Kapitel 1. Maschinelles Lernen im Finanzwesen: Die Landschaft
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Maschinelles Lernen verspricht, große Teile des Finanzwesens aufzurütteln
The Economist (2017)
Es gibt eine neue Welle des maschinellen Lernens und der Datenwissenschaft im Finanzwesen, und die damit verbundenen Anwendungen werden die Branche in den nächsten Jahrzehnten verändern.
Derzeit setzen die meisten Finanzunternehmen, darunter Hedgefonds, Investment- und Privatkundenbanken sowie Fintech-Firmen, maschinelles Lernen ein und investieren stark in dieses Thema. In Zukunft werden die Finanzinstitute immer mehr Experten für maschinelles Lernen und Data Science benötigen.
Maschinelles Lernen im Finanzwesen ist in letzter Zeit aufgrund der Verfügbarkeit großer Datenmengen und erschwinglicherer Rechenleistung immer wichtiger geworden. Der Einsatz von Data Science und maschinellem Lernen nimmt in allen Bereichen des Finanzwesens exponentiell zu.
Der Erfolg des maschinellen Lernens im Finanzbereich hängt vom Aufbau einer effizienten Infrastruktur, der Verwendung der richtigen Werkzeuge und der Anwendung der richtigen Algorithmen ab. Die Konzepte, die mit diesen Bausteinen des maschinellen Lernens im Finanzbereich zusammenhängen, werden in diesem Buch demonstriert und angewandt.
In diesem Kapitel geben wir eine Einführung in die aktuelle und zukünftige Anwendung des maschinellen Lernens im Finanzbereich, einschließlich eines kurzen Überblicks über die verschiedenen Arten des maschinellen Lernens. Dieses Kapitel und die beiden folgenden dienen als Grundlage für die Fallstudien, die im Rest des Buches vorgestellt werden.
Aktuelle und zukünftige Anwendungen des maschinellen Lernensim Finanzwesen
Werfen wir einen Blick auf einige vielversprechende Anwendungen des maschinellen Lernens im Finanzwesen. Die in diesem Buch vorgestellten Fallstudien decken alle hier genannten Anwendungen ab.
Algorithmischer Handel
Algorithmischer Handel (oder einfach Algo-Trading) ist der Einsatz von Algorithmen zur autonomen Durchführung von Handelsgeschäften. Die Ursprünge des algorithmischen Handels reichen bis in die 1970er Jahre zurück. Der algorithmische Handel (der manchmal auch als automatisiertes Handelssystem bezeichnet wird, was wohl eine genauere Beschreibung ist) beinhaltet den Einsatz von automatisierten, vorprogrammierten Handelsanweisungen, um extrem schnelle, objektive Handelsentscheidungen zu treffen.
Maschinelles Lernen wird den algorithmischen Handel auf ein neues Niveau heben. Es können nicht nur fortschrittlichere Strategien eingesetzt und in Echtzeit angepasst werden, sondern auf maschinellem Lernen basierende Techniken bieten auch noch mehr Möglichkeiten, besondere Einblicke in Marktbewegungen zu gewinnen. Die meisten Hedgefonds und Finanzinstitute geben ihre auf maschinellem Lernen basierenden Handelsansätze nicht offen bekannt (aus gutem Grund), aber maschinelles Lernen spielt eine immer wichtigere Rolle bei der Kalibrierung von Handelsentscheidungen in Echtzeit.
Portfolio Management und Robo-Advisors
Asset- und Wealth-Management-Firmen erforschen potenzielle Lösungen für künstliche Intelligenz (KI), um ihre Investitionsentscheidungen zu verbessern und ihre historischen Datenbestände zu nutzen.
Ein Beispiel dafür ist der Einsatz von Robo-Advisors, Algorithmen, die ein Finanzportfolio auf die Ziele und die Risikotoleranz des Nutzers abstimmen. Außerdem bieten sie automatisierte Finanzberatung und Service für Endanleger und Kunden.
Der Nutzer/die Nutzerin gibt seine/ihre finanziellen Ziele (z. B. im Alter von 65 Jahren mit 250.000 USD Ersparnissen in Rente zu gehen), sein/ihr Alter, sein/ihr Einkommen und sein/ihr aktuelles Vermögen ein. Der Berater (der Allokator) verteilt dann die Investitionen auf verschiedene Anlageklassen und Finanzinstrumente, um die Ziele des Nutzers zu erreichen.
