Chapter 4. Outer Architecture
The outer architecture is the space between microservices and is by far the most difficult part. As we’ve pointed out throughout this book, microservices is a tradeoff from inner complexity to outer complexity. Broadly speaking, the outer architecture of microservices is the space between individual microservices. Think of it as anything that is not the responsibility of an individual microservice team.
Outer architecture includes all of the infrastructure on which individual microservices are deployed, discovering and connecting to microservices, and releasing new versions of microservices, communicating between microservices, and security. It’s a wide area that can become complex.
Outer architecture is best handled by a single team that is composed of your best programmers. You don’t need a big team—you need a small team of people who are really smart.
There is no number of ordinary eight-year-olds who, when organized into a team, will become smart enough to beat a grandmaster in chess.
Your goal should be to free up each microservice team to focus on just its own microservice.
Part of what complicates outer architecture is that most of the technology is brand new. The term “microservices” wasn’t used widely until 2013. The technology that powers the inner architecture is all widely established. After all, an individual microservice is just a small application.
Software-Based Infrastructure
Although each microservice team can choose its own programming language, runtime, datastore, and other upper-stack elements, all teams should be constrained to using the same cloud provider. The major cloud platforms are all “good enough” these days, both in terms of technical and commercial features.
The first major benefit is that multiple teams can access the same shared resources, like messaging, API gateways, and service discovery. Even though each team has the ability to make some choices independently, you generally want to standardize on some things across teams; for example, the messaging system. You wouldn’t want 100 different teams each using its own messaging stack—it just wouldn’t work. Instead, a centralized team must choose one implementation and have all of the microservices teams use it. It doesn’t make sense to fragment at that level and it’s difficult to implement. An added advantage of everyone using the same implementations is that latency tends to be near zero.
By standardizing on a cloud vendor, your organization has the ability to build competency with one of them. Public clouds are not standardized and specialized knowledge is required to fully use each cloud. Individuals can build competency, which is applicable regardless of the team to which they’re assigned. Teams can also publish blueprints and best practices that others can use to get started.
Working across clouds adds unnecessary complexity and you should avoid doing it.
Container Orchestration
Containers are used by individual teams to build and deploy their own microservices, as part of inner architecture. Container orchestration is the outer architecture of microservices.
Simply put, container orchestration is the system that runs individual containers on physical or virtual hosts. Managing a handful of containers from the command line is fairly straightforward. You SSH into the server, install Docker, run your container image, and expose your application’s host/port. Simple. But that doesn’t work with any more than a handful of containers. You might have dozens, hundreds or even thousands of microservices, with each microservice having multiple versions and multiple instances per version. It just doesn’t scale.
These systems can also be responsible for the following:
-
Releasing new versions of your code
-
Deploy the code to a staging environment
-
Run all integration tests
-
Deploy the code to a production environment
-
Service registry—making a microservice discoverable and routing the caller to the best instance
-
Load balancing—both within a node and across multiple nodes
-
Networking—overlay networks and dynamic firewalls
-
Autoscaling—adding and subtracting containers to deal with load
-
Storage—create and attach existing volumes to containers
-
Security—identification, authorization and authentication
Each of these topics will be covered in greater depth in the sections that follow.
Container orchestration is essentially a new form of Platform-as-a-Service (PaaS) that many use in combination with microservices. The container itself becomes the artifact that the container orchestration system manages, which makes it extremely flexible. You can put anything you want in a container. Traditionally, a PaaS is considered “opinionated” in that it forces you do things using a very prescribed approach. Container orchestration systems are much less opinionated and are more flexible.
Besides flexibility, infrastructure utilization is a top driving factor for container orchestration adoption. Virtual Machines (VMs), even in the cloud, have fixed CPU and memory, whereas multiple containers deployed to a single host share CPU and memory. The container orchestration system is responsible for ensuring that each host (whether physical or virtual) isn’t overtaxed. Utilization can be kept at 90 or 95 percent, whereas VMs are typically 10 percent utilized. If utilization of a host reaches near 100 percent, containers can be killed and restarted on another, less-loaded host.
Container orchestration, like the cloud, is a system that every team should be forced to use. These systems are extremely difficult to set up, deploy, and manage. After it is set up, the marginal cost to add a new microservice is basically zero. Each microservice team is able to easily use the system.
Let’s explore some of the many roles that container orchestration systems can play.
