Chapter 1. Introduction
Let’s get started! This chapter discusses:
-
What I mean by process automation
-
Specific technical challenges when automating processes
-
What a workflow engine can do and why this provides a ton of value
-
How business and IT can collaborate when automating processes
-
How modern tools differ very much from BPM and SOA tooling from the past
Process Automation
In essence, a process (or workflow) simply refers to a series of tasks that need to be performed to achieve a desired result.
Processes are everywhere. As a developer, I think of my personal development process as being able to manage certain tasks that go from an issue to a code change that is then rolled out to production. As an employee, I think of optimizing my process around handling emails, which involves techniques for prioritizing them quickly and keeping my inbox empty. As a business owner, I think of end-to-end business processes like fulfilling customer orders, known as “order to cash.” And as a backend developer, I might also think of remote calls in my code, as these involve a series of tasks—especially if you consider retry or cleanup tasks, because a distributed system can fail at any time.
Processes can be automated on different levels. The main distinction is if a human controls the process, if a computer controls the process, or if the process is fully automated. Here are some examples that highlight these different levels of automation.
After high school, I helped organize meals-on-wheels deliveries to elderly people in their homes. There was a daily process going on to handle the meal orders, aggregate a list of orders that went to the kitchen, package the meals, and finally ensure that all the orders were labeled correctly so they would be delivered to the correct recipients. In addition to that, there was the delivery service itself. When I started, the process was completely paper-driven, and it took an entire morning to accomplish. I changed that, leveraging Microsoft Excel to automate some tasks. This brought the processing time down to about 30 minutes—so it was a lot more efficient. But there were still physical activities involved, like packing and labeling the food as well as driving to the recipients’ homes.
More importantly, the process was still human-controlled, as it was my job to press the right buttons and show up in the kitchen at the appropriate times with the appropriate lists. Only some tasks were supported by software.
During my last hospital visit I chatted to the staff about how the meal preparation worked. The patients were required to fill out a paper card to mark allergies and meal preferences, and this information was typed into a computer. Then the IT system was in charge of transporting that information to the right place at the right time, and it needed to be done in an automatic fashion. People still played a role in the process, but they did not steer it. This was a computer-controlled, but not fully automated process.
If you take this example even further, today there are cooking robots available. If you were to add these robots to the process, it would be possible to task the computer with not only automating the control flow, but also the cooking tasks. This moves the process closer to a fully automated process.
As you can see, there is an important distinction between the automation of the control flow between tasks, and the automation of the tasks themselves:
- Automation of the control flow
-
The interactions between tasks are automated, but the tasks themselves might not be. If humans do the work, the computer controls the process and involves them whenever necessary, for example using tasklist user interfaces. This is known as human task management. In the previous example, this was the humans cooking the food. This is in contrast to a completely manual process that works because people control the task flow, by passing paper or emails around.
- Automation of the tasks
-
The tasks themselves are automated. In the previous example, this would be the robots cooking the food.
If you combine automation of both the control flow and the tasks you end up with fully automated processes, also known as straight-through processing (STP). These processes only require manual intervention if something happens beyond the expected normal operations.
While there is of course an overall tendency to automate processes as much as possible, there are specific reasons that motivate automation:
- High number of repetitions
-
The effort put into automation is worthwhile only if the potential savings exceed the cost of development. Processes with a high volume of executions are excellent candidates for automation.
- Standardization
-
Processes need to be structured and repeatable to be easily automated. While some degree of variance and flexibility is possible with automated processes, it increases the effort required for automation and weakens some of the advantages.
- Compliance conformance
-
For some industries or specific processes there are strict rules around auditability, or even rules that mandate following a documented procedure in a repeatable and revisable manner. Automation can deliver this and provide high-quality, relevant data right away.
- Need for quality
-
Some processes should produce results of consistent quality. For example, you might promise a certain delivery speed for customer orders. This is easier to achieve and retain with an automated process.
- Information richness
-
Processes that carry a lot of digitized information are better suited to automation.
Automating processes can be achieved by different means, as further examined in “Limitations of Other Implementation Options”, but there is special software that is dedicated to process automation. As mentioned in the Preface, this book will focus on those tools, and especially look at workflow engines.
Note
Automating processes does not necessarily mean doing software development or using some kind of workflow engine. It can be as simple as leveraging tools like Microsoft Office, Slack, or Zapier to automate tasks triggered by certain events. For example, every time I enter a new conference talk in my personal spreadsheet, it triggers a couple of automated tasks to publish it on my homepage, the company event table, our developer relations Slack channel, and so forth. This kind of automation is relatively easy to implement, even by non-IT folks in a self-service manner, but of course is limited in power.
In the rest of this book I will not focus on these office-like workflow automation tools. Instead, we’ll explore process automation from a software development and architecture perspective.
To help you understand how to automate processes with a workflow engine, let’s quickly jump into a story that illustrates the kinds of real-life developer problems it can solve.
Wild West Integrations
Imagine Ash is a backend developer who gets tasked with building a small backend system for collecting payments via credit card. This doesn’t sound too complex, right? Ash starts right away and designs a beautiful architecture. In conversations with the folks doing order fulfillment, they agree that providing a REST API for the order fulfillment service is the easiest option to move forward. So Ash goes ahead and starts coding it.
Halfway through, a colleague walks in and looks at Ash’s whiteboard, where the beauty of the architecture is captured. The colleague casually says, “Ah, you’re using that external credit card service. I used to work with it, too. We had a lot of issues with leaky connections and outages back then; did that improve?”
