Capítulo 4. Patrones de gestión de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Los datos son la clave de todas las aplicaciones. Incluso un simple servicio de eco depende de los datos del mensaje entrante para enviar una respuesta. Este capítulo trata sobre los datos y su gestión en las aplicaciones nativas de la nube.
En primer lugar, nos centraremos en la arquitectura de datos, explicando cómo se recopilan, procesan y almacenan los datos en las aplicaciones nativas de la nube. Después, veremos cómo entender los datos categorizándolos a través de múltiples dimensiones, basándonos en cómo se utilizan en una aplicación, su estructura y su escala. Discutiremos las posibles opciones de almacenamiento y procesamiento y cómo hacer la mejor elección dado un tipo específico de datos.
A continuación, pasaremos a explicar varios patrones relacionados con los datos, centrándonos en los datos centralizados y descentralizados, la composición de datos, el almacenamiento en caché, la gestión, la optimización del rendimiento, la fiabilidad y la seguridad. El capítulo también cubre varias tecnologías utilizadas actualmente en la industria para implementar eficazmente estos patrones de desarrollo de aplicaciones nativas de la nube.
Este conocimiento conjunto de datos, patrones y tecnologías te ayudará a diseñar aplicaciones nativas de la nube para tu caso de uso específico y para el tipo de datos que tratan tus aplicaciones.
Arquitectura de datos
Las aplicaciones nativas de la nube deben ser capaces de recoger, almacenar, procesar y presentar datos de forma que satisfagan nuestros casos de uso(Figura 4-1).
Aquí, las fuentes de datos son aplicaciones nativas de la nube que alimentan datos como entradas de usuario y lecturas de sensores. A veces alimentan con datos los sistemas de ingestión de datos, como los corredores de mensajes o, cuando es posible, escriben directamente en los almacenes de datos. Los sistemas de ingestión de datos pueden transferir datos como eventos/mensajes a otras aplicaciones o almacenes de datos; a través de ellos podremos conseguir un procesamiento de datos fiable y asíncrono.(El Capítulo 5 proporciona más detalles sobre los sistemas de ingestión de datos).
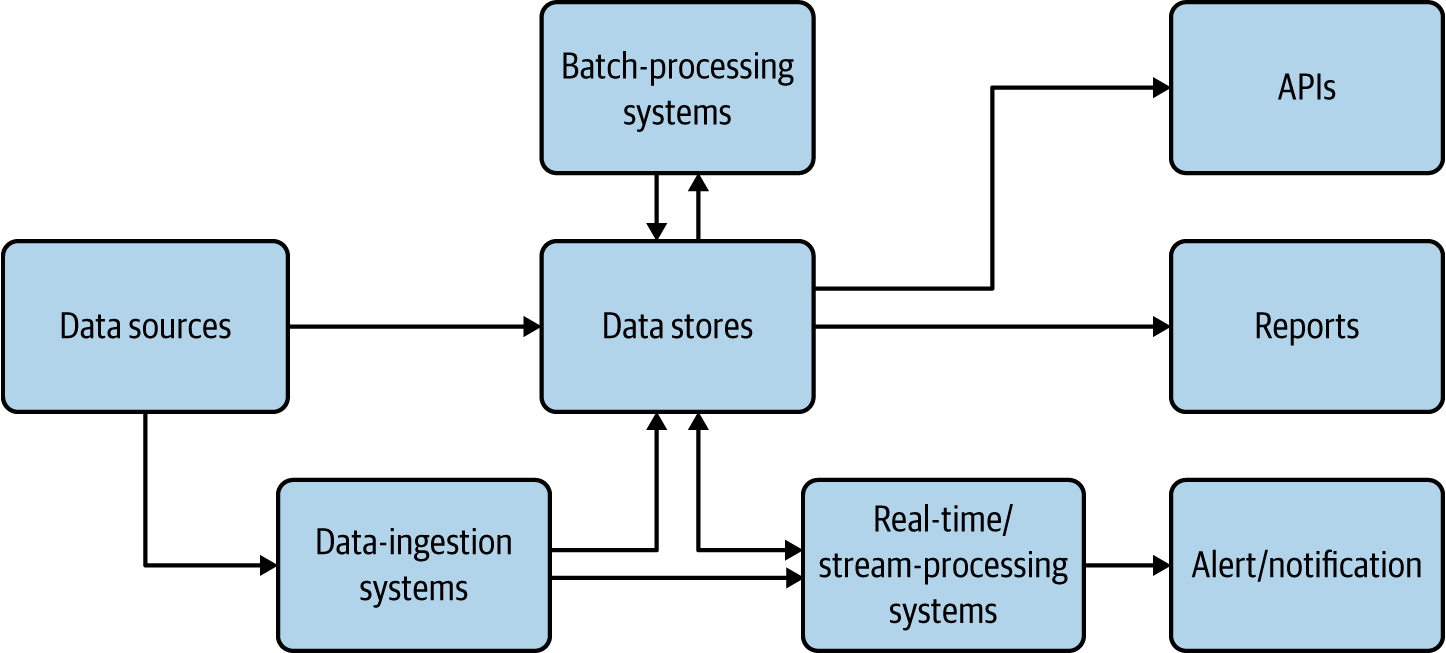
Figura 4-1. Arquitectura de datos para aplicaciones nativas en la nube
Los almacenes de datos son la parte crítica de esta arquitectura; almacenan datos en varios formatos y a escala para facilitar el caso de uso. Se utilizan como fuente para generar informes y también como base de las API de datos. Presentamos más detalles sobre los almacenes de datos en las secciones siguientes.
Los sistemas y de procesamiento de flujos en tiempo real procesan los sucesos sobre la marcha y producen información útil para el caso de uso, además de proporcionar alertas y notificaciones cuando se producen. El Capítulo 6 los trata en detalle. Los sistemas de procesamiento por lotes procesan los datos de las fuentes de datos por lotes, y escriben el resultado procesado de nuevo en los almacenes de datos para que pueda ser utilizado para la elaboración de informes o expuesto a través de API. En estos casos, el sistema de procesamiento puede leer datos de un tipo de almacén y escribir en otro, como leer de un sistema de archivos y escribir en una base de datos relacional. El procesamiento por lotes de datos nativos de la nube es similar al procesamiento tradicional de datos por lotes, por lo que no entraremos en detalles aquí.
Sólo al igual que los microservicios nativos de la nube tienen características como ser escalables, resistentes y manejables, los datos nativos de la nube tienen sus propias características únicas que son bastante diferentes de las prácticas tradicionales de procesamiento de datos. Lo más importante es que los datos nativos de la nube pueden almacenarse de muchas formas, en diversos formatos y almacenes de datos. No se espera que mantengan un esquema fijo y se les anima a tener datos duplicados para facilitar la disponibilidad y el rendimiento por encima de la consistencia. Además, en las aplicaciones nativas de la nube, no se anima a que varios servicios accedan a la misma base de datos; en su lugar, deben llamar a las respectivas API de servicio propietarias del almacén de datos para acceder a los datos. Todo esto proporciona separación de preocupaciones y permite que los datos nativos de la nube se escalen.
Tipos y formas de datos
Los datos, en sus múltiples formas, tienen una enorme influencia en las aplicaciones, nativas de la nube o no. En esta sección se analiza cómo los datos alteran la ejecución de una aplicación, los formatos de estos datos y la mejor forma de transmitirlos y almacenarlos.
El comportamiento de la aplicación se ve influido por los siguientes tres tipos principales de datos:
- Datos de entrada
- Enviados a como parte del mensaje de entrada por el usuario o cliente. Lo más habitual es que estos datos sean mensajes JSON o XML, aunque los formatos binarios como gRPC y Thrift están adquiriendo cierta tracción.
- Datos de configuración
- Proporcionado por el entorno como variables. XML se ha utilizado como lenguaje de configuración durante mucho tiempo, y ahora las configuraciones YAML se han convertido en el estándar de facto para las aplicaciones nativas de la nube.
- Datos estatales
- Los datos almacenados por la propia aplicación, relativos a su estado, se basan en todos los mensajes y eventos ocurridos antes del momento actual. Al persistir los datos de estado y cargarlos al iniciarse, la aplicación podrá reanudar sin problemas su funcionalidad al reiniciarse.
Las aplicaciones que sólo dependen de los datos de entrada y configuración (config) se denominan aplicaciones sin estado. Estas aplicaciones son relativamente sencillas de implementar y escalar porque su fallo o reinicio casi no tiene impacto en su ejecución. En cambio, las aplicaciones que dependen de datos de entrada, configuración y estado -lasaplicacionescon estado - son mucho más complejas de implementar y escalar. El estado de la aplicación se almacena en almacenes de datos, por lo que los fallos de la aplicación pueden dar lugar a escrituras parciales que corrompan su estado, lo que puede conducir a una ejecución incorrecta de la aplicación.
Las aplicaciones nativas de la nube se dividen en aplicaciones con estado y sin estado. En el Capítulo 3 se trataron las aplicaciones sin estado. Este capítulo se centra en las aplicaciones con estado.
Las aplicaciones nativas de la nube utilizan diversas formas de datos, que generalmente se agrupan en las tres categorías siguientes:
- Datos estructurados
- Puede ajustarse a un esquema predefinido. Por ejemplo, los datos de un típico formulario de registro de usuario pueden almacenarse cómodamente en una base de datos relacional.
- Datos semiestructurados
- Tiene algún tipo de estructura. Por ejemplo, cada campo de una entrada de datos puede tener una clave o nombre correspondiente que podemos utilizar para referirnos a él, pero cuando tomamos todas las entradas, no hay garantía de que cada entrada tenga el mismo número de campos o incluso claves comunes. Estos datos pueden representarse fácilmente mediante los formatos JSON, XML, y YAML.
- Datos no estructurados
- no contiene ningún campo significativo. Las imágenes, los vídeos y el contenido de texto sin formato son ejemplos de ello. Normalmente, estos datos se almacenan sin comprender su contenido.
Almacenes de datos
En tenemos que elegir el tipo de almacén de datos para los datos nativos de la nube, basándonos en el caso de uso de la aplicación. Los distintos casos de uso utilizan distintos tipos de datos (estructurados, semiestructurados o no estructurados) y tienen distintos requisitos de escalabilidad y disponibilidad. Con las diversas opciones de almacenamiento disponibles, los distintos almacenes de datos ofrecen características diferentes, como que uno proporcione un alto rendimiento y otro una gran escalabilidad. A veces, incluso podemos acabar utilizando más de un almacén de datos al mismo tiempo para conseguir características diferentes. En esta sección, veremos los tipos comunes de almacenes de datos, y cuándo y cómo pueden utilizarse en aplicaciones nativas de la nube.
Bases de datos relacionales
Las bases de datos relacionales son ideales para almacenar datos estructurados que tienen un esquema predefinido. Estas bases de datos utilizan el Lenguaje de Consulta Estructurado (SQL) para procesar, almacenar y acceder a los datos. También siguen el principio de definir el esquema al escribir: el esquema de datos se define antes de escribir los datos en la base de datos.
Las bases de datos relacionales pueden almacenar y recuperar datos de forma óptima utilizando la indexación y normalización de bases de datos. Dado que estas bases de datos admiten las propiedades de atomicidad, consistencia, aislamiento y durabilidad (ACID), también pueden ofrecer garantías de transacción. Aquí, la atomicidad garantiza que todas las operaciones de una transacción se ejecutan como una sola unidad; la consistencia asegura que los datos son consistentes antes y después de la transacción; el aislamiento hace que el estado intermedio de una transacción sea invisible para otras transacciones; y, por último, la durabilidad garantiza que, tras una transacción exitosa, los datos son persistentes incluso en caso de fallo del sistema. Todas estas características hacen que las bases de datos relacionales sean ideales para implementar aplicaciones financieras críticas para el negocio.
Las bases de datos relacionales no funcionan bien con datos semiestructurados. Por ejemplo, si estamos almacenando datos del catálogo de productos para un sitio de comercio electrónico y la entrada inicial contiene detalles del producto, precio, algunas imágenes y reseñas, no podemos almacenar todos estos datos en un almacén relacional. Aquí necesitamos extraer sólo los campos más importantes y comunes, como el ID del producto, el nombre, el detalle y el precio, para almacenarlos en una base de datos relacional, mientras almacenamos la lista de reseñas del producto en NoSQL y las imágenes en un sistema de archivos. Sin embargo, este enfoque podría imponer una degradación del rendimiento debido a las múltiples búsquedas al recuperar todos los datos. En tales casos, recomendamos almacenar los campos de datos críticos no estructurados y semiestructurados, como la imagen en miniatura del producto, como un blob o texto en el almacén de datos relacional para mejorar el rendimiento de la lectura. Al adoptar este enfoque, ten siempre en cuenta el coste y el consumo de espacio de las bases de datos relacionales.
Las bases de datos relacionales son una buena opción para almacenar datos de aplicaciones nativas de la nube. Recomendamos utilizar una base de datos relacional por microservicio, ya que esto ayudará a desplegar y escalar los datos junto con el microservicio como una única unidad de implementación. Es importante recordar que las bases de datos relacionales no son escalables por diseño. En términos de escalado, sólo admiten una arquitectura primaria/secundaria, que permite un nodo para las operaciones de escritura y múltiples nodos trabajadores para las operaciones de lectura.
Por tanto, recomendamos utilizar bases de datos relacionales en aplicaciones nativas de la nube cuando el número de registros del almacén nunca supere el límite que la base de datos puede procesar eficientemente. Si podemos prever que los datos crecerán constantemente, como ocurre con el número de pedidos, registros o notificaciones almacenados, entonces puede que necesitemos implementar patrones de escalado de datos a almacenes de datos relacionales que trataremos más adelante en este capítulo, o deberíamos buscar otras alternativas.
Bases de datos NoSQL
El término NoSQL suele malinterpretarse como no SQL. Más bien, se explica mejor como no sólo SQL. Esto se debe a que estas bases de datos siguen teniendo un buen soporte de consultas y comportamientos similares a SQL, junto con muchas otras ventajas, como la escalabilidad y la capacidad de almacenar y procesar datos semiestructurados. Las bases de datos NoSQL siguen el principio del esquema en lectura: el esquema de los datos se define sólo en el momento de acceder a ellos para procesarlos, y no cuando se escriben en el disco.
Estas bases de datos son las más adecuadas para manejar big data, ya que están diseñadas para la escalabilidad y el rendimiento. Como los almacenes NoSQL son de naturaleza distribuida, podemos utilizarlos en múltiples aplicaciones nativas de la nube. Para optimizar el rendimiento, los datos almacenados en bases de datos NoSQL no suelen estar normalizados y pueden tener campos redundantes. Cuando los datos estén normalizados, habrá que realizar uniones de tablas al recuperar los datos, y esto puede llevar mucho tiempo debido a la naturaleza distribuida de estas bases de datos. Además, sólo unos pocos almacenes NoSQL admiten transacciones, lo que compromete su rendimiento y escalabilidad; por tanto, en general no se recomienda almacenar datos en almacenes NoSQL que necesiten garantías de transacción.
El uso de los almacenes NoSQL en las aplicaciones nativas de la nube varía, ya que hay varios tipos de almacenes NoSQL y, a diferencia de las bases de datos relacionales, no tienen comportamientos comunes. Estos almacenes NoSQL pueden clasificarse por la forma en que almacenan los datos y por las garantías de consistencia y disponibilidad que ofrecen.
Algunos almacenes NoSQL comunes clasificados por la forma en que almacenan los datos son los siguientes:
- Almacén clave-valor
- Este contiene registros como pares clave-valor. Podemos utilizarlo para almacenar información de sesión de acceso basada en identificadores de sesión. Este tipo de almacenes se utilizan mucho para almacenar datos en caché. Redis es un popular almacén de datos clave-valor de código abierto. Memcached y Ehcache son otras opciones populares.
- Almacén de columnas
-
Este almacena múltiples pares de clave (columna) y valor en cada una de sus filas, como se muestra en la Figura 4-2. Estos almacenes son un buen ejemplo de esquema en lectura: podemos escribir cualquier número de columnas durante la fase de escritura, y cuando se recuperan los datos, podemos especificar sólo las columnas que nos interesa procesar. El almacén de columnas más utilizado es Apache Cassandra. Para quienes utilicen big data e infraestructura Apache Hadoop, Apache HBase puede ser una opción, ya que forma parte del ecosistema Hadoop.
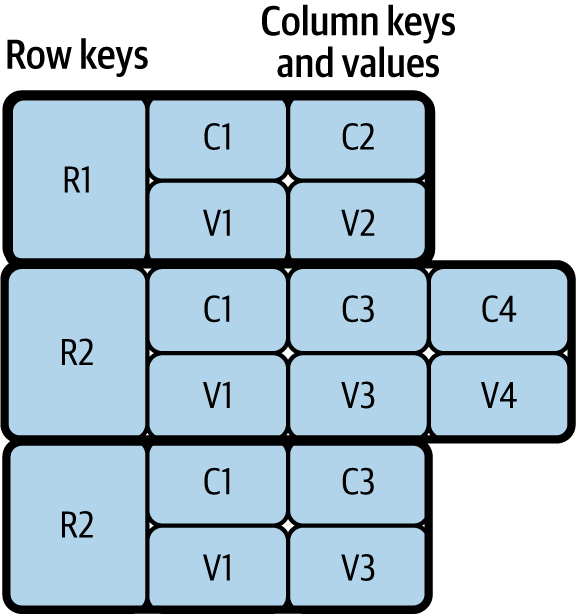
Figura 4-2. Almacén de columnas
- Almacén de documentos
- Este puede almacenar datos semiestructurados como documentos JSON y XML. También nos permite procesar los documentos almacenados mediante expresiones de ruta JSON y XML. Estos almacenes de datos son populares porque pueden almacenar mensajes JSON y XML, que suelen utilizar las aplicaciones frontales y las API para comunicarse. MongoDB, Apache CouchDB, y CouchBase son opciones populares para almacenar documentos JSON.
- Tienda gráfica
- Estos almacenan datos como nodos y utilizan perímetros para representar la relación entre los nodos de datos. Estos almacenes son multidimensionales y resultan útiles para construir y consultar redes, como las redes de amigos en los medios sociales y las redes de transacciones para detectar fraudes. Neo4j, el almacén de datos de grafos más popular, es muy utilizado por los líderes del sector.
Muchos otros tipos de almacenes NoSQL, como los almacenes de objetos y los almacenes de datos de series temporales, pueden ayudar a almacenar y consultar datos especializados específicos para cada caso de uso. Algunos almacenes también tienen un comportamiento multimodelo; pueden pertenecer a varias de las categorías anteriores. Por ejemplo, Amazon DynamoDB puede funcionar como almacén de valores clave y documentos, y Azure Cosmos DB puede funcionar como almacén de valores clave, columnas, documentos y gráficos.
Los almacenes NoSQL son distribuidos, por lo que tienen que cumplir el teorema CAP; CAP significa consistencia, disponibilidad y tolerancia a la partición. Este teorema establece que una aplicación distribuida puede proporcionar o bien disponibilidad total o bien consistencia; no podemos conseguir ambas cosas a la vez que proporcionamos tolerancia a la partición de la red. Aquí, disponibilidad significa que el sistema es totalmente funcional cuando algunos de sus nodos están caídos, consistencia significa que una actualización/cambio en un nodo se propaga inmediatamente a otros nodos, y tolerancia a la partición significa que el sistema puede seguir funcionando incluso cuando algunos nodos no pueden conectarse entre sí. Algunos almacenes priorizan la consistencia sobre la disponibilidad, mientras que otros priorizan la disponibilidad sobre la consistencia.
