Capítulo 1. Introducción al Procesamiento de Secuencias con Estado
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Apache Flink es un procesador de flujos distribuido con API intuitivas y expresivas para implementar aplicaciones de procesamiento de flujos con estado. Ejecuta eficientemente dichas aplicaciones a gran escala de forma tolerante a fallos. Flink se unió a la Fundación del Software Apache como proyecto incubador en abril de 2014 y se convirtió en proyecto de primer nivel en enero de 2015. Desde sus inicios, Flink ha contado con una comunidad de usuarios y colaboradores muy activa y en continuo crecimiento. Hasta la fecha, más de quinientas personas han contribuido a Flink, y se ha convertido en uno de los motores de procesamiento de flujos de código abierto más sofisticados, como demuestra su adopción generalizada. Flink impulsa aplicaciones críticas a gran escala en muchas empresas de distintos sectores y en todo el mundo.
La tecnología de procesamiento de flujos se está haciendo cada vez más popular entre las empresas grandes y pequeñas porque ofrece soluciones superiores para muchos casos de uso establecidos, como el análisis de datos, el ETL y las aplicaciones transaccionales, pero también facilita nuevas aplicaciones, arquitecturas de software y oportunidades de negocio. En este capítulo, analizamos por qué el procesamiento de flujos con estado se está haciendo tan popular y evaluamos su potencial. Comenzamos revisando las arquitecturas convencionales de aplicaciones de datos y señalamos sus limitaciones. A continuación, presentamos diseños de aplicaciones basados en el procesamiento de flujos con seguimiento de estado que presentan muchas características y ventajas interesantes respecto a los enfoques tradicionales. Por último, comentamos brevemente la evolución de los procesadores de flujo de código abierto y te ayudamos a ejecutar una aplicación de flujo en una instancia local de Flink.
Infraestructuras de datos tradicionales
Los datos y el procesamiento de datos han estado omnipresentes en las empresas durante muchas décadas. A lo largo de los años, la recopilación y el uso de datos han crecido constantemente, y las empresas han diseñado y construido infraestructuras para gestionar esos datos. La arquitectura tradicional que implementan la mayoría de las empresas distingue dos tipos de procesamiento de datos: el procesamiento transaccional y el procesamiento analítico. En esta sección, hablamos de ambos tipos y de cómo gestionan y procesan los datos.
Procesamiento transaccional
Las empresas utilizan todo tipo de aplicaciones para sus actividades empresariales cotidianas, como sistemas de planificación de recursos empresariales (ERP), software de gestión de relaciones con los clientes (CRM) y aplicaciones basadas en la web. Estos sistemas suelen diseñarse con niveles separados para el procesamiento de datos (la propia aplicación) y el almacenamiento de datos (un sistema de base de datos transaccional), como se muestra en la Figura 1-1.
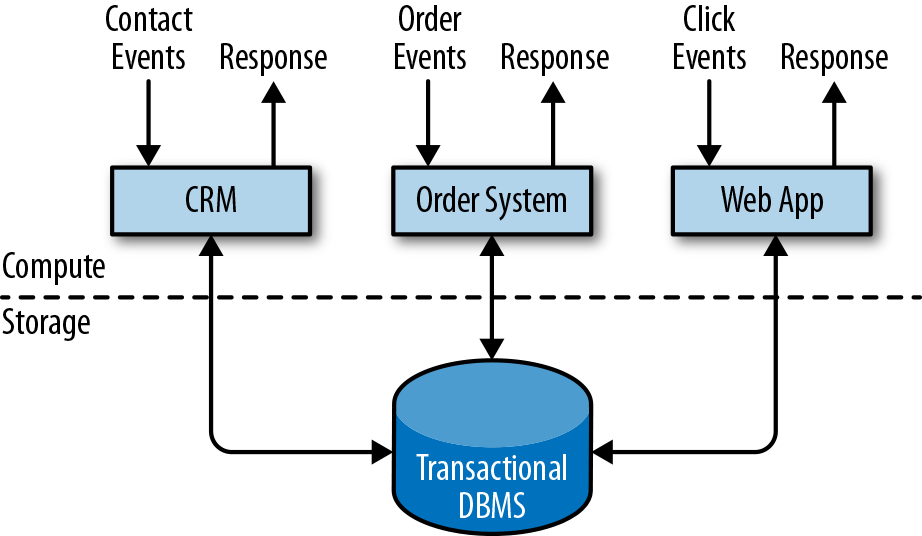
Figura 1-1. Diseño tradicional de aplicaciones transaccionales que almacenan datos en un sistema de base de datos remoto
Las aplicaciones suelen estar conectadas a servicios externos o se enfrentan a usuarios humanos y procesan continuamente los eventos entrantes, como pedidos, correo electrónico o clics en un sitio web. Cuando se procesa un evento, una aplicación lee su estado o lo actualiza ejecutando transacciones contra el sistema de base de datos remoto. A menudo, un sistema de bases de datos sirve a varias aplicaciones que a veces acceden a las mismas bases de datos o tablas.
Este diseño de la aplicación puede causar problemas cuando las aplicaciones necesitan evolucionar o escalar. Dado que varias aplicaciones pueden trabajar sobre la misma representación de datos o compartir la misma infraestructura, cambiar el esquema de una tabla o escalar un sistema de base de datos requiere una planificación cuidadosa y mucho esfuerzo. Un enfoque reciente para superar la agrupación estrecha de aplicaciones es el patrón de diseño de microservicios. Los microservicios se diseñan como aplicaciones pequeñas, autocontenidas e independientes. Siguen la filosofía UNIX de hacer una sola cosa y hacerla bien. Las aplicaciones más complejas se construyen conectando entre sí varios microservicios que sólo se comunican a través de interfaces estandarizadas, como las conexiones RESTful HTTP. Dado que los microservicios están estrictamente desacoplados entre sí y sólo se comunican a través de interfaces bien definidas, cada microservicio puede implementarse con una pila tecnológica diferente que incluya un lenguaje de programación, bibliotecas y almacenes de datos. Los microservicios y todo el software y servicios necesarios suelen agruparse y desplegarse en contenedores independientes. La Figura 1-2 muestra una arquitectura de microservicios.