Releasing Code
Each team must continually release new versions of its code. Each team is responsible for building and deploying its own containers, but they do so using the container orchestration system. Every team should release code using the same process. The artifacts should be containers that, like microservices, do only one thing. For example, your application should be in one container and your datastore should be in another. Container orchestration systems are all built around the assumption of a container running just one thing.
To begin, you need to build a container image, inclusive of code/configuration/runtime/system libraries/operating system/start-and-stop hooks. As we previously discussed, this is best done through a Dockerfile YAML that is checked in to source control and managed like source code. The Dockerfile should be tested on a regular basis. It should be upgraded. The start/stop hook scripts should be tested, too.
After you’ve built your image, you need to define success/failure criteria. For example, what automated tests can you run to verify that the deployment was successful? It’s best to throughly test out every API, both through the API and through any calling clients. What constitutes a failure? If an inconsequential function isn’t working, should the entire release be pulled?
Then, you need to define your rollout strategy. Are you replacing an existing implementation of a microservice that’s backward compatible with the existing version? Or, are you rolling out a new major version that is not backward compatible? Should the deployment proceed in one operation (often called “blue/green”), or should it be phased in gradually, at say 10 percent per hour (often called “canary”)? How many regions should it be deployed to? How many fault domains? How many datacenters? Which datacenters?
Following the deployment, the container orchestration system then must update load balancers with the new routes, cutover traffic, and then run the container’s start/stop hooks.
As you can see, this all can become quite complicated. With a proper container orchestration system and some experience, releases can be as carried out often as every few hours. Again, it takes a small team of very specialized people to build the container orchestration system. Then, individual teams can use it.
Service Registry
When the container orchestration system places a container on a host, clients need to be able to call it. But there are a few complicating factors:
-
Containers might live for only a few seconds, minutes, or hours. They are ephemeral by definition.
-
Containers often expose nonstandard ports. For example, you might not always be able to hit HTTP over port 80.
-
A microservice is likely to have many major and minor versions live at the same time, requiring the client to state a version in the request.
-
There are dozens, hundreds or even thousands of different microservices.
There are two basic approaches: client-side and server-side.
The client-side approach is straightforward conceptually. The client (be it an API gateway, another microservice, or a user interface) queries a standalone service registry to ask for the path to a fully qualified endpoint. Again, the client should be able to specify the major and possibly the minor version of the microservice for which it’s looking. The client will get back a fully qualified path to an instance of that microservice, which it can then call over and over again.
The main benefit of this approach is that there are no intermediaries between the client and the endpoint. Calls go directly from the client to the endpoint without traversing through a proxy. Also, clients can be more rich in how they query for an endpoint. The query could be a formal JSON document stating version and other quality-of-service preferences, depending on the sophistication of your service registry.
The major drawback of this approach is that the client must “learn” how to query each microservice, which is a form of coupling. It’s not transparent. Each microservice will have its own semantics about how it needs to be queried because each microservice implementation will differ. Another issue is that the client will need to requery for an endpoint if the one it’s communicating with directly fails.
Although the client-side approach can be helpful, the server-side method is often preferable due to its simplicity and extensive use in the world today. This approach is to basically use a load balancer. When the container orchestration places a container, it registers the endpoint with the load balancer. The client can make some requests about the endpoint by specifying HTTP headers or similar.
Unlike client-side load balancing, the client doesn’t need to know how to query for an endpoint. The load balancer just picks the best endpoint. It’s very simple.
Load Balancing
If you use a server-side service registry, you’ll need a load balancer. Every time a container is placed, the load balancer needs to be updated with the IP, port and other metadata of the newly-created endpoint.
There are two levels of load balancing within a container orchestration system: local and remote.
Local load balancing is load balancing within a single host. A host can be a physical server or it can be virtualized. A host runs one or more containers. Your container orchestration system might be capable of deploying instances of microservices that regularly communicate to the same physical host. Figure 4-1 presents an overview.
