Capítulo 1. Introducción al procesamiento de flujos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En 2011, Marc Andreessen dijo célebremente que "el software se está comiendo el mundo", refiriéndose a la floreciente economía digital, en un momento en que muchas empresas se enfrentaban a los retos de una transformación digital. Las empresas online de éxito, que utilizaban modos de funcionamiento "online" y "móvil", estaban tomando el relevo de sus homólogas tradicionales "de ladrillo y mortero".
Por ejemplo, imagina la experiencia tradicional de comprar una cámara nueva en una tienda de fotografía: visitaríamos la tienda, echaríamos un vistazo, tal vez haríamos algunas preguntas al dependiente, nos decidiríamos y, finalmente, compraríamos un modelo que cumpliera nuestros deseos y expectativas. Tras finalizar nuestra compra, la tienda habría registrado una transacción con tarjeta de crédito -o sólo un cambio de saldo en efectivo en caso de pago en metálico- y el director de la tienda sabría que tiene un artículo menos en su inventario de ese modelo concreto de cámara.
Ahora, llevemos esa experiencia a Internet: primero, empezamos a buscar en la red. Visitamos un par de tiendas online, dejando rastros digitales al pasar de una a otra. De repente, los anuncios de las páginas web empiezan a mostrarnos promociones de la cámara que estábamos mirando, así como de alternativas de la competencia. Finalmente, encontramos una tienda online que nos ofrece la mejor oferta y compramos la cámara. Creamos una cuenta. Nuestros datos personales quedan registrados y vinculados a la compra. Mientras completamos la compra, se nos ofrecen opciones adicionales que supuestamente son populares entre otras personas que compraron la misma cámara. Cada una de nuestras interacciones digitales, como buscar palabras clave en la web, hacer clic en algún enlace o dedicar tiempo a leer una página concreta, genera una serie de eventos que se recopilan y se transforman en valor empresarial, como publicidad personalizada o recomendaciones de venta adicionales.
Comentando la cita de Andreessen, en 2015, Dries Buytaert dijo "no, en realidad, los datos se están comiendo el mundo" Lo que quería decir es que las empresas disruptivas de hoy ya no lo son por su software, sino por los datos únicos que recopilan y su capacidad para transformar esos datos en valor.
La adopción de las tecnologías de procesamiento de flujos está impulsada por la creciente necesidad de las empresas de mejorar el tiempo necesario para reaccionar y adaptarse a los cambios en su entorno operativo. Esta forma de procesar los datos a medida que llegan proporciona una ventaja técnica y estratégica. Ejemplos de esta adopción en curso son sectores como el comercio por Internet, con flujos de datos en continuo funcionamiento creados por empresas que interactúan con los clientes 24 horas al día, 7 días a la semana, o las empresas de tarjetas de crédito, que analizan las transacciones a medida que se producen para detectar y detener las actividades fraudulentas en el momento en que se producen.
Otro factor que impulsa el procesamiento de flujos es que nuestra capacidad para generar datos supera con creces nuestra capacidad para darles sentido. Aumentamos constantemente el número de dispositivos con capacidad informática en nuestros entornos personales y profesionales<m-dash>televisores, coches conectados, smartphones, ordenadores para bicicletas, relojes inteligentes, cámaras de vigilancia, termostatos, etc. Nos rodeamos de dispositivos destinados a producir registros de eventos: flujos de mensajes que representan acciones e incidentes que forman parte de la historia del dispositivo en su contexto. Nos estamos rodeando de dispositivos destinados a producir registros de eventos: flujos de mensajes que representan las acciones e incidentes que forman parte de la historia del dispositivo en su contexto. A medida que interconectamos cada vez más esos dispositivos, creamos la capacidad de acceder a esos registros de eventos y, por tanto, de analizarlos. Este fenómeno abre la puerta a un increíble estallido de creatividad e innovación en el ámbito del análisis de datos casi en tiempo real, a condición de que encontremos la forma de hacer que este análisis sea manejable. En este mundo de registros de eventos agregados, el procesamiento de flujos ofrece la forma más respetuosa con los recursos de facilitar el análisis de flujos de datos.
No es una sorpresa que no sólo los datos se estén comiendo el mundo, sino también los datos en streaming.
