Capítulo 1. Arquitectura de MySQL
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Las características arquitectónicas de MySQL lo hacen útil para una amplia gama de propósitos. Aunque no es perfecto, es lo suficientemente flexible como para funcionar bien tanto en entornos pequeños como grandes. Éstos van desde un sitio web personal hasta aplicaciones empresariales a gran escala. Para sacar el máximo partido de MySQL, debes comprender su diseño para poder trabajar con él, no contra él.
Este capítulo proporciona una visión general de alto nivel de la arquitectura del servidor MySQL, las principales diferencias entre los motores de almacenamiento y por qué son importantes esas diferencias. Hemos intentado explicar MySQL simplificando los detalles y mostrando ejemplos. Este debate será útil tanto para los que se inician en los servidores de bases de datos como para los lectores expertos en otros servidores de bases de datos.
Arquitectura lógica de MySQL
Una buena imagen mental de cómo funcionan juntos los componentes de MySQL te ayudará a entender el servidor. La Figura 1-1 muestra una vista lógica de la arquitectura de MySQL.
La capa superior, clientes, contiene los servicios que no son exclusivos de MySQL. Son servicios que necesitan la mayoría de las herramientas cliente/servidor o servidores basados en red: gestión de conexiones, autenticación, seguridad, etc.
La segunda capa es donde las cosas se ponen interesantes. Gran parte del cerebro de MySQL está aquí, incluido el código para el análisis sintáctico de consultas, el análisis, la optimización y todas las funciones incorporadas (por ejemplo, fechas, horas, matemáticas y cifrado). Cualquier funcionalidad proporcionada a través de los motores de almacenamiento vive en este nivel: procedimientos almacenados, desencadenadores y vistas, por ejemplo.
La tercera capa contiene los motores de almacenamiento. Son los responsables de almacenar y recuperar todos los datos almacenados "en" MySQL. Al igual que los distintos sistemas de archivos disponibles para GNU/Linux, cada motor de almacenamiento tiene sus propias ventajas e inconvenientes. El servidor se comunica con ellos a través de la API del motor de almacenamiento. Esta API oculta las diferencias entre los motores de almacenamiento y las hace en gran medida transparentes en la capa de consulta. También contiene un par de docenas de funciones de bajo nivel que realizan operaciones como "iniciar una transacción" o "recuperar la fila que tiene esta clave primaria". Los motores de almacenamiento no analizan SQL1 ni se comunican entre sí; simplemente responden a las peticiones del servidor.
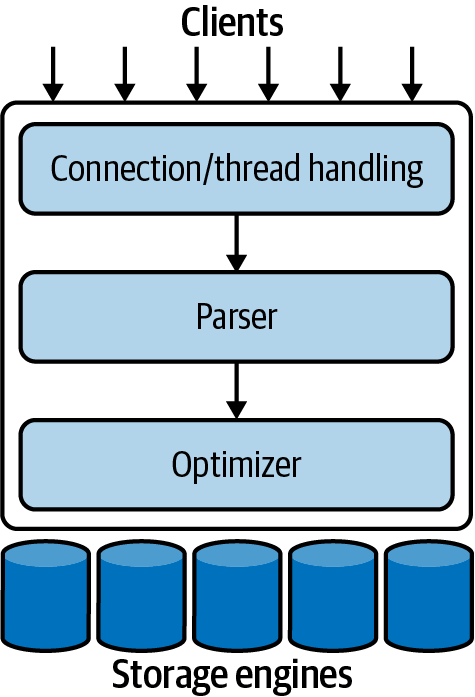
Figura 1-1. Una vista lógica de la arquitectura del servidor MySQL
Gestión y seguridad de la conexión
Por defecto en, cada conexión de cliente tiene su propio hilo dentro del proceso del servidor. Las consultas de la conexión se ejecutan dentro de ese único hilo, que a su vez reside en un núcleo o CPU. El servidor mantiene una caché de hilos listos para usar, de modo que no es necesario crearlos y destruirlos para cada nueva conexión.2
Cuando los clientes (aplicaciones) de se conectan al servidor MySQL, el servidor necesita autenticarlos. La autenticación se basa en el nombre de usuario, el host de origen y la contraseña. También se pueden utilizar certificados X.509 en una conexión de Seguridad de la Capa de Transporte (TLS). Una vez que el cliente se ha conectado, el servidor comprueba si tiene privilegios para cada consulta que emite (por ejemplo, si el cliente está autorizado a emitir una sentencia SELECT que acceda a la tabla Country de la base de datos world ).
Optimización y ejecución
MySQL analiza las consultas de para crear una estructura interna (el árbol de análisis) y luego aplica una serie de optimizaciones. Éstas pueden incluir la reescritura de la consulta, la determinación del orden en que leerá las tablas, la elección de los índices que utilizará, etc. Puedes pasar pistas al optimizador a través de palabras clave especiales en la consulta, afectando a su proceso de toma de decisiones. También puedes pedir al servidor que te explique diversos aspectos de la optimización. Esto te permite saber qué decisiones está tomando el servidor y te da un punto de referencia para reelaborar consultas, esquemas y configuraciones para que todo funcione de la forma más eficiente posible. Hay más detalles sobre esto en el Capítulo 8.
Al optimizador de no le importa realmente qué motor de almacenamiento utiliza una tabla concreta, pero el motor de almacenamiento sí afecta al modo en que el servidor optimiza la consulta. El optimizador pregunta al motor de almacenamiento por algunas de sus capacidades y por el coste de determinadas operaciones, así como por estadísticas sobre los datos de la tabla. Por ejemplo, algunos motores de almacenamiento admiten tipos de índices que pueden ser útiles para determinadas consultas. Puedes leer más sobre optimización de esquemas e indexación en los Capítulos 6 y 7.
En versiones anteriores, MySQL hacía uso de una caché de consultas interna para ver si podía servir los resultados desde allí. Sin embargo, al aumentar la concurrencia, la caché de consultas se convirtió en un notorio cuello de botella. A partir de MySQL 5.7.20, la caché de consultas quedó oficialmente obsoleta como característica de MySQL, y en la versión 8.0, la caché de consultas se elimina por completo. Aunque la caché de consultas ya no es una parte esencial del servidor MySQL, almacenar en caché conjuntos de resultados servidos con frecuencia es una buena práctica. Aunque queda fuera del alcance de este libro, un patrón de diseño popular es almacenar datos en caché en memcached o Redis.
