Chapter 4. Deep Learning Basics
In this chapter we will cover the basics of deep learning. The goal of this chapter is to create a foundation for us to discuss how to apply deep learning to NLP. There are new deep learning techniques being developed every month, and we will cover some of the newer techniques in later chapters, which is why we need this foundation. In the beginning of this chapter we will cover some of the history of the artificial neural network, and we will work through some example networks representing logical operators. This will help us build a solid foundation for thinking about artificial neural networks.
Fundamentally, deep learning is a field of study of artificial neural networks, or ANNs. The first appearance of artificial neural networks in academic literature was in a paper called A Logical Calculus of the Ideas Immanent in Nervous Activity, by Warren S. McCulloch and Walter Pitts in 1943. Their work was an attempt to explain how the brain worked from a cyberneticist perspective. Their work would become the root of modern neuroscience and modern artificial neural networks.
An ANN is a biologically inspired algorithm. ANNs are not realistic representations of how a brain learns, although from time to time news stories still hype this. We are still learning many things about how the brain processes information. As new discoveries are made, there is often an attempt to represent real neurological structures and processes in terms of ANNs, like the concept of receptive fields inspiring convolutional neural networks. Despite this, it cannot be overstated how far we are from building an artificial brain.
In 1957, Frank Rosenblatt created the perceptron algorithm. Initially, there were high hopes about the perceptron. When evaluating, the single layer perceptron does the following:
- inputs,
- Each input is multiplied by a weight,
- These products are then summed with the bias term,
-
This sum is then run through an activation function, which returns 0 or 1,
- The Heaviside step function, , is often used
This can also be expressed through linear algebra.
This can be visualized with the diagram in Figure 4-1.
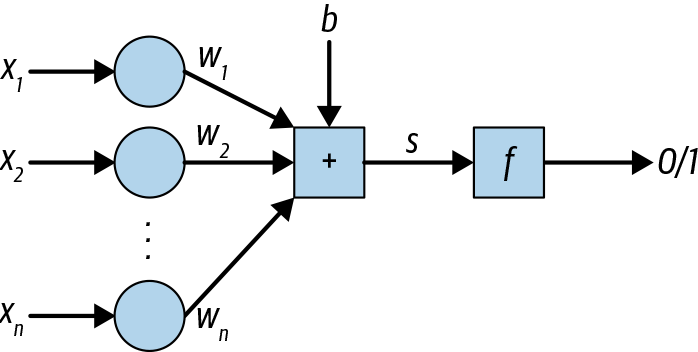
Figure 4-1. Perceptron
In 1969, Marvin Minsky and Seymour Papert showed the limitations of the algorithm. The perceptron could not represent the exclusive “or” operator XOR. The difficulty here is that a simple perceptron cannot solve problems that do not have linear separability. In terms of binary classification, a linearly separable problem is one in which the two classes can be separated by a single line, or plane in higher dimensions. To better understand this in terms of neural networks, let’s look at some examples.
We will try and create some perceptrons representing logical functions by hand, to explore the XOR problem. Imagine that we want to train networks to perform some basic logical functions. The inputs will be 0s and 1s.
If we want to implement the NOT operator, what would we do? In this case, there is no . We want the following function:
This gives us two equations to work with.
So let’s see if we can find values that satisfy these equations.
So we know b must be positive.
So must be a negative number less than . An infinite number of values fit this, so the perceptron can easily represent NOT.
Now let’s represent the OR operator. This requires two inputs. We want the following function:
We have a few more equations here; let’s start with the last case.
So must be negative. Now let’s handle the second case.
So must be larger than , and so it is a positive number. The same will work for case 3. For case 1, if and then . So again, there are an infinite number of values. A perceptron can represent .
Let’s look at now.
So we have four equations:
Cases 2 to 4 are the same as for , so this implies the following:
However, when we look at case 1, it falls apart. We cannot add the two weights, either of which are larger than to and get a negative number. So XOR is not representable with the perceptron. In fact, the perceptron can solve only linearly separable classification problems. Linearly separable problems are problems that can be solved by drawing a single line (or plane for higher dimensions). XOR is not linearly separable.
