Capítulo 1. Hola Transformers
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En 2017, investigadores de Google publicaron un artículo en el que proponían una novedosa arquitectura de red neuronal para el modelado de secuencias.1 Denominada Transformer, esta arquitectura superó a las redes neuronales recurrentes (RNN) en tareas de traducción automática, tanto en calidad de traducción como en coste de entrenamiento.
Paralelamente, un método eficaz de aprendizaje por transferencia llamado ULMFiT demostró que el entrenamiento de redes de memoria a corto plazo (LSTM) en un corpus muy grande y diverso podía producir clasificadores de texto de última generación con pocos datos etiquetados.2
Estos avances fueron los catalizadores de dos de los transformadores actuales más conocidos: el Transformador Preentrenado Generativo (GPT)3 y las Representaciones Codificadoras Bidireccionales de Transformadores (BERT).4 Al combinar la arquitectura del Transformador con el aprendizaje no supervisado, estos modelos eliminaron la necesidad de entrenar arquitecturas específicas de tareas desde cero y superaron casi todos los puntos de referencia de la PNL por un margen significativo. Desde el lanzamiento de GPT y BERT, ha surgido un zoo de modelos de transformadores; en laFigura 1-1 se muestra una cronología de las entradas más destacadas.
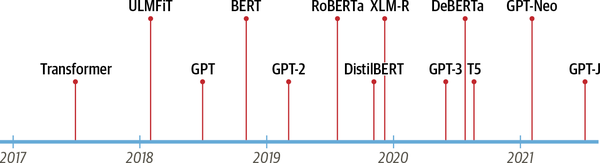
Figura 1-1. La línea de tiempo de los transformadores
Pero nos estamos adelantando. Para entender qué tienen de novedoso los transformadores, primero tenemos que explicarlo:
-
El marco codificador-decodificador
-
Mecanismos de atención
-
Aprendizaje por transferencia
En este capítulo presentaremos los conceptos básicos que subyacen a la omnipresencia de los transformadores, haremos un recorrido por algunas de las tareas en las que destacan y concluiremos con un vistazo al ecosistema de herramientas y bibliotecas de Hugging Face.
Empecemos explorando el marco codificador-decodificador y las arquitecturas que precedieron al surgimiento de los transformadores.
El marco codificador-decodificador
Antes de los transformadores, las arquitecturas recurrentes como las LSTM eran el estado del arte en PNL. Estas arquitecturas contienen un bucle de retroalimentación en las conexiones de la red que permite que la información se propague de un paso a otro, lo que las hace ideales para modelar datos secuenciales como el texto. Como se ilustra en la parte izquierda de la Figura 1-2, una RNN recibe una entrada (que puede ser una palabra o un carácter), la hace pasar por la red y emite un vector llamado estado oculto. Al mismo tiempo, el modelo se devuelve a sí mismo cierta información a través del bucle de realimentación, que puede utilizar en el paso siguiente. Esto puede verse más claramente si "desenrollamos" el bucle como se muestra en la parte derecha dela Figura 1-2: la RNN pasa información sobre su estado en cada paso a la siguiente operación de la secuencia. Esto permite a una RNN mantener un registro de la información de los pasos anteriores, y utilizarla para sus predicciones de salida.
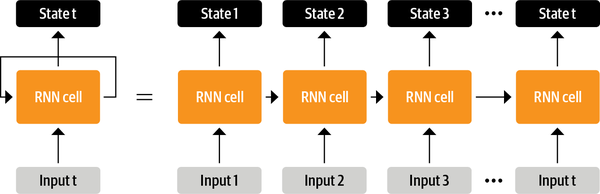
Figura 1-2. Desenrollar una RNN en el tiempo
Estas arquitecturas se utilizaron (y se siguen utilizando) ampliamente para tareas de PNL, procesamiento del habla y series temporales. Puedes encontrar una magnífica exposición de sus capacidades en la entrada del blog de Andrej Karpathy,"La irrazonable eficacia de las redes neuronales recurrentes".
Un área en la que las RNN desempeñaron un papel importante fue en el desarrollo de sistemas de traducción automática, en los que el objetivo es mapear una secuencia de palabras de un idioma a otro. Este tipo de tarea suele abordarse con una arquitectura codificador-decodificador o secuencia-a-secuencia,5 que se adapta bien a situaciones en las que tanto la entrada como la salida son secuencias de longitud arbitraria. La tarea del codificador consiste en codificar la información de la secuencia de entrada en una representación numérica que suele denominarse último estado oculto. Este estado se pasa luego al decodificador, que genera la secuencia de salida.
En general, los componentes codificador y decodificador pueden ser cualquier tipo de arquitectura de red neuronal que pueda modelar secuencias. Esto se ilustra para un par de RNN en la Figura 1-3, donde la frase en inglés "Transformers are great!" se codifica como un vector de estado oculto que luego se decodifica para producir la traducción al alemán "Transformer sind grossartig!" Las palabras de entrada pasan secuencialmente por el codificador y las palabras de salida se generan de una en una, de arriba abajo.

Figura 1-3. Una arquitectura codificador-decodificador con un par de RNN (en general, hay muchas más capas recurrentes que las que se muestran aquí)
Aunque es elegante en su simplicidad, un punto débil de esta arquitectura es que el estado oculto final del codificador crea un cuello de botella de información: tiene que representar el significado de toda la secuencia de entrada porque esto es todo a lo que tiene acceso el decodificador cuando genera la salida. Esto es especialmente difícil en el caso de las secuencias largas, en las que la información del principio de la secuencia puede perderse en el proceso de comprimirlo todo en una única representación fija.
