Kapitel 1. Zeitreihen: Ein Überblick und eine kurze Geschichte
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Zeitreihendaten und ihre Analyse werden immer wichtiger, da sie beispielsweise durch das Internet der Dinge, die Digitalisierung des Gesundheitswesens und den Aufstieg der Smart Cities in großem Umfang produziert werden. In den kommenden Jahren werden Menge, Qualität und Bedeutung von Zeitreihendaten rasant zunehmen.
Da die kontinuierliche Überwachung und Datenerfassung immer weiter verbreitet ist, wird der Bedarf an kompetenter Zeitreihenanalyse mit statistischen und maschinellen Lernverfahren steigen. Die vielversprechendsten neuen Modelle kombinieren sogar beide Methoden. Aus diesem Grund werden wir beide ausführlich besprechen. Wir werden ein breites Spektrum an Zeitreihentechniken untersuchen und anwenden, die für die Analyse und Vorhersage von menschlichem Verhalten, wissenschaftlichen Phänomenen und Daten aus dem Privatsektor nützlich sind, da alle diese Bereiche eine Vielzahl von Zeitreihendaten bieten.
Beginnen wir mit einer Definition. Bei der Zeitreihenanalyse geht es darum, aus chronologisch angeordneten Punkten aussagekräftige zusammenfassende und statistische Informationen zu extrahieren. Sie wird durchgeführt, um vergangenes Verhalten zu diagnostizieren und zukünftiges Verhalten vorherzusagen. In diesem Buch werden wir eine Vielzahl von Ansätzen verwenden, die von hundert Jahre alten statistischen Modellen bis hin zu neu entwickelten neuronalen Netzwerkarchitekturen reichen.
Keine der Techniken hat sich in einem Vakuum oder aus rein theoretischem Interesse heraus entwickelt. Innovationen in der Zeitreihenanalyse ergeben sich aus neuen Möglichkeiten der Datenerfassung, -aufzeichnung und -visualisierung. Im Folgenden gehen wir kurz auf die Entstehung der Zeitreihenanalyse in einer Vielzahl von Anwendungen ein.
Die Geschichte der Zeitreihen in verschiedenen Anwendungen
Die Zeitreihenanalyse läuft oft auf die Frage nach der Kausalität hinaus: Wie hat die Vergangenheit die Zukunft beeinflusst? Manchmal werden solche Fragen (und ihre Antworten) streng innerhalb der eigenen Disziplin behandelt und nicht als Teil der allgemeinen Disziplin der Zeitreihenanalyse. Infolgedessen haben eine Reihe von Disziplinen neue Denkansätze für Zeitreihendaten geliefert.
In diesem Abschnitt geben wir einen Überblick über einige historische Beispiele für Zeitreihendaten und -analysen in diesen Disziplinen:
-
Medizin
-
Wetter
-
Wirtschaft
-
Astronomie
Wie wir sehen werden, waren das Tempo der Entwicklung in diesen Disziplinen und die Beiträge, die in jedem Bereich entstanden, stark von der Art der gleichzeitig verfügbaren Zeitreihendaten abhängig.
Medizin als Zeitreihenproblem
Die Medizin ist ein datengesteuerter Bereich, der schon seit einigen Jahrhunderten interessante Zeitreihenanalysen zum menschlichen Wissen beiträgt. Schauen wir uns nun ein paar Beispiele für Zeitreihendatenquellen in der Medizin an und wie sie sich im Laufe der Zeit entwickelt haben.
Die Medizin hat erstaunlich langsam begonnen, über die Mathematik der Zukunftsvorhersage nachzudenken, obwohl Prognosen ein wesentlicher Bestandteil der medizinischen Praxis sind. Das hat viele Gründe. Statistik und eine wahrscheinlichkeitstheoretische Denkweise über die Welt sind neuere Phänomene, und diese Disziplinen standen viele Jahrhunderte lang nicht zur Verfügung, selbst als sich die medizinische Praxis entwickelte. Außerdem praktizierten die meisten Ärztinnen und Ärzte in Isolation, ohne einfache berufliche Kommunikation und ohne eine formale Infrastruktur für die Aufzeichnung von Patienten- oder Bevölkerungsdaten. Selbst wenn Ärztinnen und Ärzte in früheren Zeiten in statistischem Denken geschult worden wären, hätten sie daher wahrscheinlich keine vernünftigen Daten gehabt, aus denen sie ihre Schlüsse hätten ziehen können.
Damit will ich keineswegs die frühen Ärzte kritisieren, sondern erklären, warum es nicht allzu überraschend ist, dass eine der ersten Zeitreihen-Innovationen in der Bevölkerungsgesundheit von einem Hutverkäufer und nicht von einem Arzt stammt. Wenn du darüber nachdenkst, macht das Sinn: In früheren Jahrhunderten hatte ein städtischer Hutverkäufer wahrscheinlich mehr Übung im Führen von Aufzeichnungen und in der Kunst, Trends zu erkennen, als ein Arzt.
Der Erfinder war John Graunt, ein Londoner Kurzwarenhändler aus dem 17. Jahrhundert. Graunt untersuchte die Sterberegister, die in den Londoner Kirchengemeinden seit den frühen 1500er Jahren geführt wurden. Auf diese Weise begründete er die Disziplin der Demografie. Im Jahr 1662 veröffentlichte er Natural and Political Observations . . . Made upon the Bills of Mortality (siehe Abbildung 1-1).