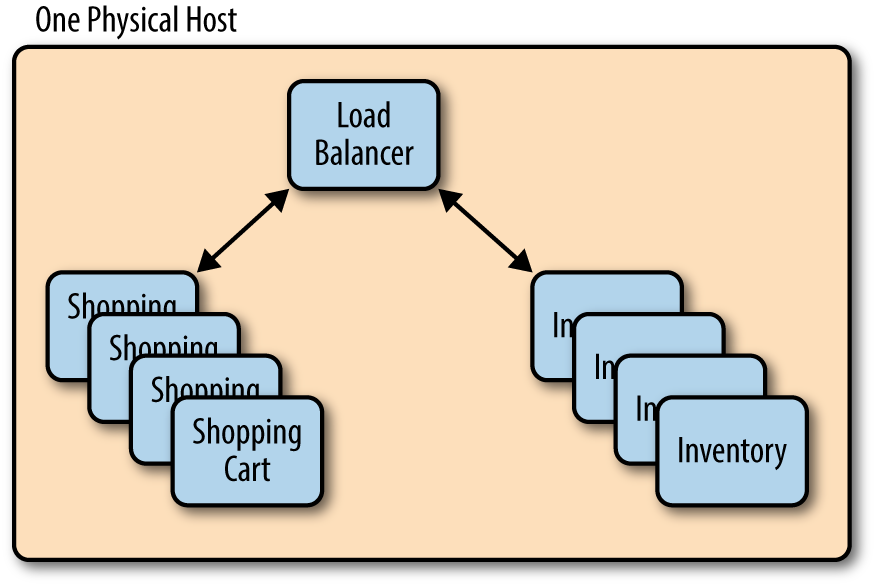
Figure 4-1. Local load balancing within a single host
By being told or by learning that certain microservices communicate, and by intelligently placing those containers together on the same host, you can minimize the vast majority of network traffic because most of it is local to a single host. Networking can also be dramatically simplified because it’s all over localhost. Latency is zero, which helps improve performance.
In addition to local load balancing, remote load balancing is what you’d expect. It’s a standalone load balancer that is used to route traffic across multiple hosts.
Look for products specifically marketed as “API load balancers.” They’re often built on traditional web servers, but they are built more specifically for APIs. They can support identification, authentication, and authorization-related security concerns. They can cache entire responses where appropriate. And finally, they have better support for versioning.
Networking
Placed on a physical host, the container needs to join a network. One of the benefits of the modern cloud is that everything is just software, including networks. Creating a network is now as simple as invoking it, as shown here:
$ docker network create pricing_microservice_networkWith this new “pricing_microservice_network” network created, you can run a container and hook up its network to the container:
$docker run -itd corp/pricing_microservice --network=pricing_microservice_network --name Pricing Microservice
Of course, container orchestration does this all at scale, which is part of the value. Your networking can become quite advanced depending on the container orchestration you use. What matters is that you define separate, isolated networks for each tier of each microservice, as demonstrated in Figure 4-2.
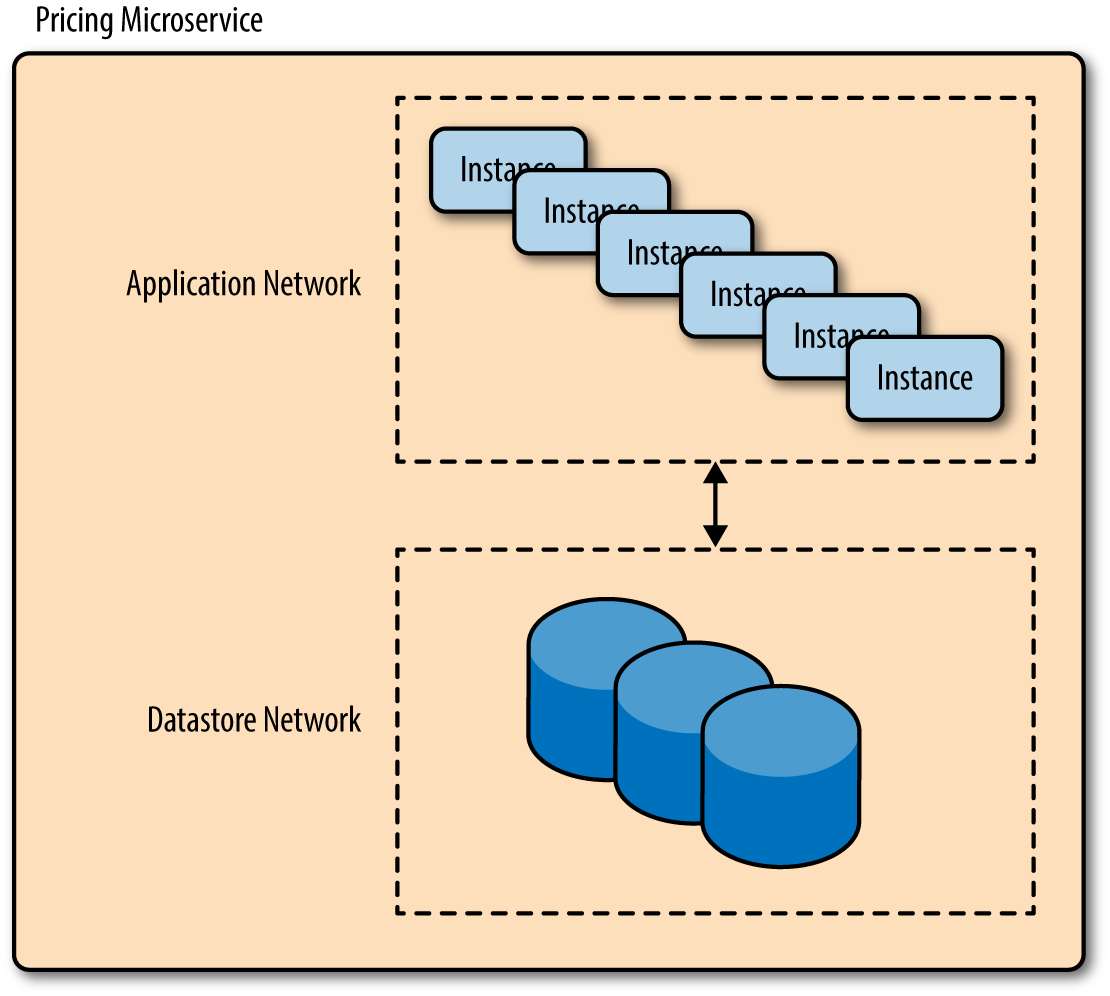
Figure 4-2. Software-based overlay networks are required for full isolation and proper bulkheading
