Preface
Natural language processing (NLP) is a field at the intersection of computer science, artificial intelligence, and linguistics. It concerns building systems that can process and understand human language. Since its inception in the 1950s and until very recently, NLP has primarily been the domain of academia and research labs, requiring long formal education and training. The past decade’s breakthroughs have resulted in NLP being increasingly used in a range of diverse domains such as retail, healthcare, finance, law, marketing, human resources, and many more. There are a range of driving forces for these developments:
- Widely available and easy-to-use NLP tools, techniques, and APIs are now all-pervading in the industry. There has never been a better time to build quick NLP solutions.
- Development of more interpretable and generalized approaches has improved the baseline performance for even complex NLP tasks, such as open-domain conversational tasks and question answering, which were not practically feasible before.
- More and more organizations, including Google, Microsoft, and Amazon, are investing heavily in more interactive consumer products, where language is used as the primary medium of communication.
- Increased availability of useful open source datasets, along with standard benchmarks on them, has acted as a catalyst in this revolution, as opposed to being impeded by proprietary datasets only available to limited organizations and individuals.
- The viability of NLP has moved beyond English or other major languages. Datasets and language-specific models are being created for the less-frequently digitized languages too. A fruitful product that came out this effort was a near-perfect automatic machine translation tool available to all individuals with a smartphone.
With this rapidly expanding usage, a growing proportion of the workforce that builds these NLP systems is grappling with limited experience and theoretical knowledge about the topic. This book addresses this need from an applied perspective. Our book aims to guide the readers to build, iterate, and scale NLP systems in a business setting, and to tailor them for various industry verticals.
Why We Wrote This Book
There are many popular books on NLP available. While some of these serve as textbooks, focusing on theoretical aspects, some others aim to introduce NLP concepts through a lot of code examples. There are a few others that focus on specific NLP or machine learning libraries and provide “how-to” guides on solving different NLP problems using the libraries. So, why do we need another book on NLP?
We have been building and scaling NLP solutions for over a decade at leading universities and technology companies. While mentoring colleagues and other engineers, we noticed a gap between NLP practice in the industry and the NLP skill sets of new engineers and those who are just starting with NLP in particular. We started understanding these gaps even better during NLP workshops we were conducting for industry professionals, where we noticed that business and engineering leaders also have these gaps.
Most online courses and books tackle NLP problems using toy use cases and popular (often large, clean, and well-defined) datasets. While this imparts the general methods of NLP, we believe it does not provide enough of a foundation to tackle new problems and develop specific solutions in the real world. Commonly encountered problems while building real-world applications, such as data collection, working with noisy data and signals, incremental development of solutions, and issues involved in deploying the solutions as a part of a larger application, are not dealt with by existing resources, to the best of our knowledge. We also saw that best practices to develop NLP systems were missing in most scenarios. We felt a book was needed to bridge this gap, and that is how this book was born!
The Philosophy
We want to provide a holistic and practical perspective that enables the reader to successfully build real-world NLP solutions embedded in larger product setups. Thus, most chapters are accompanied by code walkthroughs in the associated Git repository. The book is also supplemented with extensive references for readers who want to delve deeper. Throughout the book, we start with a simple solution and incrementally build more complex solutions by taking a minimum viable product (MVP) approach, as commonly found in industry practice. We also give tips based on our experience and learnings. Where possible, each chapter is accompanied by a discussion on the state-of-the-art in that topic. Most chapters conclude with a case study of real-world use cases.
Consider the task of building a chatbot or text classification system at your organization. In the beginning there may be little or no data to work with. At this point, a basic solution using rule-based systems or traditional machine learning will be apt. As you accumulate more data, more sophisticated NLP techniques (which are often data intensive) can be used, including deep learning. At each step of this journey there are dozens of alternative approaches one can take. This book will help you navigate this maze of options.
Scope
This book provides a comprehensive view on building real-world NLP applications. We will cover the complete lifecycle of a typical NLP project—from data collection to deploying and monitoring the model. Some of these steps are applicable to any ML pipeline, while some are very specific to NLP. We also introduce task-specific case studies and domain-specific guides to build an NLP system from scratch. We specifically cover a gamut of tasks ranging from text classification to question answering to information extraction and dialog systems. Similarly, we provide recipes to apply these tasks in domains ranging from e-commerce to healthcare, social media, and finance. Owing to the depth and breadth of the topics and scenarios we cover, we will not go step by step explaining the code and all the concepts. For details of the implementation, we have provided detailed source code notebooks. The code snippets in this book cover the core logic and often skip introductory steps like setting up a library or importing a package as they are covered in the associated notebooks. To cover the wide range of concepts we have given more than 450 extensive references to delve deeper into these topics. This book will be a day-to-day cookbook giving you a pragmatic view while building any NLP system, as well as be a stepping stone to broaden the application of NLP into your domain.