Abbildung 1-1. Die versicherungsmathematischen Tabellen von John Graunt waren eines der ersten Ergebnisse des zeitreihenbasierten Denkens, das auf medizinische Fragen angewandt wurde. Quelle: Wikipedia.
In diesem Buch stellte Graunt die ersten Lebenstafeln vor, die du vielleicht als versicherungsmathematische Tafeln kennst. Diese Tabellen zeigen die Wahrscheinlichkeit, dass eine Person eines bestimmten Alters vor ihrem nächsten Geburtstag stirbt. Graunt war der erste, von dem bekannt ist, dass er Lebenstafeln formuliert und veröffentlicht hat, und er war auch der erste dokumentierte Statistiker der menschlichen Gesundheit. Seine Lebenszeittabellen sahen in etwa so aus wie Tabelle 1-1, die aus einem Statistikkurs der Rice University stammt.
| Alter | Anteil der Todesfälle im Intervall | Anteil der Überlebenden bis zum Beginn des Intervalls |
|---|---|---|
| 0-6 | 0.36 | 1.0 |
| 7-16 | 0.24 | 0.64 |
| 17-26 | 0.15 | 0.40 |
| 27-36 | 0.09 | 0.25 |
Leider setzte sich Graunts Art, mathematisch über das menschliche Überleben nachzudenken, nicht durch. Eine stärker vernetzte und datengesteuerte Welt begann sich zu entwickeln - mit Nationalstaaten, Akkreditierung, Fachgesellschaften, wissenschaftlichen Zeitschriften und, viel später, staatlich vorgeschriebenen Gesundheitsaufzeichnungen -, aber die Medizin konzentrierte sich weiterhin auf Physiologie und nicht auf Statistik.
Dafür gab es verständliche Gründe. Erstens hatte das Studium der Anatomie und Physiologie an einer kleinen Zahl von Probanden jahrhundertelang die größten Fortschritte in der Medizin gebracht, und die meisten Menschen (auch Wissenschaftler) halten sich so lange wie möglich an das, was für sie funktioniert. Solange der Fokus auf die Physiologie so erfolgreich war, gab es keinen Grund, weiter zu schauen. Zweitens gab es kaum eine Infrastruktur für die Berichterstattung, die es Ärzten ermöglicht hätte, Informationen in einem Umfang zu erfassen und auszutauschen, der statistische Methoden den klinischen Beobachtungen überlegen gemacht hätte.
Die Zeitreihenanalyse hat sich in der Medizin noch langsamer durchgesetzt als andere Bereiche der Statistik und Datenanalyse, wahrscheinlich weil die Zeitreihenanalyse höhere Anforderungen an die Aufzeichnungssysteme stellt. Die Aufzeichnungen müssen im Laufe der Zeit miteinander verknüpft und möglichst in regelmäßigen Abständen erhoben werden. Aus diesem Grund hat sich die Zeitreihenanalyse in der Epidemiologie erst in jüngster Zeit und schrittweise durchgesetzt, nachdem eine ausreichende staatliche und wissenschaftliche Infrastruktur vorhanden war, um eine einigermaßen gute und lange zeitliche Erfassung zu gewährleisten.
Auch die individualisierte Gesundheitsfürsorge mit Hilfe von Zeitreihenanalysen ist noch ein junges und schwieriges Feld, weil es ziemlich schwierig sein kann, Datensätze zu erstellen, die im Laufe der Zeit konsistent sind. Selbst bei kleinen, auf Fallstudien basierenden Untersuchungen ist es äußerst schwierig und teuer, den Kontakt zu einer Gruppe von Personen aufrechtzuerhalten und deren Teilnahme zu gewährleisten. Wenn solche Studien über einen langen Zeitraum durchgeführt werden, werden sie in ihrem Bereich oft zum Kanon - und immer wieder oder sogar übermäßig erforscht -, weil ihre Daten trotz der Herausforderungen bei der Finanzierung und Verwaltung wichtige Fragen beantworten können.1
Medizinische Instrumente
Die Zeitreihenanalyse für einzelne Patienten hat eine viel frühere und erfolgreichere Geschichte als die der Gesundheitsstudien auf Bevölkerungsebene. Die Zeitreihenanalyse hielt Einzug in die Medizin, als 1901 die ersten praktischen Elektrokardiogramme (EKGs) erfunden wurden, mit denen Herzkrankheiten durch die Aufzeichnung der elektrischen Signale, die das Herz durchlaufen, diagnostiziert werden können (siehe Abbildung 1-2). Ein weiteres Zeitreihengerät, das Elektroenzephalogramm (EEG), das nichtinvasiv elektrische Impulse im Gehirn misst, wurde 1924 in der Medizin eingeführt und eröffnete Medizinern weitere Möglichkeiten, die Zeitreihenanalyse für die medizinische Diagnose einzusetzen (siehe Abbildung 1-3).
Beide Maschinen waren Teil eines größeren Trends zur Verbesserung der Medizin mit wiederverwendeten Ideen und Technologien, die aus der zweiten industriellen Revolution stammen.
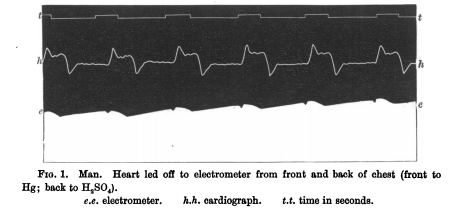
Abbildung 1-2. Eine frühe EKG-Aufzeichnung aus der Originalarbeit von Augustus D. Waller, M.D., "A Demonstration on Man of Electromotive Changes Accompanying the Heart's Beat" von 1877 . Die ersten EKGs waren schwierig zu konstruieren und anzuwenden, so dass es noch einige Jahrzehnte dauerte, bis sie zu einem praktischen Hilfsmittel für Ärzte wurden.