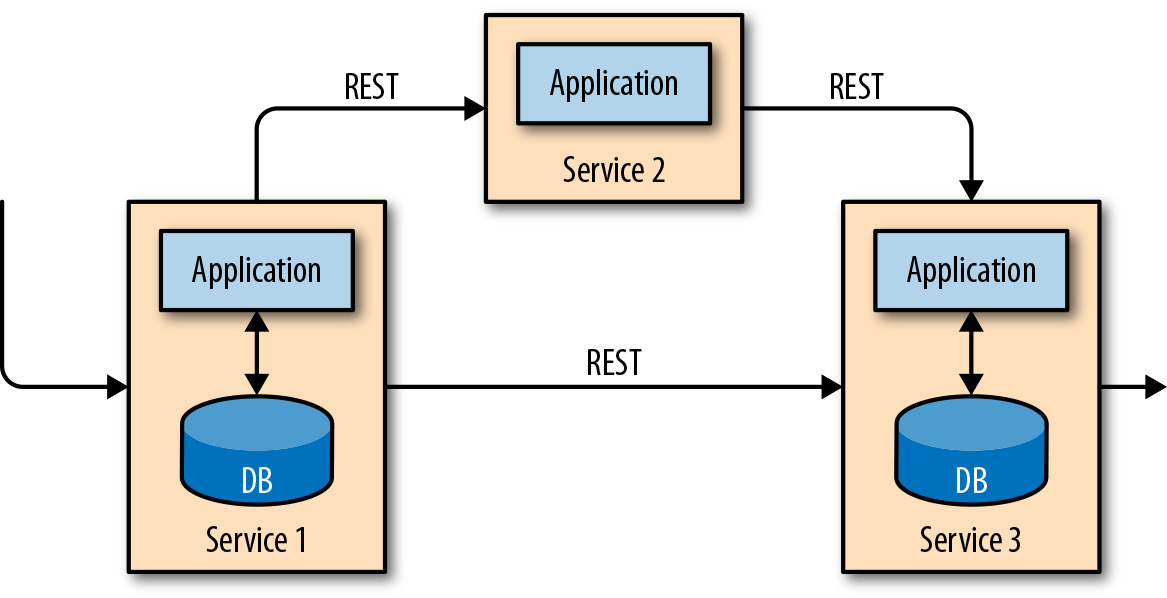
Figura 1-2. Una arquitectura de microservicios
Procesamiento analítico
Los datos de que se almacenan en los distintos sistemas de bases de datos transaccionales de una empresa pueden proporcionar información valiosa sobre sus operaciones comerciales. Por ejemplo, los datos de un sistema de procesamiento de pedidos pueden analizarse para obtener el crecimiento de las ventas a lo largo del tiempo, identificar los motivos de los retrasos en los envíos o predecir las ventas futuras para ajustar el inventario. Sin embargo, los datos transaccionales suelen estar distribuidos en varios sistemas de bases de datos desconectados y son más valiosos cuando pueden analizarse conjuntamente. Además, a menudo es necesario transformar los datos a un formato común.
En lugar de ejecutar consultas analíticas directamente en las bases de datos transaccionales, los datos suelen replicarse en un almacén de datos, un almacén de datos dedicado a cargas de trabajo de consultas analíticas. Para poblar un almacén de datos, es necesario copiar en él los datos gestionados por los sistemas de bases de datos transaccionales. El proceso de copiar datos al almacén de datos se denomina extraer-transformar-cargar (ETL). Un proceso ETL extrae datos de una base de datos transaccional, los transforma en una representación común que puede incluir validación, normalización de valores, codificación, deduplicación y transformación de esquemas, y finalmente los carga en la base de datos analítica. Los procesos ETL pueden ser bastante complejos y a menudo requieren soluciones técnicamente sofisticadas para cumplir los requisitos de rendimiento. Los procesos ETL deben ejecutarse periódicamente para mantener sincronizados los datos del almacén de datos.
Una vez importados los datos al almacén de datos, se pueden consultar y analizar. Normalmente, hay dos clases de consultas que se ejecutan en un almacén de datos. El primer tipo son las consultas de informes periódicos que calculan estadísticas relevantes para el negocio, como los ingresos, el crecimiento de usuarios o el rendimiento de la producción. Estas métricas se reúnen en informes que ayudan a la dirección a evaluar la salud general de la empresa. El segundo tipo son las consultas ad hoc que pretenden dar respuesta a preguntas concretas y respaldar decisiones críticas para el negocio, por ejemplo, una consulta para recopilar cifras de ingresos y gasto en anuncios de radio para evaluar la eficacia de una campaña de marketing. Ambos tipos de consultas se ejecutan mediante un almacén de datos en forma de procesamiento por lotes, como se muestra en la Figura 1-3.
