Chapter 3. Object, Block, and Streaming Storage with Kubernetes
How data is stored and processed will make a big difference to your team’s quality of life. A well thought-out, optimized data pipeline makes teams more productive. While Kubernetes makes deploying new technologies easier, the storage systems we choose to rely on still remain a crucial determinant of long-term success. With many options available, it pays to be well informed on the trade-offs of each type of storage and how best to deliver persistent data services to a Kubernetes cluster in use.
In this chapter, we’ll explain what object, block, and streaming storage are and how best to put them to use in data pipelines built with Kubernetes. Chapters 4 and 5 will explain in more detail how to tie these components together in practice with a Kubernetes architecture.
Object Storage
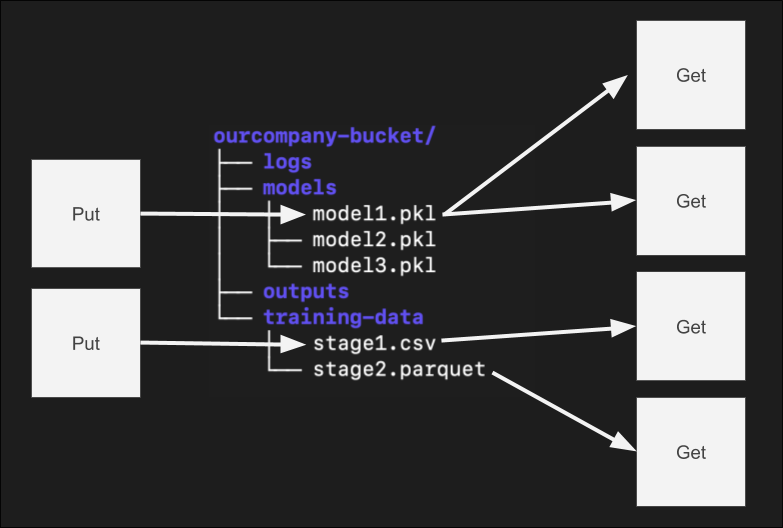
Object storage is one of the most essential types of storage for intelligent and cloud native applications. Many use cases rely on a storage system that offers a stable API for storing and retrieving data that can then be scaled massively to downstream clients who need the data. As seen in Figure 3-1, object storage is deployed into “buckets” (ourcompany-bucket in the diagram), which store objects in a flat namespace, though separators in the key such as / can allow end users to organize and interact with objects in a nested fashion.
Get Open Source Data Pipelines for Intelligent Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