Abbildung 1-3. Die erste menschliche EEG-Aufzeichnung aus dem Jahr 1924. Quelle: Wikipedia.
Die Klassifizierung von EKG- und EEG-Zeitreihen ist nach wie vor ein aktives Forschungsgebiet für sehr praktische Zwecke, z. B. zur Einschätzung des Risikos einer plötzlichen Herzkrise oder eines Krampfanfalls. Diese Messungen sind reichhaltige Datenquellen, aber ein "Problem" mit solchen Daten ist, dass sie in der Regel nur für Patienten mit bestimmten Erkrankungen verfügbar sind. Diese Maschinen erzeugen keine langfristigen Zeitreihen, die uns mehr über die Gesundheit und das Verhalten der Menschen verraten, denn ihre Messungen werden selten über lange Zeiträume oder vor dem Auftreten einer Krankheit bei einem Patienten durchgeführt.
Aus Sicht der Datenanalyse haben wir glücklicherweise die Zeiten hinter uns gelassen, in denen EKGs und Ähnliches die wichtigsten medizinischen Zeitreihen waren. Mit dem Aufkommen tragbarer Sensoren und "intelligenter" elektronischer medizinischer Geräte führen viele gesunde Menschen Routinemessungen automatisch oder mit minimalen manuellen Eingaben durch, was zu einer kontinuierlichen Sammlung guter Längsschnittdaten sowohl über kranke als auch über gesunde Menschen führt. Dies steht im krassen Gegensatz zu den medizinischen Zeitreihendaten des letzten Jahrhunderts, die fast ausschließlich bei kranken Menschen gemessen wurden und nur sehr begrenzt zugänglich waren.
Wie die jüngste Berichterstattung gezeigt hat, drängen eine Reihe von nicht-traditionellen Akteuren in den medizinischen Bereich, von riesigen Social-Media-Unternehmen über Finanzinstitute bis hin zu Einzelhandelsriesen.2 Sie alle planen wahrscheinlich, große Datensätze zu nutzen, um das Gesundheitswesen zu optimieren. Es gibt nicht nur neue Akteure im Gesundheitsbereich, sondern auch neue Techniken. Die personalisierte, DNA-gesteuerte Medizin bedeutet, dass Zeitreihendaten zunehmend gemessen und ausgewertet werden. Dank der wachsenden modernen Datensätze im Gesundheitswesen werden sich sowohl das Gesundheitswesen als auch die Zeitreihenanalyse in den kommenden Jahren wahrscheinlich weiterentwickeln, insbesondere als Reaktion auf die lukrativen Datensätze des Gesundheitssektors. Hoffentlich wird dies so geschehen, dass Zeitreihen für alle von Nutzen sind.
Wettervorhersage
Es liegt auf der Hand, dass die Vorhersage des Wetters viele Menschen schon immer beschäftigt hat. Der antike griechische Philosoph Aristoteles beschäftigte sich in einer ganzen Abhandlung(Meteorologie) mit dem Wetter, und seine Ideen über die Ursachen und Abläufe des Wetters blieben bis zur Renaissance vorherrschend. Zu dieser Zeit begannen Wissenschaftler, mit Hilfe neu erfundener Instrumente wie dem Barometer wetterbezogene Daten zu sammeln, um den Zustand der Atmosphäre zu messen. Sie nutzten diese Instrumente, um Zeitreihen in täglichen oder sogar stündlichen Abständen aufzuzeichnen. Die Aufzeichnungen wurden an verschiedenen Orten aufbewahrt, z. B. in privaten Tagebüchern und Logbüchern der Städte. Über Jahrhunderte hinweg war dies die einzige Art und Weise, wie die westliche Zivilisation das Wetter beobachtete.
Eine stärkere Formalisierung und Infrastruktur für Wetteraufzeichnungen kam in den 1850er Jahren, als Robert FitzRoy zum Leiter einer neuen britischen Regierungsabteilung ernannt wurde, die wetterbezogene Daten für Seeleute aufzeichnen und veröffentlichen sollte.3 FitzRoy prägte den Begriff Wettervorhersage. Damals wurde er für die Qualität seiner Vorhersagen kritisiert, aber heute gilt er als seiner Zeit weit voraus, was die Wissenschaft angeht, mit der er sie entwickelte. Er führte den Brauch ein, Wettervorhersagen in der Zeitung abzudrucken; sie waren die ersten Vorhersagen, die in der Londoner Times abgedruckt wurden. FitzRoy wird heute als der "Vater der Vorhersage" gefeiert.
Im späten 19. Jahrhundert - Hunderte von Jahren nach der Einführung vieler atmosphärischer Messungen - ermöglichte der Telegraf die schnelle Zusammenstellung von atmosphärischen Bedingungen in Zeitreihen von vielen verschiedenen Orten. Diese Praxis wurde in den 1870er Jahren in vielen Teilen der Welt zum Standard und führte zur Erstellung der ersten aussagekräftigen Datensätze für die Vorhersage des lokalen Wetters auf der Grundlage von Ereignissen an anderen geografischen Orten.
