First, some metadata on the college dataset will be collected, followed by basic summary statistics of each column:
- Read in the dataset, and view the first five rows with the head method:
>>> college = pd.read_college('data/college.csv')>>> college.head()
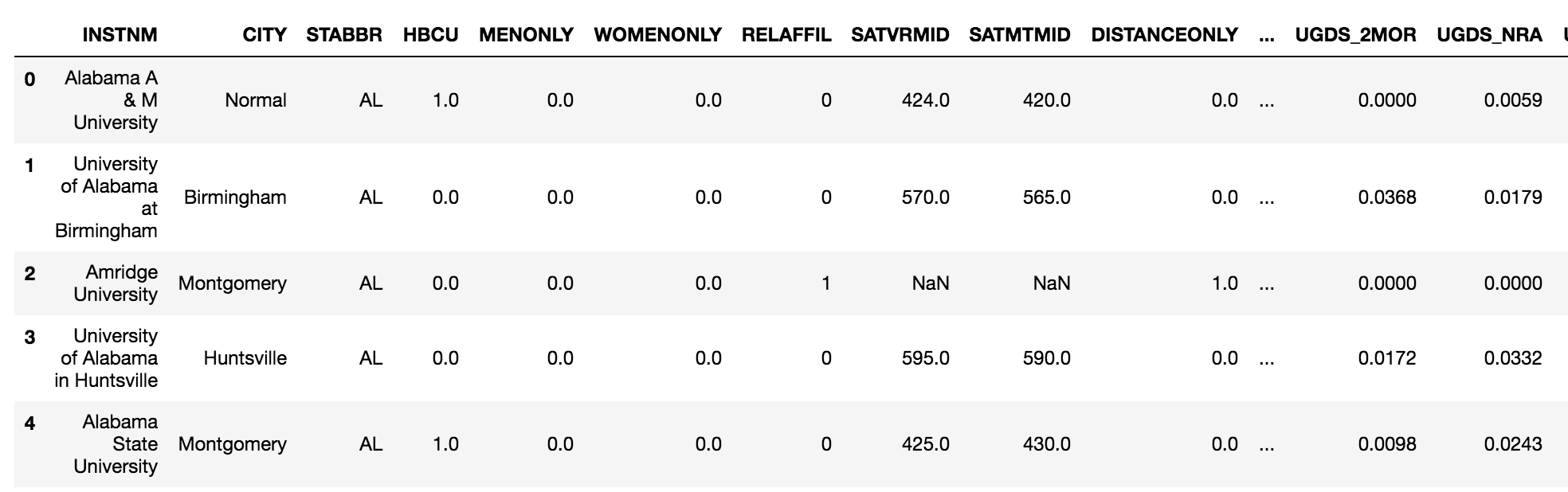
- Get the dimensions of the DataFrame with the shape attribute:
>>> college.shape>>> (7535, 27)
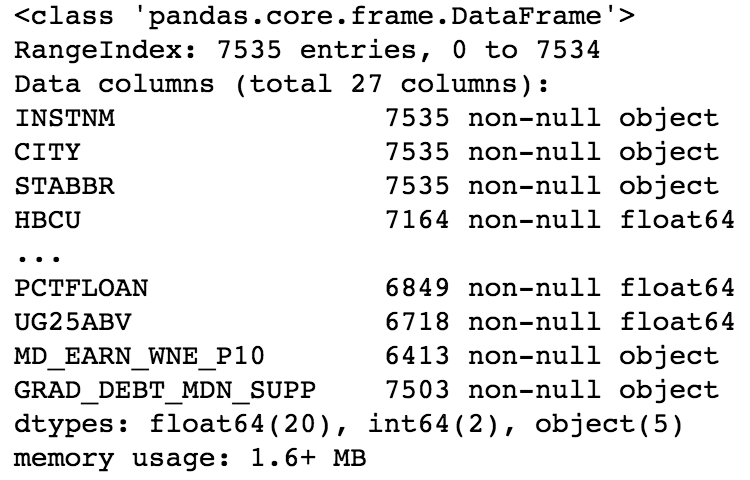
- List the data type of each column, number of non-missing values, and memory usage with the info method:
>>> college.info()
- Get summary statistics for the numerical columns and ...