However, this problem can be solved by having multiple layers, but this was difficult given the computational capability of the time. The limitations of the single-layer perceptron network caused research to turn toward other machine-learning approaches. In the 1980s there was renewed interest when hardware made multilayer perceptron networks more feasible (see Figure 4-2).
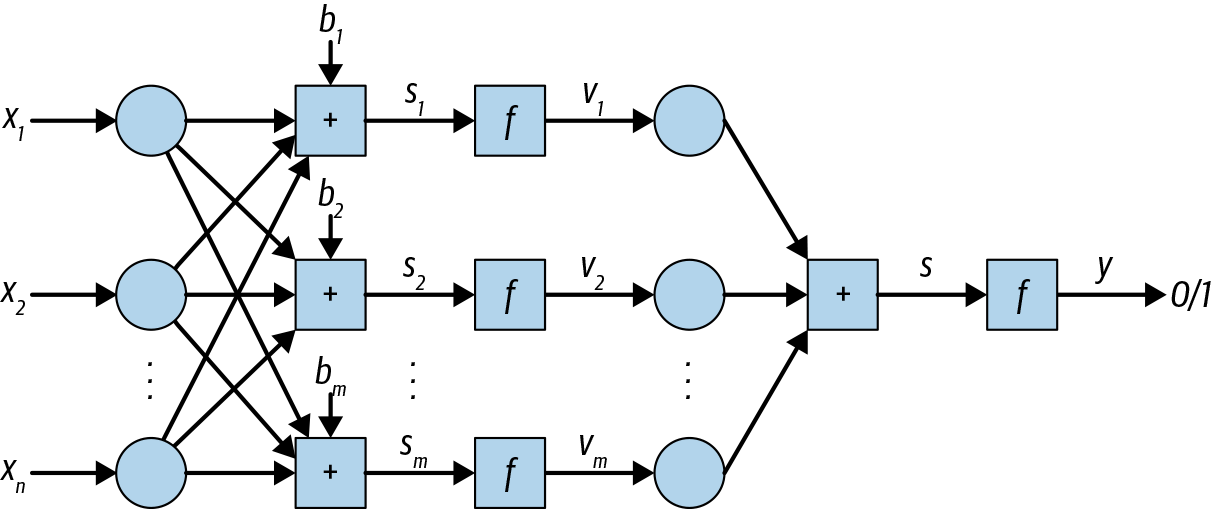
Figure 4-2. Multilayer perceptron
Now that we are dealing with modern neural networks there are some more options for us to consider:
- The output is not necessarily 0 or 1. It could be real valued, or even a vector of values.
- There are several activation functions to choose from.
- Now that we have hidden layers, we will have a matrix of weights between each layer.
Look at how we would calculate the output for a neural network with one hidden layer:
We could repeat this for many layers if we wish. And now that we have hidden layers, we’re going to have a lot more parameters—so solving for them by hand won’t do. We are going to need to talk about gradient descent and backpropagation.
Gradient Descent
In gradient descent, we start with a loss function. The loss function is a way of assigning a loss, also referred to as a cost, to an undesired output. Let’s represent our model with the function , where represents our parameters , and is an input. There are many options for a loss function; let’s use squared error for now.
Naturally, the higher the value the worse the loss. So we can also imagine this loss function as a surface. We want to find the lowest point in this surface. To find it, we start from some point and find the slope along each dimension—the gradient . We then want to adjust each parameter so that it decreases the error. So if parameter has a positive slope, we want to decrease the parameter, and if it has a negative slope we want to increase the parameter. So how do we calculate the gradient? We take the partial derivative for each parameter.
We calculate partial derivatives for \theta_i by holding the other parameters constant and taking the derivative with respect to . This will give us the slope for each parameter. We can use these slopes to update the parameters by subtracting the slope from the parameter value.
If we overcorrect a parameter we might overshoot the minimal point, but the weaker our updates, the slower we learn from examples. To control the learning rate we use a hyperparameter. I’ll use for this learning rate, but you may also see it represented by other characters (often Greek). The update looks like this:
If we do this for each example, training on a million examples will take a prohibitively long time, so let’s use an error function based on a batch of examples—a mean squared error.
