Chapter 1. Introduction to Lakehouse Architecture
All data practitioners, irrespective of their job profiles, perform two common and foundational activities—asking questions and finding answers! Any data person, whether they’re a data engineer, data architect, data analyst, data scientist, or even a data leader like a chief information officer (CIO) or chief data officer (CDO), must be curious and ask questions.
Finding answers to complex questions is difficult. But the more challenging task is to ask the right questions. The “art of the possible” can only be explored by: (1) asking the right questions and (2) uncovering answers by leveraging the data. However simple this might sound, an organization needs an entire data platform to enable users to perform these tasks. This platform must support data ingestion and storage, provide tools for users to ask and discover new questions, perform advanced analysis, predict and forecast results, and generate insights. The data platform is the infrastructure that enables users to leverage data for business benefits.
To implement such data platforms, you need a robust data architecture—one that can help you define the core components of the data platform and establish the design principles for putting it into practice. Traditionally, organizations have used data warehouse or data lake architectures to implement their data platforms. Both of these architectural approaches have been widely adopted across industries. These architectures have also evolved to leverage continuously improving modern technologies and patterns. Lakehouse architecture is one such modern architectural pattern that has developed in the last few years, and it has become a popular choice for data architects who are designing data platforms.
In this chapter, I’ll introduce you to the fundamental concepts related to data architecture, data platforms and their core components, and how data architecture helps build a data platform. Then, I’ll explain why there is a need for new architectural patterns like the lakehouse. You’ll learn lakehouse architecture fundamentals, characteristics, and the benefits of implementing a data platform using lakehouse architecture. I’ll conclude the chapter with important takeaways, which will summarize everything we’ve discussed and help you remember the key points while reading the subsequent chapters in this book.
Let’s start with the fundamentals of data architecture.
Understanding Data Architecture
The data platform is the end result of implementing a data architecture using the chosen technology stack. Data architecture is the blueprint that defines the system that you aim to build. It helps you visualize the end state of your target system and how you plan to achieve it. Data architecture defines the core components, the interdependencies between these components, fundamental design principles, and processes required to implement your data platform.
What Is Data Architecture?
To understand data architecture, consider this real-world analogy of a commercial construction site, such as a shopping mall or large residential development.
Building a commercial property requires robust architecture, innovative design, an experienced architect, and an army of construction workers. Architecture plays the most crucial role in development—it ensures that the construction survives all weather conditions, helps people easily access and navigate through various floors, and enables quick evacuation for people in an emergency. Such architectures are based on certain guiding principles that define the core design and layout of the building blocks. Whether you are constructing a residential property, a commercial complex, or a sports arena, the foundational pillars and the core design principles for the architecture remain the same. However, the design patterns—interiors, aesthetics, and other features catering to the users—differ.
Similar to building a commercial property, data architecture plays the most crucial role when developing robust data platforms that will support various users and various data and analytics use cases. To build a platform that is resilient, scalable, and accessible to all users, the data architecture should be based on core guiding principles. Regardless of the industry or domain, the data architecture fundamentals remain the same.
Data architecture, like the design architecture for a construction site, plays a significant role in determining how users adapt to the platform. The section will cover the importance of data architecture in the overall process of implementing a data platform.
How Does Data Architecture Help Build a Data Platform?
Architecting the data platform is probably the most critical phase of a data project and often impacts key outcomes like the platform’s user adoption, scalability, compliance, and security. Data architecture helps you define the following foundational activities that you need to do to start building your platform.
Defining core components
The core components of your data platform help perform daily activities like data ingestion, storage, transformation, consumption, and other common services related to management, operations, governance, and security. Data architecture helps you define these core components of your data platform. These core components are discussed in detail in the next section.
Defining component interdependencies and data flow
After defining the core components of your platform, you need to determine how they will interact. Data architecture defines these dependencies and helps you to visualize how the data would flow between producers and consumers. Architecture also helps you determine and address any specific limitations or integration challenges you may face while moving data across these components.
Defining guiding principles
As part of the data architecture design process, you’ll also define the guiding principles for implementing your data platform. These principles help build a shared understanding between the various data teams that are using the platform. They ensure everyone follows the same design approach, common standards, and reusable frameworks. Defining shared guiding principles allows you to implement an optimized, efficient, and reliable data platform solution. Guiding principles can be applied across various components and are defined based on the data architecture capabilities and limitations. For example, if your platform has multiple business intelligence (BI) tools provisioned, a guiding principle should specify which BI tool to use based on the data consumption pattern or use case.
Defining the technology stack
The architecture blueprint also informs the tech stack of the core components in the platform. When architecting the platform, it might be challenging to finalize all the underlying technologies—a detailed study of limitations and benefits, along with proof of concept (PoC), would be required to finalize them. Data architecture helps to define key considerations for making these technology choices and the desired success factors when carrying out any PoC activities and finalizing the tech stack.
Aligning with overall vision and data strategy
Finally, and most critically, data architecture helps you implement a data platform that is aligned with your overall vision and your organization’s data strategy for achieving its business goals. For example, data governance is integral to any organization’s data strategy. Data architecture defines the components that ensure data governance is at the core of each process. These are components like metadata repositories, data catalogues, access controls, and data sharing principles.
Note
Data governance is an umbrella term that comprises various standards, rules, and policies that ensure all data processes follow the same formal guidelines. These guidelines help to assure compliance with geographic or industry regulations, as well as to ensure the data is trustworthy, high quality, and delivers value. Organizations should follow data governance policies across all data management processes to maintain consumers’ trust in data and to remain compliant. Data governance helps organizations maintain better control over their data, to easily discover data, and to securely share data with consumers.
Now that you better understand data architecture and its significance in implementing data platforms, let’s discuss the core components of a data platform.
Core Components of a Data Platform
In this section, we’ll look at the core components of a data platform and how their features contribute to a robust data ecosystem. Figure 1-1 shows the core components for implementing a data platform based on a data architecture blueprint.
