthrough(),"scene":RunnablePassthrough(),"index":RunnablePassthrough(),}|character_script_prompt|model|StrOutputParser())summarize_chain=summarize_prompt|model|StrOutputParser()# You might want to use tqdm here to track the progress,# or use all of the scenes:forindex,sceneinenumerate(scenes[0:3]):# # Create a scene generation:scene_result=character_script_generation_chain.invoke({"characters":story_result["characters"],"genre":"fantasy","previous_scene_summary":previous_scene_summary,"index":index,})# Store the generated scenes:generated_scenes.append({"character_script":scene_result,"scene":scenes[index]})# If this is the first scene then we don't have a# previous scene summary:ifindex==0:previous_scene_summary=scene_resultelse:# If this is the second scene or greater then# we can use and generate a summary:summary_result=summarize_chain.invoke({"character_script":scene_result})previous_scene_summary=summary_result
Zunächst richtest du in deinem Skript eine character_script_generation_chain ein und nutzt verschiedene Runnables wie RunnablePassthrough für einen reibungslosen Datenfluss. Entscheidend ist, dass diese Kette model = ChatOpenAI(model='gpt-3.5-turbo-16k') integriert, ein leistungsstarkes Modell mit einem großzügigen 16k-Kontextfenster, das ideal für umfangreiche Inhaltserstellungsaufgaben ist. Wenn du diese Kette aufrufst, generiert sie gekonnt Charakterskripte, die auf Eingaben wie Charakterprofile, Genre und Szenenspezifika zurückgreifen.
Du reicherst jede Szene dynamisch an, indem du die Zusammenfassung der vorherigen Szene hinzufügst und so einen einfachen, aber effektiven Pufferspeicher erstellst. Diese Technik sorgt für Kontinuität und Kontext in der Erzählung und verbessert die Fähigkeit des LLM, kohärente Zeichenskripte zu erstellen.
Außerdem wirst du sehen, wie StrOutputParser die Modellausgaben elegant in strukturierte Strings umwandelt, so dass die generierten Inhalte leicht nutzbar sind.
Arbeitsteilung
Erinnere dich daran, dass das Prinzip der Arbeitsteilung bei der Gestaltung deiner Aufgaben in einer sequentiellen Kette von großem Nutzen ist. Die Aufteilung der Aufgaben in kleinere, überschaubare Ketten kann die Gesamtqualität deiner Arbeit erhöhen. Jede Kette in der sequentiellen Kette trägt mit ihrem individuellen Aufwand dazu bei, das übergeordnete Aufgabenziel zu erreichen.
Die Verwendung von Ketten gibt dir die Möglichkeit, verschiedene Modelle zu verwenden. Wenn du zum Beispiel ein intelligentes Modell für die Ideenfindung und ein billiges Modell für die Generierung verwendest, erhältst du in der Regel optimale Ergebnisse. Das bedeutet auch, dass du fein abgestimmte Modelle für jeden Schritt haben kannst.
Strukturierung von LCEL-Ketten
In LCEL musst du sicherstellen, dass der erste Teil von deiner LCEL-Kette ein lauffähiger Typ ist. Der folgende Code wird einen Fehler auslösen:
fromlangchain_core.prompts.chatimportChatPromptTemplatefromoperatorimportitemgetterfromlangchain_core.runnablesimportRunnablePassthrough,RunnableLambdabad_first_input={"film_required_age":18,}prompt=ChatPromptTemplate.from_template("Generate a film title, the age is{film_required_age}")# This will error:bad_chain=bad_first_input|prompt
Ein Python-Wörterbuch mit einem Wert von 18 erzeugt keine lauffähige LCEL-Kette. Die folgenden Implementierungen funktionieren jedoch alle:
# All of these chains enforce the runnable interface:first_good_input={"film_required_age":itemgetter("film_required_age")}# Creating a dictionary within a RunnableLambda:second_good_input=RunnableLambda(lambdax:{"film_required_age":x["film_required_age"]})third_good_input=RunnablePassthrough()fourth_good_input={"film_required_age":RunnablePassthrough()}# You can also create a chain starting with RunnableParallel(...)first_good_chain=first_good_input|promptsecond_good_chain=second_good_input|promptthird_good_chain=third_good_input|promptfourth_good_chain=fourth_good_input|promptfirst_good_chain.invoke({"film_required_age":18})# ...