Control de concurrencia
Cualquier vez que más de una consulta necesite cambiar datos al mismo tiempo, surge el problema del control de concurrencia. Para nuestros propósitos en este capítulo, MySQL tiene que hacerlo a dos niveles: el nivel del servidor y el nivel del motor de almacenamiento. Te daremos una visión simplificada de cómo MySQL trata con lectores y escritores concurrentes, para que tengas el contexto que necesitas para el resto de este capítulo.
Para ilustrar cómo gestiona MySQL el trabajo concurrente sobre el mismo conjunto de datos, utilizaremos como ejemplo un archivo de hoja de cálculo tradicional. Una hoja de cálculo consta de filas y columnas, de forma muy parecida a una tabla de base de datos. Supón que el archivo está en tu portátil y que sólo tú tienes acceso a él. No hay conflictos potenciales; sólo tú puedes hacer cambios en el archivo. Ahora, imagina que necesitas colaborar con un compañero de trabajo en esa hoja de cálculo. Ahora está en un servidor compartido al que ambos tenéis acceso. ¿Qué ocurre cuando ambos necesitáis hacer cambios en ese archivo al mismo tiempo? ¿Y si tenemos a todo un equipo de personas intentando activamente editar, añadir y eliminar celdas de esta hoja de cálculo? Podemos decir que se turnen para hacer cambios, pero eso no es eficaz. Necesitamos un enfoque que permita el acceso concurrente a una hoja de cálculo de gran volumen.
Cerraduras de lectura/escritura
Leer desde la hoja de cálculo no es tan problemático. No hay nada malo en que varios clientes lean el mismo archivo simultáneamente; como no están haciendo cambios, es probable que nada vaya mal. ¿Qué ocurre si alguien intenta borrar la celda A25 mientras otros están leyendo la hoja de cálculo? Depende, pero un lector podría salir con una visión corrupta o incoherente de los datos. Así que, para estar seguros, incluso la lectura de una hoja de cálculo requiere un cuidado especial.
Si piensas en la hoja de cálculo como en una tabla de base de datos, es fácil ver que el problema es el mismo en este contexto. En muchos sentidos, una hoja de cálculo es en realidad una simple tabla de base de datos. Modificar las filas de una tabla de base de datos es muy similar a eliminar o cambiar el contenido de las celdas de un archivo de hoja de cálculo.
La solución a este problema clásico del control de la concurrencia es bastante sencilla. Los sistemas que se ocupan del acceso concurrente de lectura/escritura suelen implementar un sistema de bloqueo que consta de dos tipos de bloqueo. Estos bloqueos de suelen conocerse como bloqueos compartidos y bloqueos exclusivos, o bloqueos de lectura y bloqueos de escritura.
Sin preocuparnos por el mecanismo de bloqueo real, podemos describir el concepto de la siguiente manera. Los bloqueos de lectura en un recurso son compartidos, o mutuamente no bloqueantes: muchos clientes pueden leer de un recurso al mismo tiempo y no interferir entre sí. Los bloqueos de escritura, en por otra parte, son exclusivos -es decir, bloquean tanto los bloqueos de lectura como otros bloqueos de escritura- porque la única política segura es tener un único cliente escribiendo en el recurso en un momento dado e impedir todas las lecturas cuando un cliente está escribiendo.
En el mundo de las bases de datos, el bloqueo ocurre todo el tiempo: MySQL tiene que impedir que un cliente lea un dato mientras otro lo está modificando. Si un servidor de bases de datos tiene un rendimiento aceptable, esta gestión de bloqueos es lo suficientemente rápida como para no ser perceptible para los clientes. En el Capítulo 8 veremos cómo ajustar tus consultas para evitar los problemas de rendimiento causados por los bloqueos.
Granularidad de bloqueo
Una forma de mejorar la concurrencia de un recurso compartido es ser más selectivo con lo que bloqueas. En lugar de bloquear todo el recurso, bloquea sólo la parte que contiene los datos que necesitas cambiar. Mejor aún, bloquea sólo la parte exacta de los datos que piensas cambiar. Minimizar la cantidad de datos que bloqueas en un momento dado permite que los cambios en un determinado recurso se produzcan simultáneamente, siempre que no entren en conflicto entre sí.
Por desgracia, los bloqueos no son gratuitos: consumen recursos. Cada operación de bloqueo -obtener un bloqueo, comprobar si un bloqueo está libre, liberar un bloqueo, etc.- tiene una sobrecarga. Si el sistema pasa demasiado tiempo gestionando bloqueos en lugar de almacenando y recuperando datos, el rendimiento puede verse afectado.
Una estrategia de bloqueo es un compromiso entre la sobrecarga de los bloqueos y la seguridad de los datos, y ese compromiso afecta al rendimiento. La mayoría de los servidores de bases de datos comerciales no te dan muchas opciones: obtienes lo que se conoce como bloqueo a nivel de fila en tus tablas, con una variedad de formas, a menudo complejas, de ofrecer un buen rendimiento con muchos bloqueos. Los bloqueos son la forma en que las bases de datos implementan las garantías de coherencia. Un operador experto de una base de datos tendría que llegar incluso a leer el código fuente para determinar el conjunto más adecuado de configuraciones de ajuste para optimizar este compromiso de velocidad frente a seguridad de los datos.
MySQL, en cambio, sí ofrece opciones. Sus motores de almacenamiento pueden implementar sus propias políticas de bloqueo y granularidades de bloqueo. La gestión de los bloqueos es una decisión muy importante en el diseño de los motores de almacenamiento; fijar la granularidad en un determinado nivel puede mejorar el rendimiento para ciertos usos, pero hacer que ese motor sea menos adecuado para otros fines. Dado que MySQL ofrece múltiples motores de almacenamiento, no requiere una única solución de uso general. Veamos las dos estrategias de bloqueo más importantes.