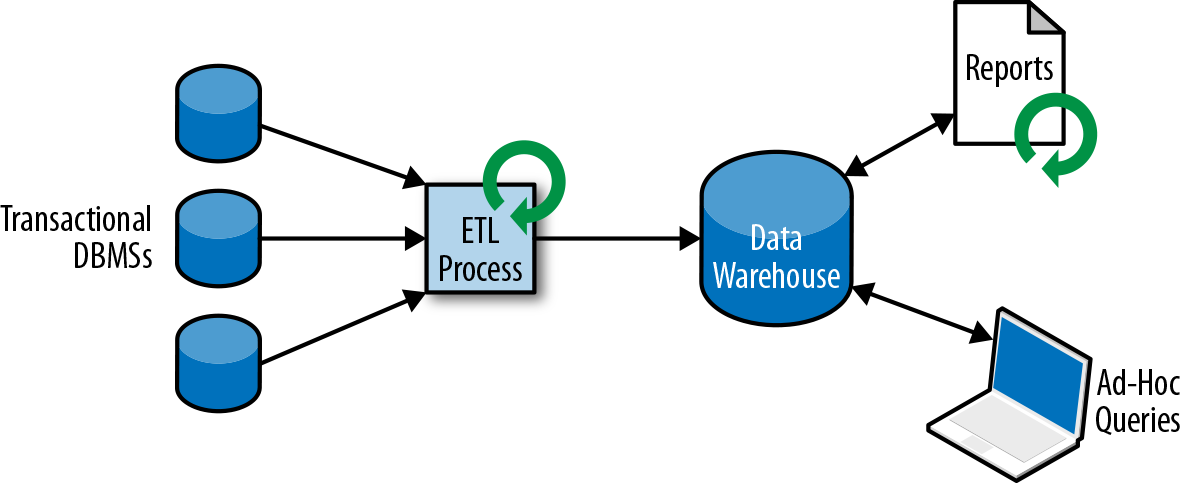
Figura 1-3. Una arquitectura tradicional de almacén de datos para el análisis de datos
Hoy en día, los componentes del ecosistema Apache Hadoop son parte integrante de las infraestructuras informáticas de muchas empresas. En lugar de introducir todos los datos en un sistema de base de datos relacional, cantidades significativas de datos, como archivos de registro, medios sociales o registros de clics web, se escriben en el sistema de archivos distribuidos de Hadoop (HDFS), S3 u otros almacenes de datos masivos, como Apache HBase, que proporcionan una capacidad de almacenamiento masiva a un coste reducido. Los datos que residen en estos sistemas de almacenamiento pueden consultarse y procesarse con un motor SQL-on-Hadoop, por ejemplo Apache Hive, Apache Drill o Apache Impala. Sin embargo, la infraestructura sigue siendo básicamente la misma que la de una arquitectura de almacén de datos tradicional.
Procesamiento de flujos con estado
Prácticamente todos los datos se crean como flujos continuos de eventos. Piensa en las interacciones de los usuarios en los sitios web o en las aplicaciones móviles, la realización de pedidos, los registros de los servidores o las mediciones de los sensores; todos ellos son flujos de eventos. De hecho, es difícil encontrar ejemplos de conjuntos de datos finitos y completos que se generen todos a la vez. El procesamiento de flujos con estado es un patrón de diseño de aplicaciones para procesar flujos ilimitados de eventos y es aplicable a muchos casos de uso diferentes en la infraestructura informática de una empresa. Antes de hablar de sus casos de uso, explicaremos brevemente cómo funciona el procesamiento de flujos con estado.
Cualquier aplicación que procese un flujo de eventos y no se limite a realizar transformaciones triviales de registro en registro necesita tener estado, con capacidad para almacenar y acceder a datos intermedios. Cuando una aplicación recibe un evento, puede realizar cálculos arbitrarios que impliquen leer datos del estado o escribir datos en él. En principio, el estado puede almacenarse y accederse a él en muchos lugares diferentes, como variables de programa, archivos locales o bases de datos integradas o externas.
Apache Flink almacena el estado de la aplicación localmente en la memoria o en una base de datos integrada. Como Flink es un sistema distribuido, el estado local debe estar protegido contra fallos para evitar la pérdida de datos en caso de fallo de la aplicación o de la máquina. Flink garantiza esto escribiendo periódicamente un punto de control consistente del estado de la aplicación en un almacenamiento remoto y duradero. El estado, la consistencia del estado y el mecanismo de puntos de control de Flink se tratarán con más detalle en los capítulos siguientes, pero, por ahora, la Figura 1-4 muestra una aplicación Flink de flujo con estado.
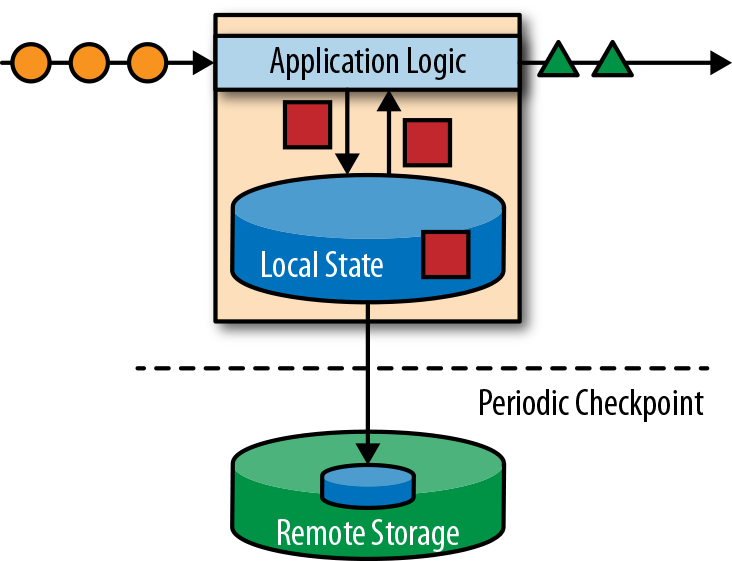
Figura 1-4. Una aplicación de streaming con estado
Procesamiento de flujos con estado Las aplicaciones a menudo ingieren sus eventos entrantes desde un registro de eventos. Un registro de eventos almacena y distribuye flujos de eventos. Los eventos se escriben en un registro duradero de sólo apéndice, lo que significa que el orden de los eventos escritos no se puede cambiar. Un flujo que se escribe en un registro de eventos puede ser leído muchas veces por el mismo consumidor o por consumidores diferentes. Debido a la propiedad de "sólo añadir" del registro, los eventos se publican siempre a todos los consumidores exactamente en el mismo orden. Hay varios sistemas de registro de eventos disponibles como software de código abierto, siendo Apache Kafka el más popular, o como servicios integrados ofrecidos por proveedores de computación en nube.
