Chapter 1. Introduction to Model Performance Management and Explainability
Before the rise of the internet, software development life cycles were longer due to the nature of distributing and accessing software. Remember the days of having to purchase a CD or DVD and insert it into your computer to install software? The life cycle was a waterfall, and it used to take months (if not years) to perform actions like pushing a patch or an update to consumers that are taken for granted in today’s agile world.
After the internet brought about more connected software systems, monitoring communications and interactions between systems as well as between people and systems became harder and harder. This led to the rise of two frameworks that work well with each other to enable rapid iteration while maintaining high-performing systems: development operations (DevOps) and application performance management (APM). As systems started to advance and become more intelligent, we saw the rise of machine learning (ML) and artificial intelligence (AI) systems. But with this fancy new technology comes many risks and questions about what might happen if we let these systems behave in uninterpretable or unexplainable ways.
The rapid emergence of these systems also led to the development of new practices focused on machine learning and data specifically. With traditional software, it is easy to test if it’s working: there is usually a discrete set of possible inputs and outputs. When it comes to sophisticated ML models and AI systems, however, it becomes hard to fully monitor and observe what is happening inside. Some models may draw upon thousands if not millions of inputs to make a decision. This is why we need a new framework focused around ML and AI that is data-centric and aims at producing high-quality models and systems that work with the goals of rapid iteration of DevOps and MLOps.
Such a framework would be similar to APM but would apply to ML models and account for the nuances and differences between these models and traditional applications. This framework can be called model performance management (MPM). Model performance is not only reliant on metrics but also on how well a model can be explained when something eventually goes wrong. This is known as model explainability. Just as APM aims at providing ops teams with more visibility into the entire application development process, MPM allows those teams to monitor models as they are being trained, validated, and deployed. In this chapter, we will discuss the need for such a framework before delving deeper into the nuances and stages involved in the ML life cycle and how MPM and model explainability fit into it.
DevOps and Application Performance Management
Let’s take a step back and talk about why DevOps and APM came to be and what they are.
DevOps
DevOps, or development operations, is a term used to describe the combination of cultural practices, business processes, and toolchains that are used to achieve rapid iteration and high velocity. The goal is to innovate quickly and catch problems and issues as soon as they arise. There are many DevOps frameworks and tools out there, and each has its pros and cons, but at the center of it all is an overarching philosophy that unifies the practices in some ways across companies and domains.
One tenet of DevOps is system observability and, in turn, monitoring. Monitoring is achieved through the use of metrics and logs that enable us to track what is happening inside an application. There are tools that do monitoring, and there are tools that offer full observability, but there is no one unified framework that aims at achieving full visibility into application systems. Thus, DevOps is often combined with APM.
Application Performance Management
APM provides a framework for monitoring and managing software application performance through measuring metrics about the application, with the aim of catching issues as soon as they appear, if not before. The exact metrics used can vary, but, with applications increasingly moving to the cloud, ensuring that APIs remain performant and meet users’ real-time expectations is getting more and more complicated. We need to make sure our applications are always available when needed and can handle an increase or decrease in load without losing performance.
Your business might have APIs it serves to customers, or internal APIs for applications used by employees. You might also be using an external vendor’s APIs for your own business needs. Regardless of the details, you will need to ensure that the applications using these APIs are performing with acceptable responsiveness and fluidness so that users aren’t left waiting for minutes for a page to load. This comes down to how fast the API can respond to user requests. If an API is suddenly slowing down, an APM framework will automatically alert the responsible team so they can investigate it, find the root cause, and address it. Having full observability allows teams to rapidly identify and fix problems before they cause a loss in revenue for your business.
The benefits of APM are:
- Broad visibility
-
Prior to the rise of the DevOps tools that we have today, monitoring infrastructure was limited in functionality and difficult to use. Software and hardware were monitored separately, creating disconnected experiences. APM introduces broad visibility across all aspects of the deployment cycle, unified under one framework.