Digamos que tenemos que llevar un registro e informar del número de ciudadanos del país, y que omitir los últimos datos en el cálculo no causará un error significativo en el resultado final. Podemos utilizar un almacén de datos que favorezca la disponibilidad. En cambio, cuando necesitamos hacer un seguimiento de las transacciones con fines empresariales, debemos elegir un almacén de datos que favorezca la coherencia.
La Tabla 4-1 clasifica los almacenes de datos NoSQL en términos de consistencia y disponibilidad .
| Favorece la coherencia | Favorecer la disponibilidad | |
|---|---|---|
| Almacenes clave-valor | Redis, Memcached | DynamoDB, Voldemort |
| Almacenes de columna | Google Cloud Bigtable, Apache HBase | Apache Cassandra |
| Almacenes de documentos | MongoDB, Terrastore | CouchDB, SimpleDB |
| Almacenes gráficos | Azure Cosmos DB | Neo4j |
Aunque algunos favorecen la consistencia y otros la disponibilidad, otros almacenes de datos NoSQL (como Cassandra y DynamoDB) pueden proporcionar ambas. Por ejemplo, en Cassandra podemos definir niveles de consistencia como Uno, Quórum o Todos. Cuando el nivel de consistencia se establece en Uno, los datos se leen/escriben en un solo nodo del clúster, lo que proporciona disponibilidad total con consistencia eventual. Durante la consistencia eventual, los datos se propagan finalmente a otros nodos, y las lecturas pueden quedar obsoletas durante este periodo. Por otra parte, cuando se establece en Todos, los datos se leen/escriben desde todos los nodos antes de que la operación tenga éxito, proporcionando una fuerte consistencia con degradación del rendimiento. Pero cuando se utiliza Quórum, sólo se leen/escriben datos desde el 51% de los nodos. De este modo, podemos garantizar que la última actualización estará disponible en al menos un nodo, proporcionando tanto consistencia como disponibilidad con una mínima sobrecarga de rendimiento.
Por tanto, te recomendamos que comprendas la naturaleza de los datos y sus casos de uso dentro de las aplicaciones nativas de la nube antes de elegir el almacén de datos NoSQL adecuado. Recuerda que el formato de los datos, así como sus requisitos de coherencia y disponibilidad, pueden influir en tu elección del almacén de datos.
Almacenamiento del sistema de archivos
El sistema de almacenamiento de archivos es el mejor para almacenar datos no estructurados en aplicaciones nativas de la nube. A diferencia de los almacenes NoSQL, no intenta comprender los datos, sino que se limita a optimizar su almacenamiento y recuperación. También podemos utilizar el almacenamiento del sistema de archivos para almacenar grandes datos de aplicaciones como caché, ya que puede ser más barato que recuperar datos repetidamente a través de la red.
Aunque ésta es la opción más barata, puede no ser una solución óptima cuando se almacenan datos de texto o semiestructurados, ya que nos obligará a cargar varios archivos al buscar una sola entrada de datos. En estos casos, recomendamos utilizar sistemas de indexación como Apache Solr o Elasticsearch para facilitar la búsqueda.
Cuando es necesario almacenar datos a escala, se pueden utilizar sistemas de archivos distribuidos. La opción de código abierto más conocida es Hadoop Distributed File System (HDFS), y las opciones populares en la nube incluyen Amazon Simple Storage Service (S3), Azure Storage services y Google Cloud Storage.
Resumen del almacén de datos
Hemos hablado de tres tipos de almacenes de datos: relacionales, NoSQL y sistemas de archivos. Las aplicaciones nativas de la nube deben utilizar almacenes de datos relacionales cuando necesiten garantías transaccionales y cuando los datos deban estar estrechamente acoplados a la aplicación.
Cuando los datos contienen campos semiestructurados o no estructurados, pueden separarse y almacenarse en almacenes NoSQL o de sistemas de archivos para conseguir escalabilidad sin perder las garantías transaccionales. Las aplicaciones pueden optar por almacenar en NoSQL cuando la cantidad de datos es extremadamente grande, necesita una capacidad de consulta o está semiestructurada, o el almacén de datos está suficientemente especializado para manejar el caso de uso específico de la aplicación, como el procesamiento de grafos.
En todos los demás casos, recomendamos almacenar los datos en almacenes de sistemas de archivos, ya que están optimizados para el almacenamiento y la recuperación de datos sin procesar su contenido. A continuación, veremos cómo pueden implementarse, gestionarse y compartirse estos datos entre aplicaciones nativas de la nube.
Gestión de datos
Ahora que hemos cubierto los tipos de datos y los correspondientes almacenes de datos utilizados para desarrollar aplicaciones nativas de la nube, esta sección trata de cómo se pueden implementar, gestionar y compartir los datos y el almacén de datos entre esas aplicaciones. Los datos pueden gestionarse mediante técnicas centralizadas, descentralizadas o híbridas. A continuación profundizaremos en cada opción.
Gestión centralizada de datos
Gestión centralizada de datos es el tipo más común en las aplicaciones tradicionales centradas en datos. En este enfoque, todos los datos se almacenan en una única base de datos, y varios componentes de la aplicación pueden acceder a ellos para procesarlos(Figura 4-3).
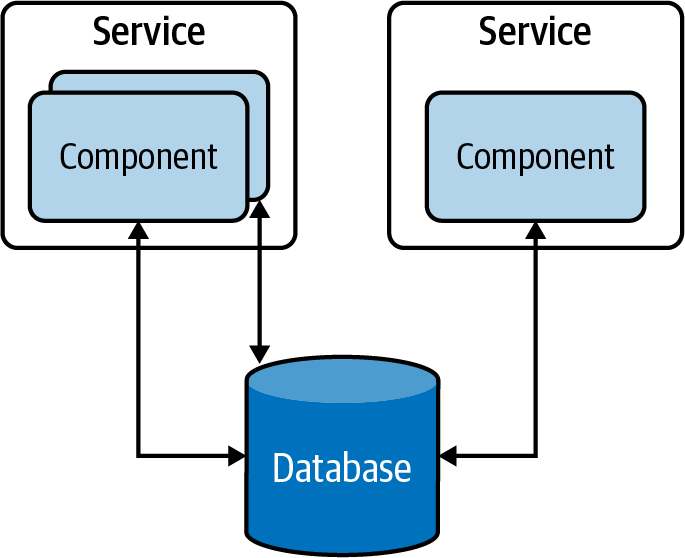
Figura 4-3. Gestión centralizada de datos en una aplicación tradicional centrada en datos
Este enfoque tiene varias ventajas; por ejemplo, los datos de estas tablas de la base de datos pueden normalizarse, lo que proporciona una gran coherencia de los datos. Además, como los componentes pueden acceder a todas las tablas, el almacenamiento centralizado de datos ofrece la posibilidad de ejecutar procedimientos almacenados en varias tablas y recuperar los resultados más rápidamente. Por otro lado, esto proporciona un acoplamiento estrecho entre las aplicaciones, y dificulta la capacidad de evolucionar las aplicaciones de forma independiente. Por lo tanto, se considera un antipatrón a la hora de construir aplicaciones nativas de la nube.
Gestión descentralizada de datos
Para superar los problemas de con la gestión centralizada de datos, cada componente funcional independiente puede modelarse como un microservicio que tiene almacenes de datos separados, exclusivos para cada uno de ellos. Este enfoque descentralizado de gestión de datos, ilustrado en la Figura 4-4, nos permite escalar microservicios de forma independiente sin afectar a otros microservicios.
Estas bases de datos no introducen el acoplamiento que puede hacer más arriesgado y difícil el cambio. Aunque los propietarios de la aplicación tienen menos libertad para gestionar o hacer evolucionar los datos, segregarlos en cada microservicio para que sean gestionados por sus equipos/propietarios no sólo resuelve los problemas de gestión y propiedad de los datos, sino que también mejora el tiempo de desarrollo de las implementaciones de nuevas funciones y los ciclos de lanzamiento.
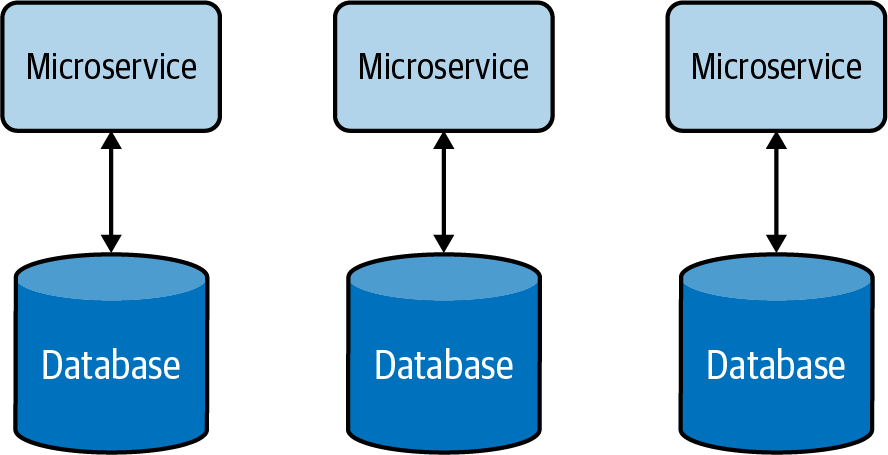
Figura 4-4. Gestión descentralizada de datos
La gestión descentralizada de datos permite a los servicios elegir el almacén de datos más adecuado para su caso de uso. Por ejemplo, un servicio de Pago puede utilizar una base de datos relacional para realizar transacciones, mientras que un servicio de Consulta puede utilizar un almacén de documentos para almacenar los detalles de la consulta, y un servicio de Cesta de la Compra puede utilizar un almacén distribuido de valores clave para almacenar los artículos elegidos por el cliente.
Gestión híbrida de datos
Aparte de las ventajas de utilizar una única base de datos que hemos comentado en el apartado anterior, hay otras ventajas operativas que puede proporcionar. Por ejemplo, ayuda a cumplir las modernas leyes de protección de datos y facilita la aplicación de la seguridad, ya que los datos residen en un lugar central. Por lo tanto, es aconsejable que todos los datos de los clientes se gestionen a través de unos pocos microservicios dentro de un contexto delimitado seguro, y proporcionar la propiedad de los datos a uno o unos pocos equipos bien formados para aplicar las políticas de protección de datos .
Por otra parte, una de las desventajas de la gestión descentralizada de datos es el coste de gestionar almacenes de datos independientes para cada servicio. Por lo tanto, para algunas organizaciones pequeñas y medianas, podemos utilizar un enfoque híbrido de gestión de datos(Figura 4-5). Esto permite que varios microservicios compartan la misma base de datos, siempre que estos servicios estén gobernados por el mismo equipo y residan en el mismo contexto delimitado.
Pero al utilizar la gestión híbrida de datos, tenemos que asegurarnos de que nuestros servicios no acceden directamente a tablas propiedad de otros servicios. De lo contrario, esto aumentará la complejidad del sistema y dificultará la separación de datos en varias bases de datos en el futuro.
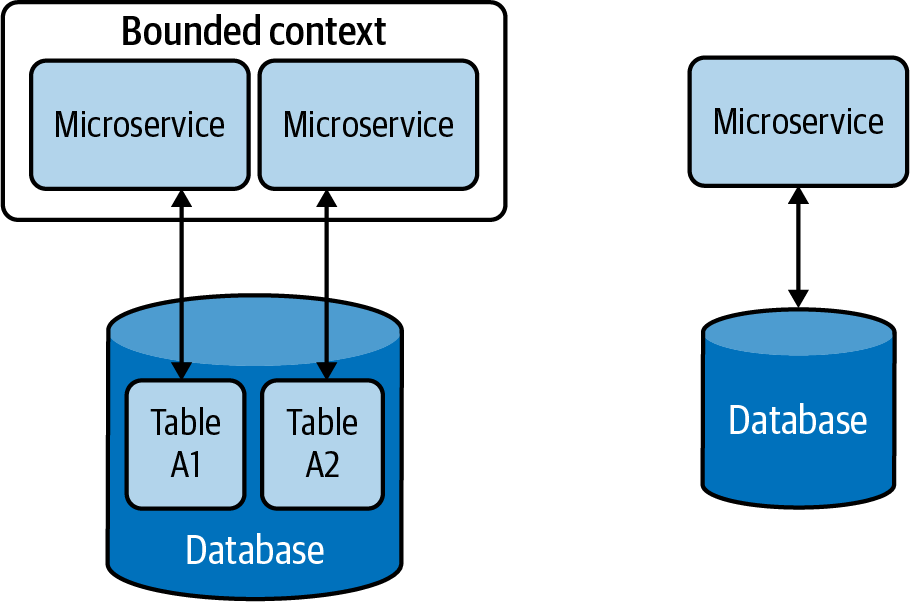
Figura 4-5. Gestión híbrida de datos
Resumen de la gestión de datos
En esta sección, hemos visto cómo se modelan las aplicaciones nativas de la nube como microservicios independientes, y cómo conseguimos escalabilidad, mantenibilidad y seguridad, utilizando exclusivamente almacenes de datos independientes para cada microservicio(Figura 4-6).
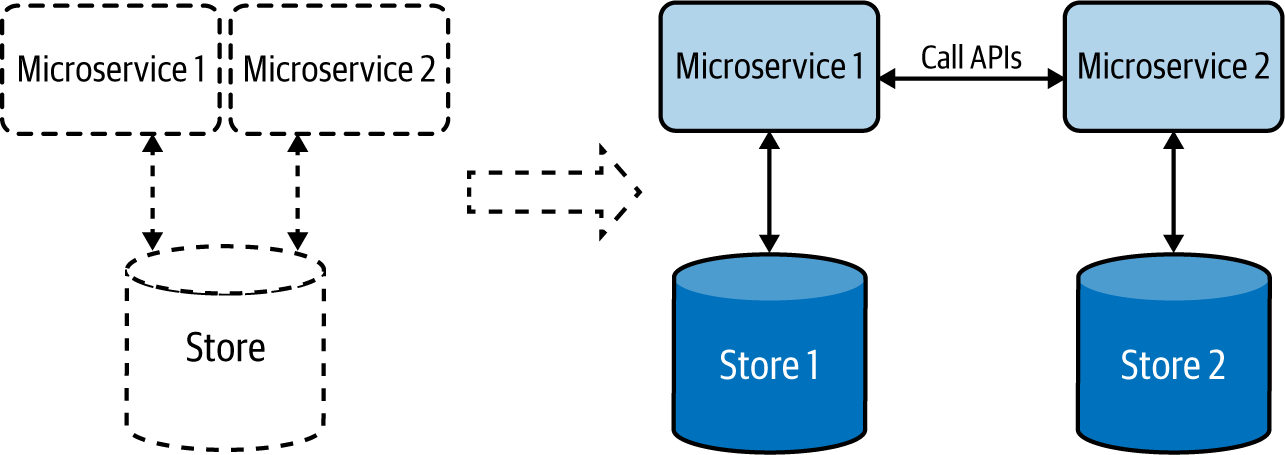
Figura 4-6. Las aplicaciones nativas en la nube, representadas a la derecha, tienen un almacén de datos dedicado para cada microservicio.
Hemos visto cómo las aplicaciones se comunican entre sí mediante API bien definidas, y podemos utilizar este enfoque para recuperar datos de las respectivas aplicaciones sin acceder directamente a sus almacenes de datos.
Ahora que hemos cubierto los tipos y formatos de datos, así como las opciones de almacenamiento y gestión, profundicemos en los patrones relacionados con los datos que podemos aplicar al desarrollar nuestras aplicaciones nativas de la nube. Los patrones de gestión de datos proporcionan una buena manera de entender cómo manejar mejor los datos con respecto a su composición, escalabilidad, optimización del rendimiento, fiabilidad y seguridad. A continuación se tratan en detalle los patrones de gestión de datos relevantes, incluyendo su uso, casos de uso en el mundo real, consideraciones y patrones relacionados.
Patrones de composición de datos
Esta sección describe las formas en que los datos pueden compartirse y combinarse de una manera significativa que te ayude a construir eficientemente aplicaciones nativas de la nube. Consideremos una sencilla aplicación nativa de la nube y su almacén de datos, mostrados en la Figura 4-7. Aquí, el microservicio de la aplicación es totalmente propietario de los datos que residen en su almacén de datos.
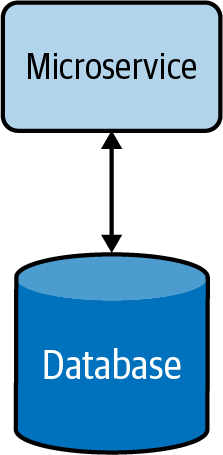
Figura 4-7. Microservicio básico nativo en la nube
Cuando el servicio está sometido a una carga elevada, puede introducir una latencia alta debido al mayor tiempo de recuperación de los datos. Esto puede mitigarse utilizando una caché (Figura 4-8). Esto reduce la carga de la base de datos cuando se producen múltiples solicitudes de lectura y mejora el rendimiento general del servicio. Más adelante, en este mismo capítulo, encontrarás más información sobre los patrones de caché y otras técnicas de optimización del rendimiento.
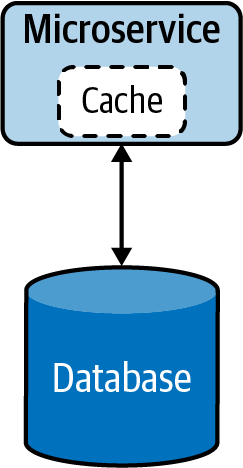
Figura 4-8. Microservicio nativo en la nube con caché
Cuando la funcionalidad del servicio se vuelve más compleja, el servicio puede dividirse en microservicios más pequeños(Figura 4-9). Durante esta fase, los datos relevantes también se dividirán y trasladarán junto con los nuevos servicios, ya que no es recomendable que varios servicios compartan los mismos datos.
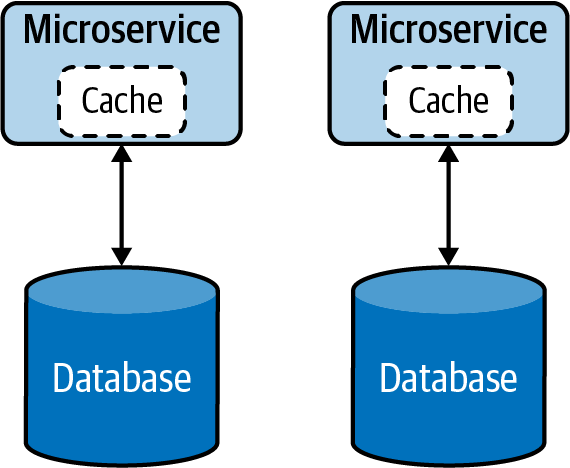
Figura 4-9. Segregación de microservicios por funcionalidad
A veces, dividir los datos en dos puede no ser sencillo, y podríamos necesitar una opción alternativa para compartir los datos de forma segura y reutilizable. El siguiente patrón de Servicio de Datos explica detalladamente cómo puede gestionarse.