Conectar una aplicación de streaming con estado que se ejecuta en Flink y un registro de eventos es interesante por múltiples razones. En esta arquitectura, el registro de eventos conserva los eventos de entrada y puede reproducirlos en orden determinista. En caso de fallo, Flink recupera una aplicación de flujo con estado restaurando su estado a partir de un punto de control anterior y restableciendo la posición de lectura en el registro de sucesos. La aplicación reproducirá (y adelantará) los eventos de entrada del registro de eventos hasta que llegue a la cola del flujo. Esta técnica se utiliza para recuperarse de fallos, pero también puede aprovecharse para actualizar una aplicación, corregir errores y reparar resultados emitidos anteriormente, migrar una aplicación a un clúster diferente o realizar pruebas A/B con diferentes versiones de la aplicación.
Como ya se ha dicho, el procesamiento de flujo con estado es una arquitectura de diseño versátil y flexible que puede utilizarse para muchos casos de uso diferentes. A continuación, presentamos tres clases de aplicaciones que suelen implementarse utilizando el procesamiento de flujos con estado: (1) aplicaciones basadas en eventos, (2) aplicaciones de canalización de datos y (3) aplicaciones de análisis de datos.
Implementaciones y Casos de Uso de Streaming en el Mundo Real
Si te interesa saber más sobre casos de uso e Implementaciones en el mundo real, consulta la página Powered By de Apache Flink y las grabaciones de charlas y diapositivas de las presentaciones de Flink Forward.
Describimos las clases de aplicaciones como patrones distintos para destacar la versatilidad del procesamiento de flujos con estado, pero la mayoría de las aplicaciones del mundo real comparten las propiedades de más de una clase.
Aplicaciones basadas en eventos
Aplicaciones dirigidas por eventos son aplicaciones de flujo con estado que ingieren flujos de eventos y procesan los eventos con lógica empresarial específica de la aplicación. Dependiendo de la lógica empresarial, una aplicación basada en eventos puede desencadenar acciones como enviar una alerta o un correo electrónico, o escribir eventos en un flujo de eventos salientes para que los consuma otra aplicación basada en eventos.
Los casos de uso típicos de las aplicaciones basadas en eventos incluyen:
-
Recomendaciones en tiempo real (por ejemplo, para recomendar productos mientras los clientes navegan por el sitio web de un minorista)
-
Detección de patrones o procesamiento de eventos complejos (por ejemplo, para la detección de fraudes en transacciones con tarjetas de crédito)
-
Detección de anomalías (por ejemplo, para detectar intentos de intrusión en una red informática)
Las aplicaciones basadas en eventos son una evolución de los microservicios de. Se comunican a través de registros de eventos en lugar de llamadas REST y mantienen los datos de la aplicación como estado local en lugar de escribirlos y leerlos de un almacén de datos externo, como una base de datos relacional o un almacén de valores clave. La Figura 1-5 muestra una arquitectura de servicios compuesta por aplicaciones de streaming basadas en eventos.
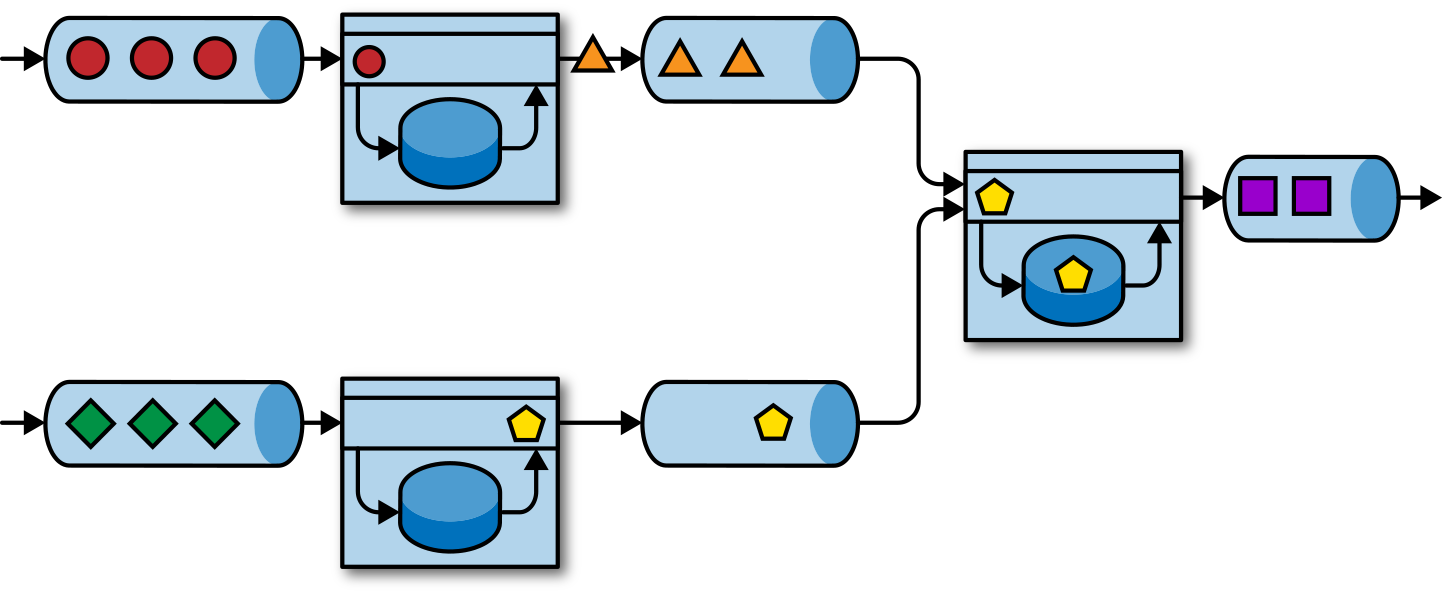
Figura 1-5. Una arquitectura de aplicación basada en eventos
Las aplicaciones de la Figura 1-5 están conectadas por registros de eventos. Una aplicación emite su salida a un registro de eventos y otra aplicación consume los eventos que la otra aplicación emitió. El registro de eventos desacopla emisores y receptores y proporciona una transferencia de eventos asíncrona y no bloqueante. Cada aplicación puede tener estado y gestionar localmente su propio estado sin acceder a almacenes de datos externos. Las aplicaciones también pueden funcionar y escalarse individualmente.
