Kapitel 1. Microservices
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In den letzten Jahren hat die Technologiebranche einen rasanten Wandel in der angewandten, praktischen Architektur verteilter Systeme erlebt, der dazu geführt hat, dass Branchenriesen (wie Netflix, Twitter, Amazon, eBay und Uber) keine monolithischen Anwendungen mehr bauen, sondern die Microservice-Architektur übernehmen. Während die grundlegenden Konzepte hinter Microservices nicht neu sind, ist die heutige Anwendung der Microservice-Architektur tatsächlich neu. Ihre Einführung wurde zum Teil durch Skalierbarkeitsprobleme, mangelnde Effizienz, langsame Entwicklungsgeschwindigkeit und die Schwierigkeiten bei der Einführung neuer Technologien vorangetrieben, die entstehen, wenn komplexe Softwaresysteme in einer großen monolithischen Anwendung enthalten sind und als solche bereitgestellt werden.
Die Einführung einer Microservice-Architektur, sei es von Grund auf oder durch die Aufteilung einer bestehenden monolithischen Anwendung in unabhängig entwickelte und bereitgestellte Microservices, löst diese Probleme. Mit der Microservice-Architektur kann eine Anwendung sowohl horizontal als auch vertikal skaliert werden, die Produktivität und Geschwindigkeit der Entwickler/innen steigt drastisch und alte Technologien können leicht gegen die neuesten ausgetauscht werden.
Wie wir in diesem Kapitel sehen werden, kann die Einführung einer Microservice-Architektur als natürlicher Schritt bei der Skalierung einer Anwendung angesehen werden. Die Aufteilung einer monolithischen Anwendung in Microservices wird durch Skalierbarkeits- und Effizienzüberlegungen vorangetrieben, aber Microservices bringen auch eigene Herausforderungen mit sich. Ein erfolgreiches, skalierbares Microservice-Ökosystem setzt eine stabile und ausgefeilte Infrastruktur voraus. Außerdem muss die Organisationsstruktur eines Unternehmens, das Microservices einführt, radikal verändert werden, um die Microservice-Architektur zu unterstützen, und die daraus resultierenden Teamstrukturen können zu Siloing und Zersplitterung führen. Die größten Herausforderungen, die die Microservice-Architektur mit sich bringt, sind jedoch die notwendige Standardisierung der Architektur der Dienste selbst sowie die Anforderungen an jeden Microservice, um Vertrauen und Verfügbarkeit zu gewährleisten.
Von Monolithen zu Microservices
Fast jede Softwareanwendung, die heute geschrieben wird, kann in drei verschiedene Elemente unterteilt werden: ein Frontend (oder clientseitiger Teil), ein Backend-Teil und eine Art Datenspeicher(Abbildung 1-1). Anfragen an die Anwendung werden über die Client-Seite gestellt, der Backend-Code erledigt die gesamte Arbeit und alle relevanten Daten, die gespeichert oder abgerufen werden müssen (ob vorübergehend im Speicher oder dauerhaft in einer Datenbank), werden an den Ort, an dem die Daten gespeichert sind, gesendet oder von dort abgerufen. Wir nennen das die dreistufige Architektur.

Abbildung 1-1. Dreistufige Architektur
Es gibt drei verschiedene Möglichkeiten, wie diese Elemente zu einer Anwendung kombiniert werden können. Die meisten Anwendungen fassen die ersten beiden Teile in einer Codebasis (oder einem Repository) zusammen, in der der gesamte clientseitige und der Backend-Code als eine ausführbare Datei mit einer separaten Datenbank gespeichert und ausgeführt werden. Bei anderen Anwendungen wird der gesamte clientseitige Frontend-Code vom Backend-Code getrennt und als getrennte logische ausführbare Dateien gespeichert, die von einer externen Datenbank begleitet werden. Anwendungen, die keine externe Datenbank benötigen und alle Daten im Arbeitsspeicher speichern, fassen alle drei Elemente in einem Repository zusammen. Unabhängig davon, wie diese Elemente aufgeteilt oder kombiniert werden, wird die Anwendung selbst als die Summe dieser drei verschiedenen Elemente betrachtet.
Anwendungen werden in der Regel von Beginn ihres Lebenszyklus an auf diese Weise konzipiert, entwickelt und betrieben. Die Architektur der Anwendung ist in der Regel unabhängig vom Produkt, das das Unternehmen anbietet, oder vom Zweck der Anwendung selbst. Diese drei architektonischen Elemente, aus denen sich die dreistufige Architektur zusammensetzt, sind in jeder Website, jeder Telefonanwendung, jedem Backend und Frontend und jeder merkwürdigen riesigen Unternehmensanwendung vorhanden und finden sich als eine der beschriebenen Permutationen.
In der Anfangsphase, wenn ein Unternehmen noch jung ist, seine Anwendung(en) einfach sind und nur wenige Entwickler/innen zur Codebasis beitragen, teilen sich die Entwickler/innen in der Regel die Last, zur Codebasis beizutragen und sie zu pflegen. Wenn das Unternehmen wächst, werden mehr Entwickler/innen eingestellt, die Anwendung wird um neue Funktionen erweitert, und drei wichtige Dinge passieren.
Zunächst einmal steigt die betriebliche Arbeitsbelastung. Operative Arbeit ist, allgemein gesprochen, die Arbeit, die mit dem Betrieb und der Wartung der Anwendung verbunden ist. Dies führt in der Regel dazu, dass Betriebsingenieure (Systemadministratoren, TechOps-Ingenieure und so genannte "DevOps"-Ingenieure) eingestellt werden, die den Großteil der betrieblichen Aufgaben übernehmen, z. B. in Bezug auf Hardware, Überwachung und Rufbereitschaft.
Die zweite Sache, die passiert, ist ein Ergebnis einfacher Mathematik: Wenn du neue Funktionen zu deiner Anwendung hinzufügst, steigt sowohl die Anzahl der Codezeilen in deiner Anwendung als auch die Komplexität der Anwendung selbst.