Who Should Read This Book
This book is for anyone involved in building NLP applications for real-world use cases. This includes software developers and testers, machine learning engineers, data engineers, MLOps engineers, NLP engineers, data scientists, product managers, people managers, VPs, CXOs, and startup founders. This also includes those involved in data creation and annotation processes—in short anyone and everyone who is involved in any way in building NLP systems in industry. While not all chapters are useful for people with all roles, we tried to give lucid explanations using less technical jargon and more intuitive understanding wherever possible. We believe there is something in every chapter for all potential readers interested in getting a holistic perspective about building NLP applications.
Some chapters or sections can be understood without much coding experience and code bits can be skipped as needed. For example, the first two sections in Chapter 1 and Chapter 9, or the sections “The Data Science Process” and “Making AI succeed in your organization” in Chapter 11 can be understood without any coding experience by all groups of readers. As you progress through the book, you will find more such sections in all chapters. However, to extract maximum benefit from this book, its notebooks, and references, we expect the reader to have the following background:
- Intermediate proficiency in Python programming. For example, understanding Python features such as list comprehension, writing functions and classes, and using existing libraries.
- Familiarity with various aspects of the software development life cycle (SDLC) such as design, development, testing, DevOps, etc.
- Basics of machine learning, including familiarity with commonly used machine learning algorithms such as logistic regression and decision trees and the ability to use them in Python with existing libraries such as scikit-learn.
- Basic knowledge of NLP is useful but not mandatory. Having an idea of tasks such as text classification and named entity recognition is also helpful.
What You Will Learn
Our primary audience is comprised of engineers and scientists involved in building real-world NLP systems for different verticals. Some of the common job titles are: Software Engineer, NLP Engineer, ML Engineer, and Data Scientist. The book may also be helpful for product managers and engineering leaders. However, it may not be as helpful for those pursuing cutting-edge research in NLP because we do not cover in-depth theoretical and technical details related to NLP concepts. With this book, you will:
- Understand the wide spectrum of problem statements, tasks, and solution approaches within NLP.
- Gain experience in implementing and evaluating different NLP applications and applying machine learning and deep learning methods for this process.
- Fine-tune an NLP solution based on the business problem and industry vertical.
- Evaluate various algorithms and approaches for the given task, dataset, and stage of the NLP product.
- Plan the lifecycle of the NLP product and produce software solutions following best practices around release, deployment, and DevOps for NLP systems.
- Understand best practices, opportunities, and the roadmap for NLP from a business and product leader’s perspective.
You will also learn to adapt your solutions for different industry verticals like healthcare, finance, and retail. Moreover, you will learn about specific caveats you will encounter in each.
Structure of the Book
The book is divided into four sections. Figure P-1 illustrates the chapter organization. Isolated chapters that are not directly connected to other chapters are easiest to skip while moving forward.