The gradient is a linear operator, so we can distribute it under the sum.
This will change if you use a different loss function. We will go over loss functions as we come across them in the rest of the book. The value of will depend on your model. If it is a neural network, it will depend on your activation function.
Backpropagation
Backpropagation is an algorithm for training neural networks. It is essentially an implementation of chain rule from calculus. To talk about backpropagation, we must first talk about forward propagation.
To build a solid intuition, we will proceed with two parallel descriptions of neural networks: mathematical and numpy. The mathematical description will help us understand what is happening on a theoretical level. The numpy description will help us understand how this can be implemented.
We will again be using the Iris data set. This data is really too small for a realistic use of deep learning, but it will help us explore backpropagation. Let’s remind ourselves about the Iris data set (see Table 4-1).
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from scipy.special import softmax
df = pd.read_csv('data/iris/iris.data', names=[
'sepal_length',
'sepal_width',
'petal_length',
'petal_width',
'class',
])
df.head()
| sepal_length | sepal_width | petal_length | petal_width | class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
Now, let’s define our network.
We know we will have 4 inputs (the number of our features), so our input layer has a length of 4. There are 3 outputs (the number of our classes), so our output layer must have a length of 3. We do whatever we want for the layers in between, and we will use 6 and 5 for the first and second hidden layers, respectively. A lot of research has gone into how to construct your network. You will likely want to explore research for different use cases and approaches. As is so common in NLP and machine learning in general, one size does not fit all.
layer_sizes = [4, 6, 5, 3]
We will define our inputs, X, and our labels, Y. We one-hot encode the classes. In short, one-hot encoding is when we represent a categorical variable as a collection of binary variables. Let’s look at the one-hot–encoded DataFrame. The results are in Tables 4-2 and 4-3.
X = df.drop(columns=['class']) Y = pd.get_dummies(df['class'])
X.head()
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
Y.head()
| Iris-setosa | Iris-versicolor | Iris-virginica | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 |
As we can see, each possible value of the class column has become a column itself. For a given row, if the value of class was, say, iris-versicolor, then the iris-versicolor column will have value 1, and the others will have 0.
In mathematical terms, this is what our network looks like:
There are many ways to initialize parameters. It might seem easy to set all the parameters to 0, but this does not work. If all the weights are 0, then the output of forward propagation is unaffected by the input, making learning impossible. Here, we will be randomly initializing them. If you want to learn about more sophisticated initialization techniques, there are links in the “Resources”. We can, however, set the bias terms to 0, since they are not associated with an input.
np.random.seed(123)
W_1 = np.random.randn(layer_sizes[1], layer_sizes[0])
b_1 = np.zeros((layer_sizes[1], 1))
f_1 = np.tanh
W_2 = np.random.randn(layer_sizes[2], layer_sizes[1])
b_2 = np.zeros((layer_sizes[2], 1))
f_2 = np.tanh
W_3 = np.random.randn(layer_sizes[3], layer_sizes[2])
b_3 = np.zeros((layer_sizes[3], 1))
f_3 = lambda H: np.apply_along_axis(softmax, axis=0, arr=H)
layers = [
(W_1, b_1, f_1),
(W_2, b_2, f_2),
(W_3, b_3, f_3),
]
Now, we will implement forward propagation.
Mathematically, this is what our network is doing:
The following code shows how forward propagation works with an arbitrary number of layers. In this function, X is the input (one example per row). The argument layers is a list of weight matrix, bias term, and activation function triplets.
def forward(X, layers):
V = X.T
Hs = []
Vs = []
for W, b, f in layers:
H = W @ V
H = np.add(H, b)
Hs.append(H)
V = f(H)
Vs.append(V)
return V, Hs, Vs
Now we need to talk about our loss function. As we described previously, the loss function is the function we use to calculate how the model did on a given batch of data. We will be using log-loss.
