Chapter 4. Data Sources
In this chapter weâll take a deep dive into the kernel of the operating system and Falcoâs data collection stack. Youâll learn how Falco captures the different types of events that feed its rule engine, how its data collection process compares to alternative approaches, and why it was built the way it is. Youâll get to understand the details well enough that you will be able to pick and deploy the right drivers and plugins for your needs by the end of this chapter.
The first order of business is understanding what data sources you can use in Falco. Falcoâs data sources can be grouped into two main families: system calls and plugins. System calls are Falcoâs original data source. They come from the kernel of the operating system and offer visibility into the activities of processes, containers, virtual machines, and hosts. Falco uses them to protect workloads and applications. The second family of data sources, plugins, is relatively new: support was added in 2022. Plugins connect various types of inputs to Falco, such as cloud logs and APIs.
Falco previously supported Kubernetes audit logs as a third, separate source type; starting from Falco 0.32, however, this data source has been reimplemented as a plugin, so we wonât cover it in this chapter.
System Calls
As weâve stated several times already, system calls are a key source of data for Falco and one of the ingredients that make it unique. But what exactly is a system call? Letâs start with a high-level definition, courtesy of Wikipedia:
In computing, a system call (commonly abbreviated to syscall) is the programmatic way in which a computer program requests a service from the kernel of the operating system on which it is executed. This may include hardware-related services (for example, accessing a hard disk drive or accessing the deviceâs camera), creation and execution of new processes, and communication with integral kernel services such as process scheduling.
Letâs unpack this. At the highest level of abstraction, a computer consists of a bunch of hardware that runs a bunch of software. In modern computing, however, itâs extremely unusual for a program to run directly on the hardware. Instead, in the vast majority of cases, programs run on top of an operating system. Falcoâs drivers focus specifically on the operating system powering the cloud and the modern data center: Linux.
An operating system is a piece of software designed to conduct and support the execution of other software. Among many other things, the OS takes care of:
-
Scheduling processes
-
Managing memory
-
Mediating hardware access
-
Implementing network connectivity
-
Handling concurrency
Clearly, the vast majority of this functionality needs to be exposed to the programs that are running on top of the OS, so that they can do something useful. And clearly, the best way for a piece of software to expose functionality is to offer an application programming interface (API): a set of functions that client programs can call. This is what system calls almost are: APIs to interact with the operating system.
Wait, why almost?
Well, the operating system is a unique piece of software, and you canât just call it like you would a library. The OS runs in a separate execution mode, called privileged mode, thatâs isolated from user mode, which is the context used for executing regular processes (that is, running programs). This separation makes calling the OS more complicated. With some CPUs, you invoke a system call by triggering an interrupt. With most modern CPUs, however, you need to use a specific CPU instruction. If we exclude this additional level of complexity, it is fair to say that system calls are APIs to access operating system functionality. There are lots of them, each with their own input arguments and return value.
Every program, with no exceptions, makes extensive and constant use of the system call interface for anything that is not pure computation: reading input, generating output, accessing the disk, communicating on the network, running a new program, and so on. This means, as you can imagine, that observing system calls gives a very detailed picture of what each process does.
Operating system developers have long treated the system call interface as a stable API. This means that you can expect it to stay the same even if, inside, the kernel changes dramatically. This is important because it guarantees consistency across time and execution environments, making the system call API an ideal choice for collecting reliable security signals. Falco rules, for example, can reference specific system calls and assume that using them will work on any Linux distribution.
Examples
Linux offers many system callsâmore than 300 of them. Going over all of them would be next to impossible and very boring, so weâll spare you that. However, we do want to give you an idea of the kinds of system calls that are available.
Table 4-1 includes some of the system call categories that are most relevant for a security tool like Falco. For each category, the table includes examples of representative system calls. You can find more information on each by entering man 2 X, where X is the system call name, in a Linux terminal or in your browserâs search bar.
| Category | Examples |
|---|---|
| File I/O | open, creat, close, read, write, ioctl, link, unlink, chdir, chmod, stat, seek, mount, rename, mkdir, rmdir |
| Network | socket, bind, connect, listen, accept, sendto, recvfrom, getsockopt, setsockopt, shutdown |
| Interprocess communication | pipe, futex, inotify_add_watch, eventfd, semop, semget, semctl, msgctl |
| Process management | clone, execve, fork, nice, kill, prctl, exit, setrlimit, setpriority, capset |
| Memory management | brk, mmap, mprotect, mlock, madvise |
| User management | setuid, getuid, setgid, getgid |
| System | sethostname, setdomainname, reboot, syslog, uname, swapoff, init_module, delete_module |
Tip
If you are interested in taking a look at the full list of Linux system calls, type man syscalls into a Linux terminal or a search engine. This will show the official Linux manual page, which includes a comprehensive list of system calls with hyperlinks to take a deeper look at many of them. In addition, software engineer Filippo Valsorda offers a nicely organized and searchable list on his personal home page.