Las aplicaciones basadas en eventos ofrecen varias ventajas en comparación con las aplicaciones transaccionales o los microservicios. El acceso local al estado proporciona un rendimiento muy bueno en comparación con las consultas de lectura y escritura contra almacenes de datos remotos. El escalado y la tolerancia a fallos son gestionados por el procesador de flujo, y al aprovechar un registro de eventos como fuente de entrada, la entrada completa de una aplicación se almacena de forma fiable y puede reproducirse de forma determinista. Además, Flink puede restablecer el estado de una aplicación a un punto de guardado anterior, lo que permite evolucionar o reescalar una aplicación sin perder su estado.
Las aplicaciones basadas en eventos exigen mucho del procesador de flujo que las ejecuta. No todos los procesadores de flujos son igual de adecuados para ejecutar aplicaciones basadas en eventos. La expresividad de la API y la calidad del manejo de estados y del soporte de eventos determinan la lógica empresarial que se puede implementar y ejecutar. Este aspecto depende de las API del procesador de flujo, de los tipos de primitivas de estado que proporcione y de la calidad de su soporte para el procesamiento en tiempo de eventos. Además, la consistencia del estado exactamente una vez y la capacidad de escalar una aplicación son requisitos fundamentales para las aplicaciones basadas en eventos. Apache Flink cumple todos estos requisitos y es una muy buena opción para ejecutar este tipo de aplicaciones.
Canalizaciones de datos
Las arquitecturas informáticas actuales incluyen muchos almacenes de datos diferentes, como sistemas de bases de datos relacionales y especiales, registros de eventos, sistemas de archivos distribuidos, cachés en memoria e índices de búsqueda. Todos estos sistemas almacenan datos en diferentes formatos y estructuras de datos que proporcionan el mejor rendimiento para su patrón de acceso específico. Es habitual que las empresas almacenen los mismos datos en varios sistemas diferentes para mejorar el rendimiento de los accesos a los datos. Por ejemplo, la información de un producto que se ofrece en una tienda web puede almacenarse en una base de datos transaccional, una caché web y un índice de búsqueda. Debido a esta replicación de datos, los almacenes de datos deben mantenerse sincronizados.
Un enfoque tradicional para sincronizar datos en distintos sistemas de almacenamiento son los trabajos ETL periódicos. Sin embargo, no cumplen los requisitos de latencia para muchos de los casos de uso actuales. Una alternativa es utilizar un registro de eventos para distribuir las actualizaciones. El registro de eventos escribe y distribuye las actualizaciones. Los consumidores del registro incorporan las actualizaciones a los almacenes de datos afectados. Dependiendo del caso de uso, los datos transferidos pueden necesitar ser normalizados, enriquecidos con datos externos o agregados antes de ser ingeridos por el almacén de datos de destino.
Ingerir, transformar e insertar datos con baja latencia es otro caso de uso común para las aplicaciones de procesamiento de flujos con estado. Este tipo de aplicación se denomina canalización de datos. Las canalizaciones de datos deben ser capaces de procesar grandes cantidades de datos en poco tiempo. Un procesador de flujo que opere una canalización de datos también debe disponer de muchos conectores de origen y destino para leer y escribir datos en varios sistemas de almacenamiento. De nuevo, Flink hace todo esto.
Análisis de streaming
Trabajos ETL importan periódicamente datos a un almacén de datos y los datos se procesan mediante consultas ad hoc o programadas. Se trata de un procesamiento por lotes, independientemente de si la arquitectura se basa en un almacén de datos o en componentes del ecosistema Hadoop. Aunque la carga periódica de datos en un sistema de análisis de datos ha sido el estado del arte durante muchos años, añade una latencia considerable al canal de análisis.
Dependiendo de los intervalos de programación, pueden pasar horas o días hasta que un punto de datos se incluya en un informe. Hasta cierto punto, la latencia puede reducirse importando datos al almacén de datos con una aplicación de canalización de datos. Sin embargo, incluso con una ETL continua siempre habrá un retraso hasta que un evento sea procesado por una consulta. Aunque este tipo de retraso puede haber sido aceptable en el pasado, las aplicaciones actuales deben ser capaces de recopilar datos en tiempo real y actuar inmediatamente sobre ellos (por ejemplo, ajustándose a las condiciones cambiantes en un juego para móviles o personalizando las experiencias de usuario para un minorista online).
En lugar de esperar a ser activada periódicamente, una aplicación de análisis de flujo ingesta continuamente flujos de eventos y actualiza su resultado incorporando los últimos eventos con baja latencia. Esto es similar a las técnicas de mantenimiento que utilizan los sistemas de bases de datos para actualizar las vistas materializadas. Normalmente, las aplicaciones de streaming almacenan su resultado en un almacén de datos externo que admite actualizaciones eficientes, como una base de datos o un almacén de valores clave. Los resultados actualizados en directo de una aplicación analítica de streaming pueden utilizarse para alimentar aplicaciones de cuadros de mando, como se muestra en la Figura 1-6.