Das System passt sich dann an die veränderten Ziele des Nutzers und an die Marktveränderungen in Echtzeit an und versucht so, immer die beste Lösung für die ursprünglichen Ziele des Nutzers zu finden. Robo-Advisors haben bei Verbrauchern, die keinen menschlichen Berater brauchen, um sich beim Investieren wohl zu fühlen, stark an Bedeutung gewonnen.
Betrugsaufdeckung
Betrug ist ein massives Problem für Finanzinstitute und einer der wichtigsten Gründe, maschinelles Lernen im Finanzwesen einzusetzen.
Aufgrund der hohen Rechenleistung, der häufigen Internetnutzung und der zunehmenden Menge an Unternehmensdaten, die online gespeichert werden, besteht derzeit ein erhebliches Datensicherheitsrisiko. Während frühere Systeme zur Aufdeckung von Finanzbetrug in hohem Maße von komplexen und robusten Regelwerken abhingen, geht die moderne Betrugserkennung über das Befolgen einer Checkliste von Risikofaktoren hinaus - sie lernt aktiv und passt sich an neue potenzielle (oder reale) Sicherheitsbedrohungen an.
Maschinelles Lernen ist ideal geeignet, um betrügerische Finanztransaktionen zu bekämpfen. Denn maschinelle Lernsysteme können riesige Datensätze durchsuchen, ungewöhnliche Aktivitäten erkennen und sie sofort markieren. Angesichts der unüberschaubar vielen Möglichkeiten, die Sicherheit zu verletzen, werden echte maschinelle Lernsysteme in den kommenden Tagen eine absolute Notwendigkeit sein.
Kredite/Kreditkarten/Versicherungen Underwriting
Das Underwriting könnte als perfekter Job für maschinelles Lernen in der Finanzbranche bezeichnet werden, und in der Tat gibt es in der Branche große Sorgen, dass Maschinen einen großen Teil der heute bestehenden Underwriting-Positionen ersetzen werden.
Vor allem bei großen Unternehmen (Großbanken und börsennotierten Versicherungsunternehmen) können maschinelle Lernalgorithmen auf Millionen von Verbraucherdaten und Finanz- oder Versicherungsergebnissen trainiert werden, z. B. darauf, ob eine Person ihren Kredit oder ihre Hypothek nicht bedient hat.
Die zugrundeliegenden finanziellen Trends können mit Algorithmen bewertet und kontinuierlich analysiert werden, um Trends zu erkennen, die das Kreditvergabe- und Underwriting-Risiko in Zukunft beeinflussen könnten. Algorithmen können automatisierte Aufgaben wie den Abgleich von Datensätzen, die Identifizierung von Ausnahmen und die Berechnung, ob ein Antragsteller für ein Kredit- oder Versicherungsprodukt geeignet ist, übernehmen.
Automatisierung und Chatbots
Die Automatisierung eignet sich hervorragend für das Finanzwesen. Sie reduziert die Belastung, die sich wiederholende, geringwertige Aufgaben auf menschliche Mitarbeiter/innen ausüben. Sie nimmt die alltäglichen Routineprozesse in Angriff und verschafft den Teams den nötigen Freiraum, um ihre hochwertige Arbeit zu erledigen. Auf diese Weise lassen sich enorme Zeit- und Kosteneinsparungen erzielen.
Wenn man maschinelles Lernen und KI in den Automatisierungsmix einbezieht, erhält man eine weitere Ebene der Unterstützung für die Beschäftigten. Mit Zugriff auf relevante Daten können maschinelles Lernen und KI eine tiefgreifende Datenanalyse durchführen, um Finanzteams bei schwierigen Entscheidungen zu unterstützen. In manchen Fällen können sie sogar die beste Vorgehensweise empfehlen, die die Beschäftigten genehmigen und umsetzen müssen.
KI und Automatisierung im Finanzsektor können auch lernen, Fehler zu erkennen, wodurch die Zeit zwischen Entdeckung und Lösung reduziert wird. Das bedeutet, dass sich menschliche Teammitglieder bei der Erstellung ihrer Berichte weniger verspäten und ihre Arbeit mit weniger Fehlern erledigen können.
KI-Chatbots können zur Unterstützung von Finanz- und Bankkunden eingesetzt werden. Mit der zunehmenden Beliebtheit von Live-Chat-Software im Bank- und Finanzwesen sind Chatbots die natürliche Weiterentwicklung.