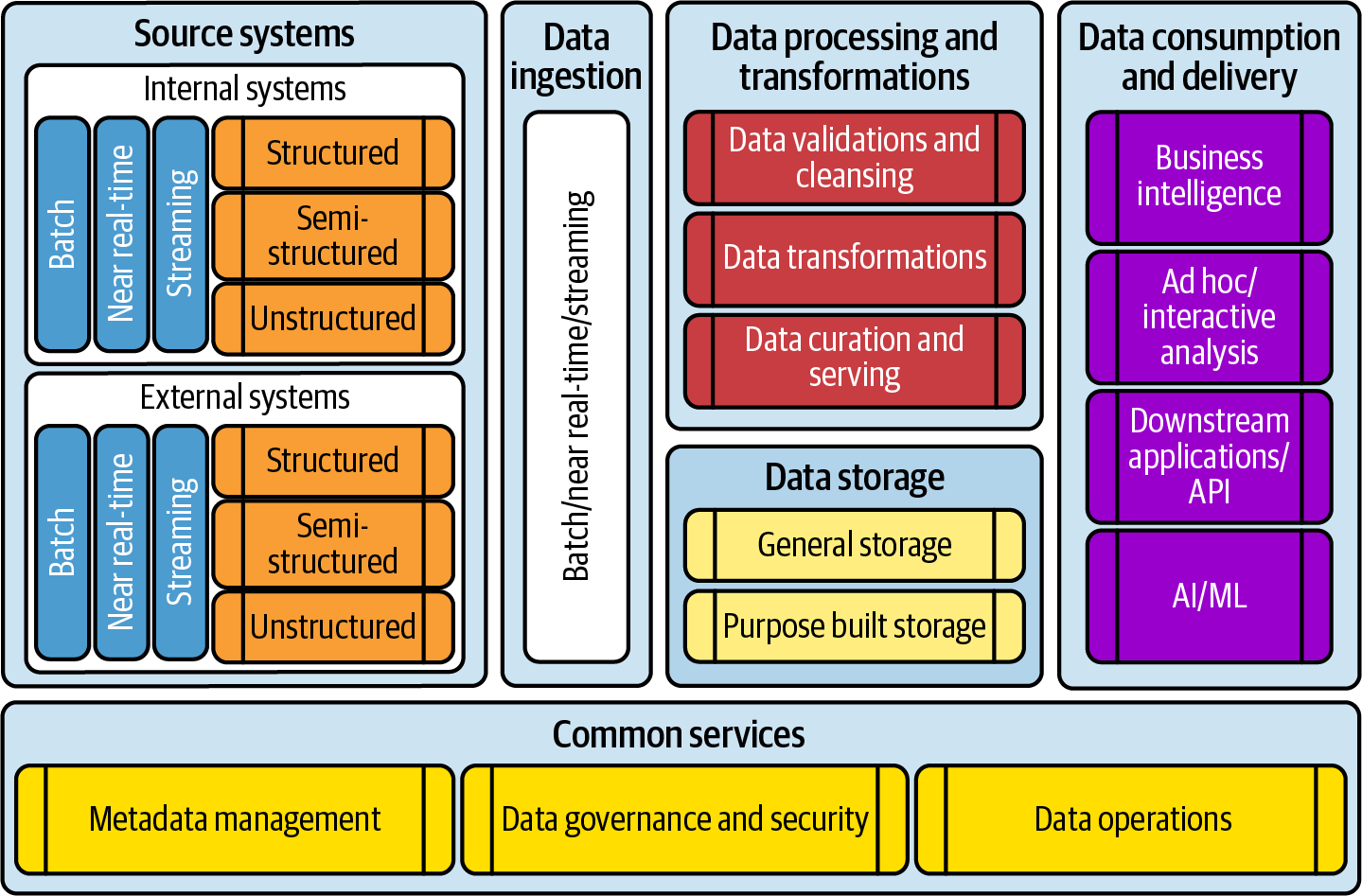
Figure 1-1. Core components of a data platform
Let’s explore these core components and their associated processes.
Source systems
Source systems provide data to the data platform that can be used for analytics, business intelligence (BI), and machine learning (ML) use cases. These sources include legacy systems, backend online transaction processing (OLTP) systems, IoT devices, clickstreams, and social media. Sources can be categorized based on multiple factors.
Internal and external source systems
Internal sources are the internal applications within an organization that produce data. These include in-house customer relationship management (CRM) systems, transactional databases, and machine-generated logs. Internal sources can be owned by internal domain-specific teams that are responsible for generating the data.
Data platforms often need data from external systems to enhance their internal data and gain competitive insights. Examples of data that come from external source systems are exchange rates, weather information, and market research data.
Batch, near real-time, and streaming systems
Until a couple of decades ago, most source systems could send only batch data, meaning that they would generally send the data at the end of the day as a daily batch process. With the increasing demand for more near real-time insights and analytics, source systems started sending data on a near real-time basis. These systems can now share data as multiple, smaller micro-batches at a fixed interval that can be as low as a few minutes. Sources like IoT devices, social media feeds, and clickstreams send data as a continuous stream that should be ingested and processed in real time to get the maximum value.
Structured, semi-structured, and unstructured data
Source systems traditionally produced only structured data in tables or fixed structured files. With advances in data interchange formats, there was increased production of semi-structured data in the form of XML and JSON files. And as organizations started implementing big data solutions, they started generating large volumes of unstructured data in the form of images, videos, and machine logs. Your data platform should support all types of source systems, sending different types of data at various time intervals.
Data ingestion
Data ingestion is the process of extracting data from source systems and loading it into your data platform. As seen in the earlier section, based on the source system’s capability to produce and send data, the ingestion framework must be implemented to build a batch, near real-time, or streaming system.
Batch ingestion
Data that is sent once a day (either as the end-of-day or the start-of-day process) can be ingested as a batch process into the data platform. This is the most common ingestion pattern used in traditional data warehouse architectures for generating daily management information systems (MIS) or regulatory reports.
Near real-time
For more time-sensitive data, ingestion can be done as micro-batches or in near real-time. The ingestion intervals for micro-batches can be between a few hours to a few minutes, while near real-time data can be ingested in a gap of a few minutes to seconds. The data ingestion tools should meet the required service level agreements (SLAs) as per the business demands.
Streaming
Streaming analytics use cases are extremely sensitive to time and need an architecture that supports data ingestion in real time—as in, within a few milliseconds from the time data is generated. Because this data is time critical, it can rapidly lose value if not ingested and processed immediately. Your data platform’s ingestion components should be able to support low-latency requirements to make the data available as soon as the source systems generate it.
Tip
A good practice for designing the ingestion process is to design reusable, configurable frameworks that can ingest data from multiple source feeds or entities. This helps to quickly onboard new entities on the data platform. While designing the data architecture, you can consider building reusable solutions across these core components to reduce implementation efforts.
Data storage
Once the data is ingested, it must be stored for durability, easy discovery, and further analysis. Data storage components enable the effective storing of various data types. These components persist data that can be retrieved as and when required and should provide high availability and high durability.
Depending on the use cases, you can categorize data storage into two broad categories: general storage and purpose-built storage.
General storage
All data type in object storage like Hadoop Distributed File System (HDFS), Amazon Simple Storage Service (S3), Azure Data Lake Storage (ADLS), or Google Cloud Storage (GCS). These object stores support persisting the structured, semi-structured, or unstructured data. They provide high availability and durability and are also cost efficient, making them one of the best choices for storing data for a longer durations can be stored
Note
ADLS Gen 2 is a cloud object storage service provided by Azure that is built on Azure Blob Storage. It provides high availability, features for disaster recovery, different storage tiers to save cost and other big data capabilities. It is widely used to implement data lakes within the Azure ecosystem. Previously, Azure also offered ADLS Gen 1 (based on HDFS), which has now been retired. Throughout this book, when we refer to ADLS, we mean the ADLS Gen 2 service.
Purpose-built storage
While object storages are good for cost-effective, long-term storage, you might need a purpose-built storage system that can exhibit features like quick access, faster retrieval, key-based searches, columnar storage, and high concurrency.
There are different technologies and architectural patterns to implement these purpose-built storage systems:
- Data warehouses
-
Provide support for Online Analytical Processing (OLAP) workloads
- Relational database management systems (RDBMS)
-
Support Online Transaction Processing (OLTP) systems for application backends
- In-memory databases
- Graph databases
The data storage components are the most widely used components within a data platform. From storing long-term data to serving it quickly, all major activities happen through these components with the help of a compute engine.