Der dritte Punkt ist die notwendige horizontale und/oder vertikale Skalierung der Anwendung. Eine Zunahme des Verkehrsaufkommens stellt erhebliche Anforderungen an die Skalierbarkeit und Leistung der Anwendung, so dass mehr Server für die Anwendung erforderlich sind. Es werden weitere Server hinzugefügt, eine Kopie der Anwendung wird auf jedem Server installiert und Load Balancer werden eingesetzt, damit die Anfragen angemessen auf die Server verteilt werden, auf denen die Anwendung läuft (siehe Abbildung 1-2 mit einem Frontend, das seine eigene Load Balancing-Schicht enthalten kann, einer Backend Load Balancing-Schicht und den Backend-Servern). Die vertikale Skalierung wird notwendig, wenn die Anwendung eine größere Anzahl von Aufgaben im Zusammenhang mit ihren vielfältigen Funktionen zu verarbeiten beginnt, sodass die Anwendung auf größeren, leistungsfähigeren Servern bereitgestellt wird, die die CPU- und Speicheranforderungen bewältigen können(Abbildung 1-3).
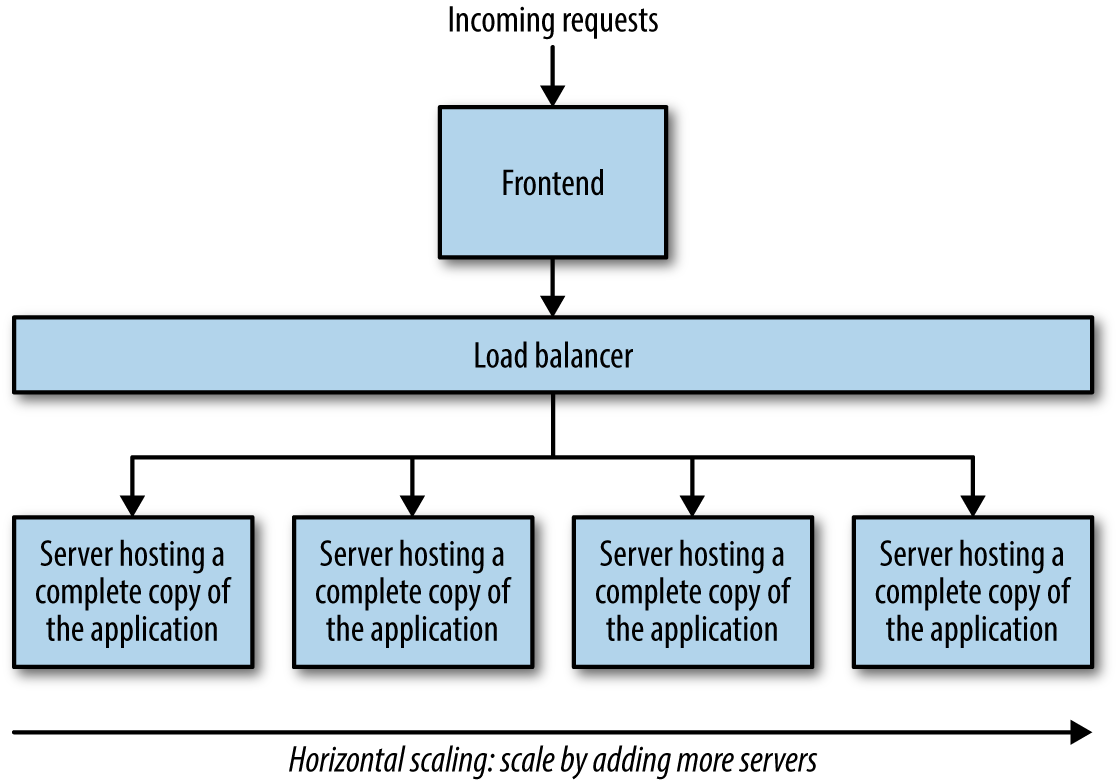
Abbildung 1-2. Horizontale Skalierung einer Anwendung
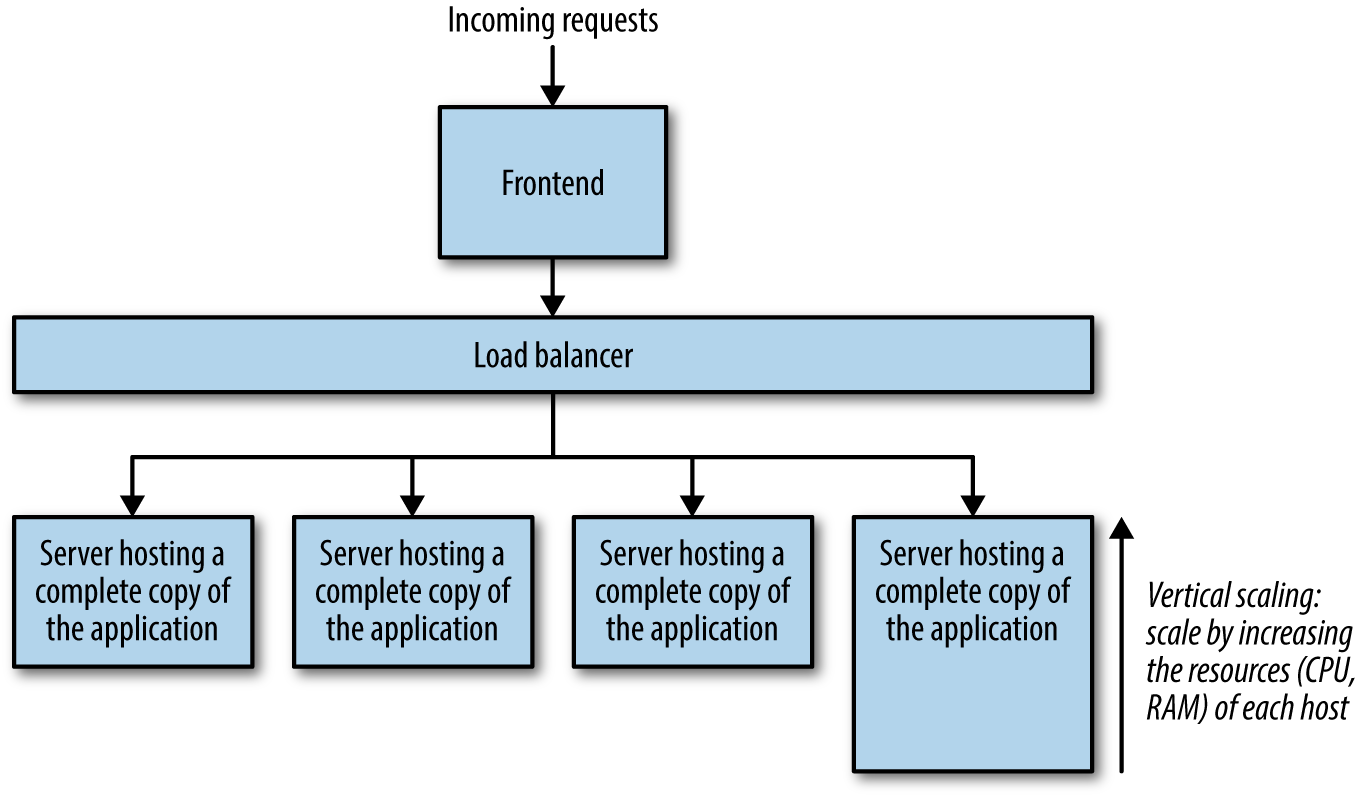
Abbildung 1-3. Vertikale Skalierung einer Anwendung
Wenn das Unternehmen wächst und die Zahl der Ingenieure nicht mehr im ein-, zwei- oder gar dreistelligen Bereich liegt, werden die Dinge ein wenig komplizierter. Dank all der Funktionen, Patches und Korrekturen, die von den Entwicklern zur Codebasis hinzugefügt wurden, ist die Anwendung nun Tausende von Zeilen lang. Die Komplexität der Anwendung nimmt stetig zu, und es müssen Hunderte (wenn nicht Tausende) von Tests geschrieben werden, um sicherzustellen, dass jede Änderung (selbst eine Änderung von ein oder zwei Zeilen) die Integrität der bestehenden Tausenden von Codezeilen nicht gefährdet. Entwicklung und Bereitstellung werden zu einem Albtraum, Tests werden zu einer Last und zu einem Hindernis für die Bereitstellung selbst der wichtigsten Korrekturen, und die technischen Schulden häufen sich schnell an. Anwendungen, deren Lebenszyklus (im Guten wie im Schlechten) in dieses Muster passt, werden in der Software-Community liebevoll (und zu Recht) als Monolithen bezeichnet.
Natürlich sind nicht alle monolithischen Anwendungen schlecht und nicht jede monolithische Anwendung leidet unter den aufgeführten Problemen, aber Monolithen, die nicht irgendwann in ihrem Lebenszyklus auf diese Probleme stoßen, sind (meiner Erfahrung nach) ziemlich selten. Der Grund dafür, dass die meisten Monolithen für diese Probleme anfällig sind, liegt darin, dass die Natur eines Monolithen der Skalierbarkeit im allgemeinsten Sinne direkt entgegensteht. Die Skalierbarkeit erfordert Gleichzeitigkeit und Partitionierung: zwei Dinge, die bei einem Monolithen schwer zu erreichen sind.
Wir haben dieses Muster bei Unternehmen wie Amazon, Twitter, Netflix, eBay und Uber beobachtet: Unternehmen, die Anwendungen nicht nur auf Hunderten, sondern auf Tausenden oder sogar Hunderttausenden von Servern betreiben und deren Anwendungen sich zu Monolithen entwickelt haben und auf Skalierungsprobleme stießen. Die Herausforderungen, mit denen sie konfrontiert waren, wurden durch die Abkehr von der monolithischen Anwendungsarchitektur zugunsten von Microservices gelöst.
Das Grundkonzept eines Microservice ist einfach: Es handelt sich um eine kleine Anwendung, die nur eine Sache tut, und zwar eine gute. Ein Microservice ist eine kleine Komponente, die leicht austauschbar ist, unabhängig entwickelt und unabhängig eingesetzt werden kann. Ein Microservice kann jedoch nicht alleine leben - kein Microservice ist eine Insel - und er ist Teil eines größeren Systems, das zusammen mit anderen Microservices läuft und arbeitet, um das zu erreichen, was normalerweise von einer großen, eigenständigen Anwendung erledigt wird.
Das Ziel der Microservice-Architektur ist es, eine Reihe von kleinen Anwendungen zu erstellen, die jeweils für eine Funktion verantwortlich sind (im Gegensatz zur traditionellen Methode, eine einzige Anwendung zu erstellen, die alles kann), und dafür zu sorgen, dass jeder Microservice eigenständig, unabhängig und in sich geschlossen ist. Der Hauptunterschied zwischen einer monolithischen Anwendung und Microservices ist folgender: Eine monolithische Anwendung(Abbildung 1-4) enthält alle Funktionen in einer Anwendung und einer Codebasis, die alle zur gleichen Zeit bereitgestellt werden, wobei jeder Server eine vollständige Kopie der gesamten Anwendung enthält, während ein Microservice(Abbildung 1-5) nur eine Funktion oder ein Feature enthält und in einem Microservice-Ökosystem zusammen mit anderen Microservices lebt, die jeweils eine Funktion oder ein Feature ausführen.
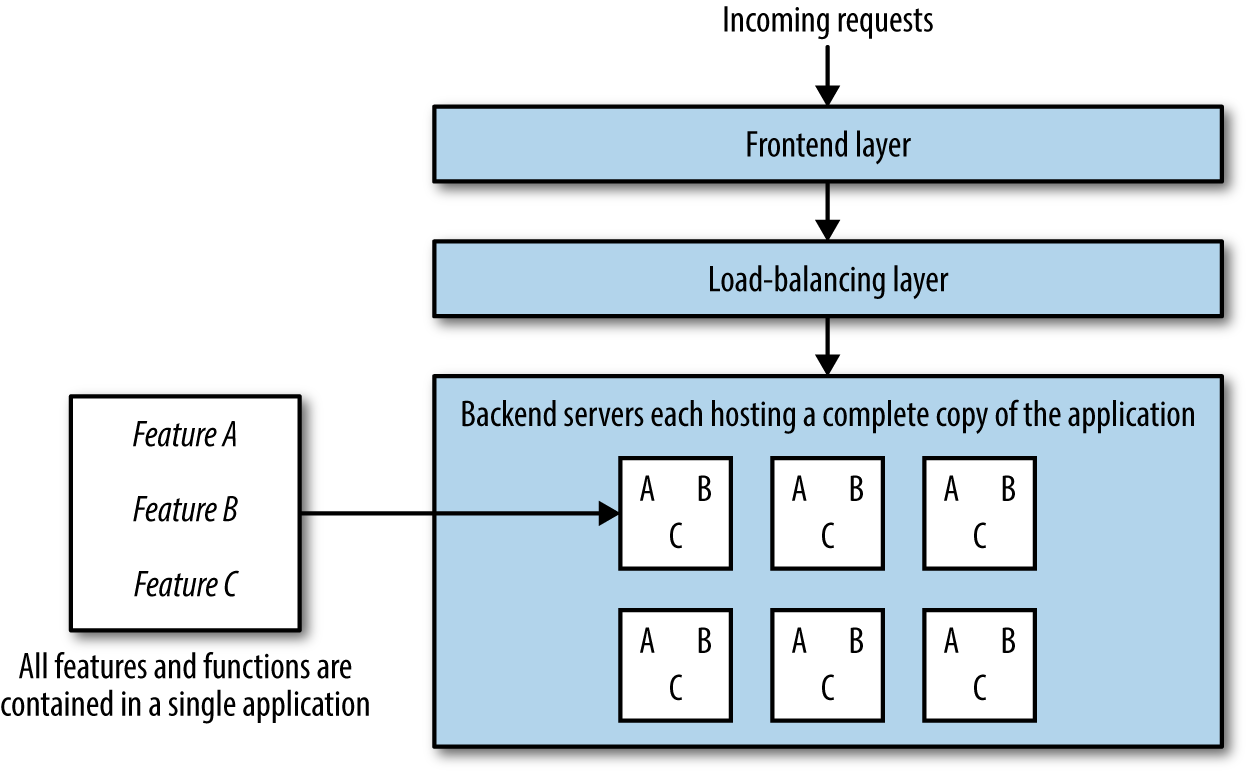
Abbildung 1-4. Monolith
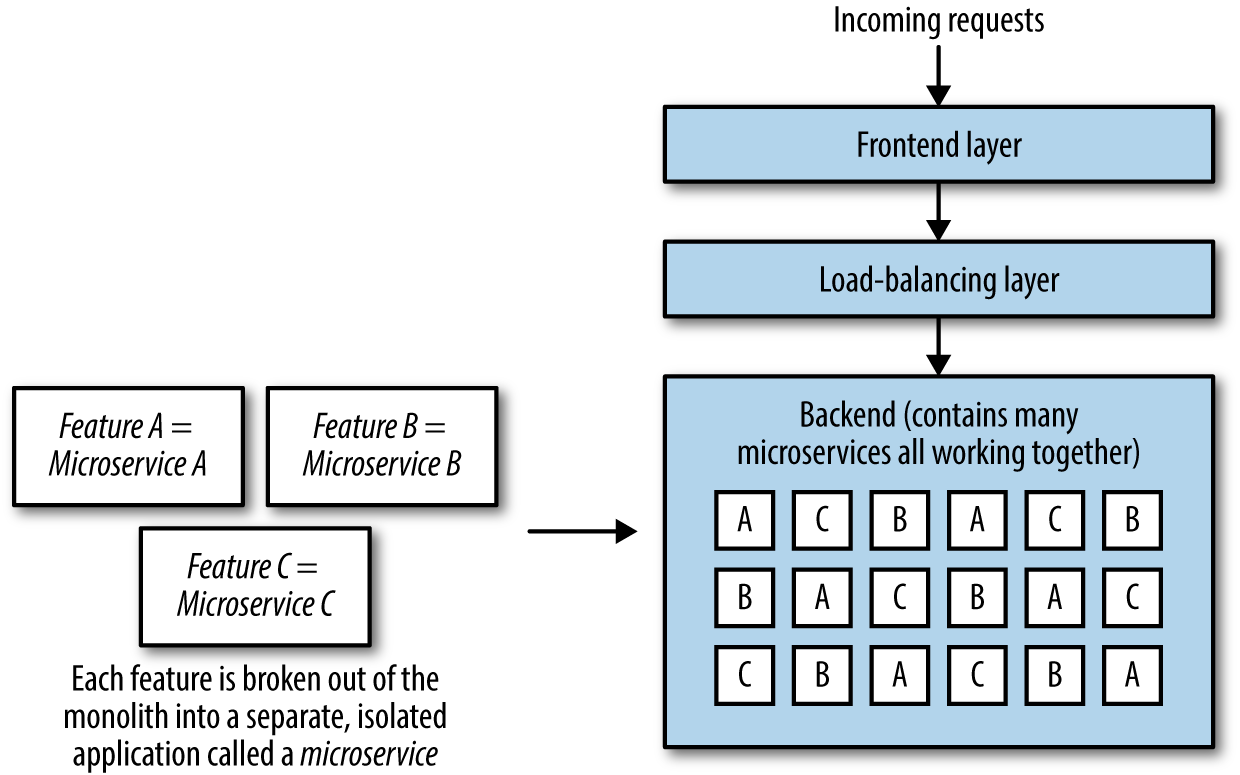
Abbildung 1-5. Microservices
Es gibt zahlreiche Vorteile der Microservice-Architektur, darunter (aber nicht nur) eine geringere technische Verschuldung, eine höhere Produktivität und Geschwindigkeit der Entwickler, eine bessere Testeffizienz, eine höhere Skalierbarkeit und eine einfachere Bereitstellung. Unternehmen, die eine Microservice-Architektur einführen, tun dies in der Regel, nachdem sie eine Anwendung entwickelt haben und auf Skalierbarkeits- und Organisationsprobleme gestoßen sind. Sie beginnen mit einer monolithischen Anwendung und unterteilen den Monolithen dann in Microservices.
Die Schwierigkeiten bei der Aufspaltung eines Monolithen in Microservices hängen ganz von der Komplexität der monolithischen Anwendung ab. Eine monolithische Anwendung mit vielen Funktionen erfordert einen hohen architektonischen Aufwand und sorgfältige Überlegungen, um sie erfolgreich in Microservices aufzuteilen, und zusätzliche Komplexität entsteht durch die Notwendigkeit, Teams neu zu organisieren und umzustrukturieren. Die Entscheidung, auf Microservices umzusteigen, muss immer ein unternehmensweiter Prozess sein.