- Increased observability
-
When monitoring triggers an alert, teams address the problem with a fix. However, locating the source can be tedious and repetitive, especially when an alert was actually expected rather than a surprise. Going beyond visibility, APM provides additional root-cause debugging support, called observability. For example, with observability, an application’s drop in performance might be attributed to a node in the cluster failing to process requests and not a problem with the code itself.
- Clear ownership
-
APM enables DevOps engineers to manage the end-to-end life cycle of production code through observability and clear ownership. Clarity of ownership allows for the designation of specialized individuals who can respond to issues rapidly.
- Iteration speed
-
Ultimately, a streamlined process with clear stakeholders and availability of monitoring tools for broad visibility enables your teams to deploy and identify and fix issues quickly, thus reducing the time between iterations and maximizing the impact of each iteration.
Application Performance Metrics
The typical metrics that are measured for application performance are:
- API latency
-
The amount of time the system takes to perform an action, typically measured in milliseconds (ms)
- Queries per second (QPS)
-
The amount of times the API is invoked every second
These metrics are vital for an application team to monitor the scale and load their application is able to handle. They are also the basis for any automated alerts or trigger-based events, such as system failovers, and can feed into an automated scale management solution such as cluster resizing or node pool resizing (a way of managing the number of computers the API is using to process its requests). With cloud computing becoming more and more accessible, companies are migrating many of their applications and workloads to the cloud, making monitoring these metrics ever more important.
There might be a day—say, Black Friday—when your systems get flooded with requests, causing the application to crash. By simulating such traffic using an APM framework and measuring the latency the system will have at any given QPS before the fact, your team can capture any issues and design ahead to prevent any failures or performance degradations. This is known as load testing and can aid in scaling up systems.
Real-time streaming data, historical replay, and great visualization tools are standard parts of APM solutions today. The popular APM products don’t just offer insights into simple statistics but also have API and component integrations that are business-ready.
The Rise of MLOps
As applications have started to adopt more advanced decision-making algorithms and models, the management and tooling required to ensure high performance has become more complicated. With code-centric applications, it’s fairly trivial to test whether they are doing what they’re supposed to do. But ML and AI models are data-centric, which adds many challenges that traditional DevOps teams are not used to dealing with (like ensuring data integrity and validity). This is where MLOps comes in.
Machine learning operations, or MLOps for short, is an amalgamation of cultural practices around data and its usage, data science, and tools that all aim at rapidly iterating through versions of a model or running experiments rapidly to test different hypotheses. MLOps does not exist in isolation from DevOps, and they need to work hand in hand to ensure that all bases are covered and that any issues can be addressed and resolved with little effort from your teams. We will cover the ML life cycle and some aspects of ML in Chapter 3 of this report, but for now let’s look at how MLOps compares to DevOps.
MLOps Compared to DevOps
MLOps and DevOps both come from the same foundations and are focused on rapid iteration and continuous improvement. Without frameworks based around these philosophies, teams will have a hard time establishing efficient cycles and will yield few fruitful results. Both MLOps and DevOps propose validating and testing any system before it is released. However, they lack when it comes to observability and monitoring. This is where APM shines for DevOps, as it offers full visibility into an application, allowing teams to find the root cause of a problem as soon as it becomes apparent.
ML/AI models are inherently black boxes; data scientists do not always know why and how a model works. But this lack of visibility can’t be solved with a one-size-fits-all solution, because each model is unique. Therefore, the testing and validation you need to perform to properly monitor a model require a lot of planning and work.
Model Performance Metrics
There are many different types of machine learning (ML) models, each with its own nuances and metrics that it needs to track. ML models are highly data-centric and rely on the quality and consistency of the data being fed into them. Here are some examples of the sources of complexity in ML models today:
- Versatility
-
ML serves a wide range of use cases—anti-money laundering, job matching, clinical diagnosis, and planetary surveillance, just to name a few.
- Architecture
-
ML algorithms can take many forms, which are easier or harder to interpret; they range from simple logistic regression and decision trees to advanced neural networks for deep learning.
- Variety
-
ML models come in many varieties (tabular, time series, text, image, video, and audio), and often these modalities are mixed for certain domains, further adding to the complexity of tracking the performance of the model.