Data processing and transformations
Raw data collected from source systems must be validated, cleansed, integrated, and transformed per business requirements. As part of data processing, the following steps are carried out to transform the raw data into a more consumable end product.
Data validation and cleansing
When data is ingested from source systems, it is in raw form and needs validations and cleansing before it can be made available to end users. Both of these steps are important to ensure that data accuracy does not get compromised during its movement to the higher storage zones of the lakehouse ecosystem. The hierarchy of data storage zones—raw, cleansed, curated, and semantic— will be discussed in detail in Chapter 7.
Input data is validated as the first step post-ingestion. These validations apply to structured data and, to some extent, semi-structured data that is used for reports and insight generation. During this step, data flows through various validation lenses, including the following technical and business validations:
- Technical validations
-
Mainly related to the data types, data formats, and other checks that are technical in nature and can be applied across any domain or industry
- Business validations
-
Domain- or function-specific and related to particular values in attributes, and their accuracy or completeness
- Schema validations
-
What the input data feeds should follow, as per the agreed schema defined in the specifications or data contracts
Note
Data contract is a relatively new term that describes the agreement between the data producer and its consumers. It defines various parameters associated with the data produced, like its owner, frequency, data type, and format. Data contracts ensure there is a common understanding between producers and consumers of data.
Data transformation
The process of transforming raw data into useful information is known as data transformation. It can consist of a series of transformations that first integrates the data received from multiple source systems and then transforms it into a consumable form that downstream applications, business users, and other data consumers can use per their requirements.
There are multiple data transformations that you can apply based on your use case and requirements. The common data transformations are:
- Data integration
-
As data is ingested from multiple source systems, you must combine it to get an integrated view. An example is integrating customer profile data from external source systems, internal systems, or marketing applications. Different source systems can supply data in different formats and so we need to bring it into a common, standard format for consumption by downstream applications. For example, consider the “date of birth” attribute that can have different formats (like MM/DD/YYYY or DD-MM-YY) in different source systems. It is important to transform all records across source systems into a standard format (like DD/MM/YYYY) before storing them in your central data platform. As part of the transformation process, this integration is done before storing data in the higher storage zones.
- Data enhancement
-
To make data more meaningful, it must be enhanced, or augmented with external data. Examples of data enhancement are:
-
Augmenting your internal data with external exchange rates from third-party applications to calculate global daily sales
-
Augmenting your internal data with external data from credit rating agencies to calculate credit scores of your customers
-
- Data aggregation
-
Data needs to be summarized according to business needs for faster querying and retrieval. An example would be aggregating data based on date, product, and location to get summarized views of sales.
Data curation and serving
In the final data processing step, data is curated and served per the business processes and requirements. Data gets loaded in the curated storage zone, based on an industry-standard data model using modeling approaches like dimension modeling. This arrangement of data using industry-specific data models facilitates faster and easier insight generation and reporting. Curated data can then be used to create data products that consumers can use directly to fulfill their business needs.
Note
Data product is a new term used to define a consumable end product specifically curated for its consumers. Data products are generally created by domain teams responsible for the data. These products can be shared with other domain teams and downstream applications. A data product can be a table, view, report, dashboard, or even a machine learning (ML) model that can be easily discovered and consumed by end users.
Data consumption and delivery
The data consumption components in your platform enable users to access, analyze, query, and consume the data. These can be your BI reporting tools or even ML models that are used for making predictions and forecasting. The various workloads supported by these components include:
Ad hoc/Interactive analysis
Business users, data analysts, and data leaders often need to perform analysis to support ad hoc requirements or to find answers to impromptu questions that pop up during meetings. The components that enable such interactive, ad hoc analysis provide a simple SQL interface.
AI and ML workloads
AI and ML can help support multiple use cases like predictions, forecasting, and recommendations. If these types of use cases exist in your organization, then your data platform should be able to provide tools for the ML lifecycle, including training, deployment, and inferencing the models.
All of these components—BI reporting tools and ML models—enable data consumption and delivery to consumers and play a significant role in increasing user adoption of the platform. These components also provide an interface for users to interact with the data that resides within the platform, and so user experience should be considered when designing the platform.
Common services
There are common services that provide functionality across a data platform and play a significant role in making data easily discoverable, available, and securely accessible for its consumers. These common services are summarized as follows.
Metadata management
These consist of tools and technologies to help you ingest, manage, and maintain metadata within your ecosystem. Metadata helps ease data discoverability and access for users. You can create data catalogs to organize the metadata with details of various tables, attributes, data types, lengths, keys, and other information. Data catalogs help users to more quickly and effectively discover and leverage data.
Data governance and data security
Implementing strong data governance and data security policies is essential in order to:
-
Ensure good data quality to build consumers’ trust in data
-
Meet all relevant regulatory compliance requirements
-
View data lineage to track the flow of data across systems
-
Implement the right levels of access controls for all platform users
-
Share data with internal and external data consumers
-
Manage sensitive data by abstracting it from non-permissioned users
-
Protect data when it is stored or moves within or outside the data platform
These topics will be discussed in detail in Chapter 6.
Data operations
These services help to manage various operations across various stages in the data lifecycle. Data operations enable the following activities:
-
Orchestrating data pipelines and defining schedules to run processes
-
Automating testing, integration, and deployment of data pipelines
-
Managing and observing the health of the entire data ecosystem
Modern data platforms employ data observability features for monitoring the health of data overall.
Note
Data observability is a new term used for understanding the health of data within the ecosystem. It is a process for identifying the issues related to quality, accuracy, freshness, and completeness of data proactively to avoid any data downtimes. Modern data platforms should provide features for data observability, mainly considering the large volumes and rapid data ingestion and processing, wherein any downtime can impact the system severely.
All of these core components form the data platform and enable its users to perform various activities. Data architectures provide the blueprint and guiding principles to build these data platforms. With this basic understanding of data architectures and data platforms and their significance, let’s now discuss a new architectural pattern—the lakehouse—which is the main topic of this book.
Why Do We Need a New Data Architecture?
Data warehouses and data lakes have remained the most popular architectures for implementing data platforms. However, in the last few years, some organizations have strived to implement data platforms by leveraging different architectural approaches.
Their motivations to look for new approaches instead of implementing the well-known traditional data architectures, is mainly twofold:
-
Traditional architectures have several limitations when implemented as standalone systems. I’ll discuss these traditional architectures and their restrictions in Chapter 2.
-
There have been multiple technological advancements in the last few years. Innovations within the cloud space and the maturity of open-source technologies have been the main drivers of these advancements.