Es gibt mehrere Schritte, um einen Monolithen zu zerlegen. Der erste besteht darin, die Komponenten zu identifizieren, die als unabhängige Dienste geschrieben werden sollten. Dies ist vielleicht der schwierigste Schritt des gesamten Prozesses, denn es gibt zwar eine Reihe richtiger Wege, den Monolithen in Komponentendienste aufzuteilen, aber noch viel mehr falsche Wege. Die Faustregel bei der Identifizierung von Komponenten lautet, die wichtigsten Gesamtfunktionen des Monolithen zu bestimmen und diese Funktionen dann in kleine unabhängige Komponenten aufzuteilen. Microservices müssen so einfach wie möglich sein, sonst riskiert das Unternehmen, einen Monolithen durch mehrere kleinere Monolithen zu ersetzen, die alle die gleichen Probleme haben, wenn das Unternehmen wächst.
Sobald die Schlüsselfunktionen identifiziert und in unabhängige Microservices aufgeteilt sind, muss die Organisationsstruktur des Unternehmens so umstrukturiert werden, dass jeder Microservice von einem Ingenieurteam betreut wird. Dafür gibt es mehrere Möglichkeiten. Die erste Methode zur Umstrukturierung des Unternehmens im Zusammenhang mit der Einführung von Microservices besteht darin, jedem Microservice ein eigenes Team zu widmen. Die Größe des Teams richtet sich ganz nach der Komplexität und der Arbeitslast des Microservices und sollte mit genügend Entwicklern und Site Reliability Engineers besetzt sein, damit sowohl die Entwicklung von Funktionen als auch die Bereitschaftsrotation des Services bewältigt werden können, ohne das Team zu belasten. Die zweite Möglichkeit ist, mehrere Dienste einem Team zuzuweisen und dieses Team die Dienste parallel entwickeln zu lassen. Das funktioniert am besten, wenn die Teams nach bestimmten Produkten oder Geschäftsbereichen organisiert sind und für die Entwicklung aller Dienste zuständig sind, die mit diesen Produkten oder Bereichen zusammenhängen. Wenn sich ein Unternehmen für die zweite Methode der Reorganisation entscheidet, muss es sicherstellen, dass die Entwickler/innen nicht überlastet werden und nicht unter Aufgaben-, Ausfall- oder Betriebsmüdigkeit leiden.
Ein weiterer wichtiger Teil der Einführung von Microservices ist die Schaffung eines Microservice-Ökosystems. Normalerweise (oder zumindest hoffentlich) hat ein Unternehmen, das eine große monolithische Anwendung betreibt, eine eigene Infrastrukturorganisation, die für die Entwicklung, den Aufbau und die Wartung der Infrastruktur verantwortlich ist, auf der die Anwendung läuft. Wenn eine monolithische Anwendung in Microservices aufgeteilt wird, wächst die Verantwortung der Infrastrukturorganisation für die Bereitstellung einer stabilen Plattform, auf der die Microservices entwickelt und ausgeführt werden können, drastisch an. Die Infrastrukturteams müssen den Microservice-Teams eine stabile Infrastruktur zur Verfügung stellen, die den Großteil der Komplexität der Interaktionen zwischen den Microservices abstrahiert.
Sobald diese drei Schritte abgeschlossen sind - die Komponentisierung der Anwendung, die Umstrukturierung der Ingenieurteams für jeden Microservice und die Entwicklung der Infrastrukturorganisation innerhalb des Unternehmens - kann die Migration beginnen. Einige Teams entscheiden sich dafür, den relevanten Code für ihren Microservice direkt aus dem Monolithen in einen separaten Dienst zu ziehen und den Datenverkehr des Monolithen zu beschatten, bis sie davon überzeugt sind, dass der Microservice die gewünschten Funktionen auch allein ausführen kann. Andere Teams entscheiden sich dafür, den Dienst von Grund auf neu aufzubauen und den Datenverkehr zu beschatten oder umzuleiten, nachdem der Dienst die entsprechenden Tests bestanden hat. Der beste Migrationsansatz hängt von der Funktionalität des Microservices ab, und ich habe gesehen, dass beide Ansätze in den meisten Fällen gleich gut funktionieren. Der eigentliche Schlüssel zu einer erfolgreichen Migration ist jedoch eine gründliche, sorgfältige und sorgfältig dokumentierte Planung und Durchführung sowie die Erkenntnis, dass eine vollständige Migration eines großen Monolithen mehrere Jahre dauern kann.
Bei all der Arbeit, die mit der Aufteilung eines Monolithen in Microservices verbunden ist, mag es besser erscheinen, mit einer Microservice-Architektur zu beginnen, alle schmerzhaften Skalierbarkeitsherausforderungen zu überspringen und das Drama der Microservice-Migration zu vermeiden. Dieser Ansatz mag für einige Unternehmen gut funktionieren, aber ich möchte einige Worte der Vorsicht aussprechen. Kleine Unternehmen verfügen oft nicht über die nötige Infrastruktur, um Microservices zu betreiben, selbst wenn sie sehr klein sind: Eine gute Microservice-Architektur erfordert eine stabile, oft sehr komplexe Infrastruktur. Eine solche stabile Infrastruktur erfordert ein großes, engagiertes Team, dessen Kosten in der Regel nur von Unternehmen getragen werden können, die die Herausforderungen der Skalierbarkeit erreicht haben, die den Wechsel zur Microservice-Architektur rechtfertigen. Kleine Unternehmen haben einfach nicht genug betriebliche Kapazitäten, um ein Microservice-Ökosystem zu unterhalten. Außerdem ist es außerordentlich schwierig, die wichtigsten Bereiche und Komponenten zu identifizieren, die in Microservices integriert werden sollen, wenn sich ein Unternehmen noch in der Anfangsphase befindet: Anwendungen in neuen Unternehmen haben weder viele Funktionen noch viele separate Funktionsbereiche, die angemessen in Microservices aufgeteilt werden können.