Risikomanagement
Die Techniken des maschinellen Lernens verändern die Art und Weise, wie wir das Risikomanagement angehen. Alle Aspekte des Risikoverständnisses und der Risikokontrolle werden durch das Wachstum von Lösungen, die durch maschinelles Lernen angetrieben werden, revolutioniert. Die Beispiele reichen von der Entscheidung, wie viel eine Bank einem Kunden leihen sollte, bis hin zur Verbesserung der Compliance und der Reduzierung von Modellrisiken.
Vermögenspreisvorhersage
Die Vorhersage von Vermögenspreisen gilt als der am häufigsten diskutierte und anspruchsvollste Bereich im Finanzwesen. Die Vorhersage von Vermögenspreisen ermöglicht es, die Faktoren zu verstehen, die den Markt antreiben, und auf die Entwicklung von Vermögenswerten zu spekulieren. Traditionell wurden die Preise von Vermögenswerten vorhergesagt, indem vergangene Finanzberichte und Marktentwicklungen analysiert wurden, um zu bestimmen, welche Position für ein bestimmtes Wertpapier oder eine bestimmte Anlageklasse eingenommen werden sollte. Mit demenormen Anstieg der Finanzdatenmenge werden die traditionellen Analyseansätze und Strategien zur Aktienauswahl jedoch durch ML-basierteVerfahren ergänzt.
Derivative Preisgestaltung
Die jüngsten Erfolge des maschinellen Lernens und das hohe Innovationstempo deuten darauf hin, dass ML-Anwendungen für die Preisgestaltung von Derivaten in den kommenden Jahren weit verbreitet sein werden. Die Welt der Black-Scholes-Modelle, der Volatilitätslächeln und der Excel-Tabellenmodelle dürfte verschwinden, wenn fortschrittlichere Methoden verfügbar werden.
Die klassischen Preisbildungsmodelle für Derivate beruhen auf mehreren unpraktischen Annahmen, um die empirische Beziehung zwischen den zugrunde liegenden Eingabedaten (Ausübungspreis, Laufzeit, Optionsart) und dem auf dem Markt beobachteten Preis der Derivate zu reproduzieren. Methoden des maschinellen Lernens stützen sich nicht auf mehrere Annahmen, sondern versuchen lediglich, eine Funktion zwischen den Eingabedaten und dem Preis zu schätzen und die Differenz zwischen den Ergebnissen des Modells und dem Ziel zu minimieren.
Die schnelleren Einsatzzeiten, die mit modernen ML-Tools erreicht werden, sind nur einer der Vorteile, die den Einsatz von maschinellem Lernen bei der Preisbildung von Derivaten beschleunigen werden.
Stimmungsanalyse
Bei der Stimmungsanalyse werden riesige Mengen unstrukturierter Daten wie Videos, Transkriptionen, Fotos, Audiodateien, Social-Media-Beiträge, Artikel und Geschäftsdokumente ausgewertet, um die Marktstimmung zu ermitteln. Die Stimmungsanalyse ist heute für alle Unternehmen wichtig und ein hervorragendes Beispiel für maschinelles Lernen im Finanzwesen.
Die häufigste Anwendung der Stimmungsanalyse im Finanzsektor ist die Analyse von Finanznachrichten - insbesondere die Vorhersage des Verhaltens und möglicher Trends der Märkte. Der Aktienmarkt bewegt sich als Reaktion auf unzählige menschliche Faktoren, und man hofft, dass maschinelles Lernen die menschliche Intuition für Finanzaktivitäten nachahmen und verbessern kann, indem es neue Trends und aufschlussreiche Signale entdeckt.
Ein Großteil der zukünftigen Anwendungen des maschinellen Lernens wird jedoch darin bestehen, soziale Medien, Nachrichtentrends und andere Datenquellen zu verstehen, um die Stimmung der Kunden gegenüber Marktentwicklungen vorherzusagen. Es wird sich nicht nur auf die Vorhersage von Aktienkursen und Handelsgeschäften beschränken.
Handelsabrechnung
Die Handelsabwicklung ist der Prozess der Übertragung von Wertpapieren auf das Konto des Käufers und von Bargeld auf das Konto des Verkäufers nach einer Transaktion eines finanziellen Vermögenswerts.
Obwohl die meisten Geschäfte automatisch und mit wenig oder gar keinem menschlichen Eingriff abgewickelt werden, müssen etwa 30% der Geschäfte manuell abgewickelt werden.
