Chapter 1. Understanding the Data Integration Problem
Jean-Jacques Rousseau, the 18th-century philosopher, famously wrote, “Man is born free and everywhere he is in chains.”
If Rousseau had been a 21st-century data architect, he might have remarked, “Data is born free but is everywhere in chains.”
After all, data is born free in the sense that all data is fundamentally the same, and there are no intrinsic reasons why data that originates in one context can’t integrate into another context. There are different ways of formatting and organizing data—such as databases, file systems, and object storage platforms—but all data consists of the same material and has the potential to deliver value to any application. A data object that lives in, say, a MySQL database and one hosted in an S3 storage bucket in the Amazon cloud are fundamentally similar. The difference between them lies in storage structure, not the intrinsic nature of the data itself.
Yet, in practice, data is everywhere in chains because most modern information technology environments enmesh data in silos that are very difficult to integrate with each other. This reality—which results from complex historical patterns that associated data with individual applications instead of making it easily shareable across the organization—means that it’s difficult to derive maximum value from data in modern organizations, which might maintain hundreds of distinct, poorly integrated data sources. Data silos also hamper processes like governance, privacy, and security.
This first chapter dives into the details of why data silos exist and why data integration remains so problematic. As you’ll learn, it’s not because developers, data architects, and information technology organizations don’t care about data integration. They do, and they often work hard (even harder than they need to) to ensure that data can move seamlessly between different applications and services. The root of the problem lies instead with the way organizations have approached data integration. They deal with integration in piecemeal fashion, finding ways to integrate one app with another but not to integrate all apps with all other apps.
At the same time, the explosion in the sheer number of applications and data sources that modern organizations have to contend with has substantially upped the ante when it comes to solving the problem of data organization. The issue is not just that businesses are doing data integration wrong; it’s also that the more data sources they add, the more wrong their data integration strategies become.
The Basics of the Integration Problem
Most modern applications can share data with one another. Using methods like APIs, connectors, or plug-ins, it’s possible to move data between applications. If you want to export data from, say, your enterprise resource planning system and import it into a customer relationship management app, there’s almost certainly a way to do so.
But just because it’s possible to move data doesn’t mean that doing so is easy or efficient, and therein lies the core of the data integration problem that the typical business faces today. The time and effort required to implement, maintain, and update the integrations that allow data to flow between applications are far higher than they should or need to be.
The problem, which is illustrated by Figure 1-1, starts at the stage in which organizations implement a data integration that connects two applications. Because developing the integration usually requires special technical knowledge that is specific to each app, the teams that support the apps must work together on planning and implementing the integration. Plus, given that engineers may not understand which data exists in each app or how best to format, map, and share the data, it’s often necessary for developers to consult business users so that they gain critical context on how the data integration should work.
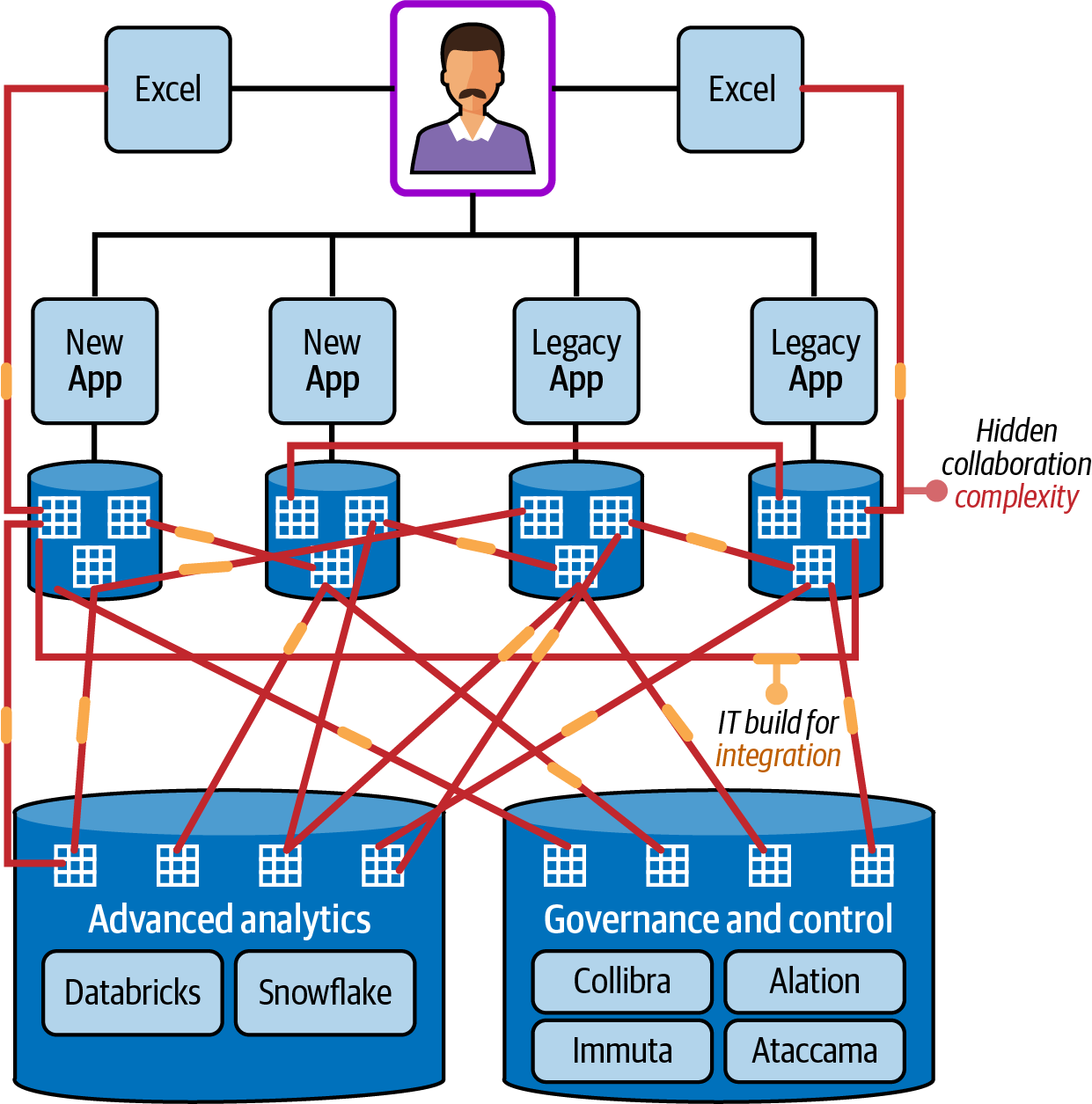
Figure 1-1. Conventional data integration architectures that require application-specific integrations