Patrón de Servicio de Datos
El patrón Servicio de datos expone los datos de la base de datos como un servicio, denominado servicio de datos. El servicio de datos se convierte en el propietario, responsable de añadir y eliminar datos del almacén de datos. El servicio puede realizar búsquedas sencillas o incluso encapsular operaciones complejas al construir respuestas para solicitudes de datos.
Cómo funciona
Exponer los datos como un servicio de datos, como se muestra en la Figura 4-10, nos proporciona más control sobre esos datos. Esto nos permite presentar los datos en varias composiciones a varios clientes, aplicar seguridad e imponer un estrangulamiento basado en la prioridad, permitiendo que sólo los servicios críticos accedan a los datos durante situaciones de restricción de recursos, como picos de carga o fallos del sistema .
Estos servicios de datos pueden realizar operaciones sencillas de lectura y escritura en una base de datos o incluso ejecutar lógica compleja, como unir varias tablas o ejecutar procedimientos almacenados para construir respuestas de forma mucho más eficiente. Estos servicios de datos también pueden utilizar el almacenamiento en caché para mejorar su rendimiento de lectura.
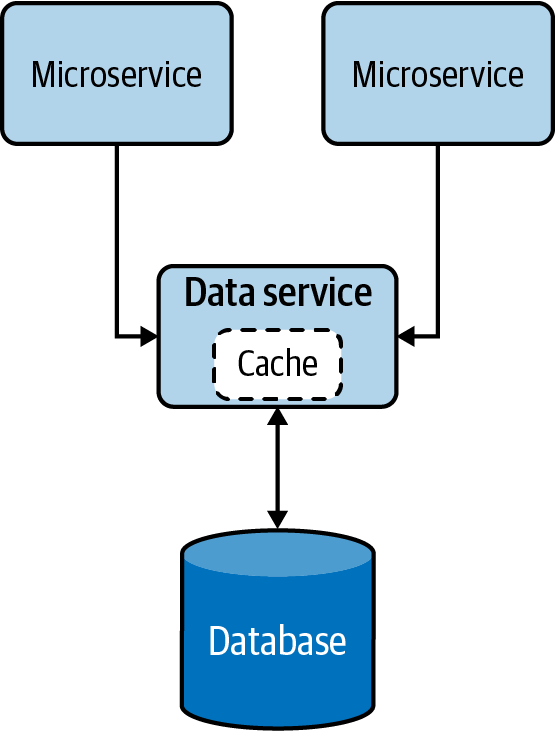
Figura 4-10. Patrón del Servicio de Datos
Cómo se utiliza en la práctica
Este patrón puede utilizarse cuando necesitamos permitir el acceso a datos que no pertenecen a un único microservicio, o cuando necesitamos abstraer almacenes de datos heredados/propios a otras aplicaciones nativas de la nube.
Permitir que varios microservicios accedan a los mismos datos
Podemos utilizar este patrón cuando los datos no pertenecen a ningún microservicio en particular; ningún microservicio es el propietario legítimo de esos datos, pero múltiples microservicios dependen de ellos para su funcionamiento. En tales casos, los datos comunes deben exponerse como un servicio de datos independiente, que permita a todas las aplicaciones dependientes acceder a los datos mediante APIs.
Por ejemplo, supongamos que un sistema de comercio electrónico tiene microservicios de Pedido y Detalle de Producto que necesitan acceder a los datos de descuento. Como el descuento no pertenece a ninguno de esos microservicios, debe crearse un servicio independiente para exponer los datos de descuento. Ahora, tanto los microservicios de Pedido como los de Detalle del Producto deben acceder al nuevo servicio de datos de descuento a través de las API para obtener información.
Exponer almacenes de datos abstractos heredados/propietarios
Podemos utilizar también este patrón para exponer almacenes de datos heredados locales o propietarios a otras aplicaciones nativas de la nube. Imaginemos que tenemos una base de datos heredada para registrar todas las transacciones comerciales de nuestra aplicación propietaria local. En este caso, si necesitamos que nuestras aplicaciones nativas de la nube accedan a esos datos, tenemos que utilizar su controlador de base de datos C# y asegurarnos de que todas ellas conocen la tabla y la estructura de la base de datos para acceder a los datos.
Puede que no sea una buena idea acceder a la base de datos directamente a través del controlador, ya que esto nos obligará a escribir todas nuestras aplicaciones nativas de la nube en C#, y todas nuestras aplicaciones deberán incorporar también el conocimiento de la tabla. En su lugar, podemos crear un único servicio de datos que se enfrente a la base de datos heredada y exponga esos datos mediante API bien definidas. Esto permitirá que otras aplicaciones nativas de la nube accedan a los datos mediante API y se desacoplen de la tabla de la base de datos subyacente y del lenguaje de programación. También nos permitirá migrar la base de datos a otra distinta en el futuro sin afectar a los servicios que dependen del servicio de datos.
Consideraciones
Al construir aplicaciones nativas de la nube, acceder a los mismos datos a través de múltiples microservicios se considera un antipatrón. Esto introducirá un acoplamiento estrecho entre los microservicios y no permitirá que los microservicios escalen y evolucionen por sí mismos. El patrón Servicio de datos puede ayudar a reducir el acoplamiento proporcionando API gestionadas para acceder a los datos.
Este patrón no debe utilizarse cuando los datos puedan asociarse claramente a un microservicio existente, ya que introducir microservicios innecesarios causará una complejidad de gestión adicional.
Patrón de Servicios de Datos Compuestos
El patrón de Servicios de Datos Compuestos realiza la composición de datos combinando datos de más de un servicio de datos y, cuando es necesario, realiza una agregación bastante compleja para proporcionar una respuesta más rica y concisa. Este patrón también se denomina patrón Mashup del lado del servidor, ya que la composición de datos se produce en el servicio y no en el consumidor de datos.
Cómo funciona
Este patrón, que se parece al patrón de Orquestación de Servicios del Capítulo 3, combina datos de varios servicios y de su propio almacén de datos en un servicio de datos compuesto. Este patrón no sólo elimina la necesidad de que varios microservicios realicen operaciones de composición de datos, sino que también permite que los datos combinados se almacenen en caché para mejorar el rendimiento(Figura 4-11).
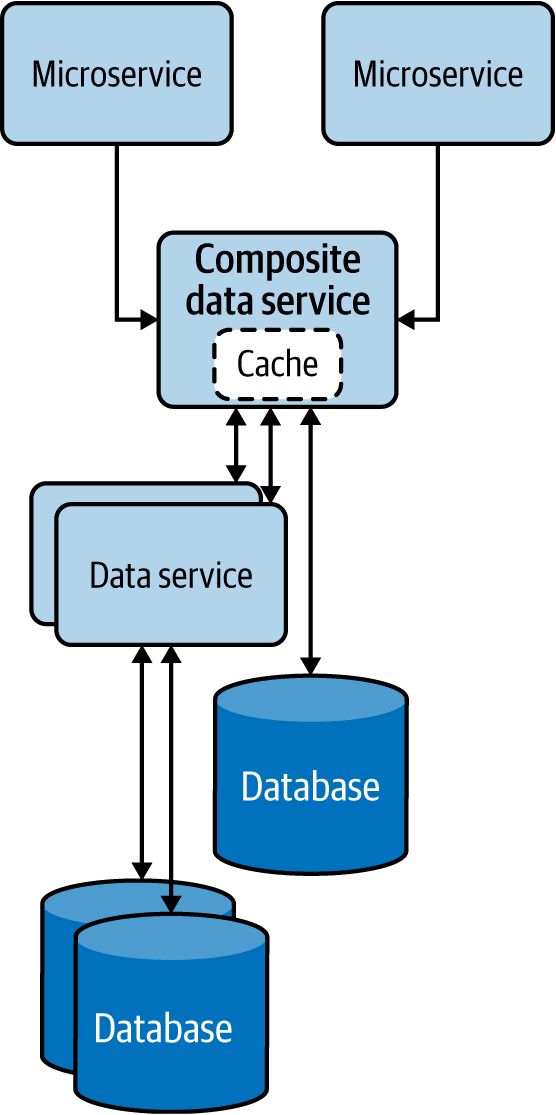
Figura 4-11. Patrón de Servicios de Datos Compuestos
Cómo se utiliza en la práctica
Este patrón puede utilizarse cuando necesitamos eliminar varios microservicios que repiten la misma composición de datos. Los servicios de datos de grano fino obligan a los clientes a consultar varios servicios para construir los datos que desean. Podemos utilizar este patrón para reducir el trabajo duplicado realizado por los clientes y consolidarlo en un servicio común.
Tomemos un sistema de comercio electrónico que calcula el inventario de productos agregando varios servicios de datos expuestos por diferentes tiendas de cumplimiento. En este caso, introducir un servicio común para combinar datos de todos los servicios de cumplimiento puede ser beneficioso, ya que ayudará a eliminar el trabajo duplicado, reducirá la complejidad de cada cliente y ayudará a que los servicios de datos compuestos evolucionen sin entorpecer a los clientes.
Cuando estos datos se almacenan en caché en el servicio de datos compuestos, también puede mejorarse el tiempo de respuesta para la información de inventario. Esto se debe a que, en un intervalo de tiempo determinado, la mayoría de los microservicios accederán al mismo conjunto de datos, y el almacenamiento en caché puede mejorar drásticamente su rendimiento de lectura.
Consideraciones
Utiliza este patrón sólo cuando la consolidación sea lo suficientemente genérica y otros microservicios puedan reutilizar los datos consolidados. No recomendamos introducir capas innecesarias de servicios si no proporcionan composiciones de datos significativas que puedan reutilizarse. Sopesa las ventajas de la reutilización y la simplicidad de los clientes frente a la latencia adicional y la complejidad de gestión que añaden las capas de servicios .
Patrón Mashup del lado del cliente
En el patrón Client-Side Mashup, los datos se recuperan de varios servicios y se consolidan en el lado del cliente. El cliente suele ser un navegador que carga los datos mediante llamadas Ajax asíncronas.
Cómo funciona
Este patrón utiliza la carga asíncrona de datos, como se muestra en la Figura 4-12. Por ejemplo, cuando un navegador que utiliza este patrón está cargando una página web, carga y renderiza primero parte de la página web, mientras carga el resto de la página web. Este patrón utiliza scripts del lado del cliente, como JavaScript, para cargar asíncronamente el contenido en el navegador web.
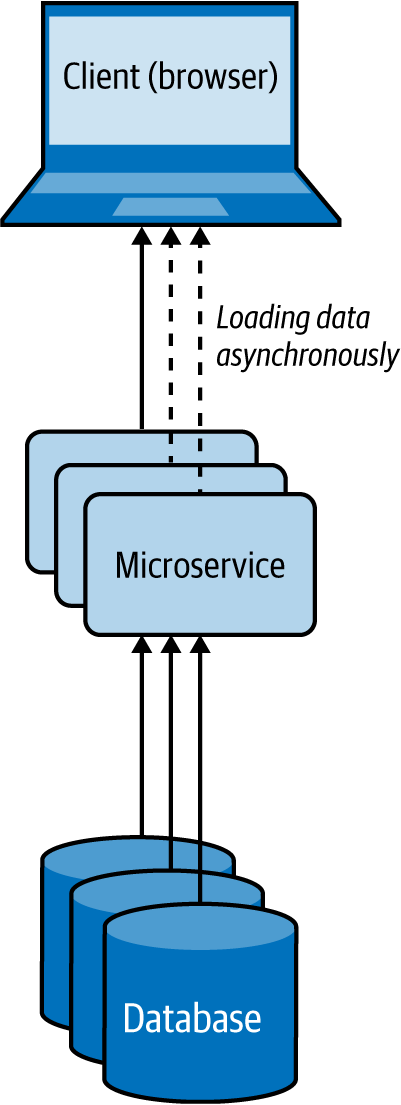
Figura 4-12. Mashup del lado del cliente en un navegador web
En lugar de dejar que el usuario espere más tiempo cargando todo el contenido del sitio web a la vez, este patrón utiliza múltiples llamadas asíncronas para obtener diferentes partes del sitio web y renderiza cada fragmento cuando llega. Estas aplicaciones también se denominan aplicaciones ricas de Internet(RIA).
Cómo se utiliza en la práctica
Este patrón puede utilizarse cuando necesitamos presentar los datos disponibles lo antes posible, mientras proporcionamos más detalles después, o cuando queremos dar la percepción de que la página web se carga mucho más rápido.
Presenta datos críticos con baja latencia
Tomemos un caso de uso de un sistema de comercio electrónico como Amazon; cuando el usuario carga una página de detalles del producto, debemos ser capaces de presentar todos los datos críticos que el usuario espera, con la menor latencia. Obtener estas reseñas de productos y cargar imágenes puede llevar tiempo, así que renderizamos la página con los detalles básicos del producto con la imagen por defecto, y luego utilizamos llamadas Ajax para cargar otras imágenes y reseñas de productos, y actualizar la página web dinámicamente. Este enfoque nos permitirá entregar al usuario los datos más importantes mucho más rápido que esperar a que se obtengan todos los datos.
Dar la percepción de que la página web se carga más rápido
Si estamos recuperando contenido HTML poco relacionado y construyendo la página web mientras el usuario la está cargando, y si podemos permitir que el usuario vea parte del contenido mientras se carga el resto, entonces podemos dar la percepción de que el sitio web se está cargando más rápidamente. Esto mantiene al usuario enganchado al sitio web hasta que el resto de los datos está disponible y, en última instancia, puede mejorar la experiencia del usuario.
Consideraciones
Utiliza este patrón sólo cuando los datos parciales cargados en primer lugar puedan presentarse al usuario o utilizarse de forma significativa. No aconsejamos utilizar este patrón cuando los datos recuperados deban combinarse y transformarse con datos posteriores mediante algún tipo de unión antes de que puedan presentarse al usuario.
Resumen de los patrones de composición de datos
En esta sección se han esbozado los patrones de composición de datos más utilizados en el desarrollo de aplicaciones nativas de la nube. La Tabla 4-2 resume cuándo debemos y cuándo no debemos utilizar estos patrones y las ventajas de cada uno.
Patrones de escalado de datos
Cuando aumenta la carga de en las aplicaciones nativas de la nube, el servicio o el almacén pueden convertirse en un cuello de botella. Los patrones para escalar servicios se tratan en el Capítulo 3. Aquí veremos cómo escalar datos. Cuando los datos pueden clasificarse como big data, podemos utilizar bases de datos NoSQL o sistemas de archivos distribuidos. Estos sistemas hacen el trabajo pesado de escalar y particionar los datos y reducen la complejidad de desarrollo y gestión.
Sin embargo, los requisitos de consistencia y transaccionalidad de las aplicaciones críticas para el negocio pueden seguir exigiéndonos utilizar bases de datos relacionales, y como las bases de datos relacionales no escalan por defecto, es posible que tengamos que alterar la arquitectura de la aplicación para lograr la escalabilidad de los datos. En esta sección, profundizaremos en los patrones que pueden ayudarnos a facilitar el escalado de los almacenes de datos para almacenar y recuperar datos de forma óptima.
Patrón de fragmentación de datos
En el patrón de fragmentación de datos, el almacén de datos se divide en fragmentos, lo que permite almacenarlos y recuperarlos fácilmente a escala. Los datos se particionan por uno o varios de sus atributos para que podamos identificar fácilmente el fragmento en el que residen.
Cómo funciona
Para fragmentar los datos, podemos utilizar enfoques horizontales, verticales o funcionales. Veamos estas tres opciones en detalle:
- Separación horizontal de datos
-
Cada fragmento de tiene el mismo esquema, pero contiene registros de datos distintos en función de su clave de fragmentación. Una tabla de una base de datos se divide en varios nodos en función de estas claves de fragmentación. Por ejemplo, los pedidos de los usuarios se pueden compartir mediante el hash del ID del pedido en tres fragmentos, como se muestra en la Figura 4-13.
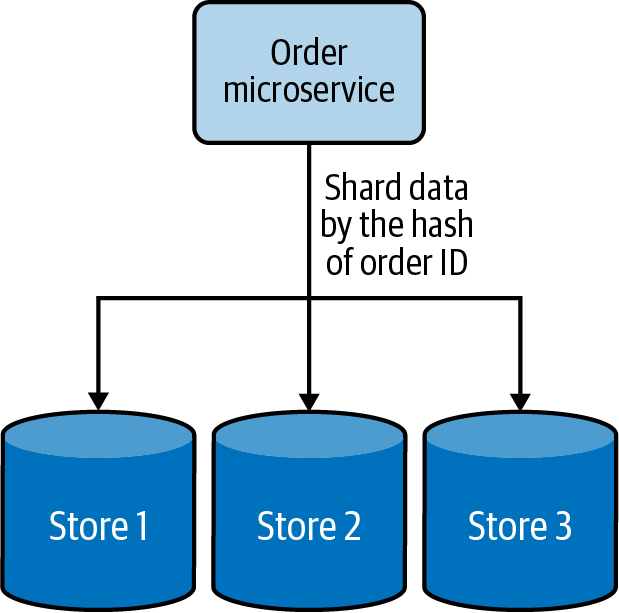
Figura 4-13. Separación horizontal de datos mediante hashing
- Desagregación vertical de datos
-
Cada fragmento de no tiene por qué tener un esquema idéntico y puede contener varios campos de datos. Cada fragmento puede contener un conjunto de tablas que no necesitan estar en otro fragmento. Esto es útil cuando necesitamos particionar los datos en función de la frecuencia de acceso a los mismos; podemos poner los datos a los que se accede con más frecuencia en un fragmento y mover el resto a un fragmento diferente. La Figura 4-14 muestra cómo los datos de usuario a los que se accede con frecuencia se separan de los demás datos.
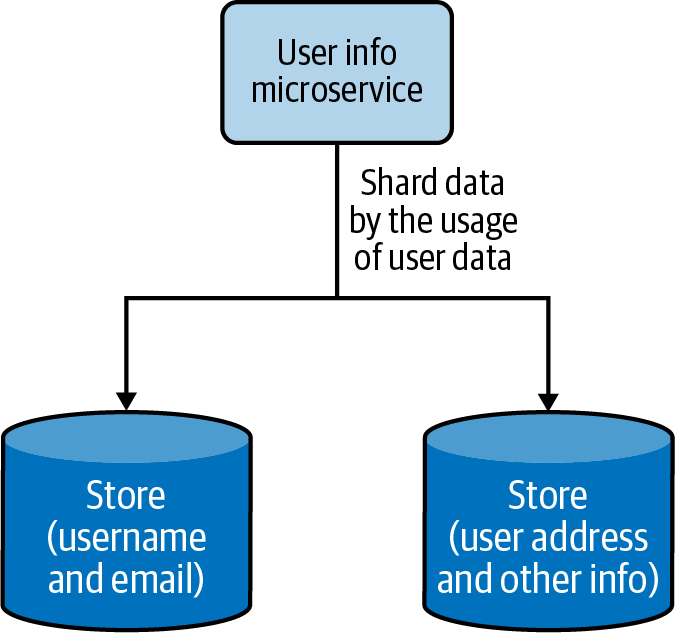
Figura 4-14. Desagregación vertical de datos basada en la frecuencia de acceso a los datos
- Separación funcional de datos
-
Los datos se dividen por casos de uso funcionales. En lugar de mantener todos los datos juntos, los datos pueden segregarse en diferentes fragmentos basados en diferentes funcionalidades. Esto también se alinea con el proceso de segregación de funciones en servicios funcionales separados en la arquitectura de aplicaciones nativas de la nube. La Figura 4-15 muestra cómo los detalles del producto y las reseñas se dividen en dos almacenes de datos.