Der Einsatz von maschinellem Lernen kann nicht nur den Grund für fehlgeschlagene Trades ermitteln, sondern auch analysieren, warum die Trades abgelehnt wurden, eine Lösung anbieten und vorhersagen, welche Trades in Zukunft fehlschlagen könnten. Wofür ein Mensch normalerweise fünf bis zehn Minuten bräuchte, kann das maschinelle Lernen in einem Bruchteil einer Sekunde erledigen.
Geldwäscherei
Ein Bericht der Vereinten Nationen schätzt, dass die Menge des weltweit gewaschenen Geldes pro Jahr 2-5% des globalen BIP beträgt. Maschinelle Lernverfahren können interne, öffentlich zugängliche und Transaktionsdaten aus dem größeren Netzwerk eines Kunden analysieren, um Anzeichen für Geldwäsche zu erkennen.
Maschinelles Lernen, Deep Learning, künstliche Intelligenz und Datenwissenschaft
Für die meisten Menschen sind die Begriffe maschinelles Lernen, Deep Learning, künstliche Intelligenz und Datenwissenschaft verwirrend. Tatsächlich verwenden viele Menschen einen Begriff austauschbar mit den anderen.
Abbildung 1-1 zeigt die Beziehungen zwischen KI, maschinellem Lernen, Deep Learning und Data Science. Maschinelles Lernen ist ein Teilbereich der KI, der aus Techniken besteht, die es Computern ermöglichen, Muster in Daten zu erkennen und KI-Anwendungen zu erstellen. Deep Learning hingegen ist ein Teilbereich des maschinellen Lernens, der es Computern ermöglicht, komplexere Probleme zu lösen.
Data Science ist nicht unbedingt eine Unterkategorie des maschinellen Lernens, aber es nutzt maschinelles Lernen, Deep Learning und KI, um Daten zu analysieren und umsetzbare Schlussfolgerungen zu ziehen. Sie kombiniert maschinelles Lernen, Deep Learning und KI mit anderen Disziplinen wie Big Data Analytics und Cloud Computing.
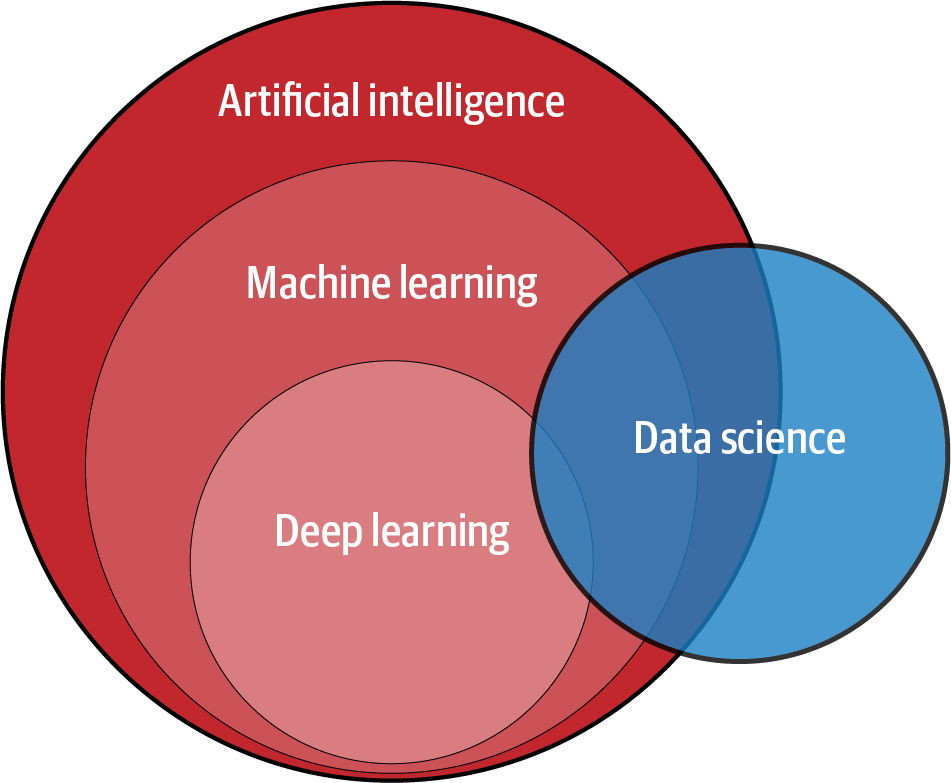
Abbildung 1-1. KI, maschinelles Lernen, Deep Learning und Data Science
Im Folgenden findest du eine Zusammenfassung der Details über künstliche Intelligenz, maschinelles Lernen, Deep Learning und Data Science:
- Künstliche Intelligenz
-
Künstliche Intelligenz ist das Fachgebiet, in dem ein Computer (und seine Systeme) die Fähigkeit entwickelt, komplexe Aufgaben, die normalerweise menschliche Intelligenz erfordern, erfolgreich zu bewältigen. Zu diesen Aufgaben gehören unter anderem die visuelle Wahrnehmung, Spracherkennung, Entscheidungsfindung und die Übersetzung zwischen Sprachen. KI wird in der Regel als die Wissenschaft definiert, die Computer dazu bringt, Dinge zu tun, die bei Menschen Intelligenz erfordern.