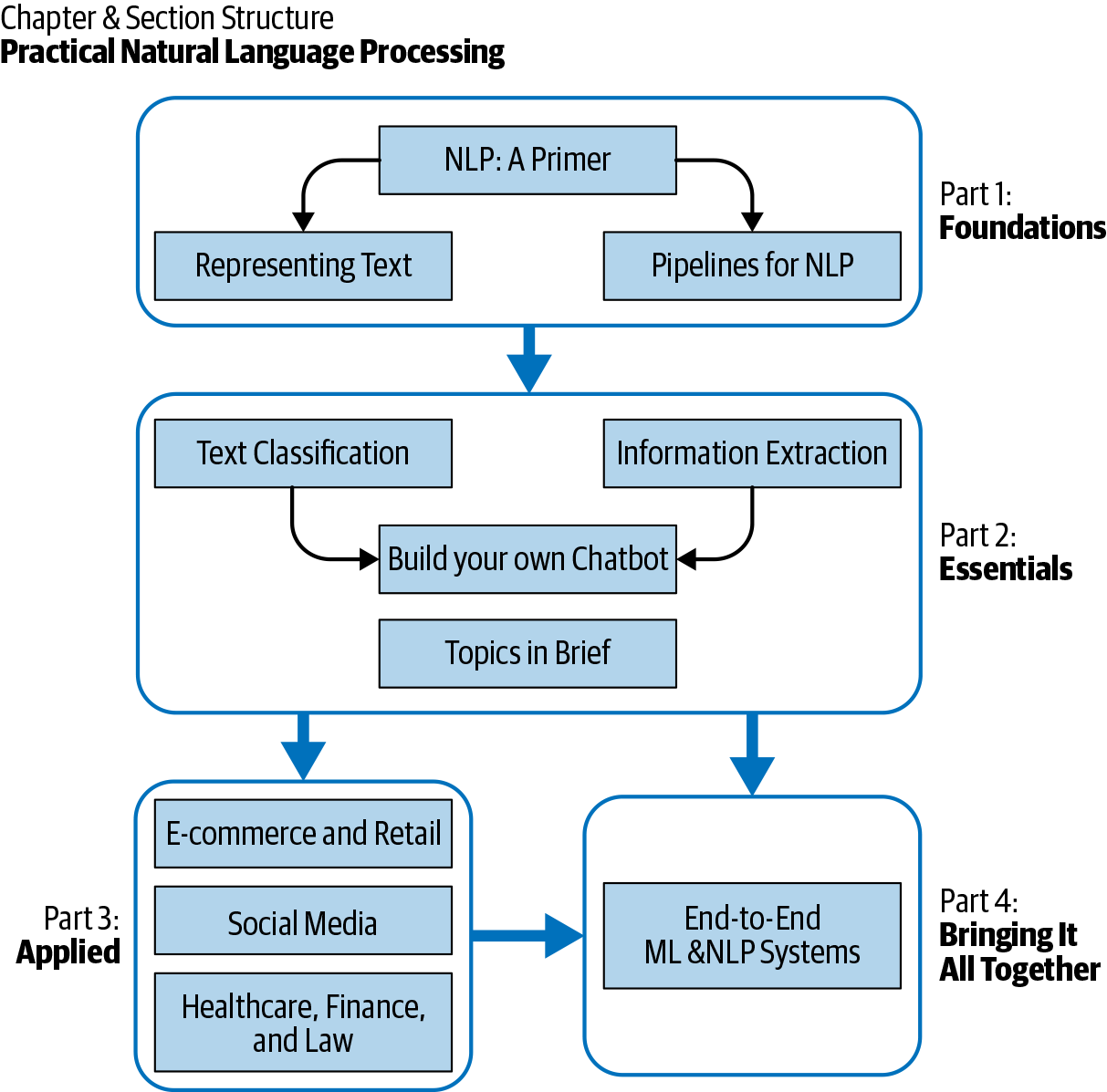
Figure P-1. How the book’s sections are structured
Part I, Foundations acts as a bedrock for the rest of the book, by giving an overview of NLP (Chapter 1), discussing typical data processing and modeling pipelines used in building NLP systems (Chapter 2), and introducing different ways of representing textual data in NLP (Chapter 3).
Part II, Essentials, focuses on the most common NLP applications, with an emphasis on real-world use cases. Where possible, we show multiple solutions to the problem at hand to demonstrate how to choose among different options. Some applications include text classification (Chapter 4), information extraction (Chapter 5), and the building of chat bots (Chapter 6). We also introduce other applications, such as search, topic modeling, text summarization, and machine translation, along with a discussion about practical use cases (Chapter 7).
Part III, Applied (Chapters 8–10) specifically focuses on three industry verticals where NLP is heavily used, with a detailed discussion on those domains’ specific problems and how NLP is useful in addressing them.
Finally, Part IV (Chapter 11) brings all the learning together by dealing with the issues involved in end-to-end deployment of NLP systems in practice.
How to Read This Book
How one reads the book depends on their role and objective. For a data scientist or an engineer delving into NLP, we recommend reading Chapters 1–6 and then focusing on the particular domain or subproblem of interest. For someone in a leadership role, we recommend focusing on Chapters 1, 2, and 11. They might want to give extra focus to case studies for Chapters 3–7, which provide more ideas on the process of building NLP applications from scratch. A product leader might want to delve deep into the references provided for relevant chapters, as well as Chapter 11.
NLP applications for various domains can be different from the general problems covered in Chapters 3–7. That is why we have focused more on certain domains such as e-commerce, social media, healthcare, finance, and law. If your interest or work takes you to these areas, you can dig deeper into those chapters and corresponding references.
Conventions Used in This Book
The following typographical conventions are used in this book:
- Italic
-
Indicates new terms, URLs, email addresses, filenames, and file extensions.