This question takes Ash by surprise. This expensive SaaS service is flaky? That means Ash’s nice, straightforward code is too naive! But no worries, Ash adds some code to retry the call when the service is not available. After chatting a bit more, the colleague reveals that their service suffered from outages that sometimes lasted hours. Puh—so Ash needs to think of a way of retrying over a longer period of time. But darn it, this involves state handling and using a scheduler! So Ash decides to not tackle this right away but just add an issue to the backlog in the hopes that the order fulfillment team can sort it out. For now, Ash’s code simply throws an exception when the credit card service is unavailable, with fingers crossed that all will work out well.
Two weeks into production, a different colleague from order fulfillment walks over, alongside the CEO. What the heck? It turns out Ash’s system raises a lot of “credit card service unavailable” errors, and the CEO is not happy about the amount of orders not being fulfilled—this issue has resulted in lost revenue. Ash tries to act immediately and asks the order fulfillment team to attempt retrying the payments, but they have to iron out other urgent problems and are reluctant to take over responsibilities that should be handled by Ash’s service (and they are totally right to be reluctant, as you’ll read about in Chapter 7).
Ash promises to fix the situation and get something live ASAP. Back at their desk, Ash creates a database table called payment with a column called status. Every payment request gets inserted there, with a status of open. On top of that Ash adds a simple scheduler that checks for open payments every couple of seconds and processes them. Now the service can do stateful retries over longer periods of time. This is great. Ash calls the order fulfillment folks and they discuss the changes needed in the API, as payments are now processed asynchronously. The original REST API will hand back HTTP 202 (Accepted) responses, and Ash’s service can either call back the fulfillment service, send them some message, or let them periodically poll for the payment status. The teams agree on the polling approach as a quick fix, so Ash just needs to provide another REST endpoint to allow querying the payment status.
The change gets rolled out to production and Ash is happy to have dealt with the CEO’s concerns. But unfortunately, the peace doesn’t last too long. A caravan of people arrive in Ash’s office, including the director of operations. They tell Ash that no orders can be shipped because no payments are successfully being taken. What? Ash makes a mental note to add some monitoring to avoid being surprised by these situations in the future, and takes a look at the database. Oh no, there are a huge amount of open payments piling up. Digging a bit into the logs Ash discovers that the scheduler was interrupted by an exceptional case and crashed. Dang it.
Ash puts the one poisoned payment that interrupted the whole process aside, restarts the scheduler, and sees that payments are being processed again. Relieved, Ash vows to keep a closer eye on things and hacks together a small script to periodically look at the table and send an email alert whenever something unusual happens. Ash also decides to add some mitigation strategies for the exceptional case to that script. Great!
After all these stressful weeks, Ash plans to go on vacation. But it turns out that the boss isn’t too happy about Ash leaving because nobody except Ash actually understands the tool stack that they just built. Even worse, the boss instead pulls out a list of additional requirements for the payment service, as some business folks have heard about the flaky credit card service and want more in-depth reports about availability and response times. They also want to know if the agreed-on service level agreement (SLA) is actually being met and want to monitor that in real time. Gosh—now Ash has to add report generation on top of a database that hadn’t seemed necessary in the first place. Figure 1-1 shows the resulting mess in its full beauty.
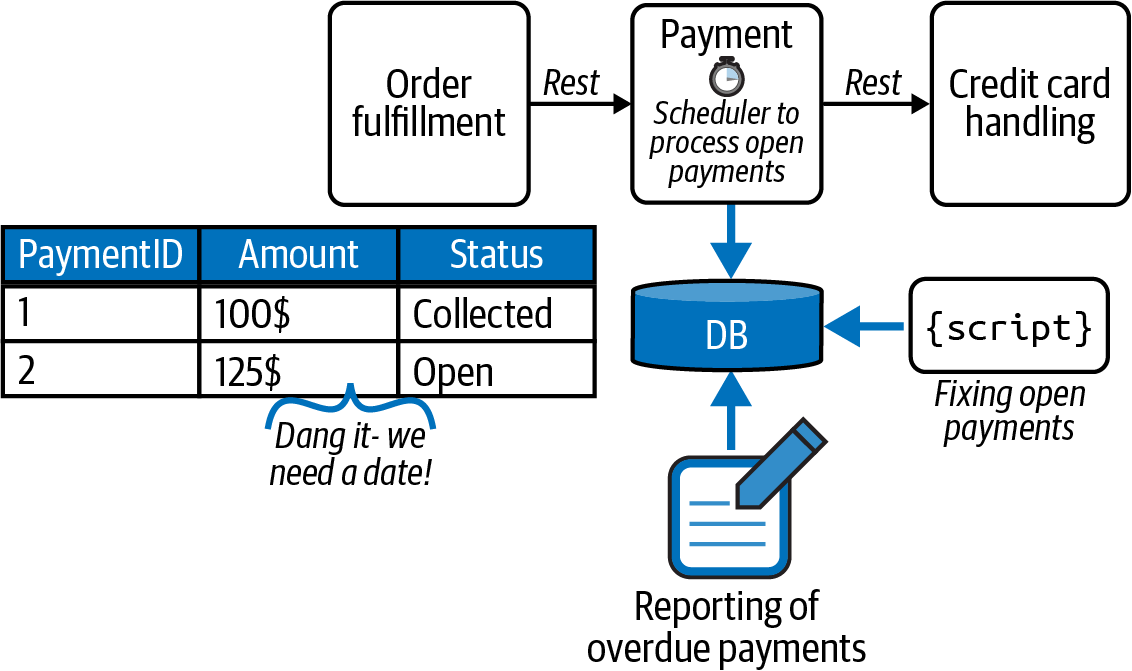
Figure 1-1. Wild West integration at play—the usual chaos you actually find at most enterprises
Unfortunately, Ash just used a far-too-common approach to automate processes that I call Wild West integration. It’s an ad hoc approach to creating systems without any kind of governance. It is very likely that such a system doesn’t serve the business as a whole well.