- Volume
-
The rise of cloud computing has enabled teams to train multiple models with more data in parallel, which makes it harder to keep track of the training data.
Teams must be able to monitor sudden changes in data distributions that might lead to bias. Other issues might arise from the model being trained on too little or too much data, making it underperform. Tracking all the parameters that can affect a model’s performance is much harder than tracking code changes in a repository.
The metrics often used to track model performance are:
- Accuracy
-
The percentage of total predictions that were actually correct
- Precision
-
The percentage of positive cases that were correctly identified
- Negative predictive value
-
The percentage of negative cases that were correctly identified
- Sensitivity/recall
-
The percentage of actual positive cases that are correctly identified
- Specificity
-
The proportion of actual negative cases that are correctly identified
Using some or all of these metrics, a model can be tracked from offline to online and have its performance measured against a simulated baseline. Since different models have different types of data and outputs, each will use different forms of these metrics. A tool that’s commonly used to visualize them is the confusion matrix. Figure 1-1 illustrates this concept using a matrix with binary classification (the model only predicts either true or false). If the model has more output classes, then this matrix can be scaled to any number of rows and columns to analyze all the classes that are underperforming.
Using this matrix, we can see that:
-
Accuracy = TP + TN / (TP + TN + FP + FN)
-
Precision = TP / (TP + FP)
-
Recall = TP / (TP + FN)
Although these metrics can offer a good measure of the performance of a model, it is not always possible to determine the “true” values of the predictions once a model is deployed. In production situations, models are often measured in relation to the business outcome they are trying to achieve. For example, a marketing model aimed at targeted emails might be measured by how many of the emails result in a purchase. In this scenario, the model is not measured by accuracy but by the business outcome it is able to achieve. We will go into more detail about all of these metrics in later chapters.
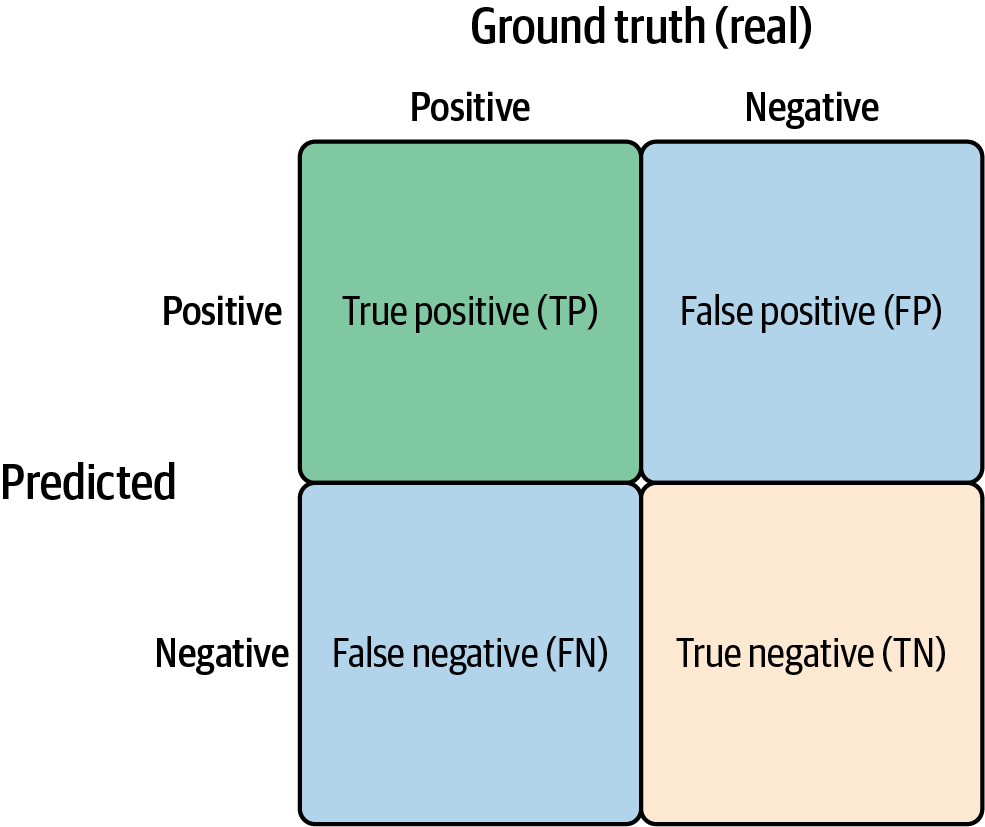
Figure 1-1. A confusion matrix for binary classification
The ML Development Process
Developing a machine learning model typically involves multiple steps, with various stakeholders working together and constantly iterating on data and models in the workflow. As the first step, data scientists define a business problem and turn it into a machine learning model, after gathering the necessary data.
