Chapter 1. The World of Service-Based Architectures
Both microservices architecture and SOA are considered service-based architectures, meaning that they are architecture patterns that place a heavy emphasis on services as the primary architecture component used to implement and perform business and nonbusiness functionality. Although microservices and SOA are very different architecture styles, they share many characteristics.
One thing all service-based architectures have in common is that they are generally distributed architectures, meaning that service components are accessed remotely through some sort of remote-access protocol—for example, Representational State Transfer (REST), Simple Object Access Protocol (SOAP), Advanced Message Queuing Protocol (AMQP), Java Message Service (JMS), Microsoft Message Queuing (MSMQ), Remote Method Invocation (RMI), or .NET Remoting. Distributed architectures offer significant advantages over monolithic and layered-based architectures, including better scalability, better decoupling, and better control over development, testing, and deployment. Components within a distributed architecture tend to be more self-contained, allowing for better change control and easier maintenance, which in turn leads to applications that are more robust and more responsive. Distributed architectures also lend themselves to more loosely coupled and modular applications.
In the context of service-based architecture, modularity is the practice of encapsulating portions of your application into self-contained services that can be individually designed, developed, tested, and deployed with little or no dependency on other components or services in the application. Modular architectures also support the notion of favoring rewrite over maintenance, allowing architectures to be refactored or replaced in smaller pieces over time as the business grows—as opposed to replacing or refactoring an entire application using a big-bang approach.
Unfortunately, very few things in life are free, and the advantages of distributed architectures are no exception. The trade-offs associated with those advantages are, primarily, increased complexity and cost. Maintaining service contracts, choosing the right remote-access protocol, dealing with unresponsive or unavailable services, securing remote services, and managing distributed transactions are just a few of the many complex issues you have to address when creating service-based architectures. In this chapter I’ll describe some of these complex issues as they relate to serviced-based architecture.
Service Contracts
A service contract is an agreement between a (usually remote) service and a service consumer (client) that specifies the inbound and outbound data along with the contract format (XML, JavaScript Object Notation [JSON], Java object, etc.). Creating and maintaining service contracts is a difficult task that should not be taken lightly or treated as an afterthought. As such, the topic of service contracts deserves some special attention in the scope of service-based architecture.
In service-based architecture you can use two basic types of service contract models: service-based contracts and consumer-driven contracts. The real difference between these contract models is the degree of collaboration. With service-based contracts, the service is the sole owner of the contract and is generally free to evolve and change the contract without considering the needs of the service consumers. This model forces all service consumers to adopt new service contract changes, whether or not the service consumers need or want the new service functionality.
Consumer-driven contracts, on the other hand, are based on a closer relationship between the service and the service consumers. With this model there is strong collaboration between the service owner and the service consumers so that needs of the service consumers are taken into account with respect to the contracts that bind them. This type of model generally requires the service to know who its consumers are and how the service is used by each service consumer. Service consumers are free to suggest changes to the service contract, which the service can either adopt or reject depending on how it affects other service consumers. In a perfect scenario, service consumers deliver tests to the service owner so that if one consumer suggests a change, tests can be executed to see if the change breaks another service consumer. Open source tools such as Pact and Pacto can help with maintaining and testing consumer-driven contracts.
Another critical topic within the context of service contracts is contract versioning. Let’s face it—at some point the contracts binding your services and service consumers are bound to change. The degree and magnitude of this change are largely dependent on how those changes affect each service consumer and the backward compatibility supported by the service with respect to the contract changes.
Contract versioning allows you to roll out new service features that involve contract changes and at the same time provide backward compatibility for service consumers that are still using prior contracts. Perhaps one of the most important pieces of advice in this chapter is to plan for contract versioning from the very start of your development effort, even if you don’t think you’ll need it—because eventually you will. While several open source and commercial frameworks are available to help you manage and implement contract-versioning strategies, you can use two basic techniques to implement your own custom contract-versioning strategy: homogeneous versioning and heterogeneous versioning.
Homogeneous versioning involves using contract version numbers in the same service contract. Notice in Figure 1-1 that the contract used by service consumer A and service consumer B are both the same circle shape (signifying the same contract) but contain different version numbers. A simple example of this might be an XML-based contract that represents an order for some goods, with a contract version number 1.0. Let’s say a newer version (version 1.1) is released containing an additional field used to provide delivery instructions in the event the recipient is not at home when the order is delivered. In this case the original contract (version 1.0) can remain backward compatible by making the new delivery-instructions field optional.

