The following image shows Kafka Connect's architecture:
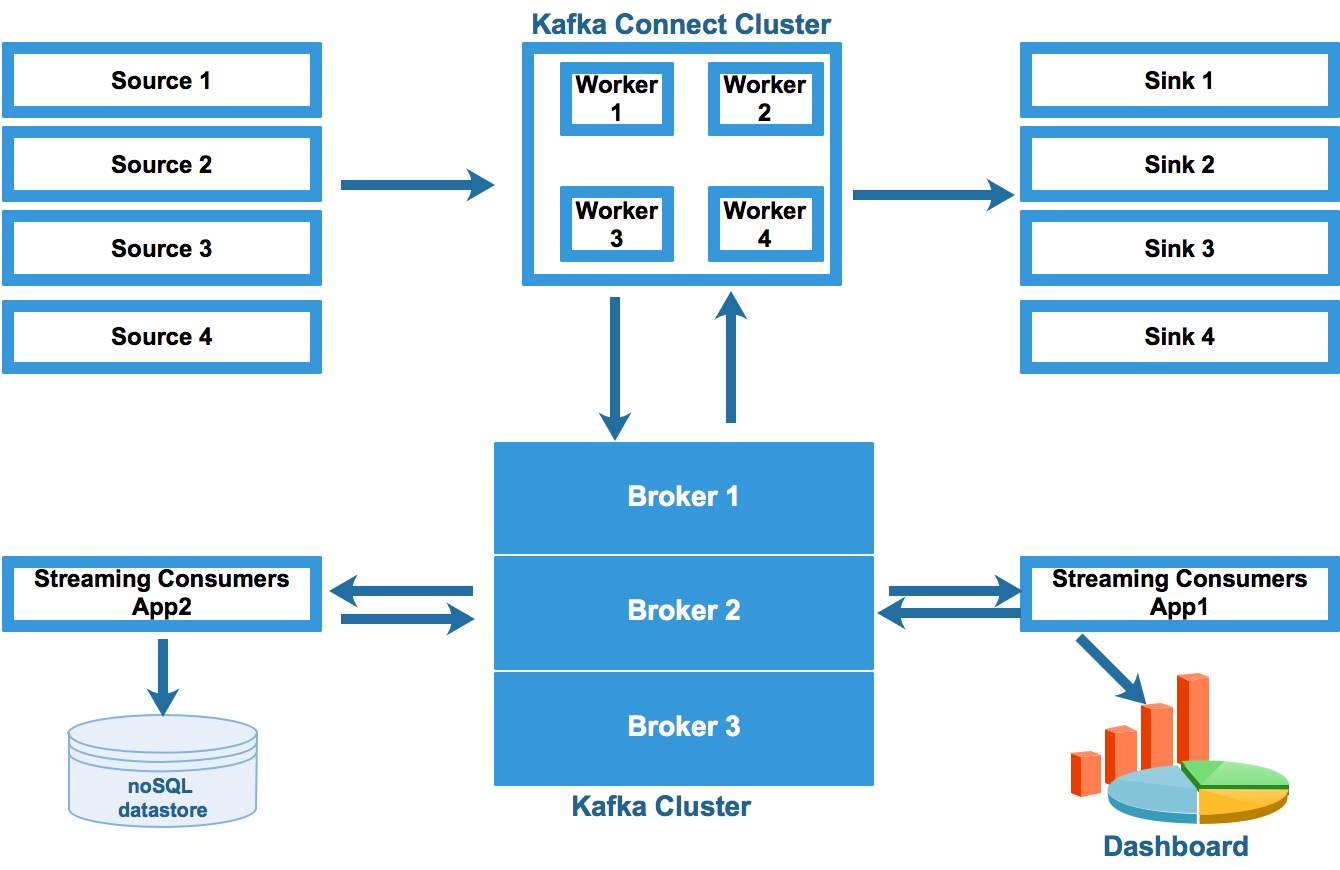
The data flow can be explained as follows:
- Various sources are connected to Kafka Connect Cluster. Kafka Connect Cluster pulls data from the sources.
- Kafka Connect Cluster consists of a set of worker processes that are containers that execute connectors, and tasks automatically coordinate with each other to distribute work and provide scalability and fault tolerance.
- Kafka Connect Cluster pushes data to Kafka Cluster.
- Kafka Cluster persists the data on to the broker local disk or on Hadoop.
- Streams applications such as Storm, Spark Streaming, and Flink pull ...