En este capítulo, iniciamos nuestro viaje en el procesamiento de flujos utilizando Apache Spark. Para prepararnos a discutir las capacidades de Spark en el área del procesamiento de flujos, necesitamos establecer un entendimiento común de lo que es el procesamiento de flujos, sus aplicaciones y sus retos. Después de construir ese lenguaje común, presentamos Apache Spark como un marco genérico de procesamiento de datos capaz de manejar los requisitos de las cargas de trabajo por lotes y de flujo utilizando un modelo unificado. Por último, nos centramos en las capacidades de flujo de Spark, donde presentamos las dos API disponibles: Spark Streaming y Structured Streaming: Spark Streaming y Structured Streaming. Discutimos brevemente sus características más destacadas para proporcionarte un anticipo de lo que descubrirás en el resto de este libro.
¿Qué es el procesamiento de flujos?
Procesamiento de flujos es la disciplina y el conjunto de técnicas relacionadas que se utilizan para extraer información de datos ilimitados.
En su libro Streaming Systems, Tyler Akidau define los datos ilimitados del siguiente modo:
Un tipo de conjunto de datos de tamaño infinito (al menos teóricamente).
Dado que nuestros sistemas de información están construidos sobre hardware con recursos finitos, como la memoria y la capacidad de almacenamiento, no es posible que contengan conjuntos de datos ilimitados. En lugar de ello, observamos los datos tal y como se reciben en el sistema de procesamiento, en forma de flujo de acontecimientos a lo largo del tiempo. A esto lo llamamos flujo de datos.
En en cambio, consideramos datos ac otados un conjunto de datos de tamaño conocido. Podemos contar el número de elementos de un conjunto de datos acotado.
Procesamiento por lotes frente a procesamiento por flujos
¿Cómo procesamos ambos tipos de conjuntos de datos? Con el procesamiento por lotes nos referimos al análisis computacional de conjuntos de datos acotados. En términos prácticos, esto significa que esos conjuntos de datos están disponibles y son recuperables en su totalidad desde algún tipo de almacenamiento. Conocemos el tamaño del conjunto de datos al inicio del proceso computacional, y la duración de ese proceso está limitada en el tiempo.
En cambio, con el procesamiento de flujos nos ocupamos del procesamiento de los datos a medida que llegan al sistema. Dada la naturaleza ilimitada de los flujos de datos, los procesadores de flujos necesitan funcionar constantemente mientras el flujo esté entregando nuevos datos. Eso, como hemos aprendido, puede ser -teóricamente- para siempre.
Los sistemas de procesamiento de flujos aplican técnicas de programación y funcionamiento para hacer posible el procesamiento de flujos de datos potencialmente infinitos con una cantidad limitada de recursos informáticos.
La noción de tiempo en el procesamiento de flujos
Los datos pueden encontrarse de dos formas:
-
En reposo, en forma de archivo, contenido de una base de datos u otro tipo de registro
-
En movimiento, como secuencias de señales generadas continuamente, como la medición de un sensor o las señales GPS de vehículos en movimiento
Ya hemos dicho que un programa de procesamiento de secuencias es un programa que supone que su entrada tiene un tamaño potencialmente infinito. Más concretamente, un programa de procesamiento de secuencias supone que su entrada es una secuencia de señales de longitud indefinida, observadas a lo largo del tiempo.
Desde el punto de vista de una línea de tiempo, los datos en reposo son datos del pasado: podría decirse que todos los conjuntos de datos acotados, ya estén almacenados en archivos o contenidos en bases de datos, fueron inicialmente un flujo de datos recogidos a lo largo del tiempo en algún almacenamiento. La base de datos del usuario, todos los pedidos del último trimestre, las coordenadas GPS de los viajes en taxi en una ciudad, etc., todo empezó como eventos individuales recogidos en un repositorio.
Intentar razonar sobre datos en movimiento es más difícil. Hay una diferencia temporal entre el momento en que se generan los datos originalmente y el momento en que están disponibles para su procesamiento. Esa diferencia temporal puede ser muy corta, como los eventos de registro web generados y procesados dentro del mismo centro de datos, o mucho más larga, como los datos GPS de un coche que viaja por un túnel y que sólo se envían cuando el vehículo restablece su conectividad inalámbrica después de salir del túnel.