Constant width-
Used for program listings, as well as within paragraphs to refer to program elements such as variable or function names, databases, data types, environment variables, statements, and keywords.
Constant width bold-
Shows commands or other text that should be typed literally by the user.
Constant width italic-
Shows text that should be replaced with user-supplied values or by values determined by context.
Tip
This element signifies a tip or suggestion.
Note
This element signifies a general note.
Warning
This element indicates a warning or caution.
Using Code Examples
Supplemental material (code examples, exercises, etc.) is available for download at https://oreil.ly/PracticalNLP.
If you have a technical question or a problem using the code examples, please send email to bookquestions@oreilly.com.
This book is here to help you get your job done. In general, if example code is offered with this book, you may use it in your programs and documentation. You do not need to contact us for permission unless you’re reproducing a significant portion of the code. For example, writing a program that uses several chunks of code from this book does not require permission. Selling or distributing examples from O’Reilly books does require permission. Answering a question by citing this book and quoting example code does not require permission. Incorporating a significant amount of example code from this book into your product’s documentation does require permission.
We appreciate, but generally do not require, attribution. An attribution usually includes the title, author, publisher, and ISBN. For example: “Practical Natural Language Processing by Sowmya Vajjala, Bodhisattwa Majumder, Anuj Gupta, and Harshit Surana (O’Reilly). Copyright 2020 Anuj Gupta, Bodhisattwa Prasad Majumder, Sowmya Vajjala, and Harshit Surana, 978-1-492-05405-4.”
If you feel your use of code examples falls outside fair use or the permission given above, feel free to contact us at permissions@oreilly.com.
O’Reilly Online Learning
Note
For more than 40 years, O’Reilly Media has provided technology and business training, knowledge, and insight to help companies succeed.
Our unique network of experts and innovators share their knowledge and expertise through books, articles, and our online learning platform. O’Reilly’s online learning platform gives you on-demand access to live training courses, in-depth learning paths, interactive coding environments, and a vast collection of text and video from O’Reilly and 200+ other publishers. For more information, visit http://oreilly.com.
How to Contact Us
Please address comments and questions concerning this book to the publisher:
- O’Reilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (in the United States or Canada)
- 707-829-0515 (international or local)
- 707-829-0104 (fax)
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at https://oreil.ly/PNLP.
Email bookquestions@oreilly.com to comment or ask technical questions about this book.
For news and information about our books and courses, visit http://oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://youtube.com/oreillymedia
Further Information
In the GitHub repo you will find notebooks explaining various concepts covered in the book. The notebooks have been organized by chapter. We also provide additional notebooks, not necessarily covered in the book.
Book website: http://www.practicalnlp.ai
The world of NLP is always evolving. To stay updated on how concept mentioned in the book fit into the broader context one, two, and five years from now, follow our blog. We keep it updated with relevant writeups and articles, and tag every post with the book’s corresponding chapter title.
Contact the authors:
- Email: authors@practicalnlp.ai
- Linkedin: https://linkedin.com/company/practical-nlp
- Twitter: https://twitter.com/PracticalNLProc
- Facebook: https://oreil.ly/facebookPNLP
Acknowledgments
A book like this is a compendium of knowledge; hence, it cannot exist in isolation. While writing this book, we drew a lot of inspiration and information from several books, research papers, software projects and numerous other resources on the internet. We thank the NLP and Machine Learning community for all their efforts. We have merely stood on the shoulders on these giants. We also thank various people who attended some of the authors’ talks and workshops and participated in discussions that lead to the idea of writing this book and shaping its premise. This book is the result of a long collaborative effort and several people supported us in different ways in our endeavor.
We thank the O’Reilly reviewers Will Scott, Darren Cook, Ramya Balasubramaniam, Priyanka Raghavan, and Siddharth Narayanan for their meticulous, invaluable, and detailed comments which helped us improve earlier drafts. Detailed feedback from Siddharth Sharma, Sumod Mohan, Vinayak Hegde, Aasish Pappu, Taranjeet Singh, Kartikay Bagla, and Varun Purushotham were instrumental in improving the quality of the content.
We are also very thankful to Rui Shu, Shreyans Dhankhar, Jitin Kapila, Kumarjit Pathak, Ernest Kirubakaran Selvaraj, Robin Singh, Ayush Datta, Vishal Gupta, and Nachiketh for helping us prepare the early versions of code notebooks. We would especially like to thank Varun Purushotham, who spent several weeks reading and rereading our drafts and preparing and cross-checking the code notebooks. This book would not be the same without his contribution.