- Maschinelles Lernen
-
Maschinelles Lernen ist eine Anwendung der künstlichen Intelligenz, die das KI-System in die Lage versetzt, automatisch aus der Umwelt zu lernen und diese Erkenntnisse anzuwenden, um bessere Entscheidungen zu treffen. Es gibt eine Vielzahl von Algorithmen, die das maschinelle Lernen verwendet, um iterativ zu lernen, Daten zu beschreiben und zu verbessern, Muster zu erkennen und dann Maßnahmen auf diese Muster anzuwenden.
- Deep Learning
-
Deep Learning ist ein Teilbereich des maschinellen Lernens, der sich mit der Untersuchung von Algorithmen beschäftigt, die mit künstlichen neuronalen Netzen verwandt sind, die viele übereinander gestapelte Blöcke (oder Schichten) enthalten. Das Design von Deep Learning-Modellen ist vom biologischen neuronalen Netzwerk des menschlichen Gehirns inspiriert. Es strebt danach, Daten mit einer logischen Struktur zu analysieren, die der Art und Weise ähnelt, wie ein Mensch seine Schlüsse zieht.
- Datenwissenschaft
-
Data Science ist ein interdisziplinäres Fachgebiet, das ähnlich wie Data Mining wissenschaftliche Methoden, Prozesse und Systeme einsetzt, um Wissen oder Erkenntnisse aus strukturierten oder unstrukturierten Daten zu gewinnen. Die Datenwissenschaft unterscheidet sich von ML und KI, weil ihr Ziel darin besteht, durch den Einsatz verschiedener wissenschaftlicher Werkzeuge und Techniken Einblicke in und Verständnis für Daten zu gewinnen. Es gibt jedoch einige Werkzeuge und Techniken, die sowohl ML als auch Data Science gemeinsam haben und von denen einige in diesem Buch vorgestellt werden.
Maschinelles Lernen Typen
In diesem Abschnitt werden alle Arten des maschinellen Lernens vorgestellt, die in den verschiedenen Fallstudien in diesem Buch für verschiedene Finanzanwendungen verwendet werden. Die drei Arten des maschinellen Lernens, die in Abbildung 1-2 dargestellt sind, sind das überwachte Lernen, das unüberwachte Lernen und das verstärkende Lernen.
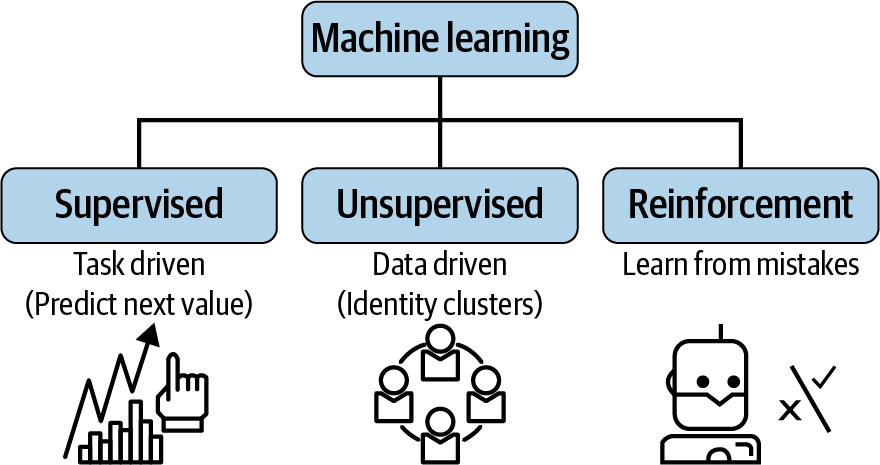
Abbildung 1-2. Arten des maschinellen Lernens
Beaufsichtigt
Das Hauptziel des überwachten Lernens ist es, aus gekennzeichneten Daten ein Modell zu trainieren, das es uns ermöglicht, Vorhersagen über ungesehene oder zukünftige Daten zu treffen. Der Begriff " überwacht" bezieht sich hier auf eine Gruppe von Stichproben, bei denen die gewünschten Ausgangssignale (Labels) bereits bekannt sind. Es gibt zwei Arten von überwachten Lernalgorithmen: Klassifizierung und Regression.