Afortunadamente, hay una forma de salir de este cuello de botella permitiendo que el descodificador tenga acceso a todos los estados ocultos del codificador. El mecanismo general para ello se llamaatención6 y es un componente clave en muchas arquitecturas modernas de redes neuronales. Comprender cómo se desarrolló la atención para las RNN nos pondrá en buena forma para entender uno de los principales bloques de construcción de la arquitectura Transformer. Echemos un vistazo más profundo.
Mecanismos de atención
La idea principal de la atención es que, en lugar de producir un único estado oculto para la secuencia de entrada, el codificador emite un estado oculto en cada paso al que puede acceder el decodificador. Sin embargo, utilizar todos los estados al mismo tiempo crearía una entrada enorme para el descodificador, por lo que se necesita algún mecanismo para priorizar qué estados utilizar. Aquí es donde entra en juego la atención: permite al descodificador asignar una cantidad diferente de peso, o "atención", a cada uno de los estados del codificador en cada paso de tiempo de descodificación. Este proceso se ilustra enla Figura 1-4, donde se muestra el papel de la atención para predecir el tercer token de la secuencia de salida.
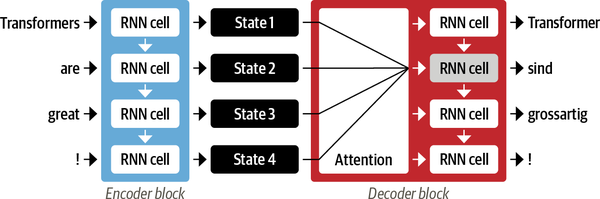
Figura 1-4. Una arquitectura codificador-decodificador con un mecanismo de atención para un par de RNNs
Al centrarse en qué tokens de entrada son más relevantes en cada paso temporal, estos modelos basados en la atención son capaces de aprender alineaciones no triviales entre las palabras de una traducción generada y las de una frase fuente. Por ejemplo, la Figura 1-5 visualiza los pesos de la atención para un modelo de traducción del inglés al francés, donde cada píxel denota un peso. La figura muestra cómo el descodificador es capaz de alinear correctamente las palabras "zona" y "Área", que están ordenadas de forma diferente en los dos idiomas.

Figura 1-5. Alineación RNN codificador-decodificador de palabras en inglés y la traducción generada en francés (cortesía de Dzmitry Bahdanau).
Aunque la atención permitió producir traducciones mucho mejores, el uso de modelos recurrentes para el codificador y el descodificador seguía teniendo un gran inconveniente: los cálculos son intrínsecamente secuenciales y no pueden paralelizarse a lo largo de la secuencia de entrada.
Con el transformador, se introdujo un nuevo paradigma de modelado: prescindir por completo de la recurrencia y, en su lugar, confiar por completo en una forma especial de atención llamada autoatención. Trataremos la autoatención con más detalle en el Capítulo 3, pero la idea básica es permitir que la atención opere sobre todos los estados de lamisma capa de la red neuronal. Esto se muestra enla Figura 1-6, donde tanto el codificador como el decodificador tienen sus propios mecanismos de autoatención, cuyas salidas se alimentan a redes neuronales feed-forward (NN FF). Esta arquitectura se puede entrenar mucho más rápido que los modelos recurrentes y allanó el camino para muchos de los avances recientes en PNL.
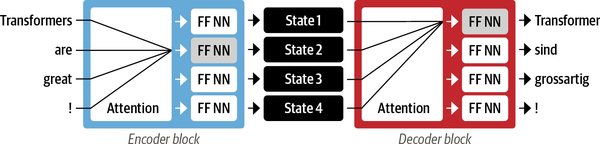
Figura 1-6. Arquitectura codificador-decodificador del Transformer original
En el artículo original sobre Transformer, el modelo de traducción se entrenaba desde cero en un gran corpus de pares de frases en varios idiomas. Sin embargo, en muchas aplicaciones prácticas de la PNL no tenemos acceso a grandes cantidades de datos de texto etiquetados en los que entrenar nuestros modelos. Faltaba una última pieza para poner en marcha la revolución de los transformadores: el aprendizaje por transferencia.
Aprendizaje por transferencia en PNL
Hoy en día es práctica común en visión por ordenador utilizar el aprendizaje por transferencia para entrenar una red neuronal convolucional como ResNet en una tarea, y luego adaptarla o afinarla en una nueva tarea. Arquitectónicamente, esto implica dividir el modelo en un cuerpo y una cabeza, donde la cabeza es una red específica de la tarea. Durante el entrenamiento, los pesos del cuerpo aprenden características generales del dominio de origen, y estos pesos se utilizan para inicializar un nuevo modelo para la nueva tarea.7 En comparación con el aprendizaje supervisado tradicional, este enfoque suele producir modelos de alta calidad que pueden entrenarse de forma mucho más eficaz en una variedad de tareas posteriores, y con muchos menos datos etiquetados. Enla Figura 1-7 se muestra una comparación de los dos enfoques.