Podemos observar que hay una línea de tiempo para cuando se produjeron los acontecimientos y otra para cuando los acontecimientos son tratados por el sistema de procesamiento de flujos. Estas líneas de tiempo son tan significativas que les damos nombres específicos:
- Hora del acontecimiento
-
La hora en la que se creó el evento. La información sobre la hora la proporciona el reloj local del dispositivo que genera el suceso.
- Tiempo de procesamiento
-
La hora en la que el evento es gestionado por el sistema de procesamiento de flujos. Es el reloj del servidor que ejecuta la lógica de procesamiento. Suele ser relevante por razones técnicas, como calcular el retardo del procesamiento o como criterio para determinar la salida duplicada.
La diferenciación entre estas líneas temporales adquiere gran importancia cuando necesitamos correlacionar, ordenar o agregar los acontecimientos entre sí.
El factor de la incertidumbre
En una línea de tiempo, los datos en reposo se refieren al pasado, y los datos en movimiento pueden considerarse el presente. Pero, ¿qué ocurre con el futuro? Uno de los aspectos más sutiles de este debate es que no hace suposiciones sobre el rendimiento al que el sistema recibe los acontecimientos.
En general, los sistemas de streaming no requieren que la entrada se produzca a intervalos regulares, todos a la vez, o siguiendo un ritmo determinado. Esto significa que, como el cálculo suele tener un coste, es un reto predecir los picos de carga: hacer coincidir la llegada repentina de elementos de entrada con los recursos informáticos necesarios para procesarlos.
Si disponemos de la capacidad de cálculo necesaria para hacer frente a una afluencia repentina de elementos de entrada, nuestro sistema producirá los resultados esperados, pero si no hemos previsto semejante ráfaga de datos de entrada, algunos sistemas de streaming podrían sufrir retrasos, estrechamiento de recursos o fallos.
Hacer frente a la incertidumbre es un aspecto importante del procesamiento de flujos.
En resumen, el procesamiento de flujos nos permite extraer información de infinitos flujos de datos observados como eventos entregados a lo largo del tiempo. Sin embargo, al recibir y procesar los datos, tenemos que hacer frente a la complejidad adicional del tiempo-evento y a la incertidumbre introducida por una entrada ilimitada.
¿Por qué querríamos lidiar con ese problema adicional? En la siguiente sección, echamos un vistazo a una serie de casos de uso que ilustran el valor añadido por el procesamiento de flujos y cómo cumple la promesa de proporcionar perspectivas más rápidas y procesables, y por tanto valor empresarial, sobre los flujos de datos.
Algunos ejemplos de procesamiento de flujos
El uso del procesamiento de flujos es tan amplio como nuestra capacidad para imaginar nuevas aplicaciones de los datos en tiempo real e innovadoras. Los siguientes casos de uso, en los que los autores han participado de una forma u otra, son sólo una pequeña muestra que utilizamos para ilustrar el amplio espectro de aplicación del procesamiento de flujos:
- Monitoreo de dispositivos
-
Una pequeña empresa de puso en marcha un monitor de dispositivos del Internet de las Cosas (IoT) basado en la nube, capaz de recoger, procesar y almacenar datos de hasta 10 millones de dispositivos. Se desplegaron varios procesadores de flujo para alimentar distintas partes de la aplicación, desde actualizaciones del panel de control en tiempo real utilizando almacenes en memoria, hasta agregados de datos continuos, como recuentos únicos y mediciones mínimas/máximas.
- Detección de fallos
-
Un gran fabricante de hardware aplica una compleja canalización de procesamiento de flujos para recibir métricas del dispositivo. Mediante el análisis de series temporales, se detectan posibles fallos y se envían automáticamente medidas correctoras al dispositivo.
- Modernización de la facturación
-
Una compañía de seguros bien establecida en cambió su sistema de facturación a una canalización de flujos. Las exportaciones por lotes de su infraestructura mainframe existente se transmiten a través de este sistema para satisfacer los procesos de facturación existentes, al tiempo que permiten que los nuevos flujos en tiempo real de los agentes de seguros sean atendidos por la misma lógica.
- Gestión de flotas
-
Una empresa de gestión de flotas de instaló dispositivos capaces de informar en tiempo real de los datos de los vehículos gestionados, como la ubicación, los parámetros del motor y los niveles de combustible, lo que le permite hacer cumplir normas como los límites geográficos y analizar el comportamiento de los conductores en relación con los límites de velocidad.