Um die Jahrhundertwende zum 20. Jahrhundert wurde die Idee, das Wetter mit Hilfe von Berechnungsmethoden vorherzusagen, mit Nachdruck verfolgt. Die ersten Versuche, das Wetter zu berechnen, erforderten einen spektakulären Aufwand, lieferten aber schlechte Ergebnisse. Physiker und Chemiker hatten zwar bewährte Vorstellungen von den relevanten Naturgesetzen, aber es gab zu viele Naturgesetze, die man nicht alle auf einmal anwenden konnte. Das daraus resultierende Gleichungssystem war so komplex, dass es ein bemerkenswerter wissenschaftlicher Durchbruch war, als jemand zum ersten Mal versuchte, die Berechnungen durchzuführen.
Es folgten mehrere Jahrzehnte der Forschung, um die physikalischen Gleichungen so zu vereinfachen, dass die Genauigkeit und die Effizienz der Berechnungen erhöht wurden. Diese Tricks wurden bis zu den aktuellen Wettervorhersagemodellen weitergegeben, die mit einer Mischung aus bekannten physikalischen Prinzipien und bewährten Heuristiken arbeiten.
Heutzutage führen viele Regierungen sehr detaillierte Wettermessungen von Hunderten oder sogar Tausenden von Wetterstationen auf der ganzen Welt durch, und diese Vorhersagen stützen sich auf Daten mit genauen Informationen über die Standorte und Ausrüstung der Wetterstationen. Die Wurzeln dieser Bemühungen gehen auf die koordinierten Datensätze der 1870er Jahre zurück und sogar noch früher auf die Praxis der Renaissance, lokale Wettertagebücher zu führen.
Leider ist die Wettervorhersage ein Beispiel für die zunehmenden Angriffe auf die Wissenschaft, die sogar bis in den Bereich der Zeitreihenvorhersage reichen. Nicht nur die Zeitreihendebatten über die globalen Temperaturen wurden politisiert, sondern auch banalere Zeitreihenvorhersagen wie die Vorhersage des Verlaufs eines Hurrikans.
Vorhersage des Wirtschaftswachstums
Indikatoren für die Produktion und die Effizienz von Märkten liefern seit langem interessante Daten, die mit Hilfe einer Zeitreihenanalyse untersucht werden können. Am interessantesten und dringlichsten ist die Frage, wie man auf der Grundlage der Vergangenheit künftige wirtschaftliche Entwicklungen vorhersagen kann. Solche Prognosen sind nicht nur nützlich, um Geld zu verdienen - sie helfen auch, den Wohlstand zu fördern und soziale Katastrophen abzuwenden. Im Folgenden werden einige wichtige Entwicklungen in der Geschichte der Wirtschaftsprognose erläutert.
Wirtschaftsprognosen entstanden aus der Angst, die durch episodische Bankenkrisen in den Vereinigten Staaten und Europa im späten 19. und frühen 20. Damals ließen sich Unternehmer und Forscher gleichermaßen von der Idee inspirieren, dass die Wirtschaft mit einem zyklischen System verglichen werden kann, so wie man dachte, dass sich das Wetter verhält. Mit den richtigen Messungen, so dachte man, ließen sich Vorhersagen treffen und Zusammenbrüche abwenden.
Sogar die Sprache der frühen Wirtschaftsprognosen spiegelte die Sprache der Wettervorhersage wider. Das war ungewollt treffend. Zu Beginn des 20. Jahrhunderts waren sich Wirtschafts- und Wettervorhersagen in der Tat ähnlich: Beide waren ziemlich schrecklich. Aber die Bestrebungen der Ökonomen schufen ein Umfeld, in dem man zumindest auf Fortschritte hoffen konnte, und so wurden verschiedene öffentliche und private Einrichtungen zur Beobachtung von Wirtschaftsdaten gegründet. Frühe Bemühungen um Wirtschaftsprognosen führten zur Entwicklung von Wirtschaftsindikatoren und tabellarischen, öffentlich zugänglichen Übersichten über diese Indikatoren, die auch heute noch verwendet werden. Einige davon werden wir auch in diesem Buch verwenden.
Heutzutage gibt es in den Vereinigten Staaten und den meisten anderen Ländern Tausende von staatlichen Forschern und Aufzeichnern, deren Aufgabe es ist, Daten so genau wie möglich zu erfassen und sie der Öffentlichkeit zur Verfügung zu stellen (siehe Abbildung 1-4). Diese Praxis hat sich als unschätzbar wertvoll für das Wirtschaftswachstum und die Vermeidung von Wirtschaftskatastrophen und schmerzhaften Boom- und Bust-Zyklen erwiesen. Darüber hinaus profitieren die Unternehmen von einer datenreichen Atmosphäre, da diese öffentlichen Datensätze es Verkehrsanbietern, Herstellern, Kleinunternehmern und sogar Landwirten ermöglichen, zukünftige Marktbedingungen zu antizipieren. Das alles entstand aus dem Versuch, "Konjunkturzyklen" zu identifizieren, die als Ursache für zyklische Bankenzusammenbrüche vermutet wurden - eine frühe Form der Zeitreihenanalyse in der Wirtschaft.
Abbildung 1-4. Die US-Bundesregierung finanziert viele Regierungsbehörden und damit verbundene gemeinnützige Organisationen, die lebenswichtige Statistiken erfassen und Wirtschaftsindikatoren formulieren. Quelle: National Bureau of Economic Research.
Viele der von der Regierung erhobenen Wirtschaftsdaten, vor allem die wichtigsten, sind ein Indikator für das wirtschaftliche Wohlergehen der Bevölkerung insgesamt. Ein Beispiel für solche wichtigen Informationen ist die Zahl der Menschen, die Arbeitslosengeld beantragen. Weitere Beispiele sind die Schätzungen der Regierung zum Bruttoinlandsprodukt und zu den gesamten Steuereinnahmen eines Jahres.