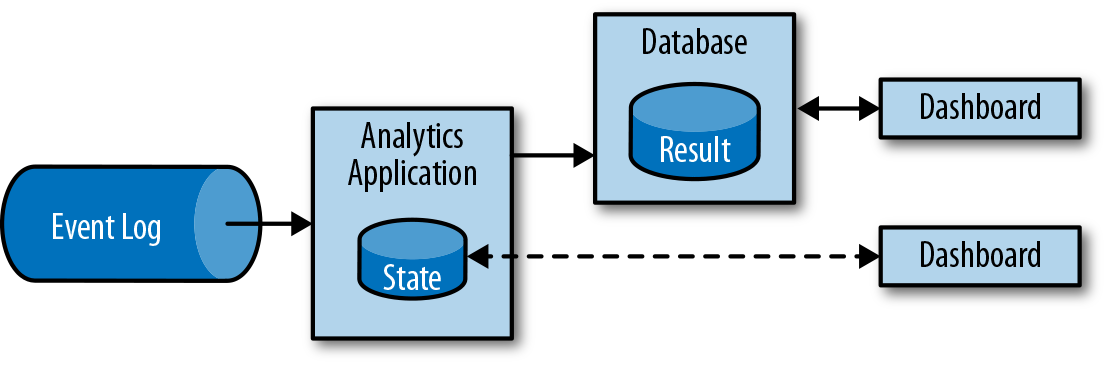
Figura 1-6. Una aplicación de análisis de flujo
Además del tiempo mucho más corto necesario para que un evento se incorpore a un resultado analítico, hay otra ventaja, menos obvia, de las aplicaciones analíticas de flujo. Los pipelines analíticos tradicionales constan de varios componentes individuales, como un proceso ETL, un sistema de almacenamiento y, en el caso de un entorno basado en Hadoop, un procesador de datos y un programador para lanzar trabajos o consultas. En cambio, un procesador de flujo que ejecuta una aplicación de flujo con estado se encarga de todos estos pasos de procesamiento, incluida la ingestión de eventos, el cálculo continuo, incluido el mantenimiento del estado, y la actualización de los resultados. Además, el procesador de flujo puede recuperarse de los fallos con garantías de coherencia de estado exactamente una vez y puede ajustar los recursos informáticos de una aplicación. Los procesadores de flujos como Flink también admiten el procesamiento en tiempo de eventos para producir resultados correctos y deterministas y la capacidad de procesar grandes cantidades de datos en poco tiempo.
Las aplicaciones analíticas de streaming se utilizan habitualmente para:
-
Monitoreo de la calidad de las redes de telefonía móvil
-
Analizar el comportamiento del usuario en aplicaciones móviles
-
Análisis ad hoc de datos en directo en tecnología de consumo
Aunque no lo cubrimos aquí, Flink también proporciona soporte para consultas SQL analíticas sobre flujos.
La evolución del procesamiento de flujos de código abierto
El procesamiento de flujos de datos no es una tecnología novedosa. Algunos de los primeros prototipos de investigación y productos comerciales se remontan a finales de los años 90. Sin embargo, la creciente adopción de la tecnología de procesamiento de flujos en los últimos tiempos se ha visto impulsada en gran medida por la disponibilidad de procesadores de flujos de código abierto maduros. Hoy en día, los procesadores de flujo distribuidos de código abierto alimentan aplicaciones críticas para el negocio en muchas empresas de distintos sectores, como el comercio minorista (online), las redes sociales, las telecomunicaciones, los juegos y la banca. El software de código abierto es uno de los principales impulsores de esta tendencia, principalmente por dos razones:
- El software de procesamiento de flujos de código abierto es un producto básico que todo el mundo puede evaluar y utilizar.
- La tecnología de procesamiento de flujos escalable está madurando y evolucionando rápidamente gracias a los esfuerzos de muchas comunidades de código abierto.
Sólo la Fundación del Software Apache alberga más de una docena de proyectos relacionados con el procesamiento de flujos. Nuevos proyectos de procesamiento distribuido de flujos entran continuamente en la escena del código abierto y desafían el estado del arte con nuevas características y capacidades. Las comunidades de código abierto mejoran constantemente las capacidades de sus proyectos y amplían los límites técnicos del procesamiento de flujos. Vamos a echar un breve vistazo al pasado para ver de dónde vino el procesamiento de flujos de código abierto y dónde está hoy.
Un poco de historia
La primera generación de procesadores de flujo distribuidos de código abierto (2011) se centraba en el procesamiento de eventos con latencias de milisegundos y ofrecía garantías contra la pérdida de eventos en caso de fallos. Estos sistemas tenían API de nivel más bien bajo y no proporcionaban soporte integrado para obtener resultados precisos y coherentes de las aplicaciones de flujo, porque los resultados dependían de la sincronización y el orden de llegada de los eventos. Además, aunque los eventos no se perdían, podían procesarse más de una vez. A diferencia de los procesadores por lotes, los primeros procesadores de flujo de código abierto cambiaban la precisión de los resultados por una mejor latencia. La observación de que los sistemas de procesamiento de datos (en ese momento) podían proporcionar resultados rápidos o precisos condujo al diseño de la llamada arquitectura lambda, que se representa en la Figura 1-7.
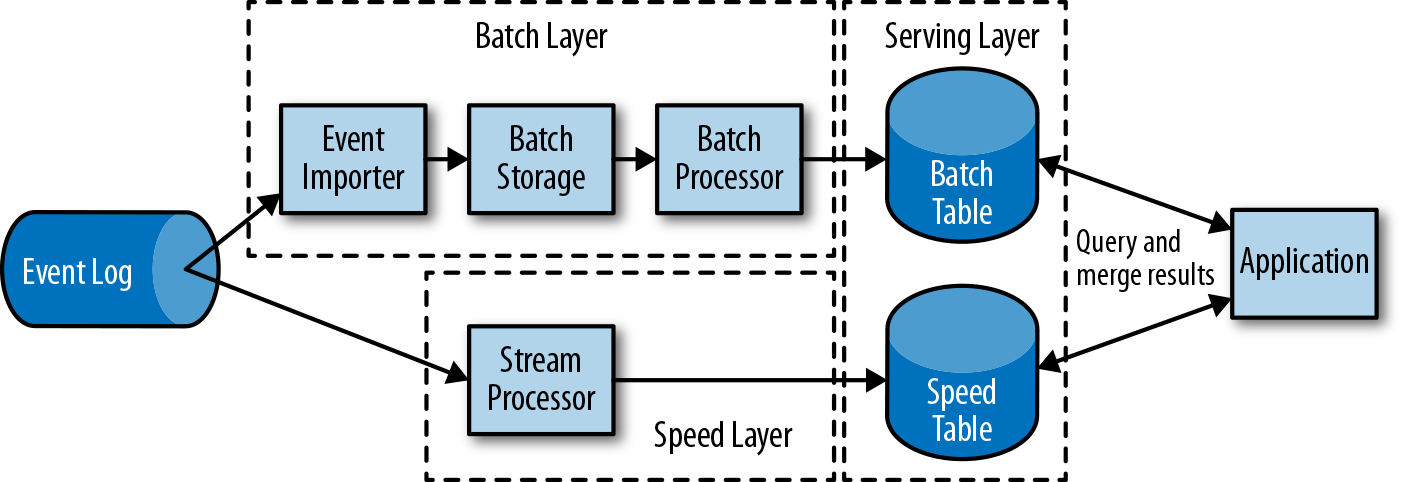
Figura 1-7. La arquitectura lambda
La arquitectura lambda aumenta la arquitectura tradicional de procesamiento periódico por lotes con una capa de velocidad alimentada por un procesador de flujo de baja latencia. Los datos que llegan a la arquitectura lambda son ingeridos por el procesador de flujo y también se escriben en el almacenamiento por lotes. El procesador de flujo calcula los resultados aproximados casi en tiempo real y los escribe en una tabla de velocidad. El procesador por lotes procesa periódicamente los datos en el almacenamiento por lotes, escribe los resultados exactos en una tabla por lotes y elimina los resultados inexactos correspondientes de la tabla de velocidad. Las aplicaciones consumen los resultados fusionando los resultados aproximados de la tabla de velocidad y los resultados exactos de la tabla de lotes.
