Capítulo 4. Entrega continua paramodelos de aprendizaje automático
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
¿Es realmente la triste verdad que la filosofía natural (lo que ahora llamamos ciencia) se ha separado tanto de sus orígenes que sólo ha dejado tras de sí papirólogos: personas que cogen papel, apagan papel y, mientras leen y escriben con asiduidad, evitan seriamente lo tangible? ¿Consideran que el contacto directo con los datos tiene un valor negativo? ¿Están, como algún paleto de la novela Tobacco Road, realmente orgullosos de su ignorancia?
Dr. Joseph Bogen
Como atleta profesional, a menudo tenía que lidiar con lesiones. Las lesiones tienen todo tipo de niveles de gravedad. A veces se trataba de algo menor, como una leve contractura en el isquiotibial izquierdo tras intensos entrenamientos de vallas. Otras veces sería más grave, como un insufrible dolor lumbar. Los atletas de alto rendimiento no pueden permitirse tener días libres en mitad de la temporada. Si el plan es entrenar siete días a la semana, es fundamental cumplir esos siete días. Saltarse un día tiene graves repercusiones que pueden disminuir (o anular por completo) los entrenamientos hasta ese momento. Los entrenamientos son como empujar una carretilla cuesta arriba, y saltarse un entrenamiento significa hacerse a un lado dejando que la carretilla vaya cuesta abajo. La repercusión de esa acción es que tendrás que volver a coger esa carretilla para empujarla de nuevo cuesta arriba. No puedes perderte entrenamientos.
Si estás lesionado y no puedes hacer ejercicio, recuperar la plena forma lo antes posible es una prioridad tan importante como encontrar entrenamientos alternativos. Eso significa que si te duelen los isquiotibiales y no puedes correr, mira a ver si puedes ir a la piscina y seguir con el plan de cardio. ¿Las repeticiones en cuesta no son posibles mañana porque te has roto un dedo del pie? Entonces intenta subirte a la bici para afrontar esas mismas cuestas. Las lesiones requieren una estrategia de guerra; rendirse y abandonar no es una opción, pero si hay que retirarse, entonces se considera primero retirarse lo menosposible. Si no podemos disparar cañones, llevemos la caballería. Siempre hay una opción, y la creatividad es tan importante como intentar recuperarse totalmente.
La recuperación también requiere estrategia, pero más que estrategia, requiere una evaluación constante. Puesto que con una lesión sigues entrenando todo lo posible, es esencial evaluar si la lesión está empeorando. Si te subes a la bici para compensar porque no puedes correr, debes ser hiperconsciente de si la bici está empeorando la lesión. La evaluación constante de las lesiones es un algoritmo bastante simplista:
-
A primera hora de cada día, valora si la lesión está igual, peor o mejor que el día anterior.
-
Si es peor, entonces haz cambios para evitar los entrenamientos anteriores o alterarlos. Pueden estar perjudicando la recuperación.
-
Si es la misma, compara la lesión con la de la semana pasada o incluso con la del mes pasado. Hazte la pregunta : "¿Me siento igual, peor o mejor que la semana pasada?".
-
Por último, si te sientes mejor, eso refuerza fuertemente que la estrategia actual está funcionando, y debes continuar hasta que estés totalmente recuperado.
Con algunas lesiones, tuve que evaluar con mayor frecuencia (en lugar de esperar hasta la mañana siguiente). El resultado de la evaluación constante fue la clave de la recuperación. En algunos casos, tuve que evaluar si una acción concreta me estaba haciendo daño. Una vez me rompí un dedo del pie (lo golpeé contra la esquina de una estantería), e inmediatamente me planteé una estrategia: ¿puedo andar? ¿Siento dolor si corro? La respuesta a todas ellas fue un rotundo sí. Aquella tarde intenté ir a nadar. Durante las semanas siguientes, comprobaba constantemente si era posible caminar sin dolor. El dolor no es un enemigo. Es el indicador que te ayuda a decidir si seguir haciendo lo que estás haciendo o parar y replantearte la estrategia actual.
Evaluar constantemente, hacer cambios y adaptarse a las reacciones, y aplicar nuevas estrategias para lograr el éxito es exactamente de lo que tratan la integración continua (IC) y la entrega continua (EC). Incluso hoy en día, cuando se puede acceder fácilmente a información sobre estrategias de implementación sólidas, a menudo te encuentras con empresas sin pruebas o con una estrategia de pruebas deficiente para garantizar que un producto está listo para una nueva versión, o incluso con versiones que tardan semanas (¡y meses!). Recuerdo cuando intentaba cortar una nueva versión de un importante proyecto de código abierto, y había veces que tardaba cerca de una semana. Peor aún, el jefe de Control de Calidad (QA) enviaba correos electrónicos a todos los jefes de equipo y les preguntaba si se sentían preparados para una versión o si querían más cambios.
Enviar correos electrónicos y esperar diferentes respuestas no es una forma sencilla de liberar software. Es propenso a errores y muy incoherente. El bucle de retroalimentación que las plataformas y pasos de CI/CD te conceden a ti y a tu equipo tiene un valor incalculable. Si encuentras un problema, debes automatizarlo y hacer que deje de ser un problema para la siguiente versión. La evaluación constante, al igual que las lesiones con los atletas de alto rendimiento, es un pilar fundamental de DevOps y absolutamente crítico para el éxito de la operacionalización del aprendizaje automático.
Me gusta la descripción de continuo como persistencia o recurrencia de un proceso. CI/CD suelen mencionarse juntos cuando se habla del sistema que construye, verifica y despliega artefactos. En este capítulo, detallaré qué aspecto tiene un proceso robusto y cómo puedes habilitar diversas estrategias para implementar (o mejorar) una canalización para enviar modelos a producción.
Embalaje para modelos ML
No hace tanto tiempo que oí hablar por primera vez de los modelos de empaquetado ML. Si nunca has oído hablar de empaquetar modelos, no pasa nada: todo esto es bastante reciente, y empaquetar aquí no significa algún tipo especial de paquete del sistema operativo como un archivo RPM (Red Hat Package Manager) o DEB (Debian Package) con directivas especiales para empaquetar y distribuir. Todo esto significa introducir un modelo en un contenedor para aprovechar los procesos en contenedores que ayudan a compartir, distribuir y facilitar la implementación. Ya he descrito en detalle la contenedorización en "Contenedores" y por qué tiene sentido utilizarlos para hacer operativo el aprendizaje automático frente al uso de otras estrategias como las máquinas virtuales, pero vale la pena reiterar que la posibilidad de probar rápidamente un modelo desde un contenedor, independientemente del sistema operativo, es un escenario de ensueño hecho realidad.