Dank dieses Wunsches nach Wirtschaftsprognosen wurde die Regierung zu einem Kurator von Daten und einem Steuereintreiber. Das Sammeln dieser Daten hat die moderne Wirtschaft, die moderne Finanzindustrie und die Datenwissenschaft im Allgemeinen zum Blühen gebracht. Dank der Zeitreihenanalyse, die sich aus wirtschaftlichen Fragestellungen entwickelt hat, können wir heute viel mehr Banken- und Finanzkrisen sicher abwenden, als es einer Regierung in den vergangenen Jahrhunderten möglich gewesen wäre. Außerdem wurden Hunderte von Zeitreihenlehrbüchern in Form von Wirtschaftslehrbüchern geschrieben, die sich mit dem Verständnis der Rhythmen dieser Finanzindikatoren beschäftigen.
Handelsmärkte
Kommen wir zurück auf die historische Seite der Dinge. Da die staatlichen Bemühungen um die Datenerfassung sehr erfolgreich waren, begannen private Organisationen, die staatlichen Aufzeichnungen zu kopieren. Mit der Zeit wurden die Rohstoff- und Aktienbörsen immer technischer. Auch Finanzalmanache wurden immer beliebter. Dies geschah zum einen, weil die Marktteilnehmer anspruchsvoller wurden, und zum anderen, weil neue Technologien eine stärkere Automatisierung und neue Wege des Wettbewerbs und des Denkens über Preise ermöglichten.
All diese winzigen Aufzeichnungen führten zu dem Bestreben, an den Märkten mit Mathematik statt mit Intuition Geld zu verdienen, und zwar auf eine Art und Weise, die vollständig von Statistiken (und in jüngerer Zeit von maschinellem Lernen) bestimmt wird. Die frühen Pioniere erledigten diese mathematische Arbeit von Hand, während die heutigen "Quants" dies mit sehr komplizierten und proprietären Methoden der Zeitreihenanalyse tun.
Einer der Pioniere des mechanischen Handels, also der Zeitreihenprognose per Algorithmus, war Richard Dennis. Dennis war ein Selfmade-Millionär, der gewöhnliche Menschen, die sogenannten Turtles, zu Star-Tradern machte, indem er ihnen ein paar ausgewählte Regeln beibrachte, wie und wann sie handeln sollten. Diese Regeln wurden in den 1970er und 1980er Jahren entwickelt und spiegelten das "KI"-Denken der 1980er Jahre wider, in denen Heuristiken noch stark das Paradigma beherrschten, wie man intelligente Maschinen baut, die in der realen Welt funktionieren.
Seitdem haben viele "mechanische" Händler diese Regeln angepasst, was dazu geführt hat, dass sie in einem überfüllten automatisierten Markt weniger profitabel geworden sind. Mechanische Händler werden immer zahlreicher und reicher und sind ständig auf der Suche nach der nächstbesten Lösung, weil es so viel Konkurrenz gibt.
Astronomie
Die Astronomie hat sich schon immer stark auf die Aufzeichnung von Objekten, Flugbahnen und Messungen im Zeitverlauf verlassen. Aus diesem Grund sind Astronomen Meister der Zeitreihen, sowohl für die Kalibrierung von Instrumenten als auch für die Untersuchung der Objekte, die sie interessieren. Ein Beispiel für die lange Geschichte von Zeitreihendaten ist die Aufzeichnung von Zeitreihen über Sonnenflecken im alten China bereits 800 v. Chr. Damit ist die Erfassung von Sonnenfleckendaten eines der am besten aufgezeichneten Naturphänomene überhaupt.
Einige der aufregendsten astronomischen Erkenntnisse des letzten Jahrhunderts beziehen sich auf die Zeitreihenanalyse. Die Entdeckung veränderlicher Sterne (aus denen sich galaktische Entfernungen ableiten lassen) und die Beobachtung vorübergehender Ereignisse wie Supernovae (die unser Verständnis davon verbessern, wie sich das Universum im Laufe der Zeit verändert) sind das Ergebnis der Überwachung von Live-Streams von Zeitreihendaten, die auf den Wellenlängen und Intensitäten von Licht basieren. Zeitreihen haben einen grundlegenden Einfluss darauf, was wir über das Universum wissen und messen können.
Übrigens hat diese Überwachung astronomischer Bilder den Astronomen sogar ermöglicht, Ereignisse einzufangen, wenn sie gerade stattfinden (oder besser gesagt, wenn wir sie beobachten können, was Millionen von Jahren dauern kann).
In den letzten Jahrzehnten ist die Verfügbarkeit von Daten mit Zeitstempeln in Form von formalen Zeitreihen in der Astronomie explodiert, da eine Vielzahl neuer Teleskope alle Arten von Himmelsdaten sammelt. Einige Astronomen haben sogar von einer "Datenflut" gesprochen, die aus Zeitreihen besteht.
Die Zeitreihenanalyse nimmt Fahrt auf
George Box, ein bahnbrechender Statistiker, der an der Entwicklung eines beliebten Zeitreihenmodells beteiligt war, war ein großer Pragmatiker. Er sagte bekanntlich: "Alle Modelle sind falsch, aber einige sind nützlich.