The symbol ∘ represents elementwise multiplication, also known as the Hadamard product. The following function safely calculates the log-loss. We need to make sure that our predicted probabilities are between 0 and 1, but neither 0 nor 1. This is why we need the eps argument.
def log_loss(Y, Y_hat, eps=10**-15):
# we need to protect against calling log(0), so we seet an
# epsilon, and define our predicted probabilities to be between
# epsilon and 1 - epsilon
min_max_p = np.maximum(np.minimum(Y_hat, 1-eps), eps)
log_losses = -np.sum(np.multiply(np.log(min_max_p), Y), axis=0)
return np.sum(log_losses) / Y.shape[1]
Y_hat, Hs, Vs = forward(X, layers) loss = log_loss(Y.T, Y_hat) loss
1.4781844247149367
Now we see how forward propagation works and how to calculate the loss. To use gradient descent, we need to be able to calculate the gradient of the loss with respect to the individual parameters.
The combination of log-loss and softmax gives us a friendly expression for .
The gradient for the bias term is derived in the same way. Instead of taking the output from the earlier layer, it is multiplied (dot product) by a vector of all 1s.
Let’s see what this looks like in code. We will use names that parallel the mathematical terms. First we can define . We need to remember to transpose Y, so it has the same dimensions as Y_hat.
Let’s look at the gradient values for (see Table 4-4).
dL_dH_3 = Y_hat - Y.values.T dH_3_dW_3 = Vs[1] dL_dW_3 = (1 / len(Y)) * dL_dH_3 @ dH_3_dW_3.T print(dL_dW_3.shape) dL_dW_3
dH_3_db_3 = np.ones(len(Y)) dL_db_3 = (1 / len(Y)) * dL_dH_3 @ dH_3_db_3 print(dL_db_3.shape) dL_db_3
Let’s look a layer further. To calculate the gradient for the , we will need to continue applying the chain rule. As you can see, this derivation gets complicated quickly.
We know part of this.
We can calculate this. Notice here that we need to keep track of intermediate values. Use these values returned from the forward propagation step.
dH_3_dV_2 = W_3 dV_2_dH_2 = 1 - np.power(Vs[1], 2) dH_2_dW_2 = Vs[0] dL_dH_2 = np.multiply((dL_dH_3.T @ dH_3_dV_2).T, dV_2_dH_2) dL_dW_2 = (1 / len(Y)) * dL_dH_2 @ dH_2_dW_2.T print(dL_dW_2.shape) dL_dW_2
For the bias term it is similar (see Table 4-7).
dH_2_db_2 = np.ones(len(Y)) dL_db_2 = (1 / len(Y)) * dL_dH_2 @ dH_2_db_2.T print(dL_db_2.shape) dL_db_2
I’ll leave deriving the next layer as an exercise. It should be straightforward because layer 1 is so similar to layer 2 (see Tables 4-8 and 4-9).
dH_2_dV_1 = W_2 dV_1_dH_1 = 1 - np.power(Vs[0], 2) dL_dH_1 = np.multiply((dL_dH_2.T @ dH_2_dV_1).T, dV_1_dH_1) dH_1_dW_1 = X.values.T dL_dW_1 = (1 / len(Y)) * dL_dH_1 @ dH_1_dW_1.T print(dL_dW_1.shape) dL_dW_1
Convolutional Neural Networks
In 1959 David H. Hubel and Torsten Wiesel conducted experiments on cats that showed the existence of specialized neurons that detected edges, position, and motion. This inspired Kunihiko Fukushima to create the “cognitron” in 1975 and later the “neocognitron” in 1980. This neural network, and others based on it, included early notions of pooling layers and filters. In 1989, the modern convolutional neural network, or CNN, with weights learned fully by backpropagation, was created by Yann LeCun.
Generally, CNNs are explained with images as an example, but it’s just as easy to apply these techniques to one-dimensional data.
Filters
Filters are layers that take a continuous subset of the previous layer (e.g., a block of a matrix) and feed it into a neuron in the next layer. This technique is inspired by the idea of a receptive field in the human eye, where different neurons are responsible for different regions and shapes in vision.