Cerraduras de mesa
La estrategia de bloqueo más básica disponible en MySQL, y la de menor sobrecarga, son los bloqueos de tabla. Un bloqueo de tabla es análogo a los bloqueos de hoja de cálculo descritos anteriormente: bloquea toda la tabla. Cuando un cliente desea escribir en una tabla (insertar, eliminar, actualizar, etc.), adquiere un bloqueo de escritura. Esto mantiene a raya todas las demás operaciones de lectura y escritura. Cuando nadie escribe, los lectores pueden obtener bloqueos de lectura, que no entran en conflicto con otros bloqueos de lectura.
Los bloqueos de tabla tienen variaciones para mejorar el rendimiento en situaciones específicas. Por ejemplo, los bloqueos de tabla READ LOCAL permiten algunos tipos de operaciones de escritura concurrentes. Las colas de bloqueos de escritura y lectura están separadas, siendo la cola de escritura totalmente más prioritaria que la cola de lectura.3
Bloqueos de filas
El estilo de bloqueo de que ofrece la mayor concurrencia (y conlleva la mayor sobrecarga) es el uso de bloqueos de fila. Volviendo a la analogía de la hoja de cálculo, los bloqueos de fila serían lo mismo que bloquear sólo la fila de la hoja de cálculo. Esta estrategia permite que varias personas editen diferentes filas simultáneamente sin bloquearse unas a otras. Esto permite al servidor realizar más escrituras simultáneas, pero el coste es una mayor sobrecarga al tener que hacer un seguimiento de quién tiene cada bloqueo de fila, cuánto tiempo lleva abierto y qué tipo de bloqueo de fila es, así como limpiar los bloqueos cuando ya no se necesitan.
Los bloqueos de fila se implementan en el motor de almacenamiento, no en el servidor. El servidor desconoce4 desconoce los bloqueos implementados en los motores de almacenamiento y, como verás más adelante en este capítulo y a lo largo del libro, todos los motores de almacenamiento implementan los bloqueos a su manera.
Transacciones
En no puedes examinar las características más avanzadas de un sistema de bases de datos durante mucho tiempo antes de que entren en juego las transacciones. Una transacción es un grupo de sentencias SQL que se tratan atómicamente, como una única unidad de trabajo. Si el motor de la base de datos puede aplicar todo el grupo de sentencias a una base de datos, lo hace, pero si alguna de ellas no puede realizarse por un fallo u otro motivo, no se aplica ninguna. Es todo o nada.
Poco de esta sección es específico de MySQL. Si ya estás familiarizado con las transacciones ACID, puedes pasar directamente a "Transacciones en MySQL".
Una aplicación bancaria es el ejemplo clásico de por qué son necesarias las transacciones.5 Imagina una base de datos bancaria con dos tablas: cuenta corriente y cuenta de ahorro. Para mover 200 $ de la cuenta corriente de Juana a su cuenta de ahorro, tienes que realizar al menos tres pasos:
-
Asegúrate de que el saldo de su cuenta corriente es superior a 200 $.
-
Resta 200 $ del saldo de su cuenta corriente.
-
Añade 200 $ al saldo de su cuenta de ahorro.
Toda la operación debe estar envuelta en una transacción, de modo que si falla alguno de los pasos, se puedan revertir todos los pasos completados.
En inicias una transacción con la sentencia START TRANSACTION y luego haces permanentes sus cambios con COMMIT o descartas los cambios con ROLLBACK. Así que el SQL de nuestra transacción de ejemplo podría tener este aspecto:
1 START TRANSACTION; 2 SELECT balance FROM checking WHERE customer_id = 10233276; 3 UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276; 4 UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276; 5 COMMIT;
Las transacciones por sí solas no lo son todo. ¿Qué ocurre si el servidor de la base de datos se bloquea mientras se ejecuta la línea 4? ¿Quién sabe? Probablemente el cliente acaba de perder 200 $. ¿Y si aparece otro proceso entre las líneas 3 y 4 y elimina todo el saldo de la cuenta corriente? El banco le ha dado al cliente un crédito de 200 $ sin ni siquiera saberlo.
Y hay muchas más posibilidades de fallo en esta secuencia de operaciones. Podrías ver caídas de conexión, tiempos de espera o incluso un fallo del servidor de base de datos que las ejecuta a mitad de las operaciones. Normalmente, ésta es la razón por la que existen los complejos y lentos sistemas de compromiso en dos fases: para mitigar todo tipo de escenarios de fallo.
Las transacciones no son suficientes a menos que el sistema supere la prueba ACID. ACID significa atomicidad, consistencia, aislamiento y durabilidad. Son criterios estrechamente relacionados que debe cumplir un sistema de procesamiento de transacciones seguro para los datos:
- Atomicidad
- Una transacción debe funcionar como una única unidad indivisible de trabajo, de modo que toda la transacción se aplique o no se comprometa nunca. Cuando las transacciones son atómicas, no existe la transacción parcialmente completada: es todo o nada.
- Coherencia
- La base de datos debe pasar siempre de un estado coherente al siguiente. En nuestro ejemplo, la coherencia garantiza que un choque entre las líneas 3 y 4 no provoque la desaparición de 200 $ de la cuenta corriente. Si la transacción nunca se consigna, ninguno de los cambios de la transacción se reflejará nunca en la base de datos.
- Aislamiento
- Los resultados de una transacción suelen ser invisibles para otras transacciones hasta que ésta se completa. Esto garantiza que si un resumen de cuenta bancaria se ejecuta después de la línea 3 pero antes de la 4 en nuestro ejemplo, seguirá viendo los 200 $ de la cuenta corriente. Cuando hablemos de los niveles de aislamiento más adelante en este capítulo, entenderás por qué hemos dicho "normalmente invisibles".
- Durabilidad
- Una vez confirmados, los cambios de una transacción son permanentes. Esto significa que los cambios deben quedar registrados de forma que los datos no se pierdan en caso de caída del sistema. Sin embargo, la durabilidad es un concepto ligeramente difuso, porque en realidad hay muchos niveles. Algunas estrategias de durabilidad ofrecen una garantía de seguridad mayor que otras, y nunca nada es 100% duradero (si la propia base de datos fuera realmente duradera, ¿cómo podrían aumentar la durabilidad las copias de seguridad?)