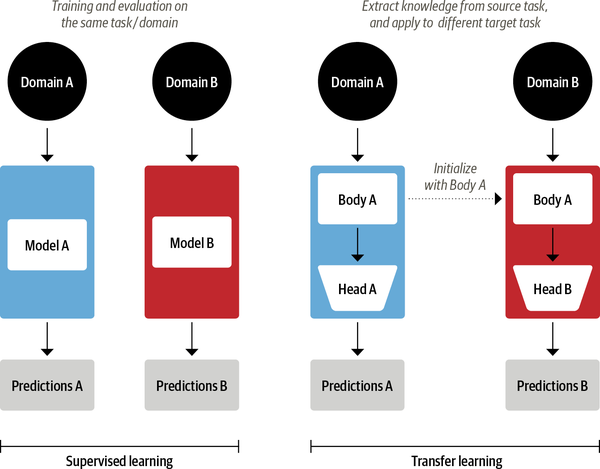
Figura 1-7. Comparación del aprendizaje supervisado tradicional (izquierda) y el aprendizaje por transferencia (derecha)
En visión por ordenador, los modelos se entrenan primero en conjuntos de datos a gran escala, como ImageNet, que contienen millones de imágenes. Este proceso se denomina preentrenamiento y su objetivo principal es enseñar a los modelos las características básicas de las imágenes, como los perímetros o los colores. A continuación, estos modelos preentrenados se pueden ajustar en una tarea posterior, como clasificar especies de flores con un número relativamente pequeño de ejemplos etiquetados (normalmente unos cientos por clase). Los modelos ajustados suelen alcanzar una precisión mayor que los modelos supervisados entrenados desde cero con la misma cantidad de datos etiquetados.
Aunque el aprendizaje por transferencia se convirtió en el enfoque estándar de la visión por ordenador, durante muchos años no estuvo claro cuál era el proceso de preentrenamiento análogo para la PNL. Como resultado, las aplicaciones de PNL solían requerir grandes cantidades de datos etiquetados para lograr un alto rendimiento. E incluso entonces, ese rendimiento no era comparable al que se conseguía en el ámbito de la visión.
En 2017 y 2018, varios grupos de investigación propusieron nuevos enfoques que finalmente hicieron que el aprendizaje por transferencia funcionara para la PNL. Empezó con una idea de los investigadores de OpenAI, que obtuvieron un gran rendimiento en una tarea de clasificación de sentimientos utilizando características extraídas de un preentrenamiento no supervisado.8 Le siguió ULMFiT, que introdujo un marco general para adaptar modelos LSTM preentrenados a diversas tareas.9
Como se ilustra en la Figura 1-8, ULMFiT implica tres pasos principales:
- Formación previa
-
El objetivo inicial del entrenamiento es bastante sencillo: predecir la siguiente palabra basándose en las palabras anteriores. Esta tarea se denomina modelado del lenguaje. La elegancia de este enfoque reside en que no se necesitan datos etiquetados, y se puede hacer uso de texto abundantemente disponible de fuentes como Wikipedia.10
- Adaptación del dominio
-
Una vez que el modelo lingüístico está preentrenado en un corpus a gran escala, el siguiente paso es adaptarlo al corpus del dominio (por ejemplo, de Wikipedia al corpus IMDb de críticas de películas, como enla Figura 1-8). En esta etapa se sigue utilizando el modelado del lenguaje, pero ahora el modelo tiene que predecir la siguiente palabra en el corpus de destino.
- Ajuste fino
-
En este paso, el modelo lingüístico se afina con una capa de clasificación para la tarea objetivo (por ejemplo, clasificar el sentimiento de las críticas de películas en la Figura 1-8).
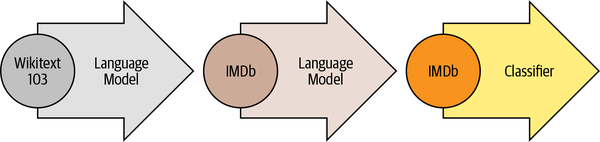
Figura 1-8. El proceso ULMFiT (cortesía de Jeremy Howard)
Al introducir un marco viable para el preentrenamiento y el aprendizaje por transferencia en PNL, ULMFiT proporcionó la pieza que faltaba para que los transformadores despegaran. En 2018, se lanzaron dos transformadores que combinaban la autoatención con el aprendizaje por transferencia:
- GPT
-
Utiliza sólo la parte descodificadora de la arquitectura Transformer, y el mismo enfoque de modelado del lenguaje que ULMFiT. GPT se preentrenó en el BookCorpus11 que consta de 7.000 libros inéditos de diversos géneros, como Aventura, Fantasía y Romance.
- BERT
-
Utiliza la parte codificadora de la arquitectura Transformer, y una forma especial de modelado del lenguaje llamada modelado del lenguaje enmascarado. El objetivo del modelado del lenguaje enmascarado es predecir palabras enmascaradas al azar en un texto. Por ejemplo, dada una frase como "Miré mi
[MASK]y vi que[MASK]llegaba tarde", el modelo tiene que predecir los candidatos más probables para las palabras enmascaradas que se denotan con[MASK]. BERT se entrenó previamente con el BookCorpus yla Wikipedia en inglés.
GPT y BERT establecieron un nuevo estado de la técnica en diversos puntos de referencia de la PNL e inauguraron la era de los transformadores.
Sin embargo, como diferentes laboratorios de investigación publicaban sus modelos en marcos incompatibles (PyTorch o TensorFlow), no siempre era fácil para los profesionales de la PNL portar estos modelos a sus propias aplicaciones. Con el lanzamiento de  Transformers, se construyó progresivamente una API unificada para más de 50 arquitecturas. Esta biblioteca catalizó la explosión de la investigación sobre transformadores y rápidamente llegó a los profesionales de la PNL, facilitando hoy la integración de estos modelos en muchas aplicaciones de la vida real. ¡Echemos un vistazo!
Transformers, se construyó progresivamente una API unificada para más de 50 arquitecturas. Esta biblioteca catalizó la explosión de la investigación sobre transformadores y rápidamente llegó a los profesionales de la PNL, facilitando hoy la integración de estos modelos en muchas aplicaciones de la vida real. ¡Echemos un vistazo!