Microservice Architektur
Die Architektur eines Microservices(Abbildung 1-6) unterscheidet sich nicht sehr von der Standardanwendungsarchitektur, die im ersten Abschnitt dieses Kapitels behandelt wurde(Abbildung 1-1). Jeder Microservice besteht aus drei Komponenten: einer Frontend-Komponente (auf der Client-Seite), einem Backend-Code, der die Hauptarbeit leistet, und einer Möglichkeit, relevante Daten zu speichern oder abzurufen.
Das Frontend, der clientseitige Teil eines Microservices, ist keine typische Frontend-Anwendung, sondern eine Programmierschnittstelle (API) mit statischen Endpunkten. Gut konzipierte Microservice-APIs ermöglichen es Microservices, einfach und effektiv zu interagieren, indem sie Anfragen an den/die entsprechenden API-Endpunkt(e) senden. Ein Microservice, der für Kundendaten zuständig ist, könnte zum Beispiel einen Endpunkt get_customer_information haben, an den andere Dienste Anfragen senden können, um Informationen über Kunden abzurufen, einen Endpunkt update_customer_information, an den andere Dienste Anfragen senden können, um die Informationen für einen bestimmten Kunden zu aktualisieren, und einen Endpunkt delete_customer_information, den Dienste verwenden können, um die Informationen eines Kunden zu löschen.
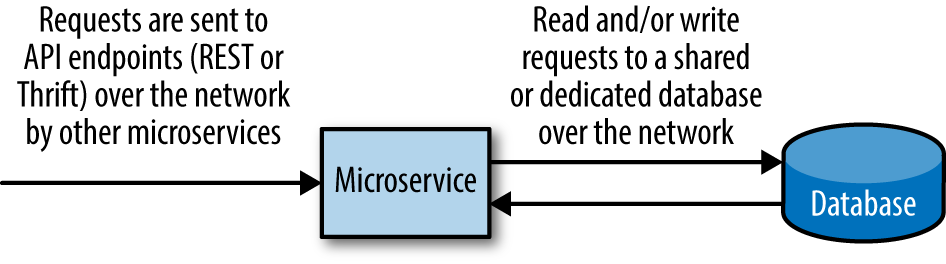
Abbildung 1-6. Elemente der Microservice-Architektur
Diese Endpunkte sind nur in der Architektur und Theorie getrennt, nicht aber in der Praxis, denn sie laufen neben und als Teil des Backend-Codes, der jede Anfrage verarbeitet. Bei unserem Beispiel-Microservice, der für Kundendaten zuständig ist, würde eine an den Endpunkt get_customer_information gesendete Anfrage eine Aufgabe auslösen, die die eingehende Anfrage verarbeitet, alle spezifischen Filter oder Optionen bestimmt, die in der Anfrage angewendet wurden, die Informationen aus einer Datenbank abruft, die Informationen formatiert und sie an den Client (Microservice) zurücksendet, der sie angefordert hat.
Die meisten Microservices speichern irgendeine Art von Daten, entweder im Speicher (vielleicht mit einem Cache) oder in einer externen Datenbank. Wenn die relevanten Daten im Arbeitsspeicher gespeichert sind, muss kein zusätzlicher Netzwerkaufruf an eine externe Datenbank erfolgen, und der Microservice kann alle relevanten Daten problemlos an den Kunden zurückgeben. Wenn die Daten in einer externen Datenbank gespeichert sind, muss der Microservice eine weitere Anfrage an die Datenbank stellen, auf eine Antwort warten und dann mit der Bearbeitung der Aufgabe fortfahren.
Diese Architektur ist notwendig, wenn Microservices gut zusammenarbeiten sollen. Das Paradigma der Microservice-Architektur erfordert, dass eine Reihe von Microservices zusammenarbeiten, um das zu bilden, was sonst eine große Anwendung wäre. Daher gibt es bestimmte Elemente dieser Architektur, die im gesamten Unternehmen standardisiert werden müssen, wenn eine Reihe von Microservices erfolgreich und effizient zusammenarbeiten soll.
Die API-Endpunkte von Microservices sollten innerhalb einer Organisation standardisiert sein. Das heißt nicht, dass alle Microservices dieselben spezifischen Endpunkte haben sollten, aber die Art des Endpunkts sollte die gleiche sein. Zwei sehr verbreitete Arten von API-Endpunkten für Microservices sind REST oder Apache Thrift, und ich habe einige Microservices gesehen, die beide Arten von Endpunkten haben (das ist allerdings selten, macht die Überwachung ziemlich kompliziert und ich empfehle es nicht unbedingt). Die Wahl des Endpunkttyps spiegelt die interne Funktionsweise des Microservices wider und bestimmt auch seine Architektur: Es ist zum Beispiel schwierig, einen asynchronen Microservice zu bauen, der über REST-Endpunkte per HTTP kommuniziert, was es erforderlich machen würde, den Services auch einen messagingbasierten Endpunkt hinzuzufügen.
Microservices interagieren über Remote Procedure Calls (RPCs) miteinander. sind Aufrufe über das Netzwerk, die genauso aussehen und sich genauso verhalten wie lokale Prozeduraufrufe. Welche Protokolle verwendet werden, hängt von den architektonischen Entscheidungen und der organisatorischen Unterstützung sowie von den verwendeten Endpunkten ab. Ein Microservice mit REST-Endpunkten wird beispielsweise wahrscheinlich über HTTP mit anderen Microservices interagieren, während ein Microservice mit Thrift-Endpunkten über HTTP oder eine individuellere, interne Lösung mit anderen Microservices kommunizieren kann.
Versionierung von Microservices und Endpunkten vermeiden
Ein Microservice ist keine Bibliothek (er wird weder bei der Kompilierung noch zur Laufzeit in den Speicher geladen), sondern eine unabhängige Softwareanwendung. Aufgrund der Schnelllebigkeit der Microservice-Entwicklung kann die Versionierung von Microservices leicht zu einem organisatorischen Albtraum werden, da die Entwickler/innen der Client-Services bestimmte (veraltete, nicht gewartete) Versionen eines Microservices in ihrem eigenen Code festhalten. Microservices sollten als lebendige, sich verändernde Dinge behandelt werden, nicht als statische Versionen oder Bibliotheken. Die Versionierung von API-Endpunkten ist ein weiteres Anti-Muster, das aus denselben Gründen vermieden werden sollte.
Jede Art von Endpunkt und jedes Protokoll, das für die Kommunikation mit anderen Microservices verwendet wird, bringt Vorteile und Kompromisse mit sich. Die architektonischen Entscheidungen, die hier getroffen werden, sollten nicht vom einzelnen Entwickler getroffen werden, der einen Microservice baut, sondern sie sollten Teil des architektonischen Designs des Microservice-Ökosystems als Ganzes sein (wir kommen im nächsten Abschnitt darauf zu sprechen).
Das Schreiben eines Microservices gibt dem Entwickler viele Freiheiten: Abgesehen von den organisatorischen Entscheidungen bezüglich der API-Endpunkte und Kommunikationsprotokolle können die Entwickler das Innenleben ihres Microservices schreiben, wie sie wollen. Er kann in jeder beliebigen Sprache geschrieben werden - in Go, in Java, in Erlang, in Haskell - solange die Endpunkte und Kommunikationsprotokolle berücksichtigt werden. Die Entwicklung eines Microservices unterscheidet sich nicht allzu sehr von der Entwicklung einer eigenständigen Anwendung. Wie wir im letzten Abschnitt dieses Kapitels ("Organisatorische Herausforderungen") sehen werden, gibt es jedoch einige Einschränkungen, denn die Freiheit der Entwickler bei der Wahl der Sprache hat einen hohen Preis für die Entwicklungsorganisation.
Auf diese Weise kann ein Microservice von anderen wie eine Blackbox behandelt werden: Du gibst einige Informationen ein, indem du eine Anfrage an einen seiner Endpunkte sendest, und bekommst etwas zurück. Wenn du das, was du willst und brauchst, in einer angemessenen Zeit und ohne verrückte Fehler aus dem Microservice herausbekommst, hat er seine Aufgabe erfüllt, und du brauchst nichts weiter zu verstehen als die Endpunkte, die du ansteuern musst, und ob der Dienst richtig funktioniert oder nicht.
Unsere Diskussion über die Besonderheiten der Microservice-Architektur endet hier - nicht, weil dies alles ist, was die Microservice-Architektur ausmacht, sondern weil jedes der folgenden Kapitel in diesem Buch dem Ziel gewidmet ist, Microservices in diesen idealen Blackbox-Zustand zu bringen.
Das Microservice-Ökosystem
Microservices leben nicht in Isolation. Sie leben in der Umgebung, in der Microservices erstellt werden, in der sie laufen und in der sie interagieren. Die Komplexität der groß angelegten Microservice-Umgebung ist vergleichbar mit der ökologischen Komplexität eines Regenwaldes, einer Wüste oder eines Ozeans, und die Betrachtung dieser Umgebung als Ökosystem - ein Microservice-Ökosystem - istbei der Einführung der Microservice-Architektur von Vorteil.
In gut durchdachten, nachhaltigen Microservice-Ökosystemen sind die Microservices von der gesamten Infrastruktur abstrahiert. Sie sind abstrahiert von der Hardware, abstrahiert von den Netzwerken, abstrahiert von der Build- und Deployment-Pipeline, abstrahiert von der Service Discovery und dem Lastausgleich. All dies ist Teil der Infrastruktur des Microservice-Ökosystems, und der Aufbau, die Standardisierung und die Wartung dieser Infrastruktur in einer stabilen, skalierbaren, fehlertoleranten und zuverlässigen Weise ist für den erfolgreichen Betrieb von Microservices unerlässlich.
Die Infrastruktur muss das Microservice-Ökosystem unterstützen. Das Ziel aller Infrastruktur-Ingenieure und -Architekten muss es sein, die betrieblichen Belange der Microservice-Entwicklung aus dem Weg zu räumen und eine stabile, skalierbare Infrastruktur aufzubauen, auf der Entwicklerinnen und Entwickler problemlos Microservices entwickeln und ausführen können. Die Entwicklung eines Microservices innerhalb eines stabilen Microservice-Ökosystems sollte genauso einfach sein wie die Entwicklung einer kleinen, eigenständigen Anwendung. Dies erfordert eine sehr ausgefeilte, erstklassige Infrastruktur.