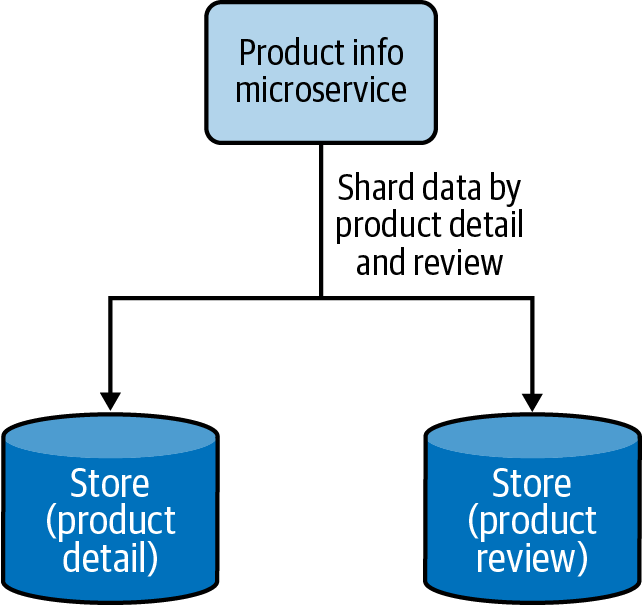
Figura 4-15. Separación funcional de datos segregando los detalles del producto y las reseñas en dos almacenes de datos
Las aplicaciones nativas de la nube pueden utilizar los tres enfoques para escalar los datos, pero existe un límite en cuanto a la segregación vertical y funcional de los datos. En última instancia, es necesario recurrir a la fragmentación horizontal de datos para escalar aún más los datos. Cuando utilizamos la fragmentación horizontal de datos, podemos desplegar una de las siguientes técnicas para localizar dónde hemos almacenado los datos:
- Compartimentación de datos basada en búsquedas
- Se utiliza un servicio de búsqueda o una caché distribuida para almacenar la correspondencia entre la clave del fragmento y la ubicación real de los datos físicos. Al recuperar los datos, la aplicación cliente comprobará primero el servicio de búsqueda para resolver la ubicación física real de la clave de fragmento prevista, y luego accederá a los datos desde esa ubicación. Si los datos se reequilibran o se reorganizan más tarde, el cliente tiene que volver a buscar la ubicación actualizada de los datos.
- Separación de datos por rangos
- Este enfoque especial de fragmentación del tipo puede aplicarse cuando la clave de fragmentación tiene caracteres secuenciales. Los datos se comparten en rangos, y como en la fragmentación basada en la búsqueda, se puede utilizar un servicio de búsqueda para determinar dónde está disponible el rango de datos dado. Este enfoque da los mejores resultados para la fragmentación de claves basadas en fecha y hora. Un rango de datos de un mes, por ejemplo, puede residir en el mismo fragmento, lo que permite al servicio recuperar todos los datos de una sola vez, en lugar de consultar varios fragmentos.
- Separación de datos basada en hash
- Construir una clave de fragmento basada en los campos de datos o dividir los datos por intervalos de fechas no siempre da como resultado fragmentos equilibrados. A veces necesitamos distribuir los datos aleatoriamente para generar fragmentos mejor equilibrados. Esto puede hacerse utilizando la fragmentación de datos basada en hash, que crea hashes basados en la clave del fragmento y los utiliza para determinar la ubicación de los datos del fragmento. Este enfoque no es el mejor cuando los datos se consultan en rangos, pero es ideal cuando se consultan registros individuales. En este caso, también podemos utilizar un servicio de búsqueda para almacenar la clave hash y el mapeo de la ubicación del fragmento, para facilitar la carga de datos.
Para que la fragmentación sea útil, los datos deben contener uno o un conjunto de campos que los identifiquen de forma única o los agrupen de forma significativa en subconjuntos. La combinación de estos campos genera la clave del fragmento/partición que se utilizará para localizar los datos. Los valores almacenados en los campos que contribuyen a la clave del fragmento deben ser fijos y no modificarse nunca al actualizar los datos. Esto se debe a que, cuando cambien, también cambiará la clave de fragmento, y si la clave de fragmento actualizada apunta ahora a una ubicación de fragmento diferente, también habrá que migrar los datos del fragmento actual a la nueva ubicación de fragmento. Mover datos entre fragmentos lleva mucho tiempo, por lo que debe evitarse a toda costa.
Cómo se utiliza en la práctica
Este patrón puede utilizarse cuando ya no podemos almacenar datos en un único nodo, o cuando necesitamos que los datos estén distribuidos para poder acceder a ellos con menor latencia.
Escala más allá de un único nodo
Este patrón puede ser útil cuando recursos como el almacenamiento, el cálculo o el ancho de banda de la red se convierten en un cuello de botella. La capacidad de un sistema para escalar verticalmente siempre es limitada cuando se añaden más recursos como espacio en disco, RAM o ancho de banda de red; tarde o temprano, la aplicación se quedará sin recursos. En lugar de trabajar en soluciones a corto plazo, particionar los datos y escalar horizontalmente te ayudará a escalar más allá de la capacidad de un solo nodo.
Segrega los datos para mejorar el tiempo de recuperación de los datos
Podemos segregar los datos de combinando varios campos de datos para generar claves de fragmentos especiales. Por ejemplo, imaginemos que tenemos una tienda de moda online y hemos creado una clave de fragmento que combina un vestido type y brand para almacenar datos. Si conocemos el tipo y la marca del vestido que buscamos, podremos asignarlo al fragmento correspondiente y recuperar rápidamente los datos. Pero si sólo conocemos type y size del vestido, no podremos construir una clave de fragmento válida. En este caso, tenemos que buscar en todos los fragmentos para encontrar la coincidencia, y esto puede afectar enormemente a nuestro rendimiento.
Este problema puede superarse construyendo claves de fragmentos jerárquicas. Por ejemplo, podemos construir la clave con el vestido type / brand. Si conocemos el tipo de vestido, podemos buscar todos los fragmentos que tengan ese vestido type y luego buscar en ellos el vestido concreto size. Esto limita el número de fragmentos que tenemos que buscar y mejora el rendimiento. Si necesitamos un rendimiento aún mejor para la combinación type y size, podemos crear índices secundarios utilizándolas. Estas claves de shard secundarias pueden ayudarnos a recuperar los datos con baja latencia. Pero el uso de índices secundarios puede aumentar el coste de modificación de los datos, ya que ahora también tenemos que actualizar las claves de los fragmentos secundarios cuando se actualizan los datos.
También podemos fragmentar los datos por intervalos de fecha y hora. Por ejemplo, si estamos procesando pedidos, es probable que nos interesen más los pedidos recientes que los antiguos. Podemos fragmentar los datos por intervalos de tiempo y almacenar los pedidos más recientes (como los del último mes o los del último trimestre) en un fragmento caliente y el resto en un conjunto de fragmentos archivados. Esto puede ayudar a recuperar los datos críticos con eficacia. En este caso, también deberíamos mover periódicamente los datos del fragmento caliente a los fragmentos archivados cuando se vuelvan antiguos.
Distribuye geográficamente los datos
Cuando los clientes están distribuidos geográficamente, podemos fragmentar los datos por regiones y acercarles los datos relevantes. Por ejemplo, en un caso de uso de un sitio web de venta al por menor, los detalles sobre los productos vendidos en cada región pueden almacenarse y servirse localmente. Esto ayudará a servir más peticiones con un tiempo de respuesta menor.
Algunos clientes pueden estar interesados en comprar productos de todo el mundo, por lo que es posible que necesitemos recuperar datos de varios shards distribuidos por regiones para satisfacer una solicitud. Para que este caso de uso funcione eficazmente, tenemos que modelar a los clientes de forma que puedan enviar una solicitud en abanico a todos los shards y recuperar datos simultáneamente. Por ejemplo, si un usuario está buscando los productos, podemos enviar una solicitud en abanico y responder sólo con las 10 primeras entradas más rápidas que recibamos, pero si el usuario está buscando las opciones de precio más bajo por nombre, puede que tengamos que esperar a que llegue la respuesta de todos los fragmentos antes de mostrar los resultados. Ten en cuenta que podríamos mejorar el rendimiento mediante el almacenamiento en caché. Hablaremos de ello más adelante en este capítulo.
Consideraciones
Cuando utilizamos este patrón, es importante equilibrar al máximo los shards para que la carga se distribuya uniformemente. También es necesario monitorear la carga en cada fragmento y realizar un reequilibrio si la carga no se distribuye uniformemente. El desequilibrio puede producirse con el tiempo, debido a nuevos datos sesgados con inserciones, eliminaciones o un cambio en el comportamiento de consulta. Ten en cuenta que con los big data, el reequilibrio de los almacenes de datos puede llevar de un par de horas a días.
Para facilitar el reequilibrio, recomendamos hacer los fragmentos razonablemente pequeños. En los días iniciales del sistema, cuando los datos y la carga son bajos, todos los shards pueden vivir en el mismo nodo. Con el tiempo, cuando la carga aumente, uno o un conjunto de fragmentos pueden migrar a otros nodos. Esto no sólo permite una mayor escalabilidad a largo plazo, sino que también hace que cada migración de fragmentos sea relativamente pequeña, permitiendo que el reequilibrio de datos se produzca más rápidamente con menos interrupciones para todo el sistema.
También es importante disponer de varias copias de shards para gestionar con elegancia los fallos. Incluso cuando un nodo esté caído, tendremos acceso a los mismos datos en otro nodo, y esto puede ayudarnos a realizar tareas de mantenimiento sin que todo el sistema deje de estar disponible.
Cuando se trata de procesar la agregación de datos entre shards, las distintas agregaciones se comportan de forma diferente. Las agregaciones como suma, media, mínimo y máximo pueden procesar los datos de forma aislada en cada partición, recuperar los resultados y combinarlos para determinar los resultados finales. En cambio, las operaciones de agregación como la mediana requieren todos los datos a la vez, por lo que no pueden implementarse con gran precisión cuando se utilizan datos fragmentados.
No recomendamos utilizar campos autoincrementables al generar claves de fragmentos. Los fragmentos no se comunican entre sí, y debido al uso de campos autoincrementables, varios fragmentos pueden haber generado las mismas claves y referirse a datos diferentes con esas claves a nivel local. Esto puede convertirse en un problema cuando los datos se redistribuyan durante las operaciones de reequilibrio de datos.
Además, es importante seleccionar claves de fragmentos que den lugar a fragmentos bastante equilibrados. Sin fragmentos equilibrados, no se puede conseguir la escalabilidad esperada. El fragmento más grande siempre será el de peor rendimiento y acabará provocando cuellos de botella.
Patrón de Segregación de Responsabilidades de Mando y Consulta
El patrón Segregación de Responsabilidades de Comandos y Consultas(CQRS) separa las actualizaciones y las operaciones de consulta de un conjunto de datos, y permite que se ejecuten en almacenes de datos distintos. Esto da lugar a una actualización y recuperación más rápidas de los datos. También facilita el modelado de datos para manejar múltiples casos de uso, logra una gran escalabilidad y seguridad, y permite que los modelos de actualización y consulta evolucionen independientemente con interacciones mínimas.
Cómo funciona
Podemos separar las órdenes (actualizaciones/escrituras) y las consultas (lecturas) creando diferentes servicios responsables de cada una(Figura 4-16). Esto no sólo facilita la ejecución de servicios relacionados con las actualizaciones y las lecturas en nodos diferentes, sino que también ayuda a modelar servicios adecuados para esas operaciones y a escalar los servicios de forma independiente.
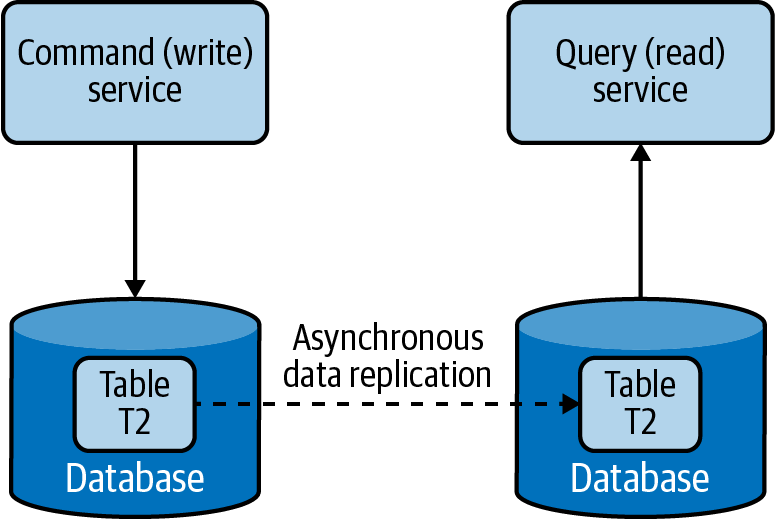
Figura 4-16. Separar las operaciones de comando y consulta
El comando y la consulta no deben tener información específica del almacén de datos, sino datos de alto nivel relevantes para la aplicación. Cuando se emite un comando a un servicio, éste extrae la información del mensaje y actualiza el almacén de datos. Luego enviará esa información como un evento de forma asíncrona a los servicios que atienden las consultas, para que puedan construir su modelo de datos. Para pasar los eventos entre servicios se puede utilizar el patrón Event Sourcing, que utiliza un sistema de colas basado en registros, como Kafka. De este modo, los servicios de consulta pueden leer datos de las colas de eventos y realizar actualizaciones masivas en sus almacenes locales, en el formato óptimo para servir esos datos.
Cómo se utiliza en la práctica
Podemos utilizar este patrón cuando queramos utilizar modelos de dominio distintos para las órdenes y las consultas, y cuando necesitemos separar las actualizaciones y la recuperación de datos por motivos de rendimiento y seguridad. Veamos estos enfoques en detalle a continuación.
Utilizar diferentes modelos de dominio para el mando y la consulta
En el caso de un sitio web de venta al por menor, puede que almacenemos la información detallada del producto y del inventario en una base de datos relacional normalizada. Esta podría ser nuestra mejor opción para actualizar eficazmente la información de inventario en cada compra. Pero puede que no sea la mejor opción para consultar estos datos a través de un navegador, ya que unir y convertir los datos a JSON puede llevar mucho tiempo. En ese caso, podemos utilizar este patrón para construir asíncronamente un conjunto de datos de consulta, como un almacén de documentos que almacene datos en formato JSON, y utilizarlo para realizar consultas. Entonces tendremos modelos de datos optimizados independientes para las operaciones de comando y de consulta.
Como los modelos de comandos y consultas no están estrechamente acoplados, podemos utilizar diferentes equipos para que sean propietarios de aplicaciones relacionadas con comandos y consultas, así como permitir que ambos modelos evolucionen independientemente según el caso de uso.
Distribuye las operaciones y reduce la contención de datos
Este patrón puede utilizarse cuando las aplicaciones nativas de la nube tienen operaciones de actualización de rendimiento intensivo, como validaciones de datos y seguridad, o transformaciones de mensajes, o tienen operaciones de consulta de rendimiento intensivo que contienen uniones complejas o mapeo de datos. Cuando se utiliza la misma instancia del almacén de datos tanto para el comando como para la consulta, puede producirse un rendimiento global deficiente debido a una mayor carga en el almacén de datos. Por tanto, al dividir las operaciones de comando y consulta, el CQRS no sólo elimina el impacto de una sobre la otra, mejorando el rendimiento y la escalabilidad del sistema, sino que también ayuda a aislar las operaciones que necesitan una mayor aplicación de la seguridad.
Dado que este patrón permite que los comandos y las consultas se ejecuten en distintos comercios, también permite que los sistemas de comandos y consultas tengan distintos requisitos de escalado. En el caso de uso del sitio web de venta al por menor, tenemos más consultas que comandos, y tenemos más vistas detalladas de productos que compras reales. Por tanto, podemos hacer que la mayoría de los servicios soporten las operaciones de consulta y que un par de servicios realicen las actualizaciones.
Consideraciones
Como este patrón segrega las operaciones de comando y consulta, puede proporcionar una alta disponibilidad. Aunque algunos servicios de comando o consulta dejen de estar disponibles, no se detendrá todo el sistema. En este patrón, podemos escalar las operaciones de consulta infinitamente, y con un número adecuado de réplicas, las operaciones de consulta pueden ofrecer garantías de tiempo de inactividad cero. Al escalar las operaciones de comando, puede que necesitemos utilizar patrones como Data Sharding para particionar los datos y eliminar posibles conflictos de fusión.
No se recomienda CQRS cuando se requiera una alta consistencia entre las operaciones de comando y consulta. Cuando se actualizan los datos, las actualizaciones se envían asíncronamente a los almacenes de consulta mediante eventos, utilizando patrones como Event Sourcing. Por tanto, utiliza CQRS sólo cuando la consistencia eventual sea tolerable. No se recomienda lograr una alta consistencia con la replicación síncrona de datos en entornos de aplicaciones nativas de la nube, ya que puede causar contención de bloqueos e introducir altas latencias.
Al utilizar este patrón, es posible que no podamos generar automáticamente modelos separados de comandos y consultas utilizando herramientas como el mapeo objeto-relacional (ORM). La mayoría de estas herramientas utilizan esquemas de bases de datos y suelen producir modelos combinados, por lo que puede que tengamos que modificar manualmente los modelos o escribirlos desde cero.
Nota
Aunque este patrón parece fascinante, recuerda que puede introducir mucha complejidad en la arquitectura del sistema. Ahora tenemos que mantener actualizadas varias fuentes de datos mediante el envío de eventos a través del patrón Event Sourcing, así como gestionar los duplicados de eventos y los fallos. Por tanto, si los modelos de comandos y consultas son bastante sencillos, y la lógica empresarial no es compleja, te aconsejamos encarecidamente que no utilices este patrón. Puede introducir más complejidad de gestión que las ventajas que puede producir.
Resumen de los patrones de escalado de datos
En esta sección se han esbozado los patrones de escalado de datos más utilizados en el desarrollo de aplicaciones nativas de la nube. La Tabla 4-3 resume cuándo debemos y cuándo no debemos utilizar estos patrones y las ventajas de cada uno .
Patrones de optimización del rendimiento
En las aplicaciones distribuidas nativas de la nube, los datos suelen ser la causa más común de los cuellos de botella. Los datos son difíciles de escalar, ya que los requisitos de consistencia pueden causar contención de bloqueos y sobrecarga de sincronización. Todo esto da lugar a sistemas con un rendimiento deficiente.
Una forma primitiva de mejorar el rendimiento es indexar los datos de. Aunque esto mejora el rendimiento de búsqueda, el uso excesivo de índices puede perjudicar el rendimiento tanto de lectura como de escritura. Para cada operación de escritura, es necesario actualizar todos los índices, lo que hace que las bases de datos realicen múltiples escrituras. Del mismo modo, cuando se trata de lecturas, los almacenes de datos pueden no ser capaces de cargar todos los índices y mantenerlos en memoria. Cada consulta puede necesitar realizar un par de operaciones de lectura, lo que se traduce en más tiempo para obtener los datos.