Imagine you have a matrix coming into a layer. We can use a filter of size to feed into 9 neurons. We do this by doing an element-wise multiplication between a subsection of the input matrix and the filter and then summing the products. In this example we use elements (1,1) to (4,4) with the filter for the first element of the output vector. We then multiply the elements (1,2) to (4,5) with the filter for the second element. We can also change the stride, which is the number of columns/rows for which we move the filter for each output neuron. If we have our matrix with filter and a stride of 2, we can feed into 4 neurons. With padding, we can add extra rows and columns of 0s to our input matrix, so that the values at the edge get the same treatment as the interior values. Otherwise, elements on the edge are used less than inner elements.
Pooling
Pooling works similarly to filters—except, instead of using weights that must be learned, simple aggregate is used. Max pooling, taking the max of the continuous subset, is the most commonly used. Though, one can use average pooling or other aggregates.
This is often useful for reducing the size of the input data without adding new parameters.
Recurrent Neural Networks
In the initial research into modeling biological neural networks, it has been assumed that memory and learning have some dependence on time. However, none of the techniques covered so far take that into account.
In a multilayer perceptron, we get one example and produce one output. The forward propagation step for one example is not affected by another example. In a recurrent neural network, or RNN, we need to be aware of the previous, and sometimes later, examples. For example, if I am trying to translate a word, it is important that I know its context.
Now, the most common type of RNN uses long short-term memory, or LSTM. To understand LSTMs, let’s talk about some older techniques.
Backpropagation Through Time
The primary training algorithm for RNNs is backpropagation through time, or BPTT. This works by unfolding the network. Let’s say we have a sequence of k items. Conceptually, unfolding works by copying the recurrent part of the network k times. Practically, it works by calculating the partial derivate of each intermediate output with respect to the parameters of the recurrent part of the network.
We will go through BPTT in depth in Chapter 8 when we cover sequence modeling.
Elman Nets
Also known as simple RNNs, or SRNNs, an Elman network reuses the output of the previous layer. Jeffrey Elman invented the Elman network in 1990. The idea is relatively straightforward. We want the output of the previous example to represent the context. We combine that output with current input, using different weights.
As you can see, the context is represented by . This will provide information from all previous elements in the sequence to some degree. This means that the longer the sequence, the more terms there are in the gradient for the parameters. This can make the parameters change chaotically. To reduce this concern, we could use a much smaller learning rate at the cost of increased training time. We still have the chance of a training run resulting in exploding or vanishing gradients. Exploding/vanishing gradients are when the gradients for a parameter increase rapidly or go to 0. This problem can occur in any sufficiently deep network, but RNNs are particularly susceptible.
For long sequences, this could make our gradient go very high or very low quickly.
LSTMs
The LSTM was invented by Sepp Hochreiter and Jürgen Schmidhuber in 1997 to address the exploding/vanishing gradients problem. The idea is that we can learn how long to hold on to information by giving our recurrent units state. We can store an output produced from an element of the sequence and use this to modify the output. This state can also be connected with a notion of forgetting, so we can allow some gradients to vanish when appropriate. Here are the components of the LSTM:
There is a lot to unpack here. We will go into more depth, including covering variants, when we get to Chapter 8, in which we present a motivating example.
Exercise 2
A common exercise when studying deep learning is to implement a classifier on the Modified National Institute of Standards and Technology (MNST) data set. This classifier takes in an image of a handwritten digit and predicts which digit it represents.
There are thousands of such tutorials available, so I will not retread that overtrodden ground. I recommend doing the TensorFlow tutorial.
Resources
- Andrew Ng’s Deep Learning Specialization: this course is a great way to become familiar with deep learning concepts.
- TensorFlow tutorials: TensorFlow has a number of great resources. Their tutorials are a way to get familiar with deep learning and the TensorFlow API.
- Deep Learning, by Ian Goodfellow, Yoshua Bengio, and Aaron Courville (MIT Press): this is a free online book that goes over the theory of deep learning.
- Natural Language Processing with PyTorch, by Delip Rao and Brian McMahan (O’Reilly)
- This book covers NLP with PyTorch, which is another popular deep learning library. This book won’t cover PyTorch, but if you want to have a good understanding of the field, learning about PyTorch is a good idea.
- Hands-On Machine Learning with Scikit-Learn, Keras and TensorFlow, by Aurélien Géron (O’Reilly)
Get Natural Language Processing with Spark NLP now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