Observing System Calls
Given how crucial system calls are for Falco and for runtime security in general, itâs important that you learn how to capture, observe, and interpret them. This is a valuable skill that you will find useful in many situations. Weâre going to show you two different tools you can use for this purpose: strace and sysdig.
strace
strace is a tool that you can expect to find on pretty much every machine running a Unix-compatible operating system. In its simplest form, you use it to run a program, and it will print every system call issued by the program to standard error. In other words, add strace to the beginning of an arbitrary command line and you will see all of the system calls that command line generates:
$ strace echo hello world
execve("/bin/echo", ["echo", "hello", "world"], 0x7ffc87eed490 /* 32 vars */) = 0
brk(NULL) = 0x558ba22bf000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=121726, ...}) = 0
mmap(NULL, 121726, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f289009c000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\20\35\2\0\0\0\0\0" ...
fstat(3, {st_mode=S_IFREG|0755, st_size=2030928, ...}) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) ...
mmap(NULL, 4131552, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) ...
mprotect(0x7f288fc87000, 2097152, PROT_NONE) = 0
mmap(0x7f288fe87000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED| ...
mmap(0x7f288fe8d000, 15072, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED| ...
close(3) = 0
arch_prctl(ARCH_SET_FS, 0x7f289009b540) = 0
mprotect(0x7f288fe87000, 16384, PROT_READ) = 0
mprotect(0x558ba2028000, 4096, PROT_READ) = 0
mprotect(0x7f28900ba000, 4096, PROT_READ) = 0
munmap(0x7f289009c000, 121726) = 0
brk(NULL) = 0x558ba22bf000
brk(0x558ba22e0000) = 0x558ba22e0000
openat(AT_FDCWD, "/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=3004224, ...}) = 0
mmap(NULL, 3004224, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f288f7c2000
close(3) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 2), ...}) = 0
write(1, "hello world\n", 12hello world
) = 12
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
Note how straceâs output mimics C syntax and looks like a stream of function invocations, with the addition of the return value after the = symbol at the end of each line. For example, take a look at the write syscall (in bold) that outputs the âhello worldâ string to standard output (file descriptor 1). It returns the value 12, which is the number of bytes that have been successfully written. Note how the string âhello worldâ is printed to standard output before the write system call returns and strace prints its return value on the screen.
A second way to use strace is pointing it to a running process by specifying the process ID (PID) on the command line:
$ sudo strace -p`pidof vi`
strace: Process 16472 attached
select(1, [0], [], [0], NULL) = 1 (in [0])
read(0, "\r", 250) = 1
select(1, [0], [], [0], {tv_sec=0, tv_usec=0}) = 0 (Timeout)
select(1, [0], [], [0], {tv_sec=0, tv_usec=0}) = 0 (Timeout)
write(1, "\7", 1) = 1
select(1, [0], [], [0], {tv_sec=4, tv_usec=0}) = 0 (Timeout)
select(1, [0], [], [0], NULL
^C
strace: Process 16472 detached
<detached ...>
strace has some pros and some cons. Itâs broadly supported, so either itâs already available or itâs an easy package install away. Itâs also simple to use and ideal when you need to inspect a single process, which makes it perfect for debugging use cases.
As for disadvantages, strace instruments individual processes, which makes it unsuitable for inspecting the activity of the whole system or when you donât have a specific process to start from. Further, strace is based on ptrace for system call collection, which makes it very slow and unsuitable for use in production environments. You should expect a process to slow down substantially (sometimes by orders of magnitude) when you attach strace to it.
sysdig
We introduced sysdig in Chapter 3âs discussion of trace files. sysdig is more sophisticated than strace and includes several advanced features. While this can make it a bit harder to use, the good news is that sysdig shares Falcoâs data model, output format, and filtering syntaxâso you can use a lot of what you learn about Falco in sysdig, and vice versa.