Das Microservice-Ökosystem lässt sich in vier Schichten unterteilen(Abbildung 1-7), wobei die Grenzen der einzelnen Schichten nicht immer klar definiert sind: Einige Elemente der Infrastruktur berühren jeden Teil des Stacks. Die unteren drei Schichten sind die Infrastrukturebenen: Am unteren Ende des Stacks befindet sich die Hardwareschicht, darüber die Kommunikationsschicht (die in die vierte Schicht übergeht), gefolgt von der Anwendungsplattform. Auf der vierten (obersten) Schicht befinden sich die einzelnen Microservices.
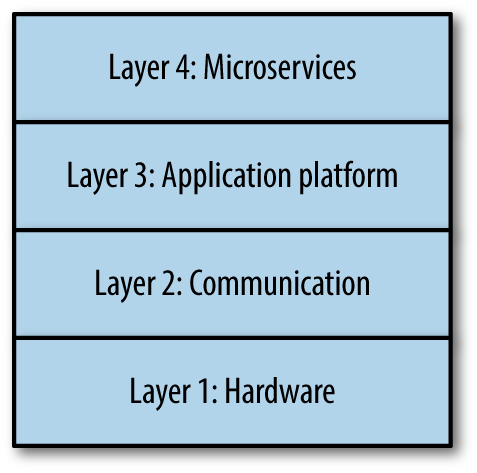
Abbildung 1-7. Vier-Schichten-Modell des Microservice-Ökosystems
Schicht 1: Hardware
ganz unten im Microservice-Ökosystem finden wir die Hardware-Schicht. Das sind die eigentlichen Maschinen, die echten, physischen Computer, auf denen alle internen Tools und alle Microservices laufen. Diese Server befinden sich in Racks in Rechenzentren, werden von teuren HVAC-Systemen gekühlt und mit Strom versorgt. Hier können viele verschiedene Arten von Servern stehen: Einige sind für Datenbanken optimiert, andere für die Verarbeitung von CPU-intensiven Aufgaben. Diese Server können entweder dem Unternehmen selbst gehören oder von sogenannten Cloud-Providern wie Amazon Web Services' Elastic Compute Cloud (AWS EC2), Google Cloud Platform (GCP) oder Microsoft Azure "gemietet" werden.
Die Wahl der spezifischen Hardware wird von den Eigentümern der Server bestimmt. Wenn dein Unternehmen eigene Rechenzentren betreibt, hast du die Wahl der Hardware selbst in der Hand und kannst die Serverauswahl für deine spezifischen Bedürfnisse optimieren. Wenn du Server in der Cloud betreibst (was das häufigere Szenario ist), ist deine Auswahl auf die vom Cloud-Provider angebotene Hardware beschränkt. Die Entscheidung zwischen Bare Metal und einem Cloud-Provider (oder mehreren Cloud-Providern) ist nicht leicht zu treffen, denn Kosten, Verfügbarkeit, Zuverlässigkeit und Betriebskosten müssen berücksichtigt werden.
Die Verwaltung dieser Server ist Teil der Hardwareschicht. Auf jedem Server muss ein Betriebssystem installiert sein, und das Betriebssystem sollte für alle Server standardisiert sein. Es gibt keine richtige Antwort auf die Frage, welches Betriebssystem ein Microservice-Ökosystem verwenden sollte: Die Antwort auf diese Frage hängt ganz von den Anwendungen ab, die du erstellen willst, von den Sprachen, in denen sie geschrieben werden, und von den Bibliotheken und Tools, die deine Microservices benötigen. Die meisten Microservice-Ökosysteme verwenden eine Variante von Linux, in der Regel CentOS, Debian oder Ubuntu, aber ein .NET-Unternehmen wird sich natürlich anders entscheiden. Zusätzliche Abstraktionen können auf der Hardware aufgebaut und geschichtet werden: Ressourcenisolierung und Ressourcenabstraktion (wie sie von Technologien wie Docker und Apache Mesos angeboten werden) gehören ebenfalls in diese Schicht, ebenso wie Datenbanken (dediziert oder gemeinsam genutzt).
Die Installation eines Betriebssystems und die Bereitstellung der Hardware ist die erste Schicht über den Servern selbst. Jeder Host muss eingerichtet und konfiguriert werden. Nach der Installation des Betriebssystems sollte ein Konfigurationsmanagement-Tool (wie Ansible, Chef oder Puppet) verwendet werden, um alle Anwendungen zu installieren und alle notwendigen Konfigurationen festzulegen.
Die Hosts benötigen eine angemessene Überwachung auf Host-Ebene (z. B. mit Nagios) und eine Protokollierung auf Host-Ebene, damit im Falle eines Ereignisses (Festplattenausfall, Netzwerkausfall oder wenn die CPU-Auslastung durch die Decke geht) Probleme mit den Hosts leicht diagnostiziert, entschärft und behoben werden können. Die Überwachung auf Host-Ebene wird in Kapitel 6, Überwachung, ausführlicher behandelt.
Schicht 2: Kommunikation
Die zweite Schicht des Microservice-Ökosystems ist die Kommunikationsschicht. Die Kommunikationsschicht fließt in alle anderen Schichten des Ökosystems ein (einschließlich der Anwendungsplattform und der Microservice-Schichten), da hier die gesamte Kommunikation zwischen den Diensten abgewickelt wird. Die Grenzen zwischen der Kommunikationsschicht und jeder anderen Schicht des Microservice-Ökosystems sind nur unzureichend definiert. Auch wenn die Grenzen nicht klar sind, sind die Elemente eindeutig: Die zweite Schicht eines Microservice-Ökosystems enthält immer das Netzwerk, DNS, RPCs und API-Endpunkte, Service Discovery, Service Registry und Load Balancing.
Die Erörterung der Netzwerk- und DNS-Elemente der Kommunikationsschicht würde den Rahmen dieses Buches sprengen, daher konzentrieren wir uns in diesem Abschnitt auf RPCs, API-Endpunkte, Service Discovery, Service Registry und Lastausgleich.
RPCs, Endpunkte und Messaging
Microservices interagieren über das Netzwerk miteinander, indem sie Remote Procedure Calls (RPCs) oder Messaging an die API-Endpunkte anderer Microservices senden (oder, wie wir im Fall von Messaging sehen werden, an einen Message Broker, der die Nachricht entsprechend weiterleitet). Der Grundgedanke ist folgender: Ein Microservice sendet mithilfe eines bestimmten Protokolls Daten in einem standardisierten Format über das Netzwerk an einen anderen Service (vielleicht an den API-Endpunkt eines anderen Microservices) oder an einen Message Broker, der dafür sorgt, dass die Daten an den API-Endpunkt eines anderen Microservices gesendet werden.
Es gibt verschiedene Kommunikationsparadigmen für Microservices . Das erste ist das am weitesten verbreitete: HTTP+REST/THRIFT. Bei HTTP+REST/THRIFT kommunizieren die Dienste über das Netzwerk mit dem Hypertext Transfer Protocol (HTTP), und senden Anfragen und empfangen Antworten entweder an oder von bestimmten REST-Endpunkten (mit verschiedenen Methoden wie GET, POST usw.) oder bestimmten Apache Thrift-Endpunkten (oder beidem). Die Daten werden normalerweise formatiert und als JSON (oder Protokollpuffer) über HTTP gesendet.
HTTP+REST ist die bequemste Form der Microservice-Kommunikation. Es gibt keine Überraschungen, sie ist einfach einzurichten und am stabilsten und zuverlässigsten - vor allem, weil es schwierig ist, sie falsch zu implementieren. Der Nachteil dieses Paradigmas ist, dass es zwangsläufig synchron (blockierend) ist.
Das zweite Kommunikationsparadigma ist Messaging. Messaging ist asynchron (nicht blockierend), aber es ist etwas komplizierter. Messaging funktioniert folgendermaßen: Ein Microservice sendet Daten (eine Nachricht) über das Netzwerk (HTTP oder andere) an einen Message Broker, der die Kommunikation an andere Microservices weiterleitet.
Nachrichtenübermittlung gibt es in verschiedenen Varianten, die beiden beliebtesten sind Publish-Subscribe (Pubsub)-Nachrichten und Request-Response-Nachrichten. Bei Pubsub-Modellen abonnieren Kunden ein Thema und erhalten eine Nachricht, sobald ein Publisher eine Nachricht in diesem Thema veröffentlicht. Request-Response-Modelle sind einfacher: Ein Kunde sendet eine Anfrage an einen Dienst (oder Message Broker), der daraufhin mit den gewünschten Informationen antwortet. Es gibt einige Messaging-Technologien, die eine einzigartige Mischung aus beiden Modellen darstellen, wie Apache Kafka. Celery und Redis (oder Celery mit RabbitMQ) können für das Messaging (und die Aufgabenverarbeitung) von in Python geschriebenen Microservices verwendet werden: Celery verarbeitet die Aufgaben und/oder Nachrichten mit Redis oder RabbitMQ als Broker.
Messaging birgt einige erhebliche Nachteile, die es abzumildern gilt. Messaging kann genauso skalierbar sein (wenn nicht sogar noch skalierbarer) als HTTP+REST-Lösungen, wenn es von Anfang an auf Skalierbarkeit ausgelegt ist. Messaging ist nicht so einfach zu ändern und zu aktualisieren, und seine zentrale Natur (auch wenn sie als Vorteil erscheinen mag) kann dazu führen, dass seine Warteschlangen und Broker zu Ausfallpunkten für das gesamte Ökosystem werden. Die asynchrone Natur des Messagings kann zu Wettlaufsituationen und Endlosschleifen führen, wenn man nicht darauf vorbereitet ist. Wenn ein Messaging-System mit Schutzmaßnahmen gegen diese Probleme implementiert wird, kann es genauso stabil und effizient sein wie eine synchrone Lösung.