Hay tres características del empaquetado de modelos ML en contenedores que es importante repasar:
-
Siempre que esté instalado un tiempo de ejecución de contenedor, no supone ningún esfuerzo ejecutar un contenedor localmente.
-
Hay muchas opciones para implementar un contenedor en la nube, con la posibilidad de ampliarlo o reducirlo según sea necesario.
-
Otros pueden probarlo rápidamente con facilidad e interactuar con el contenedor.
Las ventajas de estas características son que el mantenimiento se hace menos complicado, y depurar un modelo que no funcione localmente (o incluso en una oferta en la nube) puede ser tan sencillo como unos pocos comandos en un terminal. Cuanto más complicada sea la estrategia de implementación, más difícil será solucionar e investigar los posibles problemas.
Para esta sección, utilizaré un modelo ONNX y lo empaquetaré dentro de un contenedor que sirve a una app Flask que realiza la predicción. Utilizaré el modelo ONNX RoBERTa-SequenceClassification, que está muy bien documentado. Tras crear un nuevo repositorio Git, el primer paso es averiguar las dependencias necesarias. Tras crear el repositorio Git, empieza por añadir el siguiente archivo requirements.txt:
simpletransformers==0.4.0 tensorboardX==1.9 transformers==2.1.0 flask==1.1.2 torch==1.7.1 onnxruntime==1.6.0
A continuación, crea un Dockerfile que instale todo en el contenedor:
FROM python:3.8 COPY ./requirements.txt /webapp/requirements.txt WORKDIR /webapp RUN pip install -r requirements.txt COPY webapp/* /webapp ENTRYPOINT [ "python" ] CMD [ "app.py" ]
El archivo Dockerfile copia el archivo de requisitos, crea un directorio webapp y copia el código de la aplicación en un único archivo app.py. Crea el archivo webapp/app.py para realizar el análisis de sentimientos. Comienza añadiendo las importaciones y todo lo necesario para crear una sesión en tiempo de ejecución de ONNX:
fromflaskimportFlask,request,jsonifyimporttorchimportnumpyasnpfromtransformersimportRobertaTokenizerimportonnxruntimeapp=Flask(__name__)tokenizer=RobertaTokenizer.from_pretrained("roberta-base")session=onnxruntime.InferenceSession("roberta-sequence-classification-9.onnx")
Esta primera parte del archivo crea la aplicación Flask, define el tokenizador que se utilizará con el modelo y, por último, inicializa una sesión en tiempo de ejecución de ONNX que requiere pasar una ruta al modelo. Hay bastantes importaciones que aún no se utilizan. Las utilizarás a continuación, cuando añadas la ruta Flask para activar la inferencia en tiempo real:
@app.route("/predict",methods=["POST"])defpredict():input_ids=torch.tensor(tokenizer.encode(request.json[0],add_special_tokens=True)).unsqueeze(0)ifinput_ids.requires_grad:numpy_func=input_ids.detach().cpu().numpy()else:numpy_func=input_ids.cpu().numpy()inputs={session.get_inputs()[0].name:numpy_func(input_ids)}out=session.run(None,inputs)result=np.argmax(out)returnjsonify({"positive":bool(result)})if__name__=="__main__":app.run(host="0.0.0.0",port=5000,debug=True)
La función predict() es una ruta Flask que habilita la URL /predict cuando la aplicación se está ejecutando. La función sólo permite los métodos HTTP POST. Aún no hay descripción de las entradas y salidas de ejemplo porque falta una parte crítica de la aplicación: el modelo ONNX aún no existe. Descarga localmente el modelo ONNX RoBERTa-SequenceClassification y colócalo en la raíz del proyecto. Así es como debe quedar la estructura final del proyecto:
.
├── Dockerfile
├── requirements.txt
├── roberta-sequence-classification-9.onnx
└── webapp
└── app.py
1 directory, 4 files
Una última cosa que falta antes de construir el contenedor es que no hay instrucciones para copiar el modelo en el contenedor. El archivo app.py requiere que el modelo roberta-sequence-classification-9.onnx exista en el directorio /webapp. Actualiza el archivo Dockerfile para reflejarlo:
COPY roberta-sequence-classification-9.onnx /webapp
Ahora el proyecto tiene todo lo necesario para que puedas construir el contenedor y ejecutar la aplicación. Antes de construir el contenedor, vamos a comprobar que todo funciona. Crea un nuevo entorno virtual, actívalo e instala todas las dependencias:
$ python3 -m venv venv $ source venv/bin/activate $ pip install -r requirements.txt
El modelo ONNX existe en la raíz del proyecto, pero la aplicación lo quiere en el directorio/webapp, así que muévelo dentro de ese directorio para que la aplicación Flask no se queje (este paso extra no es necesario cuando se ejecuta el contenedor):
$ mv roberta-sequence-classification-9.onnx webapp/
Ahora ejecuta la aplicación localmente invocando el archivo app.py con Python:
$ cd webapp $ python app.py * Serving Flask app "app" (lazy loading) * Environment: production WARNING: This is a development server. Use a production WSGI server instead. * Debug mode: on * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
A continuación, la aplicación está lista para consumir solicitudes HTTP. Hasta ahora, no he mostrado cuáles son las entradas esperadas. Van a ser peticiones con formato JSON y respuestas JSON. Utiliza el programa curl para enviar una carga útil de muestra para detectar el sentimiento:
$ curl -X POST -H "Content-Type: application/JSON" \
--data '["Containers are more or less interesting"]' \
http://0.0.0.0:5000/predict
{
"positive": false
}
$ curl -X POST -H "Content-Type: application/json" \
--data '["MLOps is critical for robustness"]' \
http://0.0.0.0:5000/predict
{
"positive": true
}
La solicitud JSON es una matriz con una única cadena, y la respuesta es un objeto JSON con una clave "positiva" que indica el sentimiento de la frase. Ahora que has comprobado que la aplicación se ejecuta y que la predicción en vivo funciona correctamente, es el momento de crear el contenedor localmente para verificar que todo funciona allí. Crea el contenedor y etiquétalo con algo significativo:
$ docker build -t alfredodeza/roberta . [+] Building 185.3s (11/11) FINISHED => [internal] load metadata for docker.io/library/python:3.8 => CACHED [1/6] FROM docker.io/library/python:3.8 => [2/6] COPY ./requirements.txt /webapp/requirements.txt => [3/6] WORKDIR /webapp => [4/6] RUN pip install -r requirements.txt => [5/6] COPY webapp/* /webapp => [6/6] COPY roberta-sequence-classification-9.onnx /webapp => exporting to image => => naming to docker.io/alfredodeza/roberta
Ahora ejecuta el contenedor localmente para interactuar con él del mismo modo que cuando ejecutas la aplicación directamente con Python. Recuerda asignar los puertos del contenedor al localhost:
$ docker run -it -p 5000:5000 --rm alfredodeza/roberta * Serving Flask app "app" (lazy loading) * Environment: production WARNING: This is a development server. Use a production WSGI server instead. * Debug mode: on * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
Envía una solicitud HTTP del mismo modo que antes. Puedes volver a utilizar el programa curl:
$ curl -X POST -H "Content-Type: application/json" \
--data '["espresso is too strong"]' \
http://0.0.0.0:5000/predict
{
"positive": false
}
Hemos pasado por muchos pasos para empaquetar un modelo y meterlo en un contenedor. Algunos de estos pasos pueden parecer abrumadores, pero los procesos difíciles son una oportunidad perfecta para automatizar y aprovechar los patrones de entrega continua. En la siguiente sección, automatizaré todo esto utilizando la entrega continua y publicando este contenedor en un registro de contenedores que cualquiera pueda consumir.