We would like to thank the O’Reilly Media team, without whom this would not have been possible: Jonathan Hassell, for giving us this opportunity; Melissa Potter, for regularly following up with us throughout this journey and patiently answering all our questions! Beth Kelly and Holly Forsyth, for all the help and support in shaping it into a book from the chapter drafts.
Finally, the following are personal thank you notes by each author:
Sowmya: My first and biggest thank you goes to my daughter, Sahasra Malathi, whose birth and first year of life coincided with the writing of this book. It is not easy to write a book, and not easy at all to write it with a newborn. And yet, here we are. Thank you, Sahasra! My mom, Geethamani, and my husband, Sriram, supported my writing by taking up baby care and household duties at different phases of writing. My friends, Purnima and Visala, were always available to listen to my excited updates as well as rants about the book. My boss, Cyril Goutte, encouraged me and checked on my writing progress throughout. Discussions with my former colleagues, Chris Cardinal and Eric Le Fort, taught me a lot about developing NLP solutions for industry problems, without which I perhaps would never have thought of being a part of this kind of book. I thank all of them for their support.
Bodhisattwa: I would like to take this opportunity to thank my parents, their unquestionable sacrifice, and the constant encouragement that made me the person I am today. Their efforts have instilled in me the love and dedication to learning in my life. I am eternally grateful to my advisors, Prof. Animesh Mukherjee and Pawan Goyal, who introduced me to this world of NLP; and Prof. Julian McAuley, who is nothing less than fundamental to my technical, academic, and personal development in my PhD career. The courses taken by my other professors—Taylor Berg-Kirkpatrick, Lawrence Saul, David Kriegman, Debasis Sengupta, Sudeshna Sarkar, and Sourav Sen Gupta—have significantly shaped my learning on the subject. In the early days of the book, my colleagues from Walmart Labs—especially Subhasish Misra, Arunita Das, Smaranya Dey, Sumanth Prabhu, and Rajesh Bhat—gave me the motivation for this crazy idea. To my mentors at Google AI, Microsoft Research, Amazon Alexa, and my labmates from the UCSD NLP Group, thank you for being supportive and helpful in this entire journey. Also, my friends Sanchaita Hazra, Sujoy Paul, and Digbalay Bose, who stood by me through thick and thin in this mammoth project, deserve a special mention. At last, none of this would have been possible without my coauthors, who believed in this project and stayed together till the last bit of it!
Anuj: First and foremost, I would like to express my sincere gratitude to my wife, Anu, and my son, Nirvaan. Without their unwavering support, I would not have been able to devote the last three years to this endeavor. Thank you so much! I would also like to thank my parents and family for their encouragement. A big shout out goes to Saurabh Arora, for introducing me to the world of NLP. Many thanks to my friends, the late Vivek Jain and Mayur Hemani; they have always encouraged me to keep going, especially in hard times. I would also like to thank all of the amazing people involved in machine learning communities in Bangalore; especially: Sumod Mohan, Vijay Gabale, Nishant Sinha, Ashwin Kumar, Mukundhan Srinivasan, Zainab Bawa, and Naresh Jain for all the wonderful and thought-provoking discussions. I would like to thank my colleagues—former and present—at CSTAR, Airwoot, FreshWorks, Huawei Research, Intuit, and Vahan, Inc., for everything they taught me. To my professors, Kannan Srinathan, P.R.K Rao, and B. Yegnanarayana, whose teachings have had a profound impact on me.
Harshit: I want to thank my parents, who have supported and encouraged me to pursue every crazy idea I have had. I cannot thank my dear friends Preeti Shrimal and Dev Chandan enough. They have been with me throughout the book’s entire journey. To my cofounders, Abhimanyu Vyas and Aviral Mathur, thank you for adjusting our startup endeavor to help me complete the book. I want to thank all my former colleagues at Quipio and Notify.io who helped crystalize my thinking, especially Zubin Wadia, Amit Kumar, and Naveen Koorakula. None of this would have been possible without my professors and everything they taught me—thank you, Prof. Luis von Ahn, Anil Kumar Singh, Alan W Black, William Cohen, Lori Levin, and Carlos Guestrin. I also want to acknowledge Kaustuv DeBiswas, Siddharth Narayanan, Siddharth Sharma, Alok Parlikar, Nathan Schneider, Aasish Pappu, Manish Jawa, Sumit Pandey, and Mohit Ranka, who have supported me at various junctures of this journey.
Get Practical Natural Language Processing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