Figure 1-1 shows that implementing a single integration ties up a significant amount of personnel resources. It also requires complex coordination between a variety of stakeholders. On top of that, updating the applications necessitates bringing all parties together to create updates for the integration on a recurring basis because changes to the applications could break the integration.
Your teams may decide to hold off on updating applications because they are worried about disrupting the integration or they lack the resources to update it. In that case, the integration becomes a bottleneck to change. Rather than being able to innovate whenever opportunities arise, you become hostage to the limitations of your data integrations. You may also be constrained by rigid data contracts that define the terms under which data can be shared—such as how much data applications can share with each other, how rapidly they can move data, whether and how the data can be modified, and so on.
A second fundamental limitation of data integration is that because developers typically create each integration to connect only two specific apps, there is often no way to reuse integrations for other applications. You have to start the laborious implementation process from scratch whenever you want to integrate a new application or data source.
The operational overhead that integrations create adds another critical challenge. Each integration that your business deploys becomes an object that your information technology team needs to monitor, support, and troubleshoot in the event that something goes wrong. With hundreds of integrations spread across your business, managing them all could easily become a full-time job for multiple engineers.
A third challenge arising from integration strategies that focus on building connections between individual applications is that the business ends up with multiple copies of information spread across the organization. The state of a given data set within one application may not match the same data inside another application that integrates with it. This inconsistency may lead to data quality problems that undercut the ability of the business to derive value from data. It also becomes another source of increased operational overhead for the information technology team, which has to invest time and resources in reconciling conflicting copies of data in addition to supporting all of the integrations that created those conflicts.
Data privacy and compliance initiatives may also be undercut by modern approaches to data integration. When you are constantly copying data between applications via a sprawling set of integrations, it becomes exponentially harder to apply a consistent set of data security and protection policies to all data. Different instances of the data may end up protected with different security rules, increasing the risk of accidental exposure of sensitive information. Backing up the data is more challenging for the same reasons. And when you can’t properly back up or secure your data, you’re more likely not just to suffer breaches and data leaks, but also to run afoul of compliance laws and regulations—such as the General Data Protection Regulation (GDPR), California Consumer Privacy Act (CPRA), and Health Insurance Portability and Accountability Act of 1996 (HIPAA)—that place a premium on data privacy.
Last but not least, analyzing data in ways that create value for the business becomes more difficult and resource intensive when applications integrate with each other on an individual basis but not in a more streamlined, collaborative, and holistic way. You can’t easily aggregate, integrate, or evaluate data from across your organization if applications share data only with each other rather than sharing through a broader platform that lends itself to comprehensive data analysis. As a result, understanding the totality of the data that your business owns, let alone deriving insights from that data, is difficult under the standard approach to data integration. As you’ll learn in a moment, solutions like data warehouses can help to address this particular issue, but they don’t solve the many other problems that stem from conventional integration strategies.
