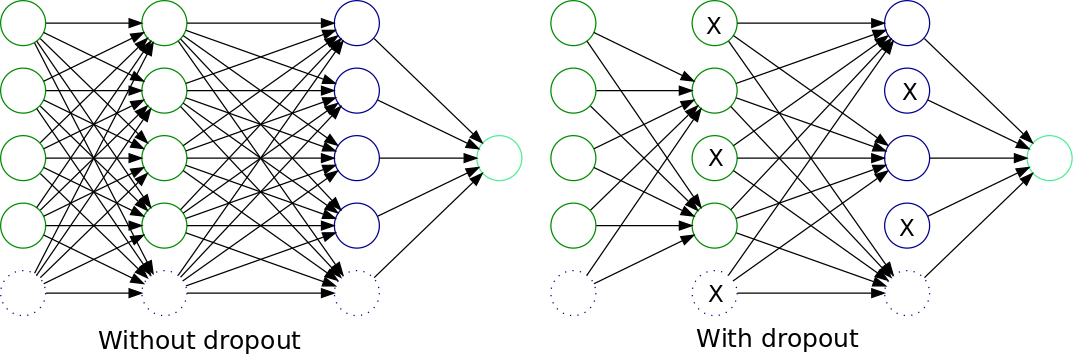
The main advantage of this method is that it prevents all neurons in a layer from synchronously optimizing their weights. This adaptation, made in random groups, prevents all the neurons from converging to the same goal, thus decorrelating the weights.
A second property discovered for the application of dropout is that the activations of the hidden units become sparse, which is also a desirable characteristic.
In the following diagram, we have a representation of an original, fully-connected multi-layer neural network, and the associated network with dropout:
>