Las transacciones ACID y las garantías que ofrecen en el motor InnoDB en concreto son una de las características más sólidas y maduras de MySQL. Aunque conllevan ciertas compensaciones de rendimiento, cuando se aplican adecuadamente pueden ahorrarte la implementación de una gran cantidad de lógica compleja en la capa de aplicación.
Niveles de aislamiento
Aislamiento es más complejo de lo que parece. La norma ANSI SQL define cuatro niveles de aislamiento. Si eres nuevo en el mundo de las bases de datos, te recomendamos que te familiarices con el estándar general de ANSI SQL6 antes de volver a leer sobre la implementación específica de MySQL. El objetivo de esta norma es definir las reglas sobre qué cambios son y no son visibles dentro y fuera de una transacción. Los niveles de aislamiento más bajos suelen permitir una mayor concurrencia y tienen una menor sobrecarga.
Nota
Cada motor de almacenamiento implementa los niveles de aislamiento de forma ligeramente distinta, y no coinciden necesariamente con lo que podrías esperar si estás acostumbrado a otro producto de base de datos (por eso, no entraremos en detalles exhaustivos en esta sección). Debes leer los manuales de los motores de almacenamiento que decidas utilizar.
Echemos un vistazo rápido a los cuatro niveles de aislamiento:
READ UNCOMMITTED- En el nivel de aislamiento
READ UNCOMMITTED, las transacciones pueden ver los resultados de las transacciones no comprometidas. En este nivel pueden surgir muchos problemas, a menos que sepas muy, muy bien lo que haces y tengas una buena razón para hacerlo. Este nivel se utiliza raramente en la práctica porque su rendimiento no es mucho mejor que el de los otros niveles, que tienen muchas ventajas. La lectura de datos no comprometidos también se conoce como lectura sucia. READ COMMITTED- El nivel de aislamiento por defecto de para la mayoría de los sistemas de bases de datos (¡pero no para MySQL!) es
READ COMMITTED. Satisface la sencilla definición de aislamiento utilizada anteriormente: una transacción seguirá viendo los cambios realizados por las transacciones que se hayan consignado después de que ella comenzara, y sus cambios no serán visibles para los demás hasta que se haya consignado. Este nivel sigue permitiendo lo que se conoce como lectura no repetible. Esto significa que puedes ejecutar la misma sentencia dos veces y ver datos diferentes. REPEATABLE READ-
REPEATABLE READresuelve los problemas que permiteREAD UNCOMMITTED. Garantiza que todas las filas que lea una transacción "tendrán el mismo aspecto" en las lecturas posteriores dentro de la misma transacción, pero en teoría sigue permitiendo otro problema peliagudo: las lecturas fantasma. En pocas palabras, una lectura fantasma puede ocurrir cuando seleccionas un rango de filas, otra transacción inserta una nueva fila en el rango y, a continuación, vuelves a seleccionar el mismo rango; entonces verás la nueva fila "fantasma". InnoDB y XtraDB resuelven el problema de la lectura fantasma con el control de concurrencia multiversión, que explicamos más adelante en este capítulo.REPEATABLE READes el nivel de aislamiento de transacciones por defecto de MySQL. SERIALIZABLE- El nivel más alto de aislamiento de,
SERIALIZABLE, resuelve el problema de la lectura fantasma obligando a ordenar las transacciones de modo que no puedan entrar en conflicto. En pocas palabras,SERIALIZABLEcoloca un bloqueo en cada fila que lee. A este nivel, pueden producirse muchos tiempos muertos y contención de bloqueos. Rara vez hemos visto a la gente utilizar este nivel de aislamiento, pero las necesidades de tu aplicación pueden obligarte a aceptar la disminución de la concurrencia en favor de la seguridad de los datos resultante.
La Tabla 1-1 resume los distintos niveles de aislamiento y los inconvenientes asociados a cada uno de ellos.
| Nivel de aislamiento | Posibilidad de lecturas sucias | Posibilidad de lecturas no repetibles | Posible lectura fantasma | El bloqueo se lee |
|---|---|---|---|---|
READ UNCOMMITTED |
Sí | Sí | Sí | No |
READ COMMITTED |
No | Sí | Sí | No |
REPEATABLE READ |
No | No | Sí | No |
SERIALIZABLE |
No | No | No | Sí |
Bloqueos
Un bloqueo se produce cuando dos o más transacciones mantienen y solicitan mutuamente bloqueos sobre los mismos recursos, creando un ciclo de dependencias. Los bloqueos se producen cuando las transacciones intentan bloquear recursos en un orden diferente. Pueden ocurrir siempre que varias transacciones bloqueen los mismos recursos. Por ejemplo, considera estas dos transacciones que se ejecutan contra una tabla StockPrice, que tiene una clave primaria de (stock_id, date):
Transacción 1
START TRANSACTION; UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 and date = ‘2020-05-01’; UPDATE StockPrice SET close = 19.80 WHERE stock_id = 3 and date = ‘2020-05-02’; COMMIT;
Transacción 2
START TRANSACTION; UPDATE StockPrice SET high = 20.12 WHERE stock_id = 3 and date = ‘2020-05-02’; UPDATE StockPrice SET high = 47.20 WHERE stock_id = 4 and date = ‘2020-05-01’; COMMIT;
Cada transacción ejecutará su primera consulta y actualizará una fila de datos, bloqueando esa fila en el índice de clave primaria y en cualquier índice único adicional del que forme parte en el proceso. A continuación, cada transacción intentará actualizar su segunda fila, sólo para descubrir que ya está bloqueada. Las dos transacciones esperarán eternamente a que la otra se complete, a menos que algo intervenga para romper el bloqueo. En el Capítulo 7 veremos cómo la indexación puede mejorar o empeorar el rendimiento de tus consultas a medida que evoluciona tu esquema.