The first thing to keep in mind is that you donât point sysdig to an individual process like you do with strace. Instead, you just run it and it will capture every system call invoked on the machine, inside or outside containers:
$ sudo sysdig 1 17:41:13.628568857 0 prlcp (4358) < write res=0 data=.N;.n... 2 17:41:13.628573305 0 prlcp (4358) > write fd=6(<p>pipe:[43606]) size=1 4 17:41:13.609136030 3 gmain (2935) < poll res=0 fds= 5 17:41:13.609146818 3 gmain (2935) > write fd=4(<e>) size=8 6 17:41:13.609149203 3 gmain (2935) < write res=8 data=........ 9 17:41:13.626956525 0 Xorg (3214) < epoll_wait res=1 10 17:41:13.626964759 0 Xorg (3214) > setitimer 11 17:41:13.626966955 0 Xorg (3214) < setitimer
Usually this is too noisy and not very useful, so you can restrict what sysdig shows you by using filters. sysdig accepts the same filtering syntax as Falco (which, incidentally, makes it a great tool to test and troubleshoot Falco rules). Hereâs an example where we restrict sysdig to capturing system calls for processes named âcatâ:
$ sudo sysdig proc.name=cat & cat /etc/hosts 47190 14:40:39.913809700 12 cat (377163.377163) < execve res=0 exe=cat args=/etc/hosts. tid=377163(cat) pid=377163(cat) ptid=5860(zsh) cwd= fdlimit=1024 pgft_maj=0 pgft_min=60 vm_size=424 vm_rss=4 vm_swap=0 comm=cat cgroups=cpuset=/user.slice.cpu=/user.slice.cpuacct=/.io=/user.slice.memory= /user.slic... env=SYSTEMD_EXEC_PID=3558.GJS_DEBUG_TOPICS=JS ERROR;JS LOG.SESSION_MANAGER=local/... tty=34817 pgid=377163(cat) loginuid=1000 flags=0 47194 14:40:39.913846153 12 cat (377163.377163) > brk addr=0 47196 14:40:39.913846951 12 cat (377163.377163) < brk res=55956998C000 vm_size=424 vm_rss=4 vm_swap=0 47205 14:40:39.913880404 12 cat (377163.377163) > arch_prctl 47206 14:40:39.913880871 12 cat (377163.377163) < arch_prctl 47207 14:40:39.913896493 12 cat (377163.377163) > access mode=4(R_OK) 47208 14:40:39.913900922 12 cat (377163.377163) < access res=-2(ENOENT) name=/etc/ld.so.preload 47209 14:40:39.913903872 12 cat (377163.377163) > openat dirfd=-100(AT_FDCWD) name=/etc/ld.so.cache flags=4097(O_RDONLY|O_CLOEXEC) mode=0 47210 14:40:39.913914652 12 cat (377163.377163) < openat fd=3(<f>/etc/ld.so.cache) dirfd=-100(AT_FDCWD) name=/etc/ld.so.cache flags=4097(O_RDONLY|O_CLOEXEC) mode=0 dev=803
This output requires a little more explanation than straceâs. The fields sysdig prints are:
-
Incremental event number
-
Event timestamp
-
CPU ID
-
Command name
-
Process ID and thread ID (TID), separated by a dot
-
Event direction (
>means enter, while<means exit) -
Event type (for our purposes, this is the system call name)
-
System call arguments
Unlike strace, sysdig prints two lines for each system call: the enter line is generated when the system call starts and the exit line is printed when the system call returns. This approach works well if you need to identify how long a system call took to run or pinpoint a process that is stuck in a system call.
Also note that, by default, sysdig prints thread IDs in addition to process IDs. Threads are the core execution unit for the operating system and thus for sysdig as well. Multiple threads can exist within the same process or command and share resources, such as memory. The TID is the basic identifier to follow when tracking execution activity in your machine. You do that by just looking at the TID number, or by filtering out the noise with a command line like this one:
$ sysdig thread.tid=1234
which will preserve the execution flow only for thread 1234.
Threads live inside processes, which are identified by a process ID. A lot of the processes running on an average Linux box are single-threaded, and in that case thread.tid is the same as proc.pid. Filtering by proc.pid is useful to observe how threads interact with each other inside a process.
Trace files
As you learned in Chapter 3, you can instruct sysdig to save the system calls it captures to a trace file, like so:
$ sudo sysdig -w testfile.scap
You will likely want to use a filter to keep the file size under control. For example:
$ sudo sysdig -w testfile.scap proc.name=cat
You can also use filters when reading trace files:
$ sysdig -r testfile.scap proc.name=cat
sysdigâs filters are important enough that we will devote a full chapter (Chapter 6) to them.
We recommend you play with sysdig and explore the activity of common programs in Linux. This will be helpful later, when creating or interpreting Falco rules.
Capturing System Calls
All right, system calls are cool and we need to capture them. So whatâs the best way to do it?
Earlier in this chapter, we described how system calls involve transitioning the execution flow from a running process to the kernel of the operating system. Intuitively, and as shown in Figure 4-1, there are two places where system calls can be captured: in the running process or the operating system kernel.