Here are some more flavors of Wild West integration:
- Integration via database
-
A service accesses some other service’s database directly in order to communicate, often without the other service knowing it.
- Naive point-to-point integrations
-
Two components communicate directly with each other, often via REST, SOAP, or messaging protocols, without properly clarifying all aspects around remote communication.
- Database triggers
-
Additional logic is invoked whenever you write something to the database.
- Brittle toolchains
-
For example, moving comma-separated (CSV) text files via FTP.
Ash needed to write a lot of code for features that are built-in capabilities of a workflow engine: keeping the current state, scheduling retries, reporting on the current state, and operating long-running processes. Instead of writing your own code, you should leverage existing tools. There’s really nothing to gain by rolling your own solution. Even if you think that your project doesn’t need the additional complexity of a workflow engine, you should always give it a second thought.
Tip
Coding processes without a workflow engine typically results in complex code; state handling ends up being coded into the components themselves. This makes it harder to understand the business logic and business process implemented in that code.
Ash’s story could also easily lead to the development of a homegrown workflow engine. Such company-specific solutions cause a lot of development and maintanence effort and will still lack behind what existing tools can deliver.
Workflow Engines and Executable Process Models
So what is the alternative to hardcoded workflow logic or a homegrown workflow engine? You can use an existing tool, such as one of the products contained in the curated list on this book’s website.
A workflow engine automates the control of a process. It allows you to define and deploy a blueprint of your process, the process definition, expressed in a certain modeling language. With that process definition deployed you can start process instances, and the workflow engine keeps track of their state.
Figure 1-2 shows a process for the payment example introduced earlier. The process starts when a payment is required, as indicated by the first circle in the process model (the so-called start event, marking the beginning of a process). It then goes through the one and only task, called a service task, indicated by the cog wheels. This service task will implement the REST call to the external credit card service. You will learn how this can be done in Chapter 2. For now, simply imagine that you write some normal programming code to do this, which I call glue code. After that task, the process ends in the end event, the circle with the thick border.
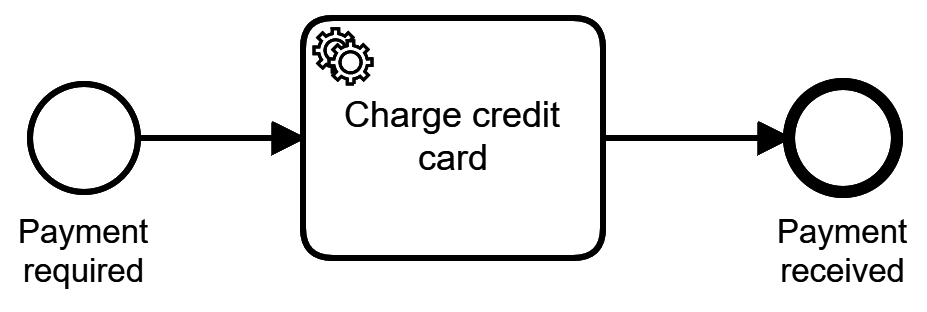
Figure 1-2. A very simple process, which can already handle many requirements in the credit card example
Figure 1-3 visualizes with some pseudocode how you can use this process model to implement payments. First, you will write some code that reacts to something in the outside world—for example, a call to the REST endpoint to collect payments. This code will then use the workflow engine API to start a new process instance. This process instance is persisted by the workflow engine; Figure 1-3 visualizes this via a relational database. You’ll read about different engine architectures, persistence options, and deployment scenarios later in this book.