Transformadores de Caras Abrazadas: Salvando las distancias
Aplicar una arquitectura novedosa de aprendizaje automático a una nueva tarea puede ser una empresa compleja, y suele implicar los siguientes pasos:
-
Implementar la arquitectura del modelo en código, normalmente basado en PyTorch oTensorFlow.
-
Carga los pesos preentrenados (si están disponibles) desde un servidor.
-
Preprocesa las entradas, pásalas por el modelo y aplica algún postprocesamiento específico de la tarea.
-
Implementa cargadores de datos y define funciones de pérdida y optimizadores para entrenar el modelo.
Cada uno de estos pasos requiere una lógica personalizada para cada modelo y tarea. Tradicionalmente (¡pero no siempre!), cuando los grupos de investigación publican un nuevo artículo, también liberan el código junto con los pesos del modelo. Sin embargo, este código rara vez está estandarizado y a menudo requiere días de ingeniería para adaptarlo a nuevos casos de uso.
Aquí es donde Transformers viene al rescate del profesional de la PNL. Proporciona una interfaz estandarizada para una amplia gama de modelos de transformadores, así como código y herramientas para adaptar estos modelos a nuevos casos de uso. Actualmente, la biblioteca es compatible con los tres principales marcos de aprendizaje profundo (PyTorch, TensorFlow y JAX) y te permite cambiar fácilmente entre ellos. Además, proporciona cabezales específicos para cada tarea, de modo que puedes afinar fácilmente los transformadores en tareas posteriores como la clasificación de textos, el reconocimiento de entidades con nombre y la respuesta a preguntas. Esto reduce el tiempo que tarda un profesional en entrenar y probar un puñado de modelos, ¡de una semana a una sola tarde!
Lo comprobarás por ti mismo en la siguiente sección, donde mostraremos que, con sólo unas pocas líneas de código, se pueden aplicar los Transformadores para abordar algunas de las aplicaciones PNL más comunes que es probable que encuentres en la naturaleza.
Un recorrido por las aplicaciones de los transformadores
Cada tarea de PNL comienza con un fragmento de texto, como la siguiente opinión inventada de un cliente sobre un determinado pedido online:
text="""Dear Amazon, last week I ordered an Optimus Prime action figurefrom your online store in Germany. Unfortunately, when I opened the package,I discovered to my horror that I had been sent an action figure of Megatroninstead! As a lifelong enemy of the Decepticons, I hope you can understand mydilemma. To resolve the issue, I demand an exchange of Megatron for theOptimus Prime figure I ordered. Enclosed are copies of my records concerningthis purchase. I expect to hear from you soon. Sincerely, Bumblebee."""
Dependiendo de tu aplicación, el texto con el que trabajas podría ser un contrato legal, la descripción de un producto o algo totalmente distinto. En el caso de la opinión de un cliente, probablemente te gustaría saber si la opinión es positiva o negativa. Esta tarea se denominaanálisis de sentimiento y forma parte del tema más amplio de la clasificación de textos que exploraremos enel Capítulo 2. De momento, veamos qué se necesita para extraer el sentimiento de nuestro texto utilizando los Transformadores .
Clasificación del texto
Como veremos en capítulos posteriores, Transformers tiene una API en capas que te permite interactuar con la biblioteca en varios niveles de abstracción. En este capítulo empezaremos con las canalizaciones, que abstraen todos los pasos necesarios para convertir texto sin procesar en un conjunto de predicciones a partir de un modelo afinado.
En Transformadores, instanciamos un pipeline llamando a la función pipeline() y proporcionando el nombre de la tarea que nos interesa:
fromtransformersimportpipelineclassifier=pipeline("text-classification")
La primera vez que ejecutes este código, verás que aparecen algunas barras de progreso porque la canalización descarga automáticamente los pesos del modelo desde el Hub Cara Abrazada. La segunda vez que instales el proceso, la biblioteca se dará cuenta de que ya has descargado los pesos y utilizará la versión en caché. Por defecto, el canal text-classification utiliza un modelo diseñado para el análisis de sentimientos, pero también admite la clasificación multiclase y multietiqueta.
Ahora que tenemos nuestra canalización, ¡vamos a generar algunas predicciones! Cada canalización toma una cadena de texto (o una lista de cadenas) como entrada y devuelve una lista de predicciones. Cada predicción es un diccionario Python, por lo que podemos utilizar Pandas para mostrarlas de forma agradable enDataFrame:
importpandasaspdoutputs=classifier(text)pd.DataFrame(outputs)
| etiqueta | puntuación | |
|---|---|---|
| 0 | NEGATIVO | 0.901546 |
En este caso, el modelo está muy seguro de que el texto tiene un sentimiento negativo, ¡lo que tiene sentido si tenemos en cuenta que se trata de una queja de un cliente enfadado! Ten en cuenta que, para las tareas de análisis del sentimiento, la canalización sólo devuelve una de las etiquetas POSITIVE o NEGATIVE, ya que la otra puede deducirse calculando 1-score.
Veamos ahora otra tarea habitual, la identificación de entidades con nombre en un texto.