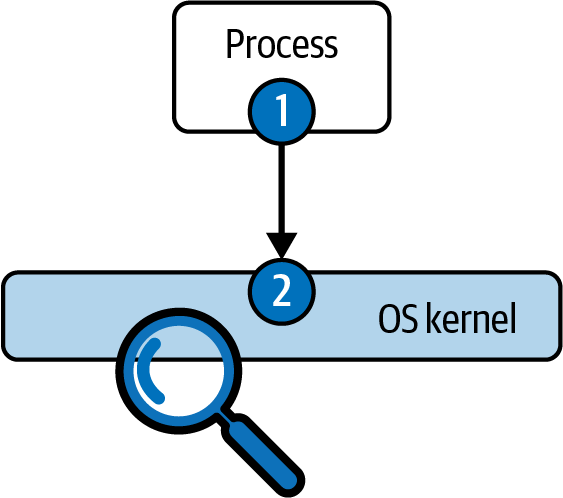
Figure 4-1. System call capture options
Capturing system calls in a running process typically involves modifying either the process or some of its libraries with some kind of instrumentation. The fact that most programs in Linux use the C standard library, also known as glibc, to execute system calls makes instrumenting it quite appealing. As a consequence, there are abundant tools and frameworks to modify glibc (and other system libraries) for instrumentation purposes. These techniques can be static, changing the libraryâs source code and recompiling it, or dynamic, finding its location in the address space of the target process and inserting hooks in it.
Note
Another method to capture system calls without instrumenting the OS kernel involves using the operating systemâs debugging facilities. For example, strace uses a facility called ptrace,1 which is at the base of tools like the GNU debugger (gdb).
The second option involves intercepting the system call execution after it has transitioned to the operating system. This requires running some code in the OS kernel itself. It tends to be more delicate and riskier, because running code in the kernel requires elevated privileges. Anything running in the kernel has potential control of the machine, its processes, its users, and its hardware. Therefore, a bug in anything that runs inside the kernel can cause major security risks, data corruption, or, in some cases, even a machine crash. This is why many security tools pick instrumentation option 1 and capture system calls at the user level, inside the process.
Falco does the opposite: it sits squarely on the kernel instrumentation side. The rationale behind this choice can be summarized in three words: accuracy, performance, and scalability. Letâs explore each in turn.
Accuracy
User-level instrumentation techniquesâin particular, those that work at the glibc levelâhave a couple of major problems. First, a motivated attacker can evade them by, well, not using glibc! You donât have to use a library to issue system calls, and attackers can easily craft a simple sequence of CPU instructions instead, completely bypassing the glibc instrumentation. Not good.
Even worse, there are major categories of software that just donât load glibc at all. For example, statically linked C programs, very common in containers, import glibc functions at compile time and embed them in their executables. With these programs, you donât have the option to replace or modify the library. The same goes for programs written in Go, which has its own statically linked system call interface library.
Kernel-level capture doesnât suffer from these limitations. It supports any language, any stack, and any framework, because system call collection happens at a level below all of the libraries and abstraction layers. This means that kernel-level instrumentation is much harder for attackers to evade.
Performance
Some user-level capture techniques, such as using ptrace, have significant overhead because they generate a high number of context switches. Every single system call needs to be uniquely delivered to a separate process, which requires the execution to ping-pong between processes. This is very, very slow, to the point that it becomes an impediment to using such techniques in production, where such a substantial impact on the instrumented processes is not acceptable.
Itâs true that glibc-based capture can be more efficient, but it still introduces high overhead for basic operations like timestamping events. Kernel-level capture, by contrast, requires zero context switches and can collect all of the necessary context, like timestamps, from within the kernel. This makes it much faster than any other technique, and thus the most suitable for production.
Scalability
As the name implies, process-level capture requires âdoing somethingâ for every single process. What that something is can vary, but it still introduces an overhead that is proportional to the number of observed processes. Thatâs not the case with kernel-level instrumentation. Take a look at Figure 4-2.
If you insert kernel instrumentation in the right place, it is possible to have one single instrumentation point (labeled 2 in Figure 4-2), no matter how many processes are running. This ensures not only maximum efficiency but also the certainty that you will never miss anything, because no process escapes kernel-level capture.
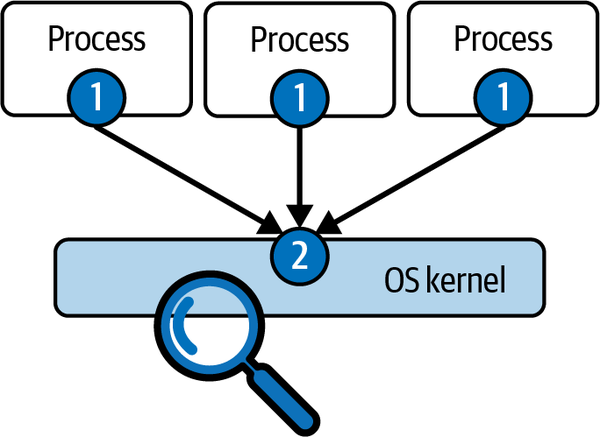
Figure 4-2. System call capture scalability, process-level versus kernel
So What About Stability and Security?