Mit dieser Aussage reagierte Box auf die weit verbreitete Ansicht, dass es bei der Modellierung von Zeitreihen darum geht, das beste Modell für die Daten zu finden. Wie er erklärte, ist die Vorstellung, dass jedes Modell die reale Welt beschreiben kann, sehr unwahrscheinlich. Box machte diese Aussage im Jahr 1978, was in der Geschichte eines so wichtigen Fachgebiets wie der Zeitreihenanalyse seltsam spät erscheint, aber in Wirklichkeit war die formale Disziplin überraschend jung.
Eine der Errungenschaften, die George Box berühmt gemacht haben, die Box-Jenkins-Methode, die als grundlegender Beitrag zur Zeitreihenanalyse gilt, erschien zum Beispiel erst 1970.4 Interessanterweise wurde diese Methode erstmals nicht in einer Fachzeitschrift, sondern in einem Statistik-Lehrbuch, Time Series Analysis, veröffentlicht: Forecasting and Control (Wiley). Dieses Lehrbuch ist übrigens nach wie vor beliebt und liegt inzwischen in der fünften Auflage vor.
Das ursprüngliche Box-Jenkins-Modell wurde auf einen Datensatz mit Kohlendioxid-Emissionen eines Gasofens angewendet. Ein Gasofen hat zwar nichts Seltsames an sich, aber der 300-Punkte-Datensatz, der zur Demonstration der Methode verwendet wurde, wirkt doch etwas veraltet. Natürlich gab es in den 1970er Jahren größere Datensätze, aber erinnere dich daran, dass es damals äußerst schwierig war, mit ihnen zu arbeiten. Damals gab es noch keine Annehmlichkeiten wie R, Python und sogar C++. Forscherinnen und Forscher hatten gute Gründe, sich auf kleine Datensätze und Methoden zu konzentrieren, die die Rechenressourcen minimierten.
Die Zeitreihenanalyse und -prognose entwickelte sich wie die Computer: Größere Datensätze und einfachere Programmierwerkzeuge ebneten den Weg für mehr Experimente und die Möglichkeit, interessantere Fragen zu beantworten. Die Geschichte der Prognosewettbewerbe von Professor Rob Hyndman ist ein treffendes Beispiel dafür, wie sich die Wettbewerbe für Zeitreihenprognosen parallel zur Entwicklung der Computer entwickelt haben.
Professor Hyndman führt die "früheste nicht-triviale Studie über die Genauigkeit von Zeitreihenprognosen" auf eine Dissertation der Universität Nottingham aus dem Jahr 1969 zurück, nur ein Jahr vor der Veröffentlichung der Box-Jenkins-Methode. Diesem ersten Versuch folgten bald organisierte Zeitreihenprognosewettbewerbe, von denen die ersten in den frühen 1970er Jahren etwa 100 Datensätze umfassten.5 Nicht schlecht, aber sicherlich etwas, das man auch von Hand machen könnte, wenn es unbedingt nötig wäre.
Ende der 1970er Jahre hatten die Forscher einen Wettbewerb mit rund 1.000 Datensätzen zusammengestellt, eine beeindruckende Steigerung. In diese Zeit fielen übrigens auch der erste kommerzielle Mikroprozessor, die Entwicklung von Disketten, die ersten Personal Computer von Apple und die Computersprache Pascal. Es ist wahrscheinlich, dass einige dieser Innovationen hilfreich waren. Ein Wettbewerb für Zeitreihenprognosen in den späten 1990er Jahren umfasste 3.000 Datensätze. Diese Datensätze waren zwar beachtlich und erforderten zweifellos viel Arbeit und Einfallsreichtum, um sie zu sammeln und aufzubereiten, aber sie werden von der Menge der heute verfügbaren Daten in den Schatten gestellt. Zeitreihendaten gibt es überall, und bald wird alles eine Zeitreihe sein.
Das rasante Wachstum von Größe und Qualität der Datensätze ist auf die enormen Fortschritte zurückzuführen, die in den letzten Jahrzehnten in der Computertechnik gemacht wurden. Den Hardware-Ingenieuren gelang es in dieser Zeit, den durch das Mooresche Gesetz beschriebenen Trend fortzusetzen, der ein exponentielles Wachstum der Rechenleistung vorhersagt. Da die Hardware immer kleiner, leistungsfähiger und effizienter wurde, war es ein Leichtes, viel mehr davon zu erschwinglichen Preisen zu produzieren - von kleinen tragbaren Computern mit angeschlossenen Sensoren bis hin zu riesigen Rechenzentren, die das moderne Internet in seiner datenhungrigen Form betreiben. In jüngster Zeit haben Wearables, Techniken des maschinellen Lernens und Grafikprozessoren die Menge und Qualität der Daten, die zur Untersuchung zur Verfügung stehen, revolutioniert.6
Zeitreihen werden zweifellos davon profitieren, dass die Rechenleistung steigt, denn viele Aspekte von Zeitreihendaten sind rechenintensiv. Mit dem Ausbau der Rechen- und Datenressourcen wird sich die Zeitreihenanalyse voraussichtlich weiter rasant entwickeln.
Die Ursprünge der statistischen Zeitreihenanalyse
Die Statistik ist eine sehr junge Wissenschaft. Fortschritte in den Bereichen Statistik, Datenanalyse und Zeitreihen hingen schon immer stark davon ab, wann, wo und wie Daten in welcher Menge verfügbar waren. Die Entstehung der Zeitreihenanalyse als Disziplin ist nicht nur mit den Entwicklungen in der Wahrscheinlichkeitstheorie verbunden, sondern auch mit der Entwicklung stabiler Nationalstaaten, in denen die Aufzeichnung von Daten zum ersten Mal zu einem realistischen und interessanten Ziel wurde. Wir haben dies bereits in Bezug auf eine Reihe von Disziplinen behandelt. Jetzt werden wir uns mit der Zeitreihenanalyse selbst als Disziplin beschäftigen.