Infraestructura como código para la entrega continua demodelos ML
Hace poco, en el trabajo, vi que existían unas cuantas imágenes de contenedores de prueba en un repositorio público, que eran muy utilizadas por la infraestructura de pruebas. Tener imágenes alojadas en un registro de contenedores (como Docker Hub) ya es un gran paso en la dirección correcta para obtener compilaciones repetibles y pruebas fiables. Me encontré con un problema con una de las bibliotecas utilizadas en un contenedor que necesitaba una actualización, así que busqué los archivos utilizados para crear estos contenedores de prueba. No estaban por ninguna parte. En algún momento, un ingeniero los creó localmente y subió las imágenes al registro. Esto supuso un gran problema, porque no podía hacer un simple cambio en la imagen, ya que los archivos necesarios para crearla se habían perdido.
Los desarrolladores de contenedores experimentados pueden encontrar la forma de conseguir que la mayoría de los archivos (si no todos) reconstruyan el contenedor, pero eso no viene al caso. Un paso adelante en esta problemática situación es crear una automatización que pueda construir automáticamente estos contenedores a partir de archivos fuente conocidos, incluido el Dockerfile. Reconstruir o resolver el problema para actualizar el contenedor y volver a cargarlo en el registro es como buscar velas y linternas en un apagón, en lugar de tener un generador que se pone en marcha automáticamente en cuanto se va la luz. Sé muy analítico cuando se produzcan situaciones como la que acabo de describir. En lugar de señalar con el dedo y culpar a los demás, aprovéchalas como una oportunidad para mejorar el proceso con la automatización.
El mismo problema ocurre en el aprendizaje automático. Tendemos a acostumbrarnos fácilmente a que las cosas sean manuales (¡y complejas!), pero siempre hay una oportunidad para automatizar. En esta sección no volveré a repasar todos los pasos necesarios en la contenedorización (ya tratados en "Contenedores"), pero entraré en los detalles necesarios para automatizarlo todo. Supongamos que nos encontramos en una situación similar a la que acabo de describir y que alguien ha creado un contenedor con un modelo que vive en Docker Hub. Nadie sabe cómo llegó el modelo entrenado al contenedor; no hay documentación y se necesitan actualizaciones. Añadamos una ligera complejidad: el modelo no se encuentra en ningún repositorio, pero vive en Azure como modelo registrado. Pongamos en marcha alguna automatización para resolver este problema.
Advertencia
Puede resultar tentador añadir modelos a un repositorio de GitHub. Aunque esto es ciertamente posible, GitHub tiene (en el momento de escribir esto) un límite duro de archivos de 100 MB. Si el modelo que intentas empaquetar se acerca a ese tamaño, es posible que no puedas añadirlo al repositorio. Además, Git (el sistema de control de versiones) no está pensado para gestionar el versionado de archivos binarios y tiene el efecto secundario de crear repositorios enormes por este motivo.
En el escenario del problema actual, el modelo está disponible en la plataforma Azure ML y se ha registrado previamente. Yo no tenía ya uno, así que registré rápidamente RoBERTa-SequenceClassification utilizando Azure ML Studio. Haz clic en la sección Modelos y luego en "Registrar modelo", como se muestra en la Figura 4-1.
Figura 4-1. Menú de registro del modelo Azure
Rellena el formulario de la Figura 4-2 con los datos necesarios. En mi caso, he descargado el modelo localmente y necesito subirlo utilizando el campo "Subir archivo".
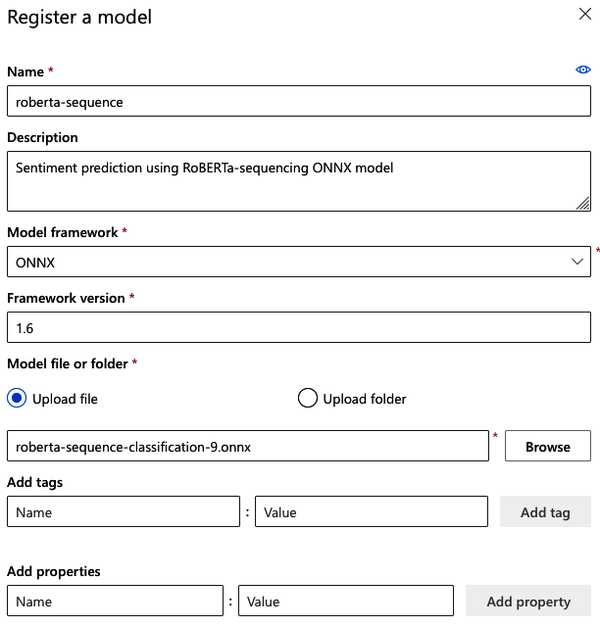
Figura 4-2. Formulario de registro del modelo Azure
Nota
Si quieres saber más sobre cómo registrar un modelo en Azure, explico cómo hacerlo con el SDK de Python en "Registro de modelos".