Reconocimiento de Entidades Nombradas
Predecir el sentimiento de la opinión de un cliente es un buen primer paso, pero a menudo quieres saber si la opinión se refería a un artículo o servicio concreto. En PLN, los objetos del mundo real, como productos, lugares y personas, se denominan entidadescon nombre, y extraerlos del texto se denominareconocimiento de entidades con nombre (NER ). Podemos aplicar el NER cargando la canalización correspondiente e introduciendo en ella la opinión de nuestro cliente:
ner_tagger=pipeline("ner",aggregation_strategy="simple")outputs=ner_tagger(text)pd.DataFrame(outputs)
| grupo_entidad | puntuación | palabra | empieza | fin | |
|---|---|---|---|---|---|
| 0 | ORG | 0.879010 | Amazon | 5 | 11 |
| 1 | MISC | 0.990859 | Optimus Prime | 36 | 49 |
| 2 | LOC | 0.999755 | Alemania | 90 | 97 |
| 3 | MISC | 0.556569 | Mega | 208 | 212 |
| 4 | POR | 0.590256 | #tron | 212 | 216 |
| 5 | ORG | 0.669692 | Decept | 253 | 259 |
| 6 | MISC | 0.498350 | ##iconos | 259 | 264 |
| 7 | MISC | 0.775361 | Megatrón | 350 | 358 |
| 8 | MISC | 0.987854 | Optimus Prime | 367 | 380 |
| 9 | POR | 0.812096 | Abejorro | 502 | 511 |
Puedes ver que la tubería detectó todas las entidades y también asignó una categoría como ORG (organización), LOC (ubicación) oPER (persona) a cada una de ellas. Aquí utilizamos el argumento aggregation_strategypara agrupar las palabras según las predicciones del modelo. Por ejemplo, la entidad "Optimus Prime" se compone de dos palabras, pero se le asigna una sola categoría: MISC
(varios). Las puntuaciones nos indican el grado de confianza del modelo en las entidades que identificó. Podemos ver que se mostró menos seguro con "Decepticons" y con la primera aparición de "Megatron", que no consiguió agrupar como una sola entidad.
Nota
¿Ves esos extraños símbolos hash (#) en la columna word de la tabla anterior? Los produce el tokenizador del modelo, que divide las palabras en unidades atómicas llamadas tokens. Aprenderás todo sobre la tokenización en el Capítulo 2.
Extraer todas las entidades con nombre de un texto está bien, pero a veces nos gustaría hacer preguntas más específicas. Aquí es donde podemos utilizarla respuesta a preguntas.
Respuesta a preguntas
En la respuesta a preguntas, proporcionamos al modelo un fragmento de texto llamado contexto, junto con una pregunta cuya respuesta queremos extraer. A continuación, el modelo devuelve el fragmento de texto correspondiente a la respuesta. Veamos lo que obtenemos cuando formulamos una pregunta concreta sobre las opiniones de nuestros clientes:
reader=pipeline("question-answering")question="What does the customer want?"outputs=reader(question=question,context=text)pd.DataFrame([outputs])
| puntuación | empieza | fin | responde | |
|---|---|---|---|---|
| 0 | 0.631291 | 335 | 358 | un intercambio de Megatron |
Podemos ver que, junto con la respuesta, la tubería también devolvió los enterosstart y end que corresponden a los índices de caracteres donde se encontró el tramo de respuesta (igual que con el etiquetado NER). Hay varios tipos de respuesta a preguntas que investigaremos enel Capítulo 7, pero este tipo concreto se denomina respuesta extractiva a preguntas porque la respuesta se extrae directamente del texto.
Con este enfoque puedes leer y extraer rápidamente información relevante de las opiniones de un cliente. Pero, ¿qué ocurre si recibes una montaña de quejas interminables y no tienes tiempo de leerlas todas? ¡Veamos si un modelo de resumen puede ayudarte!
Resumir
El objetivo del resumen de texto es tomar un texto largo como entrada y generar una versión corta con todos los hechos relevantes. Se trata de una tarea mucho más complicada que las anteriores, ya que requiere que el modelo genere un texto coherente. En lo que ya debería ser un modelo familiar, podemos instanciar una canalización de resumen de la siguiente manera:
summarizer=pipeline("summarization")outputs=summarizer(text,max_length=45,clean_up_tokenization_spaces=True)(outputs[0]['summary_text'])
Bumblebee ordered an Optimus Prime action figure from your online store in Germany. Unfortunately, when I opened the package, I discovered to my horror that I had been sent an action figure of Megatron instead.
¡Este resumen no está tan mal! Aunque se han copiado partes del texto original, el modelo fue capaz de captar la esencia del problema e identificar correctamente que "Abejorro" (que aparecía al final) era el autor de la queja. En este ejemplo también puedes ver que pasamos algunos argumentos de palabra clave como max_length yclean_up_tokenization_spaces a la canalización; éstos nos permiten ajustar las salidas en tiempo de ejecución.
Pero, ¿qué ocurre cuando recibes comentarios en un idioma que no entiendes? Puedes utilizar Google Translate, ¡o puedes utilizar tu propio transformador para que te lo traduzca!
Traducción
Al igual que el resumen, la traducción es una tarea cuyo resultado consiste en un texto generado. Utilicemos una cadena de traducción para traducir un texto del inglés al alemán:
translator=pipeline("translation_en_to_de",model="Helsinki-NLP/opus-mt-en-de")outputs=translator(text,clean_up_tokenization_spaces=True,min_length=100)(outputs[0]['translation_text'])
Sehr geehrter Amazon, letzte Woche habe ich eine Optimus Prime Action Figur aus Ihrem Online-Shop in Deutschland bestellt. Leider, als ich das Paket öffnete, entdeckte ich zu meinem Entsetzen, dass ich stattdessen eine Action Figur von Megatron geschickt worden war! Als lebenslanger Feind der Decepticons, Ich hoffe, Sie können mein Dilemma verstehen. Um das Problem zu lösen, Ich fordere einen Austausch von Megatron für die Optimus Prime Figur habe ich bestellt. Anbei sind Kopien meiner Aufzeichnungen über diesen Kauf. Ich erwarte, bald von Ihnen zu hören. Aufrichtig, Bumblebee.
