Chapter 4. MPM in the ML Life Cycle
MPM serves as the glue that binds the model training, deployment, and monitoring stages together. Without an MPM process or system in place, your team will have a hard time finding the root cause of model performance issues. Whether the problem is caused by bad data or by the model being out of date, your team should be able to pinpoint its source. In this chapter, we’ll look at how MPM can help provide full visibility into any issues that may arise when training, deploying, and monitoring models.
The ML Feedback Loop
The machine learning life cycle is cyclic, due to the ever-changing nature of the world. Since models serve as general representations of real-world situations or scenarios, they need to constantly be monitored and updated to deal with new or previously unseen data and circumstances. Closing the feedback loop is a concept taken from control theory where the expected outputs and measured outputs of a system are compared in order to tune the system’s performance and achieve optimal results with minimal or zero error. To explore this concept further, let’s first take a quick look at what control theory is.
Brief on Control Theory
Control theory is about the control of dynamic (engineered) systems, typically using feedback mechanisms, in order to achieve optimality. Optimality is based on the context of the system being controlled and can be deterministic and exact or within a margin of acceptable error. There are two types of controllers, open loop and closed loop. To relate this to MPM, the expected outputs and metrics of a model need to be tracked with their actual outputs and metrics over time to ensure that the model is achieving optimal results.
MPM closes the loop of outputs in order to correct any errors in the future and maintain a state of optimality (something we will discuss later in this chapter). Often in control systems, the analysis is done in the frequency domain as opposed to the time domain. This means that instead of analyzing when something happened, a control system analyzes how often and how intensely something happens. Model error is a good thing to measure, as it can show how often something is not going as expected rather than when this is occurring. This measurement helps in pinpointing the highest-priority issues to fix (i.e., those that have the highest impact on your business).
Open-loop versus closed-loop controllers
An open-loop controller is one that does not rely on the measured output for regular operation. This is the case in highly predictable systems that have a discrete set of outputs based on the inputs. Looking at Figure 4-1, we can see how the flow of inputs to outputs is linear and easy to follow.

Figure 4-1. An open-loop controller
Think of the timer on a microwave that heats up food. It only knows how long it needs to go for and has no need to detect the temperature of whatever’s inside it to adjust that time. The reference here would be the time the food needs to be heated for, and the system input would be to turn on or keep on the microwave based on how much time is left. Once the reference signal runs out (the timer ends), the controller will turn off the microwave.
A closed-loop controller, as can be seen in Figure 4-2, is one where the system relies on the output to achieve its desired state. The reference signal and the measured output are compared in order to tune the controller’s output (which would be the system input) and try to minimize the error between the reference and the measured output. An error function is used to compare the two signals, and it sends the error as an input into the controller. The controller then, using its internal model, tweaks the system inputs to try and achieve the desired output.
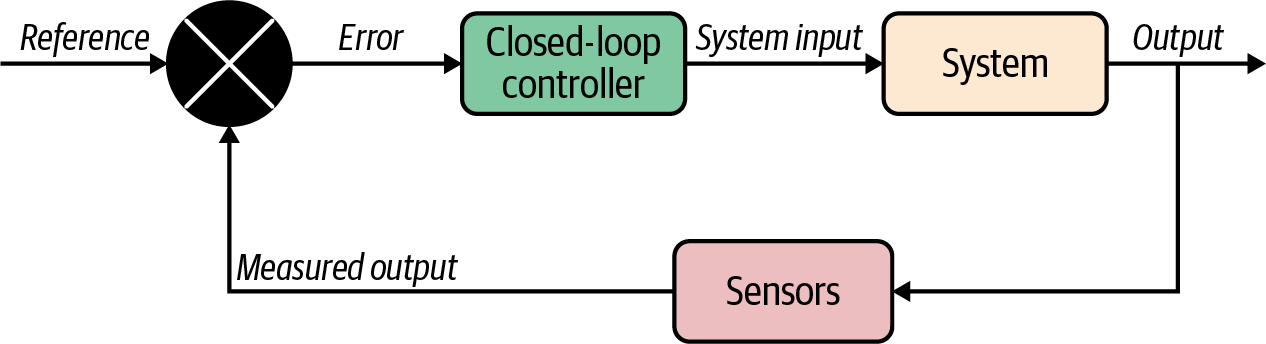
Figure 4-2. A closed-loop controller
In Figure 4-3 we see an example of a closed-loop controller: the power steering system on a car. The desired direction of the car is implied by the direction the steering wheel is being turned in, and any undesired resistance is given as feedback to the user in the form of the steering wheel rotating in the direction of the undesired motion. The controller has an internal model mapping the rotational distance of the steering wheel to the desired direction of the wheels to turn the car.