Sequentielle Ketten eignen sich hervorragend für den inkrementellen Aufbau von Wissen, das von zukünftigen Ketten verwendet wird, aber aufgrund ihres sequentiellen Charakters führen sie oft zu langsameren Antwortzeiten. Daher eignen sich SequentialChain Datenpipelines am besten für serverseitige Aufgaben, bei denen sofortige Antworten keine Priorität haben und die Nutzer/innen kein Echtzeit-Feedback erwarten.
Dokumentenketten
Stellen wir uns vor, dass der örtliche Verlag vor der Annahme deiner von generierten Geschichte eine Zusammenfassung aller Zeichenskripte von dir verlangt hat. Dies ist ein guter Anwendungsfall für Dokumentenketten, weil du einen LLM mit einer großen Textmenge bereitstellen musst, die aufgrund der Längenbeschränkungen des Kontexts nicht in eine einzelne LLM-Anfrage passen würde.
Bevor wir uns mit dem Code beschäftigen, sollten wir uns erst einmal einen Überblick verschaffen. Das Skript, das du sehen wirst, führt eine Text zusammenfassung einer Sammlung von Szenen durch.
Erinnere dich daran, Pandas mit pip install pandas zu installieren.
Beginnen wir mit dem ersten Satz Code:
fromlangchain_text_splittersimportCharacterTextSplitterfromlangchain.chains.summarizeimportload_summarize_chainimportpandasaspd
Diese Zeilen importieren alle notwendigen Tools, die du brauchst. CharacterTextSplitter und load_summarize_chain sind aus dem LangChain-Paket und helfen bei der Textverarbeitung, während Pandas (importiert als pd) bei der Manipulation deiner Daten hilft.
Als Nächstes wirst du dich mit deinen Daten beschäftigen:
df=pd.DataFrame(generated_scenes)
Hier erstellst du einen Pandas-Datenrahmen aus der Variable generated_scenes und konvertierst so deine Rohszenen in ein tabellarisches Datenformat, das von Pandas leicht bearbeitet werden kann.
Dann musst du deinen Text konsolidieren:
all_character_script_text="\n".join(df.character_script.tolist())
In dieser Zeile wandelst du die Spalte character_script deines Datenrahmens in eine einzelne Textzeichenfolge um. Jeder Eintrag in der Spalte wird in ein Listenelement umgewandelt und alle Elemente werden mit neuen Zeilen dazwischen zu einer einzigen Zeichenkette verbunden, die alle Zeichen enthält.
Sobald du deinen Text fertig hast, bereitest du ihn für den Zusammenfassungsprozess vor:
text_splitter=CharacterTextSplitter.from_tiktoken_encoder(chunk_size=1500,chunk_overlap=200)docs=text_splitter.create_documents([all_character_script_text])
Hier erstellst du eine Instanz von CharacterTextSplitter mit der Klassenmethode from_tiktoken_encoder, mit spezifischen Parametern für die Größe der Stücke und die Überlappung. Mit diesem Textsplitter teilst du dann deinen konsolidierten Skripttext in Stücke auf, die du mit deinem Zusammenfassungswerkzeug verarbeiten kannst.
Als Nächstes richtest du dein Verdichtungswerkzeug ein:
chain=load_summarize_chain(llm=model,chain_type="map_reduce")
In dieser Zeile geht es darum, deinen Zusammenfassungsprozess einzurichten. Du rufst eine Funktion auf, die eine Zusammenfassungskette mit einem Chat-Modell im Stil von map-reduce lädt.