Regression
DieRegression ist eine weitere Unterkategorie des überwachten Lernens, die für die Vorhersage von kontinuierlichen Ergebnissen verwendet wird. Bei der Regression erhalten wir eine Reihe von Prädiktorvariablen (Erklärungsvariablen) und eine kontinuierliche Antwortvariable (Ergebnis oder Ziel) und versuchen, eine Beziehung zwischen diesen Variablen zu finden, die es uns ermöglicht, ein Ergebnis vorherzusagen.
Ein Beispiel für die Regression im Vergleich zur Klassifizierung ist in Abbildung 1-3 dargestellt. Das Diagramm auf der linken Seite zeigt ein Beispiel für eine Regression. Die kontinuierliche Antwortvariable ist die Rendite, und die beobachteten Werte werden gegen die vorhergesagten Ergebnisse aufgetragen. Auf der rechten Seite ist das Ergebnis eine kategoriale Klassenbezeichnung, d. h. ob es sich um einen Bullen- oder Bärenmarkt handelt, und ist ein Beispiel für eine Klassifizierung.
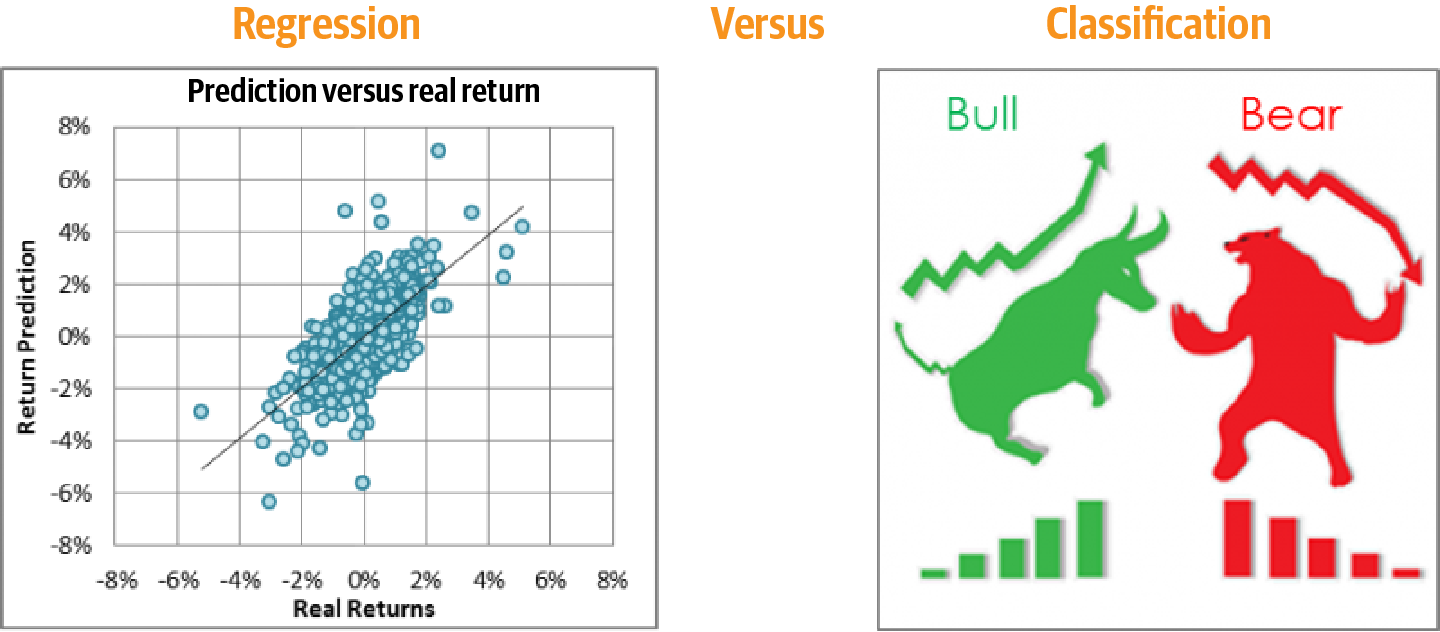
Abbildung 1-3. Regression versus Klassifizierung
Unüberwacht
Unüberwachtes Lernen ist eine Art des maschinellen Lernens, bei dem Rückschlüsse aus Datensätzen gezogen werden, die aus Eingabedaten ohne beschriftete Antworten bestehen. Es gibt zwei Arten des unüberwachten Lernens: Dimensionalitätsreduktion und Clustering.