Ein Maßstab für den Beginn der Zeitreihenanalyse als Disziplin ist die Anwendung von autoregressiven Modellen auf reale Daten. Das geschah erst in den 1920er Jahren. Udny Yule, ein Experimentalphysiker, der später als Dozent für Statistik an der Universität Cambridge tätig war, wandte ein autoregressives Modell auf Sonnenfleckendaten an und bot damit im Gegensatz zu Methoden, die auf die Frequenz einer Schwingung abzielten, eine neuartige Denkweise für die Daten. Yule wies darauf hin, dass ein autoregressives Modell nicht von einem Modell ausgeht, das Periodizität voraussetzt:
Wenn die Periodogramm-Analyse auf Daten eines physikalischen Phänomens angewandt wird, um eine oder mehrere echte Periodizitäten herauszufinden, neigt man in der Regel dazu, so scheint es mir, von der Ausgangshypothese auszugehen, dass die Periodizität oder die Periodizitäten nur durch mehr oder weniger zufällige, überlagerte Fluktuationen verdeckt werden - Fluktuationen, die den stetigen Verlauf der zugrunde liegenden periodischen Funktion(en) in keiner Weise stören... Es gibt keinen Grund, dies als die a priori wahrscheinlichste Hypothese anzunehmen.
Yule hatte seine eigene Meinung, aber es ist wahrscheinlich, dass einige historische Einflüsse ihn dazu brachten, zu erkennen, dass das traditionelle Modell sein eigenes Ergebnis voraussetzte. Als ehemaliger Experimentalphysiker, der im Ausland in Deutschland gearbeitet hatte (dem Epizentrum der aufkeimenden Theorie der Quantenmechanik), war sich Yule sicherlich der jüngsten Entwicklungen bewusst, die den probabilistischen Charakter der Quantenmechanik hervorhoben. Er hätte auch die Gefahren erkannt, sich auf ein Modell zu beschränken, das zu viel voraussetzt, wie es die klassischen Physiker vor der Entdeckung der Quantenmechanik getan hatten.
Als die Welt vor allem nach dem Zweiten Weltkrieg geordneter, aufgezeichneter und vorhersehbarer wurde, kamen die ersten Probleme der praktischen Zeitreihenanalyse aus dem Wirtschaftssektor. Geschäftsorientierte Zeitreihenprobleme waren wichtig und in ihren Ursprüngen nicht allzu theoretisch. Dazu gehörten die Vorhersage der Nachfrage, die Schätzung zukünftiger Rohstoffpreise und die Absicherung von Produktionskosten. In diesen industriellen Anwendungsfällen wurden die Techniken übernommen, wenn sie funktionierten, und verworfen, wenn sie nicht funktionierten. Wahrscheinlich war es hilfreich, dass Industriearbeiter/innen Zugang zu größeren Datensätzen hatten als Akademiker/innen damals (und auch heute noch). Das bedeutete, dass manchmal praktische, aber theoretisch nicht ausreichend erforschte Techniken weit verbreitet waren, bevor sie richtig verstanden wurden.
Die Ursprünge der Zeitreihenanalyse durch maschinelles Lernen
Die Anfänge des maschinellen Lernens in der Zeitreihenanalyse reichen viele Jahrzehnte zurück. In einem oft zitierten Aufsatz aus dem Jahr 1969, "The Combination of Forecasts", wurde die Idee analysiert, Prognosen zu kombinieren, anstatt eine "beste" zu wählen, um die Prognoseleistung zu verbessern. Diese Idee war den traditionellen Statistikern zunächst ein Dorn im Auge, aber mittlerweile sind Ensemble-Methoden bei vielen Prognoseproblemen der Goldstandard. Ensembling lehnt die Idee eines perfekten oder sogar deutlich überlegenen Prognosemodells im Vergleich zu allen möglichen Modellen ab.
In jüngerer Zeit wurden Zeitreihenanalyse und maschinelles Lernen bereits in den 1980er Jahren in einer Vielzahl von Szenarien praktisch eingesetzt:
-
Computersicherheitsexperten haben die Anomalieerkennung als Methode zur Identifizierung von Hackern/Eindringlingen vorgeschlagen.
-
Dynamisches Time Warping, eine der vorherrschenden Methoden zur "Messung" der Ähnlichkeit von Zeitreihen, kam zum Einsatz, weil die Rechenleistung endlich eine einigermaßen schnelle Berechnung von "Abständen", z. B. zwischen verschiedenen Audioaufnahmen, ermöglichte.
-
Rekursive neuronale Netze wurden erfunden und haben sich als nützlich erwiesen, um Muster aus verfälschten Daten zu extrahieren.
Die Zeitreihenanalyse und -vorhersage hat ihre Blütezeit noch nicht erreicht. Bis heute wird die Zeitreihenanalyse von traditionellen statistischen Methoden und einfacheren maschinellen Lernverfahren wie Baumgruppen und linearen Anpassungen dominiert. Wir warten immer noch auf einen großen Sprung nach vorn bei der Vorhersage der Zukunft.
Mehr Ressourcen
-
Über die Geschichte der Zeitreihenanalyse und -prognose:
- Kenneth F. Wallis, "Revisiting Francis Galton's Forecasting Competition", Statistical Science 29, no. 3 (2014): 420-24, https://perma.cc/FJ6V-8HUY.