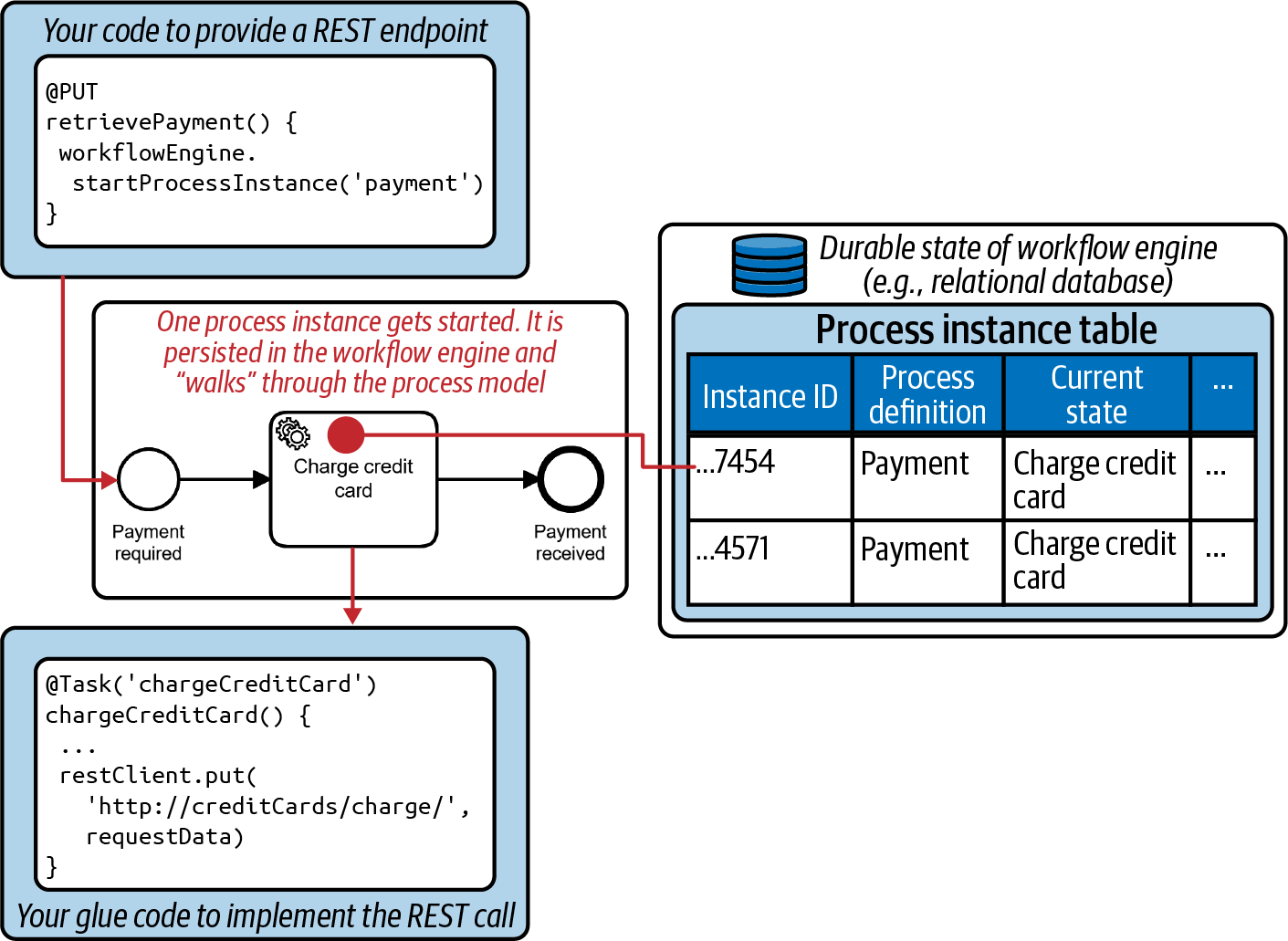
Figure 1-3. Workflow engine
Next, you will write some glue code to charge the credit card. This code acts like a callback and will be executed when the process instance advances to the task to charge the credit card, which will happen automatically after the process instance is started. Ideally, the credit card payment is processed right away and the process instance ends afterward. Your REST endpoint might even be able to return a synchronous response to its client. But in case of an outage of the credit card service, the workflow engine can safely wait in the task to charge the credit card and trigger retries.
We just touched on the two most important capabilities of a workflow engine:
-
Persist the state, which allows waiting.
-
Schedule things, like the retries.
Depending on the tooling, the glue code might need to be written in a specific programming language. But some products allow arbitrary programming languages, so if you decide to clean up your Wild West implementation you’ll probably be able to reuse big parts of your code and just leverage the workflow engine for state handling and scheduling.
Of course, many processes go far beyond that simple example. When retrieving payments, the process model might solve more business problems. For example, the process could react to expired credit cards and wait for the customer to update their payment information, as visualized in Figure 1-4.
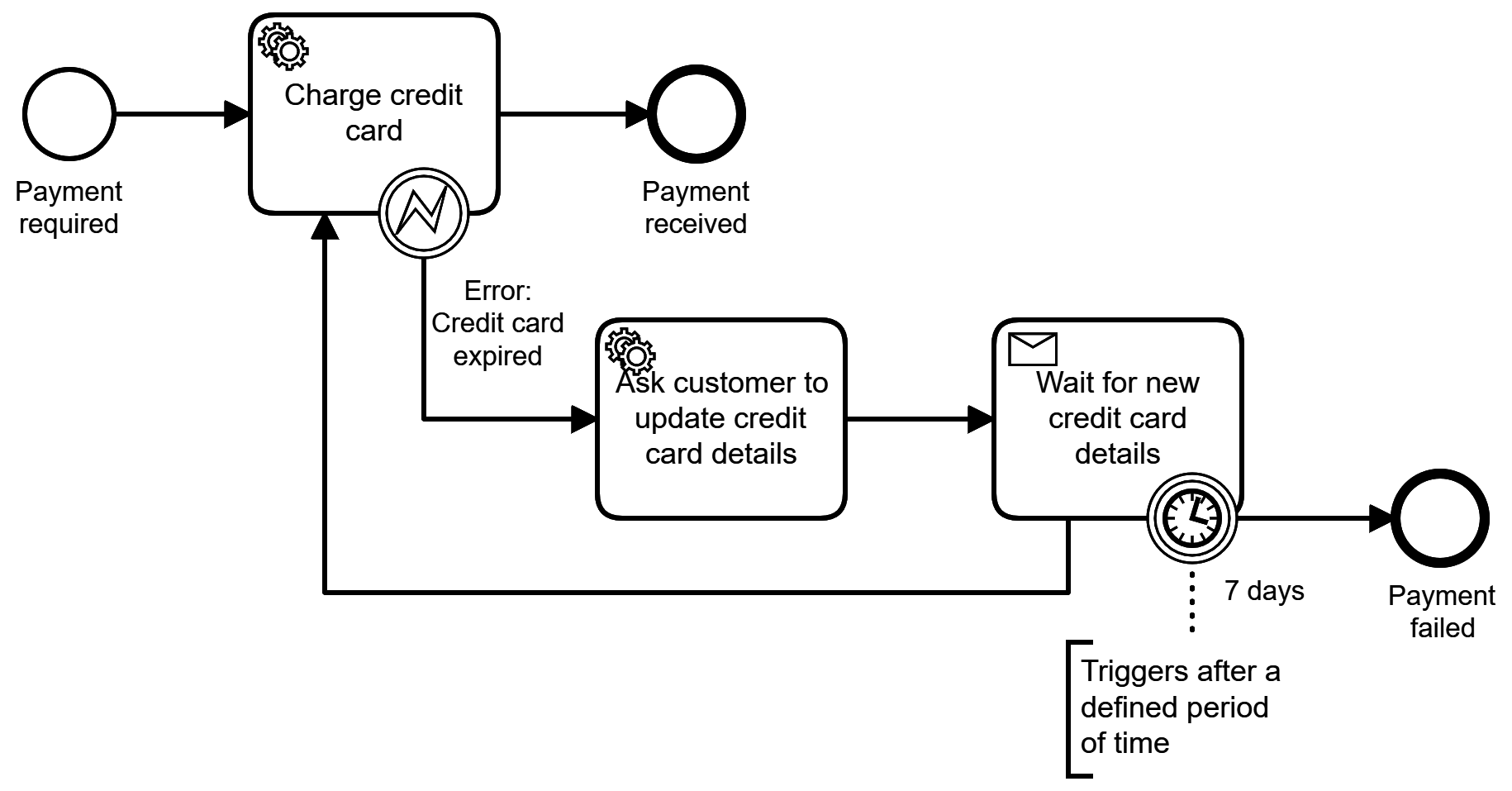
Figure 1-4. The payment process can quickly become more elaborate
So far, the payment process is more of an integration process, which is not the most typical use for process automation. I like starting with it as it helps technical audiences to understand core workflow engine capabilities, but we’ll examine a more typical business process in the next section.
A Business Scenario
Let’s look at a typical (but imaginary) project. ShipByButton Inc. (SBB) is a tech startup. It provides a small hardware button. Whenever it is pressed, one specific item is ordered. For example, you could put this button next to your washing powder, and when you see that the powder is almost empty, you just press the button, and one box of washing powder will then be ordered and shipped to you (if this reminds you of the Amazon Dash button, this might be simply coincidence ;-)).
SBB wants to automate its core business process, which is order fulfillment. An elaborate discussion of the different roles and their collaboration is provided in “A Typical Project”. For now, let’s just say SBB starts with drawing out the process relating to the physical steps involved, and work their way down to the level of detail that can be automated using a workflow engine. They benefit from the fact that the process modeling language, BPMN, is universal regardless of the level at which you apply it.
The resulting process model is shown in Figure 1-5.

Figure 1-5. End-to-end business process that is subject to automation
This is of course a bit simplified, as in real life you have more exceptional cases; e.g., if payment cannot be retrieved or goods are out of stock.
You can see that this process relies on other services, for example the first task invoking the payment service. This is a typical scenario when applying microservices, as you will learn later in this book.
Note