- Recomendaciones para los medios de comunicación
-
Una empresa nacional de medios de comunicación ha implementado un canal de streaming para incorporar nuevos vídeos, como noticias, a su sistema de recomendaciones, de modo que los vídeos estén disponibles para las sugerencias personalizadas de sus usuarios casi tan pronto como se incorporan al repositorio de medios de la empresa. El sistema anterior de la empresa tardaba horas en hacer lo mismo.
- Préstamos más rápidos
-
Un banco de, activo en servicios de préstamos, pudo reducir la aprobación de préstamos de horas a segundos combinando varios flujos de datos en una aplicación de streaming.
Un hilo común entre esos casos de uso es la necesidad de la empresa de procesar los datos y crear perspectivas procesables en un breve periodo de tiempo desde que se reciben los datos. Este tiempo es relativo al caso de uso: aunque unos minutos es un tiempo de respuesta muy rápido para la aprobación de un préstamo, probablemente sea necesaria una respuesta en milisegundos para detectar un fallo del dispositivo y emitir una acción correctiva dentro de un umbral de nivel de servicio determinado.
En todos los casos, podemos argumentar que los datos son mejores cuando se consumen lo más frescos posible.
Ahora que ya sabemos qué es el procesamiento de flujos y tenemos algunos ejemplos de cómo se utiliza hoy en día, es hora de profundizar en los conceptos que sustentan su aplicación.
Aumentar el procesamiento de datos
Antes de hablar de las implicaciones de la computación distribuida en el procesamiento de flujos, hagamos un rápido recorrido por MapReduce, un modelo de computación que sentó las bases del procesamiento de datos escalable y fiable.
MapReduce
La historia de la programación para sistemas distribuidos vivió un acontecimiento notable en febrero de 2003. Jeff Dean y Sanjay Gemawhat, tras pasar por un par de iteraciones de reescritura de los sistemas de rastreo e indexación de Google, empezaron a notar algunas operaciones que podían exponer a través de una interfaz común, lo que les llevó a desarrollar MapReduce, un sistema para el procesamiento distribuido en grandes clusters en Google.
Parte de la razón por la que no desarrollamos MapReduce antes fue probablemente porque, cuando operábamos a menor escala, nuestros cálculos utilizaban menos máquinas y, por tanto, la robustez no era tan importante: estaba bien comprobar periódicamente algunos cálculos y reiniciar todo el cálculo desde un punto de comprobación si una máquina moría. Sin embargo, una vez que alcanzas una cierta escala, esto se vuelve bastante insostenible, ya que siempre estarías reiniciando cosas y nunca avanzarías.
Jeff Dean, correo electrónico a Bradford F. Lyon, agosto de 2013
MapReduce es una API de programación primero, y un conjunto de componentes después, que hacen que programar para un sistema distribuido sea una tarea relativamente más fácil que todos sus predecesores.
Sus principios básicos son dos funciones:
- Mapa
-
La operación map toma como argumento una función que se aplicará a cada elemento de la colección. Los elementos de la colección se leen de forma distribuida, a través del sistema de archivos distribuido, un chunk por máquina ejecutora. A continuación, todos los elementos de la colección que residen en el chunk local ven la función que se les ha aplicado, y el ejecutor emite el resultado de esa aplicación, si lo hay.
- Reduce
-
La operación reducir toma dos argumentos: uno es un elemento neutro, que es lo que devolvería la operación reducir si se le pasara una colección vacía. El otro es una operación de agregación, que toma el valor actual de un agregado, un nuevo elemento de la colección, y los agrupa en un nuevo agregado.
Las combinaciones de estas dos funciones de orden superior son lo suficientemente potentes como para expresar todas las operaciones que queramos hacer en un conjunto de datos.
La lección aprendida: Escalabilidad y tolerancia a fallos
Desde la perspectiva del programador, éstas son las principales ventajas de MapReduce:
-
Tiene una API sencilla.
-
Ofrece una gran expresividad.
-
Descarga significativamente la dificultad de distribuir un programa de los hombros del programador a los del diseñador de la biblioteca. En concreto, la resistencia está integrada en el modelo.
Aunque estas características hacen que el modelo sea atractivo, el principal éxito de MapReduce es su capacidad de crecimiento sostenido. A medida que aumentan los volúmenes de datos y las crecientes necesidades de las empresas dan lugar a más trabajos de extracción de información, el modelo MapReduce demuestra dos propiedades cruciales:
- Escalabilidad
-
A medida que crecen los conjuntos de datos de, es posible añadir más recursos al clúster de máquinas para conservar un rendimiento de procesamiento estable.