Ahora que el modelo preentrenado está en Azure, reutilicemos el mismo proyecto de "Empaquetado de modelos ML". Todo el trabajo pesado para realizar la inferencia en vivo (local) está hecho, así que crea un nuevo repositorio de GitHub y añade el contenido del proyecto excepto el modelo ONNX. Recuerda que hay un límite de tamaño para los archivos en GitHub, por lo que no es posible añadir el modelo ONNX en el repositorio de GitHub. Crea un archivo .gitigore para ignorar el modelo y evitar añadirlo por error:
*onnx
Tras enviar el contenido del repositorio Git sin el modelo ONNX, estamos listos para empezar a automatizar la creación y entrega del modelo. Para ello, utilizaremos las Acciones de GitHub, que nos permiten crear un flujo de trabajo de entrega continua en un archivo YAML que se activa cuando se cumplen unas condiciones configurables. La idea es que cada vez que el repositorio tenga un cambio en la rama principal, la plataforma extraerá el modelo registrado de Azure, creará el contenedor y, por último, lo enviará a un registro de contenedores. Empieza creando un directorio .github/workflows/ en la raíz de tu proyecto, y luego añade un main.yml que tenga este aspecto:
name:Build and package RoBERTa-sequencing to Dockerhubon:# Triggers the workflow on push or pull request events for the main branchpush:branches:[main]# Allows you to run this workflow manually from the Actions tabworkflow_dispatch:
La configuración hasta ahora no hace nada más que definir la acción. Puedes definir cualquier número de trabajos, y en este caso, definimos un trabajo de compilación que lo juntará todo. Añade lo siguiente al archivo main.yml que creaste anteriormente:
jobs:build:runs-on:ubuntu-lateststeps:-uses:actions/checkout@v2-name:Authenticate with Azureuses:azure/login@v1with:creds:${{secrets.AZURE_CREDENTIALS}}-name:set auto-install of extensionsrun:az config set extension.use_dynamic_install=yes_without_prompt-name:attach workspacerun:az ml folder attach -w "ml-ws" -g "practical-mlops"-name:retrieve the modelrun:az ml model download -t "." --model-id "roberta-sequence:1"-name:build flask-app containeruses:docker/build-push-action@v2with:context:./file:./Dockerfilepush:falsetags:alfredodeza/flask-roberta:latest
El trabajo de construcción tiene muchos pasos. En este caso, cada paso tiene una tarea distinta, lo que es una forma excelente de separar los dominios de fallo. Si todo estuviera en un único script, sería más difícil captar los posibles problemas. El primer paso es comprobar el repositorio cuando se dispara la acción. A continuación, como el modelo ONNX no existe localmente, necesitamos recuperarlo de Azure, por lo que debemos autenticarnos mediante la acción Azure. Tras la autenticación, la herramienta az estará disponible, y deberás adjuntar la carpeta de tu espacio de trabajo y grupo. Por último, el trabajo puede recuperar el modelo por su ID.
Nota
Algunos pasos del archivo YAML tienen una directiva uses, que identifica qué acción externa (por ejemplo actions/checkout) y en qué versión. Las versiones pueden ser ramas o etiquetas publicadas de un repositorio. En el caso de checkout es la etiqueta v2.
Una vez completados todos esos pasos, el modelo RoBERTa-Sequence debería estar en la raíz del proyecto, permitiendo que los siguientes pasos construyan el contenedor adecuadamente.
El archivo del flujo de trabajo utiliza AZURE_CREDENTIALS. Se utilizan con una sintaxis especial que permite al flujo de trabajo recuperar secretos configurados para el repositorio. Estas credenciales son la información del principal de servicio. Si no estás familiarizado con un principal de servicio, esto se trata en la "Autenticación". Necesitarás la configuración del principal de servicio que tiene acceso a los recursos del espacio de trabajo y del grupo donde vive el modelo. Añade el secreto en tu repositorio de GitHub yendo a Configuración, luego a Secretos y, por último, haciendo clic en el enlace "Nuevo secreto de repositorio". La Figura 4-3 muestra el formulario que se te presentará al añadir un nuevo secreto.
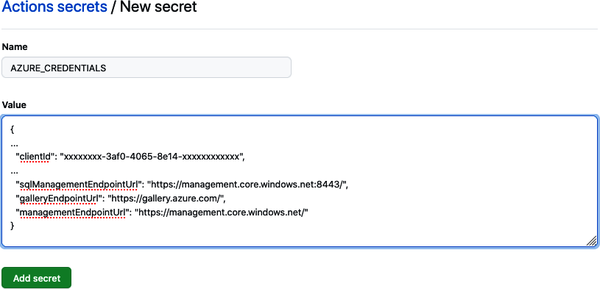
Figura 4-3. Añadir secreto
Confirma y empuja tus cambios a tu repositorio y luego dirígete a la pestaña Acciones. Inmediatamente se programará una nueva ejecución, que debería comenzar en unos segundos. Al cabo de unos minutos, todo debería haberse completado. En mi caso, la Figura 4-4 muestra que tarda cerca de cuatro minutos.
Figura 4-4. Éxito de la acción de GitHub
Ahora hay bastantes partes móviles para realizar con éxito una ejecución de trabajo. Al diseñar un nuevo conjunto de pasos (o conductos, como explicaré en la siguiente sección), una buena idea es enumerar los pasos e identificar los pasos codiciosos. Estos pasos codiciosos son pasos que intentan hacer demasiado y tienen mucha responsabilidad. A primera vista, es difícil identificar algún paso que pueda ser problemático. El proceso de mantenimiento de un trabajo CI/CD incluye refinar las responsabilidades de los pasos y adaptarlos en consecuencia.
Una vez identificados los pasos, puedes descomponerlos en pasos más pequeños, lo que te ayudará a comprender más rápidamente la responsabilidad de cada parte. Una comprensión más rápida significa una depuración más fácil, y aunque no sea inmediatamente evidente, te beneficiarás de convertir esto en un hábito.
Éstos son los pasos que tenemos que seguir para empaquetar el modelo RoBERTa-Secuencia:
-
Consulta la rama actual del repositorio.
-
Autentícate en Azure Cloud.
-
Configura la autoinstalación de las extensiones de Azure CLI.
-
Adjunta la carpeta para interactuar con el espacio de trabajo.
-
Descarga el modelo ONNX.
-
Construye el contenedor para el repositorio actual.
Sin embargo, falta un último elemento, que es publicar el contenedor después de construirlo. Diferentes registros de contenedores requerirán diferentes opciones aquí, pero la mayoría admiten Acciones de GitHub, lo cual es refrescante. Docker Hub es sencillo, y todo lo que requiere es crear un token y luego guardarlo como secreto de proyecto de GitHub, junto con tu nombre de usuario de Docker Hub. Una vez hecho esto, adapta el archivo de flujo de trabajo para incluir el paso de autenticación antes de construir:
-name:Authenticate to Docker hubuses:docker/login-action@v1with:username:${{ secrets.DOCKER_HUB_USERNAME }}password:${{ secrets.DOCKER_HUB_ACCESS_TOKEN }}
Por último, actualiza el paso de compilación para utilizar push: true.