Organizations have constantly sought to overcome the limitations of traditional architectures and leverage new technologies to build scalable, secure, and reliable platforms. Organizations, independent service vendors (ISVs), and system integrators (SIs) have tried different and innovative approaches to implement more modern data platforms. Some of these approaches include:
-
A two-tiered architecture combining a data lake and data warehouse to support BI, data analytics, and ML use cases
-
Leveraging hybrid transactional/analytical processing (HTAP) technologies, which use a single storage layer, to unify transactional (OLTP) and analytical (OLAP) workloads
-
Building modern cloud data warehouses that can process unstructured data along with structured and semi-structured data
-
Implementing proprietary storage formats on cloud object storage that can provide warehouse-like performance
-
Building compute engines for performing BI directly on data lakes
All of these efforts indicate a need for a new architectural pattern that can:
-
Support implementation of a simple, unified platform that can handle all data formats and a diverse set of use cases to help users easily consume data
-
Provide the ACID support, excellent BI performance, and access control mechanisms of a data warehouse
-
Provide the scalability, cost efficiency, and flexibility of a data lake
This is how a new pattern—lakehouse architecture—has emerged over the last few years. We’ll talk more about it in the next section.
Lakehouse Architecture: A New Pattern
New tools, products, and open-source technologies have changed how organizations are implementing data ecosystems. These new technologies have helped to simplify complex data architectures, resulting in data platforms that are more reliable, open, and flexible to support a variety of data and analytics workloads.
The data lakehouse (referred to as the lakehouse, or lakehouse architecture throughout this book) is a new architectural pattern that leverages new technology for building simple and open data platforms. As shown in Figure 1-2, a lakehouse is, at the core, a data lake with an additional transactional layer and a performant compute layer. The additional transactional layer gives it data warehouse-like ACID properties and other features.
Note
The additional transactional layer is sometimes referred to as the “metadata layer,” as it provides metadata related to the transaction. To maintain consistency, we will refer to it as a transactional layer throughout the book.
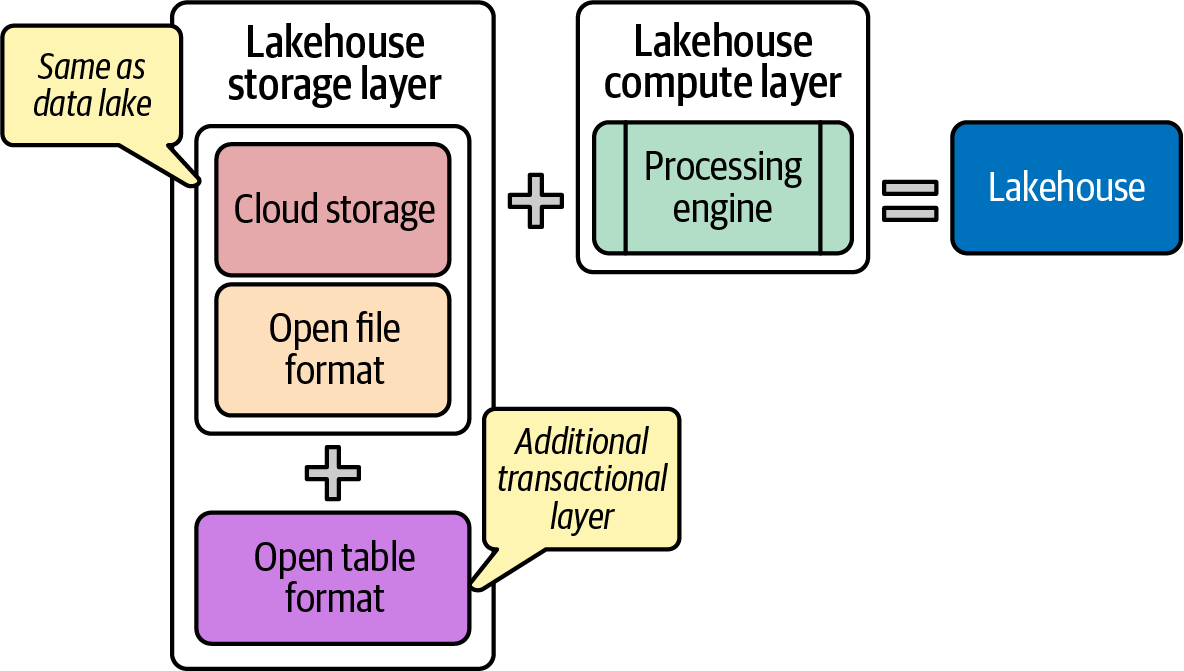
Figure 1-2. Lakehouse architecture layers
We will discuss these layers in more detail soon. But first, let’s spend more time understanding the lakehouse concept and how it combines data warehouse and data lake features.
The Lakehouse: Best of Both Worlds
Data platforms built using lakehouse architecture exhibit features of a data warehouse and a data lake, hence the name lakehouse. Figure 1-3 shows the key lakehouse architecture features, which are a combination of the best features of a data lake and a warehouse. The features of a data lake and a data warehouse will be discussed in more detail in Chapter 2, where I will explain these traditional architectures, their characteristics, and their benefits.
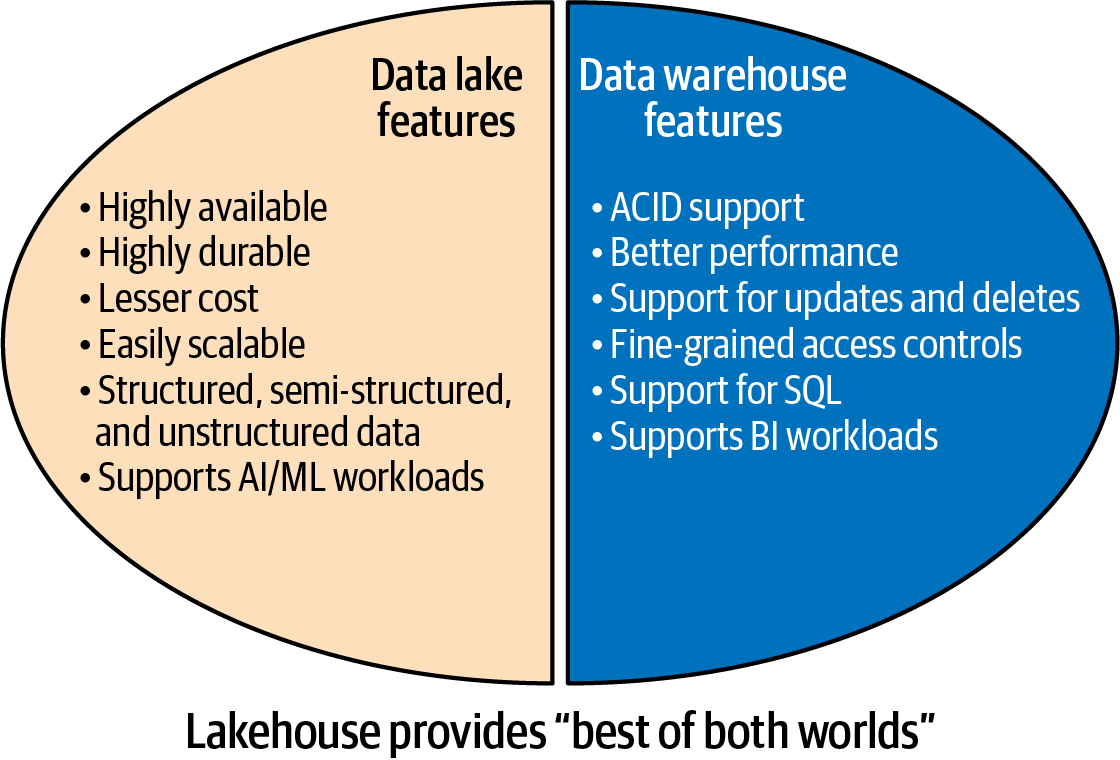
Figure 1-3. Lakehouse features
But how do lakehouses get the best features of both data warehouses and data lakes within a single storage tier? What technologies enable these features?