Figure 1-1. Contract version numbers
Heterogeneous versioning involves supporting multiple types of contracts. This technique is closer to the concept of consumer-driven contracts described earlier in this section. With this technique, as new features are introduced, new contracts are introduced as well that support that new functionality. Notice the difference between Figure 1-1 and Figure 1-2 in terms of the service contract shape. In Figure 1-2, service consumer A communicates using a contract represented by a circle, whereas service consumer B uses an entirely different contract represented by the triangle. In this case, backward compatibility is supplied by different contracts rather than versions of the same contract. This is a common practice in many JMS-based messaging systems, particularly those leveraging the ObjectMessage message type. For instance, a Java-based receiver can interrogate the payload object sent through the message using the instanceof keyword and take appropriate action based on the object type. Alternatively, XML payload can be sent through a JMS TextMessage that contains entirely different XML schema for each contract, with a message property indicating the corresponding XML schema associated with the XML payload.

Figure 1-2. Multiple contracts
Providing backward compatibility is the real goal of contract versioning. Maintaining a mindset that services must support multiple versions of a contract (or multiple contracts) will allow your development teams to quickly deploy new features and other changes without fear of breaking the existing contracts with other service consumers. Keep in mind that it is also possible to combine these two techniques by supporting multiple version numbers for different contract types.
One last thing about service contracts with respect to contract changes: be sure to have a solid service consumer communication strategy in place from the start so that service consumers know when a contract changes or a particular version or contract type is no longer supported. In many circumstances this may not be feasible because the number of internal and/or external service consumers is large. In this situation an integration hub (i.e., messaging middleware) can help by providing an abstraction layer to transform service contracts between services and service consumers. I’ll be talking more about this capability later in this report in the “Contract Decoupling” section in Chapter 4.
Service Availability
Service availability and service responsiveness are two other considerations common to all service-based architectures. Although both of these topics relate to the ability of the service consumer to communicate with a remote service, they have slightly different meanings and are addressed by service consumers in different ways.
Service availability refers to the ability of a remote service to accept requests in a timely manner (e.g., establishing a connection to the remote service). Service responsiveness refers to the ability of the service consumer to receive a timely response from the service. The diagram in Figure 1-3 illustrates this difference.
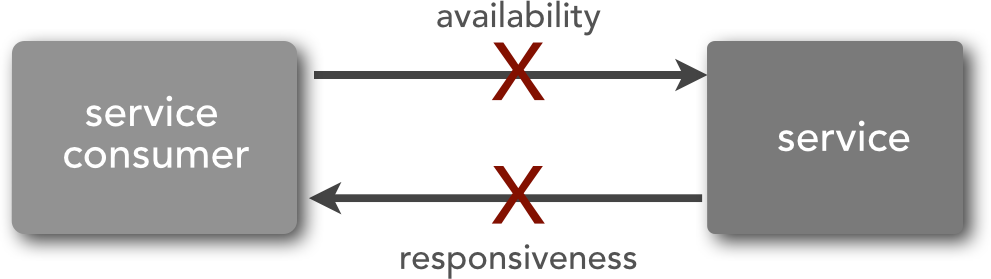
Figure 1-3. Service availability and responsiveness
Although the end result of these error conditions is the same (the service request cannot be processed), they are handled in different ways. Since service availability is related to service connectivity, there is not much a service consumer can do except to retry the connection for a set number of times or queue the request for later processing if possible.
Service responsiveness is much more difficult to address. Once you successfully send a request to a service, how long should you wait for a response? Is the service just slow, or did something happen in the service to prevent the response from being sent?
Addressing timeout conditions can be one of the more challenging aspects of remote service connectivity. A common way to determine reasonable timeout values is to first establish benchmarks under load to get the maximum response time, and then add extra time to account for variable load conditions. For example, let’s say you run some benchmarks and find that the maximum response time for a particular service request is 2,000 milliseconds. In this case you might double that value to account for high load conditions, resulting in a timeout value of 4,000 milliseconds.
Although this may seem like a reasonable solution for calculating a service response timeout, it is riddled with problems. First of all, if the service really is down and not running, every request must wait four seconds before determining that the service is not responding. This is inefficient and annoying to the end user of the service request. Another problem is that your benchmarks may not have been accurate, and under heavy load the service response is actually averaging five seconds rather than the four seconds you calculated. In this case the service is in fact responding, but the service consumer will reject every request because the timeout value is set too low.
A popular technique to address this issue is to use the circuit breaker pattern. If the service is not responding in a timely manner (or not at all), a software circuit breaker will be thrown so that service consumers don’t have to waste time waiting for timeout values to occur. The cool thing is that unlike a physical circuit breaker, this pattern can be implemented to reset itself when the service starts responding or becomes available. There are numerous open-source implementations of the circuit breaker pattern, including Ribbon from Netflix. You can read more about the circuit breaker pattern in Michael Nygard’s book Release It! (Pragmatic Bookshelf).