Next, a model validator evaluates the model to make sure it works as intended and complies with company standards and government regulations. After the model is validated, it’s deployed into production by a machine learning engineer and starts to make predictions in business applications. Once it’s in production, the process of continuous monitoring, testing, and debugging starts, typically managed by a team of DevOps engineers, data engineers, ML engineers, and data scientists. And finally, teams analyze the model’s output in real time or in batches to check its performance, fix errors, and gather insights to train a better-performing model.
The stakeholders may vary from company to company because this field is still new and developing, but the core loop of iterating ML models remains the same. Simply put, MLOps is this continuous feedback-driven loop of operationalizing machine learning models. To close this loop, MLOps requires a dedicated framework that can act as a centralized control system at the heart of the ML workflow. This framework, which tracks and monitors the model’s performance through all the stages, is model performance management.
Model Performance Management
When compared to application performance, managing or overseeing model performance is a lot more data-intensive and requires a deeper understanding of the domain at hand. Without a unified framework or set of tools to use, your data science and machine learning teams might find it hard to deploy models at scale and maintain high performance. This is where MPM comes in. MPM is a framework for managing model performance throughout its life cycle and ensuring that teams have clear visibility into every stage of the ML life cycle. Figure 1-2 shows an overview of this life cycle. The feedback loop provided by MPM permits continuous model improvement.
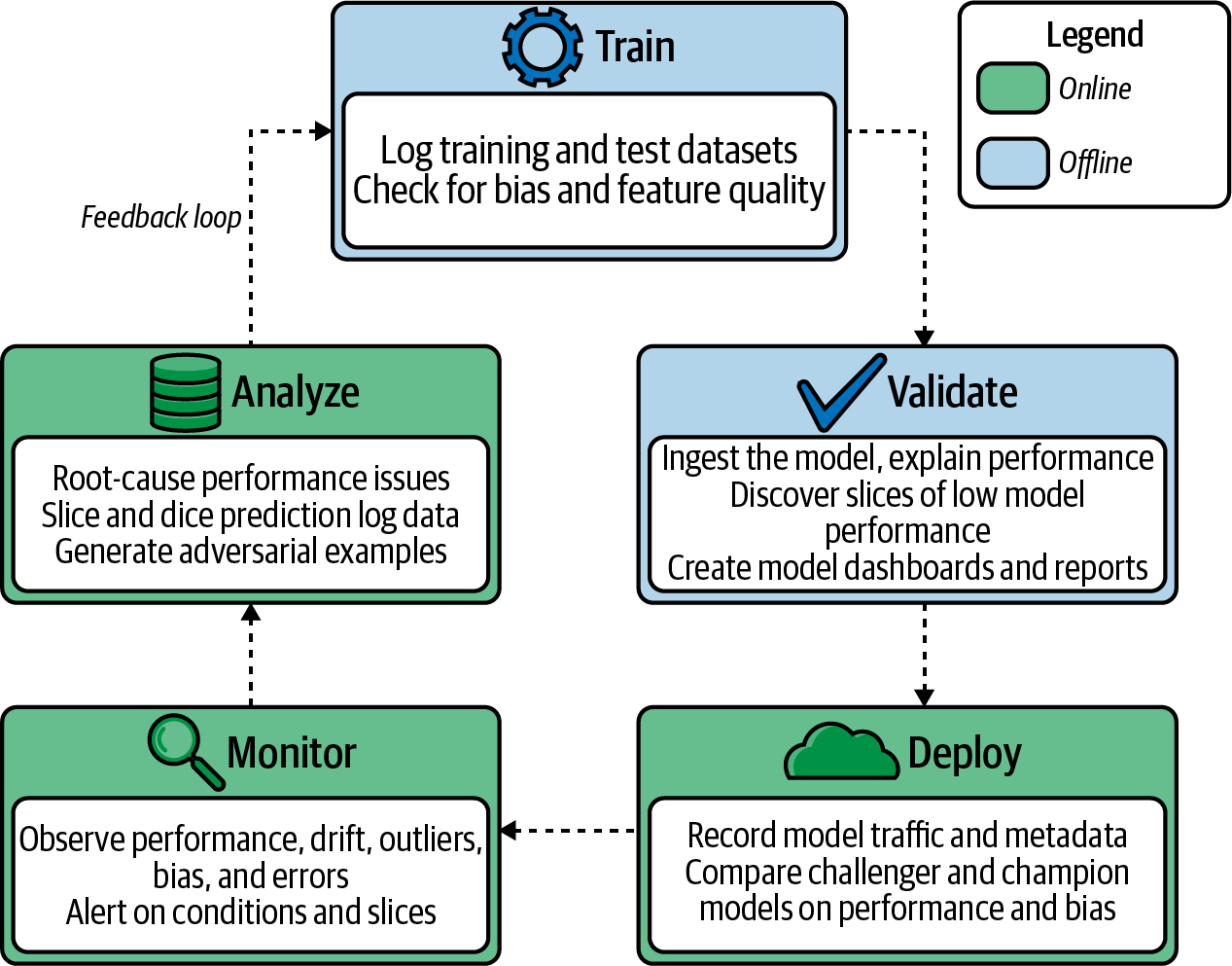
Figure 1-2. The life cycle of a model
The MPM feedback loop augments each step of the life cycle in the following ways:
-
While training a model and selecting features or data to train the model on, your teams can uncover hidden bias through under- or overrepresented groups in the data. Bias can also occur as a result of a change in the data coming in, known as data drift.
-
After the model is trained, the MPM framework can validate and log any performance estimates to a database for tracking and auditing purposes. This can be used to generate summary reports for business, compliance, and AI ethics stakeholders.
