The following diagram shows the working of Hive bucketing in detail:
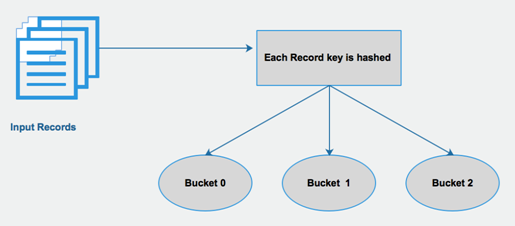
If we decide to have three buckets in a table for a column, (Ord_city) in our example, then Hive will create three buckets with numbers 0-2 (n-1). During record insertion time, Hive will apply the Hash function to the Ord_city column of each record to decide the hash key. Then Hive will apply a modulo operator to each hash value. We can use bucketing in non-partitioned tables also. But we will get the best performance when the bucketing feature is used with a partitioned table. Bucketing has two key benefits:
- Improved query performance: During joins ...