De nuevo, el modelo produjo una traducción muy buena que utiliza correctamente los pronombres formales del alemán, como "Ihrem" y "Sie". Aquí también hemos mostrado cómo puedes anular el modelo predeterminado en la canalización para elegir el mejor para tu aplicación, y puedes encontrar modelos para miles de pares de idiomas en el Hub de Hugging Face. Antes de dar un paso atrás y echar un vistazo a todo el ecosistema de Hugging Face, examinemos una última aplicación.
Generación de texto
Supongamos que te gustaría poder responder más rápidamente a las opiniones de los clientes teniendo acceso a una función de autocompletar. Con un modelo de generación de texto puedes hacerlo de la siguiente manera:
generator=pipeline("text-generation")response="Dear Bumblebee, I am sorry to hear that your order was mixed up."prompt=text+"\n\nCustomer service response:\n"+responseoutputs=generator(prompt,max_length=200)(outputs[0]['generated_text'])
Dear Amazon, last week I ordered an Optimus Prime action figure from your online store in Germany. Unfortunately, when I opened the package, I discovered to my horror that I had been sent an action figure of Megatron instead! As a lifelong enemy of the Decepticons, I hope you can understand my dilemma. To resolve the issue, I demand an exchange of Megatron for the Optimus Prime figure I ordered. Enclosed are copies of my records concerning this purchase. I expect to hear from you soon. Sincerely, Bumblebee. Customer service response: Dear Bumblebee, I am sorry to hear that your order was mixed up. The order was completely mislabeled, which is very common in our online store, but I can appreciate it because it was my understanding from this site and our customer service of the previous day that your order was not made correct in our mind and that we are in a process of resolving this matter. We can assure you that your order
Vale, quizá no querríamos utilizar esta terminación para calmar a Bumblebee, pero ya te haces una idea general.
Ahora que ya has visto unas cuantas aplicaciones geniales de los modelos de transformadores, quizá te preguntes dónde tiene lugar el entrenamiento. Todos los modelos que hemos utilizado en este capítulo están disponibles públicamente y ya se han ajustado para la tarea en cuestión. En general, sin embargo, querrás afinar los modelos con tus propios datos, y en los capítulos siguientes aprenderás a hacerlo.
Pero entrenar un modelo es sólo una pequeña parte de cualquier proyecto de PNL: ser capaz de procesar datos de forma eficiente, compartir resultados con colegas y hacer que tu trabajo sea reproducible también son componentes clave. Afortunadamente, Transformers está rodeado de un gran ecosistema de herramientas útiles que soportan gran parte del flujo de trabajo del aprendizaje automático moderno. Echemos un vistazo.
El Ecosistema de las Caras Abrazadas
Lo que empezó con Transformers ha crecido rápidamente hasta convertirse en todo un ecosistema formado por muchas bibliotecas y herramientas para acelerar tus proyectos de PNL y aprendizaje automático. El ecosistema Hugging Face consta principalmente de dos partes: una familia de bibliotecas y el Hub, como se muestra en la Figura 1-9. Las bibliotecas proporcionan el código, mientras que el Hub proporciona los pesos del modelo preentrenado, conjuntos de datos, scripts para las métricas de evaluación y mucho más. En esta sección echaremos un breve vistazo a los distintos componentes. Nos saltaremos Transformers, pues ya hemos hablado de él y veremos mucho más a lo largo del libro.
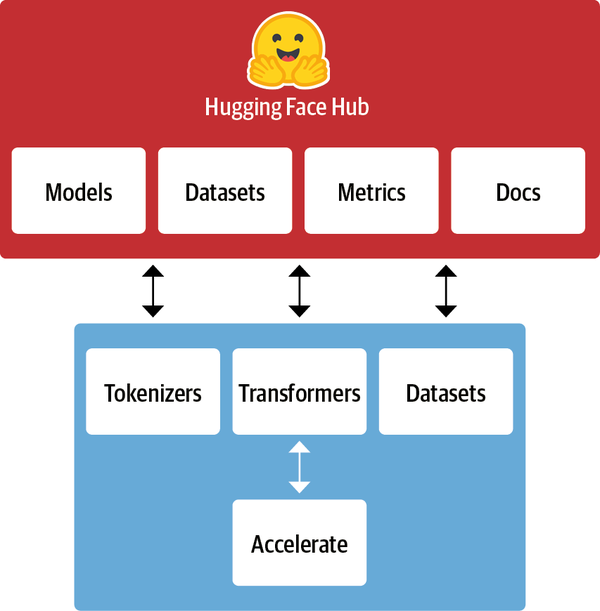
Figura 1-9. Visión general del ecosistema Cara Abrazada
El Centro de Caras Abrazadas
Como ya se ha señalado, el aprendizaje por transferencia es uno de los factores clave del éxito de los transformadores, porque permite reutilizar modelos preentrenados para nuevas tareas. En consecuencia, es crucial poder cargar rápidamente los modelos preentrenados y realizar experimentos con ellos.
El Hugging Face Hub alberga más de 20.000 modelos disponibles gratuitamente. Como se muestra en la Figura 1-10, hay filtros para tareas, marcos, conjuntos de datos y más, diseñados para ayudarte a navegar por el Hub y encontrar rápidamente candidatos prometedores. Como hemos visto con los pipelines, cargar un modelo prometedor en tu código está literalmente a una línea de código de distancia. Esto simplifica la experimentación con una amplia gama de modelos, y te permite centrarte en las partes específicas del dominio de tu proyecto.