How does a lakehouse get data lake features?
Like a data lake, a lakehouse uses cloud object storage like Amazon S3, ADLS, or GCS and stores the data in open file formats like Apache Parquet, Apache Avro, or Apache ORC. This cloud storage enables lakehouses to have all the best features of data lakes, like high availability, high durability, cost efficiency, scalability, support for all data types (structured, semi-structured, unstructured), and support for AI and ML use cases.
How does a lakehouse get data warehouse features?
Compared to a data lake, a lakehouse has one additional component: the transactional layer, which is an additional layer on top of the file formats. This extra layer separates a lakehouse from a data lake. It enables lakehouses to get data warehouse capabilities like ACID compliance, support for updates and deletes, better BI performance, and fine-grained access control. The technology used to implement this transactional layer is known as “open table formats,” which we will discuss in detail in the next section.
Lakehouse architecture has attracted interest within the data community, and various organizations have started adopting it to build platforms to support multiple use cases, such as ETL processing, BI, ML, data science, and streaming analytics. Apart from the leading cloud service providers, multiple commercial product vendors provide SaaS or PaaS offerings to support implementing data platforms-based lakehouse architecture. These include products from Databricks, Snowflake, Dremio, and Onehouse.
Let’s dive deeper into lakehouse architecture and the underlying technologies that it uses.
Understanding Lakehouse Architecture
Figure 1-4 shows a simple view of lakehouse architecture, comprised of the storage and compute layers along with the underlying technology options. This is a granular view of Figure 1-2, seen earlier in this chapter.
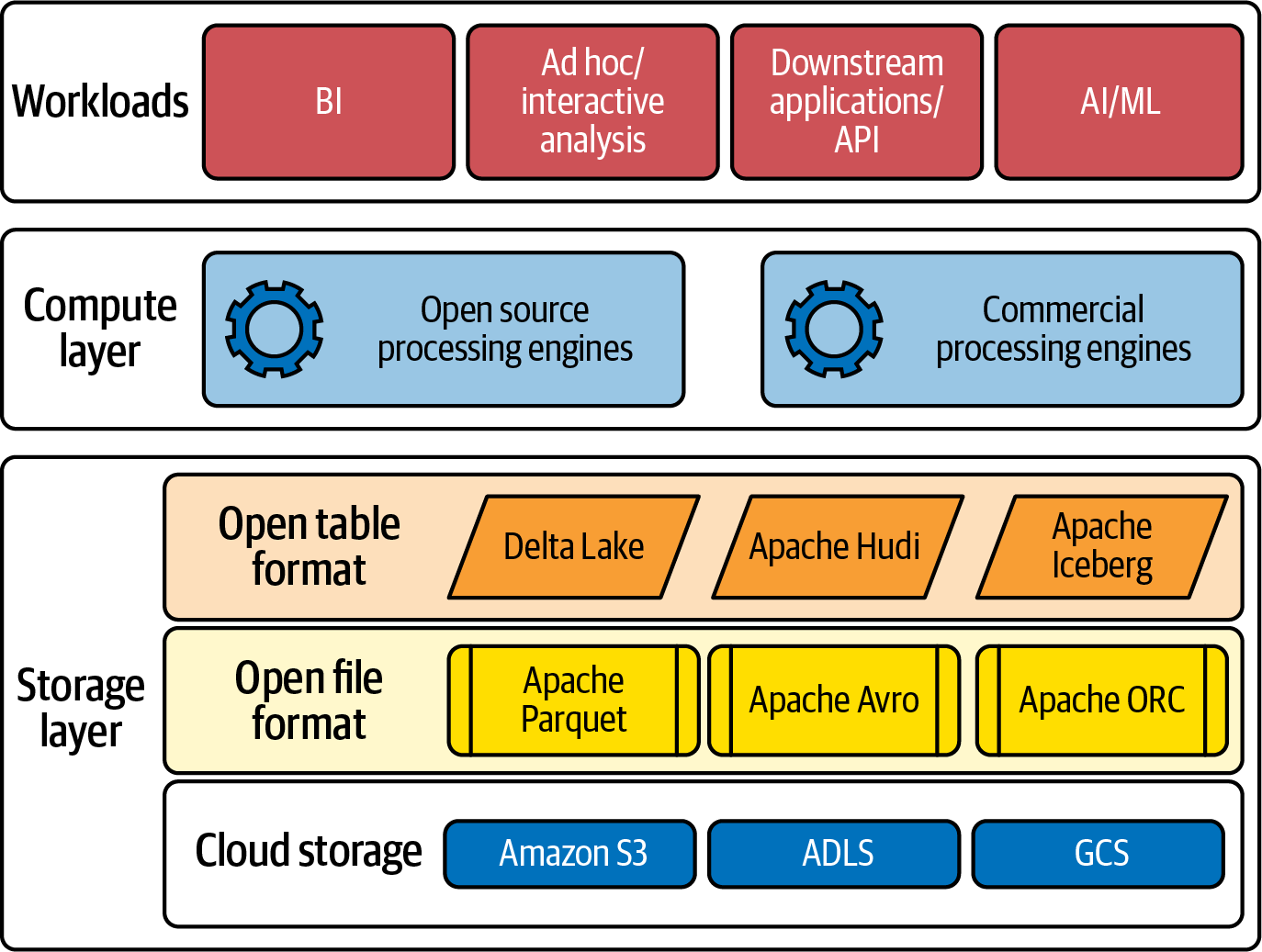
Figure 1-4. More granular view of lakehouse architecture
As we’ve discussed, lakehouse architecture consists of a storage layer and compute layer. Data platforms built using lakehouse architecture enable data and analytics workloads to consume data from the storage layer while using the compute engine.
Storage layer
Let’s first understand the technology options in the storage layer. This layer is comprised of three components: cloud storage, open file format, and open table format.
Cloud storage
Cloud storage is a service that offers the high availability, durability, and scalability required for implementing data lake and lakehouse platforms. Leading cloud service providers offer the following services for implementing lakehouse platforms:
Note
Organizations can also implement a lakehouse using on-premises HDFS storage. Using only cloud object storage for implementing a lakehouse is not necessary. However, considering features like low cost, separation of compute and storage, and easy scalability, it is advisable to use cloud object storage as the underlying infrastructure for implementing a lakehouse.
This book will only discuss modern platforms that organizations implement using cloud technologies. We will learn more about modern platforms in Chapter 2.
Open file formats
Data platforms can store data in different file formats in cloud storage. File formats like CSV, JSON, and XML are the most popular. For analytics platforms, the three most widely adopted file formats used are Parquet, ORC, and Avro.
All of these are open file formats, that is they are part of an open-source ecosystem. These are not proprietary; anyone can easily use them for storing data. Any compatible processing engine can interact with such open file formats. Many other features make these three formats suitable for analytical workloads. We will discuss these file formats in more detail in Chapter 3.