La desnormalización de datos también es una buena técnica para simplificar los modelos de lectura, ya que puede eliminar la necesidad de uniones y mejorar drásticamente el rendimiento de la lectura. Esto puede ser especialmente útil cuando combinamos este enfoque con el patrón CQRS, ya que los escritores pueden utilizar almacenes de datos normalizados para mantener una alta coherencia, permitiendo al mismo tiempo que las consultas lean de datos desnormalizados con eficiencia.
Además de estas técnicas sencillas, vamos a discutir cómo mejorar el rendimiento acercando los datos a la ejecución, acercando la ejecución a los datos, reduciendo la cantidad de datos que se transfieren o almacenando datos preprocesados para su uso futuro. En esta sección se analizan detalladamente estas pautas.
Patrón de vista materializada
El patrón de Vista Materializada proporciona la capacidad de recuperar datos de forma eficiente al realizar una consulta, acercando los datos a la ejecución y rellenando previamente las vistas materializadas. Este patrón almacena todos los datos relevantes de un servicio en su almacén de datos local y formatea los datos de forma óptima para servir a las consultas, en lugar de dejar que ese servicio llame a servicios dependientes para obtener datos cuando sea necesario.
Cómo funciona
Este patrón replica y traslada los datos de los servicios dependientes a su almacén de datos local y construye vistas materializadas(Figura 4-17). También construye vistas óptimas para consultar eficientemente los datos, de forma similar al patrón de Servicios de Datos Compuestos .
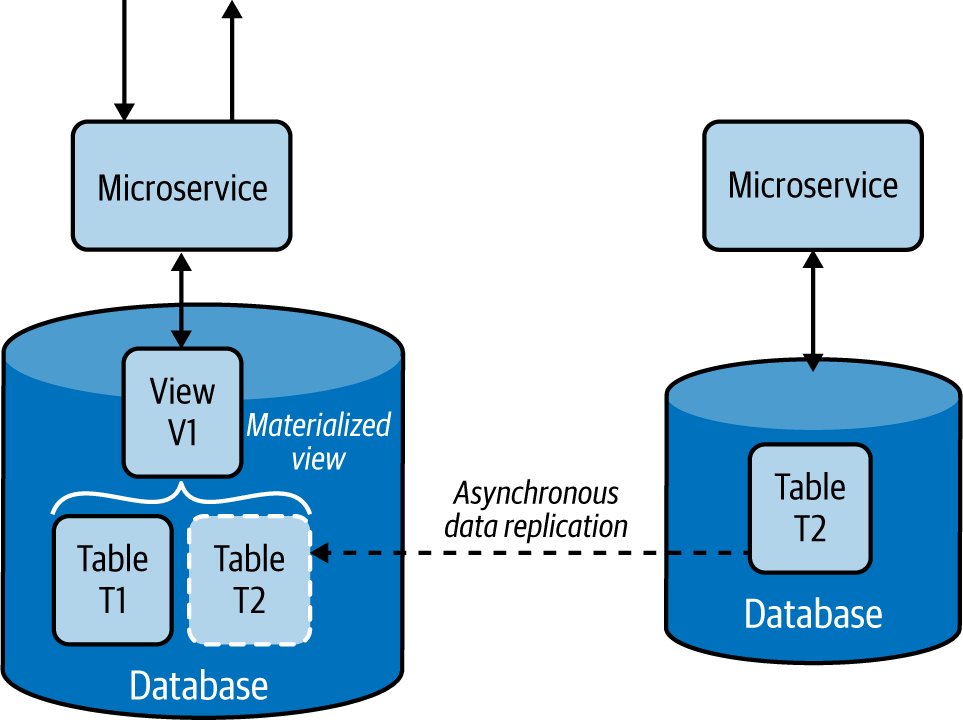
Figura 4-17. Servicio construido con el patrón Vista Materializada
Este patrón replica asíncronamente los datos de los servicios dependientes. Si las bases de datos admiten la replicación asíncrona de datos, podemos utilizarla como forma de transferir datos de un almacén de datos a otro. En su defecto, tenemos que utilizar el patrón Event Sourcing y utilizar flujos de eventos para replicar los datos. El servicio fuente envía cada operación de inserción, borrado y actualización de forma asíncrona a un flujo de eventos, y éstos se propagan a los servicios que crean vistas materializadas, donde obtendrán y cargarán los datos en sus almacenes locales. En el Capítulo 5 se trata en detalle el patrón Event Sourcing.
Cómo se utiliza en la práctica
Podemos utilizar este patrón cuando queramos mejorar la eficacia de la recuperación de datos eliminando uniones complejas y para reducir el acoplamiento con servicios dependientes.
Mejorar la eficacia de la recuperación de datos
Este patrón se utiliza cuando parte de los datos están disponibles localmente y el resto debe obtenerse de fuentes externas que incurren en una alta latencia. Por ejemplo, si estamos sirviendo una página de detalles del producto de una aplicación de comercio electrónico que, de hecho, recupera comentarios y valoraciones de un servicio de reseñas relativamente lento, podríamos estar mostrando los datos al usuario con una alta latencia. Mediante este patrón, la valoración global y los mejores y peores comentarios precalculados pueden replicarse en el almacén de datos del servicio de detalles del producto para mejorar la eficiencia de la recuperación de datos.
Incluso cuando introducimos datos en la misma base de datos, a veces unir varias tablas puede seguir siendo costoso. En este caso, podemos utilizar técnicas como las vistas de bases de datos relacionales para consolidar los datos en una vista materializada fácilmente consultable. Entonces, cuando necesitemos recuperar los detalles del producto, el servicio de detalles puede servir los datos con gran eficacia.
Proporcionar acceso a datos no sensibles alojados en sistemas seguros
En algunos casos de uso de, nuestro servicio de llamada podría depender de datos no sensibles que están detrás de una capa de seguridad, lo que requiere que el servicio tenga que autenticarse y pasar por comprobaciones de validación antes de recuperar los datos. Pero mediante este patrón, podemos replicar los datos no sensibles relevantes para el servicio y permitir que el servicio que llama acceda a los datos directamente desde su almacén local. Este enfoque no sólo elimina comprobaciones de seguridad y validaciones innecesarias, sino que también mejora el rendimiento.
Consideraciones
A veces, los datos dependientes pueden almacenarse en distintos tipos de almacenes de datos, o esos almacenes pueden contener muchos datos innecesarios. En este caso, deberíamos replicar sólo el subconjunto de datos relevante y almacenarlo en un formato que pueda ayudar a construir la vista materializada. Esto mejorará el rendimiento general de la consulta al utilizar los datos localmente, y reducirá el uso de ancho de banda al transferir los datos. Siempre debemos utilizar la replicación de datos asíncrona, ya que la replicación de datos síncrona puede causar contención de bloqueos e introducir altas latencias.
El patrón de Vista Materializada no sólo mejora el rendimiento del servicio al reducir el tiempo de recuperación de datos, sino que también simplifica la lógica del servicio al eliminar el procesamiento innecesario de datos y la necesidad de conocer los servicios dependientes.
Este patrón también proporciona resiliencia. Como los datos se replican en el almacén local, el servicio podrá realizar sus operaciones sin ninguna interrupción, incluso cuando el servicio fuente que proporcionó los datos no esté disponible.
No recomendamos utilizar este patrón cuando los datos puedan recuperarse de los servicios dependientes con baja latencia, cuando los datos de los servicios dependientes cambien rápidamente, o cuando la consistencia de los datos se considere importante para la respuesta. En estos casos, este patrón puede introducir una sobrecarga innecesaria y un comportamiento incoherente.
Este patrón no es ideal cuando la cantidad de datos que hay que mover es enorme o los datos se actualizan con frecuencia. Esto puede causar retrasos en la replicación y un gran ancho de banda de red, afectando a la precisión y al rendimiento de la aplicación. Considera la posibilidad de utilizar el patrón de localidad de datos (tratado a continuación) para estos casos de uso.
Patrón de localidad de datos
El objetivo del patrón de localidad de datos es acercar la ejecución a los datos. Esto se hace colocando los servicios con los datos o realizando la ejecución en el propio almacén de datos. Esto permite que la ejecución acceda a los datos con menos limitaciones, ayudando a acelerar la ejecución, y a reducir el ancho de banda mediante el envío de resultados agregados.
Cómo funciona
Mover la ejecución puede mejorar el rendimiento más que mover los datos. Cuando se dispone de suficientes recursos de CPU, añadir un servicio dedicado a la consulta en el nodo de datos, como se muestra en la Figura 4-18, puede mejorar el rendimiento al procesar la mayor parte de los datos localmente en lugar de transferirlos por la red.
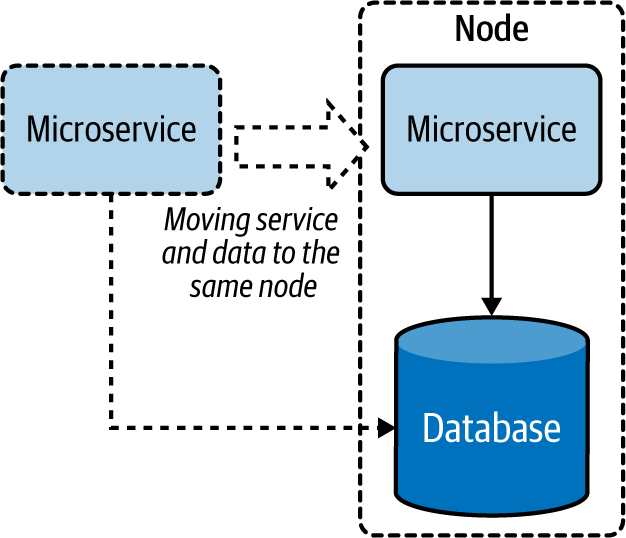
Figura 4-18. Acercar un microservicio al almacén de datos
Cuando el servicio no puede trasladarse al mismo nodo, trasladar el servicio a la misma región o centro de datos puede ayudar a utilizar mejor el ancho de banda. Este enfoque también puede ayudar a que el servicio almacene en caché los resultados y sirva a partir de ellos de forma más eficiente.
También podemos acercar la ejecución a los datos trasladándola al almacén de datos como procedimientos almacenados(Figura 4-19). Ésta es una forma estupenda de utilizar las capacidades de las bases de datos relacionales para optimizar el procesamiento y la recuperación de datos.
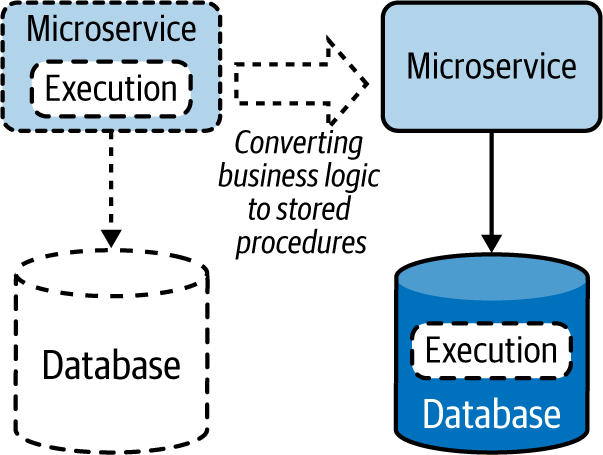
Figura 4-19. Trasladar la ejecución a los almacenes de datos como procedimientos almacenados
Cómo se utiliza en la práctica
Este patrón fomenta el acoplamiento de la ejecución con los datos para reducir la latencia y ahorrar ancho de banda, permitiendo que las aplicaciones nativas de la nube distribuidas funcionen eficientemente en la red.
Reduce la latencia al recuperar datos
Podemos utilizar este patrón cuando necesitemos recuperar datos de de una o varias fuentes de datos y realizar algún tipo de unión. Para procesar los datos, un servicio necesita recuperar todos los datos en su memoria local antes de poder realizar una operación con sentido. Esto requiere que los datos se transfieran a través de la red, lo que introduce latencia. Moviendo el servicio más cerca del almacén de datos (o cuando hay varios almacenes implicados, moviéndolo al almacén que contribuya a la mayor parte de la entrada) se reducirá la transferencia de datos a través de la red, reduciendo así el tiempo de recuperación de datos. También podemos utilizar este patrón para los servicios de composición que realizan uniones consumiendo datos de los almacenes de datos y otros servicios. Al acercar estos servicios a la fuente de datos, podemos mejorar su rendimiento general.
Reduce el uso de ancho de banda al recuperar datos
Este patrón es especialmente útil cuando necesitamos recuperar datos de múltiples fuentes para realizar operaciones de agregación o filtrado de datos. La salida de estas consultas será significativamente menor que su entrada. Al realizar la ejecución más cerca de la fuente de datos, sólo necesitamos transferir una pequeña cantidad de datos, lo que puede mejorar la utilización del ancho de banda. Esto es especialmente útil cuando los almacenes de datos son enormes y los clientes están distribuidos geográficamente. Es un buen enfoque cuando las aplicaciones nativas de la nube experimentan cuellos de botella en el ancho de banda.
Consideraciones
Aplicar el patrón de localidad de datos también puede ayudar a utilizar los recursos de CPU ociosos en los nodos de datos. La mayoría de los nodos de datos hacen un uso intensivo de E/S, y cuando las consultas que realizan son lo suficientemente sencillas, pueden tener muchos recursos de CPU ociosos. Trasladar la ejecución al nodo de datos puede utilizar mejor los recursos y optimizar el rendimiento general. Debemos tener cuidado de no mover todas las ejecuciones a los nodos de datos, ya que esto puede sobrecargarlos y causar problemas con la recuperación de datos.
Este patrón no es ideal cuando las consultas emiten la mayor parte de su entrada. Estos casos sobrecargarán los nodos de datos sin ningún ahorro de ancho de banda o rendimiento. Decidir cuándo utilizar este patrón depende del equilibrio entre el ancho de banda y la utilización de la CPU. Recomendamos utilizar este patrón cuando las ganancias conseguidas al reducir la transferencia de datos sean mucho mayores que el coste de ejecución adicional en que se incurre en los nodos de datos.
Nota
Transfiere la ejecución al almacén de datos sólo cuando ese almacén de datos sea utilizado exclusivamente por el microservicio que realiza la consulta. Ejecutar procedimientos almacenados en una base de datos compartida es un antipatrón, ya que puede causar implicaciones en el rendimiento y la gestión. Ten en cuenta también que la gestión de cambios de las bases de datos no es trivial, y si no se hace con cuidado, la actualización del procedimiento almacenado podría incurrir en tiempo de inactividad. Traslada la ejecución al almacén de datos sólo con precaución, y prefiere tener la lógica empresarial en el microservicio cuando no haya una mejora significativa del rendimiento.
Patrón de caché
El patrón de almacenamiento en caché almacena en memoria datos procesados o recuperados previamente, y sirve estos datos para consultas similares emitidas en el futuro. Esto no sólo reduce el procesamiento repetido de datos en los servicios, sino que también elimina las llamadas a servicios dependientes cuando la respuesta ya está almacenada en el servicio.
Cómo funciona
Una caché suele ser un almacén de datos en memoria que se utiliza para almacenar datos previamente procesados o recuperados, de forma que podamos reutilizar esos datos cuando sea necesario sin necesidad de volver a procesarlos o recuperarlos. Cuando se hace una petición para recuperar datos, y podemos encontrar los datos necesarios almacenados en la caché, tenemos un acierto de caché. Si los datos no están disponibles en la caché, tenemos un fallo de caché.
Cuando se produce un fallo en la caché, el sistema suele necesitar procesar o recuperar datos del almacén de datos, así como actualizar la caché con los datos recuperados para futuras consultas. Este proceso se denomina operación de lectura de la caché. Del mismo modo, cuando se solicita una actualización de los datos, debemos actualizarlos en el almacén de datos y eliminar o invalidar cualquier entrada relevante obtenida previamente y almacenada en la caché. Este proceso se denomina operación de escritura a través de la caché . En este caso, la invalidación es importante, porque cuando se vuelvan a solicitar esos datos, la caché no debe devolver los datos antiguos, sino que debe recuperar los datos actualizados del almacén mediante la operación de lectura en caché. Este comportamiento de lectura y actualización se conoce comúnmente como caché al margen, y la mayoría de las cachés comerciales admiten esta función por defecto.
El almacenamiento de datos en caché puede producirse en el lado del cliente o del servidor, o en ambos, y la propia caché puede ser local (almacenamiento de datos en una instancia) o compartida (almacenamiento de datos de forma distribuida).
Especialmente cuando la caché no es compartida, no puede seguir añadiendo datos, ya que acabará agotando la memoria disponible. Por ello, utiliza políticas de desalojo para eliminar algunos registros y dar cabida a otros nuevos. La política de desalojo más popular esla de uso menos reciente(LRU), que elimina los datos que no se utilizan durante un largo periodo para dar cabida a nuevas entradas. Otras políticas incluyen la primera en entrar, primera en salir(FIFO), que elimina la entrada cargada más antigua; la más recientemente utilizada(MRU), que elimina la entrada utilizada en último lugar; y las opciones basadas en disparadores que eliminan entradas en función de los valores del evento disparador. Debemos utilizar la política de desalojo adecuada a nuestro caso de uso.
Cuando los datos se almacenan en caché, los datos almacenados en el almacén de datos pueden ser actualizados por otras aplicaciones, por lo que retener datos durante un largo periodo en la caché puede provocar incoherencias entre los datos de la caché y los del almacén. Esto se gestiona utilizando un tiempo de caducidad para cada entrada de la caché. Esto ayuda a recargar los datos del almacén de datos cuando se agota el tiempo y mejora la coherencia entre la caché y el almacén de datos.
Cómo se utiliza en la práctica
Este patrón suele aplicarse cuando la misma consulta puede ser llamada repetidamente varias veces por uno o varios clientes, sobre todo cuando no tenemos suficiente conocimiento de qué datos se van a consultar a continuación.
Mejorar el tiempo de recuperación de datos
El almacenamiento en caché puede utilizarse cuando recuperar los datos de del almacén de datos requiere mucho más tiempo que recuperarlos de la caché. Esto es especialmente útil cuando el almacén original tiene que realizar operaciones complejas o está desplegado en una ubicación remota, y por tanto la latencia de la red es alta.
Mejorar la carga de contenido estático
La caché es mejor para datos estáticos de o para datos que se actualizan raramente. Especialmente cuando los datos son estáticos y pueden almacenarse en memoria, podemos cargar el conjunto completo de datos en la caché y configurar ésta para que no caduque. Esto mejora drásticamente el tiempo de recuperación de los datos y elimina la necesidad de cargarlos desde la fuente de datos original.
Reducir la contención del almacén de datos
Como reduce el número de llamadas al almacén de datos, podemos utilizar este patrón para reducir la contención del almacén de datos o cuando el almacén está sobrecargado con muchas peticiones concurrentes. Si la aplicación que consume los datos puede tolerar incoherencias, como que los datos estén desfasados unos minutos, también podemos implementar este patrón en almacenes de datos de escritura intensiva para reducir la carga de lectura y mejorar la estabilidad del sistema. En este caso, los datos de la caché acabarán siendo coherentes cuando se agote el tiempo de la caché.
Precarga de datos para mejorar el tiempo de recuperación de datos
Podemos precargar la caché total o parcialmente cuando conocemos el tipo de consultas que es más probable que se emitan. Por ejemplo, si estamos procesando pedidos y sabemos que las solicitudes llamarán sobre todo a los datos de la semana pasada, podemos precargar la caché con los datos de la semana pasada cuando iniciemos el servicio. Esto puede proporcionar un mejor rendimiento que cargar los datos bajo demanda. Cuando se omite la precarga, el servicio y el almacén de datos pueden sufrir un gran estrés, ya que la mayoría de las solicitudes iniciales provocarán una pérdida de caché.
Este patrón también puede utilizarse cuando sabemos qué datos se consultarán a continuación. Por ejemplo, si un usuario está buscando productos en un sitio web de venta al por menor, y sólo estamos mostrando las 10 primeras entradas, es probable que el usuario solicite las 10 siguientes. Precargar las 10 entradas siguientes en la caché puede ahorrar tiempo cuando se necesiten esos datos.
Consigue alta disponibilidad relajando la dependencia del almacén de datos
El almacenamiento en caché también puede utilizarse para lograr una alta disponibilidad, especialmente cuando la disponibilidad del servicio es más importante que la consistencia de los datos. Podemos gestionar las llamadas al servicio con datos almacenados en caché incluso cuando el almacén de datos backend no esté disponible. Como se muestra en la Figura 4-20, también podemos ampliar este patrón haciendo que la caché local recurra a una caché compartida o distribuida, que a su vez puede recurrir al almacén de datos cuando los datos no estén presentes. Este patrón puede incorporar el patrón de Conectividad Resistente con un disyuntor del que se habló en el Capítulo 3 para las llamadas de retorno, de modo que puedan reintentarse y reconectarse con gracia cuando los backends estén disponibles tras un fallo.
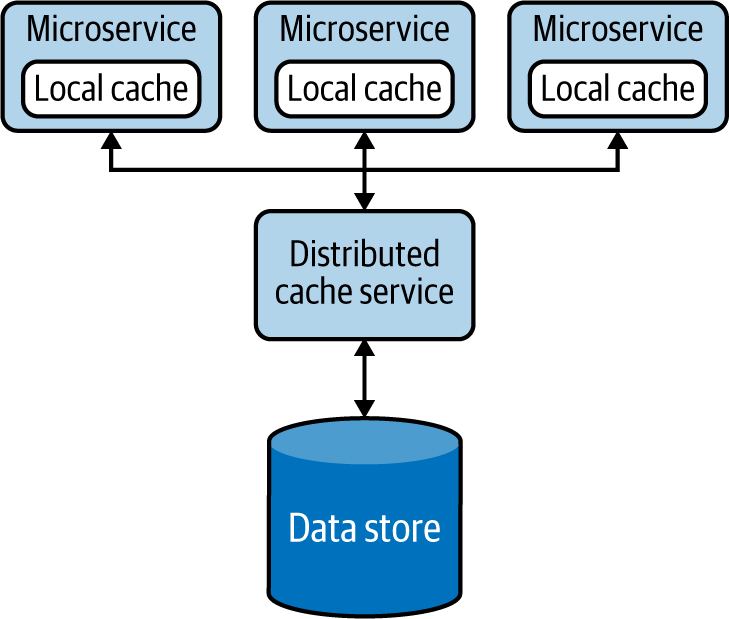
Figura 4-20. Retroceso de caché multicapa
Al utilizar una caché compartida, también podemos introducir una instancia de caché secundaria como reserva y replicar los datos en ella, para mejorar la disponibilidad. Esto permite a nuestras aplicaciones recurrir a la caché secundaria cuando falla la caché primaria.
Almacena en caché más datos de los que puede contener un solo nodo
Los sistemas de caché distribuidos pueden utilizarse como otra opción alternativa cuando la caché local o la caché compartida no pueden contener todos los datos necesarios. También proporcionan escalabilidad y resistencia al particionar y replicar los datos. Estos sistemas admiten operaciones de lectura y escritura y pueden realizar llamadas directas a los almacenes de datos para recuperar y actualizar datos. También podemos escalarlos simplemente añadiendo más servidores caché según sea necesario.
Aunque las cachés distribuidas pueden almacenar muchos datos, no son tan rápidas como la caché local y añaden más complejidad al sistema. Podríamos necesitar saltos de red adicionales para recuperar datos, y ahora tenemos que gestionar un conjunto adicional de nodos. Y lo que es más importante, todos los nodos que participan en la caché distribuida deben estar dentro de la misma red y tener un ancho de banda relativamente alto entre sí; de lo contrario, también pueden sufrir retrasos en la sincronización de los datos. En cambio, cuando los clientes están distribuidos geográficamente, una caché distribuida puede acercar los datos a los clientes, con lo que se consiguen tiempos de respuesta más rápidos.
Consideraciones
La caché nunca debe utilizarse como única fuente de verdad, y no es necesario diseñarla pensando en la alta disponibilidad. Incluso cuando las cachés no estén disponibles, la aplicación debe poder ejecutar sus funcionalidades previstas. Dado que las cachés almacenan los datos en memoria, siempre existe la posibilidad de que se pierdan, por lo que son los almacenes de datos los que deben utilizarse para persistir los datos para su uso a largo plazo.
En algunos casos, la mayoría de los datos que contribuyen a un mensaje de respuesta serán estáticos, y sólo una pequeña parte de los datos se actualizará con frecuencia. Si construir la parte estática de los datos es costoso, puede ser beneficioso dividir los registros en dos, como partes estáticas y dinámicas, y luego almacenar sólo esas partes estáticas en la caché. Al construir la respuesta, podemos combinar los datos estáticos almacenados en la caché y los datos generados dinámicamente.
Como alternativa a las políticas de desalojo de caché, también podemos hacer cachés locales para soportar el desbordamiento de datos. Estos datos desbordados se escriben en el disco. Sólo debes utilizar este enfoque cuando leer los datos del disco sea mucho más rápido que recuperarlos del almacén de datos original. Este enfoque puede introducir una complejidad adicional, ya que ahora también hay que gestionar el desbordamiento de la caché.
Nota
El tiempo de espera de la caché debe fijarse en un nivel óptimo, ni demasiado largo ni demasiado corto. Aunque fijar un tiempo de espera de la caché demasiado largo puede provocar mayores incoherencias, fijar un tiempo de espera demasiado corto también es perjudicial, ya que recargará los datos con demasiada frecuencia y anulará el propósito de almacenar datos en la caché. Sin embargo, establecer un tiempo de espera largo también puede ser beneficioso cuando el coste de la recuperación de datos es significativamente mayor que el coste de que los datos sean incoherentes.
La mayor desventaja de almacenar los datos en caché localmente es que, cuando los servicios escalan, cada servicio tendrá su propia caché local y sincronizará los datos con los almacenes de datos en momentos diferentes. Uno podría recibir una actualización antes que el otro, y eso puede llevar a una situación en la que las cachés de distintos microservicios no estén sincronizadas. Entonces, cuando se envía la misma consulta a dos servicios, éstos podrían responder con valores diferentes, porque la invalidación de la caché sólo se produce en el servicio que procesa la solicitud original de actualización, y las cachés de otros microservicios no tienen conocimiento de esta invalidación. Esta situación también puede producirse cuando los datos se replican a nivel del almacén de datos, ya que las cachés de los microservicios desconocen esas actualizaciones.
Podemos mitigar este problema, como se muestra en la Figura 4-21, invalidando todas las cachés durante las actualizaciones de datos, bien informando a los nodos caché sobre la actualización mediante un sistema de mensajería, como en el patrón Editor-Suscriptor, o bien utilizando el patrón Event Sourcing. Ambos patrones se tratan en el Capítulo 5.
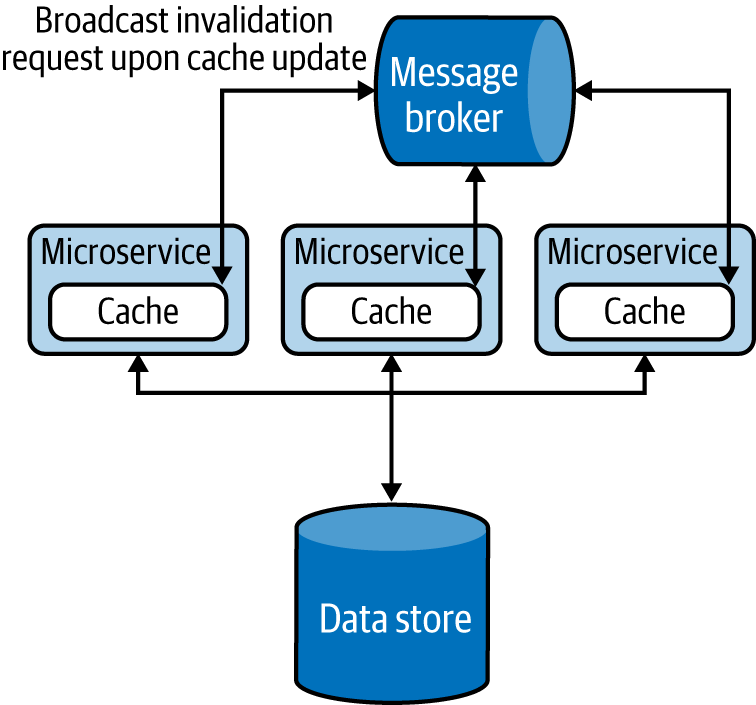
Figura 4-21. Utilizar el corredor de mensajes para invalidar la caché en todos los servicios
Nota
Introducir capas innecesarias de caché puede provocar un elevado consumo de memoria, reducir el rendimiento y causar incoherencias en los datos. Recomendamos encarecidamente realizar una prueba de carga al introducir cualquier solución de almacenamiento en caché, y sobre todo monitorear el porcentaje de aciertos de la caché, junto con el rendimiento y el uso de CPU y memoria. Un porcentaje bajo de aciertos en la caché puede indicar que ésta no es eficaz. En este caso, modifica la caché para conseguir un mayor porcentaje de aciertos o elige otras alternativas. Aumentar el tamaño de la caché, reducir su caducidad y precargarla son opciones que podemos utilizar para mejorar los aciertos de la caché.
Siempre que sea posible, recomendamos actualizar los datos por lotes en las cachés, como se hace en los almacenes de datos. Esto optimiza el ancho de banda y mejora el rendimiento cuando la carga es alta. Cuando se actualizan varias entradas de la caché al mismo tiempo, las actualizaciones pueden seguir un enfoque optimista o pesimista. En el enfoque optimista, suponemos que no se producirán actualizaciones concurrentes y comprobamos la caché sólo en busca de una escritura concurrente antes de actualizar la caché. Pero en el enfoque pesimista, bloqueamos la caché durante todo el periodo de actualización para que no puedan producirse actualizaciones concurrentes. Este último enfoque no es escalable, por lo que sólo debes utilizarlo para operaciones de muy corta duración.
También recomendamos implementar la expiración o recarga forzosa de la caché. Por ejemplo, si el cliente es consciente de una posible actualización por otros medios, podemos dejar que recargue forzosamente la caché antes de recuperar los datos. Podemos conseguirlo introduciendo una variable aleatoria como parte de la clave de la caché al almacenar los datos. El cliente puede utilizar la misma clave una y otra vez, y cambiarla sólo cuando necesite forzar una recarga. Este enfoque lo utilizan, por ejemplo, los clientes web contra el almacenamiento en caché de los navegadores. Como los navegadores almacenan datos en caché contra un URI de solicitud, al tener un elemento aleatorio en el URI, los clientes pueden recargar forzosamente la entrada almacenada en caché simplemente cambiando ese elemento URI aleatorio cuando envían la solicitud. Ten cuidado al utilizar esta técnica con clientes de terceros, porque pueden cambiar continuamente la variable aleatoria que solicita la recarga forzosa, y sobrecargar el sistema. Pero si los clientes están bajo el control del mismo equipo, éste puede ser un enfoque viable.
Algunos servicios comerciales de caché pueden proporcionar seguridad de los datos utilizando el patrón Clave Bóveda, que se trata más adelante en este capítulo. Pero la mayoría de las cachés no suelen estar diseñadas para la seguridad, y no deben exponerse directamente a sistemas externos. Para conseguir seguridad, podemos añadir un servicio de datos sobre la caché utilizando el patrón Servicio de datos y aplicar seguridad de API para el servicio de datos(Figura 4-22). Esto añadirá protección a los datos y permitirá que sólo los servicios autorizados lean y escriban datos en la caché.
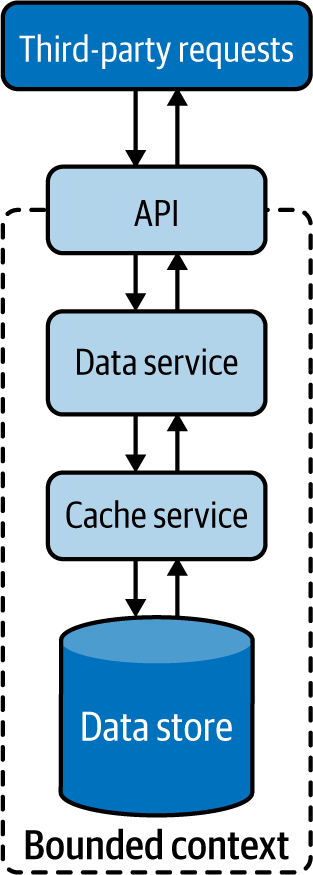
Figura 4-22. Exposición segura de la caché a servicios externos
Patrón de alojamiento de contenido estático
El patrón de alojamiento de contenido estático despliega el contenido estático en almacenes de datos que están más cerca de los clientes, de modo que el contenido pueda entregarse directamente al cliente con baja latencia y sin consumir excesivos recursos informáticos.
Cómo funciona
Los servicios web nativos en la nube se utilizan para crear contenido dinámico basado en las peticiones de los clientes. Algunos clientes, especialmente los navegadores, requieren mucho contenido estático, como páginas HTML estáticas, archivos JavaScript y CSS, imágenes y archivos para descargas. En lugar de utilizar microservicios para atender el contenido estático, este patrón nos permite servir directamente contenido estático desde servicios de almacenamiento como las redes de distribución de contenidos (CDN).
La Figura 4-23 ilustra este patrón en el contexto de una aplicación web. Cuando el navegador solicita datos, podemos hacer que el servicio responda con HTML dinámico que contenga enlaces incrustados a datos estáticos relevantes que deban renderizarse en varias ubicaciones de la página. Esto permite al navegador solicitar el contenido estático, que será resuelto por DNS y servido desde la CDN más cercana.
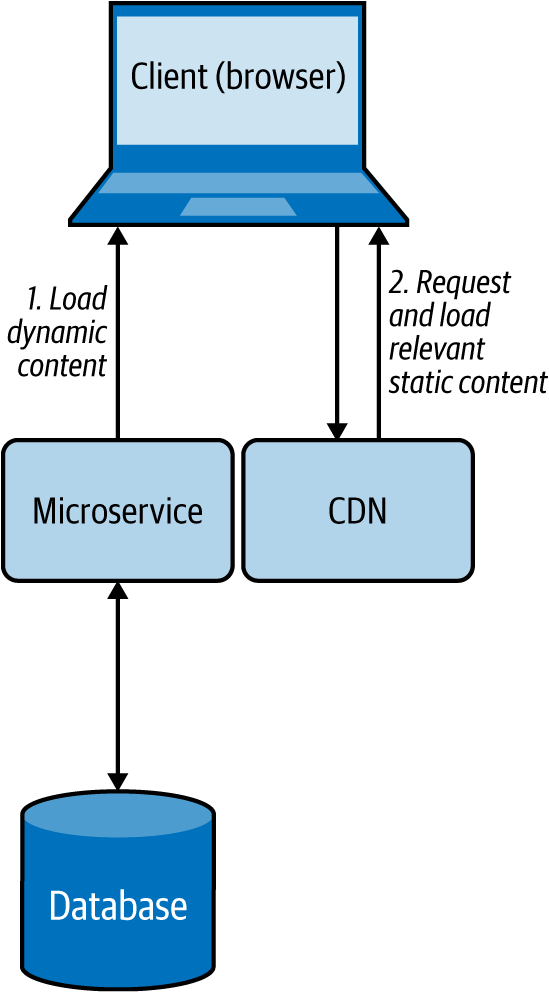
Figura 4-23. Navegador cargando contenido dinámico desde un microservicio mientras carga contenido estático desde una CDN
Cómo se utiliza en la práctica
Este patrón se utiliza cuando necesitamos entregar rápidamente contenido estático a los clientes con un tiempo de respuesta bajo, y cuando necesitamos reducir la carga de los servicios de renderizado.
Proporcionar una entrega de contenido estático más rápida
Como el contenido estático no cambia, este patrón replica y almacena en caché los datos en múltiples entornos y ubicaciones geográficas con la motivación de acercarlos a los clientes. Esto puede ayudar a servir datos estáticos con baja latencia.
Reducir la utilización de recursos en la prestación de servicios
Cuando necesitemos enviar datos estáticos y dinámicos a los clientes, como hemos visto en el ejemplo anterior del navegador web, podemos separar los datos estáticos y moverlos a un sistema de almacenamiento como una CDN o un bucket de S3, y dejar que los clientes obtengan directamente esos datos. Esto reduce la utilización de recursos del microservicio que renderiza el contenido dinámico, ya que no necesita empaquetar todo el contenido estático en su respuesta.
Consideraciones
No podemos utilizar este patrón si es necesario actualizar el contenido estático antes de entregarlo a los clientes, como añadir la hora de acceso y la ubicación actuales a la respuesta web. Además, no es una solución viable cuando la cantidad de datos estáticos que hay que servir es pequeña; el coste para el cliente de solicitar datos de múltiples fuentes puede incurrir en más latencia que la que se sirve directamente por el servicio. Cuando necesites enviar tanto contenido estático como dinámico, te recomendamos que utilices este patrón sólo cuando pueda proporcionar una ventaja de rendimiento significativa.
Cuando utilices este patrón, recuerda que podrías necesitar implementaciones de cliente más complejas. Esto se debe a que, en función de los datos dinámicos que lleguen, el cliente debe ser capaz de recuperar el contenido estático adecuado y combinar ambos tipos de datos en el lado del cliente. Si utilizamos este patrón para casos de uso distintos de la representación de páginas web en un navegador, también tendremos que ser capaces de construir y ejecutar clientes complejos para cumplir ese caso de uso.
A veces puede que necesitemos almacenar datos estáticos de forma segura. Si necesitamos permitir que los usuarios autorizados accedan a los datos estáticos mediante este patrón, podemos utilizar el patrón Servicio de datos junto con la seguridad de la API o el patrón Clave de bóveda para proporcionar seguridad al almacén de datos.
Resumen de los patrones de optimización del rendimiento
En esta sección se han esbozado los patrones de optimización del rendimiento más utilizados en el desarrollo de aplicaciones nativas de la nube. La Tabla 4-4 resume cuándo debemos y cuándo no debemos utilizar estos patrones y las ventajas de cada uno.
Patrones de fiabilidad
Las pérdidas de datos en no son toleradas por ninguna aplicación crítica para el negocio, por lo que la fiabilidad de los datos es de suma importancia. Es fundamental aplicar los mecanismos de fiabilidad pertinentes cuando se modifican los almacenes de datos y cuando se transmiten datos entre aplicaciones. Esta sección describe el uso del patrón de fiabilidad Transacción para garantizar la fiabilidad del almacenamiento y procesamiento de datos.
Patrón de transacción
El patrón Transacción utiliza transacciones para realizar un conjunto de operaciones como una única unidad de trabajo, de modo que todas las operaciones se completan o deshacen como una unidad. Esto ayuda a mantener la integridad de los datos y evita errores en la ejecución de los servicios. Esto es fundamental para el éxito de la ejecución de aplicaciones financieras.
Cómo funciona
Este patrón envuelve múltiples operaciones individuales en una sola operación grande, proporcionando una garantía de que todas las operaciones o ninguna operación tendrán éxito. Todas las operaciones siguen estos pasos:
-
El sistema inicia una transacción.
-
Se ejecutan varias operaciones de manipulación de datos.
-
Commit se utiliza para indicar el final de la transacción.
-
Si no hay errores, la confirmación tendrá éxito, la transacción finalizará correctamente y los cambios se reflejarán en los almacenes de datos.
Si hay errores, todas las operaciones de la transacción se revertirán y la transacción fallará. No se reflejará ningún cambio en los almacenes de datos.
Si necesitamos procesar pedidos de usuario como una transacción, por ejemplo, podemos iniciar una transacción, eliminar la cantidad de producto pedida de la tabla Inventario, añadirla a la tabla Pedido de usuario y, finalmente, emitir una confirmación de transacción. Cuando esto ocurra, ambas operaciones de actualización de datos se ejecutarán como una única operación atómica. Si la tabla Inventario está vacía, la transacción fallará y el sistema volverá a su estado inicial. Pero si ambas operaciones tienen éxito, la transacción se realizará correctamente y los cambios se conservarán en el almacén de datos.
El patrón Transacción cumple las siguientes propiedades ACID:
- Atómica
- Todas las operaciones de deben producirse a la vez, o no debe producirse ninguna.
- Consistente
- Antes de y después de la transacción, el sistema estará en un estado válido.
- Aislamiento
- Los resultados de producidos por transacciones concurrentes serán idénticos a los de dichas transacciones ejecutadas en orden secuencial.
- Duradero
- Cuando finalice la transacción, los cambios confirmados permanecerán confirmados incluso durante los fallos del sistema.
Podemos conseguir el aislamiento de transacciones a distintos niveles. El aislamiento serializable proporciona el nivel más alto. Bloquea el acceso a los datos seleccionados para consultas paralelas de lectura y escritura durante la transacción, y bloquea la adición y eliminación de datos que puedan caer dentro del rango de datos de la transacción. Por ejemplo, si estamos modificando todos los usuarios menores de 30 años con una transacción, no nos permitirá añadir simultáneamente un nuevo usuario con 23 años. Lecturas repetibles El aislamiento proporciona el segundo mejor nivel de aislamiento. Esto bloquea el acceso a los datos seleccionados para las consultas de lectura y escritura durante la transacción, pero permite añadir y eliminar nuevos datos en el rango de datos de la transacción. Al mismo tiempo, el aislamiento de lectura comprometida sólo bloquea las escrituras de datos, mientras que el aislamiento de lectura no comprometida permite leer las actualizaciones no comprometidas realizadas por otras transacciones.
Las transacciones se suelen utilizar con un único almacén de datos, como una base de datos relacional, pero también podemos coordinar operaciones entre varios sistemas, como bases de datos, flujos de eventos y sistemas de colas. Por ejemplo, cuando se realiza un pedido, podemos hacer que el sistema no sólo actualice la base de datos, sino que también añada una entrada a la cola de mensajes de entrega para informar al equipo de cumplimiento sobre la entrega, como una única transacción.
Estas transacciones entre varios sistemas se gestionan mediante algoritmos de consenso como las transacciones XA, Paxos y Raft. Éstos pueden utilizar protocolos de confirmación bifásicos y trifásicos para asegurarse de que las operaciones se coordinan entre sistemas.
Cómo se utiliza en la práctica
Las transacciones pueden utilizarse para combinar varias operaciones como una sola unidad de trabajo, y para coordinar las operaciones de varios sistemas.
Combinar varias operaciones como una sola unidad de trabajo
Podemos utilizar este patrón para combinar varios pasos que deben procesarse todos completamente para considerar válida la operación. Por ejemplo, transferir 25$ de la cuenta de Bob a la de Alice implica dos pasos: deducir 25$ de la cuenta de Bob y añadir 25$ a la cuenta de Alice. Si uno de estos pasos falla, toda la operación se considera inválida, y el sistema debe revocar todos los cambios realizados y devolver las cuentas al mismo estado que tenían antes de iniciar la transacción.
También podemos asegurarnos de que las transacciones múltiples no interfieran entre sí. Por ejemplo, tanto Bob como Eva podrán transferir dinero a la cuenta de Alicia al mismo tiempo y en paralelo.
Combinar operaciones en varios sistemas
Este patrón puede utilizarse cuando queremos consumir un evento de una cola de eventos, realizar una actualización basada en él a un almacén de datos y pasar ese mensaje a otra cola de eventos para su posterior procesamiento, todo ello en una única transacción, como se muestra en la Figura 4-24. Para sincronizar las operaciones entre varios sistemas, podemos utilizar una transacción XA que utilice un protocolo de confirmación en dos fases. La mayoría de las bases de datos y los sistemas de cola de eventos también soportan de forma nativa las transacciones XA, y así podemos garantizar que el evento no se perderá aunque el sistema de procesamiento falle en mitad de su ejecución.
Figura 4-24. Caso de uso de procesamiento simple de mensajes aplicando una transacción XA
Consideraciones
No necesitamos utilizar este patrón cuando la operación sólo tiene un paso, o cuando hay múltiples pasos pero el fallo de alguno se considera aceptable.
Es importante tener en cuenta que el uso de algoritmos de consenso, como las transacciones XA, sincronizará las operaciones e introducirá latencia. Recomendamos utilizar este patrón sólo cuando la transacción tenga una duración relativamente corta, y sólo si implica a pocos sistemas, como hemos visto en el ejemplo del procesamiento de pedidos.
Siempre que sea posible, haz que la operación sea idempotente; esto ayudará a eliminar la necesidad de utilizar cualquier transacción y simplifica el sistema. Esto se debe a que con las actualizaciones idempotentes, aunque se realice la misma operación varias veces, los resultados serán los mismos. Por ejemplo, supongamos que sobrescribimos siempre un valor, como el número de artículos disponibles en el inventario. Aunque sobrescribamos el valor varias veces, no afectará a los resultados finales. Esto nos permitirá reenviar el mismo evento varias veces para superar fallos del sistema.
Cuando necesitemos sincronizar la ejecución y tengamos más de tres sistemas, te recomendamos que utilices el patrón Saga comentado en el Capítulo 3. Este patrón es útil para coordinar transacciones entre múltiples almacenes de datos, microservicios y corredores de mensajes. Nos permite ejecutar múltiples transacciones en orden, y compensar las transacciones anteriores cuando falla una última transacción. Esto también puede reducir la alta latencia o el acoplamiento que puede producirse por los bloqueos distribuidos que utilizan las transacciones XA. Pero sólo podemos utilizar Saga cuando todas las transacciones participantes pueden revertirse -en caso de fallo- utilizando una transacción de compensación. Esto puede convertirse en un problema especialmente cuando nos integramos con sistemas de terceros y puede que no tengamos forma de compensarlos en caso de fallo.
Recomendamos utilizar transacciones XA en lugar de Saga cuando todas las actualizaciones deban realizarse en un único almacén de datos o cuando todos los pasos deban realizarse al mismo tiempo como una operación atómica. Mientras Saga realiza las transacciones en orden, otros sistemas pueden acceder a los datos de los almacenes de datos y microservicios en paralelo. Entonces pueden obtener resultados incoherentes si recuperan una parte de los datos de un almacén de datos que ya ha realizado la transacción y otra de un almacén de datos que aún no ha procesado la transacción.
Resumen del patrón de fiabilidad de las transacciones
En esta sección se ha esbozado un patrón de uso común que proporciona fiabilidad en el desarrollo de aplicaciones nativas de la nube. La Tabla 4-5 resume cuándo debemos y cuándo no debemos utilizar este patrón, así como sus ventajas .
| Patrón | Cuándo utilizar | Cuándo no utilizar | Beneficios |
|---|---|---|---|
| Transacción | Una operación contiene múltiples pasos, y todos los pasos deben procesarse automáticamente para considerar válida la operación. | La aplicación sólo tiene un único paso en la operación. La aplicación tiene múltiples pasos, y el fallo de algunos pasos se considera aceptable. |
Cumple las propiedades ACID. Procesa múltiples transacciones independientes. |
Seguridad: Patrón de clave de bóveda
La seguridad de los datos de se trata en detalle en "Seguridad". Aquí mostramos cómo se puede controlar el acceso a los almacenes de datos mediante el patrón Clave Bóveda para reforzar la seguridad al desarrollar aplicaciones nativas de la nube.
El patrón Clave de Bóveda proporciona acceso directo a los almacenes de datos mediante un token de confianza, comúnmente denominado clave de bóveda. Algunos de los almacenes de datos en la nube más populares admiten esta funcionalidad.
Cómo funciona
El patrón Clave Bóveda se basa en un token de confianza presentado por el cliente y validado por el almacén de datos. En este patrón, la aplicación determina quién puede acceder a qué parte de los datos.
La Figura 4-25 ilustra este patrón. El cliente o servicio que llama llama a la aplicación para recuperar un token de acceso al almacén de datos pertinente. La aplicación puede ser un proveedor de identidad o puede ponerse en contacto con un proveedor de identidad para validar a la persona que llama y emitir un token de clave de bóveda de confianza para acceder al almacén de datos pertinente. La aplicación también puede proporcionar un ámbito de operaciones que la persona que llama puede realizar en el almacén de datos. También añadirá un tiempo de caducidad a la clave, dando acceso al servicio sólo durante un periodo definido. La persona que llama puede entonces llamar al recurso utilizando la clave dada y puede realizar operaciones autorizadas hasta que la clave caduque.
Figura 4-25. Acciones realizadas por los clientes para recuperar datos en el patrón Clave de bóveda
Este patrón también puede admitir la renovación de las claves de bóveda cuando caduquen mediante un token de actualización, como en la seguridad de la API. Esto facilita el funcionamiento fluido de los servicios sin interrupciones para la reautorización.
Cómo se utiliza en la práctica
Este patrón puede utilizarse cuando el almacén de datos no puede llegar al proveedor de identidad para autenticar y autorizar al cliente en el acceso a los datos. En este patrón, el almacén de datos contendrá el certificado del proveedor de identidad, por lo que podrá descifrar el token y validar su autenticidad sin llamar al proveedor de identidad. Como no necesita hacer llamadas a servicios remotos para la validación, también puede realizar operaciones de autenticación con una latencia mínima.
Consideraciones
Una vez que el servicio que llama obtiene acceso al almacén de datos, la aplicación que gobierna el servicio suele perder el control. Este patrón proporciona un mecanismo para retener el control sobre el almacén de datos y reforzar la seguridad. Pero sólo podemos aplicar este patrón cuando el almacén de datos admite la validación de claves. Esto es importante para garantizar que el token ha sido emitido por el proveedor de identidad y no ha caducado. Algunos almacenes de datos avanzados también admiten ámbitos de acceso; pueden identificar a qué sección del almacén de datos, como la tabla o la fila, puede acceder la solicitud entrante. Cuando el almacén de datos no pueda validar el acceso basándose en claves, utiliza enfoques alternativos, como hacer frente a los almacenes con un servicio de datos y protegerlos con la seguridad de la API.
A veces, la clave de bóveda emitida puede verse comprometida. En estos casos, normalmente no es posible bloquear el uso de ese token, ya que la mayoría de los almacenes de datos no admiten esta funcionalidad. Podemos reducir el daño que puede causar una clave bóveda comprometida fijando el tiempo de caducidad en un valor moderado.
Resumen del Patrón de la Llave Bóveda
En esta sección se ha esbozado el patrón Clave Bóveda, de uso común, que proporciona seguridad en el desarrollo de aplicaciones nativas de la nube. La Tabla 4-6 resume cuándo debemos y cuándo no debemos utilizar este patrón, y sus ventajas .
| Patrón | Cuándo utilizar | Cuándo no utilizar | Beneficios |
|---|---|---|---|
| Llave de bóveda | Para acceder de forma segura a datos remotos con una latencia mínima. El almacén tiene una capacidad informática limitada para realizar llamadas de servicio para autenticación y autorización. |
Necesidad de protección de datos de grano fino. Necesidad de restringir con gran precisión qué consultas deben ejecutarse en el almacén de datos. El almacén de datos expuesto no puede validar el acceso basándose en claves. |
Accede directamente a los almacenes de datos utilizando un token de confianza, una clave de bóveda Tiene unos costes operativos mínimos en comparación con la llamada al servicio central de identidad para la validación |
Tecnologías para implementar patrones de gestión de datos
Como desarrollador o arquitecto de software, tienes que seleccionar las tecnologías más adecuadas para tu caso de uso. Esto incluye también la selección de almacenes de datos. Tienes que seleccionar un almacén de datos basándote en factores como lo que vas a almacenar, la cantidad de datos (escalabilidad), el rendimiento esperado de escritura y lectura, la disponibilidad del sistema y la coherencia. En esta sección, hablaremos de los tipos de almacenes de datos más utilizados para las aplicaciones nativas de la nube, y de cuándo puedes utilizarlos.
Sistemas de gestión de bases de datos relacionales
La mayoría de las bases de datos tradicionales entran en la categoría de sistemas de gestión de bases de datos relacionales (RDBMS), que incluye MySQL, Oracle, MSSQL, Postgres, H2, etc. Estas bases de datos relacionales proporcionan las propiedades ACID, y con su SQL también pueden tener patrones de acceso a datos muy complejos. Sin embargo, si tienes datos no relacionales como XML, JSON o en formato binario, entonces un RDBMS puede no ser la mejor opción, y puede que necesites seleccionar un sistema de archivos distribuido o una base de datos NoSQL para almacenar los datos, como se ha comentado anteriormente en "Bases de datos relacionales".
Cuando construye aplicaciones nativas de la nube, en lugar de implementar tú mismo la base de datos en la infraestructura de la nube, recomendamos encarecidamente utilizar una versión gestionada de RDBMS proporcionada por un proveedor de la nube, como Amazon Relational Database Service (RDS), Google Cloud SQL o Azure SQL. Esto no sólo reducirá la complejidad de gestionar las bases de datos, sino que también estará mejor ajustado al entorno.
Para escalar los RDBMS, podemos implementarlos como bases de datos primarias y réplicas, como se explica en el patrón de vista materializada, o fragmentar los datos como en el patrón de fragmentación. En el peor de los casos, si seguimos teniendo problemas de espacio, también podemos hacer copias de seguridad periódicas de los datos más antiguos y poco utilizados en un archivo como NoSQL, y eliminarlos del almacén.
Apache Cassandra
Apache Cassandra es una base de datos distribuida NoSQL que comenzó internamente en Facebook y se publicó como proyecto de código abierto en julio de 2008. El almacén de columnas Cassandra es bien conocido por su disponibilidad continua (tiempo de inactividad cero), alto rendimiento y escalabilidad lineal, que requieren las aplicaciones y microservicios modernos. También ofrece replicación entre centros de datos y geografías para garantizar la disponibilidad en todas las regiones. Cassandra puede manejar petabytes de información y miles de operaciones simultáneas por segundo, lo que te permite gestionar grandes cantidades de datos en entornos de nube híbrida y multicloud. Para la implementación de aplicaciones nativas en la nube, recomendamos utilizar implementaciones gestionadas de Cassandra como Amazon Keyspaces y Asta en Google Cloud.
El rendimiento de escritura de Cassandra es muy alto en comparación con su rendimiento de lectura, Como se ha comentado anteriormente en "Bases de datos NoSQL", proporciona consistencia eventual por diseño. Sin embargo, también nos permite cambiar sus niveles de consistencia para conseguir una consistencia débil o fuerte en función del caso de uso.
El rendimiento de Cassandra también depende de cómo almacenemos y consultemos los datos. Si vamos a consultar datos basándonos en un conjunto de claves, debemos utilizar su clave de fila (clave de partición). Si necesitamos consultar datos a partir de claves distintas, podemos crear índices secundarios. No abuses de los índices secundarios; pueden ralentizar el almacén de datos, ya que cada inserción tiene que actualizar también los índices. Además, Cassandra no es eficiente cuando queremos unir dos familias de columnas, y no debemos utilizarlo si vamos a actualizar los datos con más frecuencia.
Apache HBase
Apache HBase es un almacén de columnas distribuido, escalable y NoSQL que se ejecuta sobre el HDFS. HBase puede alojar tablas muy grandes con miles de millones de filas y millones de columnas, y también puede proporcionar acceso aleatorio de lectura/escritura en tiempo real a los datos de Hadoop. Se escala linealmente a través de conjuntos de datos muy grandes y combina fácilmente fuentes de datos con diferentes estructuras y esquemas.
Como HBase es un almacén de columnas, admite esquemas de bases de datos dinámicos, y como se ejecuta sobre HDFS, también puede utilizarse en trabajos MapReduce. En consecuencia, el complejo sistema interdependiente de HBase es más difícil de configurar, asegurar y mantener.
A diferencia de Cassandra, HBase utiliza una implementación "maestro/trabajador", por lo que puede sufrir un único punto de fallo. Si tu aplicación requiere alta disponibilidad, elige Cassandra en lugar de HBase. Sin embargo, cuando dependamos en gran medida de la consistencia de los datos, HBase será más adecuado porque escribe los datos en un solo lugar y siempre sabe dónde encontrarlos (porque la replicación de datos la realiza HDFS "externamente"). Al igual que Cassandra, HBase tampoco funciona bien cuando se borran o actualizan datos con frecuencia.
MongoDB
MongoDB es un almacén de documentos que admite el almacenamiento de datos en documentos similares a JSON, como se explica en "Bases de datos NoSQL". Los documentos y colecciones en MongoDB son comparables a los registros y tablas de las bases de datos relacionales. Utiliza el lenguaje de consulta de MongoDB para acceder a los datos almacenados, realizar filtrado de agregación y ordenación basados en cualquier campo del documento, e insertar y eliminar campos sin reestructurar los documentos. MongoDB Cloud proporciona MongoDB como solución alojada para el uso de aplicaciones nativas en la nube.
A diferencia de Cassandra o los RDBMS, MongoDB prefiere más índices. Cuando no está indexado, su rendimiento puede resentirse, ya que necesita buscar en toda la colección. MongoDB también favorece la consistencia frente a la disponibilidad. Consigue la disponibilidad utilizando un único primario de lectura/escritura y múltiples réplicas secundarias. Cuando un primario deja de estar disponible, las operaciones de lectura/escritura se detienen temporalmente entre 10 y 40 segundos, mientras MongoDB elige automáticamente una de sus réplicas secundarias como primario.
MongoDB se utiliza mucho para aplicaciones móviles, gestión de contenidos, análisis en tiempo real y aplicaciones IoT. MongoDB también es una buena opción si no tienes una definición clara del esquema de tus documentos JSON, y puedes tolerar cierta indisponibilidad del almacén de datos. Sin embargo, como otras bases de datos NoSQL, no es adecuada para datos transaccionales.
Redis
Redis es un almacén de datos clave-valor en memoria que se utiliza habitualmente como caché, tal y como se explica en en el "Patrón de almacenamiento en caché". Admite claves de cadena y varios tipos de valores, como cadenas, listas, conjuntos, conjuntos ordenados, hashes, matrices de bits y mucho más. Esto hace que la aplicación sea menos compleja, ya que ahora puede almacenar su estructura de datos interna directamente en Redis. Redis es ideal para una caché, ya que admite transacciones, claves con un tiempo de vida limitado, desalojo LRU de claves, conmutación automática por error y su capacidad para escribir el exceso de datos en el disco. Redis también tiene muchas opciones de alojamiento en la nube para que las utilicen las aplicaciones nativas de la nube, como AWS, Google, Redis Labs e IBM.
Redis admite dos tipos de opciones de persistencia: Copia de seguridad de la base de datos Redis (RDB) y Append Only File (AOF). Utilizando ambas opciones, podemos conseguir un buen rendimiento de escritura y un buen grado de seguridad de los datos ante fallos del sistema. Redis ofrece alta disponibilidad utilizando un único "maestro" y múltiples "réplicas", como en el patrón CQRS, y proporciona escalabilidad mediante la fragmentación de "maestros" y "réplicas", como se explica en el "Patrón de fragmentación de datos".
Sin embargo, Redis no es un sustituto NoSQL de los almacenes de datos relacionales, ya que no admite muchas funciones estándar de los almacenes de datos relacionales, como la consulta eficiente y la realización de operaciones complejas de manipulación y agregación de datos.
Amazon DynamoDB
DynamoDB es una base de datos clave-valor y de documentos que puede utilizarse para almacenar y recuperar datos con baja latencia y alta escalabilidad. Puede gestionar más de 10 billones de solicitudes al día y más de 20 millones de solicitudes por segundo durante los picos. Los datos de DynamoDB se almacenan en discos de estado sólido (SSD), se particionan automáticamente y se replican en varias zonas de disponibilidad. También proporciona un control de acceso de grano fino y utiliza métodos seguros probados para autenticar a los usuarios y evitar el acceso no autorizado a los datos.
DynamoDB, un servicio proporcionado por AWS, no puede instalarse en un servidor local ni en nubes distintas de AWS. Utiliza DynamoDB sólo si usas AWS como infraestructura de nube principal para tus aplicaciones nativas de la nube. Además, DynamoDB tiene una capacidad de consulta limitada en comparación con los almacenes relacionales y no es compatible con las características de las bases de datos relacionales, como las uniones de tablas y los conceptos de clave ajena; en su lugar, aboga por el uso de datos no normalizados con redundancia para mejorar el rendimiento.
Apache HDFS
El Sistema de Archivos Distribuidos Hadoop(HDFS) de Apache es un sistema de archivos distribuidos ampliamente utilizado, diseñado para funcionar en hardware básico barato, al tiempo que proporciona una gran resiliencia de los datos al almacenar al menos tres copias de los datos de forma distribuida. HDFS se utiliza habitualmente para almacenar datos analíticos, ya que los datos almacenados en HDFS son inmutables y están optimizados para escribir y leer datos en streaming. Esto también permite utilizar HDFS como fuente de datos para los trabajos MapReduce de Hadoop para un procesamiento eficiente de grandes datos. Cloudera y los principales proveedores de la nube proporcionan HDFS como servicio alojado para utilizarlo con aplicaciones nativas de la nube.
HDFS almacena los datos en varios nodos de datos, y guarda todos sus metadatos en memoria en un nodo de nombre único. Cuando ese nodo no está disponible, pueden fallar nuevas lecturas y escrituras, provocando indisponibilidad. Además, en función de la capacidad de la memoria de su nodo de nombre, tiene un límite superior en el número de archivos que puede almacenar. Recomendamos utilizar HDFS para almacenar un pequeño número de archivos grandes en lugar de un gran número de archivos pequeños. Como está optimizado para leer datos secuencialmente, no es la mejor solución cuando necesitamos lecturas aleatorias.
Amazon S3
Amazon Simple Storage Service(S3) es un almacenamiento de objetos que forma parte de AWS. Puede utilizarse en un lago de datos, como almacenamiento para aplicaciones nativas de la nube, como copia de seguridad o archivo de datos, y para análisis de big data. También admite el patrón de localización de datos mediante la ejecución de análisis en nodos de datos utilizando expresiones SQL estándar de Amazon Athena. Podemos utilizar S3 Select para recuperar subconjuntos de datos de objetos en lugar de todo el objeto. Esto puede mejorar el rendimiento del acceso a los datos hasta cuatro veces. Amazon S3 está altamente disponible y proporciona un control de acceso a los datos de grano fino. Recomendamos su uso cuando utilices AWS como plataforma principal de aplicaciones nativas en la nube.
Azure Cosmos DB
Azure Cosmos DB es un almacén de datos NoSQL totalmente gestionado que admite la semántica de bases de datos clave-valor, de documentos, de columnas y de gráficos. Puede almacenar y recuperar datos con baja latencia, y proporciona seguridad de nivel empresarial con cifrado de extremo a extremo y control de acceso. También proporciona API de código abierto para MongoDB y Cassandra, lo que permite a los clientes aprovechar la nube sin cambiar su aplicación.
Cosmos DB, un servicio proporcionado por Azure, no puede instalarse en un servidor local ni en nubes distintas de Azure. Utiliza Cosmos DB sólo si utilizas Azure como infraestructura de nube principal para tus aplicaciones nativas en la nube. Aún así, Cosmos DB proporciona cierta flexibilidad al ofrecer migración y sincronización de datos con tu clúster Cassandra local. Aunque Cosmos DB puede proporcionar soporte transaccional, está limitado dentro de la partición lógica de datos.
Llave en mano de Google Cloud
Google Cloud Spanner es un almacén de datos relacional totalmente gestionado que admite una escala ilimitada y una fuerte coherencia. Proporciona la capacidad de ejecutar consultas SQL a la vez que ofrece soporte para transacciones en todos los nodos del clúster. También escala linealmente las transacciones de escritura y lectura y proporciona seguridad mediante encriptación de la capa de datos y controles de acceso.
Dado que Cloud Spanner es un servicio proporcionado por Google, no puede instalarse en un servidor local ni en nubes distintas de Google. Utiliza Spanner sólo si utilizas Google como infraestructura de nube principal para tus aplicaciones nativas en la nube. Aunque proporciona soporte SQL, no es totalmente compatible con la especificación SQL del Instituto Nacional Americano de Normalización (ANSI), por lo que requiere cambios en las aplicaciones antes de migrar de bases de datos relacionales estándar a Spanner.
Resumen de tecnologías
En esta sección se han esbozado algunos almacenes de datos de uso común que podemos utilizar en el desarrollo de aplicaciones nativas de la nube. La Tabla 4-7 resume cuándo debemos y cuándo no debemos utilizar estos almacenes de datos.
Prueba
Probar es un paso importante para construir con éxito aplicaciones nativas de la nube. Como ya hemos hablado de probar microservicios en el Capítulo 2, aquí nos centraremos en probar servicios y almacenes de datos.
Podemos utilizar almacenes de datos de prueba para probar las interacciones dato-servicio, Aunque los servicios de datos pueden tener una lógica compleja o sencilla, pueden provocar cuellos de botella en producción. A continuación se ofrecen recomendaciones útiles para superar estos problemas:
-
Las pruebas deben realizarse tanto con almacenes de datos limpios como con almacenes de datos prepoblados, ya que los primeros comprobarán el código de inicialización de los datos y los segundos comprobarán la coherencia de los datos durante el funcionamiento.
-
Prueba todos los tipos y versiones de almacenes de datos que se utilizarán en producción para eliminar cualquier sorpresa. Podemos implementar almacenes de datos de prueba como instancias Docker que ayudarán a ejecutar pruebas en múltiples entornos con un inicio rápido y una limpieza adecuada después de la prueba.
-
Prueba la asignación de datos y asegúrate de que todos los campos se asignan correctamente al llamar al almacén de datos.
-
Valida si el servicio realiza inserciones, escrituras, eliminaciones y actualizaciones en los almacenes de datos de la forma esperada, comprobando el estado del almacén de datos mediante clientes de prueba que puedan acceder directamente a la base de datos.
-
Valida que las restricciones relacionales, los activadores y los procedimientos almacenados producen resultados correctos.
Además, es importante hacer una prueba de carga en el servicio de datos junto con el almacén de datos en un entorno similar al de producción con múltiples clientes. Esto ayudará a identificar cualquier bloqueo de la base de datos, consistencia de los datos u otros cuellos de botella relacionados con el rendimiento presentes en la aplicación nativa de la nube. También mostrará cuánta carga puede soportar la aplicación y cómo se verá afectada cuando se implementen diversos patrones y técnicas de escalado de datos.
Cuando se trata de probar los microservicios nativos de la nube que dependen de servicios de datos, podemos utilizar simplemente API de servicios simulados para simular los servicios de datos y omitir la necesidad de implementar almacenes de datos.
Seguridad
Proteger los datos de y permitir que sólo las personas y sistemas adecuados accedan a los datos relevantes es clave para el éxito de la ejecución de una aplicación nativa de la nube, y para el éxito de una organización en general. La seguridad de los datos debe aplicarse tanto cuando los datos están en reposo como cuando están en movimiento.
Podemos reforzar la seguridad de los datos en reposo tanto físicamente como mediante software. Los servidores de datos deben estar vigilados y sólo deben acceder a ellos las personas autorizadas. Los almacenes de datos que se ejecutan en los servidores también deben aplicar la seguridad mediante el patrón de clave de bóveda y la seguridad de la API para controlar el acceso a los datos. Al almacenar datos sensibles, recomendamos encriptarlos antes de guardarlos en el almacén de datos. También recomendamos encriptar el sistema de archivos en el que se almacenan los datos, como capa adicional de protección.
Recomendamos separar los datos sensibles de los demás datos, de modo que los datos sensibles puedan gobernarse con capas adicionales de protección, junto con pistas de auditoría para monitorear el comportamiento sospechoso. No recopiles ni almacenes información sensible innecesaria. Cuando sea necesario, enmascara toda la información sensible, como nombres de usuario y direcciones de correo electrónico. Esto puede hacerse sustituyendo los datos sensibles por identificadores únicos y almacenando su asignación en un almacén de datos protegido. Esto puede permitirnos analizar y auditar continuamente el comportamiento de los usuarios, a la vez que proporciona la capacidad de eliminar todos los datos sensibles de los usuarios simplemente borrando el mapeo de datos. Esto también ayudará a hacer cumplir la normativa sobre privacidad y datos, como el Reglamento General de Protección de Datos (RGPD) de Europa.
Cuando se trata de datos en tránsito, debemos transmitirlos siempre a través de canales de transmisión de datos seguros, como HTTPS. Para mayor seguridad, podemos cifrar los mensajes con claves asimétricas para que los hosts intermediarios no tengan acceso al contenido.
Para proteger la información sensible sin segmentar los mensajes, podemos cifrar sólo la parte del mensaje que contenga información sensible. Todo el mensaje se entregará a cada cliente, pero sólo los clientes que tengan la clave correspondiente a los datos sensibles podrán descifrarlo, mientras que los demás no podrán acceder a esos datos.
Observabilidad y monitoreo
Observabilidad y monitoreo nos permiten conocer mejor el rendimiento de las aplicaciones nativas de la nube observando sus métricas, registros y resultados de rastreo distribuido. Como la observabilidad y el monitoreo de los microservicios se tratan en el Capítulo 2, aquí nos centraremos principalmente en los almacenes de datos.
La observabilidad y el monitoreo nos ayudan a identificar el rendimiento de los almacenes de datos y a tomar medidas correctivas cuando se desvían debido a la carga o a cambios en la aplicación. En la mayoría de las aplicaciones, las peticiones entrantes interactúan con los almacenes de datos. Cualquier problema de rendimiento o disponibilidad en el almacén de datos resonará en todas las capas del sistema, afectando a la experiencia general del usuario.
El monitoreo de los almacenes de datos es esencial para minimizar los problemas de rendimiento, disponibilidad y seguridad. Las métricas clave que hay que observar en un almacén de datos son las siguientes :
Métricas de aplicación
Tiempo de actividad/salud del almacén de datos: Para identificar si cada nodo del almacén de datos está en funcionamiento.
Tiempo de ejecución de la consulta: Cinco tipos de problemas pueden causar tiempos de ejecución de consulta elevados:
Consulta ineficiente: Uso de consultas no optimizadas, incluyendo múltiples uniones complejas, y tablas no indexadas correctamente.
Crecimiento de datos en el almacén de datos: Almacenes de datos que contienen más datos de los que puede manejar.
Concurrencia: Operaciones concurrentes sobre la misma tabla/fila, que bloquean los almacenes de datos y afectan a su rendimiento.
Falta de recursos del sistema, como CPU/memoria/espacio en disco: Los nodos del almacén de datos no disponen de recursos suficientes para servir eficientemente la petición.
Indisponibilidad del sistema dependiente o de la réplica: En los almacenes de datos distribuidos, cuando su réplica u otros sistemas dependientes, como un servicio de búsqueda, no están disponibles, pueden tardar más tiempo, ya que necesitan aprovisionar una nueva instancia o descubrir y dirigir la petición a otra instancia.
Respuesta de la ejecución de la consulta: Si la ejecución de la consulta ha tenido éxito. Si la consulta falla, es posible que tengamos que consultar los registros para obtener más detalles (dependiendo del fallo).
Auditoría de las operaciones de consulta: Las consultas u operaciones de usuario malintencionadas pueden provocar una reducción inesperada del rendimiento del almacén de datos. Podemos utilizar los registros de auditoría para identificarlas y mitigarlas.
Métricas del sistema: Para identificar la falta de recursos del sistema para un procesamiento eficaz mediante el consumo de CPU, el consumo de memoria, la disponibilidad de espacio en disco, la utilización de la red y la velocidad de E/S del disco.
Registros del almacén de datos
Tiempo empleado y rendimiento al comunicarse con el primario y las réplicas: Ayuda a comprender los problemas de red y el mal almacenamiento de datos
Al analizar las métricas de, podemos utilizar percentiles para comparar comportamientos históricos y actuales. Esto puede identificar anomalías y desviaciones, de modo que podamos identificar rápidamente la causa raíz del problema. Por ejemplo, herramientas de monitoreo como SolarWinds y SQL Power Tools proporcionan métricas como el tiempo de ejecución de las consultas y el tiempo de respuesta, y sistemas como Elastic Stack y Kibana analizan los registros de los almacenes de datos para ilustrar su salud y el motivo de los fallos en las consultas. Si utilizamos almacenes de datos gestionados por proveedores en la nube como Google Cloud, AWS o Azure, ellos también proporcionan servicios de monitoreo para monitorizar las métricas del sistema y del almacén de datos.
DevOps
Hemos tratado en varios patrones de gestión de datos que pueden aplicarse en aplicaciones nativas de la nube utilizando tanto microservicios como almacenes de datos. Ya hemos hablado del proceso DevOps para la implementación y gestión de microservicios en el Capítulo 2, así que aquí nos centraremos en la implementación y gestión de los almacenes de datos.
Los pasos y consideraciones clave para la implementación y gestión de almacenes de datos son los siguientes:
-
Selecciona los tipos de almacén de datos. Selecciona el tipo de almacén de datos (relacional, NoSQL o sistema de archivos) y su proveedor para que se ajuste a nuestro caso de uso.
-
Configura el patrón de implementación. En esto pueden influir los patrones aplicados en la aplicación nativa de la nube y el tipo de almacén de datos que hayamos seleccionado. A partir de esta selección, se debe determinar la alta disponibilidad y escalabilidad respondiendo a las siguientes preguntas:
-
¿Quiénes son los clientes?
-
¿Cuántos nodos?
-
¿Vamos a utilizar un almacén de datos gestionado por el proveedor de la nube o vamos a implementar uno propio?
-
¿Cómo funciona la replicación?
-
¿Cómo hacemos una copia de seguridad de los datos?
-
¿Cómo gestiona la recuperación en caso de catástrofe?
-
¿Cómo aseguramos el almacén de datos?
-
¿Cómo monitoreamos el almacén de datos?
-
¿Cuánto cuesta el almacenamiento/gestión de datos?
-
-
Imponer la seguridad. Los almacenes de datos deben protegerse porque contienen información crítica para la empresa. Esto puede reforzarse aplicando la seguridad física y de software pertinente, tal y como se ha comentado en la sección anterior. Esto puede incluir la habilitación de un estricto control de acceso, la encriptación de datos y el uso de registros de auditoría.
-
Configura la observabilidad y el monitoreo. Al igual que los microservicios, los almacenes de datos deben configurarse con herramientas de observabilidad y monitoreo para garantizar un funcionamiento continuo. Esto puede proporcionar información temprana sobre posibles problemas de escalado, como la necesidad de reequilibrar los fragmentos de datos, o de aplicar un patrón de diseño totalmente distinto para mejorar la escalabilidad y el rendimiento de la aplicación.
-
Automatiza la entrega continua. Cuando se trata de almacenes de datos, la automatización y la entrega continua no son sencillas. Aunque podemos idear fácilmente un esquema inicial de almacén de datos, mantener la compatibilidad con versiones anteriores es difícil a medida que evoluciona la aplicación. La compatibilidad con versiones anteriores es fundamental; sin ella, no podremos conseguir actualizaciones de la aplicación sin problemas ni retrocesos en caso de fallo. Para mejorar la productividad, debemos utilizar siempre herramientas de automatización adecuadas, como scripts, para automatizar la entrega continua. También recomendamos disponer de guardrails y utilizar varios entornos de implementación, como desarrollo y puesta en escena/preproducción, para reducir el impacto de los cambios y validar la aplicación antes de pasarla a producción.
Siguiendo estos pasos, podemos implementar y mantener con seguridad aplicaciones nativas de la nube, al tiempo que permitimos una rápida innovación y adopción a otros sistemas.
Resumen
En este capítulo, hemos analizado varios patrones de gestión de datos que pueden aplicarse a las aplicaciones nativas de la nube. Empezamos con una visión general de la arquitectura de datos y luego examinamos varios tipos de datos, como los de entrada, configuración y estado, que pueden influir en el comportamiento de la aplicación. También cubrimos formas de datos, como estructurados, semiestructurados y no estructurados, y cómo podemos almacenarlos y gestionarlos eficazmente en varios tipos de almacenes de datos, incluidos los relacionales, NoSQL y sistemas de archivos.
A continuación, debatimos cómo pueden gestionarse y compartirse estos datos entre aplicaciones nativas de la nube y cómo utilizar diversos patrones de diseño para lograr la composición de datos, el escalado de datos, la optimización del rendimiento, la fiabilidad y la seguridad. También vimos varias tecnologías específicas para la gestión de datos y cómo las aplicaciones nativas de la nube centradas en los datos deben desarrollarse, probarse, desplegarse continuamente mediante DevOps, y observarse y monitorizarse para garantizar un funcionamiento continuo. A continuación discutiremos los patrones relacionados con las aplicaciones nativas de la nube basadas en eventos.
Get Patrones de diseño para aplicaciones nativas en la nube now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