La arquitectura lambda ya no es de última generación, pero se sigue utilizando en muchos sitios. Los objetivos originales de esta arquitectura eran mejorar la alta latencia de resultados de la arquitectura original de análisis por lotes. Sin embargo, tiene algunos inconvenientes notables. En primer lugar, requiere dos implementaciones semánticamente equivalentes de la lógica de aplicación para dos sistemas de procesamiento distintos con APIs diferentes. En segundo lugar, los resultados calculados por el procesador de flujo son sólo aproximados. En tercer lugar, la arquitectura lambda es difícil de configurar y mantener.
Mejorando la primera generación, la siguiente generación de procesadores de flujo distribuidos de código abierto (2013) proporcionó mejores garantías de fallo y aseguró que, en caso de fallo, cada registro de entrada afecta al resultado exactamente una vez. Además, las API de programación evolucionaron de interfaces de operador de nivel más bien bajo a API de alto nivel con más primitivas incorporadas. Sin embargo, algunas mejoras, como un mayor rendimiento y mejores garantías de fallo, se produjeron a costa de aumentar las latencias de procesamiento de milisegundos a segundos. Además, los resultados seguían dependiendo de la sincronización y el orden de llegada de los eventos.
La tercera generación de procesadores de flujo distribuidos de código abierto (2015) abordó la dependencia de los resultados del momento y el orden de llegada de los eventos. En combinación con la semántica de fallo exactamente una vez, los sistemas de esta generación son los primeros procesadores de flujo de código abierto capaces de calcular resultados coherentes y precisos. Al calcular únicamente resultados basados en datos reales, estos sistemas también son capaces de procesar datos históricos del mismo modo que los datos "en vivo". Otra mejora fue la disolución del equilibrio entre latencia y rendimiento. Mientras que los procesadores de flujo anteriores sólo proporcionaban un alto rendimiento o una baja latencia, los sistemas de la tercera generación pueden servir a ambos extremos del espectro. Los procesadores de flujo de esta generación han dejado obsoleta la arquitectura lambda.
Además de las propiedades del sistema comentadas hasta ahora, como la tolerancia a fallos, el rendimiento y la precisión de los resultados, los procesadores de flujo también han añadido continuamente nuevas características operativas, como configuraciones de alta disponibilidad, una estrecha integración con gestores de recursos, como YARN o Kubernetes, y la capacidad de escalar dinámicamente las aplicaciones de flujo. Otras características incluyen el soporte para actualizar el código de la aplicación o migrar un trabajo a un clúster diferente o a una nueva versión del procesador de flujo sin perder el estado actual.
Un vistazo rápido a Flink
Apache Flink es un procesador de flujo distribuido de tercera generación con un conjunto de características competitivas. Proporciona un procesamiento de flujos preciso con alto rendimiento y baja latencia a escala. En concreto, Flink destaca por las siguientes características:
-
Semántica en tiempo de sucesos y en tiempo de procesamiento. La semántica en tiempo de evento proporciona resultados coherentes y precisos a pesar de que los eventos estén fuera de orden. La semántica en tiempo de procesamiento puede utilizarse para aplicaciones con requisitos de latencia muy bajos.
-
Garantías de coherencia de estado exactamente una vez.
-
Latencias de milisegundos mientras se procesan millones de eventos por segundo. Las aplicaciones Flink pueden escalarse para ejecutarse en miles de núcleos.
-
API por capas con distintas compensaciones en cuanto a expresividad y facilidad de uso. Este libro cubre la API DataStream y las funciones de proceso, que proporcionan primitivas para operaciones comunes de procesamiento de flujos, como ventanas y operaciones asíncronas, e interfaces para controlar con precisión el estado y el tiempo. Las API relacionales de Flink, SQL y la API de tablas de estilo LINQ, no se tratan en este libro.
-
Conectores a los sistemas de almacenamiento más utilizados, como Apache Kafka, Apache Cassandra, Elasticsearch, JDBC, Kinesis, y sistemas de archivos (distribuidos) como HDFS y S3.
-
Capacidad para ejecutar aplicaciones de streaming 24 horas al día, 7 días a la semana, con muy poco tiempo de inactividad gracias a su configuración de alta disponibilidad (sin un único punto de fallo), su estrecha integración con Kubernetes, YARN y Apache Mesos, su rápida recuperación ante fallos y su capacidad para escalar dinámicamente los trabajos.
-
Capacidad para actualizar el código de aplicación de los trabajos y migrar trabajos a diferentes clusters Flink sin perder el estado de la aplicación.
-
Recopilación detallada y personalizable de métricas del sistema y de la aplicación para identificar los problemas y reaccionar ante ellos con antelación.