We mentioned that kernel-level instrumentation is more delicate, because a bug can cause serious problems. You might wonder, âAm I taking additional risk by choosing a tool like Falco, which is based on kernel instrumentation, instead of a product based on user-level instrumentation?â
Not really. First of all, kernel-level instrumentation benefits from well-documented, stable hooking interfaces, while approaches like glibc-based capture are less clean and intrinsically riskier. They cannot crash the machine, but they can absolutely crash the instrumented process, with results that are typically bad. In addition to that, technologies like eBPF greatly reduce the risk involved in running code in the kernel, making kernel-level instrumentation viable even for risk-averse users.
Kernel-Level Instrumentation Approaches
We hope weâve convinced you that, whenever itâs available, kernel instrumentation is the way to go for runtime security. The question now becomes, what is the best mechanism to implement it? Among the different available approaches, two are relevant for a tool like Falco: kernel modules or eBPF probes. Letâs take a look at each of these approaches.
Kernel modules
Loadable kernel modules are pieces of code that can be loaded into the kernel at runtime. Historically, modules have been heavily used in Linux (and many other operating systems) to make the kernel extensible, efficient, and smaller.
Kernel modules extend the kernelâs functionality without the need to reboot the system. They are typically used to implement device drivers, network protocols, and filesystems. Kernel modules are written in C and are compiled for the specific kernel inside which they will run. In other words, itâs not possible to compile a module on one machine and then use it on another one (unless they have exactly the same kernel). Kernel modules can also be unloaded when the user doesnât need them anymore, to save memory.
Linux has supported kernel modules for a very long time, so they work even with very old versions of Linux. They also have extensive access to the kernel, which means there are very few restrictions on what they can do. That makes them a great choice to collect the detailed information required by a runtime security tool like Falco. Since they are written in C, kernel modules are also very efficient and therefore a great option when performance is important.
If you want to see the list of modules that are loaded in your Linux box, use this command:
$ sudo lsmod
eBPF
As mentioned in Chapter 1, eBPF is the ânext generationâ of the Berkeley Packet Filter (BPF). BPF was designed in 1992 for network packet filtering with BSD operating systems, and it is still used today by tools like Wireshark. BPFâs innovation was the ability to execute arbitrary code in the kernel of the operating system. Since such code has more or less unlimited privileges on the machine, however, this is potentially risky and must be done with care.
Figure 4-3 shows how BPF safely runs arbitrary packet filters in the kernel.

Figure 4-3. BPF filter deployment steps
Letâs take a look at the steps depicted here:
-
The user inputs a filter in a program like Wireshark (e.g.,
port 80). -
The filter is fed to a compiler, which converts it into bytecode for a virtual machine. This is conceptually similar to compiling a Java program, but both the program and the virtual machine (VM) instruction set are much simpler when using BPF. Here, for example, is what our
port 80filter becomes after being compiled:(000) ldh [12] (001) jeq #0x86dd jt 2 jf 10 (002) ldb [20] (003) jeq #0x84 jt 6 jf 4 (004) jeq #0x6 jt 6 jf 5 (005) jeq #0x11 jt 6 jf 23 (006) ldh [54] (007) jeq #0x50 jt 22 jf 8 (008) ldh [56] (009) jeq #0x50 jt 22 jf 23 (010) jeq #0x800 jt 11 jf 23 (011) ldb [23] (012) jeq #0x84 jt 15 jf 13 (013) jeq #0x6 jt 15 jf 14 (014) jeq #0x11 jt 15 jf 23 (015) ldh [20] (016) jset #0x1fff jt 23 jf 17 (017) ldxb 4*([14]&0xf) (018) ldh [x + 14] (019) jeq #0x50 jt 22 jf 20 (020) ldh [x + 16] (021) jeq #0x50 jt 22 jf 23 (022) ret #262144 (023) ret #0
-
To prevent a compiled filter from doing damage, it is analyzed by a verifier before being injected into the kernel. The verifier examines the bytecode and determines if the filter has dangerous attributes (for example, infinite loops that would cause the filter to never return, consuming a lot of kernel CPU).
-
If the filter code is not safe, the verifier rejects it, returns an error to the user, and stops the loading process. If the verifier is happy, the bytecode is delivered to the virtual machine, which runs it against every incoming packet.
eBPF is a more recent (and much more capable) version of BPF, added to Linux in 2014 and first included with kernel version 3.18. eBPF takes BPFâs concepts to new levels, delivering more efficiency and taking advantage of newer hardware. Most importantly, with hooks throughout the kernel, eBPF enables use cases that go beyond simple packet filtering, such as tracing, performance analysis, debugging, and security. Itâs essentially a general-purpose code execution VM that guarantees the programs it runs wonât cause damage.
Here are some of the improvements that eBPF introduces over classic BPF:
-
A more advanced instruction set, which means eBPF can run much more sophisticated programs.
