In the LDA architecture, there are M number of documents having an N number of words, that get processed through the black strip called LDA. It delivers X Topics with Cluster of words. Each topic has psi distribution of words out of topics. Finally, it also comes up with a distribution of topics out of documents, which is denoted by phi.
The following diagram illustrates LDA:
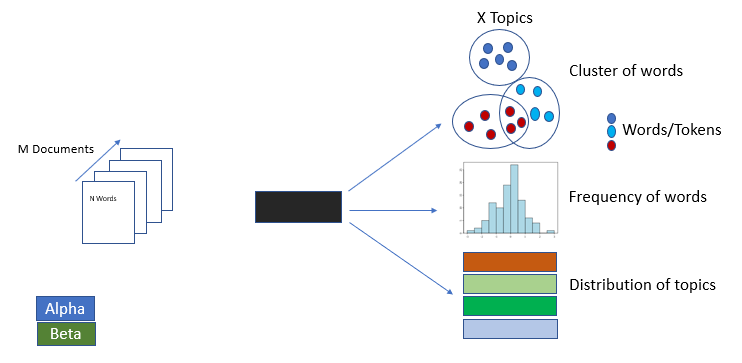
With regard to the Alpha and Beta hyperparameters: alpha represents document-topic concentration and beta represents topic-word concentration. The higher the value of alpha, the more topics we get out of documents. On the other hand, the higher the value ...