Dienstsuche, Dienstregistrierung und Lastausgleich
In einer monolithischen Architektur muss der Datenverkehr nur zu einer Anwendung geleitet und entsprechend auf die Server verteilt werden, die die Anwendung hosten. Bei der Microservice-Architektur muss der Datenverkehr an eine große Anzahl verschiedener Anwendungen geleitet und dann entsprechend auf die Server verteilt werden, die die einzelnen Microservices hosten. Damit dies effizient und effektiv geschehen kann, müssen bei der Microservice-Architektur drei Technologien in der Kommunikationsschicht implementiert werden: Service Discovery, Service Registry und Load Balancing.
Wenn ein Microservice A eine Anfrage an einen anderen Microservice B stellen muss, muss Microservice A die IP-Adresse und den Port einer bestimmten Instanz kennen, auf der Microservice B gehostet wird. Genauer gesagt muss die Kommunikationsschicht zwischen den Microservices die IP-Adressen und Ports dieser Microservices kennen, damit die Anfragen zwischen ihnen entsprechend weitergeleitet werden können. Dies wird durch Service Discovery (z. B. etcd, Consul, Hyperbahn oder ZooKeeper) erreicht, die sicherstellt, dass Anfragen genau dorthin geleitet werden, wohin sie gesendet werden sollen, und dass sie (ganz wichtig) nur an gesunde Instanzen geleitet werden. Für die Service Discovery ist eine Service Registry erforderlich, eine Datenbank, die alle Ports und IPs aller Microservices im Ökosystem erfasst.
Dynamische Skalierung und zugewiesene Ports
In Microservice-Architekturen können sich Ports und IPs ständig ändern (und tun es auch), insbesondere wenn Microservices skaliert und neu bereitgestellt werden (vor allem mit einer Hardware-Abstraktionsschicht wie Apache Mesos). Eine Möglichkeit, die Erkennung und das Routing anzugehen, besteht darin, jedem Microservice statische Ports zuzuweisen (sowohl für das Frontend als auch für das Backend).
Wenn du nicht jeden Microservice auf nur einer Instanz hostest (was sehr unwahrscheinlich ist), brauchst du einen Lastausgleich in verschiedenen Teilen der Kommunikationsschicht des Microservice-Ökosystems. Der Lastausgleich funktioniert in etwa so: Wenn du 10 verschiedene Instanzen hast, auf denen ein Microservice gehostet wird, sorgt die Software (und/oder die Hardware) für den Lastausgleich dafür, dass der Datenverkehr auf alle Instanzen verteilt (ausgeglichen) wird. Der Lastausgleich wird an jeder Stelle im Ökosystem benötigt, an der eine Anfrage an eine Anwendung gesendet wird. Das bedeutet, dass jedes große Microservice-Ökosystem viele, viele Ebenen des Lastausgleichs enthält. Häufig verwendete Load Balancer für diesen Zweck sind Amazon Web Services Elastic Load Balancer, Netflix Eureka, HAProxy, und Nginx.
Schicht 3: Die Anwendungsplattform
Die Anwendungsplattform ist die dritte Schicht des Microservice-Ökosystems und enthält alle internen Werkzeuge und Dienste, die von den Microservices unabhängig sind. Diese Schicht besteht aus zentralisierten, ökosystemweiten Tools und Diensten, die so aufgebaut sein müssen, dass die Microservice-Entwicklungsteams außer ihren eigenen Microservices nichts entwerfen, bauen oder warten müssen.
Eine gute Anwendungsplattform verfügt über interne Self-Service-Tools für Entwickler, einen standardisierten Entwicklungsprozess, ein zentralisiertes und automatisiertes Build- und Release-System, automatisierte Tests, eine standardisierte und zentralisierte Deployment-Lösung sowie eine zentralisierte Protokollierung und Überwachung auf Microservice-Ebene. Viele Details dieser Elemente werden in späteren Kapiteln behandelt, aber wir gehen hier kurz auf einige von ihnen ein, um eine Einführung in die grundlegenden Konzepte zu geben.
Selbstbedienungswerkzeuge für die interne Entwicklung
Unter lassen sich einige Dinge als interne Self-Service-Entwicklungswerkzeuge kategorisieren. Welche Dinge in diese Kategorie fallen, hängt nicht nur von den Bedürfnissen der Entwickler ab, sondern auch vom Abstraktionsgrad und der Komplexität der Infrastruktur und des Ökosystems insgesamt. Um herauszufinden, welche Tools entwickelt werden müssen, müssen zunächst die Verantwortungsbereiche aufgeteilt und dann festgelegt werden, welche Aufgaben die Entwickler/innen erledigen können müssen, um ihre Dienste zu entwerfen, zu erstellen und zu warten.
In einem Unternehmen, das eine Microservice-Architektur eingeführt hat, müssen die Verantwortlichkeiten sorgfältig an die verschiedenen Entwicklungsteams delegiert werden. Eine einfache Möglichkeit, dies zu tun, ist die Schaffung einer technischen Unterorganisation für jede Schicht des Microservice-Ökosystems, zusammen mit anderen Teams, die jede Schicht überbrücken. Jede dieser halbwegs unabhängig arbeitenden Engineering-Organisationen ist für alles innerhalb ihrer Schicht verantwortlich: TechOps-Teams sind für Layer 1 zuständig, Infrastrukturteams für Layer 2, Anwendungsplattformteams für Layer 3 und Microservice-Teams für Layer 4 (das ist natürlich eine stark vereinfachte Darstellung, aber du verstehst schon).
Innerhalb dieses Organisationsschemas sollte jedes Mal, wenn ein Entwickler, der in einer der höheren Schichten arbeitet, etwas in einer der niedrigeren Schichten einrichten, konfigurieren oder nutzen muss, ein Self-Service-Tool zur Verfügung stehen, das der Entwickler nutzen kann. Zum Beispiel sollte das Team, das an der Nachrichtenübermittlung für das Ökosystem arbeitet, ein Self-Service-Tool entwickeln, damit ein Entwickler eines Microservice-Teams die Nachrichtenübermittlung für seinen Dienst einfach konfigurieren kann, ohne sich mit den Feinheiten des Nachrichtensystems auseinandersetzen zu müssen.
Es gibt viele Gründe dafür, diese zentralisierten Self-Service-Tools für jede Schicht einzusetzen. In einem vielfältigen Microservice-Ökosystem hat der durchschnittliche Entwickler in einem bestimmten Team keine (oder nur sehr geringe) Kenntnisse darüber, wie die Dienste und Systeme in anderen Teams funktionieren, und es gibt keine Möglichkeit, Experten für jeden Dienst und jedes System zu werden, während er an seinem eigenen arbeitet - das ist einfach nicht möglich. Jeder einzelne Entwickler wird fast nichts wissen, außer seinem eigenen Dienst, aber zusammen werden alle Entwickler, die innerhalb des Ökosystems arbeiten, alles wissen. Anstatt zu versuchen, jedem Entwickler die Feinheiten der einzelnen Tools und Dienste innerhalb des Ökosystems beizubringen, solltest du nachhaltige, einfach zu bedienende Benutzeroberflächen für jeden Teil des Ökosystems entwickeln und die Entwickler dann darin schulen, wie sie diese nutzen können. Mache alles zu einer Blackbox und dokumentiere genau, wie es funktioniert und wie man es benutzt.
Der zweite Grund, diese Tools zu entwickeln und sie gut zu bauen, ist, dass du ehrlich gesagt nicht willst, dass ein Entwickler aus einem anderen Team wesentliche Änderungen an deinem Dienst oder System vornehmen kann, vor allem nicht solche, die einen Ausfall verursachen könnten. Das gilt besonders für Dienste und Systeme, die zu den unteren Schichten gehören (Schicht 1, Schicht 2 und Schicht 3). Wenn du es Nicht-Experten erlaubst, Änderungen in diesen Schichten vorzunehmen, oder von ihnen verlangst (oder schlimmer noch: erwartest), dass sie Experten in diesen Bereichen werden, ist das ein Rezept für eine Katastrophe. Ein Beispiel dafür, wo dies furchtbar schief gehen kann, ist das Konfigurationsmanagement: Wenn Entwickler/innen in Microservice-Teams Änderungen an den Systemkonfigurationen vornehmen dürfen, ohne über das entsprechende Fachwissen zu verfügen, kann und wird dies zu großflächigen Produktionsausfällen führen, wenn eine Änderung vorgenommen wird, die nicht nur den eigenen Dienst betrifft.
Der Entwicklungszyklus
Wenn Entwickler Änderungen an bestehenden Microservices vornehmen oder neue erstellen, kann die Entwicklung effektiver gestaltet werden, indem der Entwicklungsprozess gestrafft und standardisiert wird und so viel wie möglich automatisiert wird. Die Details der Standardisierung des Prozesses für eine stabile und zuverlässige Entwicklung selbst werden in Kapitel 4, Skalierbarkeit und Leistung, behandelt, aber es gibt einige Dinge, die innerhalb der dritten Schicht eines Microservice-Ökosystems vorhanden sein müssen, damit eine stabile und zuverlässige Entwicklung möglich ist.
Die erste Voraussetzung ist ein zentrales System zur Versionskontrolle, in dem der gesamte Code gespeichert, verfolgt, versioniert und durchsucht werden kann. Dies geschieht in der Regel über ein System wie GitHub oder ein selbst gehostetes git- oder svn-Repository, das mit einem Kollaborationstool wie Phabrictor verknüpft ist und die Pflege und Überprüfung des Codes erleichtert.
Die zweite Voraussetzung ist eine stabile, effiziente Entwicklungsumgebung. Entwicklungsumgebungen sind in Microservice-Ökosystemen aufgrund der komplizierten Abhängigkeiten, die jeder Microservice von anderen Diensten hat, notorisch schwierig zu implementieren, aber sie sind absolut notwendig. Manche Unternehmen bevorzugen es, wenn die gesamte Entwicklung lokal (auf dem Laptop eines Entwicklers) stattfindet, aber das kann zu schlechten Deployments führen, weil der Entwickler dadurch kein genaues Bild davon bekommt, wie sich seine Codeänderungen in der Produktionswelt verhalten werden. Die stabilste und zuverlässigste Art, eine Entwicklungsumgebung zu gestalten, ist die Erstellung einer Spiegelung der Produktionsumgebung (die weder Staging noch Canary noch Production ist), die alle komplizierten Abhängigkeitsketten enthält.