-
A just-in-time (JIT) compiler. While classic BPF was interpreted, eBPF programs, after being validated, are converted into native CPU instructions. This means they run much faster, at close to native CPU speeds.
-
The ability to write real C programs instead of just simple packet filters.
-
A mature set of libraries that let you control eBPF from languages like Go.
-
The ability to run subprograms and helper functions.
-
Safe access to several kernel objects. eBPF programs can safely âpeekâ into kernel structures to collect information and context, which are gold for tools like Falco.
-
The concept of maps, memory areas that can be used to exchange data with the user level efficiently and easily.
-
A much more sophisticated verifier, which lets eBPF programs do more while preserving their safety.
-
The ability to run in many more places in the kernel than the network stack, using facilities like tracepoints, kprobes, uprobes, Linux Security Modules hooks, and Userland Statically Defined Tracing (USDT).
eBPF is evolving quickly and is rapidly becoming the standard way to extend the Linux kernel. eBPF scripts are flexible and safe and run extremely fast, making them perfect for capturing runtime activity.
The Falco Drivers
Falco offers two different driver implementations that implement both the approaches we just described: a kernel module and an eBPF probe. The two implementations have the same functionality and are interchangeable when using Falco. Therefore, we can describe how they work without focusing on a specific one.
The high-level capture flow is shown in Figure 4-4.

Figure 4-4. The driverâs capture flow
The approach used by the Falco drivers to capture a system call involves three main steps, labeled in the figure:
-
A kernel facility called a tracepoint intercepts the execution of the system call. The tracepoint makes it possible to insert a hook at a specific place in the operating system kernel so that a callback function will be called every time kernel execution reaches that point.2 The Falco drivers install two tracepoints for system calls: one where system calls enter the kernel, and another one where they exit the kernel and give control back to the caller process.
-
While in the tracepoint callback, the driver âpacksâ the system call arguments into a shared memory buffer. During this phase, the system call is also timeÂstamâ ped and additional context is collected from the operating system (for example, the thread ID, or the connection details for some socket syscalls). This phase needs to be super-efficient, because the system call cannot be executed until the driverâs tracepoint callback returns.
-
The shared buffer now contains the system call data, and Falco can access it directly through libscap (introduced in Chapter 3). No data is copied during this phase, which minimizes CPU utilization while optimizing cache coherency.
There are a few things to keep in mind with regard to system call capture in Falco. The first one is that the way system calls are packed in the buffer is flexible and doesnât necessarily reflect the arguments of the original calls. In some cases, the driver skips unneeded arguments to maximize performance. In other cases, the driver adds fields that contain state, useful context, or additional information. For example, a clone event in Falco contains many fields that add information about the newly created process, like the environment variables.
The second thing to keep in mind is that, even if system calls are by far the most important sources of data that the drivers capture, they are not the only ones. Using tracepoints, the drivers hook into other places in the kernel, like the scheduler, to capture context switches and signal deliveries. Take a look at this command:
$ sysdig evt.type=switch
This line of code displays events captured through the context switch tracepoint.
Which Driver Should You Use?
If youâre not sure which driver you should use, here are some simple guidelines:
-
Use the kernel module when you have an I/O-intensive workload and you care about keeping the instrumentation overhead as low as possible. The kernel module has lower overhead than the eBPF probe, and on machines that generate a high number of system calls it will have less of a performance impact on running processes. Itâs not easy to estimate how much better the kernel module will perform, since this depends on how many system calls a process is making, but expect the difference to be noticeable with disk- or network-intensive workloads that generate many system calls every second.
-
You should also use the kernel module when you need to support a kernel older than Linux version 4.12.
-
Use the eBPF probe in all other situations.
Thatâs it!
Capturing System Calls Within Containers
The beauty of tracepoint-based kernel-level capture is that it sees everything that runs in a machine, inside or outside a container. Nothing escapes it. It is also easy to deploy, with no need to run anything inside the monitored containers, and it doesnât require sidecars.
Figure 4-5 shows how you deploy Falco in a containerized environment, with a simplified diagram of a machine running three containers (labeled 1, 2, and 3) based on different container runtimes.
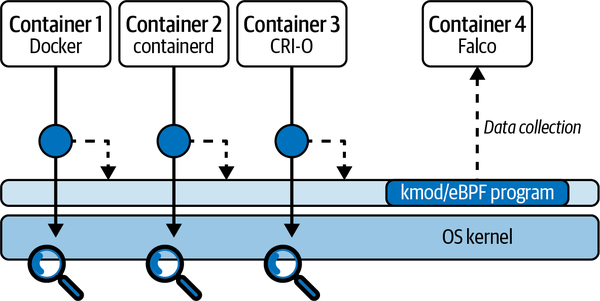
Figure 4-5. Deploying Falco in a containerized environment
In such a scenario, Falco is typically installed as a container. Orchestrators like Kubernetes make it easy to deploy Falco on every host, with facilities like DaemonSets and Helm charts.