Para combatir este problema, los sistemas de bases de datos implementan diversas formas de detección de bloqueos y tiempos de espera. Los sistemas más sofisticados, como el motor de almacenamiento InnoDB, detectarán las dependencias circulares y devolverán un error al instante. Esto puede ser bueno, de lo contrario, los bloqueos se manifestarían como consultas muy lentas. Otros se rendirán cuando la consulta supere un tiempo de espera de bloqueo, lo que no siempre es bueno. La forma en que InnoDB gestiona actualmente los bloqueos es revertir la transacción que tenga el menor número de bloqueos de fila exclusivos (una métrica aproximada para saber cuál será la más fácil de revertir).
El comportamiento y el orden de los bloqueos son específicos del motor de almacenamiento, por lo que algunos motores de almacenamiento pueden bloquearse en una determinada secuencia de sentencias, aunque otros no lo hagan. Los bloqueos tienen una doble naturaleza: algunos son inevitables debido a verdaderos conflictos de datos, y otros están causados por el funcionamiento de un motor de almacenamiento.7
Una vez que se producen, los bloqueos no pueden romperse sin hacer retroceder una de las transacciones, parcial o totalmente. Son un hecho de la vida en los sistemas transaccionales, y tus aplicaciones deben estar diseñadas para manejarlos. Muchas aplicaciones pueden simplemente reintentar sus transacciones desde el principio, y a menos que se encuentren con otro punto muerto, deberían tener éxito.
Registro de transacciones
El registro de transacciones ayuda a que las transacciones sean más eficientes. En lugar de actualizar las tablas en disco cada vez que se produce un cambio, el motor de almacenamiento puede modificar su copia en memoria de los datos. Esto es muy rápido. A continuación, el motor de almacenamiento puede escribir un registro del cambio en el registro de transacciones, que está en el disco y, por tanto, es duradero. También es una operación relativamente rápida, porque añadir eventos al registro implica una E/S secuencial en una pequeña zona del disco, en lugar de una E/S aleatoria en muchos lugares. Luego, en algún momento posterior, un proceso puede actualizar la tabla en el disco. Así, la mayoría de los motores de almacenamiento que utilizan esta técnica (conocida como registro de escritura anticipada) acaban escribiendo los cambios en el disco dos veces.
Si se produce un fallo después de que la actualización se escriba en el registro de transacciones, pero antes de que se realicen los cambios en los propios datos, el motor de almacenamiento aún puede recuperar los cambios al reiniciarse. El método de recuperación varía según el motor de almacenamiento.
Transacciones en MySQL
Motores de almacenamiento es el software que dirige cómo se almacenarán y recuperarán los datos del disco. Aunque MySQL ha ofrecido tradicionalmente varios motores de almacenamiento que admiten transacciones, InnoDB es actualmente el estándar de oro y el motor que se recomienda utilizar. Las primitivas de transacción descritas aquí se basarán en las transacciones del motor InnoDB.
Comprender AUTOCOMITAR
Por defecto , una única sentencia INSERT, UPDATE, o DELETE se envuelve implícitamente en una transacción y se consigna inmediatamente. Esto se conoce como modo AUTOCOMMIT. Desactivando este modo, puedes ejecutar una serie de sentencias dentro de una transacción y, al concluir, COMMIT o ROLLBACK.
Puedes activar o desactivar la variable AUTOCOMMIT para la conexión actual utilizando el comando SET. Los valores 1 y ON son equivalentes, al igual que 0 y OFF. Cuando se ejecuta con AUTOCOMMIT=0, siempre estás en una transacción hasta que emites un COMMIT o ROLLBACK. MySQL inicia entonces una nueva transacción inmediatamente. Además, con AUTOCOMMIT activado, puedes iniciar una transacción multiestado utilizando la palabra clave BEGIN o START TRANSACTION. Cambiar el valor de AUTOCOMMIT no tiene ningún efecto en las tablas no transaccionales, que no tienen noción de confirmar o revertir cambios.
Ciertos comandos, cuando se emiten durante una transacción abierta, hacen que MySQL consigne la transacción antes de que se ejecuten. Suelen ser comandos DDL que realizan cambios significativos, como ALTER TABLE , pero LOCK TABLES y algunas otras sentencias también tienen este efecto. Consulta la documentación de tu versión para ver la lista completa de comandos que consignan automáticamente una transacción.
MySQLte permite establecer el nivel de aislamiento mediante el comando SET TRANSACTION ISOLATION LEVEL, que entra en vigor cuando se inicia la siguiente transacción. Puedes establecer el nivel de aislamiento para todo el servidor en el archivo de configuración o sólo para tu sesión:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
Es preferible establecer el aislamiento que más utilices a nivel de servidor y cambiarlo sólo en casos explícitos. MySQL reconoce los cuatro niveles de aislamiento estándar ANSI, e InnoDB los admite todos.
Mezclar motores de almacenamiento en las transacciones
MySQL no gestiona las transacciones a nivel de servidor. En su lugar, los motores de almacenamiento subyacentes implementan ellos mismos las transacciones. Esto significa que no puedes mezclar de forma fiable diferentes motores en una misma transacción.
Si mezclas tablas transaccionales y no transaccionales (por ejemplo, tablas InnoDB y MyISAM) en una transacción, ésta funcionará correctamente si todo va bien. Sin embargo, si se requiere una reversión, los cambios en la tabla no transaccional no se pueden deshacer. Esto deja la base de datos en un estado incoherente del que puede ser difícil recuperarse y hace que todo el sentido de las transacciones sea discutible. Por eso es realmente importante elegir el motor de almacenamiento adecuado para cada tabla y evitar a toda costa mezclar motores de almacenamiento en la lógica de tu aplicación.
Normalmente, MySQL no te advertirá ni generará errores si realizas operaciones transaccionales en una tabla no transaccional. A veces, revertir una transacción generará la advertencia "Algunas tablas modificadas no transaccionales no han podido revertirse", pero la mayoría de las veces, no tendrás ninguna indicación de que estás trabajando con tablas no transaccionales.
Advertencia
Es una buena práctica no mezclar motores de almacenamiento en tu aplicación. Las transacciones fallidas pueden dar lugar a resultados incoherentes, ya que algunas partes pueden retroceder y otras no.