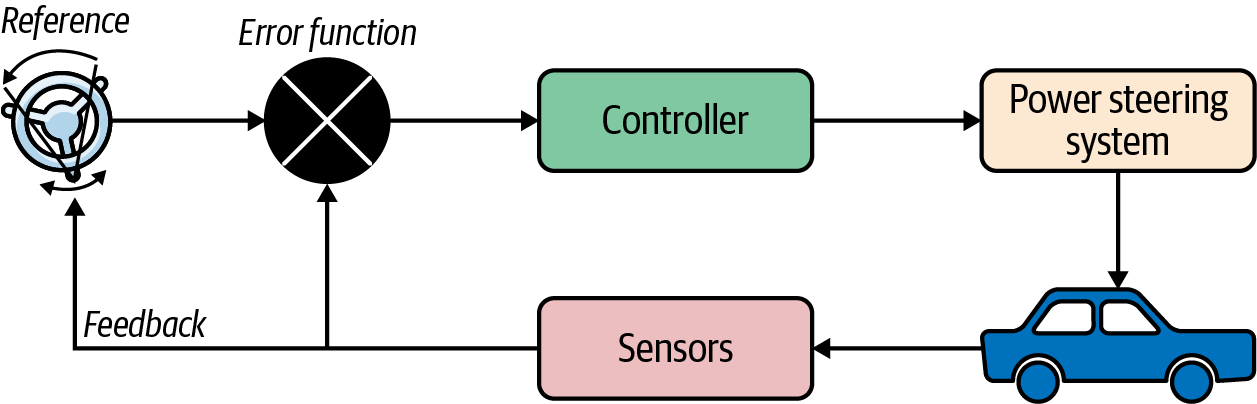
Figure 4-3. A closed-loop controller in a car’s power steering system
There might be some background noise that causes the steering wheel to turn without any input from the driver, maybe due to a bump or a hole in the road. The power steering system receives the reference signal (in this case, the rotation of the steering wheel by the driver) as well as signals from sensors in the car (the measured output) and uses these to determine how to steer the car to achieve the user’s desired result, as well as to return some feedback to the driver in case any undesired movement is detected.
Control Theory and MPM
Similar to how control theory operates on feedback using sensors, MPM acts as a feedback mechanism for your ML system. In the context of machine learning, the sensor in charge of giving feedback to your ML team is the MPM framework that is tracking the outputs of the model. The user (or human-in-the-loop) is the data scientist or ML engineer constantly monitoring and trying to update the model. The feedback is all the data collected from the model, as well as some metadata. The error function would be part of the MPM system that can flag any errors based on the reference inputs from the team or system. If the error function shows that the model is producing undesirable results, the ML system can then be investigated with the aim of improving the performance.
Thinking of the machine learning life cycle as a dynamic system allows us to understand the need for closing the feedback loop and tracking error (divergence from the desired references). References in the machine learning world are often the target labels used for training the model, which might not exist in incoming data since the expected prediction of the model is not known at the time of the prediction. Tracking the frequency of changes, as well as deviations in the model’s output, might help reveal any model drift or data drift issues. These can then trigger the team to investigate and try to correct the error in the system. Often this process of validating the model’s performance relies on some user input, such as ground truth labels or expected outputs. This validation process can be achieved through sampling a small set of the data and applying these labels, then comparing the output of the model to this expectation or ground truth.
