As mentioned, kNN operates on the principle that we should classify records according to similar records. There are some details to be dealt with in defining similar. However, kNN does not have the complexity of parameters and options that come with many models.
Imagine again that we have two classes A and B. This time, however, suppose that we are wanting to classify based on two features, x1 and x2. Visually, this looks something like the following:
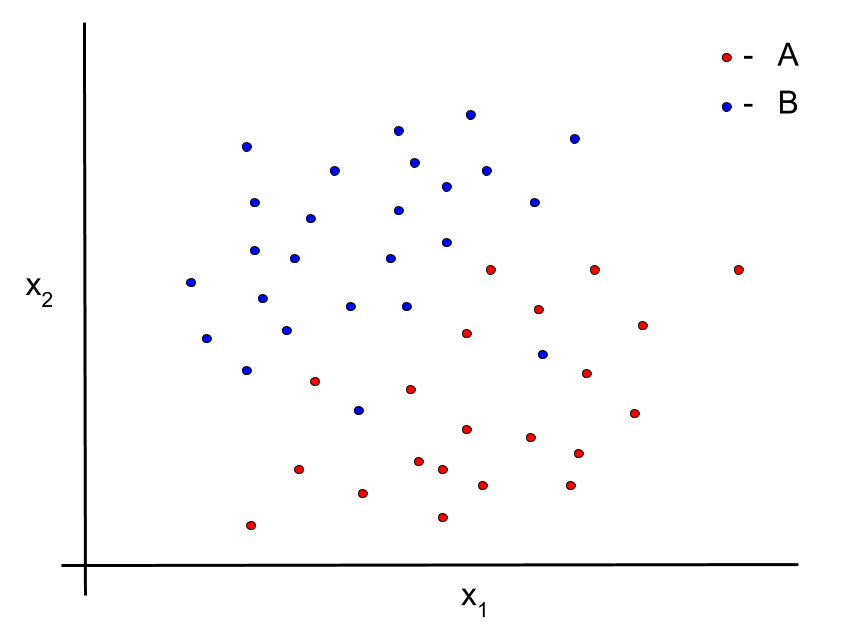
Now, suppose we have a new point of data with an unknown class. This new point of data will sit somewhere in this space. kNN says that, to classify this new point, we should perform ...