Bloqueo implícito y explícito
InnoDB utiliza un protocolo de bloqueo en dos fases. Puede adquirir bloqueos en cualquier momento durante una transacción, pero no los libera hasta que se produce una COMMIT o ROLLBACK. Libera todos los bloqueos al mismo tiempo. Los mecanismos de bloqueo descritos anteriormente son todos implícitos. InnoDB gestiona los bloqueos automáticamente, según su nivel de aislamiento.
Sin embargo, InnoDB también admite el bloqueo explícito, que la norma SQL no menciona en absoluto:8, 9
SELECT ... FOR SHARE SELECT ... FOR UPDATE
MySQL también admite los comandos LOCK TABLES y UNLOCK TABLES, que se implementan en el servidor, no en los motores de almacenamiento. Si necesitas transacciones, utiliza un motor de almacenamiento transaccional. LOCK TABLES no es necesario porque InnoDB admite el bloqueo de filas.
Consejo
La interacción entre LOCK TABLES y las transacciones es compleja, y existen comportamientos inesperados en algunas versiones del servidor. Por lo tanto, te recomendamos que nunca utilices LOCK TABLES a menos que estés en una transacción y AUTOCOMMIT esté desactivado, independientemente del motor de almacenamiento que estés utilizando.
Control de concurrencia multiversión
La mayoría de de los motores de almacenamiento transaccional de MySQL no utilizan un simple mecanismo de bloqueo de filas. En su lugar, utilizan el bloqueo a nivel de fila junto con una técnica para aumentar la concurrencia conocida como control de concurrencia multiversión (MVCC). MVCC no es exclusivo de MySQL: Oracle, PostgreSQL y algunos otros sistemas de bases de datos también lo utilizan, aunque hay diferencias significativas porque no existe una norma sobre cómo debe funcionar MVCC.
Puedes pensar en MVCC como una vuelta de tuerca al bloqueo por filas; evita la necesidad de bloqueo en muchos casos y puede tener una sobrecarga mucho menor. Dependiendo de cómo se implemente, puede permitir lecturas sin bloqueo y bloquear sólo las filas necesarias durante las operaciones de escritura.
MVCC funciona utilizando instantáneas de los datos tal y como existían en un momento dado. Esto significa que las transacciones pueden ver una vista coherente de los datos, independientemente del tiempo que se ejecuten. También significa que distintas transacciones pueden ver datos diferentes en las mismas tablas ¡al mismo tiempo! Si nunca has experimentado esto antes, puede resultar confuso, pero será más fácil de entender con la familiaridad.
Cada motor de almacenamiento implementa MVCC de forma diferente. Algunas de las variaciones incluyen el control de concurrencia optimista y pesimista. Ilustramos una forma de funcionamiento de MVCC explicando el comportamiento de InnoDB10 en forma de diagrama secuencial en la Figura 1-2.
InnoDB implementa MVCC asignando un ID de transacción a cada transacción que se inicia. Ese ID se asigna la primera vez que la transacción lee algún dato. Cuando se modifica un registro dentro de esa transacción, se escribe en el registro de deshacer un registro que explica cómo revertir ese cambio, y el puntero de retroceso de la transacción apunta a ese registro del registro de deshacer. Así es como la transacción puede encontrar la forma de revertir si es necesario.
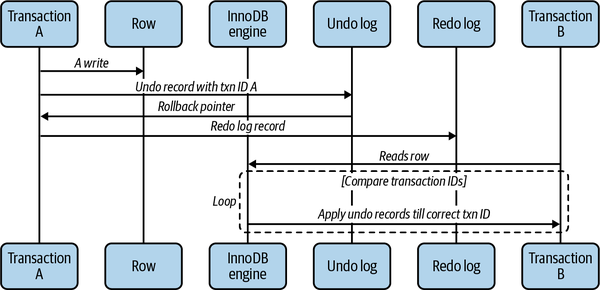
Figura 1-2. Diagrama secuencial de la gestión de varias versiones de una fila en distintas transacciones
Cuando una sesión diferente lee un registro de índice de clave de clúster, InnoDB compara el ID de transacción del registro con la vista de lectura de esa sesión. Si el registro en su estado actual no debe ser visible (la transacción que lo alteró aún no se ha comprometido), se sigue el registro de deshacer y se aplica hasta que la sesión alcanza un ID de transacción que sí puede ser visible. Este proceso puede recorrer todo el camino hasta llegar a un registro de deshacer que elimine esta fila por completo, indicando a la vista de lectura que esta fila no existe.
Los registros de una transacción se eliminan activando un bit de "eliminado" en las "banderas de información" del registro. Esto también se rastrea en el registro de deshacer como "eliminar marca de borrado".
También hay que tener en cuenta que todas las escrituras en el registro de deshacer también se registran en el registro de rehacer, porque las escrituras en el registro de deshacer forman parte del proceso de recuperación de fallos del servidor y son transaccionales.11 El tamaño de estos registros de rehacer y deshacer también desempeña un papel importante en el rendimiento de las transacciones de alta concurrencia. Trataremos su configuración con más detalle en el Capítulo 5.
El resultado de todo este mantenimiento adicional de registros es que la mayoría de las consultas de lectura nunca adquieren bloqueos. Simplemente leen los datos tan rápido como pueden, asegurándose de seleccionar sólo las filas que cumplen los criterios. Los inconvenientes son que el motor de almacenamiento tiene que almacenar más datos con cada fila, realizar más trabajo al examinar las filas y gestionar algunas operaciones de mantenimiento adicionales.
MVCC sólo funciona con los niveles de aislamiento REPEATABLE READ y READ COMMITTED. READ UNCOMMITTED no es compatible con MVCC12 porque las consultas no leen la versión de fila apropiada para su versión de transacción; leen la versión más reciente, sin importar cuál sea. SERIALIZABLE no es compatible con MVCC porque las lecturas bloquean todas las filas que devuelven.