MPM in the Training and Deployment Stage
Now that you understand what model performance is, let’s talk about how MPM fits into the ML life cycle stages and offers an easy way to manage processes to continuously monitor and improve model performance. MPM can start at the time the features are being extracted or engineered, or it can start at the moment the model is trained. This depends on the complexity of the input data and the effect of data drift on the model’s performance: a model that has very few inputs that rarely deviate from the norm would not need its features tracked since the inputs will always be predictable and have a low risk, whereas a complex model with multiple inputs that are completely variable and can change over time would need to be tracked.
Using XAI to Understand Model Bias
During the training stage of a model, bias might be hard to detect or prevent without trying to understand how the model might behave with inherent bias. In order to mitigate possible bias, XAI (discussed in Chapter 2) can be used to explain why results might be biased to a certain subset of the data. This can be caused by unbalanced training data or by the model being set up with inherent bias. Detecting unbalanced training data can be done by analyzing the distribution of the different labels and input data points to detect any underrepresented or overrepresented data. The data can then be undersampled or oversampled in order to reduce or eliminate any bias. If, however, the bias occurs due to the model itself being biased, this would show up through testing the model and using XAI to understand the model’s predictions.
Once the bias has been reduced to a negligible amount or eliminated completely, the candidate models can then be evaluated against the target labels to find the best one to release. Sometimes the best-performing model is also the most biased, and using XAI in conjunction with MPM is key to detecting these issues early on. (When you develop models that are not sensitive to bias, of course, you do not need to worry as much about detecting bias.)
Choosing the Best Model to Release
Choosing which model to integrate into your application or workflow and release to your users after optimizing performance and dealing with bias might be the most difficult decision, as models can sometimes be unpredictable, and any unpredictable behavior may translate to business risk and possible liability (depending on your line of business). The best-performing model offline might not prove to be the best-performing model online. This can be due to a high level of sensitivity—any model that you choose to release should therefore be analyzed for its sensitivity both to the training data and any unseen prediction data. As discussed already, this is done through splitting the historic data into training and test splits, where the test set is not seen by the model during training, but the expected prediction is stored alongside the test data.
Once a model is deemed to be ready for production, it can be versioned, integrated, and released. This versioning will help with many downstream analytics dependent on tracking the lineage of the model as well as its outputs. Any discrepancies between the model in offline and online environments can then be identified, and the performance of the model can be optimized to achieve the desired results.
MPM in the Release and Monitoring Stage
After a model has been approved for release, there are a number of measures to take to ensure that it can be confidently rolled out to all your users. MPM suggests that the model log all its predictions and input data alongside the model version and other metadata to allow the team to monitor it. Any issues that happen in the model can be detected by tracking the predictions being made and whether they begin to deviate far enough from the norm to trigger an investigation (known as model drift), and the root cause can be investigated using XAI. Models can also be compared in a live setting (known as A/B testing or challenger/champion testing). More advanced models might need to have more than two variations compared in order to ensure the highest-performing model is promoted; this form of testing is called multivariate testing.
Detecting Model Drift
Model drift occurs when the data feeding into the model begins to change or deviate from what the model expects, resulting in changes in the model output. When this occurs, it might be hard to detect since the model outputs are not usually stored alongside some metadata for analysis. Using an MPM system or process ensures that the model outputs are stored and accessible by your data science or operations teams. On an average day, the expectations of distributions across the different input groups should be within an acceptable margin of error. If these values begin to deviate over time, the analysis of the outputs can show any drift and allow your team to pinpoint and fix any issues.
One issue might be that the model needs to be seasonally updated due to the seasonality of your business. Another case would be that the model itself was not trained to account for all scenarios and is therefore producing unexpected outputs for unseen data. This can be caused from underrepresentation or overrepresentation of certain subsets of the data. To remedy this, your team can add in paths for unseen data, such as triggering a customer support ticket or referring the user to documentation in order to try to remedy the problem. Whether the issue is detected by the system or by users contacting your support team, the MPM system can be used to replay and analyze the predictions in order to update the model to remedy the issue.
