In a linear regression problem (as well as in a Principal Component Analysis (PCA)), it's helpful to know how much original variance can be explained by the model. This concept is useful to understand the amount of information that we lose by approximating the dataset. When this value is small, it means that the data generating process has strong oscillations and a linear model fails to capture them. A very simple but effective measure (not very different from R2) is defined as follows:
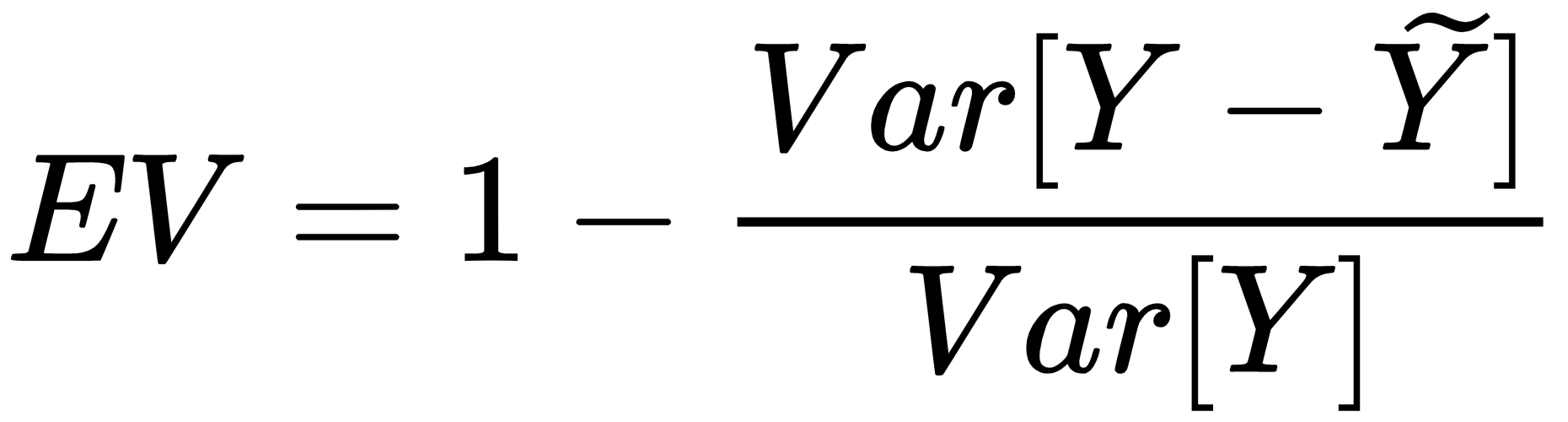
When Y is well approximated, the numerator is close to 0 and EV → 1, which is the optimal value. In all the other cases, the index represents ...