Modeling business processes often leads to an interesting by-product: unexpected insights. In a customer scenario close to SBB’s, we found that the “business people” did not actually know exactly what the “on the warehouse floor people” were doing. The visual process model not only helped to identify but also to resolve this problem.
Long-Running Processes
Process automation has a broad scope. While it is often about enterprise, end-to-end business processes like order fulfillment, account opening, or claim settlement, it can also help with much more technical use cases around orchestration and integration, as noted in the credit card example.
All these examples share one commonality, though: they involve long-running processes. That means processes that take minutes, hours, weeks, or months to complete. Handling long-running processes is what workflow engines excel at.
These processes involve waiting for something to happen; for example, for other components to respond, or simply for humans to do some work. This is why workflow engines need to handle durable state, as mentioned earlier.
Another way to look at it is that long-running behavior is required whenever logic crosses boundaries. When I say boundaries, this can mean very different things. If you call a remote service, you cross the boundary of your local program, your local OS, and your local machine. This leaves you responsible for dealing with problems around the availability of the service or added latency. If you invoke another component or resource, you also cross the technical transaction boundary. If you integrate components from other teams you cross organizational boundaries, which means you need to collaborate with these people more. If you involve external services, like from a credit card agency, you cross the boundary of your own company. And if you involve people, this crosses the boundary between automatable and not-automatable tasks.
Managing these boundaries not only requires long-running capabilities, but also requires you to think carefully about the sequence of tasks. Failure scenarios and the proper business strategy to handle them need serious discussion. And you might face regulatory requirements around data security, compliance, or auditing. These requirements further motivate graphical process visualizations, which will be covered in depth in Chapter 11; these allow technical folks to consult with the right non-technical people to solve any challenges.
Modern systems have more and more boundaries, as there is a growing tendency to move away from monolithic systems toward fine-grained components, like services, microservices, or functions. And systems are often assembled out of a wild mix of internal applications and services consumed in the cloud.
Business Processes, Integration Processes, and Workflows
To summarize, you can automate business processes as well as integration processes. The boundary between these categories is often not sharp at all, as most integration use cases have a business motivation. This is why you don’t find “integration processes” discussed as a separate category in this book. Instead, “Model or Code?” will show you that many technical details end up in normal programming code, not in a process model, and “Extracting (Integration) Logic into Subprocesses” will explain that you can extract some portions of the process model into child models. This allows you to push technical details into another level of granularity, which helps to keep the business process understandable.