Dann führst du die Verdichtung durch:
summary=chain.invoke(docs)
Hier führst du die eigentliche Textzusammenfassung durch. Die Methode invoke führt die Zusammenfassung für die Textabschnitte aus, die du zuvor vorbereitet hast, und speichert die Zusammenfassung in einer Variablen.
Zum Schluss druckst du das Ergebnis aus:
(summary['output_text'])
Dies ist der Höhepunkt deiner harten Arbeit. Der zusammenfassende Text wird auf der Konsole ausgegeben, damit du ihn sehen kannst.
Dieses Skript nimmt eine Sammlung von Szenen, fasst den Text zusammen, gliedert ihn, fasst ihn zusammen und druckt dann die Zusammenfassung aus:
fromlangchain.text_splitterimportCharacterTextSplitterfromlangchain.chains.summarizeimportload_summarize_chainimportpandasaspddf=pd.DataFrame(generated_scenes)all_character_script_text="\n".join(df.character_script.tolist())text_splitter=CharacterTextSplitter.from_tiktoken_encoder(chunk_size=1500,chunk_overlap=200)docs=text_splitter.create_documents([all_character_script_text])chain=load_summarize_chain(llm=model,chain_type="map_reduce")summary=chain.invoke(docs)(summary['output_text'])
Ausgabe:
Aurora and Magnus agree to retrieve a hidden artifact, and they enter an ancient library to find a book that will guide them to the relic...'
Auch wenn du eine map_reduce Kette benutzt hast, gibt es vier Hauptketten für die Arbeit mit Document Objekten innerhalb von LangChain: .
Sachen
Die Einfügekette für Dokumente , die auch als Stuff Chain bezeichnet wird (in Anlehnung an das Konzept des Stuffing oder Filling), ist der einfachste Ansatz unter den verschiedenen Strategien zur Verkettung von Dokumenten. Abbildung 4-5 veranschaulicht den Prozess der Integration mehrerer Dokumente in eine einzige LLM-Anfrage.
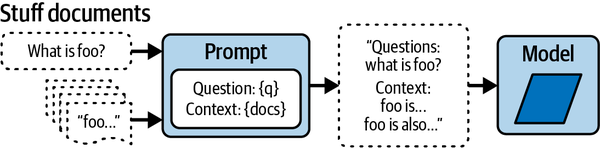
Abbildung 4-5. Kette von Stuff-Dokumenten
Verfeinern
Die Kette zur Verfeinerung von Dokumenten(Abbildung 4-6) erstellt eine LLM Antwort durch einen zyklischen Prozess, der seine Ausgabe iterativ aktualisiert. In jeder Schleife wird die aktuelle Ausgabe (aus dem LLM) mit dem aktuellen Dokument kombiniert. Eine weitere LLM-Anfrage wird gestellt, um die aktuelle Ausgabe zu aktualisieren. Dieser Prozess wird so lange fortgesetzt, bis alle Dokumente verarbeitet worden sind.
Abbildung 4-6. Dokumente verfeinern Kette
Map Reduce
Die Map-Reduce-Dokumente Kette in Abbildung 4-7 beginnt mit einer LLM-Kette zu jedem einzelnen Dokument (ein Prozess, der als Map-Schritt bekannt ist) und interpretiert die daraus resultierende Ausgabe als ein neu generiertes Dokument.
Anschließend werden all diese neu erstellten Dokumente in eine eigene Dokumentenkette eingefügt, um eine einzige Ausgabe zu formulieren (ein Prozess, der als Schritt "Reduzieren" bezeichnet wird). Um sicherzustellen, dass sich die neuen Dokumente nahtlos in die Kontextlänge einfügen, wird bei Bedarf ein optionaler Komprimierungsprozess auf die zugeordneten Dokumente angewendet. Falls erforderlich, erfolgt diese Komprimierung rekursiv.