-
Por último, pero no por ello menos importante, Flink también es un procesador por lotes en toda regla.1
Además de estas características, Flink es un marco de trabajo muy fácil de usar para los desarrolladores, gracias a sus API fáciles de usar. El modo de ejecución incrustado inicia una aplicación y todo el sistema Flink en un único proceso JVM, que puede utilizarse para ejecutar y depurar trabajos Flink dentro de un IDE. Esta función resulta muy útil a la hora de desarrollar y probar aplicaciones Flink.
Ejecutar tu primera aplicación Flink
En a continuación, te guiaremos por el proceso de iniciar un clúster local y ejecutar una aplicación de streaming para darte un primer vistazo a Flink. La aplicación que vamos a ejecutar convierte y agrega lecturas de sensores de temperatura generadas aleatoriamente por tiempo. Para este ejemplo, tu sistema necesita tener instalado Java 8. Describimos los pasos para un entorno UNIX, pero si utilizas Windows, te recomendamos que configures una máquina virtual con Linux, Cygwin (un entorno Linux para Windows) o el Subsistema Windows para Linux, introducido con Windows 10. Los siguientes pasos te muestran cómo iniciar un clúster Flink local y enviar una aplicación para su ejecución.
-
Ve a la página web de Apache Flink y descarga la distribución binaria sin Hadoop de Apache Flink 1.7.1 para Scala 2.12.
-
Extrae el archivo comprimido:
$ tar xvfz flink-1.7.1-bin-scala_2.12.tgz
-
Inicia un clúster Flink local:
$ cd flink-1.7.1 $ ./bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host xxx. Starting taskexecutor daemon on host xxx.
-
Abre la interfaz web de Flink introduciendo la URL
http://localhost:8081en tu navegador. Como se muestra en la Figura 1-8, verás algunas estadísticas sobre el clúster local de Flink que acabas de iniciar. Mostrará que hay conectado un único TaskManager (procesos de trabajo de Flink) y que hay disponible una única ranura de tarea (unidades de recursos proporcionadas por un TaskManager).
Figura 1-8. Captura de pantalla del panel web de Apache Flink mostrando la vista general
-
Descarga el archivo JAR que incluye los ejemplos de este libro:
$ wget https://streaming-with-flink.github.io/\ examples/download/examples-scala.jar
Nota
También puedes construir tú mismo el archivo JAR siguiendo los pasos del archivo README del repositorio.
-
Ejecuta el ejemplo en tu clúster local especificando la clase de entrada de la aplicación y el archivo JAR:
$ ./bin/flink run \ -c io.github.streamingwithflink.chapter1.AverageSensorReadings \ examples-scala.jar Starting execution of program Job has been submitted with JobID cfde9dbe315ce162444c475a08cf93d9
-
Inspecciona el panel web. Deberías ver un trabajo listado en "Trabajos en ejecución". Si haces clic en ese trabajo, verás el flujo de datos y las métricas en tiempo real sobre los operadores del trabajo en ejecución, de forma similar a la captura de pantalla de la Figura 1-9.
Figura 1-9. Captura de pantalla del panel web de Apache Flink mostrando un trabajo en ejecución
-
La salida del trabajo se escribe en la salida estándar del proceso trabajador de Flink, que se redirige a un archivo de la carpeta ./log por defecto. Puedes monitorizar la salida producida constantemente utilizando el comando
tailde la siguiente manera:$ tail -f ./log/flink-<user>-taskexecutor-<n>-<hostname>.out
Deberías ver que se escriben líneas como ésta en el archivo:
SensorReading(sensor_1,1547718199000,35.80018327300259) SensorReading(sensor_6,1547718199000,15.402984393403084) SensorReading(sensor_7,1547718199000,6.720945201171228) SensorReading(sensor_10,1547718199000,38.101067604893444)
El primer campo del
SensorReadinges unsensorId, el segundo campo es la marca de tiempo en milisegundos desde1970-01-01-00:00:00.000, y el tercer campo es una temperatura media calculada en 5 segundos. -
Como estás ejecutando una aplicación de streaming, la aplicación seguirá ejecutándose hasta que la canceles. Puedes hacerlo seleccionando el trabajo en el panel web y pulsando el botón Cancelar en la parte superior de la página.
-
Por último, debes detener el clúster Flink local:
$ ./bin/stop-cluster.sh
Ya está. ¡Acabas de instalar y poner en marcha tu primer clúster local de Flink y de ejecutar tu primer programa de la API Flink DataStream! Por supuesto, hay mucho más que aprender sobre el procesamiento de flujos con Apache Flink y de eso trata este libro.
Resumen
En este capítulo, hemos presentado el procesamiento de flujos con estado, hemos hablado de sus casos de uso y hemos echado un primer vistazo a Apache Flink. Comenzamos con una recapitulación de las infraestructuras de datos tradicionales, cómo se diseñan habitualmente las aplicaciones empresariales y cómo se recopilan y analizan los datos en la mayoría de las empresas actuales. A continuación, introdujimos la idea del procesamiento de flujos con estado y explicamos cómo aborda un amplio espectro de casos de uso, desde aplicaciones empresariales y microservicios hasta ETL y análisis de datos. Discutimos cómo han evolucionado los sistemas de procesamiento de flujos de código abierto desde su creación a principios de la década de 2010 y cómo el procesamiento de flujos se convirtió en una solución viable para muchos casos de uso de las empresas actuales. Por último, echamos un vistazo a Apache Flink y a las amplias funciones que ofrece, y mostramos cómo instalar una configuración local de Flink y ejecutar una primera aplicación de procesamiento de flujos.
1 La API de procesamiento por lotes de Flink, la API DataSet, y sus operadores son independientes de sus correspondientes homólogos de flujo. Sin embargo, la visión de la comunidad Flink es tratar el procesamiento por lotes como un caso especial del procesamiento de flujos: el procesamiento de flujos acotados. Un esfuerzo continuo de la comunidad Flink es hacer evolucionar Flink hacia un sistema con una API y un tiempo de ejecución de procesamiento por lotes y de flujo realmente unificados.
Get Procesamiento de flujos con Apache Flink now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