Furthermore, you’ll have noticed that I use the terms process and workflow. Truth be told, there is no common, agreed-on understanding of the difference between process automation and workflow automation. Many people use these terms interchangeably. Others don’t, and argue that business processes are more strategic and workflows are more tactical artifacts; thus, only workflows can be modeled and executed on a workflow engine. Similarly, process models can also be called workflow models; some standards use one term, and others the other. Neither is right or wrong.
I often recommend adjusting the terminology to whatever works well in your environment. However, for this book I had to make a choice, and I simply went with what I feel most comfortable with. As a rule of thumb:
-
Business process automation is what you want to achieve. It is the goal. It is what business people care about. I will use the term process (or business process) in most cases.
-
I use the term workflow whenever I talk about the tooling, which is about how processes are really automated. So, for example, I will talk about a workflow engine, even if this will automate process models.
In real life, I sometimes adjust these rules. For instance, when talking to technical folks about the implementation, I might prefer the terms workflow, workflow engine, or sometimes even orchestration engine or Saga, depending on the context (you will understand the latter terms when you’ve progressed further in this book).
Business–IT Collaboration
The collaboration of business stakeholders and IT professionals is crucial for the success of modern enterprises. Business stakeholders understand the organization, the market, the product, the strategy, and the business case for each project. They can channel all of that into requirements, features, and priorities. IT, on the other hand, understands the existing IT landscape and organization—constraints and opportunities as well as effort and availability. Only by collaborating can both “sides” win.
Unfortunately, different roles often speak different languages. Not literally—both might communicate in English—but in the way they phrase and understand things.
Putting the business process at the center of this communication helps. It makes it much easier to understand requirements in the context of a bigger picture and avoids the misunderstandings that can happen when you discuss features in isolation.
Visual process models facilitate this conversation, especially if they can be understood by business and IT. All the efficient requirement workshops I’ve seen were filled with people from business and IT.
A common example is that business folks underestimate the complexity of requirements, but at the same time miss easy picks. A typical dialogue goes like this:
Business: “Why is implementing this small button so much effort?”
IT: “Because we need to untie a gigantic knot in the legacy software to make it possible! Why can’t we just make a change over here and reach the same result?”
Business: “What, wait, we can change that over there? We thought that was impossible.”
With the right mindset and a good collaboration culture, you will not only progress faster, but also end up with better solutions and happier people. Process automation and especially visual process models will help. Chapter 10 will explain this in much more detail.
Business Drivers and the Value of Process Automation
Organizations apply process automation to:
-
Build better customer experiences.
-
Get to market faster (with changed or completely new processes, products, or business models).
-
Increase business agility.
-
Drive operational cost savings.
This can be achieved by the promises that come with the prospect of process automation: increasing visibility, efficiency, cost-effectiveness, quality, confidence, business agility, and scale. Let’s look at some of these briefly.
Business processes provide direct visibility to business stakeholders. For example, a business person cares about the sequence of tasks, such as ensuring that payment is collected before shipping, or knowing what the strategy is for handling failed payments. This information is needed to truly understand how the business currently runs and performs. The data that process automation platforms provides leads to actionable insights, which is the basis for process optimizations.
Enterprises care about the efficiency and cost-effectiveness of their automated processes, as well as quality and confidence. An online retailer might want to reduce the cycle time of their order fulfillment process, meaning that a customer will receive a parcel as fast as possible after hitting the order button. And of course, retailers also don’t want any orders to fall through the cracks in the system, leaving them not only with a missed sale, but also an unhappy customer.
Some business models even rely on the possibility of fully automating processes; it is crucial for companies to make money, or deliver responses as fast as expected, or scale their business.
Business agility is another important driver. The pace of IT is too fast to really anticipate any trend properly, so it is important for companies to build systems that can react to changes. As the CIO of an insurance company recently said to me, “We don’t know what we will need tomorrow. But we do know that we will need something. So we have to be able to move quickly!” Concentrating on building systems and architectures in a way that makes it easy to adopt changes is crucial to the survival of many businesses. Process automation is one important piece, as it makes it easier to understand how processes are currently implemented, to dive into discussions around changes, and to implement them.
Not Your Parents’ Process Automation Tools
If process automation and workflow engines are such a great solution for certain problems, why doesn’t everybody apply them? Of course, some people simply don’t know about them. But more often, people have either had bad experiences with bad tools in the past, or they only have a vague association with terms like workflow or process automation and think they relate to old-school document flows or proprietary tool suites, which they don’t see as helpful. Spoiler alert: this is wrong!
In order to overcome these misconceptions it’s good to be aware of history and past failures. This will allow you to free your mind to adopt a modern way of thinking about process automation.
A Brief History of Process Automation
The roots of dedicated process automation technology date back to around 1990, when paper-based processes began to be guided by document management systems. In these systems, a physical or digital document was the “token” (a concept we’ll discuss more in Chapter 3), and workflows were defined around that document. So, for example, the application form to open a bank account was scanned and moved automatically to the people who needed to work on it.
You can still spot these document-based systems in real life. I recently saw a tool being used with a lot of phantom PDF documents being created just to be able to kick off workflow instances that are not based on a real physical document.
This category of systems developed further into human workflow management tools that were centered around human task management. They reached their zenith around 2000. With these, you did not need documents to start a workflow. Still, these systems were built to coordinate humans, not to integrate software.
Then, also around the year 2000, service-oriented architecture (SOA) emerged as an alternative to large monolithic ecosystems where traditional enterprise application integration (EAI) tools did point-to-point integrations. The idea was to break up functionality into services that are offered in a more or less standardized way to the enterprise, so that others can easily consume them. One fundamental idea of SOA was to reuse these services and thus reduce development efforts. Hybrid tools emerged: tools that were rooted in SOA but added human task capabilities, and human workflow products that added integration capabilities.