Recientemente, GitHub ha lanzado también una oferta de registro de contenedores, y su integración con GitHub Actions es sencilla. Se pueden utilizar los mismos pasos de Docker con pequeños cambios y creando un PAT (Token de Acceso Personal). Empieza por crear un PAT yendo a la configuración de tu cuenta de GitHub, haciendo clic en "Configuración de desarrollador" y, por último, en "Tokens de acceso personal". Una vez que se cargue esa página, haz clic en "Generar nuevo token". Dale una descripción significativa en la sección Nota, y asegúrate de que el token tiene permisos para escribir paquetes, como hago yo en la Figura 4-5.
Figura 4-5. Token de acceso personal a GitHub
Cuando hayas terminado, aparecerá una nueva página con el código real. Esta es la única vez que verás el token en texto plano, así que asegúrate de copiarlo ahora. A continuación, ve al repositorio donde vive el código del contenedor y crea un nuevo secreto de repositorio, igual que hiciste con las credenciales principales del servicio Azure. Nombra al nuevo secreto GH_REGISTRY y pega el contenido del PAT creado en el paso anterior. Ahora estás listo para actualizar los pasos de Docker para publicar el paquete utilizando el nuevo token y el registro de contenedores de GitHub:
-name:Login to GitHub Container Registryuses:docker/login-action@v1with:registry:ghcr.iousername:${{ github.repository_owner }}password:${{ secrets.GH_REGISTRY }}-name:build flask-app and push to registryuses:docker/build-push-action@v2with:context:./tags:ghcr.io/alfredodeza/flask-roberta:latestpush:true
En mi caso, alfredodeza es mi cuenta de GitHub, así que puedo etiquetar con ella junto con el nombre flask-roberta del repositorio. Estos deberán coincidir según tu cuenta y repositorio. Después de enviar los cambios a la rama principal (o después de fusionarlos si has hecho un pull request), el trabajo se activará. El modelo se extraerá de Azure, se empaquetará en el contenedor y, finalmente, se publicará como un paquete de GitHub en su oferta de registro de contenedores, con un aspecto similar al de la Figura 4-6.
Figura 4-6. Contenedor de paquetes de GitHub
Ahora que el contenedor está empaquetando y distribuyendo el modelo ONNX de forma totalmente automatizada aprovechando la oferta CI/CD de GitHub y el registro de contenedores, hemos resuelto el escenario problemático que supuse al principio del capítulo: un modelo necesita empaquetarse en un contenedor, pero los archivos del contenedor no están disponibles. De este modo, aportas claridad a los demás y al propio proceso. Está segmentado en pequeños pasos, y permite realizar cualquier actualización en el contenedor. Por último, los pasos publican el contenedor en un registro seleccionado.
Puedes hacer muchas otras cosas con los entornos CI/CD, además de empaquetar y publicar un contenedor. Las plataformas CI/CD son la base de la automatización y de unos resultados fiables. En la siguiente sección, profundizo en otras ideas que funcionan bien independientemente de la plataforma. Si conoces los patrones generales disponibles en otras plataformas, podrás aprovechar esas características sin preocuparte de las implementaciones.
Utilizar tuberías en la nube
La primera vez que oí hablar de los pipelines, pensé que eran más avanzados que el típico patrón de scripting (un conjunto procedimental de instrucciones que representan una construcción). Pero los pipelines no son conceptos avanzados en absoluto. Si has trabajado con shell scripts en cualquier plataforma de integración continua, un pipeline te parecerá sencillo de utilizar. Una canalización no es más que un conjunto de pasos (o instrucciones) que pueden lograr un objetivo concreto, como publicar un modelo en un entorno de producción cuando se ejecutan. Por ejemplo, una canalización con tres pasos para entrenar un modelo puede ser tan sencilla como la Figura 4-7.

Figura 4-7. Tubería simple
Podrías representar la misma canalización como un script de shell que hiciera las tres cosas a la vez. Una canalización que separa las preocupaciones tiene múltiples ventajas. Cuando cada paso tiene una responsabilidad (o preocupación) específica, es más fácil de comprender. Si un proceso de un solo paso que recupera los datos, los valida y entrena el modelo falla, no está claro inmediatamente por qué puede fallar. De hecho, puedes bucear en los detalles, mirar los registros y comprobar el error real. Si separas el proceso en tres pasos y falla el paso de entrenamiento del modelo, puedes reducir el alcance del fallo y llegar más rápidamente a una posible solución.
Consejo
Una recomendación general que puedes aplicar a los muchos aspectos de la operacionalización del aprendizaje automático es considerar la posibilidad de hacer más sencilla cualquier operación para una futura situación de fallo. Evita caer en la tentación de ir rápido y conseguir que una tubería (como en este caso) se despliegue y se ejecute en un solo paso porque es más fácil. Tómate tu tiempo para razonar sobre lo que te facilitaría a ti (y a otros) la construcción de la infraestructura de ML. Cuando se produzca un fallo, e identifiques aspectos problemáticos, vuelve a la implementación y mejórala. Puedes aplicar los conceptos de CI/CD a la mejora: la evaluación y mejora continuas de los procesos es una estrategia sólida para conseguir entornos robustos.
Los pipelines en la nube no difieren de cualquier plataforma de integración continua existente, salvo en que están alojados o gestionados por un proveedor en la nube.
Algunas definiciones de canalizaciones CI/CD que puedes encontrar intentan definir rígidamente los elementos o partes de una canalización. En realidad, creo que las partes del canal deben definirse libremente y no estar limitadas por definiciones. RedHat tiene una buena explicación de las canalizaciones que describe cinco elementos comunes: compilación, prueba, lanzamiento, implementación y validación. Estos elementos sirven sobre todo para mezclarlos y combinarlos, no para incluirlos estrictamente en el pipeline. Por ejemplo, si el modelo que estás construyendo no necesita ser desplegado, entonces no hay necesidad de seguir un paso de despliegue en absoluto. Del mismo modo, si tu flujo de trabajo requiere extraer y preprocesar datos, debes implementarlo como otro paso.
Ahora que sabes que una canalización es básicamente lo mismo que una plataforma CI/CD con varios pasos, debería ser sencillo aplicar operaciones de aprendizaje automático a una canalización procesable. La Figura 4-8 muestra un supuesto pipeline bastante simplista, pero también puede implicar varios pasos más, y como he mencionado, estos elementos pueden mezclarse y combinarse entre sí para cualquier número de operaciones y pasos.