-
When a new model is ready to be deployed, it can be compared to a previous version using the same data to ensure that the new model is outperforming the old one. This is often called champion/challenger testing and validation.
-
Once the model is launched to production, an MPM framework serves as a monitoring tool to observe model performance, drift, bias, and alerts on error conditions. An MPM framework can also be used to measure the performance of two models simultaneously, known as A/B or champion/challenger testing.
-
Since MPM is a feedback loop, any insights generated from errors, performance issues, or analyses can be used to improve future models’ performance.
It is important to note that an MPM framework does not replace existing ML training, deployment, and serving systems. Instead, it sits at the heart of the ML workflow, capturing all the model artifacts, training and production data, and model performance metrics as well.
Because of the increased complexity within the ML space, teams often struggle with the following challenges, even when they have an MLOps framework in place:
- Inconsistent performance
-
Since ML models are trained on historical data, there can be large differences between how the models perform offline (in staging) and how they perform online (in production, with previously unseen data).
- Lack of control
-
Machine learning is often a black box. This makes it difficult to understand why and how the model is deriving an output from the given data to drive performance improvements.
- Amplification of bias
-
Models can amplify bias in the data they are trained on, which makes identifying potential sources of bias very important. Furthermore, because of the lack of visibility, it can be difficult to be sure that the model is operating the same way on the test dataset or on real data as it did on the training data. Failure to identify discrepancies or imbalances between the historical and real datasets could amplify hidden biases, possibly violating corporate policy and resulting in customer mistrust.
- Lack of debuggability
-
Inability to debug complex models could lead to low trust and model performance deterioration. It also prevents these models from being used in regulated industries such as finance and healthcare.