When the Falco container starts, it installs the driver in the operating system. Once installed, the driver can see the system calls of any process in any container, with no further user action required, because all of these system calls go through the same tracepoint. Advanced logic in the driver can attribute each captured system call to its container so that Falco always knows which container has generated a system call. Falco also fetches metadata from the container runtime, making it easy to create rules that rely on container labels, image names, and other metadata. (Falco includes a further level of enrichment based on Kubernetes metadata, which weâll discuss in the next chapter.)
Running the Falco Drivers
Now that you have an idea of how they work, letâs take a look at how to deploy and use the two Falco drivers on a local machine. (If you want to install Falco in production environments, see Chapters 9 and 10.)
Kernel Module
Falco, by default, runs using the kernel module, so no additional steps are required if you want to use that as your driver. Just run Falco, and it will pick up the kernel module. If you want to unload the kernel module and load a different version, for example because you have built your own customized module, use the following commands:
$ sudo rmmod falco $ sudo insmod path/to/your/module/falco.ko
eBPF Probe
To enable eBPF support in Falco, you need to set the FALCO_BPF_PROBE environment variable. If you set it to an empty value (FALCO_BPF_PROBE=""), Falco will load the eBPF probe from ~/.falco/falco-bpf.o. Otherwise, you can explicitly point to the path where the eBPF probe resides:
export FALCO_BPF_PROBE="path/to/your/ebpf/probe/falco-bpf.o"
After setting the environment variable, just run Falco normally and it will use the eBPF probe.
Tip
To ensure that Falcoâs eBPF probe (and any other eBPF program) runs with the best performance, make sure that your kernel has CONFIG_BPF_JIT enabled and that net.core.bpf_jit_enable is set to 1. This enables the BPF JIT compiler in the kernel, substantially speeding up the execution of eBPF programs.
Using Falco in Environments Where Kernel Access Is Not Available: pdig
Kernel instrumentation, whenever possible, is always the way to go. But what if you want to run Falco in environments where access to the kernel is not allowed? This is common in managed container environments, like AWS Fargate. In such environments, installing a kernel module is not an option because the cloud provider blocks it.
For these situations, the Falco developers have implemented a user-level instrumentation driver called pdig. It is built on top of ptrace, so it uses the same approach as strace. Like strace, pdig can operate in two ways: it can run a program that you specify on the command line, or it can attach to a running process. Either way, pdig instruments the process and its children in a way that produces a Falco-compatible stream of events.
Note that pdig, like strace, requires you to enable CAP_SYS_PTRACE for the container runtime. Make sure you launch your container with this capability, or pdig will fail.
The eBPF probe and kernel module work at the global host level, whereas pdig works at the process level. This can make container instrumentation more challenging. Fortunately, pdig can track the children of an instrumented process. This means that running the entrypoint of a container with pdig will allow you to capture every system call generated by any process for that container.
The biggest limitation of pdig is performance. ptrace is versatile, but it introduces substantial overhead on the instrumented processes. pdig employs several tricks to reduce this overhead, but itâs still substantially slower than the kernel-level Falco drivers.
Running Falco with pdig
You run pdig with the path (and arguments, if any) of the process you want to trace, much as you would with strace. Hereâs an example:
$ pdig [-a] curl https://example.com/
The -a option enables the full filter, which provides a richer set of instrumented system calls. You probably donât want to use this option with Falco, for performance reasons.
You can also attach to a running process with the -p option:
$ pdig [-a] -p 1234
To observe any effect, you will need to have Falco running in a separate process. Use the -u command-line flag:
$ falco -u
Falco Plugins
In addition to system calls, Falco can collect and process many other types of data, such as application logs and cloud activity streams. Letâs round out this chapter by exploring the mechanism at the base of this functionality: Falcoâs plugins framework.
Plugins are a modular, flexible way to extend Falco ingestion. Anyone can use them to add a new source of data, local or remote, to Falco. Figure 4-6 indicates where plugins sit in the Falco capture stack: they are inputs for libscap and act as alternatives to the drivers that are used when capturing system calls.
Plugins are implemented as shared libraries that conform to a documented API. They allow you to add new event sources that you can then evaluate using filtering expressions and Falco rules. They also let you define new fields that can extract information from events.