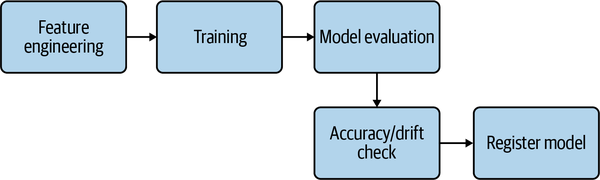
Figura 4-8. Tuberías implicadas
AWS SageMaker realiza un excelente trabajo al proporcionar ejemplos listos para usar desde el primer momento para crear canalizaciones complejas que incluyen todo lo necesario para ejecutar varios pasos. SageMaker es una plataforma especializada en aprendizaje automático que va más allá de ofrecer pasos en una canalización para lograr un objetivo como publicar un modelo. Al estar especializada en el aprendizaje automático, estás expuesto a funciones que son especialmente importantes para poner modelos en producción. Esas funciones no existen en otras plataformas comunes como GitHub Actions, o si existen, no están tan bien pensadas porque el objetivo principal de plataformas como GitHub Actions o Jenkins no es entrenar modelos de aprendizaje automático, sino ser lo más genéricas posible para adaptarse a los casos de uso más comunes.
Otro problema crucial que resulta algo difícil de resolver es que las máquinas especializadas para el entrenamiento (por ejemplo, las tareas que requieren un uso intensivo de la GPU) no están disponibles o son difíciles de configurar en una oferta de canalización genérica.
Abre SageMaker Studio y dirígete a la sección Componentes y Registros de la barra lateral izquierda y selecciona Proyectos. Aparecerán varias plantillas de proyecto de SageMaker entre las que puedes elegir, como se muestra en la Figura 4-9.

Figura 4-9. Plantillas de SageMaker
Nota
Aunque los ejemplos están pensados para que empieces, y se proporcionan Cuadernos Jupyter, son estupendos para aprender más sobre los pasos que hay que seguir y cómo cambiarlos y adaptarlos a tus necesidades específicas. Después de crear una instancia de canalización en SageMaker, entrenar y, finalmente, registrar el modelo, puedes navegar por los parámetros de la canalización, como en la Figura 4-10.
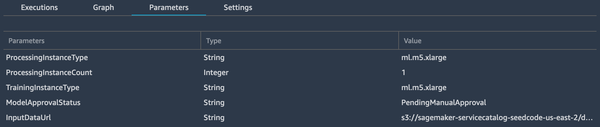
Figura 4-10. Parámetros de la tubería
También está disponible otra parte crucial de la tubería que muestra todos los pasos implicados, como se muestra en la Figura 4-11.
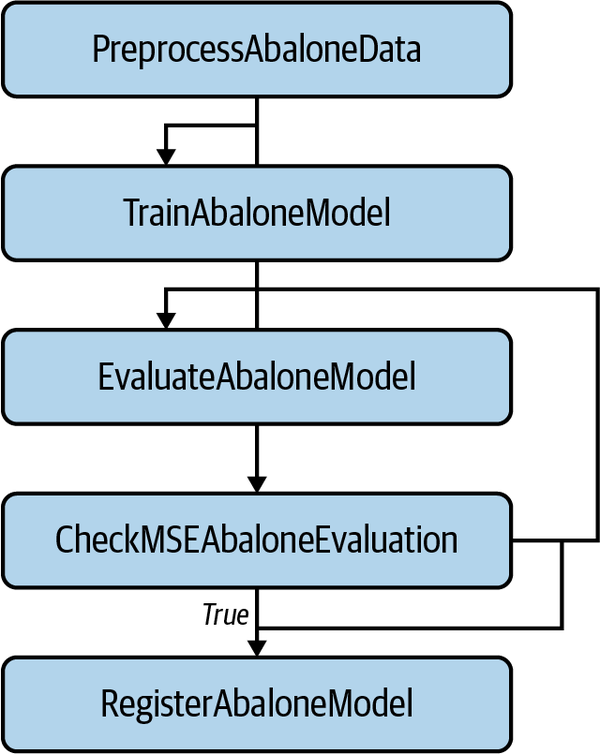
Figura 4-11. Canalización de SageMaker
Como puedes ver, la preparación de los datos, el entrenamiento, la evaluación y el registro de un modelo forman parte del proceso. El objetivo principal es registrar el modelo para desplegarlo más tarde para la inferencia en vivo después del empaquetado. Tampoco es necesario capturar todos los pasos en este proceso concreto. Puedes crear otros procesos que se ejecuten siempre que haya un modelo recién registrado. De este modo, esa canalización no está vinculada a un modelo concreto, sino que puedes reutilizarla para cualquier otro modelo que se entrene con éxito y se registre. La reutilización de componentes y automatización es otro componente crítico de DevOps que funciona bien cuando se aplica a MLOps.
Ahora que los pipelines están desmitificados, podemos ver ciertas mejoras que pueden hacerlos más robustos, controlando manualmente el despliegue de modelos o incluso cambiando la inferencia de un modelo a otro.
Despliegue controlado de los modelos
Hay algunos conceptos de las Implementaciones de servicios web que se adaptan perfectamente a las estrategias de despliegue de modelos en entornos de producción, como la creación de varias instancias de una aplicación de inferencia en vivo para la escalabilidad y el cambio progresivo de un modelo antiguo a otro más reciente. Antes de entrar en algunos de los detalles que engloban la parte de control del despliegue de modelos en producción, merece la pena describir las estrategias en las que entran en juego estos conceptos.
En esta sección hablaré en detalle de dos de estas estrategias. Aunque estas estrategias son similares, tienen un comportamiento particular que puedes aprovechar al realizar la implementación:
-
Implementación azul-verde
-
Implementación canaria
Una implementación azul-verde es una estrategia que introduce una nueva versión en un entorno de ensayo idéntico al de producción. A veces, este entorno de ensayo es el mismo que el de producción, pero el tráfico se enruta de forma diferente (o por separado). Sin entrar en detalles, Kubernetes es una plataforma que permite este tipo de implementación con facilidad, ya que puedes tener las dos versiones en el mismo clúster de Kubernetes, pero enrutando el tráfico a una dirección separada para la versión más nueva ("azul"), mientras que el tráfico de producción sigue yendo a la más antigua ("verde"). La razón de esta separación es que permite realizar más pruebas y garantizar que el nuevo modelo funciona como se espera. Una vez finalizada esta comprobación y cuando ciertas condiciones sean satisfactorias, modifica la configuración para cambiar el tráfico del modelo actual al nuevo.
Existen algunos problemas con las Implementaciones azul-verde, principalmente asociados a lo complicado que puede resultar replicar los entornos de producción. De nuevo, ésta es una de esas situaciones en las que Kubernetes encaja a la perfección, ya que el clúster puede alojar la misma aplicación con diferentes versiones con facilidad.