Replicación
MySQL está diseñado para aceptar escrituras en un solo nodo en un momento dado. Esto tiene ventajas a la hora de gestionar la coherencia, pero conlleva inconvenientes cuando necesitas que los datos se escriban en varios servidores o en varias ubicaciones. MySQL ofrece una forma nativa de distribuir las escrituras que realiza un nodo a nodos adicionales. Esto se denomina replicación. En MySQL, el nodo fuente tiene un hilo por réplica que se registra como cliente de replicación que se despierta cuando se produce una escritura, enviando nuevos datos. En la Figura 1-3, mostramos un ejemplo sencillo de esta configuración, que suele denominarse árbol topológico de varios servidores MySQL en una configuración de origen y réplica.
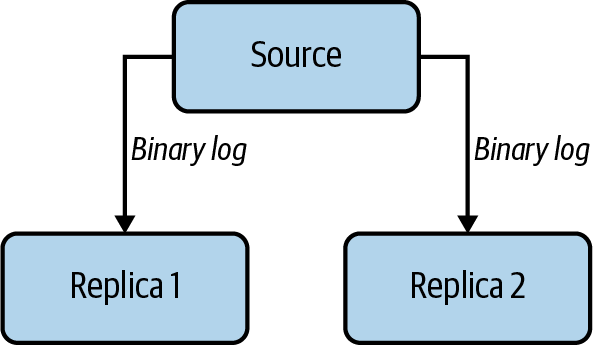
Figura 1-3. Una vista simplificada de la topología de replicación de un servidor MySQL
Para cualquier dato que ejecutes en producción, debes utilizar la replicación y tener al menos tres réplicas más, idealmente distribuidas en distintas ubicaciones (en entornos alojados en la nube, conocidas como regiones) para planificar la recuperación en caso de desastre.
A lo largo de los años, la replicación en MySQL fue ganando en sofisticación. Los identificadores de transacciones globales, la replicación multifuente, la replicación paralela en réplicas y la replicación semisincronizada son algunas de las principales actualizaciones. Cubrimos la replicación con gran detalle en el Capítulo 9.
Estructura de los archivos de datos
En versión 8.0, MySQL rediseñó los metadatos de las tablas en un diccionario de datos que se incluye con el archivo .ibd de una tabla. Esto hace que la información sobre la estructura de la tabla admita transacciones y cambios atómicos en la definición de datos. En lugar de confiar únicamente en information_schema para recuperar la definición de la tabla y los metadatos durante las operaciones, se nos presenta la caché de objetos del diccionario, que es una caché en memoria basada en el uso menos reciente (LRU) de definiciones de partición, definiciones de tabla, definiciones de programas almacenados, conjunto de caracteres e información de cotejo. Este importante cambio en la forma en que el servidor accede a los metadatos sobre las tablas reduce la E/S y es eficiente, especialmente si un subconjunto de tablas es el que ve la mayor actividad y, por tanto, está en la caché más a menudo. Los archivos .ibd y .frm se sustituyen por información de diccionario serializada (.sdi) por tabla.
El motor InnoDB
InnoDB es el motor de almacenamiento transaccional por defecto de MySQL y el más importante y útil en general. Se diseñó para procesar muchas transacciones de corta duración que suelen completarse en lugar de ser revertidas. Su rendimiento y recuperación automática de fallos lo hacen popular también para necesidades de almacenamiento no transaccional. Si quieres estudiar los motores de almacenamiento, merece la pena que estudies a fondo InnoDB para aprender todo lo que puedas sobre él, en lugar de estudiar todos los motores de almacenamiento por igual.
Nota
Es una buena práctica utilizar el motor de almacenamiento InnoDB como motor por defecto para cualquier aplicación. MySQL lo facilitó al hacer de InnoDB el motor por defecto hace unas cuantas versiones principales.
InnoDB es el motor de almacenamiento de propósito general por defecto de MySQL. Por defecto, InnoDB almacena sus datos en una serie de archivos de datos que se conocen colectivamente como tablespace. Un tablespace es esencialmente una caja negra que InnoDB gestiona por sí mismo.
InnoDB utiliza MVCC para lograr una alta concurrencia, e implementa los cuatro niveles de aislamiento estándar de SQL. Utiliza por defecto el nivel de aislamiento REPEATABLE READ , y tiene una estrategia de bloqueo de la siguiente clave que impide las lecturas fantasma en este nivel de aislamiento: en lugar de bloquear sólo las filas que has tocado en una consulta, InnoDB bloquea también los huecos en la estructura del índice, impidiendo que se inserten fantasmas.
Las tablas InnoDB se construyen sobre un índice agrupado, que trataremos en detalle en el Capítulo 8, cuando hablemos del diseño de esquemas. Las estructuras de índices de InnoDB son muy diferentes de las de la mayoría de motores de almacenamiento MySQL. Como resultado, proporciona búsquedas de claves primarias muy rápidas. Sin embargo, los índices secundarios (índices que no son la clave primaria) contienen las columnas de la clave primaria, por lo que si tu clave primaria es grande, los demás índices también lo serán. Debes procurar que la clave primaria sea pequeña si vas a tener muchos índices en una tabla.
InnoDB tiene una serie de optimizaciones internas. Entre ellas se incluyen la lectura anticipada predictiva para la obtención anticipada de datos del disco, un índice hash adaptativo que construye automáticamente índices hash en memoria para realizar búsquedas muy rápidas, y un búfer de inserción para acelerar las inserciones. Hablaremos de ellas en el Capítulo 4 de este libro.
El comportamiento de InnoDB es muy intrincado, y te recomendamos encarecidamente que leas la sección "InnoDB Locking and Transaction Model" del manual de MySQL si utilizas InnoDB. Debido a su arquitectura MVCC, hay muchas sutilezas que debes conocer antes de crear una aplicación con InnoDB. Trabajar con un motor de almacenamiento que mantiene vistas coherentes de los datos para todos los usuarios, incluso cuando algunos usuarios están cambiando los datos, puede ser complejo.
Como motor de almacenamiento transaccional, InnoDB admite copias de seguridad en línea verdaderamente "en caliente" a través de diversos mecanismos, como MySQL Enterprise Backup, propiedad de Oracle, y Percona XtraBackup, de código abierto. Hablaremos en detalle de las copias de seguridad y la restauración en el Capítulo 10.