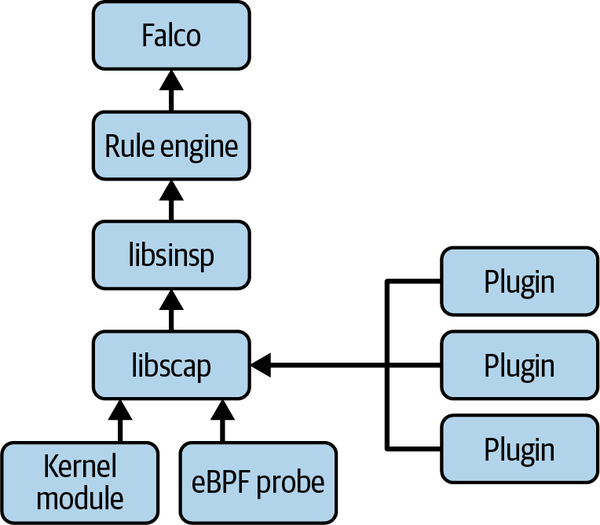
Figure 4-6. Falco plugins
Plugin Architecture Concepts
Plugins are dynamic shared libraries (.so files in Unix, .dll files in Windows) that export C calling convention functions. Falco dynamically loads these libraries and calls the exported functions. Plugins are versioned using semantic versioning to minimize regressions and compatibility issues. They can be written in any language, as long as they export the required functions. Go is the preferred language for writing plugins, followed by C/C++.
Plugins include two main pieces of functionality, also called capabilities:
- Event sourcing
-
This capability is used to implement a new event source. An event source can âopenâ and âcloseâ a stream of events and can return an event to libscap via a
nextmethod. In other words, itâs used to feed new âstuffâ to Falco. - Field extraction
-
Field extraction focuses on producing fields from events generated by other plugins or by the core libraries. Fields, youâll recall, are the basic components of Falco rules, so exposing new fields is equivalent to expanding the applicability of Falco rules to new domains. An example is JSON parsing, where a plugin might be able to extract fields from arbitrary JSON payloads. Youâll learn more about fields in Chapter 6.
An individual plugin can offer the event sourcing capability, field extraction capability, or both at the same time. Capabilities are exported by implementing certain functions in the plugin API interface.
To make it easier to write plugins, there are Go and C++ SDKs that handle the details of memory management and type conversion. They provide a streamlined way to implement plugins without having to deal with all the details of lower-level functions that make up the plugin API.
The libraries will do everything possible to validate data that comes from the plugins, to protect Falco and other consumers from corrupted data. However, for performance reasons plugins are trusted, and because they run in the same thread and address space as Falco, they could crash the program. Falco assumes that you, as a user, are in control and will make sure only plugins you have vetted are loaded or packaged.
How Falco Uses Plugins
Falco loads plugins based on the configuration in falco.yaml. As of summer 2022, when this book went to press, if a source plugin is loaded, the only events processed are from that plugin, and system call capture is disabled. Also, a running Falco instance can use only one plugin. If, on a single machine, you want Falco to collect data from multiple plugins or from plugins and drivers, you will need to run multiple Falco instances and use a different source for each of them.3
Falco configures plugins via the plugins property in falco.yaml. Hereâs an example:
plugins:-name:cloudtraillibrary_path:libcloudtrail.soinit_config:"..."open_params:"..."load_plugins:[cloudtrail]
The plugins property in falco.yaml defines the set of plugins that Falco can load, and the load_plugins property controls which plugins load when Falco starts.
The mechanics of loading a plugin are implemented in libscap and leverage the dynamic library functionality of the operating system.4 The plugin loading code also ensures that:
-
The plugin is valid (i.e., it exports the set of expected symbols).
-
The pluginâs API version number is compatible with the plugin framework.
-
Only one source plugin is loaded at a time for a given event source.
-
If a mix of source and extractor plugins is loaded for a given event source, the exported fields have unique names that donât overlap across plugins.
An up-to-date list of available Falco plugins can be found in the plugins repository under the Falcosecurity GitHub organization. As of this writing, the Falcosecurity organization officially maintains plugins for CloudTrail, GitHub, Okta, Kubernetes audit logs, and JSON. In addition to these, there are third-party plugins available for seccomp and Docker.
If you are interested in writing your own plugins, you will find everything you need to know in Chapter 14. If youâre impatient and just want to get to the code, you can find the source code for all the currently available plugins in the plugins repo.
Conclusion
Congratulations on making it to the end of a rich chapter packed with a lot of information! What you learned here is at the core of understanding and operating Falco. It also constitutes a solid architectural foundation that will be useful every time you need to run or deploy a security tool on Linux.
Next, youâre going to learn about how context is added to the captured data to make Falco even more powerful.
1 Run man 2 ptrace for more information on this.
2 For more information, see the article âUsing the Linux Kernel Tracepointsâ by Mathieu Desnoyer.
3 Note that the Falco developers are working on removing this limitation. As a consequence, in the future Falco will be able to receive data from multiple plugins at the same time or to capture system calls and at the same time use plugins.
4 A dynamic library is loaded using dlopen/dlsym in Unix, or LoadLibrary/GetProcAddress in Windows.
Get Practical Cloud Native Security with Falco now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