Around the same time, business process management (BPM) was gaining traction as a discipline, taking not only these technical and tooling aspects into account, but also the lessons around setting up scalable organizations and business process reengineering (BPR).
These developments are summarized in Figure 1-6.
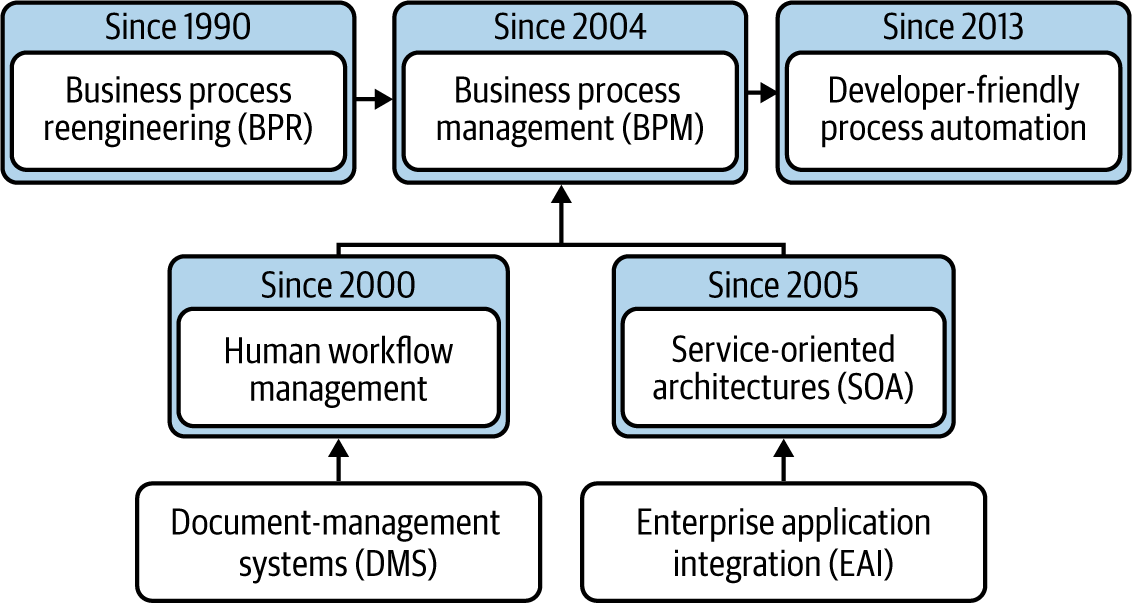
Figure 1-6. Historical development of disciplines
Process automation was a hyped topic in the BPM and SOA era. Unfortunately, there were some major flaws that led to many disappointments, for the following reasons: BPM was too detached from developers, and the tools were too vendor-driven, too centralized, and too focused on low code. Let me explain.
BPM in the ivory tower
BPM as a discipline includes methods to discover, model, analyze, measure, improve, optimize, and automate business processes. In that sense, it is a very broad topic. Unfortunately, many BPM initiatives were too detached from IT. For a long time, the folks doing BPM worked in silos, not considering how processes were really automated within the given IT infrastructure. This led to process models that could not function in real life, and yet these models were given to the IT departments to “simply” implement. Unsurprisingly, this did not work very well.
Centralized SOA and the ESB
In an instance of unfortunate timing, SOA collided with the high times of very complex technologies like the Simple Object Access Protocol (SOAP), which made it difficult for any development team to offer or consume any other service. This opened up the space for tool vendors. Since SOA initiatives were typically very centrally organized and governed, it brought the big vendors into the game, and they sold very expensive middleware that was placed at the heart of many companies in a top-down approach. The tooling was called an enterprise service bus (ESB); it was a messaging system at its core, with multiple tools around it to connect services or transform data.
Looking back at SOA from today’s perspective, it is easy to highlight some of the shortcomings:
- Centralized
-
SOA and ESB tools were typically installed as centralized systems and were operated by their own teams. This very much led to situations where you not only had to implement and deploy your own service, but also interact with the SOA team to deploy additional configuration into these tools, which caused a lot of friction.
- Alien to the development process
-
Tools broke the development workflow, making automated testing or continuous integration/continuous delivery (CI/CD) pipelines impossible. Many of the tools did not even allow for automated testing or deployment.
- Vendor-driven
-
The vendors overtook the industry and sold products before best practices existed, which forced practices into many companies that simply did not work.
- Mixed infrastructure and business logic
-
Important business logic often ended up in routing procedures that were deployed on the middleware, leaving it without clear ownership or responsibility. Different teams implemented various aspects of logic that better belonged in one place.
But how does this relate to process automation? Great question! SOA typically came in tandem with BPM suites.
Misguided BPM suites
BPM suites were standalone tools that included a workflow engine at their core, with tools around it. Like ESBs, these suites were vendor-driven. They were deployed as centralized tools that were introduced from the top down. In these environments a central team took care of the platform, and this team often was the only group capable of deployment. This dependence on single teams led to a lot of problems.
It’s worth mentioning that BPM suites emerged during a time when most companies were still running software on physical hardware—automated deployment pipelines weren’t really a thing then.
The limitations of low code
BPM suites came with the promise of zero code, which was later rebranded as low code. The idea is as simple as it is appealing to business stakeholders: develop processes without IT being involved so a non-technical person can create an executable process model without writing programming code.