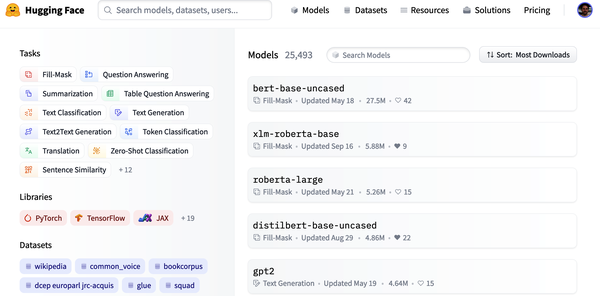
Figura 1-10. La página Modelos del Hub Cara Abrazada, mostrando los filtros a la izquierda y una lista de modelos a la derecha
Además de las ponderaciones de los modelos, el Hub también alberga conjuntos de datos y scripts para calcular métricas, que te permiten reproducir resultados publicados o aprovechar datos adicionales para tu aplicación.
El Hub también proporciona fichas de modelos y conjuntos de datos para documentar el contenido de los modelos y conjuntos de datos y ayudarte a tomar una decisión informada sobre si son los adecuados para ti. Una de las características más interesantes de Hub es que puedes probar cualquier modelo directamente a través de los diversos widgets interactivos específicos de cada tarea, como se muestra en laFigura 1-11.
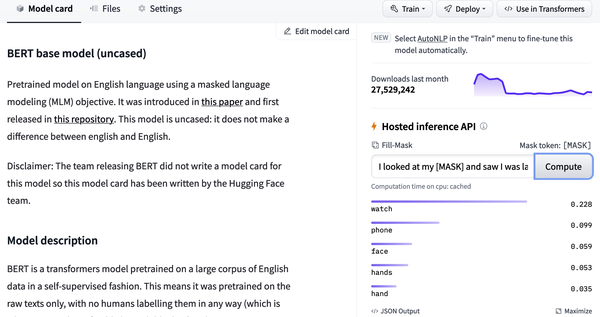
Figura 1-11. Una tarjeta modelo de ejemplo del Hub Cara Abrazada: el widget de inferencia, que te permite interactuar con el modelo, se muestra a la derecha
Continuemos nuestro recorrido con Tokenizers.
Nota
PyTorch y TensorFlow también ofrecen hubs propios y merece la pena consultarlos siun determinado modelo o conjunto de datos no está disponible en el Hugging Face Hub.
Tokenizadores de caras abrazadas
Detrás de cada uno de los ejemplos de canalización que hemos visto en este capítulo hay un paso de tokenización que divide el texto en bruto en trozos más pequeños llamados tokens. Veremos cómo funciona en detalle enel Capítulo 2, pero por ahora basta con entender que los tokens pueden ser palabras, partes de palabras o simplemente caracteres como signos de puntuación. Los modelos de transformadores se entrenan con representaciones numéricas de estos tokens, por lo que hacer bien este paso es muy importante para todo el proyecto de PNL.
Tokenizers proporciona muchas estrategias de tokenización y es extremadamente rápido tokenizando texto gracias a su backend Rust.12 También se encarga de todos los pasos previos y posteriores al procesamiento, como normalizar las entradas y transformar las salidas del modelo al formato requerido. Con Tokenizers, podemos cargar un tokenizador del mismo modo que cargamos los pesos del modelo preentrenado conTransformers.
Necesitamos un conjunto de datos y métricas para entrenar y evaluar los modelos, así que echemos un vistazo aDatasets, que se encarga de ese aspecto.
Conjuntos de datos de caras abrazadas
Cargar, procesar y almacenar conjuntos de datos puede ser un proceso engorroso, sobre todo cuando los conjuntos de datos son demasiado grandes para caber en la memoria RAM de tu portátil. Además, normalmente necesitas implementar varios scripts para descargar los datos y transformarlos en un formato estándar.
Datasets simplifica este proceso proporcionando una interfaz estándar para miles de conjuntos de datos que se pueden encontrar en el Hub. También proporciona caché inteligente (para que no tengas que rehacer el preprocesamiento cada vez que ejecutes tu código) y evita las limitaciones de RAM aprovechando un mecanismo especial llamado mapeo de memoria que almacena el contenido de un archivo en memoria virtual y permite que varios procesos modifiquen un archivo de forma más eficiente. La biblioteca también es interoperable con marcos populares como Pandas y NumPy, por lo que no tienes que abandonar la comodidad de tus herramientas favoritas de manipulación de datos.
Sin embargo, tener un buen conjunto de datos y un modelo potente no sirve de nada si no puedes medir el rendimiento de forma fiable. Por desgracia, las métricas clásicas de la PNL vienen con muchas implementaciones diferentes que pueden variar ligeramente y conducir a resultados engañosos. Al proporcionar los scripts de muchas métricas, Datasets ayuda a que los experimentos sean más reproducibles y los resultados más fiables.
Con las bibliotecas Transformadores, Tokenizadores y Conjuntos de datos, ¡tenemos todo lo que necesitamos para entrenar nuestros propios modelos transformadores! Sin embargo, como veremos en el Capítulo 10, hay situaciones en las que necesitamos un control preciso del bucle de entrenamiento. Ahí es donde entra en juego la última biblioteca del ecosistema: Acelerar.