Abbildung 4-7. Kette der Map-Reduce-Dokumente
Map Re-rank
Es gibt auch das Map Re-Rank, das mit einer anfänglichen Eingabeaufforderung für jedes Dokument arbeitet. Dabei wird nicht nur versucht, eine bestimmte Aufgabe zu erfüllen, sondern es wird auch ein Konfidenzwert vergeben, der die Gewissheit der Antwort widerspiegelt. Die Antwort mit dem höchsten Konfidenzwert wird dann ausgewählt und zurückgegeben.
Tabelle 4-1 zeigt die Vor- und Nachteile für die Wahl einer bestimmten Dokumentenkettenstrategie.
| Annäherung | Vorteile | Benachteiligungen |
|---|---|---|
Stuff Dokumente Kette |
Einfach zu implementieren. Ideal für Szenarien mit kleinen Dokumenten und wenigen Eingaben. |
Aufgrund der Größenbeschränkung der Eingabeaufforderung ist sie möglicherweise nicht für die Bearbeitung großer Dokumente oder mehrerer Eingaben geeignet. |
Dokumente verfeinern Kette |
Ermöglicht die iterative Verfeinerung der Antwort. Mehr Kontrolle über jeden Schritt der Antwortgenerierung. Gut für progressive Extraktionsaufgaben. |
Aufgrund des Schleifenprozesses ist es für Echtzeitanwendungen möglicherweise nicht optimal. |
Map Reduce Dokumente Kette |
Ermöglicht die unabhängige Verarbeitung jedes Dokuments. Kann große Datenmengen verarbeiten, indem sie in überschaubare Teile zerlegt werden. |
Erfordert eine sorgfältige Steuerung des Prozesses. Der optionale Komprimierungsschritt kann die Komplexität erhöhen und die Ordnung der Dokumente beeinträchtigen. |
Map Re-rank Dokumente Kette |
Gibt für jede Antwort einen Vertrauenswert an, um eine bessere Auswahl der Antworten zu ermöglichen. |
Der Ranking-Algorithmus kann komplex zu implementieren und zu verwalten sein. Er liefert möglicherweise nicht die beste Antwort, wenn der Bewertungsmechanismus nicht zuverlässig oder gut abgestimmt ist. |
Du kannst mehr darüber lesen, wie du verschiedene Dokumentenketten in der umfassenden API von LangChain und hier implementieren kannst.
Außerdem ist es möglich, den Kettentyp einfach in der Funktion load_summarize_chain zu ändern:
chain=load_summarize_chain(llm=model,chain_type='refine')
Es gibt neuere, besser anpassbare Ansätze zur Erstellung von Verdichtungsketten mit LCEL, aber für die meisten deiner Bedürfnisse liefert load_summarize_chain ausreichende Ergebnisse.
Zusammenfassung
In diesem Kapitel hast du einen umfassenden Überblick über das LangChain-Framework und seine wesentlichen Komponenten erhalten. Du hast gelernt, wie wichtig Dokumentenlader für das Sammeln von Daten sind und welche Rolle Textsplitter beim Umgang mit großen Textblöcken spielen.
Außerdem hast du die Konzepte der Aufgabenzerlegung und der Eingabeaufforderung kennengelernt. Indem du komplexe Probleme in kleinere Aufgaben zerlegst, hast du die Macht der Problemisolierung erkannt. Außerdem verstehst du jetzt, wie Eingabeaufforderungen mehrere Inputs/Outputs kombinieren können, um mehr Ideen zu generieren.
Im nächsten Kapitel erfährst du etwas über Vektordatenbanken und wie du sie mit Dokumenten aus LangChain integrieren kannst. Diese Fähigkeit wird eine entscheidende Rolle bei der Verbesserung der Genauigkeit der Wissensextraktion aus deinen Daten spielen.
Get Prompt Engineering für generative KI now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