Open table formats
As discussed earlier, open table formats bring transactional capabilities to a data lake to make them a lakehouse. These open table formats are the heart of the lakehouse. There are three such formats gaining popularity among the data community: Apache Iceberg, Apache Hudi, and Linux Foundation’s Delta Lake.
Let’s have a quick look at these three open table formats:
- Apache Iceberg
-
Apache Iceberg is an open table format that can be used with cloud object stores and open file formats like Parquet, Avro, and ORC for implementing lakehouse architecture. It supports features like time travel, schema evolution, and SQL support, making lakehouse implementation faster and easier.
- Apache Hudi
-
Apache Hudi helps to implement a transactional data lake and can be used to bring data warehouse-like capabilities to the data lake. It provides ACID transactional guarantees, incremental processing, time travel capabilities, schema evolution, and enforcement features.
- Linux Foundation’s Delta Lake
-
Started by Databricks as an internal project, the Linux Foundation’s Delta Lake is commonly known as an open-source storage framework for building lakehouse architecture. Delta Lake provides the metadata layer and ACID capabilities to data lakes. It also provides features like time travel, schema enforcements and evolution, and audit trail logging.
Note
There are now two different distributions of Delta Lake. The commercial version comes along with the Databricks platform. The open-source version is available on the Linux Foundation’s website, and you can use it with other non-Databricks environments. Though Databricks has made all of its Delta Lake features open source, the latest open-source version might not be available immediately with managed Apache Spark services like Amazon EMR or Azure Synapse Analytics. You will have to wait till these managed cloud services offer the latest Spark and Delta Lake versions to leverage all of the latest Delta Lake features.
All these open table formats will be discussed in more detail in Chapter 3.
Compute layer
One of the main advantages of lakehouse architecture is its open nature and ability to be directly accessed or queried by any compatible processing engine. It does not need a specific, proprietary engine for running BI workloads or interactive analysis. These compute engines can be open-source or purpose-built commercial query engines designed explicitly for lakehouse architectures.
Commercial engines
These are query engines specifically built for getting better performance for running workloads on lakehouses. Commercial engines are generally built from the ground up, taking into consideration the underlying open data formats and how effectively they can get the best performance. Examples of commercial compute engine vendors are Databricks, Dremio, Snowflake, and Starburst.
Both the storage and compute layers work together to power lakehouse architectures with the best features of data lakes and data warehouses. As a result, lakehouse architecture addresses the limitations of traditional data architectures and support different workloads, from BI to AI, and different downstream applications to leverage data from a data platform.
A data platform based on lakehouse architecture exhibits key characteristics that help solve the limitations of traditional architectures. The following section details these characteristics.
Lakehouse Architecture Characteristics
The following characteristics set lakehouse architecture apart from other traditional data architectures.
Single storage tier with no dedicated warehouse
As seen in earlier sections, a lakehouse, at its core, is a data lake built using cloud object storage with an additional transactional layer. There is no separate storage like a dedicated data warehouse to support BI workloads. All consumers read, access, or query data directly from the data lake. The same cloud object storage supports all use cases, including BI and AI/ML workloads.
Warehouse-like performance on the data lake
Cloud storage is not suitable for BI workloads and lacks the performance provided by purpose-built proprietary storage of cloud data warehouses. Data platforms built using lakehouse architecture provide excellent performance for BI use cases by offering optimization levers at storage and compute layers. You can get excellent performance using the right combination of open data (file and table) formats and compute engines built explicitly for lakehouse architecture.
Decoupled architecture with separate storage and compute scaling
Lakehouse architecture is based on a decoupled approach with separate storage and compute engines. The previous generations of data platforms used architectures with integrated storage and processing layers. Examples are databases, traditional on-premises warehouses, and Hadoop ecosystems. Scaling of storage or compute power was not possible with such integrated architectures.
The decoupled lakehouse architecture helps scale storage and compute capacities individually. You can easily add more storage without increasing the compute capacity and vice versa. Figure 1-5 shows platforms implementing lakehouse architecture with decoupled storage and compute.
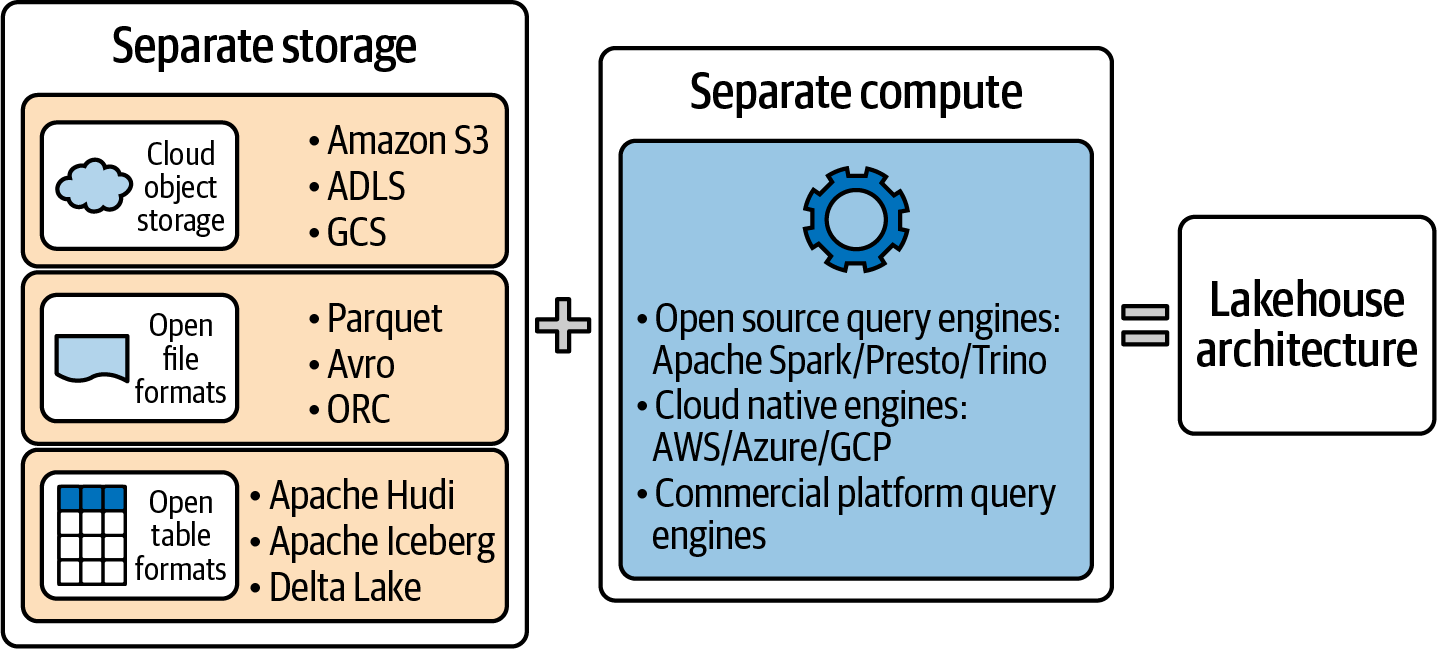
Figure 1-5. Decoupled storage and compute in lakehouse architecture
Open architecture
The lakehouse architecture uses an “open” approach for implementing data platforms. This means you have the freedom to employ open-source data formats and open-source compute engines for your data platforms. Unlike proprietary warehouses, where you have to use the native processing engine bundled within the warehouse software, lakehouses allow you to use any distributed processing engine that is compatible with the underlying storage formats. Such open architecture enables data consumers to access the data directly from cloud storage, without needing vendor-specific software.