- Tolerancia a fallos
-
El sistema puede soportar y recuperarse de fallos parciales. Todos los datos están replicados. Si un ejecutor portador de datos se bloquea, basta con relanzar la tarea que se estaba ejecutando en el ejecutor bloqueado. Como el maestro mantiene un seguimiento de esa tarea, eso no plantea ningún problema particular, aparte de la reprogramación.
Estas dos características combinadas dan como resultado un sistema capaz de sostener constantemente cargas de trabajo en un entorno fundamentalmente poco fiable, propiedades que también requerimos para el procesamiento de flujos.
Procesamiento distribuido de flujos
Una diferencia fundamental del procesamiento por flujos con el modelo MapReduce, y con el procesamiento por lotes en general, es que aunque el procesamiento por lotes tiene acceso al conjunto de datos completo, con los flujos sólo vemos una pequeña parte del conjunto de datos en cada momento.
Esta situación se agrava en un sistema distribuido; es decir, en un esfuerzo por distribuir la carga de procesamiento entre una serie de ejecutores, dividimos aún más el flujo de entrada en particiones. Cada ejecutor llega a ver sólo una vista parcial del flujo completo.
El reto para un marco de procesamiento de flujos distribuidos es proporcionar una abstracción que oculte esta complejidad al usuario y nos permita razonar sobre el flujo como un todo.
Procesamiento de flujos con estado en un sistema distribuido
Imaginemos que estamos contando los votos durante unas elecciones presidenciales. El enfoque clásico por lotes consistiría en esperar a que se hubieran emitido todos los votos y proceder a contarlos. Aunque este enfoque produce un resultado final correcto, daría lugar a noticias muy aburridas a lo largo del día porque no se conocen resultados (intermedios) hasta el final del proceso electoral.
Un escenario más emocionante es cuando podemos contar los votos por candidato a medida que se emite cada voto. En cualquier momento, tenemos un recuento parcial por participante que nos permite ver la posición actual, así como la tendencia de la votación. Probablemente podamos anticipar un resultado.
Para llevar a cabo este escenario, el procesador de flujo necesita mantener un registro interno de los votos vistos hasta el momento. Para garantizar un recuento coherente, este registro debe recuperarse de cualquier fallo parcial. De hecho, no podemos pedir a los ciudadanos que emitan de nuevo su voto debido a un fallo técnico.
Además, cualquier fallo eventual de recuperación no puede afectar al resultado final. No podemos arriesgarnos a declarar ganador al candidato equivocado como efecto secundario de un sistema mal recuperado.
Este escenario ilustra los retos del procesamiento de flujos con estado que se ejecuta en un entorno distribuido. El procesamiento con estado plantea cargas adicionales al sistema:
-
Tenemos que garantizar que el Estado se mantenga en el tiempo.
-
Exigimos garantías de coherencia de los datos, incluso en caso de fallos parciales del sistema.
Como verás a lo largo de este libro, abordar estas cuestiones es un aspecto importante del procesamiento de flujos.
Ahora que tenemos una idea más clara de los impulsores de la popularidad del procesamiento de flujos y de los aspectos desafiantes de esta disciplina, podemos presentar Apache Spark. Como motor unificado de análisis de datos, Spark ofrece capacidades de procesamiento de datos tanto por lotes como por flujos, lo que lo convierte en una opción excelente para satisfacer las demandas de las aplicaciones intensivas en datos, como veremos a continuación.
Presentación de Apache Spark
Apache Spark es un marco informático distribuido rápido, fiable y tolerante a fallos para el procesamiento de datos a gran escala.
La primera oleada: API funcionales
En sus inicios, el gran avance de Spark se debió a su novedoso uso de la memoria y a su expresiva API funcional. El modelo de memoria Spark utiliza la RAM para almacenar en caché los datos a medida que se procesan, lo que da como resultado un procesamiento hasta 100 veces más rápido que Hadoop MapReduce, la implementación de código abierto de MapReduce de Google para cargas de trabajo por lotes.