Low-code approaches involve heavyweight tools that allow these non-developers to build processes by dragging and dropping prebuilt elements. Sophisticated wizards enable users to configure them, so it’s possible to build solutions without writing any source code.
This approach is still sold as desirable by advisory firms and BPM vendors, and the low-code approach indeed has its upsides. There is a shortage of developers at the moment, so many companies simply don’t have the resources to do proper software projects as they would like to. Less tech-savvy people (referred to as citizen developers by Gartner) begin working on software projects and need these low-code approaches.
But while a low-code approach might work for relatively simple processes, it definitely falls short when dealing with complex business processes or integration scenarios. What I have regularly found is that low-code products do not deliver on their promise, and less-tech-savvy citizen developers cannot implement core processes themselves. As a result, companies have to revert back to their IT departments and ask them to assign professional software developers to finish the job. Those software developers then need to learn a proprietary, vendor-specific way of application development. Developing this skill takes a long time, and it’s often a frustrating experience. As a result, there is a lack of sufficiently skilled software developers within the organization, which forces companies to look for outside resources.
Those outside resources are system integrators that partner with the BPM vendor and provide consultants certified by that vendor. Those consultants tend to be either not as skilled as promised, too expensive, or simply not available, often all at the same time.
Furthermore:
-
You can’t use industry best practices to develop software solutions, like automated testing or frameworks that you might need for integration or user interfaces. You can only do what the vendor has foreseen, as it is hard or even impossible to break out of the preconceived path.
-
You are often blocked from open source or community-driven knowledge and tool enhancements. For example, instead of being able to pick up a code example from GitHub, you instead have to watch a video tutorial on how to use the proprietary wizard to guide you through the low-code interface.
-
The tools are typically very heavyweight and do not easily run on modern virtualized or cloud native architectures.
These unfortunate dynamics caused a lot of companies to give up on process automation tools, even though not all approaches involve this type of proprietary software or low-code development.
Tip
Instead of replacing software development with low-code process automation, the focus should be on bringing software development and process automation together!
It is important to understand that agility does not come from implementing processes without the help of developers, but by using graphical models that different stakeholders can understand and discuss.
As soon as you can combine process automation with “normal” software development practices, you gain development efficiency and quality, you allow normal developers to work on these jobs, and you have a whole universe of existing solutions available to help you out with all kinds of problems. Additionally, workflow vendors might prebuild support for certain integrations, which helps to reduce the effort required to build solutions.
Moving past old-school BPM suites
The good news is that there are now a lot of really useful, lightweight workflow engines available that integrate well with typical development practices and solve common problems.
This new generation of tools are most often open source or provided as cloud services. They target developers and support them in the challenges described earlier in this chapter. They deliver real value and are helping our industry to move forward.
The Story of Camunda
I always like to back this whole development with the story of the company I cofounded: Camunda, a vendor that—as marketing nowadays says—reinvented process automation. As mentioned in the Preface, this book will not be a marketing vehicle for the company, but its story can help you understand the market’s development.
I started Camunda together with my cofounder in 2008, as a company providing consultancy services around process automation. We did a lot of workshops and trainings and thus had thousands of customer contacts.
This collided with the peak times of the old BPM and SOA ideas and tools. We were able to observe various tools in use in different companies. The common theme was that it wasn’t working out, and it was not too hard to figure out the reasons. I described them earlier in this chapter: these tools were centralized, complex, low-code, vendor-driven.
So we began experimenting with the open source frameworks available at the time. They were much closer to developers, but they couldn’t cut it either, mainly because they were too basic, lacked important features, and required too much effort to build your own tooling around them.
At the same time, we collaborated on the development of the Business Process Model and Notation (BPMN) standard, which defines a visual but also directly executable process modeling language.
And we saw a huge opportunity: creating an open source workflow engine that was developer-friendly and fostered business–IT collaboration by using BPMN.
We validated that idea with customers, and soon made a decision to pivot with the company: in 2013 we transformed Camunda from a consulting firm into an open source process automation vendor. Our tool was the complete opposite of the common low-code BPM suites available back then.
Today, Camunda is growing fast and has hundreds of paying customers and countless community users. Many big organizations trust in the vision, and are even replacing tools from big vendors throughout their companies. We accelerate growth globally, as process automation tooling is strongly needed. This is fueled by digitalization and automation programs as well as the trend to move toward more fine-grained components and microservices, which then need to be coordinated. In short: we are doing very well.
Technically, the Camunda workflow engine is engineered the way applications were engineered in 2013. It is basically a library, built in Java, that uses a relational database to store state. The engine can be embedded into your own Java application or run standalone, providing a REST API. And of course, there are a couple of additional tools to model or operate processes.
This architecture has served Camunda very well and can handle most of today’s performance and scalability requirements. Nonetheless, a couple of years back we developed a new workflow engine in a completely different architecture, which nowadays is best described as being cloud native. This workflow engine is developed in parallel and backs the managed service offering within Camunda Cloud. As it scales infinitely, this enables the use of a workflow engine in even more scenarios, which is a vision we’ve had in mind for a long time.
Conclusion
As this chapter has shown, process automation is a centerpiece of digitalization efforts. This makes workflow engines a vital building block in modern architectures. Fortunately, we have great technology available today, which is very different from old-school BPM suites. It is not only developer-friendly, but also highly performant and scalable.
Workflow engines solve problems around state handling and allow you to model and execute graphical process models to automate the control flow of processes. This helps you to avoid Wild West integration and fosters business–IT collaboration when automating processes. You saw a first example of a process model here, directly executed on a workflow engine; this is something that will be explained further in the next chapter.
Get Practical Process Automation now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