Support for different data types
Traditionally, on-premises warehouse architectures only supported structured data. They could not store, manage, or maintain semi-structured and unstructured data. Some modern cloud warehouses can now support semi-structured data like JSON and XML files.
Data platforms built using the lakehouse approach support all data formats—structured, semi-structured, and unstructured images; audio; and video data—within a single storage tier.
Support for diverse workloads
As lakehouse can handle all data formats, it can support all types of workloads, including BI, AI/ML, ETL, and streaming. You do not need to implement separate storage tiers or purpose-built storage to support these workloads. Lakehouse architecture can support all of these within a single storage tier.
Next, let’s discuss the key benefits of lakehouse architecture and how it can help build a simple, unified, and open data platform.
Lakehouse Architecture Benefits
A data platform implemented using the lakehouse approach provides many significant benefits, especially in a world that demands building data platforms that are not just scalable and flexible but also secure and reliable.
The following is a list of benefits that you would get by implementing a data platform based on lakehouse architecture.
Simplified architecture
In lakehouse architecture, all the data resides in a single storage tier. The data architecture is simplified because there is no separate warehouse and the additional ETL pipeline required to move data from data lakes to data warehouses is reduced. Lakehouse architecture also avoids delays, failures, or data quality issues associated with integrating lakes and warehouses.
This architecture with a single storage tier has several benefits:
-
No additional efforts are required to sync data between the data lake and the warehouse. Syncing data between two different storage types is always a challenge.
-
You don’t need to worry about changing data types between data lakes and warehouses. The schema in these two often does not match, as data types can differ.
-
Data governance becomes much easier in the lakehouse as you only need to implement access controls in one place. In a two-tier storage system, you have to maintain separate access control mechanisms to access data from the data lake and warehouse, and ensure these are always in sync.
-
ML workloads can read data from the lakehouse, directly accessing underlying Parquet, Avro, or ORC storage files. This removes the need to copy any aggregated data from the warehouse to the lake if required by ML workloads.
Support for unstructured data and ML use cases
A large volume of data produced in today’s world is unstructured. A lakehouse supports unstructured data along with structured and semi-structured data. This opens up endless possibilities for implementing AI and ML use cases to leverage massive volumes of unstructured data for predictions, forecasting, recommendations, and new insights from data.
No vendor lock-ins
As we’ve discussed, lakehouses use open formats for implementing data platforms. Open formats enable consumers to query and process data using any compatible processing engine that integrates well with the underlying storage formats. Lakehouses use no proprietary storage format that needs a specific vendor’s processing engine. This enables downstream applications to have direct access to data for consumption.
For example, If you implement a two-tier data platform with a data lake and a dedicated warehouse, you must first load the data into the warehouse in order to perform any BI workloads. To query or access this data, you will have to use the proprietary compute engine of the same warehouse vendor. You must use the vendor-provided processing capacities and pay for the same. This leads to vendor lock-in and migrating to other engines takes considerable efforts.
Warning
Not all open table formats are compatible with all open-source or commercial query engines. This is a growing space, and multiple independent software vendors (ISVs) are working on building connectors for interacting with various data formats. While deciding your tech stack, you should consider the engine compatibility with underlying open table formats.
Data sharing
As the lakehouse uses open data formats, sharing data with downstream consumers becomes much more manageable. You don’t have to onboard consumers on your platforms or share file extracts with them. They can directly access data from the cloud storage based on the data sharing access permissions.
An example of data sharing is the Delta Sharing protocol, an open standard for secure data sharing introduced by Delta Lake. Figure 1-6 shows a simplified version of the Delta Sharing protocol. Please note that the actual implementations would have additional components to manage the permissions and optimize the performance to serve only the required data.
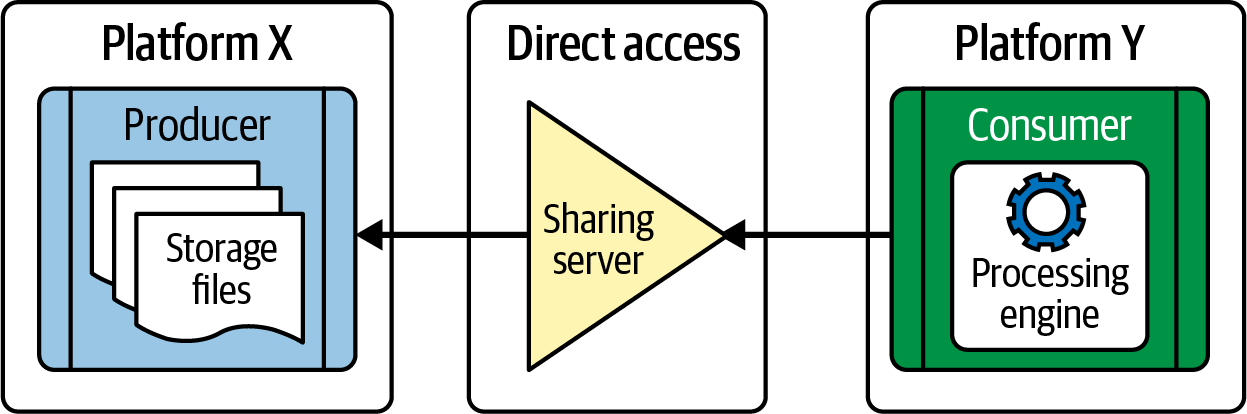
Figure 1-6. Delta sharing in Delta Lake
The key benefit of open data sharing is the freedom for data consumers to use any open-source processing engine or commercial products to query and analyze data. They are not required to use the same product as the data producer to access the shared data. On the other hand, the data producer only needs to share the data and does not have to worry about which processing engines the consumers would use for accessing the data. This feature opens up multiple possibilities for sharing data securely and implementing a marketplace for collaboratively sharing and exchanging data.
This is a growing space and, in the future, multiple vendors and communities might introduce new connectors to access data directly stored in a lakehouse.
Scalable and cost efficient
Lakehouses use cloud storage, which is scalable and much cheaper than traditional data warehouses. Storage cost for lakehouses is the cost set by the cloud storage providers. You can also leverage the lifecycle management policies and cold, or archival, tiers that cloud vendors offer to optimize long-term storage costs.
No data swamps
Many organizations have large volumes of data in their data lakes. However, most of the time, they do not leverage this data effectively due to a lack of data visibility.
Discovering these large volumes of data is difficult without proper metadata management, governance, lineage tracking, and access controls. Without these things, data lakes become data swamps and leveraging this data becomes challenging. Lakehouses help make data easily discoverable for the platform’s consumers by offering features like unified metadata management (across data and AI assets), lineage tracking, and more.