Dimensionalitätsreduktion
Unter Dimensionalitätsreduktion versteht man die Verringerung der Anzahl von Merkmalen oder Variablen in einem Datensatz, wobei die Informationen und die Gesamtleistung des Modells erhalten bleiben. Sie ist eine gängige und leistungsstarke Methode, um mit Datensätzen umzugehen, die eine große Anzahl von Dimensionen haben.
Abbildung 1-4 veranschaulicht dieses Konzept, bei dem die Dimension der Daten von zwei Dimensionen(X1 und X2) in eine Dimension(Z1) umgewandelt wird. Z1 vermittelt ähnliche Informationen, die in X1 und X2 eingebettet sind, und reduziert die Dimension der Daten.
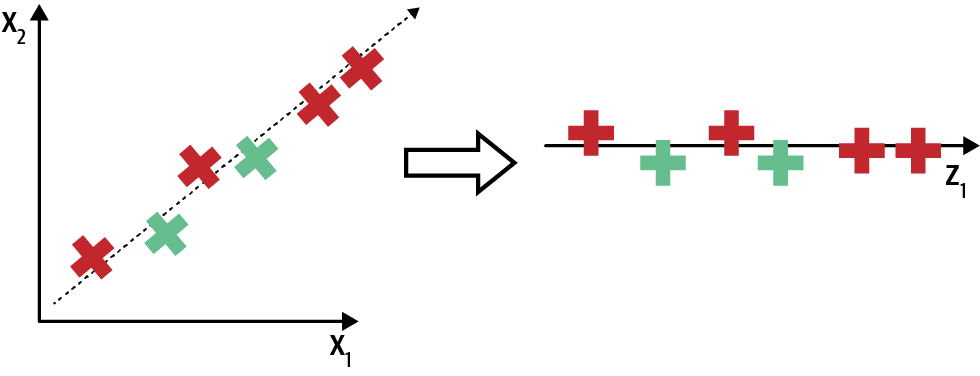
Abbildung 1-4. Dimensionalitätsreduktion
Clustering
Clustering ist eine Unterkategorie der unüberwachten Lerntechniken, die es uns ermöglicht, versteckte Strukturen in Daten zu entdecken. Das Ziel des Clusterns ist es, eine natürliche Gruppierung in den Daten zu finden, so dass Elemente im selben Cluster einander ähnlicher sind als Elemente aus anderen Clustern.
Ein Beispiel für das Clustering ist in Abbildung 1-5 zu sehen, wo die gesamten Daten durch den Clustering-Algorithmus in zwei verschiedene Gruppen eingeteilt werden.
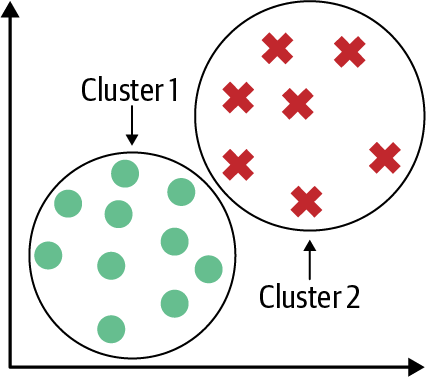
Abbildung 1-5. Clustering
Reinforcement Learning
Das Lernen aus Erfahrungen und den damit verbundenen Belohnungen oder Bestrafungen ist das Kernkonzept des Verstärkungslernens (RL). Es geht darum, geeignete Handlungen durchzuführen, um die Belohnung in einer bestimmten Situation zu maximieren. Das lernende System, ein sogenannter Agent, kann die Umwelt beobachten, Aktionen auswählen und ausführen und dafür Belohnungen (oder Bestrafungen in Form von negativen Belohnungen) erhalten, wie in Abbildung 1-6 dargestellt.