Una estrategia de implementación canaria es un poco más complicada y algo más arriesgada. Dependiendo de tu nivel de confianza y de la capacidad de cambiar progresivamente la configuración en función de las restricciones, es una forma sólida de enviar modelos a producción. En este caso, el tráfico se dirige progresivamente al modelo más nuevo al mismo tiempo que el modelo anterior está sirviendo predicciones. Así, las dos versiones están activas y procesando peticiones simultáneamente, pero haciéndolo en proporciones diferentes. La razón de este despliegue basado en porcentajes es que puedes habilitar métricas y otras comprobaciones para captar los problemas en tiempo real, permitiéndote dar marcha atrás inmediatamente si las condiciones son desfavorables.
Por ejemplo, supongamos que un nuevo modelo con mayor precisión y sin deriva observada está listo para entrar en producción. Después de que varias instancias de esta nueva versión estén disponibles para empezar a recibir tráfico, haz un cambio de configuración para enviar el 10% de todo el tráfico a la nueva versión. Mientras el tráfico empieza a enrutarse, observas una cantidad desalentadora de errores en las respuestas. Los errores HTTP 500 indican que la aplicación tiene un error interno. Tras investigar un poco, se ve que una de las dependencias de Python que hace la inferencia está intentando importar un módulo que se ha movido, lo que provoca una excepción. Si la aplicación recibe cien peticiones por minuto, sólo diez de ellas habrían experimentado la condición de error. Tras darte cuenta de los errores, cambias rápidamente la configuración para enviar todo el tráfico a la versión más antigua actualmente implementada. Esta operación también se denomina retroceso.
La mayoría de los proveedores de la nube tienen la capacidad de hacer un despliegue controlado de modelos para estas estrategias. Aunque no se trata de un ejemplo totalmente funcional, el SDK de Azure Python puede definir el porcentaje de tráfico de una versión más reciente al realizar la implementación:
fromazureml.core.webserviceimportAksEndpointendpoint.create_version(version_name="2",inference_config=inference_config,models=[model],traffic_percentile=10)endpoint.wait_for_deployment(True)
Lo complicado es que el objetivo de una implementación canaria es aumentar progresivamente hasta que el traffic_percentile esté al 100%. El aumento tiene que producirse al mismo tiempo que se cumplen las restricciones sobre la salud de la aplicación y las tasas de error mínimas (o nulas).
El monitoreo, el registro y las métricas detalladas de los modelos de producción (aparte del rendimiento de los modelos) son absolutamente fundamentales para una estrategia de implementación sólida. Las considero cruciales para la implementación, pero son un pilar básico de las prácticas DevOps robustas que se tratan en el capítulo 6. Además del monitoreo, el registro y las métricas que tienen su propio capítulo, hay otras cosas interesantes que comprobar para la entrega continua. En la siguiente sección, veremos algunas que tienen sentido y aumentan la confianza de desplegar un modelo en producción.
Técnicas de Prueba para la Implementación de Modelos
Hasta ahora, el contenedor construido en este capítulo funciona de maravilla y hace exactamente lo que necesitamos: a partir de unas solicitudes HTTP con un mensaje cuidadosamente elaborado en un cuerpo JSON, una respuesta JSON predice el sentimiento. Un ingeniero experimentado en aprendizaje automático podría haber puesto en marcha la detección de precisión y desviación (tratada en detalle en el Capítulo 6) antes de llegar a la fase de empaquetado del modelo. Supongamos que ya es así y concentrémonos en otras pruebas útiles que puedes realizar antes de implementar un modelo en producción.
Cuando envías una solicitud HTTP al contenedor para producir una predicción, varias capas de software tienen que pasar de principio a fin. A alto nivel, éstas son críticas:
-
El cliente envía una solicitud HTTP, con un cuerpo JSON, en forma de matriz con una sola cadena.
-
Tiene que existir un PUERTO HTTP específico(5000) y un punto final(predict) al que se dirija.
-
La aplicación Python Flask tiene que recibir la carga JSON y cargarla en Python nativo.
-
El tiempo de ejecución de ONNX tiene que consumir la cadena y producir una predicción.
-
Una respuesta JSON con una respuesta HTTP 200 debe contener el valor booleano de la predicción.
Cada uno de estos pasos de alto nivel puede (y debe) probarse.
Controles automatizados
Mientras montaba el contenedor para este capítulo, tuve algunos problemas con el módulo de Python onnxruntime: la documentación no señala (un número de versión exacto) la versión, lo que provocó que se instalara la última versión, que necesitaba argumentos diferentes como entrada. La precisión del modelo era buena, y no pude detectar una deriva significativa. Y, sin embargo, desplegué el modelo sólo para descubrir que estaba totalmente roto una vez consumidas las peticiones.
Con el tiempo, las aplicaciones se vuelven mejores y más resistentes. Otro ingeniero podría añadir la gestión de errores para responder con un mensaje de error cuando se detecten entradas no válidas, y quizás con una respuesta HTTP con un código de error HTTP apropiado junto con un bonito mensaje de error que el cliente pueda entender. Debes probar este tipo de adiciones y comportamientos antes de permitir que un modelo pase a producción.
A veces no se producirá ninguna condición de error HTTP y tampoco habrá trazas de Python. ¿Qué pasaría si hiciera un cambio como el siguiente en la respuesta JSON:
{"positive":"false"}
Sin mirar las secciones anteriores, ¿puedes notar la diferencia? El cambio pasaría desapercibido. La estrategia de implementación canaria llegaría al 100% sin que se detectara ningún error. El ingeniero de aprendizaje automático estaría contento con la alta precisión y la ausencia de deriva. Y, sin embargo, este cambio ha roto por completo la eficacia del modelo. Si no has captado la diferencia, no pasa nada. Me encuentro con este tipo de problemas todo el tiempo, y a veces puedo tardar horas en detectar el problema: en lugar de false (un valor booleano), está utilizando "false" (una cadena).
Ninguna de estas comprobaciones debe ser manual; la verificación manual debe reducirse al mínimo. La automatización debe ser una gran prioridad, y todas las sugerencias que he hecho hasta ahora pueden añadirse como parte de la canalización. Estas comprobaciones pueden generalizarse a otros modelos para su reutilización, pero a alto nivel, pueden ejecutarse en paralelo, como se muestra en laFigura 4-12.