Dies ist eine historische und statistische Erörterung einer sehr frühen Abhandlung über die Vorhersage des Gewichts eines geschlachteten Ochsen, während das Tier noch lebte, auf einer Bezirksmesse.
- G. Udny Yule, "On a Method of Investigating Periodicities in Disturbed Series, with Special Reference to Wolfer's Sunspot Numbers", Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character 226 (1927): 267-98, https://perma.cc/D6SL-7UZS.
Die bahnbrechende Arbeit von Udny Yule, eine der ersten Anwendungen der Analyse des autoregressiven gleitenden Durchschnitts auf reale Daten, zeigt einen Weg auf, wie die Annahme der Periodizität aus der Analyse eines vermeintlich periodischen Phänomens entfernt werden kann.
- J.M. Bates und C. W. J. Granger, "The Combination of Forecasts", Organizational Research Quarterly 20, No. 4 (1969): 451-68, https://perma.cc/9AEE-QZ2J.
Diese bahnbrechende Arbeit beschreibt die Verwendung von Ensembling für Zeitreihenprognosen. Die Idee, dass die Durchschnittsbildung von Modellen für Prognosen besser ist als die Suche nach einem perfekten Modell, war für viele traditionelle Statistiker neu und umstritten.
- Jan De Gooijer und Rob Hyndman, "25 Years of Time Series Forecasting", International Journal of Forecasting 22, no. 3 (2006): 443–73, https://perma.cc/84RG-58BU.
Dies ist eine gründliche statistische Zusammenfassung der Forschung zur Zeitreihenprognose im 20.
- Rob Hyndman, "A Brief History of Time Series Forecasting Competitions", Hyndsight blog, April 11, 2018, https://perma.cc/32LJ-RFJW.
Diese kürzere und spezifischere Geschichte enthält konkrete Zahlen, Orte und Autoren prominenter Zeitreihenprognosewettbewerbe der letzten 50 Jahre.
-
Über domänenspezifische Zeitreihenverläufe und Kommentare:
- NASA, "Weather Forecasting Through the Ages", Nasa.gov, 22. Februar 2002, https://perma.cc/8GK5-JAVT.
Die NASA gibt einen Überblick über die Geschichte der Wettervorhersage, wobei der Schwerpunkt auf den besonderen Herausforderungen und Erfolgen der Forschung im 20.
- Richard C. Cornes, "Frühe meteorologische Daten aus London und Paris: Extending the North Atlantic Oscillation Series" (Erweiterung der nordatlantischen Oszillationsreihe), Dissertation, School of Environmental Sciences, University of East Anglia, Norwich, UK, Mai 2010, https://perma.cc/NJ33-WVXH.
Diese Doktorarbeit bietet einen faszinierenden Bericht über die Arten von Wetterinformationen, die für zwei der wichtigsten Städte Europas verfügbar sind, komplett mit ausführlichen Auflistungen der Orte und der Art des historischen Wetters im Zeitreihenformat.
- Dan Mayer, "A Brief History of Medicine and Statistics", in Essential Evidence-Based Medicine (Cambridge, UK: Cambridge University Press, 2004), https://perma.cc/WKU3-9SUX.
In diesem Kapitel von Mayers Buch wird deutlich, wie sehr die Beziehung zwischen Medizin und Statistik von sozialen und politischen Faktoren abhing, die den Medizinern Daten und statistische Schulungen zur Verfügung stellten.
- Simon Vaughan, "Random Time Series in Astronomy", Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 371, no. 1984 (2013): 1-28, https://perma.cc/J3VS-6JYB.
Vaughan fasst die vielen Möglichkeiten zusammen, wie die Zeitreihenanalyse für die Astronomie relevant ist, und warnt vor der Gefahr, dass Astronomen die Zeitreihenprinzipien wiederentdecken oder vielversprechende Kooperationen mit Statistikern verpassen.
1 Beispiele sind die British Doctors Study und die Nurses' Health Study.
2 Siehe z. B. Darrell Etherington, Amazon, JPMorgan and Berkshire Hathaway to Build Their Own Healthcare Company," TechCrunch, 30. Januar 2018, https://perma.cc/S789-EQGW; Christina Farr, Facebook Sent a Doctor on a Secret Mission to Ask Hospitals to Share Patient Data," CNBC, 5. April 2018, https://perma.cc/65GF-M2SJ.
3 Dieser Robert FitzRoy war Kapitän der HMS Beagle während der Reise, die Charles Darwin um die Welt führte. Diese Reise lieferte Darwin wichtige Beweise für die Theorie der Evolution durch natürliche Selektion.
4 Die Box-Jenkins-Methode ist zu einer kanonischen Technik für die Auswahl der besten Parameter für ein ARMA- oder ARIMA-Modell zur Modellierung einer Zeitreihe geworden. Mehr dazu in Kapitel 6.
5 Das heißt, 100 separate Datensätze in verschiedenen Bereichen mit unterschiedlichen Zeitreihen unterschiedlicher Länge.
6 Angesichts der vielen Geräte, die Menschen mit sich herumtragen, und der Zeitstempel, die sie beim Einkaufen, beim Einloggen in ein Computerportal auf der Arbeit, beim Surfen im Internet, beim Überprüfen von Gesundheitsdaten, beim Telefonieren oder beim Navigieren im Straßenverkehr mit GPS erstellen, können wir mit Sicherheit sagen, dass ein durchschnittlicher Amerikaner wahrscheinlich jedes Jahr seines Lebens Tausende von Zeitreihendatenpunkten erzeugt.
Get Praktische Zeitreihenanalyse now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