A partir de MySQL 5.6, InnoDB introdujo DDL en línea, que al principio tenía casos de uso limitados que se ampliaron en las versiones 5.7 y 8.0. Los cambios de esquema en línea permiten realizar cambios específicos en las tablas sin un bloqueo completo de la tabla y sin utilizar herramientas externas, lo que mejora enormemente la operatividad de las tablas MySQL InnoDB. Cubriremos las opciones de cambios de esquema en línea, tanto nativas como con herramientas externas, en el Capítulo 6.
Soporte de documentos JSON
Introducido por primera vez en en InnoDB como parte de la versión 5.7, el tipo JSON llegó con la validación automática de documentos JSON, así como con un almacenamiento optimizado que permite un rápido acceso de lectura, lo que supone una mejora significativa respecto a las ventajas y desventajas del antiguo almacenamiento binario de objetos grandes (BLOB) al que solían recurrir los ingenieros para los documentos JSON. Junto con el nuevo soporte de tipos de datos, InnoDB también introdujo funciones SQL para soportar operaciones ricas en documentos JSON. Otra mejora de MySQL 8.0.7 añade la posibilidad de definir índices multivaluado en matrices JSON. Esta característica puede ser una potente forma de acelerar aún más las consultas de acceso de lectura a tipos JSON, haciendo coincidir los patrones de acceso comunes con funciones que pueden mapear los valores del documento JSON. Repasamos el uso y las implicaciones para el rendimiento del tipo de datos JSON en "Datos JSON", en el Capítulo 6.
Cambios en el Diccionario de Datos
Otro cambio importante de en MySQL 8.0 es la eliminación del almacenamiento de metadatos de tablas basado en archivos y el paso a un diccionario de datos que utiliza el almacenamiento de tablas InnoDB. Este cambio aporta todas las ventajas transaccionales de recuperación de fallos de InnoDB a operaciones como los cambios en las tablas. Este cambio, aunque mejora mucho la gestión de las definiciones de datos en MySQL, también requiere cambios importantes en el funcionamiento de un servidor MySQL. Sobre todo, los procesos de copia de seguridad que antes dependían de los archivos de metadatos de las tablas, ahora tienen que consultar el nuevo diccionario de datos para extraer las definiciones de las tablas.
DDL atómico
Por último, MySQL 8.0 introdujo cambios atómicos en la definición de datos. Esto significa que ahora las sentencias de definición de datos pueden terminar completamente con éxito o ser revertidas completamente. Esto es posible mediante la creación de un registro de deshacer y rehacer específico de DDL en el que se basa InnoDB para rastrear el cambio: otro punto en el que el diseño probado de InnoDB se ha ampliado a las operaciones del servidor MySQL.
Resumen
MySQL tiene una arquitectura en capas, con servicios para todo el servidor y ejecución de consultas por encima y motores de almacenamiento por debajo. Aunque hay muchas API de complementos diferentes, la API del motor de almacenamiento es la más importante. Si entiendes que MySQL ejecuta consultas pasando filas de un lado a otro de la API del motor de almacenamiento, habrás comprendido los fundamentos de la arquitectura del servidor.
En las últimas versiones importantes, MySQL se ha centrado en InnoDB como su principal foco de desarrollo e incluso ha trasladado su contabilidad interna en torno a los metadatos de tablas, la autenticación y la autorización, tras años en MyISAM. Esta mayor inversión de Oracle en el motor InnoDB ha dado lugar a importantes mejoras, como DDL atómicos, DDL en línea más robustos, mayor resistencia a los bloqueos y mejor operatividad para implementaciones orientadas a la seguridad.
InnoDB es el motor de almacenamiento por defecto y el que debería cubrir casi todos los casos de uso. Por ello, los siguientes capítulos se centran en gran medida en el motor de almacenamiento InnoDB cuando se habla de características, rendimiento y limitaciones, y sólo en raras ocasiones tocaremos cualquier otro motor de almacenamiento de aquí en adelante.
1 Una excepción es InnoDB, que sí analiza las definiciones de claves foráneas porque el servidor MySQL aún no las implementa por sí mismo.
2 MySQL 5.5 y las versiones más recientes admiten una API que puede aceptar complementos de agrupación de hilos, aunque no se utilizan habitualmente. La práctica habitual para la agrupación de hilos se realiza en las capas de acceso, de las que hablamos en el Capítulo 5.
3 Te recomendamos encarecidamente que leas la documentación sobre bloqueos exclusivos frente a compartidos, bloqueos por intención y bloqueos de registro.
4 Existen bloqueos de metadatos, que se utilizan cuando se producen cambios en el nombre de las tablas o en los esquemas, y en la 8.0 se introducen las "funciones de bloqueo a nivel de aplicación". En el curso de los cambios de datos corrientes, el bloqueo interno se deja en manos del motor InnoDB.
5 Aunque se trata de un ejercicio académico habitual, la mayoría de los bancos se basan realmente en la conciliación diaria y no en operaciones estrictamente transaccionales durante el día.
6 Para más información, lee un resumen de ANSI SQL de Adrian Coyler y una explicación de los modelos de coherencia de Kyle Kingsbury.
7 Como verás más adelante en este capítulo, algunos motores de almacenamiento bloquean tablas enteras, y otros implementan bloqueos más complejos basados en filas. Toda esa lógica vive, en su mayor parte, en la capa del motor de almacenamiento.
8 Con frecuencia se abusa de estos consejos de bloqueo y normalmente deben evitarse.
9 SELECT...FOR SHARE es una característica de MySQL 8.0 que sustituye a SELECT...LOCK IN SHARE MODE de versiones anteriores.
10 Te recomendamos que leas esta entrada del blog de Jeremy Cole para comprender mejor la estructura de los registros en InnoDB.
11 Para obtener muchos más detalles sobre cómo InnoDB gestiona las múltiples versiones de sus registros, consulta esta entrada del blog de Jeremy Cole.
12 No existe ninguna norma formal que defina MVCC, por lo que los distintos motores y bases de datos lo aplican de forma muy diferente, y nadie puede decir que alguno de ellos esté equivocado.
Get MySQL de Alto Rendimiento, 4ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