Proper use of overlay networks is another form of bulkheading, which limits the damage someone can do if they break into a network. Someone can break into your Inventory microservice’s application network and not have access to the Payment microservice’s database network.
As part of networking, container orchestration can also deploy software-based firewalls. By default, there should be absolutely no network connectivity between microservices. But if your shopping cart microservice needs to pull up-to-date inventory before checkout, you should configure your container orchestration system to automatically expose port 443 on your inventory microservice and permit only the Shopping Cart microservice to call it over Transport Layer Security (TLS). Exceptions should be made on a per-microservice basis. You would never set up a microservice to be exposed to accept traffic from any source.
Finally, you want to ensure that the transport layer between microservices is secured by using TLS or alternate. For example, never allow plain HTTP traffic within your network.
Autoscaling
Commerce is unique in the spikiness of traffic. Figure 4-3 shows the number of page views per second over the course of the month of November for a leading US retailer:
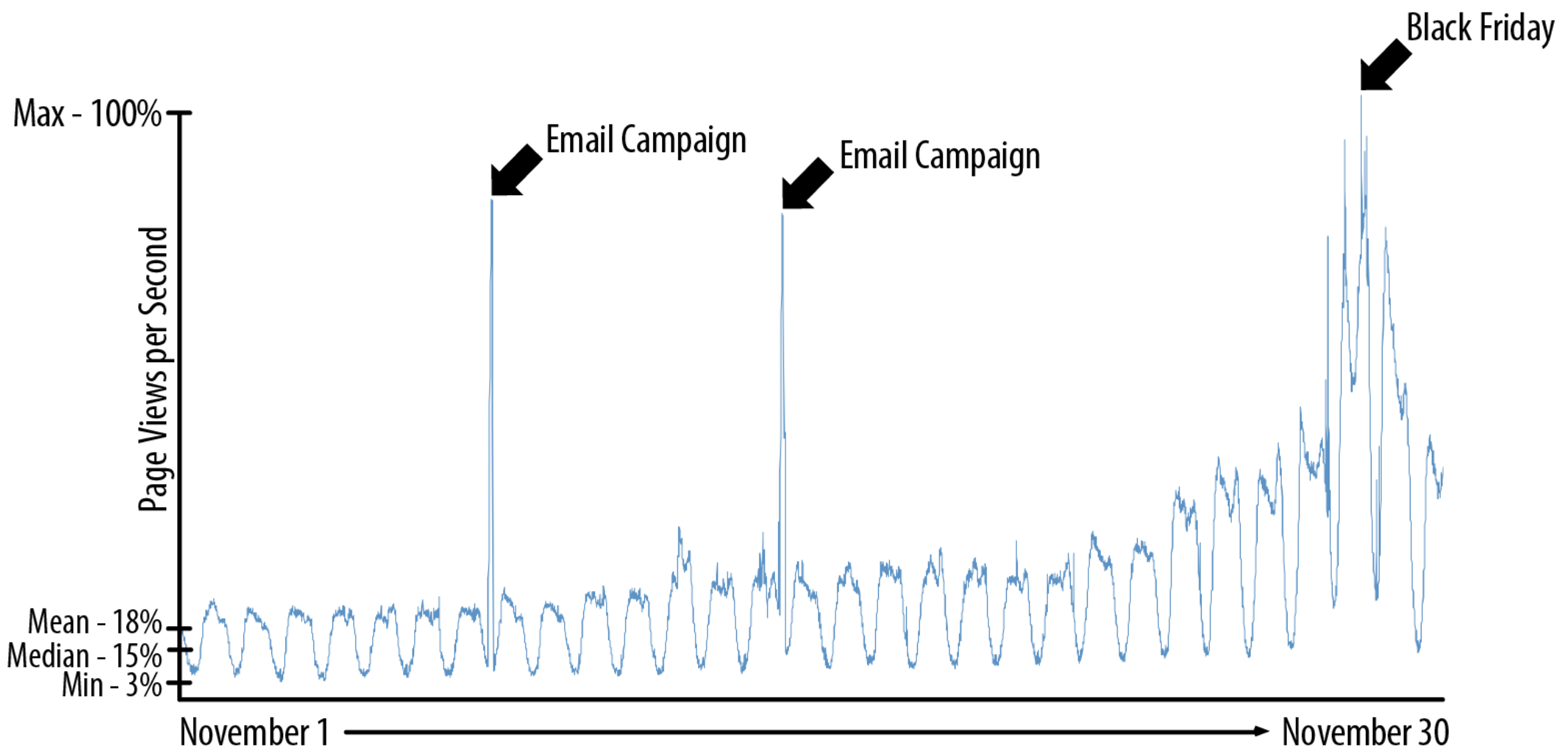
Figure 4-3. Commerce traffic is spiky
This is only web traffic. If this retailer were to be fully omnichannel, the spikes would be even more dramatic.
Before cloud and containers, this problem was handled by over-provisioning so that at steady state the system would be a few percent utilized. This practice is beyond wasteful and is no longer necessary.
The cloud and its autoscaling capabilities help but VMs take a few minutes to spin up. Spikes of traffic happen over just a few seconds, when a celebrity with 50 million followers publishes a link to your website over social media. You don’t have minutes.
Containers help because they can be provisioned in just a few milliseconds. The hosts on which the containers run are preprovisioned already. The container orchestration system just needs to instantiate some containers.