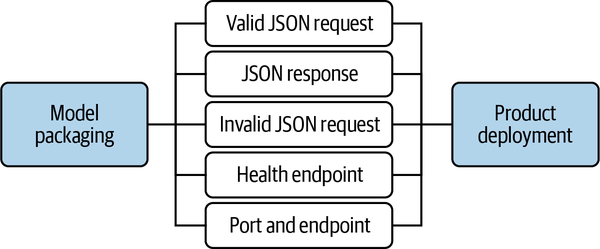
Figura 4-12. Comprobaciones automatizadas
Pelusa
Más allá de algunas de las comprobaciones funcionales que menciono, como el envío de solicitudes HTTP, hay otras comprobaciones más cercanas al código de la aplicación Flask que son mucho más sencillas de implementar, como el uso de un linter(recomiendo Flake8 para Python). Lo mejor sería automatizar todas estas comprobaciones para evitar meterte en problemas cuando llegue el momento del lanzamiento en producción. Independientemente del entorno de desarrollo en el que te encuentres, te recomiendo encarecidamente que habilites un linter para escribir código. Mientras creaba la aplicación Flask, encontré errores al adaptar el código para que funcionara con solicitudes HTTP. Aquí tienes un breve ejemplo de la salida del linter:
$ flake8 webapp/app.py webapp/app.py:9:13: F821 undefined name 'RobertaTokenizer'
Los nombres indefinidos rompen las aplicaciones. En este caso, olvidé importar el RobertaTokenizer del módulo transformers. En cuanto me di cuenta, añadí la importación y lo arreglé. Esto no me llevó más que unos segundos.
De hecho, cuanto antes puedas detectar estos problemas, mejor. Cuando se habla de seguridad en el software, es típico oír "cadena de suministro del software", donde la cadena son todos los pasos desde el desarrollo hasta el envío del código a producción. Y en esta cadena de acontecimientos, hay un empuje constante hacia la izquierda. Si ves estos pasos como una gran cadena, el eslabón más a la izquierda es el desarrollador que crea y actualiza el software, y el final de la cadena (el más a la derecha) es el producto liberado, donde el consumidor final puede interactuar con él.
Cuanto antes puedas desplazar a la izquierda la detección de errores, mejor. Esto se debe a que es más barato y rápido que esperar hasta que esté en producción cuando haya que hacer un rollback.
Mejora continua
Hace un par de años, era el gestor de publicación de un gran software de código abierto. El software era tan complicado de liberar que me llevaba desde dos días hasta una semana entera. Era difícil hacer mejoras, ya que también era responsable de otros sistemas. Una vez, mientras intentaba publicar una versión, siguiendo los distintos pasos para publicar los paquetes, un desarrollador del núcleo me pidió que introdujera un último cambio. En lugar de decir "No" de inmediato, pregunté: "¿Se ha probado ya este cambio?"
La respuesta fue totalmente inesperada: "No seas ridículo, Alfredo, se trata de un cambio de una línea, y es un comentario de documentación en una función. Realmente necesitamos que este cambio forme parte de la versión". El empuje para introducir el cambio vino desde arriba, y tuve que ceder. Añadí el cambio de última hora y corté la publicación.
A la mañana siguiente, los usuarios (y, lo que es más importante, los clientes) se quejaron de que la última versión no funcionaba. Se instalaba, pero no funcionaba. El culpable era el cambio de una línea que, aunque era un comentario dentro de una función, estaba siendo analizado por otro código. Había una sintaxis inesperada en ese comentario, por lo que impedía que la aplicación se iniciara. La historia no pretende reprender al desarrollador. No lo sabía. Todo el proceso fue un momento de aprendizaje para todos los implicados, y ahora estaba claro lo costoso que era este cambio de una sola línea.
A continuación se produjeron una serie de acontecimientos perturbadores. Aparte de reiniciar el proceso de publicación, la fase de pruebas del único cambio llevó otro día (extra). Por último, tuve que retirar los paquetes liberados y rehacer los repositorios para que los nuevos usuarios obtuvieran la versión anterior.
Fue más que costoso. El número de personas implicadas y el gran impacto hicieron que fuera una excelente oportunidad para afirmar que esto no debe volver a permitirse, aunque se trate de un cambio de una sola línea. Cuanto antes se detecte, menos impacto tendrá, y más barato resultará arreglar .
Conclusión
La entrega continua y la práctica de la retroalimentación constante son cruciales para un flujo de trabajo sólido. Como demuestra este capítulo, hay mucho valor en la automatización y la mejora continua del bucle de retroalimentación. Los contenedores de empaquetado, junto con los pipelines y las plataformas CI/CD en general, están pensados para facilitar la adición de más comprobaciones yverificaciones, que tienen por objeto aumentar la confianza del envío de modelos aproducción.
Enviar modelos a producción es el objetivo número uno, pero hacerlo con una confianza muy alta, en un conjunto de pasos resistentes, es a lo que debes aspirar. Tu tarea no termina una vez que los procesos están en marcha. Debes seguir encontrando formas de agradecértelo más adelante haciéndote la siguiente pregunta: ¿qué puedo añadir hoy para hacerme la vida más fácil si este proceso falla? Por último, recomiendo encarecidamente crear estos flujos de trabajo de forma que sea fácil añadir más comprobaciones y verificaciones. Si es difícil, nadie querrá tocarlo, anulando el propósito de un proceso sólido para enviar modelos aproducción.
Ahora que ya dominas la entrega de modelos y el aspecto de la automatización, nos sumergiremos en AutoML y Kaizen en el próximo capítulo.
Ejercicios
-
Crea tu propia aplicación Flask en un contenedor, publícala en un repositorio de GitHub, documéntala minuciosamente y añade Acciones de GitHub para asegurarte de que se compilacorrectamente.
-
Realiza cambios en el contenedor ONNX para que empuje a Docker Hub en lugar de a Paquetes de GitHub.
-
Modifica una canalización de SageMaker para que te pregunte antes de registrar el modelo después de entrenarlo.
-
Utilizando el SDK de Azure, crea un cuaderno Jupyter que aumente el percentil de tráfico que va a un contenedor.
Preguntas de debate sobre el pensamiento crítico
-
Nombra al menos cuatro comprobaciones críticas que puedas añadir para verificar que un modelo empaquetado en un contenedor se construye correctamente.
-
¿Cuáles son las diferencias entre las Implementaciones canaria y verde azulada? ¿Cuál prefieres? ¿Por qué?
-
¿Por qué son útiles las canalizaciones en la nube frente al uso de las Acciones de GitHub? Nombra al menos tres diferencias.
-
¿Qué significa envasar un recipiente? ¿Por qué es útil?
-
¿Cuáles son las tres características de los modelos de aprendizaje automático de paquetes?
Get MLOps prácticos now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