Testen, erstellen, verpacken und freigeben
Die Test-, Build-, Paketierungs- und Freigabeschritte zwischen Entwicklung und Bereitstellung sollten so weit wie möglich standardisiert und zentralisiert werden. Nach dem Entwicklungszyklus, wenn eine Codeänderung vorgenommen wurde, sollten alle notwendigen Tests durchgeführt und neue Versionen automatisch erstellt und verpackt werden. Für genau diesen Zweck gibt es Werkzeuge für die kontinuierliche Integration, und die vorhandenen Lösungen (wie Jenkins) sind sehr fortschrittlich und einfach zu konfigurieren. Mit diesen Werkzeugen lässt sich der gesamte Prozess leicht automatisieren, sodass nur wenig Raum für menschliche Fehler bleibt.
Bereitstellungspipeline
Die Deployment-Pipeline ist der Prozess, durch den neuer Code nach dem Entwicklungszyklus und den Schritten Testen, Bauen, Verpacken und Freigeben seinen Weg zu den Produktionsservern findet. Die Bereitstellung kann in einem Microservice-Ökosystem schnell sehr kompliziert werden, denn Hunderte von Bereitstellungen pro Tag sind nichts Ungewöhnliches. Oft ist es notwendig, Werkzeuge für die Bereitstellung zu entwickeln und die Bereitstellungspraktiken für alle Entwicklungsteams zu standardisieren. Die Grundsätze für den Aufbau stabiler und zuverlässiger (produktionsreifer) Bereitstellungspipelines werden in Kapitel 3, Stabilität und Zuverlässigkeit, ausführlich behandelt.
Protokollierung und Überwachung
Alle Microservices sollten über ein Logging auf Microservice-Ebene aller an den Microservice gerichteten Anfragen (einschließlich aller relevanten und wichtigen Informationen) und deren Antworten verfügen. Aufgrund der Schnelllebigkeit der Microservice-Entwicklung ist es oft unmöglich, Fehler im Code zu reproduzieren, weil es unmöglich ist, den Zustand des Systems zum Zeitpunkt des Fehlers zu rekonstruieren. Ein gutes Logging auf Microservice-Ebene gibt Entwicklern die Informationen, die sie brauchen, um den Zustand ihres Dienstes zu einem bestimmten Zeitpunkt in der Vergangenheit oder Gegenwart vollständig zu verstehen. Die Überwachung aller wichtigen Metriken der Microservices auf Microservice-Ebene ist aus ähnlichen Gründen unverzichtbar: Eine genaue Überwachung in Echtzeit ermöglicht es den Entwicklern, jederzeit den Zustand und den Status ihres Dienstes zu kennen. Die Protokollierung und Überwachung auf Microservice-Ebene wird in Kapitel 6, Überwachung, ausführlicher behandelt .
Schicht 4: Microservices
Unter befindet sich die oberste Schicht des Microservice-Ökosystems, die Microservice-Schicht(Schicht 4). In dieser Schicht leben die Microservices - und alles, was mit ihnen zu tun hat - völlig abstrahiert von den unteren Infrastrukturschichten. Hier sind sie abstrahiert von der Hardware, von der Bereitstellung, von der Service-Erkennung, vom Lastausgleich und von der Kommunikation. Die einzigen Dinge, die nicht von der Microservice-Schicht abstrahiert sind, sind die Konfigurationen, die für jeden Dienst spezifisch sind, um die Tools zu nutzen.
In der Softwareentwicklung ist es üblich, alle Anwendungskonfigurationen zu zentralisieren, sodass die Konfigurationen für ein bestimmtes Werkzeug oder eine Reihe von Werkzeugen (z. B. für das Konfigurationsmanagement, die Ressourcenisolierung oder die Bereitstellung) alle im Werkzeug selbst gespeichert werden. So werden z. B. benutzerdefinierte Bereitstellungskonfigurationen für Anwendungen oft nicht mit dem Anwendungscode, sondern mit dem Code des Bereitstellungstools gespeichert. In sehr großen Microservice-Ökosystemen mit Hunderten von Microservices und Dutzenden von internen Tools (jedes mit seinen eigenen benutzerdefinierten Konfigurationen) wird diese Praxis jedoch ziemlich chaotisch: Entwickler in Microservice-Teams müssen Änderungen an den Codebases der Tools in den darunter liegenden Schichten vornehmen und vergessen dabei oft, wo bestimmte Konfigurationen gespeichert sind (oder dass sie überhaupt existieren). Um dieses Problem zu entschärfen, können alle Microservice-spezifischen Konfigurationen im Repository des Microservices gespeichert werden und sollten dort von den Tools und Systemen der darunter liegenden Schichten zugänglich sein.
Organisatorische Herausforderungen
Die Einführung der Microservice-Architektur löst die drängendsten Probleme der monolithischen Anwendungsarchitektur. Microservices haben nicht die gleichen Probleme mit der Skalierbarkeit, der mangelnden Effizienz oder den Schwierigkeiten bei der Einführung neuer Technologien: Sie sind auf Skalierbarkeit, Effizienz und Entwicklungsgeschwindigkeit optimiert. In einer Branche, in der neue Technologien schnell auf den Markt kommen, sind die reinen Organisationskosten für die Wartung und Verbesserung einer schwerfälligen monolithischen Anwendung einfach nicht praktikabel. Vor diesem Hintergrund ist es schwer vorstellbar, warum jemand zögern sollte, einen Monolithen in Microservices aufzuteilen und ein Microservice-Ökosystem von Grund auf aufzubauen.
Microservices scheinen eine magische (und ziemlich offensichtliche) Lösung zu sein, aber wir wissen es besser als das. In seinem Buch The Mythical Man-Month hat Frederick Brooks erklärt, warum es in der Softwareentwicklung keine Patentrezepte gibt, und diese Idee wie folgt zusammengefasst: "Es gibt keine einzige Entwicklung, weder in der Technologie noch in der Managementtechnik, die für sich genommen innerhalb eines Jahrzehnts auch nur eine Verbesserung um eine Größenordnung in der Produktivität, in der Zuverlässigkeit oder in der Einfachheit verspricht."
Wenn wir mit Technologien konfrontiert werden, die uns drastische Verbesserungen versprechen, müssen wir nach den Kompromissen suchen. Microservices versprechen eine bessere Skalierbarkeit und mehr Effizienz, aber wir wissen, dass dies zu Lasten eines Teils des Gesamtsystems gehen wird.
Es gibt vier besonders wichtige Kompromisse, die mit der Microservice-Architektur einhergehen. Der erste ist die Veränderung der Organisationsstruktur, die zu Isolation und schlechter teamübergreifender Kommunikation führt - eine Folge der Umkehrung des Conway'schen Gesetzes. Der zweite ist die dramatische Zunahme der technischen Zersplitterung, die nicht nur für das gesamte Unternehmen außerordentlich kostspielig ist, sondern auch für jeden einzelnen Ingenieur erhebliche Kosten verursacht. Der dritte Kompromiss ist die erhöhte Wahrscheinlichkeit, dass das System fehlschlägt. Der vierte ist der Wettbewerb um technische und infrastrukturelle Ressourcen.
Das umgekehrte Conwaysche Gesetz
Der Gedanke hinter dem Conway's Law (benannt nach dem Programmierer Melvin Conway im Jahr 1968) ist folgender: Die Architektur eines Systems wird durch die Kommunikations- und Organisationsstrukturen des Unternehmens bestimmt. Die Umkehrung des Conway'schen Gesetzes (wir nennen es das umgekehrte Conway'sche Gesetz) ist ebenfalls gültig und besonders relevant für das Microservice-Ökosystem: Die Organisationsstruktur eines Unternehmens wird durch die Architektur seines Produkts bestimmt. Mehr als 40 Jahre nach der Einführung des Conway'schen Gesetzes scheinen sowohl das Gesetz als auch seine Umkehrung immer noch zu gelten. Die Organisationsstruktur von Microsoft sieht, wenn man sie wie die Architektur eines Systems skizziert, der Architektur seiner Produkte erstaunlich ähnlich - das Gleiche gilt für Google, für Amazon und für jedes andere große Technologieunternehmen. Unternehmen, die eine Microservice-Architektur einführen, werden nie eine Ausnahme von dieser Regel sein.
Die Microservice-Architektur besteht aus einer großen Anzahl kleiner, isolierter und unabhängiger Microservices. Das umgekehrte Conway'sche Gesetz besagt, dass die Organisationsstruktur eines Unternehmens, das eine Microservice-Architektur einsetzt, aus einer großen Anzahl sehr kleiner, isolierter und unabhängiger Teams besteht. Die Teamstrukturen, die sich daraus ergeben, führen unweigerlich zu Siloing und Zersplitterung, Probleme, die sich noch verschärfen, wenn das Microservice-Ökosystem immer ausgefeilter, komplexer, gleichzeitiger und effizienter wird.
Das umgekehrte Conway'sche Gesetz bedeutet auch, dass Entwickler in gewisser Weise wie Microservices sind: Sie können eine Sache tun und (hoffentlich) diese eine Sache sehr gut, aber sie sind (in Bezug auf Verantwortung, Fachwissen und Erfahrung) vom Rest des Ökosystems isoliert. Zusammengenommen wissen alle Entwickler, die in einem Microservice-Ökosystem arbeiten, alles, was es darüber zu wissen gibt, aber jeder einzelne ist extrem spezialisiert und kennt nur die Teile des Ökosystems, für die er verantwortlich ist.
Daraus ergibt sich ein unvermeidliches organisatorisches Problem: Obwohl Microservices isoliert entwickelt werden müssen (was zu isolierten, siloartigen Teams führt), leben sie nicht in Isolation und müssen nahtlos miteinander interagieren, wenn das Gesamtprodukt überhaupt funktionieren soll. Dies erfordert, dass diese isolierten, unabhängig voneinander arbeitenden Teams eng und häufig zusammenarbeiten - was schwierig zu bewerkstelligen ist, da die Ziele und Projekte der meisten Teams (die in den Teamzielen und Schlüsselergebnissen (OKRs) festgelegt sind) spezifisch für einen bestimmten Microservice sind, an dem sie arbeiten.