Das Verstärkungslernen unterscheidet sich auf diese Weise vom überwachten Lernen: Beim überwachten Lernen enthalten die Trainingsdaten den Antwortschlüssel, sodass das Modell mit den richtigen Antworten trainiert wird. Beim verstärkenden Lernen gibt es keine explizite Antwort. Das lernende System (Agent) entscheidet, was es tun muss, um die gegebene Aufgabe zu erfüllen, und lernt anhand der Belohnung, ob dies die richtige Handlung war. Der Algorithmus bestimmt den Antwortschlüssel durch seine Erfahrung.
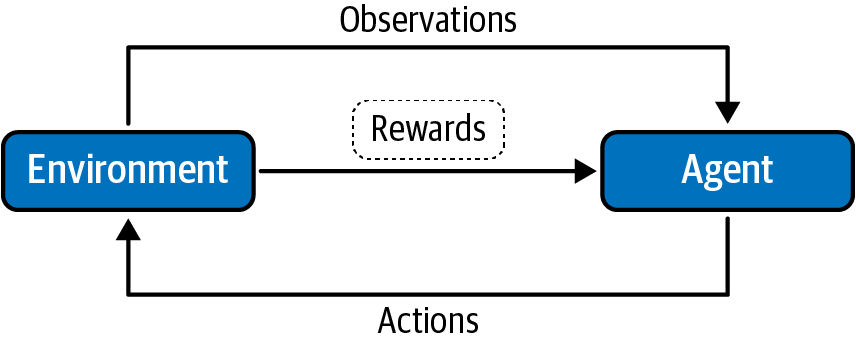
Abbildung 1-6. Verstärkungslernen
Die Schritte des Verstärkungslernens sind wie folgt:
-
Zuerst interagiert der Agent mit der Umgebung, indem er eine Aktion ausführt.
-
Dann erhält der Agent eine Belohnung, die auf der von ihm durchgeführten Aktion basiert.
-
Anhand der Belohnung erhält der Agent eine Beobachtung und erkennt, ob die Handlung gut oder schlecht war. Wenn die Handlung gut war, d.h. wenn der Agent eine positive Belohnung erhalten hat, wird er diese Handlung vorziehen. Wenn die Belohnung weniger gut war, wird der Agent versuchen, eine andere Handlung auszuführen, um eine positive Belohnung zu erhalten. Das ist im Grunde ein Versuch-und-Irrtum-Lernprozess.
Natürliche Sprachverarbeitung
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) ist ein Teilgebiet der KI, das sich mit dem Problem befasst, eine Maschine dazu zu bringen, die Struktur und die Bedeutung der natürlichen Sprache, wie sie von Menschen verwendet wird, zu verstehen. Im NLP werden verschiedene Techniken des maschinellen Lernens und des Deep Learning eingesetzt.
NLP hat viele Anwendungen im Finanzsektor, z. B. in der Stimmungsanalyse, bei Chatbots und in der Dokumentenverarbeitung. Viele Informationen, wie z. B. Verkaufsberichte, Gewinnaufrufe und Zeitungsschlagzeilen, werden über Textnachrichten übermittelt, was NLP im Finanzbereich sehr nützlich macht.
Angesichts der umfangreichen Anwendung von NLP-Algorithmen, die auf maschinellem Lernen basieren, im Finanzwesen ist ein eigenes Kapitel dieses Buches(Kapitel 10) dem NLP und den damit verbundenen Fallstudien gewidmet.
Kapitel Zusammenfassung
Maschinelles Lernen ist in allen Bereichen der Finanzdienstleistungsbranche auf dem Vormarsch. In diesem Kapitel wurden verschiedene Anwendungen des maschinellen Lernens im Finanzwesen behandelt, vom algorithmischen Handel bis hin zu Robo-Advisors. Diese Anwendungen werden in den Fallstudien weiter unten in diesem Buch behandelt.
Nächste Schritte
Was die für maschinelles Lernen verwendeten Plattformen angeht, so wächst das Python-Ökosystem und ist eine der dominierenden Programmiersprachen für maschinelles Lernen. Im nächsten Kapitel werden wir die Schritte der Modellentwicklung kennenlernen, von der Datenaufbereitung bis zur Modellbereitstellung in einem Python-basierten Framework.
Get Maschinelles Lernen und Data Science Blueprints für Finanzen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