Note
Data swamps are data lakes with large volumes of data without proper organization or structure. The data stored within such data lakes are not well-governed and do not have well-organized metadata in the form of catalogs, making data discovery extremely challenging and reducing the overall visibility of the data for consumers. In short, data swamps are data lakes with data that is not leveraged for business needs due to the absence of robust metadata and governance processes.
Schema enforcement and evolution
Technologies used in lakehouse architecture support enforcing schema validations to avoid schema mismatches while storing data. These technologies also support schema evolution, using different approaches to help accept source schema changes. These features enable a flexible system with better data quality and integrity. Let’s briefly discuss the benefits of these two features.
Schema enforcement
Schema enforcement ensures that the data stored in the lakehouse follows the schema defined by the metadata of that table. The ETL process rejects any additional attributes or mismatching data types. These validations help in storing correct data, thus improving the overall data quality. For example, if a string value arrives in an attribute defined as an integer in the schema, it will get rejected.
Schema evolution
While schema enforcement improves data quality by implementing strict validations, schema evolution supports relaxing these validations by offering more flexibility while storing the data in a lakehouse. Any additional attribute not defined in the table metadata can be stored using schema evolution. Depending on the open table format, various approaches exist to store the extra attribute. This feature helps keep new attributes or data type mismatches without rejecting them. The key benefit of this approach is that you never lose any data and can accommodate changes on the fly.
While schema enforcement helps improve data quality by enforcing strict rules on specific attributes, schema evolution provides flexibility to accommodate metadata changes in the source systems. You can use both while implementing your lakehouse to maintain data quality as well as accommodate any source metadata changes.
Unified platform for ETL/ELT, BI, AI/ML, and real-time workloads
As we’ve mentioned, the lakehouse architecture enables you to implement a unified data platform to support diverse workloads. Let’s discuss these workloads and the benefits of using a lakehouse to implement them in more detail.
ETL/ELT workloads
To implement ETL workloads, you can use popular processing engines like Spark to perform transformations before storing data in the higher zones of the lakehouse storage hierarchy. You can also implement an ELT workload to perform transformations using SQL queries using any compute engine. Data practitioners who are more conversant with SQL prefer to perform SQL-based ELT operations for transforming data.
Real-time workloads
A unified lakehouse architecture supports diverse workloads, including real-time processing. In the past few years, due to the rise of real-time data generated from IoT devices, wearables, and clickstreams, organizations have tried to implement platforms that can support real-time workloads. Earlier data architectures, such as the Lambda architecture, supported real-time workloads using different processing streams. Lakehouses support real-time workloads using a unified architecture that supports executing batch or real-time jobs using the same code base.
Note
Lambda architecture is a traditional approach to processing large volumes of data ingested at varied frequencies. Lambda architecture has two different layers for processing batch data and streaming data. The batch and streaming data components for these layers are also separate, based on factors like latency and associated SLAs. This results in a complex data architecture with additional efforts to maintain different code bases for different layers.
Time travel
The transactional layer in a lakehouse enables it to maintain various versions of data. This helps it perform time travel to query and fetch older data that has been updated or deleted. Let’s look at one example to understand the time travel feature. Table 1-1 shows a product table with three columns.
| product_id | product_name | product_category |
|---|---|---|
| 22 | keyboard | computer accessory |
| 12 | mouse | computer accessory |
| 71 | headphone | computer accessory |
| 11 | mobile case | mobile accessory |
Consider a case where the third row, with product_id 71, gets updated to change the category from “computer accessory” to “mobile accessory.” Table 1-2 shows the updated table.
| product_id | product_name | product_category |
|---|---|---|
| 22 | keyboard | computer accessory |
| 12 | mouse | computer accessory |
| 71 | headphone | mobile accessory |
| 11 | mobile case | mobile accessory |
Now, if you query the product table, you will be able to see the updated data, but the older value of product_category for the updated record won’t be visible.
If you use open table formats like Iceberg, Hudi, or Delta Lake, you would be able to see the previous records also by just querying the table using an earlier version number or older timestamp as shown next.
Retrieve older data based on timestamp
You can retrieve the older status of records by using the earlier timestamp:
select*fromproductasof<oldertimestamp>
Note
The exact SQL commands will differ based on the open table format and compute engines used for implementing the lakehouse.
This time travel operation is not possible in the traditional data warehouses or data lakes. Some NoSQL databases (like HBase) and modern cloud warehouses store all versions of data, but traditional warehouses lacked this feature.
These benefits enable all data personas to access, manage, control, analyze, and leverage data quickly and efficiently compared to earlier data architectures.
Considering the benefits, lakehouse architecture can soon become the default choice for implementing data platforms and could see a widespread adoption similar to data warehouses and data lakes. Advanced technologies, growing communities, and multiple ISVs working on lakehouse-based products indicate a growing demand and popularity of lakehouse architecture.
Key Takeaways
If you are learning about lakehouse architecture for the first time, I understand this is a lot of information to digest on the first go. I’ll summarize the key points I discussed in this chapter to help you remember the most important concepts as you read the following chapters in this book.
- Understanding data architecture
-
-
Data architecture is the foundation of any data platform. It defines the core components and their interdependencies. It provides the blueprint for building the data platform and helps establish the guiding principles for designing the system.
-
The core components of the data platform are source systems, data ingestion, data storage, data processing and transformations, data consumption and delivery, and common services like metadata management, data governance and data security, and data operations.
-
Designing the data architecture is one of the most critical steps in setting up the data infrastructure. You should make every effort to architect a scalable, flexible, reliable, and above all, simple platform. This will enable quicker user adoption.
-
- Lakehouse architecture characteristics
-
-
Lakehouse architecture is a new architectural pattern that has emerged in the last few years. It provides the best features from data warehouses and data lakes.
-
Lakehouse architecture stores the data in a cloud store with an additional transactional layer, enabling warehouse-like capabilities.
-
You get the scalability, flexibility, and cost efficiencies of a data lake, as well as the performance, ACID compliance, and better governance of data warehouses.
-
Lakehouse architecture has only a single storage tier and no separate warehouse storage. It employs decoupled architecture where compute and storage layers are separate and scale independently.
-
It supports storing and managing all data types, including structured, semi-structured, and unstructured. It also supports diverse workloads like ETL, streaming, BI, and AI/ML.
-
- Lakehouse architecture benefits
-
-
Lakehouse architecture helps you implement a simple, unified data platform to implement a diverse set of data and analytics use cases.
-
Lakehouses use open technologies for storage; you don’t have to worry about vendor lock-in issues. You can use any compatible compute engine to query the data by directly accessing the data stored on cloud object storage.
-
Data sharing with data consumers, irrespective of the technology or product they use, becomes easier without the need to replicate the data or send file extracts.
-
Lakehouses can help you manage and control your data more efficiently with features like schema enforcement, schema evolution, time travel, and more.
-
As you read this book further, you will dive deep into more advanced topics to understand how to design and implement practical lakehouse architectures and to see their benefits over traditional architectures like data warehouses and data lakes, or the combined two-tier systems. But for readers new to the data world, we first need to better understand these traditional architectures, their advantages, and their limitations to appreciate the benefits of lakehouse architecture. I’ll discuss this in the next chapter.
Get Practical Lakehouse Architecture now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