Cara de abrazo Acelerar
Si alguna vez has tenido que escribir tu propio script de entrenamiento en PyTorch, lo más probable es que hayas tenido algunos quebraderos de cabeza al intentar portar el código que se ejecuta en tu portátil al código que se ejecuta en el clúster de tu organización.Accelerate añade una capa de abstracción a tus bucles de entrenamiento normales que se encarga de toda la lógica personalizada necesaria para la infraestructura de entrenamiento. Esto acelera literalmente tu flujo de trabajo al simplificar el cambio de infraestructura cuando es necesario.
Esto resume los componentes básicos del ecosistema de código abierto de Hugging Face. Pero antes de terminar este capítulo, echemos un vistazo a algunos de los retos habituales que surgen al intentar implementar transformadores en el mundo real.
Principales retos con los transformadores
En este capítulo hemos echado un vistazo a la amplia gama de tareas de PNL que pueden abordarse con modelos de transformadores. Leyendo los titulares de los medios de comunicación, a veces puede parecer que sus capacidades son ilimitadas. Sin embargo, a pesar de su utilidad, los transformadores están lejos de ser una bala de plata. He aquí algunos retos asociados a ellos que exploraremos a lo largo del libro:
- Lengua
-
La investigación en PNL está dominada por la lengua inglesa. Existen varios modelos para otras lenguas, pero es más difícil encontrar modelos preentrenados para lenguas raras o de pocos recursos. Enel Capítulo 4, exploraremos los transformadores multilingües y su capacidad para realizar transferencias multilingües de disparo cero.
- Disponibilidad de datos
-
Aunque podemos utilizar el aprendizaje por transferencia para reducir drásticamente la cantidad de datos de entrenamiento etiquetados que necesitan nuestros modelos, sigue siendo mucha comparada con la que necesita un ser humano para realizar la tarea. Abordar los escenarios en los que tienes pocos o ningún dato etiquetado es el tema del Capítulo 9.
- Trabajar con documentos largos
-
La autoatención funciona muy bien en textos de párrafos largos, pero se vuelve muy costosa cuando pasamos a textos más largos, como documentos completos. Los métodos para mitigarlo se tratan en el Capítulo 11.
- Opacidad
-
Al igual que otros modelos de aprendizaje profundo, los transformadores son en gran medida opacos. Es difícil o imposible desentrañar "por qué" un modelo hizo una determinada predicción. Se trata de un reto especialmente duro cuando estos modelos se implementan para tomar decisiones críticas. Exploraremos algunas formas de sondear los errores de los modelos de transformadores en los Capítulos 2 y4.
- Sesgo
-
Los modelos de los transformadores se preentrenan predominantemente con datos de texto de Internet. Esto imprime en los modelos todos los sesgos presentes en los datos. Asegurarse de que éstos no son ni racistas, ni sexistas, ni nada peor, es una tarea difícil. Discutiremos algunas de estas cuestiones con más detalle en el Capítulo 10.
Aunque desalentadores, muchos de estos retos pueden superarse. Además de en los capítulos específicos mencionados, tocaremos estos temas en casi todos los capítulos que tenemos por delante.
Conclusión
Esperamos que a estas alturas estés deseando aprender a entrenar e integrar estos versátiles modelos en tus propias aplicaciones. En este capítulo has visto que con unas pocas líneas de código puedes utilizar modelos de vanguardia para la clasificación, el reconocimiento de entidades con nombre, la respuesta a preguntas, la traducción y el resumen, pero esto es sólo la "punta del iceberg".
En los siguientes capítulos aprenderás a adaptar los transformadores a una amplia gama de casos de uso, como construir un clasificador de texto, o un modelo ligero para producción, o incluso entrenar un modelo lingüístico desde cero. Adoptaremos un enfoque práctico, lo que significa que para cada concepto tratado habrá un código adjunto que podrás ejecutar en Google Colab o en tu propia máquina GPU.
Ahora que ya conocemos los conceptos básicos de los transformadores, es hora de ensuciarnos las manos con nuestra primera aplicación: la clasificación de textos. Ese es el tema del próximo capítulo.
1 A. Vaswani et al., "La atención es todo lo que necesitas",(2017). ¡Este título era tan pegadizo que no menos de 50 artículos de seguimiento han incluido "todo lo que necesitas" en sus títulos!
2 J. Howard y S. Ruder, "Universal Language Model Fine-Tuning for Text Classification",(2018).
3 A. Radford et al., "Mejora de la comprensión lingüística mediante el preentrenamiento generativo",(2018).
4 J. Devlin et al., "BERT: Preentrenamiento de Transformadores Bidireccionales Profundos para la Comprensión del Lenguaje",(2018).
5 I. Sutskever, O. Vinyals y Q.V. Le, "Aprendizaje secuencia a secuencia con redes neuronales",(2014).
6 D. Bahdanau, K. Cho e Y. Bengio, "Traducción automática neuronal mediante el aprendizaje conjunto de alinear y traducir",(2014).
7 Los pesos son los parámetros aprendibles de una red neuronal.
8 A. Radford, R. Jozefowicz e I. Sutskever, "Aprender a generar reseñas y descubrir el sentimiento",(2017).
9 Un trabajo relacionado en esa época fue ELMo (Embeddings from Language Models), que demostró cómo el preentrenamiento de los LSTM podía producir incrustaciones de palabras de alta calidad para tareas posteriores.
10 Esto es más cierto para el inglés que para la mayoría de las lenguas del mundo, donde obtener un gran corpus de texto digitalizado puede ser difícil. Encontrar formas de salvar esta brecha es un área activa de la investigación y el activismo en PNL.
11 Y. Zhu et al., "Alinear libros y películas: hacia explicaciones visuales similares a historias viendo películas y leyendo libros",(2015).
Get Procesamiento del Lenguaje Natural con Transformadores, Edición Revisada now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