Why Now Is the Time to Rethink Data Collaboration
The issues we’ve just described have impeded organizations’ abilities to work effectively with applications and data for decades. But they have grown considerably worse in recent years, for several reasons.
The largest reason is the rapid growth in the total number of integrations that businesses have to maintain. Contending with the time and effort necessary to implement and manage integrations may have been feasible enough when your organization had one or two dozen applications, at most, that needed to connect with each other.
But today, a typical business depends on more than 200 applications, according to Productiv’s “The State of SaaS Sprawl in 2021” report. This explosion in the number of applications that businesses deploy results from factors like the ease of adopting software as a service (SaaS) applications and a push to implement more applications as part of digital transformation initiatives. Those changes may ultimately bring value to your business, but only if you’re able to move data seamlessly between the hundreds of applications you depend on—a feat that’s just not feasible if you have to manage hundreds of individual integrations.
Increasingly rigid data security and compliance mandates are another reason why finding solutions to the integration problem has become a pressing priority for modern businesses. New data-centric compliance frameworks, such as GDPR and CPRA, have come online in recent years, while others, like the Payment Card Industry Data Security Standard (PCI DSS), have seen major updates that impose new data privacy requirements on organizations.
As we’ve already noted, complying with regulations like these often requires the ability to find and protect all of the sensitive data inside your business. But when your data is fractured across hundreds of applications and you have integrations generating multiple copies of your data, it becomes much harder to ensure that you know where all of your sensitive data lies, and whether you are securing it in ways that conform with compliance rules.
The pressure that modern information technology leaders face to do more, more quickly, and with fewer resources is another reason why conventional approaches to integration no longer work. We’re living in an age of automation in which information technology organizations are expected to be able to work quickly and at scale, even if they have limited personnel resources. In this environment, integrations that require extensive manual effort to build, deploy, and manage are an odd fit. They create drag on organizational agility, and they tie down resources that information technology leaders could invest in other more productive endeavors (such as, addressing growing cybersecurity threats or supporting novel practices like remote workforces).
Each of these trends is poised to grow more intense in the coming years. Digital transformation initiatives will continue, leading to more applications inside the typical business. The mandates that organizations face to secure sensitive data will become even more rigid, and attackers will be constantly devising new methods designed to evade the data privacy protections businesses have in place. Economic turbulence and expectations for fast, efficient operational processes will generate greater pressure for information technology leaders to curb the inefficiency that conventional integration strategies bring to their businesses.
This is to say that the time is now to solve the integration problem. You may have been able to manage well enough with slow, costly, and unscalable integrations in the past, but that strategy is fast becoming unsustainable for a typical business.
Conventional Approaches: Data Warehouses, Data Lakes, and Beyond
We’ll discuss what we believe to be the best way to conquer the integration problem in the next chapter. First, let’s look at other strategies that you might be tempted to try that only partly solve the typical organization’s need for making data easily shareable—which is not the same thing as data collaboration but is a step toward it.
Data warehouses, data lakes, and data lakehouses represent one trendy category of technology that focuses on making data accessible across the organization, but they are only a half-solution to the challenges described above. Each of these techniques works somewhat differently, but they all do the same basic thing: make it possible to aggregate data from multiple sources into a central storage location. You can analyze data within the warehouse or data lake. You can also set up data pipelines that push the data to destinations of your choosing if you want to work with it outside of the warehouse or lake.
These approaches are helpful in some situations. In particular, if your primary reason for bringing data together is to run analytics on it, warehouses and data lakes will serve that purpose.
However, they don’t address other important needs. You have to set up data pipelines for each use case you want to support, so you still end up having to build, deploy, and support multiple integration paths. Your data lake or warehouse becomes another resource that your information technology team has to support, which means you end up with higher operational overhead. It’s difficult, and in some cases impossible, to enforce granular security and privacy controls over data that are aggregated into a data lake or warehouse.
Another way of trying to solve the integration problem is to rely on automation platforms, such as MuleSoft, which includes features for creating data integrations between applications in a relatively low-effort way. These types of platforms reduce the technical pain associated with creating integrations, but they don’t address the underlying issue of having to create application-specific integrations, the human-related dependencies, and rigid data contracts as part of the integration process.
Put simply, the various technologies to which you might be tempted to turn to address your integration woes are superficial solutions. They make the problem of having too many integrations to create, deploy, and support less painful, but they don’t fundamentally solve it.
What does solve the core problem, as we’ll explain in the next chapter, is finding ways to collaborate around data without relying on traditional data integrations between applications, systems, and sources.
Get Moving Beyond Data Integration with Data Collaboration now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

