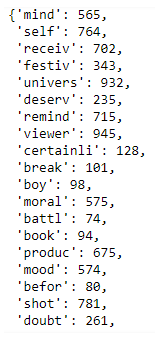
The following code will provide us with the TF-IDF feature extraction:
from sklearn.feature_extraction.text import TfidfVectorizertfidf= TfidfVectorizer(max_df=0.9,min_df= 2, max_features=1000, stop_words="english")tfidfV = tfidf.fit_transform(Newdata['Clean_review2'])tfidf.vocabulary_
We will get the following output: