Capítulo 1. La necesidad de patrones de diseño de aprendizaje automático
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En las disciplinas de ingeniería, los patrones de diseño recogen las buenas prácticas y las soluciones a los problemas más comunes. Codifican el conocimiento y la experiencia de los expertos en consejos que todos los profesionales pueden seguir. Este libro es un catálogo de patrones de diseño de aprendizaje automático que hemos observado al trabajar con cientos de equipos de aprendizaje automático.
¿Qué son los patrones de diseño?
La idea de los patrones, y de un catálogo de patrones probados, fue introducida en el campo de la arquitectura por Christopher Alexander y cinco coautores en un libro enormemente influyente titulado A Pattern Language (Oxford University Press, 1977). En su libro, catalogan 253 patrones, presentándolos de esta manera:
Cada patrón describe un problema que se produce una y otra vez en nuestro entorno, y luego describe el núcleo de la solución a ese problema, de tal forma que puedas utilizar esta solución un millón de veces, sin hacerlo nunca dos veces de la misma manera.
...
Cada solución está planteada de tal modo que proporciona el campo esencial de relaciones necesario para resolver el problema, pero de un modo muy general y abstracto, para que puedas resolverlo tú mismo, a tu manera, adaptándolo a tus preferencias y a las condiciones locales del lugar donde lo hagas.
Por ejemplo, un par de patrones que incorporan detalles humanos al construir una casa son Luz en dos lados de cada habitación y Balcón de dos metros. Piensa en tu habitación favorita de tu casa y en la que menos te gusta. ¿Tiene tu habitación favorita ventanas en dos paredes? ¿Y tu habitación menos favorita? Según Alexander:
Las habitaciones iluminadas por dos lados, con luz natural, crean menos deslumbramiento alrededor de las personas y los objetos; esto nos permite ver las cosas con más detalle y, lo que es más importante, nos permite leer con detalle las minúsculas expresiones que aparecen en los rostros de las personas....
Tener un nombre para este patrón ahorra a los arquitectos tener que redescubrir continuamente este principio. Sin embargo, dónde y cómo conseguir dos fuentes de luz en cualquier condición local específica depende de la habilidad del arquitecto. Del mismo modo, al diseñar un balcón, ¿qué tamaño debe tener? Alexander recomienda 1,80 m por 1,80 m como tamaño suficiente para 2 sillas (¡desparejadas!) y una mesa auxiliar, y 3,80 m por 3,80 m si quieres tanto un espacio cubierto para sentarte como un espacio para sentarte al sol.
Erich Gamma, Richard Helm, Ralph Johnson y John Vlissides llevaron la idea al software catalogando 23 patrones de diseño orientados a objetos en un libro de 1994 titulado Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley, 1995). Su catálogo incluye patrones como Proxy, Singleton y Decorator y tuvo un impacto duradero en el campo de la programación orientada a objetos. En 2005, la Association of Computing Machinery (ACM) concedió su premio anual Programming Languages Achievement Award a los autores, reconociendo el impacto de su trabajo "en la práctica de la programación y el diseño de lenguajes de programación".
Construir modelos de aprendizaje automático de producción se está convirtiendo cada vez más en una disciplina de ingeniería, que aprovecha los métodos de ML que se han probado en entornos de investigación y los aplica a problemas empresariales. A medida que el aprendizaje automático se generaliza, es importante que los profesionales aprovechen los métodos probados para abordar los problemas recurrentes.
Una de las ventajas de nuestro trabajo en la parte de Google Cloud orientada al cliente es que nos pone en contacto con una gran variedad de equipos de aprendizaje automático y ciencia de datos y con desarrolladores individuales de todo el mundo. Al mismo tiempo, cada uno de nosotros trabaja en estrecha colaboración con equipos internos de Google que resuelven problemas punteros de aprendizaje automático. Por último, hemos tenido la suerte de trabajar con los equipos de TensorFlow, Keras, BigQuery ML, TPU y Cloud AI Platform que están impulsando la democratización de la investigación y la infraestructura del aprendizaje automático. Todo esto nos da una perspectiva bastante única desde la que catalogar las buenas prácticas que hemos observado que llevan a cabo estos equipos.
Este libro es un catálogo de patrones de diseño o soluciones repetibles a problemas frecuentes en la ingeniería del ML. Por ejemplo, el patrón Transformación(Capítulo 6) impone la separación de entradas, características y transformaciones, y hace que las transformaciones sean persistentes para simplificar el paso de un modelo de ML a producción. Del mismo modo, Predicciones con Clave, en el Capítulo 5, es un patrón que permite la distribución a gran escala de predicciones por lotes, como en el caso de los modelos de recomendación.
Para cada patrón, describimos el problema común que se aborda y, a continuación, recorremos una variedad de posibles soluciones al problema, las ventajas y desventajas de estas soluciones, y las recomendaciones para elegir entre estas soluciones. El código de implementación de estas soluciones se proporciona en SQL (útil si estás llevando a cabo el preprocesamiento y otros ETL en Spark SQL, BigQuery, etc.), scikit-learn, y/o Keras con un backend TensorFlow.
Cómo utilizar este libro
Se trata de un catálogo de pautas que hemos observado en la práctica, entre múltiples equipos. En algunos casos, los conceptos subyacentes se conocen desde hace muchos años. No pretendemos haber inventado o descubierto estos patrones. En cambio, esperamos proporcionar un marco de referencia común y un conjunto de herramientas para los profesionales del ML. Habremos tenido éxito si este libro os proporciona a ti y a tu equipo un vocabulario a la hora de hablar de conceptos que ya incorporáis intuitivamente a vuestros proyectos de ML.
No esperamos que leas este libro de forma secuencial (¡aunque puedes hacerlo!). En su lugar, prevemos que hojearás el libro, leerás algunas secciones con más profundidad que otras, harás referencia a las ideas en conversaciones con colegas y volverás a consultar el libro cuando te enfrentes a problemas sobre los que recuerdes haber leído. Si tienes pensado hojearlo, te recomendamos que empieces por el Capítulo 1 y el Capítulo 8, antes de sumergirte en patrones individuales.
Cada modelo tiene un breve planteamiento del problema, una solución canónica, una explicación de por qué funciona la solución y una discusión en varias partes sobre las ventajas y desventajas y las alternativas. Te recomendamos que leas la sección de discusión teniendo muy presente la solución canónica, para poder comparar y contrastar. La descripción del patrón incluirá fragmentos de código extraídos de la implementación de la solución canónica. El código completo se encuentra en nuestro repositorio de GitHub. Te recomendamos encarecidamente que leas el código mientras lees la descripción del patrón.
Terminología del aprendizaje automático
Dado que los profesionales del aprendizaje automático de hoy en día pueden tener diferentes áreas de especialización primaria -ingeniería de software, análisis de datos, DevOps o estadística-, puede haber diferencias sutiles en la forma en que los distintos profesionales utilizan ciertos términos. En esta sección definimos la terminología que utilizamos a lo largo del libro.
Modelos y marcos
En esencia, el aprendizaje automático es un proceso de construcción de modelos que aprenden de los datos. Esto contrasta con la programación tradicional, en la que escribimos reglas explícitas que indican a los programas cómo comportarse. Los modelos de aprendizaje automático son algoritmos que aprenden patrones a partir de los datos. Para ilustrar este punto, imagina que somos una empresa de mudanzas y necesitamos calcular los costes de mudanza de los clientes potenciales. En la programación tradicional, podríamos resolver esto con una sentencia if:
ifnum_bedrooms==2andnum_bathrooms==2:estimate=1500elifnum_bedrooms==3andsq_ft>2000:estimate=2500
Puedes imaginar cómo se complicará esto rápidamente a medida que añadamos más variables (número de muebles grandes, cantidad de ropa, objetos frágiles, etc.) e intentemos manejar casos extremos. Es más, pedir toda esta información por adelantado a los clientes puede hacer que abandonen el proceso de estimación. En su lugar, podemos entrenar un modelo de aprendizaje automático para estimar los costes de la mudanza basándonos en los datos anteriores de los hogares que nuestra empresa ha trasladado.
A lo largo del libro, utilizamos principalmente modelos de redes neuronales de avance en nuestros ejemplos, pero también haremos referencia a modelos de regresión lineal, árboles de decisión, modelos de agrupación y otros. Las redes neuronales de alimentación directa, que abreviaremos comúnmente como redes neuronales, son un tipo de algoritmo de aprendizaje automático en el que múltiples capas, cada una con muchas neuronas, analizan y procesan la información y luego envían esa información a la siguiente capa, dando como resultado una capa final que produce una predicción como salida. Aunque no son en absoluto idénticas, las redes neuronales se comparan a menudo con las neuronas de nuestro cerebro por la conectividad entre nodos y la forma en que son capaces de generalizar y formar nuevas predicciones a partir de los datos que procesan. Las redes neuronales con más de una capa oculta (capas distintas de la de entrada y salida) se clasifican como aprendizaje profundo (ver Figura 1-1).
Los modelos de aprendizaje automático, independientemente de cómo se representen visualmente, son funciones matemáticas y, por tanto, pueden implementarse desde cero utilizando un paquete de software numérico. Sin embargo, los ingenieros de ML de la industria tienden a emplear uno de los diversos marcos de código abierto diseñados para proporcionar API intuitivas para construir modelos. La mayoría de nuestros ejemplos utilizarán TensorFlow, un marco de aprendizaje automático de código abierto creado por Google y centrado en modelos de aprendizaje profundo. Dentro de la biblioteca TensorFlow, utilizaremos la API Keras en nuestros ejemplos, que puede importarse a través de tensorflow.keras. Keras is a higher-level API for building neural networks. Aunque Keras admite muchos backends, utilizaremos su backend TensorFlow. En otros ejemplos, utilizaremos scikit-learn, XGBoost y PyTorch, que son otros populares marcos de código abierto que proporcionan utilidades para preparar tus datos, junto con API para construir modelos lineales y profundos. El aprendizaje automático sigue siendo cada vez más accesible, y un avance emocionante es la disponibilidad de modelos de aprendizaje automático que pueden expresarse en SQL. Utilizaremos BigQuery ML como ejemplo de esto, especialmente en situaciones en las que queramos combinar el preprocesamiento de datos y la creación de modelos.
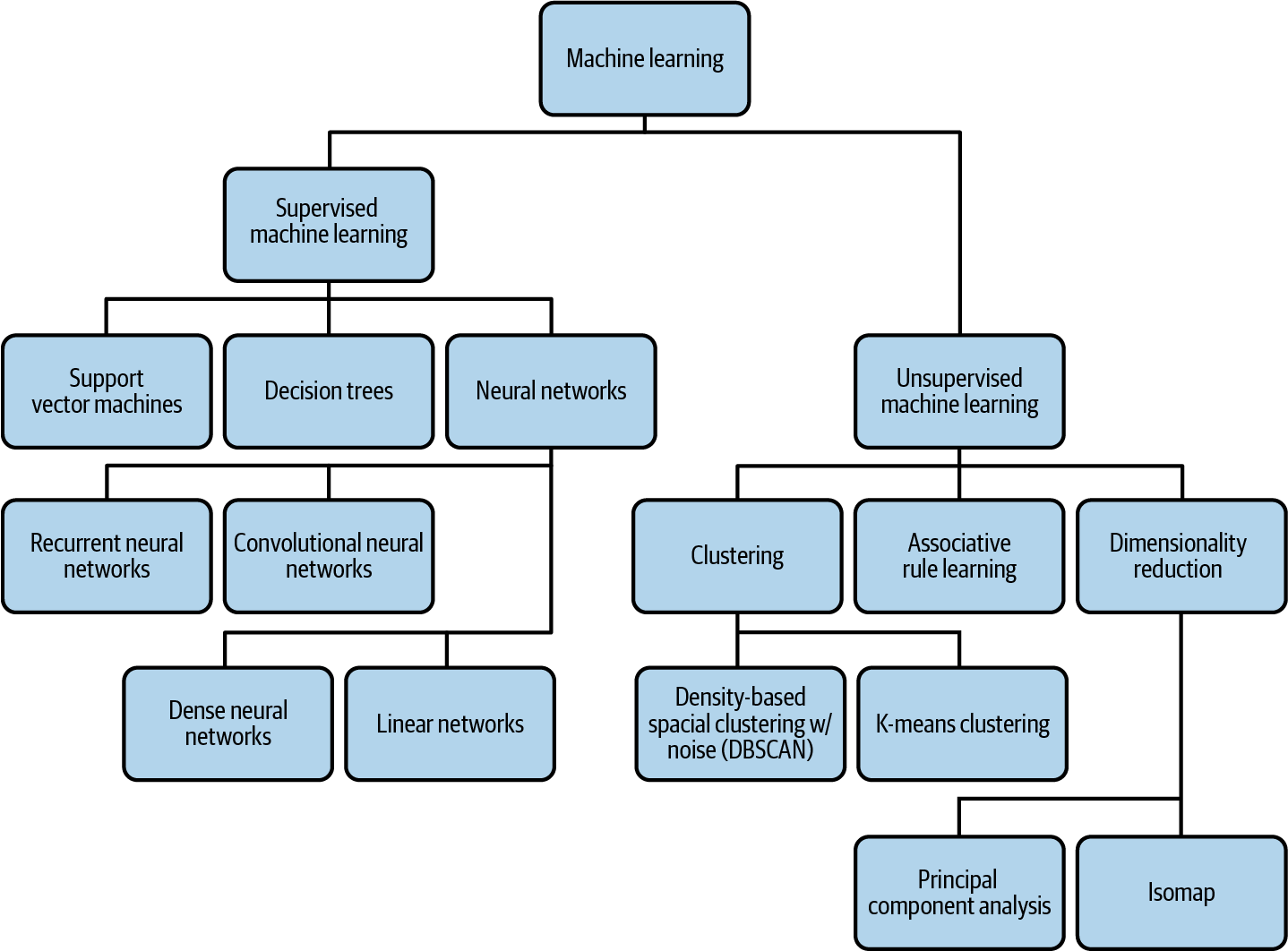
Por el contrario, las redes neuronales con sólo una capa de entrada y otra de salida son otro subconjunto del aprendizaje automático conocido como modelos lineales. Los modelos lineales representan los patrones que han aprendido de los datos mediante una función lineal. Los árboles de decisión son modelos de aprendizaje automático que utilizan tus datos para crear un subconjunto de caminos con varias ramas. Estas ramas se aproximan a los resultados de distintos resultados de tus datos. Por último, los modelos de agrupación buscan similitudes entre distintos subconjuntos de tus datos y utilizan estos patrones identificados para agrupar los datos en clusters.
Los problemas de aprendizaje automático (véase la Figura 1-1) pueden dividirse en dos tipos: aprendizaje supervisado y no supervisado. El aprendizaje supervisado define los problemas en los que conoces de antemano la etiqueta verdadera de tus datos. Por ejemplo, podrías etiquetar una imagen como "gato" o a un bebé como de 2,3 kg al nacer. Introduces estos datos etiquetados en tu modelo con la esperanza de que pueda aprender lo suficiente para etiquetar nuevos ejemplos. Con el aprendizaje no supervisado, no conoces de antemano las etiquetas de tus datos, y el objetivo es construir un modelo que pueda encontrar agrupaciones naturales de tus datos (lo que se denomina agrupación), comprimir el contenido de la información(reducción de la dimensionalidad) o encontrar reglas de asociación. La mayor parte de este libro se centrará en el aprendizaje supervisado, porque la inmensa mayoría de los modelos de aprendizaje automático utilizados en producción son supervisados.
En el aprendizaje supervisado, los problemas suelen definirse como de clasificación o de regresión. Los modelos de clasificación asignan a tus datos de entrada una etiqueta (o etiquetas) de un conjunto discreto y predefinido de categorías. Algunos ejemplos de problemas de clasificación son determinar el tipo de raza de una mascota en una imagen, etiquetar un documento o predecir si una transacción es fraudulenta o no. Los modelos de regresión asignan valores numéricos continuos a sus entradas. Algunos ejemplos de modelos de regresión son predecir la duración de un viaje en bicicleta, los ingresos futuros de una empresa o el precio de un producto.
Ingeniería de datos y características
Los datos son el núcleo de cualquier problema de aprendizaje automático. Cuando hablamos de conjuntos de datos, nos referimos a los datos utilizados para entrenar, validar y probar un modelo de aprendizaje automático. La mayor parte de tus datos serán datos de entrenamiento: los datos alimentados a tu modelo durante el proceso de entrenamiento. Los datos de validación son los datos que se retienen de tu conjunto de entrenamiento y se utilizan para evaluar el rendimiento del modelo después de cada época de entrenamiento (o paso por los datos de entrenamiento). El rendimiento del modelo en los datos de validación se utiliza para decidir cuándo detener el proceso de entrenamiento y para elegir los hiperparámetros, como el número de árboles en un modelo de bosque aleatorio. Los datos de prueba son datos que no se utilizan en absoluto en el proceso de entrenamiento y se utilizan para evaluar el rendimiento del modelo entrenado. Los informes de rendimiento del modelo de aprendizaje automático deben calcularse sobre los datos de prueba independientes, en lugar de sobre los de entrenamiento o validación. También es importante que los datos se dividan de forma que los tres conjuntos de datos (entrenamiento, prueba, validación) tengan propiedades estadísticas similares.
Los datos que utilizas para entrenar tu modelo pueden adoptar muchas formas, según el tipo de modelo. Definimos los datos estructurados como datos numéricos y categóricos. Los datos numéricos incluyen valores enteros y flotantes, y los datos categóricos incluyen datos que pueden dividirse en un conjunto finito de grupos, como el tipo de coche o el nivel educativo. También puedes pensar en los datos estructurados como los datos que encontrarías habitualmente en una hoja de cálculo. A lo largo del libro, utilizaremos el término datos tabulares indistintamente de datos estructurados. Los datos no estructurados, por otra parte, incluyen datos que no pueden representarse de forma tan ordenada. Suelen ser texto libre, imágenes, vídeo y audio.
A menudo, los datos numéricos pueden introducirse directamente en un modelo de aprendizaje automático, mientras que otros datos requieren diversos pasos de preprocesamiento antes de que estén listos para ser enviados a un modelo. Este paso de preprocesamiento suele incluir el escalado de valores numéricos, o la conversión de datos no numéricos a un formato numérico que pueda entender tu modelo. Otro término para el preprocesamiento es ingeniería de características. Utilizaremos estos dos términos indistintamente a lo largo del libro.
Hay varios términos utilizados para describir los datos a medida que pasan por el proceso de ingeniería de características. La entrada describe una única columna de tu conjunto de datos antes de que haya sido procesada, y la característica describe una única columna después de que haya sido procesada. Por ejemplo, una marca de tiempo podría ser tu entrada, y la característica sería el día de la semana. Para convertir los datos de marca de tiempo a día de la semana, tendrás que hacer un preprocesamiento de los datos. Este paso de preprocesamiento también puede denominarse transformación de datos.
Una instancia es un elemento que quieres enviar a tu modelo para que realice una predicción. Una instancia puede ser una fila de tu conjunto de datos de prueba (sin la columna de etiquetas), una imagen que quieras clasificar o un documento de texto que enviar a un modelo de análisis de sentimientos. Dado un conjunto de características sobre la instancia, el modelo calculará un valor predicho. Para ello, el modelo se entrena con ejemplos de entrenamiento, que asocian una instancia con una etiqueta. Un ejemplo de entrenamiento se refiere a una única instancia (fila) de datos de tu conjunto de datos que se alimentará a tu modelo. Basándonos en el caso de uso de la marca de tiempo, un ejemplo de entrenamiento completo podría incluir: "día de la semana", "ciudad" y "tipo de coche". Una etiqueta es la columna de salida de tu conjunto de datos: el elemento que tu modelo está prediciendo. Etiqueta puede referirse tanto a la columna objetivo de tu conjunto de datos (también llamada etiqueta de verdad básica) como a la salida dada por tu modelo (también llamada predicción). Una etiqueta de muestra para el ejemplo de entrenamiento descrito anteriormente podría ser "duración del viaje", en este caso, un valor flotante que denota minutos.
Una vez que hayas reunido tu conjunto de datos y determinado las características de tu modelo, la validación de los datos es el proceso de calcular las estadísticas de tus datos, comprender tu esquema y evaluar el conjunto de datos para identificar problemas como la desviación y la asimetría del entrenamiento. Evaluar diversas estadísticas de tus datos puede ayudarte a garantizar que el conjunto de datos contiene una representación equilibrada de cada característica. En los casos en que no sea posible recoger más datos, comprender el equilibrio de los datos te ayudará a diseñar tu modelo para tenerlo en cuenta. Comprender tu esquema implica definir el tipo de datos de cada característica e identificar ejemplos de entrenamiento en los que ciertos valores pueden ser incorrectos o faltar. Por último, la validación de datos puede identificar incoherencias que pueden afectar a la calidad de tus conjuntos de entrenamiento y prueba. Por ejemplo, puede que la mayor parte de tu conjunto de datos de entrenamiento contenga ejemplos de días laborables, mientras que tu conjunto de prueba contiene principalmente ejemplos de fines de semana.
El proceso de aprendizaje automático
El primer paso en un flujo de trabajo típico de aprendizaje automático es el entrenamiento:el proceso de pasar datos de entrenamiento a un modelo para que pueda aprender a identificar patrones. Tras el entrenamiento, el siguiente paso del proceso es probar cómo funciona tu modelo con datos ajenos al conjunto de entrenamiento. Esto se conoce como evaluación del modelo. Es posible que ejecutes el entrenamiento y la evaluación varias veces, realizando ingeniería de características adicional y ajustando la arquitectura de tu modelo. Una vez que estés satisfecho con el rendimiento de tu modelo durante la evaluación, es probable que quieras servir tu modelo para que otros puedan acceder a él para hacer predicciones. Utilizamos el término servir para referirnos a la aceptación de solicitudes entrantes y el envío de predicciones mediante la implementación del modelo como un microservicio. La infraestructura de servicio puede estar en la nube, en las instalaciones o en el dispositivo.
El proceso de enviar nuevos datos a tu modelo y hacer uso de su salida se denomina predicción. Esto puede referirse tanto a la generación de predicciones a partir de modelos locales que aún no se han desplegado como a la obtención de predicciones a partir de modelos desplegados. Para los modelos desplegados, nos referiremos tanto a la predicción en línea como a la predicción por lotes. La predicción en línea se utiliza cuando quieres obtener predicciones sobre unos pocos ejemplos casi en tiempo real. Con la predicción en línea, el énfasis se pone en baja latencia. La predicción por lotes, en cambio, se refiere a la generación de predicciones sobre un gran conjunto de datos fuera de línea. Los trabajos de predicción por lotes tardan más que la predicción en línea y son útiles para precalcular predicciones (como en los sistemas de recomendación) y para analizar las predicciones de tu modelo en una gran muestra de datos nuevos.
La palabra predicción es adecuada cuando se trata de prever valores futuros, como al predecir la duración de un paseo en bicicleta o predecir si se abandonará un carro de la compra. Es menos intuitiva en el caso de los modelos de clasificación de imágenes y textos. Si un modelo ML observa una reseña de texto y da como resultado que el sentimiento es positivo, no es realmente una "predicción" (no hay un resultado futuro). De ahí que también veas que se utiliza la palabra inferencia para referirse a las predicciones. Aquí se está reutilizando el término estadístico inferencia, pero en realidad no se trata de razonamiento.
A menudo, los procesos de recopilación de datos de entrenamiento, ingeniería de características, entrenamiento y evaluación de tu modelo se gestionan por separado de la cadena de producción. Cuando éste sea el caso, volverás a evaluar tu solución cada vez que decidas que tienes suficientes datos adicionales para entrenar una nueva versión de tu modelo. En otras situaciones, puedes tener nuevos datos que se ingieren continuamente y necesitas procesar estos datos inmediatamente antes de enviarlos a tu modelo para el entrenamiento o la predicción. Esto se conoce como streaming. Para manejar los datos en flujo, necesitarás una solución de varios pasos para realizar la ingeniería de características, el entrenamiento, la evaluación y las predicciones. Estas soluciones multipaso se denominan canalizaciones ML.
Herramientas de datos y modelos
Hay varios productos de Google Cloud a los que haremos referencia y que proporcionan herramientas para resolver problemas de datos y aprendizaje automático. Estos productos no son más que una opción para implementar los patrones de diseño a los que se hace referencia en este libro y no pretenden ser una lista exhaustiva. Todos los productos incluidos aquí son sin servidor, lo que nos permite centrarnos más en la implementación de patrones de diseño de aprendizaje automático en lugar de en la infraestructura que hay detrás de ellos.
BigQuery es un almacén de datos empresarial diseñado para analizar grandes conjuntos de datos rápidamente con SQL. Utilizaremos BigQuery en nuestros ejemplos para la recopilación de datos y la ingeniería de características. Los datos en BigQuery se organizan por Conjuntos de Datos, y un Conjunto de Datos puede tener varias Tablas. Muchos de nuestros ejemplos utilizarán datos de Google Cloud Public Datasets, un conjunto de datos gratuitos y disponibles públicamente alojados en BigQuery. Google Cloud Public Datasets consta de cientos de conjuntos de datos diferentes, incluidos datos meteorológicos de la NOAA desde 1929, preguntas y respuestas de Stack Overflow, código fuente abierto de GitHub, datos de natalidad, etc. Para construir algunos de los modelos de nuestros ejemplos, utilizaremos BigQuery Machine Learning (o BigQuery ML). BigQuery ML es una herramienta para construir modelos a partir de datos almacenados en BigQuery. Con BigQuery ML, podemos entrenar, evaluar y generar predicciones sobre nuestros modelos utilizando SQL. Admite modelos de clasificación y regresión, junto con modelos de agrupación no supervisados. También es posible importar modelos TensorFlow previamente entrenados a BigQuery ML para realizar predicciones.
Cloud AI Platform incluye una variedad de productos para entrenar y servir modelos personalizados de aprendizaje automático en Google Cloud. En nuestros ejemplos, utilizaremos AI Platform Training y AI Platform Prediction. AI Platform Training proporciona infraestructura para entrenar modelos de aprendizaje automático en Google Cloud. Con AI Platform Prediction, puedes implementar tus modelos entrenados y generar predicciones sobre ellos utilizando una API. Ambos servicios admiten modelos TensorFlow, scikit-Learn y XGBoost, junto con contenedores personalizados para modelos construidos con otros marcos. También haremos referencia a Explainable AI, una herramienta para interpretar los resultados de las predicciones de tu modelo, disponible para modelos implementados en AI Platform.
Funciones
Dentro de una organización, hay muchas funciones diferentes relacionadas con los datos y el aprendizaje automático. A continuación definiremos algunos de los más comunes a los que se hace referencia con frecuencia a lo largo del libro. Este libro está dirigido principalmente a científicos de datos, ingenieros de datos e ingenieros de ML, así que empezaremos por ellos.
Un científico de datos es alguien que se dedica a recopilar, interpretar y procesar conjuntos de datos. Realizan análisis estadísticos y exploratorios de los datos. En relación con el aprendizaje automático, un científico de datos puede trabajar en la recopilación de datos, la ingeniería de características, la creación de modelos y mucho más. Los científicos de datos suelen trabajar en Python o R en un entorno de bloc de notas, y suelen ser los primeros en crear los modelos de aprendizaje automático de una organización.
Un ingeniero de datos se centra en la infraestructura y los flujos de trabajo que impulsan los datos de una organización. Pueden ayudar a gestionar la forma en que una empresa ingiere los datos, los conductos de datos y cómo se almacenan y transfieren los datos. Los ingenieros de datos implementan la infraestructura y las canalizaciones en torno a los datos.
Los ingenieros de aprendizaje automático realizan tareas similares a las de los ingenieros de datos, pero para los modelos de ML. Toman los modelos desarrollados por los científicos de datos y gestionan la infraestructura y las operaciones en torno a la formación y la implementación de esos modelos. Los ingenieros de ML ayudan a construir sistemas de producción para gestionar la actualización de los modelos, el versionado de modelos y el servicio de predicciones a los usuarios finales.
Cuanto más pequeño es el equipo de ciencia de datos de una empresa y más ágil es el equipo, más probable es que la misma persona desempeñe múltiples funciones. Si te encuentras en una situación así, es muy probable que leas las tres descripciones anteriores y te veas parcialmente en las tres categorías. Lo normal es que empieces un proyecto de aprendizaje automático como ingeniero de datos y construyas canalizaciones de datos para hacer operativa la ingesta de datos. A continuación, pasas al papel de científico de datos y construyes el modelo o modelos de ML. Por último, te pones el sombrero de ingeniero de ML y pasas el modelo a producción. En las grandes organizaciones, los proyectos de aprendizaje automático pueden pasar por las mismas fases, pero en cada una de ellas pueden participar distintos equipos.
Los científicos investigadores, los analistas de datos y los desarrolladores también pueden construir y utilizar modelos de IA, pero estos puestos de trabajo no son el público objetivo de este libro.
Los científicos investigadores se centran principalmente en encontrar y desarrollar nuevos algoritmos para hacer avanzar la disciplina del ML. Esto podría incluir una variedad de subcampos dentro del aprendizaje automático, como arquitecturas de modelos, procesamiento del lenguaje natural, visión por ordenador, ajuste de hiperparámetros, interpretabilidad de modelos y más. A diferencia de las otras funciones que se tratan aquí, los científicos de investigación pasan la mayor parte de su tiempo creando prototipos y evaluando nuevos enfoques del LD, en lugar de crear sistemas de LD de producción.
Los analistas de datos evalúan y recopilan información a partir de los datos, y luego la resumen para otros equipos de su organización. Suelen trabajar con SQL y hojas de cálculo, y utilizan herramientas de inteligencia empresarial para crear visualizaciones de datos con las que compartir sus conclusiones. Los analistas de datos colaboran estrechamente con los equipos de producto para comprender cómo sus conocimientos pueden ayudar a abordar los problemas empresariales y crear valor. Mientras que los analistas de datos se centran en la identificación de tendencias en los datos existentes y en la obtención de perspectivas a partir de ellos, los científicos de datos se ocupan de utilizar esos datos para generar predicciones futuras y en automatizar o ampliar la generación de perspectivas. Con la creciente democratización del aprendizaje automático, los analistas de datos pueden perfeccionarse para convertirse en científicos de datos.
Los desarrolladores son los encargados de construir los sistemas de producción que permiten a los usuarios finales acceder a los modelos de ML. A menudo participan en el diseño de las API que consultan los modelos y devuelven las predicciones en un formato fácil de usar a través de una aplicación web o móvil. Puede tratarse de modelos alojados en la nube o de modelos servidos en el dispositivo. Los desarrolladores utilizan la infraestructura de servicio de modelos implementada por los ingenieros de ML para crear aplicaciones e interfaces de usuario que muestren las predicciones a los usuarios de los modelos.
La Figura 1-2 ilustra cómo estas diferentes funciones trabajan juntas a lo largo del proceso de desarrollo de modelos de aprendizaje automático de una organización.
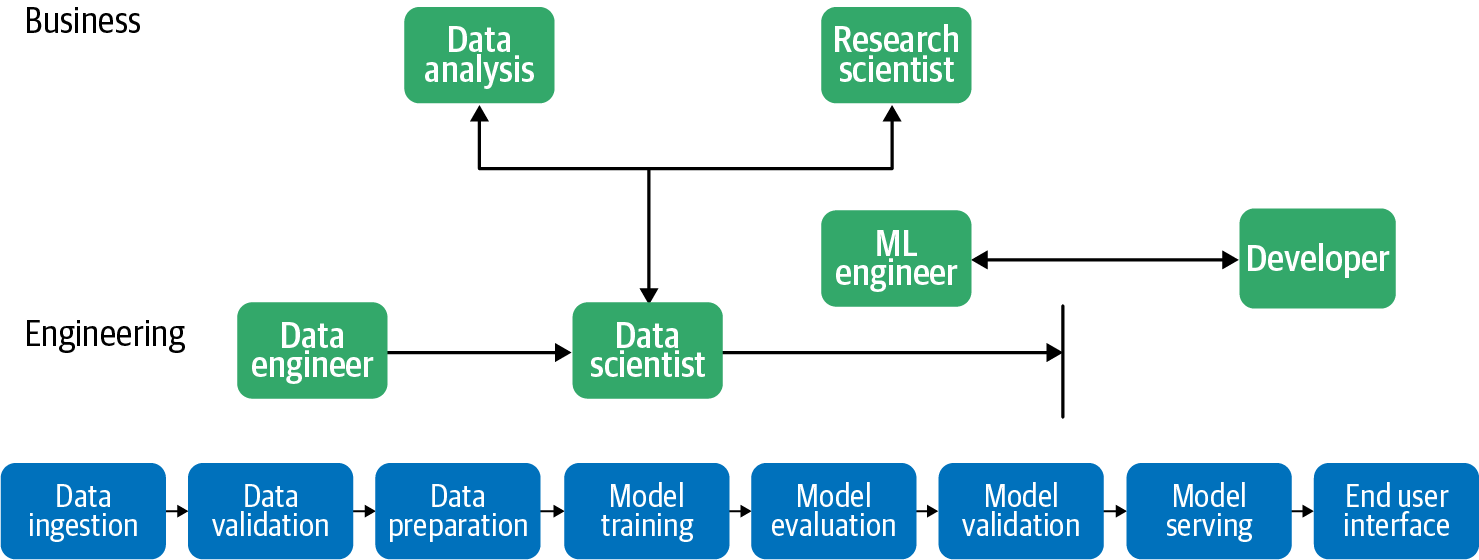
Figura 1-2. Hay muchas funciones diferentes relacionadas con los datos y el aprendizaje automático, y estas funciones colaboran en el flujo de trabajo del ML, desde la ingestión de datos hasta el servicio del modelo y la interfaz del usuario final. Por ejemplo, el ingeniero de datos trabaja en la ingestión y validación de datos y colabora estrechamente con los científicos de datos.
Retos comunes en el aprendizaje automático
¿Por qué necesitamos un libro sobre patrones de diseño de aprendizaje automático? El proceso de creación de sistemas de ML presenta una serie de retos únicos que influyen en el diseño del ML. Comprender estos retos te ayudará a ti, profesional del ML, a desarrollar un marco de referencia para las soluciones presentadas a lo largo del libro.
Calidad de los datos
Los modelos de aprendizaje automático son tan fiables como los datos utilizados para entrenarlos. Si entrenas un modelo de aprendizaje automático en un conjunto de datos incompleto, en datos con características mal seleccionadas o en datos que no representan con exactitud a la población que utiliza el modelo, las predicciones de tu modelo serán un reflejo directo de esos datos. Como resultado, los modelos de aprendizaje automático suelen denominarse "basura dentro, basura fuera". Aquí destacaremos cuatro componentes importantes de la calidad de los datos: precisión, integridad, coherencia y puntualidad.
La precisión de los datos se refiere tanto a las características de tus datos de entrenamiento como a las etiquetas de la verdad sobre el terreno correspondientes a esas características. Comprender de dónde proceden tus datos y cualquier posible error en el proceso de recopilación de datos puede ayudar a garantizar la precisión de las características. Una vez recopilados los datos, es importante realizar un análisis exhaustivo para detectar errores tipográficos, entradas duplicadas, incoherencias de medición en los datos tabulares, características que faltan y cualquier otro error que pueda afectar a la calidad de los datos. Los duplicados en tu conjunto de datos de entrenamiento, por ejemplo, pueden hacer que tu modelo asigne incorrectamente más peso a esos puntos de datos.
La precisión de las etiquetas de los datos es tan importante como la precisión de las características. Tu modelo se basa únicamente en las etiquetas de verdad en tus datos de entrenamiento para actualizar sus pesos y minimizar las pérdidas. Como resultado, los ejemplos de entrenamiento etiquetados incorrectamente pueden causar una precisión engañosa del modelo. Por ejemplo, supongamos que estás construyendo un modelo de análisis de sentimientos y el 25% de tus ejemplos de entrenamiento "positivos" se han etiquetado incorrectamente como "negativos". Tu modelo tendrá una imagen inexacta de lo que debería considerarse sentimiento negativo, y esto se reflejará directamente en sus predicciones.
Para entender la exhaustividad de los datos, supongamos que estás entrenando un modelo para identificar razas de gatos. Entrenas el modelo en un amplio conjunto de datos de imágenes de gatos, y el modelo resultante es capaz de clasificar las imágenes en 1 de las 10 categorías posibles ("Bengalí", "Siamés", etc.) con una precisión del 99%. Sin embargo, cuando implementas tu modelo en producción, descubres que, además de subir fotos de gatos para su clasificación, muchos de tus usuarios suben fotos de perros y se sienten decepcionados con los resultados del modelo. Como el modelo se entrenó sólo para identificar 10 razas diferentes de gatos, esto es todo lo que sabe hacer. Estas 10 categorías de razas son, esencialmente, toda la "visión del mundo" del modelo. No importa lo que envíes al modelo, puedes esperar que lo clasifique en una de estas 10 categorías. Incluso es posible que lo haga con gran confianza en una imagen que no se parece en nada a un gato. Además, no hay forma de que tu modelo pueda devolver "no es un gato" si estos datos y la etiqueta no se incluyeron en el conjunto de datos de entrenamiento.
Otro aspecto de la exhaustividad de los datos es garantizar que tus datos de entrenamiento contengan una representación variada de cada etiqueta. En el ejemplo de la detección de la raza de un gato, si todas tus imágenes son primeros planos de la cara de un gato, tu modelo no podrá identificar correctamente una imagen de un gato de perfil, o una imagen de un gato de cuerpo entero. Para ver un ejemplo de datos tabulares, si estás construyendo un modelo para predecir el precio de los bienes inmuebles en una ciudad concreta, pero sólo incluyes ejemplos de entrenamiento de casas de más de 2.000 pies cuadrados, tu modelo resultante tendrá un rendimiento deficiente en las casas más pequeñas.
El tercer aspecto de la calidad de los datos es su coherencia. En el caso de grandes conjuntos de datos, es habitual dividir el trabajo de recopilación y etiquetado de datos entre un grupo de personas. Desarrollar un conjunto de normas para este proceso puede ayudar a garantizar la coherencia de tu conjunto de datos, ya que cada persona implicada en ello aportará inevitablemente sus propios sesgos al proceso. Al igual que ocurre con la integridad de los datos, las incoherencias en los datos pueden encontrarse tanto en las características de los datos como en las etiquetas. Como ejemplo de características incoherentes, digamos que estás recopilando datos atmosféricos de sensores de temperatura. Si cada sensor se ha calibrado según normas diferentes, esto dará lugar a predicciones del modelo inexactas y poco fiables. Las incoherencias también pueden referirse al formato de los datos. Si estás capturando datos de localización, algunas personas pueden escribir la dirección completa de una calle como "Calle Mayor" y otras pueden abreviarla como "Calle Mayor". Las unidades de medida, como millas y kilómetros, también pueden diferir en todo el mundo.
En cuanto a las incoherencias en el etiquetado, volvamos al ejemplo del sentimiento del texto. En este caso, es probable que las personas no siempre coincidan en lo que se considera positivo y negativo al etiquetar los datos de entrenamiento. Para solucionarlo, puedes hacer que varias personas etiqueten cada ejemplo de tu conjunto de datos, y luego tomar la etiqueta más comúnmente aplicada a cada elemento. Ser consciente del posible sesgo del etiquetador, e implantar sistemas que lo tengan en cuenta, garantizará la coherencia de las etiquetas en todo tu conjunto de datos. Exploraremos el concepto de sesgo en el "Patrón de diseño 30: Lente de imparcialidad" del Capítulo 7.
La puntualidad en los datos se refiere a la latencia entre el momento en que se produjo un evento y el momento en que se añadió a tu base de datos. Si recopilas datos sobre registros de aplicaciones, por ejemplo, un registro de errores puede tardar unas horas en aparecer en tu base de datos de registros. Para un conjunto de datos que registre transacciones de tarjetas de crédito, puede pasar un día desde que se produjo la transacción hasta que aparezca en tu sistema. Para hacer frente a la puntualidad, es útil registrar toda la información posible sobre un punto de datos concreto, y asegurarte de que esa información se refleja cuando transformas tus datos en características para un modelo de aprendizaje automático. Más concretamente, puedes llevar un registro de la marca de tiempo de cuándo se produjo un evento y cuándo se añadió a tu conjunto de datos. Luego, al realizar la ingeniería de características, puedes tener en cuenta estas diferencias en consecuencia.
Reproducibilidad
En la programación tradicional, la salida de un programa es reproducible y está garantizada. Por ejemplo, si escribes un programa en Python que invierte una cadena, sabes que una entrada de la palabra "plátano" siempre devolverá una salida de "ananab". Del mismo modo, si hay un error en tu programa que hace que invierta incorrectamente cadenas que contienen números, puedes enviar el programa a un colega y esperar que sea capaz de reproducir el error con las mismas entradas que tú utilizaste (a menos que el error tenga algo que ver con que el programa mantenga algún estado interno incorrecto, diferencias en la arquitectura, como la precisión del punto flotante, o diferencias en la ejecución, como los hilos).
Los modelos de aprendizaje automático, por otra parte, tienen un elemento inherente de aleatoriedad. Cuando se entrenan, los pesos del modelo ML se inicializan con valores aleatorios. Estos pesos convergen durante el entrenamiento a medida que el modelo itera y aprende de los datos. Por este motivo, el mismo código de modelo, con los mismos datos de entrenamiento, producirá resultados ligeramente diferentes en las distintas ejecuciones de entrenamiento. Esto introduce un reto de reproducibilidad. Si entrenas un modelo con una precisión del 98,1%, no está garantizado que una ejecución de entrenamiento repetida alcance el mismo resultado. Esto puede dificultar las comparaciones entre experimentos.
Para abordar este problema de repetibilidad, es habitual establecer el valor de la semilla aleatoria que utiliza tu modelo para garantizar que se aplicará la misma aleatoriedad cada vez que ejecutes el entrenamiento. En TensorFlow, puedes hacerlo ejecutando tf.random.set_seed(value) al principio de tu programa.
Además, en scikit-learn, muchas funciones de utilidad para barajar tus datos también te permiten establecer un valor de semilla aleatorio:
fromsklearn.utilsimportshuffledata=shuffle(data,random_state=value)
Ten en cuenta que tendrás que utilizar los mismos datos y la misma semilla aleatoria al entrenar tu modelo para garantizar resultados repetibles y reproducibles en diferentes experimentos.
El entrenamiento de un modelo de ML implica varios artefactos que deben fijarse para garantizar la reproducibilidad: los datos utilizados, el mecanismo de división utilizado para generar conjuntos de datos para el entrenamiento y la validación, la preparación de los datos y los hiperparámetros del modelo, y variables como el tamaño del lote y la programación de la tasa de aprendizaje.
La reproducibilidad también se aplica a las dependencias de los marcos de aprendizaje automático. Además de establecer manualmente una semilla aleatoria, los marcos de trabajo también implementan internamente elementos de aleatoriedad que se ejecutan cuando llamas a una función para entrenar tu modelo. Si esta implementación subyacente cambia entre distintas versiones del marco, la repetibilidad no está garantizada. Como ejemplo concreto, si una versión del método train() de un framework realiza 13 llamadas a rand(), y una versión más reciente del mismo framework realiza 14 llamadas, el uso de versiones diferentes entre experimentos provocará resultados ligeramente distintos, incluso con los mismos datos y código de modelo. Ejecutar las cargas de trabajo ML en contenedores y estandarizar las versiones de las bibliotecas puede ayudar a garantizar la repetibilidad. El Capítulo 6 presenta una serie de patrones para hacer reproducibles los procesos de ML.
Por último, la reproducibilidad puede referirse al entorno de entrenamiento de un modelo. A menudo, debido a los grandes conjuntos de datos y a su complejidad, muchos modelos tardan mucho tiempo en entrenarse. Esto puede acelerarse empleando estrategias de distribución como el paralelismo de datos o modelos (véase el Capítulo 5). Sin embargo, esta aceleración conlleva un reto añadido de repetibilidad cuando vuelves a ejecutar el código que hace uso del entrenamiento distribuido.
Deriva de datos
Aunque los modelos de aprendizaje automático suelen representar una relación estática entre entradas y salidas, los datos pueden cambiar significativamente con el tiempo. La deriva de datos se refiere al reto de garantizar que tus modelos de aprendizaje automático sigan siendo relevantes, y que las predicciones de los modelos sean un reflejo exacto del entorno en el que se utilizan.
Por ejemplo, supongamos que estás entrenando un modelo para clasificar titulares de artículos de noticias en categorías como "política", "negocios" y "tecnología". Si entrenas y evalúas tu modelo con artículos de noticias históricos del siglo XX, es probable que no funcione tan bien con los datos actuales. Hoy sabemos que un artículo con la palabra "smartphone" en el titular probablemente trate sobre tecnología. Sin embargo, un modelo entrenado con datos históricos no tendría conocimiento de esta palabra. Para resolver la deriva, es importante actualizar continuamente tu conjunto de datos de entrenamiento, volver a entrenar tu modelo y modificar el peso que tu modelo asigna a determinados grupos de datos de entrada.
Para ver un ejemplo menos obvio de deriva, observa el conjunto de datos de tormentas graves de la NOAA en BigQuery. Si estuviéramos entrenando un modelo para predecir la probabilidad de una tormenta en una zona determinada, tendríamos que tener en cuenta la forma en que han cambiado los informes meteorológicos a lo largo del tiempo. Podemos ver en la Figura 1-3 que el número total de tormentas graves registradas ha aumentado de forma constante desde 1950.
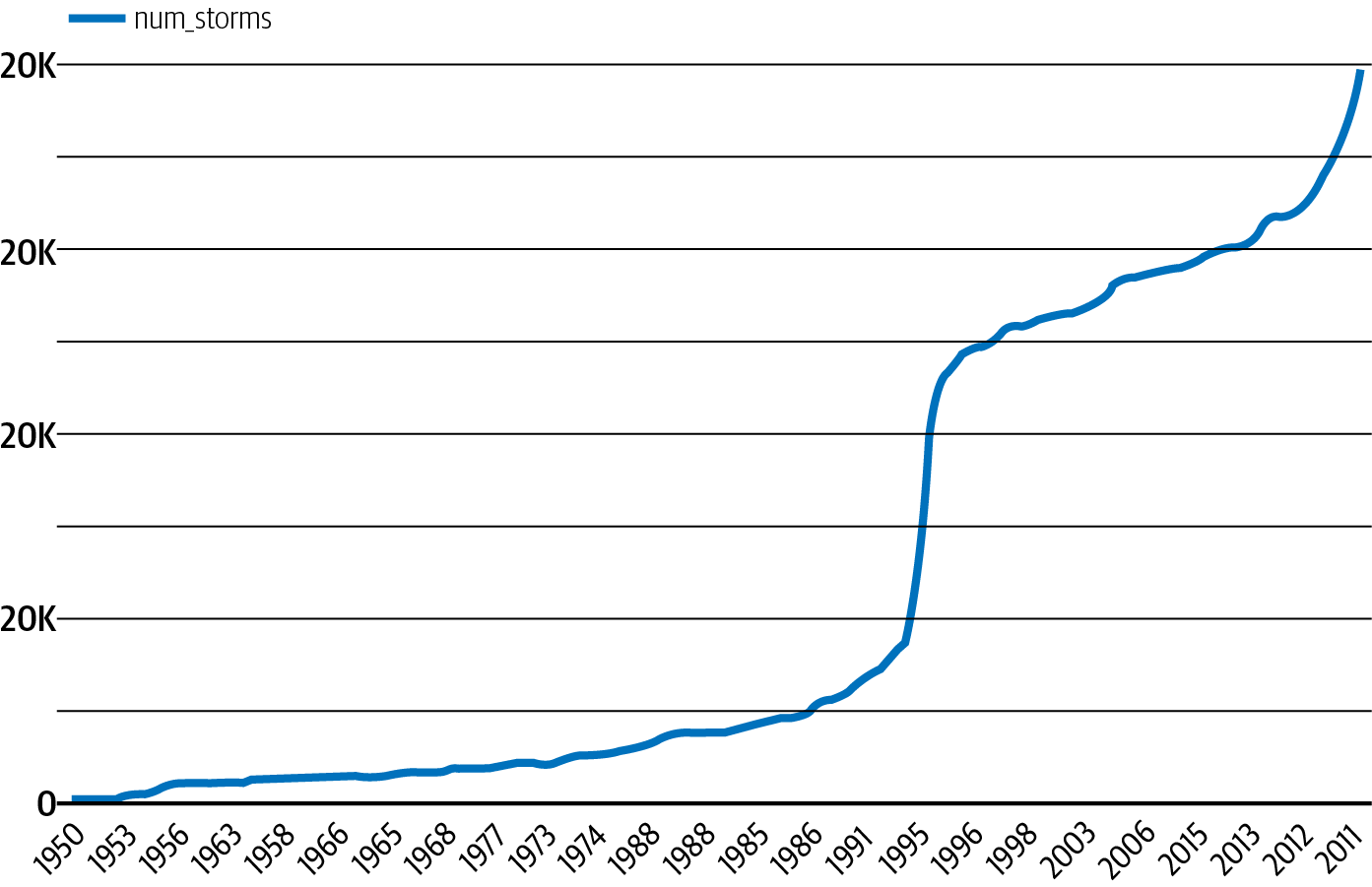
Figura 1-3. Número de tormentas graves registradas en un año, según los datos de la NOAA de 1950 a 2011.
A partir de esta tendencia, podemos ver que entrenar un modelo con datos anteriores a 2000 para generar predicciones sobre las tormentas actuales daría lugar a predicciones inexactas. Además del aumento del número total de tormentas registradas, también es importante tener en cuenta otros factores que pueden haber influido en los datos de la Figura 1-3. Por ejemplo, la tecnología para observar las tormentas ha mejorado con el tiempo, de forma más espectacular con la introducción de los radares meteorológicos en la década de 1990. En el contexto de las características, esto puede significar que los datos más recientes contienen más información sobre cada tormenta, y que una característica disponible en los datos actuales puede no haberse observado en 1950. El análisis exploratorio de datos puede ayudar a identificar este tipo de desviación y puede informar sobre la ventana correcta de datos a utilizar para el entrenamiento. La Sección , "Patrón de diseño 23: Esquema puenteado" proporciona una forma de manejar conjuntos de datos en los que la disponibilidad de características mejora con el tiempo.
Escala
El reto del escalado está presente en muchas fases de un flujo de trabajo típico de aprendizaje automático. Es probable que encuentres retos de escalado en la recopilación y el preprocesamiento de datos, el entrenamiento y el servicio. Al ingerir y preparar los datos para un modelo de aprendizaje automático, el tamaño del conjunto de datos dictará las herramientas necesarias para tu solución. A menudo, el trabajo de los ingenieros de datos consiste en crear canalizaciones de datos que puedan escalarse para manejar conjuntos de datos con millones de filas.
Para el entrenamiento de modelos, los ingenieros de ML son responsables de determinar la infraestructura necesaria para un trabajo de entrenamiento específico. Según el tipo y el tamaño del conjunto de datos, el entrenamiento de modelos puede llevar mucho tiempo y ser costoso desde el punto de vista computacional, lo que requiere una infraestructura (como GPU) diseñada específicamente para cargas de trabajo de ML. Los modelos de imágenes, por ejemplo, suelen requerir mucha más infraestructura de entrenamiento que los modelos entrenados enteramente con datos tabulares.
En el contexto del servicio de modelos, la infraestructura necesaria para apoyar a un equipo de científicos de datos que obtienen predicciones de un prototipo de modelo es totalmente diferente de la infraestructura necesaria para apoyar a un modelo de producción que recibe millones de solicitudes de predicción cada hora. Los desarrolladores y los ingenieros de ML suelen ser los responsables de gestionar los retos de escalado asociados a la implementación de modelos y el servicio de solicitudes de predicción.
La mayoría de los patrones de ML de este libro son útiles sin tener en cuenta la madurez de la organización. Sin embargo, varios de los patrones de los Capítulos 6 y 7 abordan los retos de resiliencia y reproducibilidad de diferentes maneras, y la elección entre ellos a menudo se reducirá al caso de uso y a la capacidad de tu organización para absorber la complejidad.
Objetivos múltiples
Aunque a menudo hay un único equipo responsable de crear un modelo de aprendizaje automático, muchos equipos de una organización utilizarán el modelo de alguna manera. Inevitablemente, estos equipos pueden tener ideas diferentes de lo que define un modelo de éxito.
Para entender cómo puede funcionar esto en la práctica, digamos que estás construyendo un modelo para identificar productos defectuosos a partir de imágenes. Como científico de datos, tu objetivo puede ser minimizar la pérdida de entropía cruzada de tu modelo. El director de producto, por otro lado, puede querer reducir el número de productos defectuosos que se clasifican erróneamente y se envían a los clientes. Por último, el objetivo del equipo ejecutivo podría ser aumentar los ingresos un 30%. Cada uno de estos objetivos varía en lo que se refiere a su optimización, y equilibrar estas diferentes necesidades dentro de una organización puede suponer un reto.
Como científico de datos, podrías traducir las necesidades del equipo de producto al contexto de tu modelo diciendo que los falsos negativos son cinco veces más costosos que los falsos positivos. Por lo tanto, al diseñar tu modelo, debes optimizar la recuperación por encima de la precisión para satisfacer esta necesidad. Así podrás encontrar un equilibrio entre el objetivo del equipo de producto de optimizar la precisión y tu objetivo de minimizar las pérdidas del modelo.
Al definir los objetivos de tu modelo, es importante tener en cuenta las necesidades de los distintos equipos de una organización, y cómo se relacionan las necesidades de cada equipo con el modelo. Si analizas qué optimiza cada equipo antes de crear tu solución, podrás encontrar áreas de compromiso para equilibrar óptimamente estos objetivos múltiples.
Resumen
Los patrones de diseño son una forma de codificar los conocimientos y la experiencia de los expertos en consejos que todos los profesionales pueden seguir. Los patrones de diseño de este libro recogen las buenas prácticas y las soluciones a los problemas más frecuentes en el diseño, la construcción y la implementación de sistemas de aprendizaje automático. Los retos habituales en el aprendizaje automático suelen girar en torno a la calidad de los datos, la reproducibilidad, la deriva de los datos, la escala y la necesidad de satisfacer múltiples objetivos.
Solemos utilizar distintos patrones de diseño de ML en distintas fases del ciclo de vida del ML. Hay patrones que son útiles para enmarcar el problema y evaluar la viabilidad. La mayoría de los patrones abordan el desarrollo o la implementación, y bastantes de ellos abordan la interacción entre estas etapas.
Get Patrones de diseño de aprendizaje automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