Su abstracción central, el Conjunto de Datos Distribuido Resistente (RDD), aportó un rico modelo de programación funcional que abstraía las complejidades de la computación distribuida en un clúster. introdujo los conceptos de transformaciones y acciones que ofrecían un modelo de programación más expresivo que las etapas de mapear y reducir que comentamos en la visión general de MapReduce.
En ese modelo, muchas transformaciones disponibles como map, flatmap, join, y filter expresan la conversión perezosa de los datos de una representación interna a otra, mientras que las operaciones ansiosas llamadas acciones materializan la computación en el sistema distribuido para producir un resultado.
La Segunda Ola: SQL
El segundo cambio de juego en la historia del proyecto Spark fue la introducción de Spark SQL y DataFrames (y más tarde, Dataset, un DataFrame fuertemente tipado). Desde una perspectiva de alto nivel, Spark SQL añade soporte SQL a cualquier conjunto de datos que tenga un esquema. Hace posible consultar un conjunto de datos de valores separados por comas (CSV), Parquet o JSON de la misma forma que solíamos consultar una base de datos SQL.
Esta evolución también redujo el umbral de adopción para los usuarios. El análisis avanzado de datos distribuidos ya no era el reino exclusivo de los ingenieros de software; ahora era accesible para los científicos de datos, los analistas empresariales y otros profesionales familiarizados con SQL. Desde el punto de vista del rendimiento, SparkSQL aportó un optimizador de consultas y un motor de ejecución física a Spark, haciéndolo aún más rápido a la vez que utilizaba menos recursos.
Un motor unificado
Hoy en día, Spark es un motor analítico unificado que ofrece capacidades de procesamiento por lotes y de flujo continuo y es compatible con un enfoque políglota del análisis de datos, ya que ofrece API en Scala, Java, Python y el lenguaje R.
Aunque en el contexto de este libro vamos a centrar nuestro interés en las capacidades de streaming de Apache Spark, su funcionalidad batch es igualmente avanzada y es altamente complementaria a las aplicaciones de streaming. El modelo de programación unificado de Spark significa que los desarrolladores sólo necesitan aprender un nuevo paradigma para abordar tanto las cargas de trabajo batch como las de streaming.
Nota
A lo largo del libro, utilizamos indistintamente Apache Spark y Spark. Utilizamos Apache Spark cuando queremos hacer hincapié en el proyecto o en su aspecto de código abierto, mientras que utilizamos Spark para referirnos a la tecnología en general.
Componentes de chispa
La Figura 1-1 ilustra en cómo Spark consta de un motor central, un conjunto de abstracciones construidas sobre él (representadas como capas horizontales) y bibliotecas que utilizan esas abstracciones para abordar un área concreta (recuadros verticales). Hemos resaltado las áreas que están dentro del alcance de este libro y hemos puesto en gris las que no están cubiertas. Para saber más sobre estas otras áreas de Apache Spark, te recomendamos Spark, The Definitive Guide, de Bill Chambers y Matei Zaharia (O'Reilly), y High Performance Spark, de Holden Karau y Rachel Warren (O'Reilly).
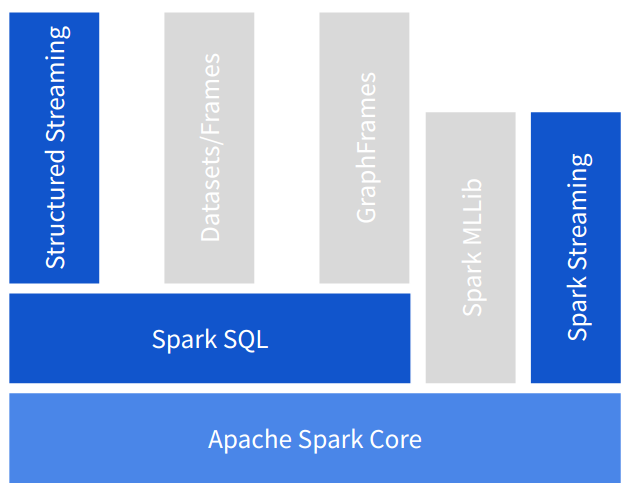
Figura 1-1. Capas de abstracción (horizontal) y bibliotecas (vertical) que ofrece Spark
Como capas de abstracción en Spark, tenemos las siguientes:
- Núcleo Spark
-
Contiene el motor de ejecución central de Spark y un conjunto de API funcionales de bajo nivel utilizadas para distribuir cálculos a un clúster de recursos informáticos, llamados ejecutores en la jerga de Spark. Su abstracción de clúster le permite enviar cargas de trabajo a YARN, Mesos y Kubernetes, así como utilizar su propio modo de clúster independiente, en el que Spark se ejecuta como un servicio dedicado en un clúster de máquinas. Su abstracción de fuente de datos permite la integración de muchos proveedores de datos diferentes, como archivos, almacenes de bloques, bases de datos y corredores de eventos.