Note that autoscaling needs to be version-aware. For example, versions 2.23 and 3.1 of your pricing microservice need to be individually autoscaled.
Storage
Like networking, storage is all software-defined, as well.
Containers themselves are mostly immutable. You shouldn’t write any files to the local container. Anything persistent should be written to a remote volume that is redundant, highly available, backed up, and so on. Those remote volumes are often cloud-based storage services.
Defining volumes for each microservice and then attaching the right volumes to the right containers at the right place is a tricky problem.
Security
Network-level security is absolutely necessary. But you need an additional layer of security on top of that.
There are three levels: identification, authentication, and authorization. Identification forces every user to identify itself. Users can be humans, user interfaces, API gateways, or other microservices. Identification is often through a user name or public key. After a user has identified itself, the user must then be authenticated. Authentication verifies that the user is who it claims it is. Authentication often occurs through a password or a private key. After it has been identified and authenticated, a user must have authorization to perform an action.
Every caller of a microservice must be properly identified, authenticated, and authorized, even “within” the network. One microservice can be compromised. You don’t want someone launching an attack from the compromised microservice.
API Gateway
A web page or screen on a mobile device might require retrieving data from dozens of different microservices. Each of those clients will need data tailored to it. For example, a web page might display 20 of a product’s attributes but an Apple Watch might display only one.
You’ll want an API gateway of some sort to serve as the intermediary, as depicted in Figure 4-4.