When dealing with timeout values, try to avoid the use of global timeout values for every request. Instead, consider using context-based timeout values, and always make these externally configurable so that you can respond quickly for varying load conditions without having to rebuild or redeploy the application. Another option is to create “smart timeout values” embedded in your code that can adjust themselves based on varying load conditions. For example, the application could automatically increase the timeout value in response to heavy load or network issues. As load decreases and response times become faster, the application could then calculate the average response time for a particular request and lower the timeout value accordingly.
Security
Because services are generally accessed remotely in service-based architectures, it is important to make sure the service consumer is allowed to access a particular service. Depending on your situation, service consumers may need to be both authenticated and authorized. Authentication refers to whether the service consumer can connect to the service, usually through sign-on credentials using a username and password. In some cases authentication is not enough: the fact that service consumers can connect to a service doesn’t necessarily mean that they can access all of the functionality in that service. Authorization refers to whether or not a service consumer is allowed to access specific business functionality within a service.
Security was a major issue with early SOA implementations. Functionality that used to be located in a secure silo-based application was suddenly available globally to the entire enterprise. This issue created a major shift in how we think about services and how to protect them from consumers who should not have access to them.
With microservices, security becomes a challenge primarily because no middleware component handles security-based functionality. Instead, each service must handle security on its own, or in some cases the API layer can be made more intelligent to handle the security aspects of the application. One security design I have seen implemented in microservices that works well is to delegate authentication to a separate service and place the responsibility for authorization in the service itself. Although this design could be modified to delegate both authentication and authorization to a separate security service, I prefer encapsulating the authorization in the service itself to avoid chattiness with a remote security service and to create a stronger bounded context with fewer external dependencies.
Transactions
Transaction management is a big challenge in service-based architectures. Most of the time when we talk about transactions we are referring to the ACID (atomicity, consistency, isolation, and durability) transactions found in most business applications. ACID transaction are used to maintain database consistency by coordinating multiple database updates within a single request so that if an error occurs during processing, all database updates are rolled back for that request.
Given that service-based architectures are generally distributed architectures, it is extremely difficult to propagate and maintain a transaction context across multiple remote services. As illustrated in Figure 1-4, a single service request (represented by the box next to the red X) may need to call multiple remote services to complete the request. The red X in the diagram indicates that it is not feasible to use an ACID transaction in this scenario.

Figure 1-4. Service transaction management
Transaction issues are much more prevalent in SOA because, unlike in microservices architecture, multiple services are typically used to perform a single business request. I discuss this in more detail in the “Service Orchestration” section of Chapter 3.
Rather than use ACID transactions, service-based architectures rely on BASE transactions. BASE is a family of styles that include basic availability, soft state, and eventual consistency. Distributed applications relying on BASE transactions strive for eventual consistency in the database rather than consistency at every transaction. A classic example of BASE transactions is making a deposit into an ATM. When you deposit cash into your account through an ATM, it can take from several minutes to several hours for the deposit to appear in your account. In other words, there is a soft transition state in which the money has left your hands but has not reached your bank account. We are tolerant of this time lag and rely on soft state and eventual consistency, knowing and trusting that the money will reach our account at some point soon. Batch jobs also sometimes rely on eventual consistency when seen from a holistic system view.
Switching to the world of service-based architectures requires us to change our way of thinking about transactions and consistency. In situations in which you simply cannot rely on eventual consistency and soft state and require transactional consistency, you can make your services more coarse-grained to encapsulate the business logic into a single service, allowing the use of ACID transactions to achieve consistency at the transaction level. You can also leverage event-driven techniques to push notifications to consumers when the state of a request has become consistent. This technique adds a significant amount of complexity to an application but helps in managing transactional state when BASE transactions are used.
Too Much Complexity?
Service-based architectures are a significant improvement over monolithic applications, but as you can see they involve many considerations—including service contracts, availability, security, and transactions (to name a few). Unfortunately, moving to a service-based architecture approach such as microservices or SOA involves trade-offs. For this reason, you shouldn’t embark on a service-based architecture solution unless you are ready and willing to address the many issues facing distributed computing.
The issues identified in this chapter are complex, but they certainly aren’t showstoppers. Most teams using service-based architectures are able to successfully address and overcome these challenges through a combination of open source tools, commercial tools, and custom solutions.
Are service-based architectures complex? Absolutely. However, with added complexity come additional characteristics and capabilities that will make your development teams more productive, produce more reliable and robust applications, reduce overall costs, and improve overall time to market. In the next three chapters I walk you through those capabilities by comparing microservices and SOA to help you decide which architecture pattern is right for you.
Get Microservices vs. Service-Oriented Architecture now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