- Feedback loop
-
Model degradation frequently drives the need to build a better model to represent the current business reality—but the operational insights that form the feedback loop are missing today.
- Difficulty in improving performance iteratively
-
Challenges in tracking and comparing model behavior and performance across production versions make it difficult to understand how performance can be improved over time.
MPM with Explainability for Full Coverage
A high-performing ML model with around 80–90% accuracy might still have hidden biases and underrepresented groups in the data. In order to detect hidden biases in data, teams need to analyze the features being used and the distribution of data in those features. This should take place during the feature selection and model training stages, and usually leads to these issues being caught early on. However, as time goes on and models are set up to be automatically retrained, bias can start to creep in as certain groups of data become more or less prevalent. In order to account for this, an MPM framework needs to monitor data distributions against a baseline to catch any arising drift that might cause bias.
Drift can occur due to the data being used to make the predictions changing or the data being used to train the model changing. In either case, MPM needs to track the distribution of data and account for the changes between what the model is expecting and what it is seeing. Any deviation above what is normal should be flagged for investigation and debugging. Chapter 2 will go into explainability in more detail and talk about the philosophy of Explainable AI.
Benefits of Using an MPM Framework
As mentioned previously, the MPM framework aims to bring visibility into the machine learning life cycle. It addresses several of the operational challenges in MLOps, such as inconsistent performance, loss of control, and lack of a feedback loop. But what does that mean for a business? Let’s take a look at some key business benefits that the MPM framework provides.
MPM validates models before pushing them live
Before deploying a model, it is crucial to validate it, whether required by law or not. This ensures that at launch, you have a high-performing, well-tested, and robust model. Since the model will have been built around a business hypothesis or problem, the validation process involves verifying with business stakeholders that it solves the intended problem once deployed and does so without hampering other aspects of the business. This requires the model to be explained in human-understandable terms. To answer questions like “How is the model making a prediction?” and “Are there any biases?” a model has to be validated. The validation can often be performed using techniques such as cross-validation to assess changes in the model’s behavior. If the model passes validation, it gets deployed, and the business gets to start using machine learning with a clear understanding of the ML model’s impact. However, this is just the beginning of the ML feedback loop.
MPM continuously monitors model performance in production
Machine learning models are unique software entities compared to traditional programs because they are trained for high performance on repeatable tasks using historical examples. As a result, their performance can fluctuate over time as the real-world data they receive as input changes. No company can know for certain exactly how a model will perform after it’s deployed. So, successful ML deployments require continuous monitoring to reassess the model’s business value and performance on an ongoing basis.
MPM proactively addresses model bias
Biases exist in the world, as a rule. Since ML models capture relationships from a limited set of training data, they are likely to propagate or amplify existing data bias and may even introduce new bias. Stories about alleged bias in credit lending, hiring, and healthcare AI algorithms demonstrate these risks. As a result, companies have been spending extra effort to measure and guard against bias by either ingesting or inferring protected attributes. But models can become biased after release as well.
Because bias can cause serious business damage, especially in highly regulated environments, identifying it in real time can save companies from costly penalties, such as financial fines or consumer outrage. As is the case with performance metrics, a data scientist typically needs to calculate bias metrics offline, which heightens the risk of errors (because they are not using production data). Moreover, bias issues can be correlated to other issues; for example, a spike in the number of male job applicants could cause bias in job candidate matching. Investigating causes of bias in a silo can cause data scientists to overlook such correlations, resulting in them spending time unnecessarily on debugging issues that could have been easily corrected.
MPM detects training/serving skew
Features used to train and serve the models in online and offline environments can differ. When this happens, the model will behave differently and needs to be debugged. By keeping the training data and prediction log in one place, MPM enables developers to detect these skews.
MPM explains past predictions
Imagine a bank is using ML to approve loans, and a customer files a complaint about a particular loan being denied. Because MPM tracks a model’s behavior from training to serving, a risk operations officer can go back in time to reproduce the prediction along with the explanation (this is known as “prediction time travel”).
In the next chapter, we’ll discuss how Explainable AI enhances the benefits of MPM even further.
Get Model Performance Management with Explainable AI now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