- Spark SQL
-
Implementa las API de nivel superior
DatasetyDataFramede Spark y añade soporte SQL sobre fuentes de datos arbitrarias. También introduce una serie de mejoras de rendimiento mediante el motor de consulta Catalyst, y la generación de código y gestión de memoria del proyecto Tungsten.
Las bibliotecas construidas sobre estas abstracciones abordan diferentes áreas del análisis de datos a gran escala: MLLib para el aprendizaje automático, GraphFrames para el análisis de grafos, y las dos API para el procesamiento de flujos en las que se centra este libro: Spark Streaming y Structured Streaming.
Spark Streaming
Spark Streaming fue el primer marco de procesamiento de flujos construido sobre las capacidades de procesamiento distribuido del motor central de Spark. Se introdujo en la versión Spark 0.7.0 en febrero de 2013 como una versión alfa que evolucionó con el tiempo hasta convertirse hoy en una API madura ampliamente adoptada en la industria para procesar flujos de datos a gran escala.
Spark Streaming se basa conceptualmente en una premisa sencilla pero potente: aplicar las capacidades de computación distribuida de Spark al procesamiento de flujos, transformando los flujos continuos de datos en colecciones de datos discretos sobre los que Spark podría operar. Este enfoque del procesamiento de flujos se denomina modelo de microlotes; esto contrasta con el modelo de elemento a elemento que predomina en la mayoría de las demás implementaciones de procesamiento de flujos.
Spark Streaming utiliza el mismo paradigma de programación funcional que el núcleo de Spark, pero introduce una nueva abstracción, el Flujo Discretizado o DStream, que expone un modelo de programación para operar sobre los datos subyacentes en el flujo.
Streaming estructurado
Structured Streaming es un procesador de flujo construido sobre la abstracción Spark SQL. Amplía las API Dataset y DataFrame con capacidades de flujo. Como tal, adopta el modelo de transformación orientado a esquemas, que le confiere la parte estructurada de su nombre, y hereda todas las optimizaciones implementadas en Spark SQL.
El Streaming Estructurado se introdujo como API experimental con Spark 2.0 en julio de 2016. Un año más tarde, alcanzó la disponibilidad general con la versión Spark 2.2, que la hizo apta para implementaciones de producción. Como desarrollo relativamente nuevo, el Streaming Estructurado sigue evolucionando rápidamente con cada nueva versión de Spark.
El Streaming Estructurado utiliza un modelo declarativo para adquirir datos de un flujo o conjunto de flujos. Para utilizar la API en toda su extensión, requiere la especificación de un esquema para los datos del flujo. Además de admitir el modelo de transformación general proporcionado por las API Dataset y DataFrame, introduce características específicas de los flujos, como la compatibilidad con el tiempo de eventos, las uniones de flujos y la separación del tiempo de ejecución subyacente.
Esta última característica abre la puerta a la implementación de tiempos de ejecución con diferentes modelos de ejecución. La implementación por defecto utiliza el enfoque clásico de microlotes, mientras que un backend de procesamiento continuo más reciente aporta soporte experimental para el modo de ejecución continua casi en tiempo real.
El Streaming Estructurado ofrece un modelo unificado que sitúa el procesamiento de flujos al mismo nivel que las aplicaciones orientadas a lotes, eliminando gran parte de la carga cognitiva que supone razonar sobre el procesamiento de flujos.
¿Y ahora qué?
Si sientes la necesidad de aprender cualquiera de estas dos API de inmediato, puedes saltar directamente a Streaming estructurado en la Parte II o a Spark Streaming en la Parte III.
Si no estás familiarizado con el procesamiento de flujos, te recomendamos que continúes por esta parte inicial del libro porque construimos el vocabulario y los conceptos comunes que utilizamos en la discusión de los marcos específicos.
Get Procesamiento de flujos con Apache Spark now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

