Chapter 6. Gradient Boosting Machines
A gradient boosting machine (GBM, from now on) is another decision tree algorithm, just like random forest (Chapter 5). If you skipped that chapter, and also don’t know what decision trees are, I suggest you go back and at least read some of it; this next section is going to talk more about how GBMs are different, and the pros and cons of their difference. Then, as in other chapters, we’ll see how the H2O implementation of GBM performs out-of-the-box on our data sets, and then how we can tune it.
Boosting
Just like random forest, GBM is an ensemble method: we’re going to be making more than one tree, then combining their outputs. Boosting is the central idea here. What is getting the “boost” is the importance of the harder-to-learn training data. Imagine a data set with just 10 rows (10 examples to learn from) and two numeric predictor columns (x1, x2), and we are trying to learn to distinguish between two possible values: circle or cross.
The very simplest decision tree we can make has just one node; I will represent it with a straight line in the following diagrams, which divides our training data into two. Unless we get lucky, chances are it has made some mistakes. Figure 6-1 shows the line it chose on its first try.
The truth table from our first decision tree looks like:
Correct
Circle Cross
Circle 3 1
Cross 3 3
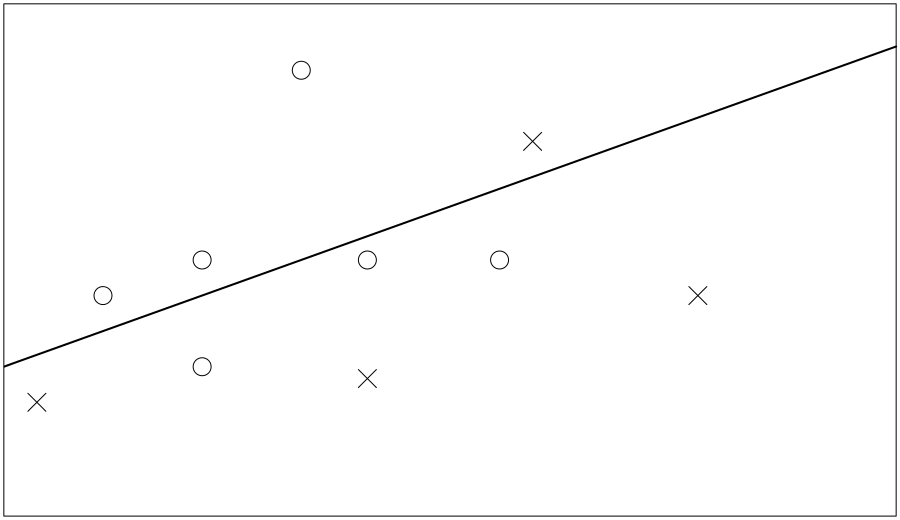
Figure 6-1. First try ...
Get Practical Machine Learning with H2O now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

