YOLO’s detection mechanism is based on a single Convolutional Neural Network (CNN) that simultaneously predicts multiple bounding boxes for objects and the probability of detection of a given object class in each bounding box. The following images illustrate this methodology:
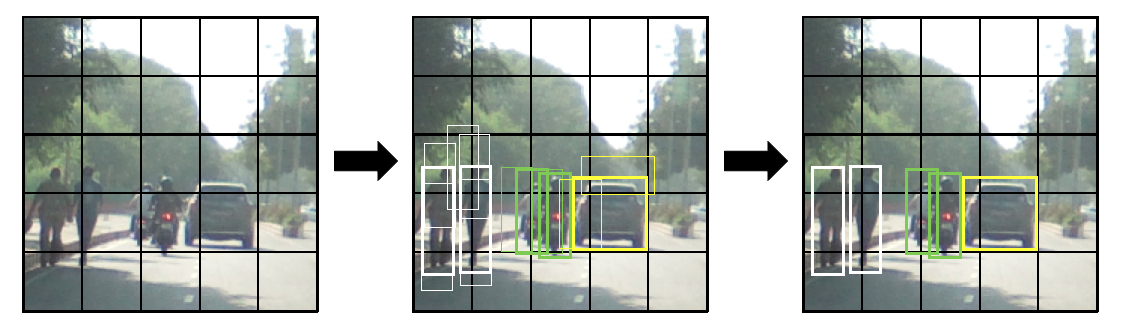
The preceding photos show the three major steps, from the development of bounding boxes to the use of non-max suppression and the final bounding boxes. The detailed steps to this are as follows:
- The CNN in YOLO uses features from the entire image to predict each bounding box. So, the prediction is global, rather than local.
- The entire ...