Es gibt auch eine große Kommunikationslücke zwischen Microservice-Teams und Infrastrukturteams, die geschlossen werden muss. Anwendungsplattform-Teams müssen zum Beispiel Plattformdienste und -tools entwickeln, die von allen Microservice-Teams genutzt werden, aber es kann Monate (oder sogar Jahre) dauern, bis die Anforderungen und Bedürfnisse von Hunderten von Microservice-Teams bekannt sind, bevor ein kleines Projekt gebaut wird. Es ist keine leichte Aufgabe, Entwickler und Infrastrukturteams zur Zusammenarbeit zu bewegen.
Dank des umgekehrten Conway'schen Gesetzes ergibt sich ein weiteres Problem, das in Unternehmen mit monolithischer Architektur nur selten vorkommt: die Schwierigkeit, eine Betriebsorganisation zu betreiben. Bei einer monolithischen Architektur kann eine Betriebsorganisation leicht besetzt werden und für die Anwendung auf Abruf bereitstehen, aber bei einer Microservice-Architektur ist dies sehr schwer zu erreichen, da jeder einzelne Microservice sowohl von einem Entwicklungsteam als auch von einem Betriebsteam betreut werden müsste. Folglich müssen die Microservice-Entwicklungsteams für die betrieblichen Pflichten und Aufgaben im Zusammenhang mit ihrem Microservice verantwortlich sein. Es gibt keine separate Ops-Organisation, die den Bereitschaftsdienst übernimmt, keine separate Ops-Organisation, die für die Überwachung zuständig ist: Die Entwickler müssen für ihre Dienste auf Abruf bereitstehen .
Technische Zersiedelung
Der zweite Kompromiss, die technische Ausbreitung, hängt mit dem ersten zusammen. Während das Conway'sche Gesetz und seine Umkehrung die organisatorische Zersplitterung und das Siloing für Microservices vorhersagen, ist eine zweite Art der Zersplitterung (in Bezug auf Technologien, Tools und dergleichen) in der Microservice-Architektur ebenfalls unvermeidlich. Es gibt viele verschiedene Arten, wie sich technische Zersplitterung äußern kann. Wir gehen hier auf einige der häufigsten Arten ein.
Wenn wir uns ein großes Microservice-Ökosystem mit 1.000 Microservices vorstellen, wird schnell klar, warum die Microservice-Architektur zu technischer Zersplitterung führt. Nehmen wir an, jeder dieser Microservices wird von einem Entwicklungsteam aus sechs Entwicklern betreut, und jeder Entwickler verwendet seine eigenen Lieblingstools, Lieblingsbibliotheken und arbeitet in seiner Lieblingssprache. Jedes dieser Entwicklungsteams hat seine eigene Art des Deployments, seine eigenen Metriken zur Überwachung und Alarmierung, seine eigenen externen Bibliotheken und internen Abhängigkeiten, die es verwendet, eigene Skripte, die es auf den Produktionsmaschinen ausführt, und so weiter.
Wenn du tausend dieser Teams hast, bedeutet das, dass es innerhalb eines Systems tausend Möglichkeiten gibt, eine Sache zu tun. Es gibt tausend Möglichkeiten der Bereitstellung, tausend Bibliotheken, die gewartet werden müssen, tausend verschiedene Arten der Alarmierung und Überwachung, des Testens und des Umgangs mit Ausfällen. Die einzige Möglichkeit, den technischen Wildwuchs zu reduzieren, ist die Standardisierung auf jeder Ebene des Microservice-Ökosystems.
Es gibt noch eine andere Art von technischer Unübersichtlichkeit, die mit der Sprachwahl verbunden ist. Microservices werden mit dem Versprechen größerer Freiheit für die Entwicklerinnen und Entwickler in Verbindung gebracht, die Sprachen und Bibliotheken nach Belieben zu wählen. Das ist im Prinzip möglich und kann in der Praxis auch stimmen, aber wenn ein Microservice-Ökosystem wächst, wird es oft unpraktisch, teuer und gefährlich. Um zu verstehen, warum dies zu einem Problem werden kann, betrachte das folgende Szenario. Nehmen wir an, wir haben ein Microservice-Ökosystem mit 200 Diensten und stellen uns vor, dass einige dieser Microservices in Python, andere in JavaScript, einige in Haskell, ein paar in Go und einige weitere in Ruby, Java und C++ geschrieben sind. Für jedes interne Tool, für jedes System und jeden Dienst in jeder Schicht des Ökosystems müssen Bibliotheken für jede dieser Sprachen geschrieben werden.
Denk einmal über den enormen Wartungs- und Entwicklungsaufwand nach, der nötig ist, um jede Sprache so zu unterstützen, wie sie benötigt wird: Das ist außergewöhnlich, und nur sehr wenige Entwicklungsunternehmen könnten es sich leisten, die dafür notwendigen technischen Ressourcen einzusetzen. Es ist realistischer, eine kleine Anzahl von unterstützten Sprachen auszuwählen und sicherzustellen, dass alle Bibliotheken und Werkzeuge mit diesen Sprachen kompatibel sind und für diese existieren, als zu versuchen, eine große Anzahl von Sprachen zu unterstützen.
Die letzte Art der technischen Auswüchse, die wir hier behandeln, ist die technische Schuld, die sich in der Regel auf Arbeit bezieht, die erledigt werden muss, weil etwas auf eine Art und Weise implementiert wurde, die die Aufgabe zwar schnell, aber nicht auf die beste oder optimalste Weise erledigt hat. Da Microservice-Entwicklungsteams neue Funktionen in einem rasanten Tempo entwickeln können, bauen sich technische Schulden oft still und leise im Hintergrund auf. Wenn es zu Ausfällen kommt, wenn Dinge kaputt gehen, ist die Arbeit, die aus einem Incident Review hervorgeht, nur selten die beste Gesamtlösung: Für die Microservice-Entwicklungsteams war das, was das Problem schnell und im Moment behebt (oder beheben konnte), gut genug, und bessere Lösungen werden auf die Zukunft verschoben .
Mehr Wege zum Fehlschlagen
Microservices sind große, komplexe, verteilte Systeme mit vielen kleinen, unabhängigen Teilen, die sich ständig verändern. Die Realität bei der Arbeit mit komplexen Systemen dieser Art ist, dass einzelne Komponenten fehlschlagen werden, und zwar häufig und auf eine Weise, die niemand vorhersehen konnte. Hier kommt der dritte Kompromiss ins Spiel: Mit der Microservice-Architektur gibt es mehr Möglichkeiten, wie dein System fehlschlagen kann.
Es gibt Möglichkeiten, sich auf Ausfälle vorzubereiten, Ausfälle abzumildern und die Grenzen sowohl der einzelnen Komponenten als auch des gesamten Ökosystems zu testen (siehe Kapitel 5, Fehlertoleranz und Katastrophenvorsorge). Es ist jedoch wichtig zu verstehen, dass du, egal wie viele Ausfallsicherheitstests du durchführst, egal wie viele Ausfälle und Katastrophenszenarien du durchgespielt hast, der Tatsache nicht entgehen kannst, dass das System fehlschlagen wird. Du kannst nur dein Bestes tun, um dich auf diesen Fall vorzubereiten.
Wettbewerb um Ressourcen
Nur wie in jedem anderen Ökosystem in der Natur herrscht auch im Microservice-Ökosystem ein harter Wettbewerb um Ressourcen. Jede technische Organisation verfügt über begrenzte Ressourcen: Sie hat begrenzte technische Ressourcen (Teams, Entwickler) und begrenzte Hardware- und Infrastrukturressourcen (physische Maschinen, Cloud-Hardware, Speicherung von Datenbanken usw.), und jede Ressource kostet das Unternehmen viel Geld.
Wenn dein Microservice-Ökosystem aus einer großen Anzahl von Microservices und einer großen und anspruchsvollen Anwendungsplattform besteht, ist der Wettbewerb zwischen den Teams um Hardware- und Infrastruktur-Ressourcen unvermeidlich: Jeder Service, jedes Tool wird als gleich wichtig dargestellt, sein Skalierungsbedarf wird als höchste Priorität dargestellt.
Wenn die Teams der Anwendungsplattformen von den Microservice-Teams Spezifikationen und Bedürfnisse erfragen, damit sie ihre Systeme und Tools entsprechend gestalten können, wird jedes Microservice-Entwicklungsteam argumentieren, dass seine Bedürfnisse am wichtigsten sind, und wird enttäuscht (und möglicherweise sehr frustriert) sein, wenn sie nicht berücksichtigt werden. Diese Art des Wettbewerbs um technische Ressourcen kann zu Unmut zwischen den Teams führen.
Die letzte Art des Wettbewerbs um Ressourcen ist vielleicht die offensichtlichste: der Wettbewerb zwischen Managern, zwischen Teams und zwischen verschiedenen technischen Abteilungen/Organisationen um technische Mitarbeiter. Trotz der steigenden Zahl von Informatikabsolventen und der Zunahme von Entwickler-Bootcamps sind wirklich gute Entwickler schwer zu finden und stellen eine der unersetzlichsten und knappsten Ressourcen dar. Wenn es Hunderte oder Tausende von Teams gibt, die ein oder zwei zusätzliche Ingenieure gebrauchen könnten, wird jedes einzelne Team darauf bestehen, dass sein Team einen zusätzlichen Ingenieur mehr braucht als alle anderen Teams.
Es gibt keine Möglichkeit, den Wettbewerb um Ressourcen zu vermeiden, aber es gibt Möglichkeiten, ihn etwas abzuschwächen. Am effektivsten scheint es zu sein, Teams nach ihrer Bedeutung und Wichtigkeit für das Gesamtunternehmen zu organisieren oder zu kategorisieren und ihnen dann entsprechend ihrer Priorität oder Wichtigkeit Zugang zu Ressourcen zu geben. Das hat allerdings auch Nachteile, denn es führt dazu, dass die Teams für die Entwicklung von Werkzeugen schlecht besetzt sind und Projekte, die für die Gestaltung der Zukunft wichtig sind (z. B. die Einführung neuer Infrastrukturtechnologien) , aufgegeben werden.
Get Produktionsfähige Microservices now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