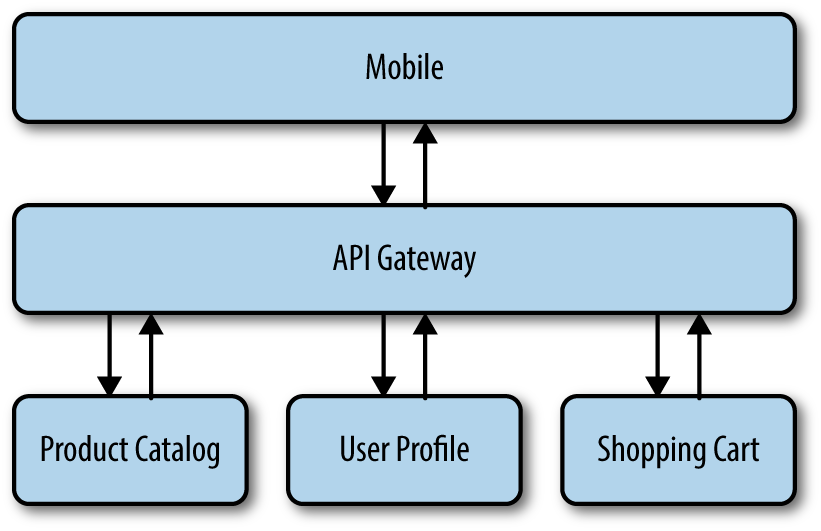
Figure 4-4. Aggregator pattern
The client makes the call to the API gateway and the API gateway makes concurrent requests to each of the microservices required to build a single response. The client gets back one tailored representation of the data. API gateways are often called “Backends for your frontend.”
When you call APIs, you need to query only for what you want. A product record might have 100 properties. Some of those properties are only relevant to the warehouse. Some are only relevant to physical stores. Remember, microservices are meant to be omnichannel. When you want to display a product description on an Apple Watch, you don’t want the client to retrieve all 100 properties. You don’t even want the API gateway to retrieve those 100 properties from the Product microservice because of the performance hit. Instead, each layer should be making API calls (client → API gateway, API gateway → each microservice) that specify which properties to return. This too creates coupling because the layer above now needs to know more details about your service. But it’s probably worth it.
The issue with API gateways is that they become tightly coupled monoliths because they need to know how to interact with every client (dozens) and every microservice (dozens, hundreds or even thousands). The very problem you sought to remedy with microservices can reappear if you’re not careful.
Eventing
We’ve mostly discussed API calls into microservices. Clients, API gateways, and other microservices might synchronously call into a microservice and ask for the current inventory level for a product, or for a customer’s order history, for example.
But behind the synchronous API calls, there’s an entire ecosystem of data that’s being passed around asynchronously. Every time a customer’s order is updated in the Order microservice, a copy should go out as an event. Refunds should be thrown up as events. Eventing is far better than synchronous API calls because it can buffer messages until the microservice is able to process them. It prevents outages by reducing tight coupling.
In addition to actual data belonging to microservices, system events are also represented as microservices. Log messages are streamed out as events—the container orchestration system should send out an event every time a container is launched; every time a healthcheck fails, an event should go out. Everything is an event in a microservices ecosystem.
Note
Why is it called “eventing” and not “messaging”? An event is essentially a message, but with one key difference: volume. Traditionally, messages were used exclusively to pass data. In a microservices ecosystem, everything is an event. Modern eventing systems can handle millions or tens of millions of events per second. Messaging is meant for much lower throughput. Although this is more characteristic of implementations, normal messaging tends to be durable and ordered. It’s usually brokered. Eventing is often unordered and often nonbrokered.
A key challenge with Service Oriented Architecture (SOA) is that messages were routed through a centralized Enterprise Service Bus (ESB), which was too “intelligent.”
The microservice community favours an alternative approach: smart endpoints and dumb pipes.
In this model, the microservices themselves hold all of the intelligence—not the “pipes,” like an ESB. In a microservices ecosystem, events shouldn’t be touched between the producer and consumer. Pipes should be dumb.
Idempotency is also an important concept in microservices. It means that an event can be delivered and consumed more than once and it will not change the output.
This example is not idempotent:
<credit><amount>100</amount><forAccount>1234</account></credit>
This event is idempotent:
<credit><amount>100</amount><forAccount>1234</account>*<creditMemoID>4567</creditMemoId>*</credit>
Summary
Microservices is revolutionizing how commerce platforms are built by allowing dozens, hundreds, or even thousands of teams to seamlessly work in parallel. New features can be released in hours rather than months.
As with any technology, there are drawbacks. Microservices does add complexity, specifically outer complexity. The enabling technology surrounding microservices is rapidly maturing and will become easier over time.
Overall, microservices is probably worth it if your application is sufficiently complex and you have the organizational maturity. Give it a try. It’s a new world out there.
Get Microservices for Modern Commerce now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