Finding the Root Cause Using MPM and XAI
Once an issue has been identified by either the MPM system, a customer, or your QA team, it’s time to find the root cause and address it. Your team might be tempted to hastily attempt to remedy the issue by applying a quick fix or patch at the application layer without looking into the black box that is the machine learning model. But using MPM, they can identify and fix the root cause of the problem by isolating the issue and determining an appropriate remedy that has no impact on other parts of your system.
In order to mitigate the risk of customer satisfaction or compliance issues, your team can test out changes or fixes on a small portion of the data, or replay the past few days’ worth of live data in a simulated environment to check if the changes would have resulted in the expected behavior. Without an MPM system to store all the predictions alongside the metadata, it would be hard to replay data and run historical tests on any patches or fixes. Once the fixes have been validated on historical data, they can be released to your users. In order to mitigate any unforeseen risk, the model can be released to a small portion of your users first, and the results can be monitored to ensure the fix is safe to roll out to the rest of your users.
Live Experiments
Validating whether a new model (or an updated model) is going to accomplish the desired outcomes might be hard to achieve without mechanisms to mitigate unforeseen risk. There are many methods you can use to identify potential issues or defects early on in the process. Private testers or QA teams can capture these issues and log them for your engineering teams to address. No process is 100% perfect, though, and there will always be unknowns. So, to further mitigate risks, live experimentation can be done to minimize any damage by targeting specific subsets of incoming data for the new model to receive. By splitting the data in this way, the person tracking the experiment can monitor the results to validate any hypotheses or fixes that might have been applied. Once the model is validated on a small portion of the data, the ratio can be increased, either straight to 100% or gradually in order to account for edge cases or low-volume data points.
Random sampling versus targeted splitting
When conducting an experiment, it is important to keep in mind the data split that will be done in order to achieve the desired ratios. Sometimes you might need to validate that a very specific edge case has been fixed and that this fix does not cause any other issues. In these cases, you might want to target the fix for the users that fit into that edge case and validate that it works before going on to validate that it does not cause any issues for other users. Random sampling can be used for testing all users by ensuring an even split of samples across the two (or more) experiment targets.
There are many methods to randomly split data to ensure no biased targets occur. A common method is to use a hash of non-identifying fields in the data (metadata) and randomly split that set of hashes into target groups. Since the data being used to generate the hash is not unique to that row, the samples will be randomly distributed across the groups. This ensures that the “randomness” of the selection process for the target groups contains no bias toward selecting one specific group over the other based on any of its identifying features. This method applies to cases where the individual predictions are not related to a specific user, but sometimes you might want to split the users into groups.
If you want to target users rather than data points, you can first assign a random universally unique identifier (UUID) to each user and then sample the IDs using the same method as mentioned previously. You might need to generate these UUIDs for each user, or you might be able to use an existing field (e.g., a user ID field). In either case, these IDs are usually stored on the user’s device or attached to their login information in order to better track the performance of the different models across the different target user groups.
A/B testing
Now that we’ve seen how the models can be split into target groups, let’s talk about the simplest type of live experiment we can perform: the A/B test or challenger/champion test. The A and B in A/B testing just refer to two models; they can be two completely different models or slightly modified versions of the same model. In either case, there is usually one model that is already in production (assuming this isn’t the first experiment you are running), which would be the champion in a challenger/champion test. The challenger is tasked with outperforming the champion and talking over its role as the champion model. Once a challenger that has been shown to be superior to the champion is promoted to that role, it awaits challenges from future models.
Multivariate testing
Sometimes you might have many different variables that need to be tested at the same time, or many different variations of models that you want to experiment with. In these cases, you’ll need to have multiple target groups vying for the glory of champion. Once the different groups and variables have been released, without an MPM system in place that is keeping track of all the different things happening at the same time, it might become extremely hard to analyze the results. Ensuring that the MPM system also tracks the metadata of each model version, as well as the users’ UUIDs, becomes a full stack effort requiring the integration of these metric trackers into your application or system.
Get Model Performance Management with Explainable AI now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

